






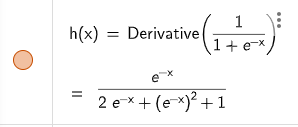
lucasw
大佬教麻
你可以叫我 000 / Lucas
建國中學資訊社37th學術長
建國中學電子計算機研習社44th學術
校際交流群創群者
不會音遊不會競程不會數學的笨
資訊技能樹亂點但都一樣爛
專案爛尾大師
IZCC x SCINT x Ruby Taiwan 聯課負責人
建國中學電子計算機研習社44th學術+總務
是的,我是總務。在座的你各位下次記得交社費束脩給我
技能樹貧乏
想拿機器學習做專題結果只學會使用API
上屆社展烙跑到資訊社的叛徒
科班墊神
四天連假得了MVP
class Neuron:
def __init__(self, w: np.ndarray, b: int) -> None:
self.w = w
self.b = b
def forward(self, x) -> int:
return relu(np.dot(x, self.w.T) + self.b)#$%#*@)$!#)$%(#)$%
以上就是我們知道的感知機
以上就是我們知道的感知機
一個感知機能變成的函數很有限
因此我們會將許多感知機結合
最常見的多重感知機應用便是神經網路
此時我們習慣將感知機稱為 Neuron(神經元)
透過花瓣跟萼片分辨鳶尾花種類
經典分類問題
輸入:花瓣長寬+花萼長寬(4項)
輸出:鳶尾花種類(3種)
山鳶尾(setosa)
雜色鳶尾(vesicolor)
維吉尼亞鳶尾(virginica)
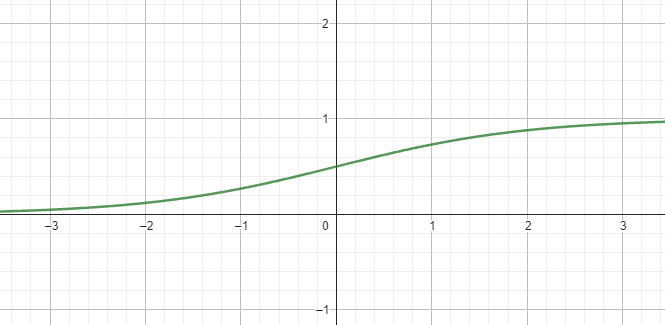
輸出一個機率
山鳶尾(setosa) => 1
雜色鳶尾(vesicolor) => 0
\(\hat y=\sigma(\vec X \cdot \vec W +b)\)
\(L = -\sum [y\ln (\hat y)+(1-y)\ln (1-\hat y)]\)
\(y\)是實際機率
\(\hat y\)是預估機率
\(\frac{\partial L}{\partial w_i}=\frac{\partial L}{\partial u}\frac{\partial u}{\partial w_i}\), \(u=x_i\times w_i+b\)
\(\frac{\partial L}{\partial u}=\frac{\partial L}{\partial \sigma(u)}\frac{\partial \sigma(u)}{\partial u}=\sum (\hat y-y)\)
\(\frac{\partial L}{\partial u}=\frac{\partial L}{\partial \hat y}\frac{\partial \hat y}{\partial u}\)
\(\frac{\partial L}{\partial u}=\frac{\partial L}{\partial \sigma (u)}\frac{\partial \sigma (u)}{\partial u}\)
\(\frac{\partial L}{\partial w_i}=\sum(\hat y_i-y_i)\times x_i\)
\(\frac{\partial L}{\partial w_i}=\sum(\hat y-y)\times\frac{\partial u}{\partial w_i}\), \(u=x_i\times w_i+b\)
\(\frac{\partial L}{\partial b}=\sum(\hat y-y)\times\frac{\partial u}{\partial b}\), \(u=x_i\times w_i+b\)
\(\frac{\partial L}{\partial b}=\sum(\hat y_i-y_i)\)
| id | 花萼長 | 花萼寬 | 花瓣長 | 花瓣寬 | 品種 |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| ... | ... | ... | ... | ... | ... |
| 150 | 5.9 | 3.0 | 5.1 | 1.8 | Iris-virginica |
setosa
versicolor
virginica
id
1~50
51~100
101~150
| id | 花萼長 | 花萼寬 | 花瓣長 | 花瓣寬 | 品種 |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| ... | ... | ... | ... | ... | ... |
| 100 | 5.7 | 2.8 | 4.1 | 1.3 | Iris-versicolor |
setosa
versicolor
id
1~50
51~100
| id | 花萼長 | 花萼寬 | 花瓣長 | 花瓣寬 | Label |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | 1 |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | 1 |
| ... | ... | ... | ... | ... | ... |
| 100 | 5.7 | 2.8 | 4.1 | 1.3 | 0 |
setosa => 1
versicolor => 0
id
1~50
51~100
| 花萼長 | 花萼寬 | 花瓣長 | 花瓣寬 | Label |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | 1 |
