PV226 ML: AutoML
Content of this session
ML frameworks - comparison and experience
AutoML
How to evaluate ML model
Before we start:
How does the model look?
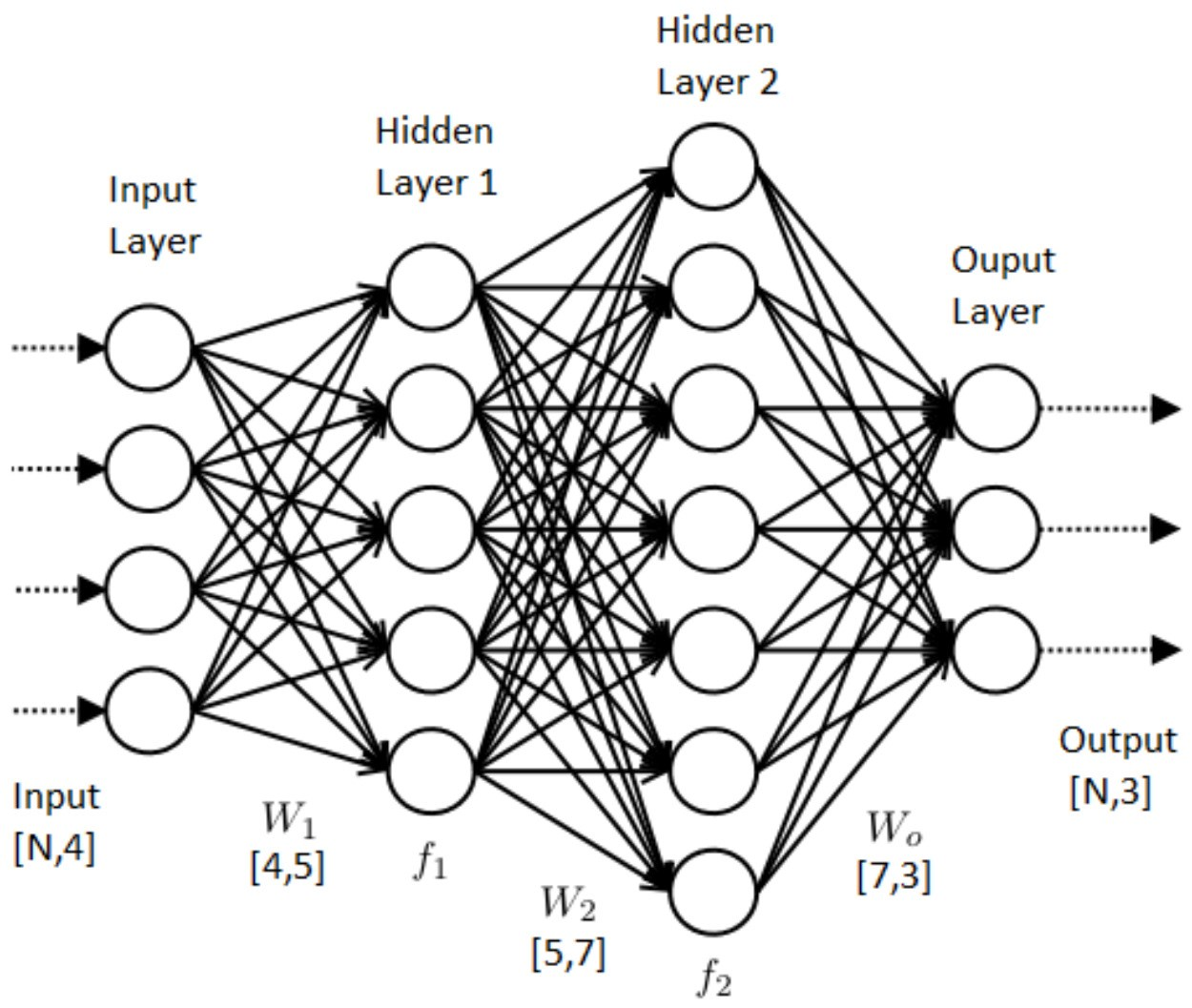
This must be represented in some way
First layer is an input and last an output
Result is an application. Containerised application.
Later challenges: scaling
ML Frameworks
Are used to create such model.
Tensorflow

- Low-level lib (with some high level interfaces)
- Good for general ML task
- Works on CPU and GPU, and all major OS
- Developed by Google
Keras
- High level abstraction on top of TensorFlow
- Focused on neural networks
- Huge ecosystem

