
lucasw
大佬教麻
你可以叫我 000 / Lucas
建國中學資訊社37th學術長
建國中學電子計算機研習社44th學術
校際交流群創群者
不會音遊不會競程不會數學的笨
資訊技能樹亂點但都一樣爛
專案爛尾大師
IZCC x SCINT x Ruby Taiwan 聯課負責人
建國中學電子計算機研習社44th學術+總務
是的,我是總務。在座的你各位下次記得交社費束脩給我
技能樹貧乏
想拿機器學習做專題結果只學會使用API
上屆社展烙跑到資訊社的叛徒
科班墊神
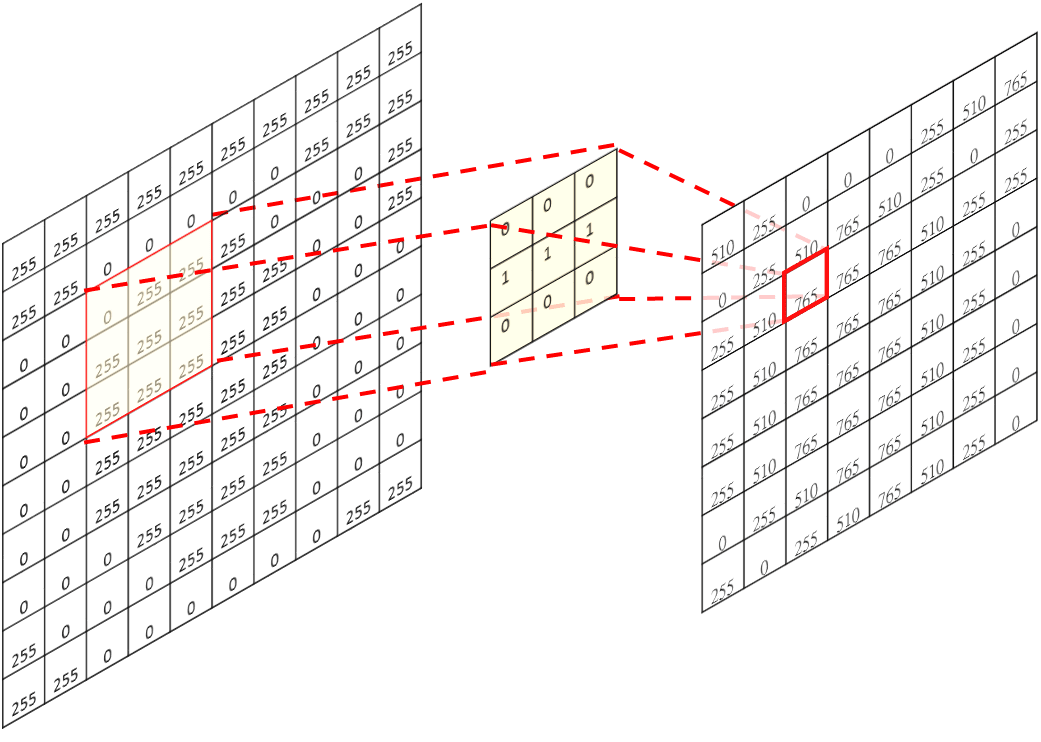
一張圖在經過卷積層時
會被截取出許多特徵
並且將圖片資訊壓縮
最後將這些圖片放入我們原本的神經網路
也稱為全連接層(Fully-Connected)
看著是挺抽象
但是你可以發現當f, g皆為純量的離散資料時
也就是我們在做多維的離散卷積時
可以視為各元素積構成的新離散資料
換成我們看得懂的形式也就是
換成我們看得懂的形式也就是
他可以讓一張圖片的每個像素進行一種固定改變
如銳化、浮雕
經常被使用在濾鏡上面
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
path = os.path.join(os.path.dirname(__file__), 'test.jpg')
x = Image.open(path)
x = np.asarray(x)
kernels = []
kernels.append(np.array([
[0, 0, 0],
[0, 1, 0],
[0, 0, 0]
]))
kernels.append(np.array([
[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]
]))
kernels.append(np.array([
[1, 1, 1],
[1, -7, 1],
[1, 1, 1]
]))
kernels.append(np.array([
[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1]
]))
kernels.append(np.array([
[-1, -1, 0],
[-1, 0, 1],
[0, 1, 1]
]))
for kernel in kernels:
image = cv2.filter2D(x, -1, kernel)
plt.imshow(image)
plt.show()一種卷積變體
將卷積的kernel換成特定條件
來達到縮小圖片 保留資訊
Max Pooling: 取區塊內最大值
Mean/Average Pooling: 取區塊平均值
通常我們在卷積層會經過
一次卷積 一次池化
因此圖片會縮小尺寸
首先我們要知道卷積層像是神經元一樣
可以橫豎擴張
對同張圖過多個卷積層
產生出來的圖像分別向後傳遞
過好幾次卷積層
然後我們需要知道
不管是卷積還是池化
我們可以控制他在橫向與縱向上的步伐
以上述的卷積&池化為例
最後你就可以開始實作了
def conv(self, x: np.ndarray, kernel: np.ndarray) -> np.ndarray:
c, cx, cy = \
self.conv_kernel_size, self.conv_kernel_size[0], self.conv_kernel_size[1]
output_shape = [int((x.shape[i]-c[i])/(self.conv_strides[i])+1) for i in [0, 1]]
output = np.zeros(output_shape)
for i, ix in enumerate(range(0, x.shape[0]-cx+1, self.conv_strides[0])):
for j, jx in enumerate(range(0, x.shape[1]-cy+1, self.conv_strides[1])):
output[i, j] = np.sum(x[ix:ix+cx, jx:jx+cy] * kernel)
return outputdef max_pooling(self, x: np.ndarray, pooling_maximum: list[list[tuple]]) -> np.ndarray:
p, px, py = \
self.pool_kernel_size, self.pool_kernel_size[0], self.pool_kernel_size[1]
output_shape = [int((x.shape[i]-p[i])/(self.pool_strides[i])+1) for i in [0, 1]]
output = np.zeros(output_shape)
for i, ix in enumerate(range(0, x.shape[0]-px+1, self.pool_strides[0])):
pooling_maximum.append([])
for j, jx in enumerate(range(0, x.shape[1]-px+1, self.pool_strides[1])):
t = x[ix:ix+px, jx:jx+py]
output[i, j] = np.max(t)
pooling_maximum[i].append([])
pooling_maximum[i][j].append(t.argmax())
return outputdef forward(self, x: np.ndarray) -> np.ndarray:
assert x.shape[0] == self.data_size[0] * self.data_size[1]
x = x.reshape(self.data_size[0], self.data_size[1])
x_conv = []
self.pooling_maximum = []
self.X = []
for i in range(len(self.kernels)):
self.pooling_maximum.append([])
_x = x.copy()
self.X.append([])
for j in range(len(self.kernels[i])):