| 4.9 | 3.0 | 1.4 | 0.2 | 1 |
| ... | ... | ... | ... | ... |
| 5.7 | 2.8 | 4.1 | 1.3 | 0 |
setosa => 1
versicolor => 0
1~50
51~100
| 花萼長 | 花萼寬 | 花瓣長 | 花瓣寬 | Label |
|---|---|---|---|---|
| 5.0 | 2.3 | 3.3 | 1.0 | 0 |
| 5.1 | 3.8 | 1.9 | 0.4 | 1 |
| ... | ... | ... | ... | ... |
| 4.7 | 3.2 | 1.6 | 0.2 | 1 |
setosa => 1
versicolor => 0
y = data[:,4].reshape(-1,1)
| 花萼長 | 花萼寬 |
|---|---|
| 5.0 | 2.3 |
| 5.1 | 3.8 |
| ... | ... |
| 4.7 | 3.2 |
| Label |
|---|
| 0 |
| 1 |
| ... |
| 1 |
x = data[:,0:2]
y = data[:,4].reshape(-1,1)
x = data[:,0:2]
W = np.random.randn(2,1)
b = np.random.randn(1)
\(\hat y=\sigma(\vec X \cdot \vec W +b)\)
\(-\sum [y\ln (\hat y)+(1-y)\ln (1-\hat y)]\)
\(\hat y=\sigma(\vec X \cdot \vec W +b)\)
\(\hat y=\sigma(\vec X \cdot \vec W +b)\)
\(\hat y=\sigma(\vec X \cdot \vec W +b)\)
\(\hat y=\sigma(\vec X \cdot \vec W +b)\)
\(\frac{\partial L}{\partial w_i}=\sum(\hat y_i-y_i)\times x_i\)
\(\frac{\partial L}{\partial b}=\sum(\hat y_i-y_i)\)
\(\frac{\partial L}{\partial w_i}=\sum(\hat y_i-y_i)\times x_i\)
\(\frac{\partial L}{\partial w_i}=\sum(\hat y_i-y_i)\times x_i\)
\(\frac{\partial L}{\partial w_i}=\sum(\hat y_i-y_i)\times x_i\)
\(\frac{\partial L}{\partial w_i}=\sum(\hat y_i-y_i)\times x_i\)
\(\frac{\partial L}{\partial w_i}=\sum(\hat y_i-y_i)\times x_i\)
\(\frac{\partial L}{\partial w_i}=\sum(\hat y_i-y_i)\times x_i\)
\(\frac{\partial L}{\partial b}=\sum(\hat y_i-y_i)\)
np.sum
layer
#&#%(@$#@)*%
#&#%(@$#@)*%
#&#%(@$#@)*%
#&#%(@$#@)*%
#&#%(@$#@)*%
Input Layer
#&#%(@$#@)*%
Input Layer
Hidden Layer
#&#%(@$#@)*%
Input Layer
Hidden Layer
Output Layer
#&#%(@$#@)*%
Input Layer
Hidden Layer
Output Layer
#&#%(@$#@)*%
Input Layer
Hidden Layer
Output Layer
#&#%(@$#@)*%
我們的目的就是幫要解決的問題
找出一個完美的函式
使同一類問題的輸入都能夠得到正確的輸出
#&#%(@$#@)*%
但是我要怎麼知道
每個神經元的參數應該要是多少呢?
我們的目的就是幫要解決的問題
找出一個完美的函式
使同一類問題的輸入都能夠得到正確的輸出
如何讓他們成為應該成為這個
目標函式的正確參數?
很多的權重與偏移
先隨便帶入任意數字
為正確的數據
為輸出的數據
我們先把算式簡化(適用於單一結果正確情況)
我們先把算式簡化(適用於單一結果正確情況)
代表著當x的比例越低 數值越高
我們先把算式簡化(適用於單一結果正確情況)
當預測值偏離1(正確)越遠,熵增加的越快
所以說我們要讓Loss越低越好
def cross_entropy(self, y_output: np.ndarray, y_label: np.ndarray) -> int:
return -np.dot(y_label, np.log2(y_output))得到了Loss之後
就可以準備來更新參數了
def cross_entropy(self, y_output: np.ndarray, y_label: np.ndarray) -> int:
return -np.dot(y_label, np.log2(y_output))Loss
W
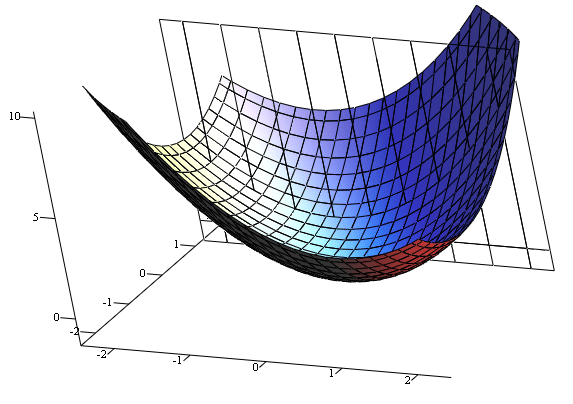
我們要做的就是找到圖中Loss最低點
並將W更新
Loss
W
我們要做的就是找到圖中Loss最低點
並將W更新
問題是要怎麼讓程式知道最低點呢?