PyTorch
- Competition to TensorFlow
- Easier debugging and more customisation
- Huge ecosystem but not as wide as TF

There are Julia frameworks: knet and flux
And AutoML tools from:
Amazon: Sage Maker
Amazon: Sage Maker
- price-wise ok
- does not provide so good results as Google or Microsoft
- Rapidly growing
- Good pretrained models for ecommerce
Google: AutoML Tables
- only NN or decision trees
- best results from top 3 cloud providers
- most expensive (= too expensive for my taste)
Microsoft: ML Studio
- many different algorithms
- not so stable results but good enough
- cheap
AutoML will do all the work for you
- it will prepare data
- try different algorithms
- prepare container

An AutoML system based on Keras.
Installation
pip install autokeras3.5 <= Python < 3.9 and TensorFlow >= 2.3.0
Supported Tasks
- Image Classification
- Image Regression
- Text Classification
- Text Regression
- Structured Data Classification
- Structured Data Regression
Working with Autokeras
from sklearn.datasets import fetch_california_housing
import numpy as np
import pandas as pd
import tensorflow as tf
import autokeras as ak
house_dataset = fetch_california_housing()
df = pd.DataFrame(
np.concatenate((
house_dataset.data,
house_dataset.target.reshape(-1,1)),
axis=1),
columns=house_dataset.feature_names + ['Price'])
train_size = int(df.shape[0] * 0.9)
df[:train_size].to_csv('train.csv', index=False)
df[train_size:].to_csv('eval.csv', index=False)
train_file_path = 'train.csv'
test_file_path = 'eval.csv'prepare data
Working with Autokeras
# Initialize the structured data regressor.
reg = ak.StructuredDataRegressor(
overwrite=True,
max_trials=3) # It tries 3 different models.
# Feed the structured data regressor with training data.
reg.fit(
# The path to the train.csv file.
train_file_path,
# The name of the label column.
'Price',
epochs=10)
# Predict with the best model.
predicted_y = reg.predict(test_file_path)
# Evaluate the best model with testing data.
print(reg.evaluate(test_file_path, 'Price'))train and evaluate
Let's say we created model. How to evaluate it?
Classification
| conf. matrix | Data | Data | |
|---|---|---|---|
| positive | negative | ||
| Model | positive | a | b |
| Model | negative | c | d |
Accuracy = (a+d)/(a+b+c+d)
Sensitivity (Recall) = a/(a+c) proportion of positive cases correctly identified
Specificity = d/(b+d) proportion of negative cases correctly identified
Confusion Matrix
F1 = 2*((precision*recall)/(precision+recall))
Matthews correlation coefficient
value from -1 to 1
0 equals random walk
Regression
Root Mean Squared Error |
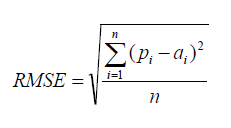
| RMSE is probably the most popular formula to measure the error rate of a regression model. |
Relative Squared Error
|
Relative squared error (RSE) can be compared between models whose errors are measured in the different units. |
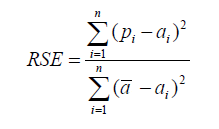
Mean Absolute Error
The mean absolute error (MAE) has the same unit as the original data, and it can only be compared between models whose errors are measured in the same units. It is usually similar in magnitude to RMSE, but slightly smaller.
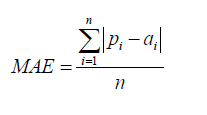
Relative Absolute Error
Like RSE , the relative absolute error (RAE) can be compared between models whose errors are measured in the different units.
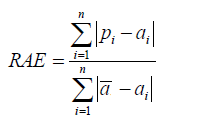
Standardized Residuals (Errors) Plot
Now let's get model
Exporting model
# Export as a Keras Model.
model = clf.export_model()
print(type(model)) # <class 'tensorflow.python.keras.engine.training.Model'>
try:
model.save("model_autokeras", save_format="tf")
except:
model.save("model_autokeras.h5")
Importing model
from tensorflow.keras.models import load_model
loaded_model = load_model("model_autokeras", custom_objects=ak.CUSTOM_OBJECTS)
predicted_y = loaded_model.predict(tf.expand_dims(x_test, -1))
print(predicted_y)Topics for discussion:
- data storage
- computation power
- GPUs vs CPUs
- cloud services
- ML pipelines
Any questions?
PV226: AutoML
By Lukáš Grolig