self.pooling_maximum[i].append([])
self.X[i].append(_x.copy())
_x = self.conv(_x, self.kernels[i][j])
_x = self.max_pooling(_x, self.pooling_maximum[i][j])
x_conv.extend(_x.reshape(-1))
x_conv = np.array(x_conv).astype("float64")
assert x_conv.shape[0] == self.layers[0]
return super().forward(x_conv)除了FC的反向傳播外
kernel也可以透過反向傳播更新
當然你也可以選擇固定kernel
來在特定資料上抓指定的特徵
卷積的部分
我們需要兩個操作
一個是更新參數(供當前的kernel更新)
一個是反向卷積(供更前面的資訊使用)
def dconv(self, x: np.ndarray, dy: np.ndarray) -> np.ndarray:
cx, cy = self.conv_kernel_size[0], self.conv_kernel_size[1]
d_kernel = np.zeros(self.conv_kernel_size)
for i, ix in enumerate(range(0, x.shape[0]-cx+1, self.conv_strides[0])):
for j, jx in enumerate(range(0, x.shape[1]-cy+1, self.conv_strides[1])):
d_kernel += x[ix:ix+cx, jx:jx+cy] * dy[i, j]
return d_kernel更新參數
def bconv(self, x: np.ndarray, kernel: np.ndarray) -> np.ndarray:
kernel = np.flip(np.flip(kernel, axis=0), axis=1)
padded = np.pad(x, ((kernel.shape[0]-1, kernel.shape[0]-1), (kernel.shape[1]-1, kernel.shape[1]-1)), mode="constant")
return self.conv(padded, kernel)反向卷積
接著是池化
池化沒有需要更新的東西
所以做個反向池化即可
那麼問題來了
要怎麼反向呢
還記得我們紀錄了每次池化的最大值位置
argmax()
def max_pooling(self, x: np.ndarray, pooling_maximum: list[list[tuple]]) -> np.ndarray:
p, px, py = \
self.pool_kernel_size, self.pool_kernel_size[0], self.pool_kernel_size[1]
output_shape = [int((x.shape[i]-p[i])/(self.pool_strides[i])+1) for i in [0, 1]]
output = np.zeros(output_shape)
for i, ix in enumerate(range(0, x.shape[0]-px+1, self.pool_strides[0])):
pooling_maximum.append([])
for j, jx in enumerate(range(0, x.shape[1]-px+1, self.pool_strides[1])):
t = x[ix:ix+px, jx:jx+py]
output[i, j] = np.max(t)
pooling_maximum[i].append([])
pooling_maximum[i][j].append(t.argmax())
return output還記得我們紀錄了每次池化的最大值位置
argmax()
而逆向操作時就是把池化後的值填回去
當初拿值的位置
Q: 其他資訊呢?
A: 跟Loss沒關聯 更新不會用到
def bmax_pooling(self, x: np.ndarray, pooling_maximum: list[list[tuple]]) -> np.ndarray:
p, px, py = self.pool_kernel_size, self.pool_kernel_size[0], self.pool_kernel_size[1]
output_shape = [int(((x.shape[i]-1)*self.pool_strides[i])+p[i]) for i in [0, 1]]
output = np.zeros(output_shape)
for i in range(x.shape[0]):
for j in range(x.shape[1]):
argmax = pooling_maximum[i][j][0]
output[i*px+argmax//px, j*py+argmax%px] = x[i, j]
return outputdef backward(self, y: np.ndarray) -> None:
x_conv = super().backward(y)
size = self.conv_data_size / self.conv_layer[1]
x_conv = x_conv.reshape(self.conv_layer[1], int(np.sqrt(size)), int(np.sqrt(size)))
for i in reversed(range(len(self.kernels))):
x = x_conv[i].copy()
for j in reversed(range(len(self.kernels[i]))):
x = self.bmax_pooling(x, self.pooling_maximum[i][j])
self.kernels[i][j] -= self.learning_rate * self.dconv(self.X[i][j], x)
x = self.bconv(x, self.kernels[i][j])你可以
但如果要更有效率
你還可以
By lucasw