Loss
W
直接把每個組合試過一遍
Loss
W
Loss
W
Loss
W
Loss
W
直接把每個組合試過一遍
各位競程大師用腳想都知道那個時間複雜度會爆炸
Loss
W
Loss
W
Loss
W
Loss
W
況且我們還不只一個參數
看起來很難懂
看起來很難懂
直接上圖
Loss
W
Loss
W
目標點
Loss
W
起始點
Loss
W
起始點
對起始點做微分
Loss
W
對起始點做微分
從微分後得到的斜率就可以判斷低點是在左邊還是右邊
Loss
W
對起始點做微分
從微分後得到的斜率就可以判斷低點是在左邊還是右邊
Loss
W
對起始點做微分
從微分後得到的斜率就可以判斷低點是在左邊還是右邊
Loss
W
對起始點做微分
從微分後得到的斜率就可以判斷低點是在左邊還是右邊
並且向那個方向前進直到斜率=0
Loss
W
對起始點做微分
從微分後得到的斜率就可以判斷低點是在左邊還是右邊
並且向那個方向前進直到斜率=0
但是我們的參數顯然不是只有一個
所以要對每個參數分別進行偏微分
下一次的位置
下一次的位置
這次的位置
下一次的位置
這次的位置
學習率
下一次的位置
這次的位置
學習率
偏微分
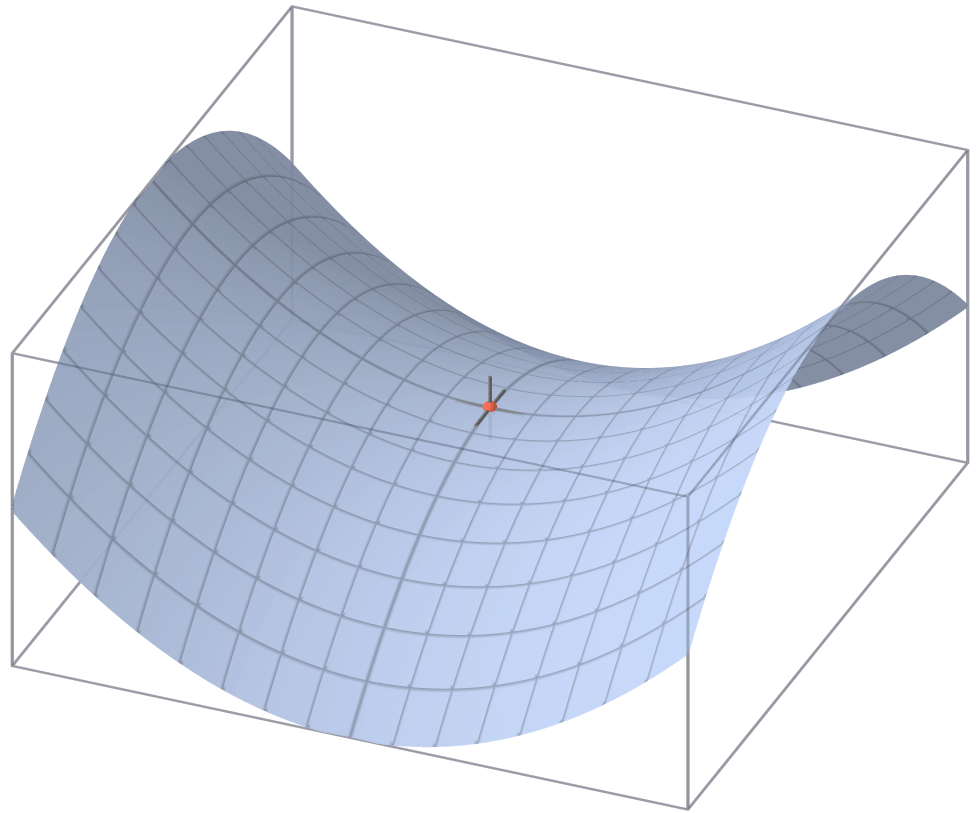
有機率找到的不是全域最小值
而是局部最小值
長得像鞍一樣的形狀
若是結果趨近於這種形狀
將會產生其中一軸最低點
=另一軸最高點
在梯度下降時便會容易卡在裡面
如果一部份的路徑過於平緩可能會
導致梯度下降的速度變很慢
當學習率過高時有可能一直卡在一個谷中找不到最低點
反向傳播時重複對梯度做微分後的activation function
有時候會造成梯度快速減少最終消失
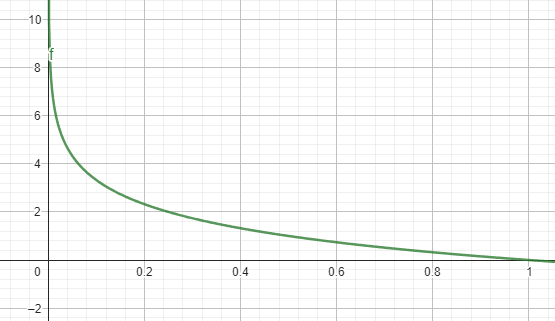
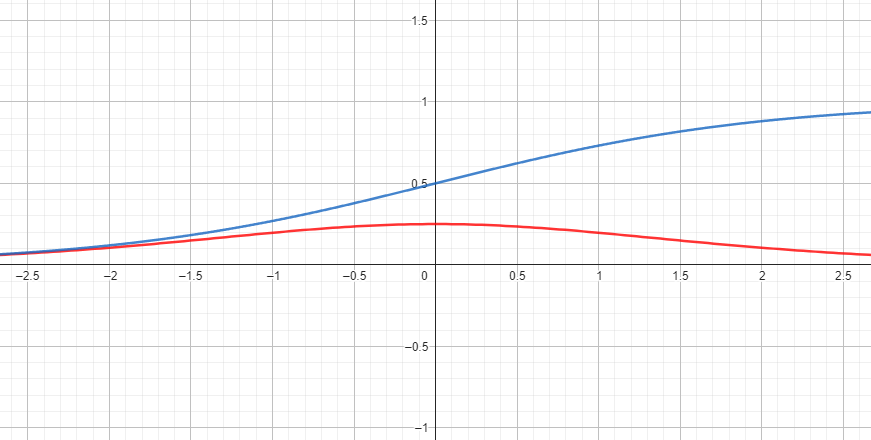
舉個例子
Sigmoid在微分過後函數落在[1/4, 0]之區間
若重複進行便有可能會使梯度趨近於0
藍線: 原
紅線: 微分後
同理於梯度消失
當梯度不斷變大之後會發生超過程式上限的狀況
最終會導致bug
這種優化方式會讓每次梯度下降時
只要與之前的更新方向相同便加快速度(v)
反之減慢速度(v)
第一次操作與一般梯度下降相同
之後的操作則會以前一次的速度乘上
運動量阻力係數( ) ※這東西小於等於1
再拿去跟前一次的梯度做差
僅是一個極小的數
用以防止分母為0無法計算
※
對過去時間點的所有梯度做平方和後開根號
可得到過去梯度的大致數值
而拿當前時間點的梯度除以過去時間點的梯度
便可得知當前時間點的梯度與過去的偏差
有點難理解?
沒關係 直接上圖!
總而言之就是如果這次的梯度特別大/小
這次的學習率便提升/降低
反之如果梯度差異不大
學習率便隨著更新次數降低
是不是覺得有點眼熟呢?
沒錯!!! Adam其實就是融合了上面2種優化型而誕生的東西
同時也是目前使用率最高的Optimizer
以z表示該神經元過激勵函數前的輸出
以y表示神經網路的輸出
以L表示Loss
Loss
W
該w的梯度為在整個產生Loss的函式中對w微分的結果
該w的梯度為在整個產生Loss的函式中對w微分的結果
我們先來求在該神經元中對w微分
->
->
->
->
->
->
這邊的算式可得知欲求之值之後其實就是前一項的a
(a亦為乘上權重前的參數)
回到這一頁
接下來求整個函式中對該神經元的微分
這邊可以發現說其實我們可以藉由這個遞迴關係直接拿最後面的資訊往前算
至於最後面的資訊....
根據選用的loss function不同計算也會不一樣
如果是範例中的softmax + cross entropy的話
微分過後會變成
由此可知先記錄一開始向前傳播時拿到的資訊(z)後
從後方再進行一次傳播便可獲得每個參數的梯度
->
->
統整一下整個神經網路的最佳化流程
->
->
資訊傳入
->
->
過神經網路運算
->
->
得到結果與Loss
<-
<-
從結果計算反向傳播時的輸入
<-
<-
更新參數
<-
<-
更新參數完畢
*視為常數
By lucasw




