PB138 JSON and REST APIS
presented by Lukas Grolig
JSON
(JavaScript Object Notation) is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for machines to parse and generate. It is based on a subset of the JavaScript
JSON is built on two structures:
A collection of name/value pairs. In various languages, this is realized as an object, record, struct, dictionary, hash table, keyed list, or associative array.
An ordered list of values. In most languages, this is realized as an array, vector, list, or sequence.
JSON
- Most used text format to share data between apps
- Files usually have an extension .json
- Mimetype is application/json
- Relatively more compact than XML
- Javascript use it as default configuration format
Let's compare JSON with XML
{
"widget": {
"debug": "on",
"window": {
"title": "Sample Konfabulator Widget",
"name": "main_window",
"width": 500,
"height": 500
},
"image": {
"src": "Images/Sun.png",
"name": "sun1",
"hOffset": 250,
"vOffset": 250,
"alignment": "center"
},
"text": {
"data": "Click Here",
"size": 36,
"style": "bold",
"name": "text1",
"hOffset": 250,
"vOffset": 100,
"alignment": "center",
"onMouseUp": "sun1.opacity = (sun1.opacity / 100) * 90;"
}
}
} <widget>
<debug>on</debug>
<window title="Sample Konfabulator Widget">
<name>main_window</name>
<width>500</width>
<height>500</height>
</window>
<image src="Images/Sun.png" name="sun1">
<hOffset>250</hOffset>
<vOffset>250</vOffset>
<alignment>center</alignment>
</image>
<text data="Click Here" size="36" style="bold">
<name>text1</name>
<hOffset>250</hOffset>
<vOffset>100</vOffset>
<alignment>center</alignment>
<onMouseUp>
sun1.opacity = (sun1.opacity / 100) * 90;
</onMouseUp>
</text>
</widget>Now let's dig into details
Defining object
start with {}
{
// this is comment
"key": "value", // keys are in double quotes
"key2": "value 2" // to sperate keys use comma
}Data types
{
"hero": "Meliodas", // string
"powerLevel": 60000, // number
"alive": true, // boolean
"mission": null // null value
}Objects
{
"type": "articles",
"id": "1",
"attributes": {
"title": "JSON:API paints my bikeshed!",
"body": "The shortest article. Ever.",
"created": "2015-05-22T14:56:29.000Z",
"updated": "2015-05-22T14:56:28.000Z"
}
}Array
{
"team": "Avengers",
"heroes": [
"Ironman",
"Captain America",
"Thor",
"Hulk"
]
}And mixing it together
{
"teams": [
{
"name": "Seven Deadly Sins",
"heroes": [
{
"name": "Meliodas",
"powerLevel": 60000,
"race": "Demon"
},
{
"name": "Elizabeth",
"powerLevel": 60000,
"race": "Goddess"
},
{
"name": "Bane",
"powerLevel": 30000,
"race": "Human"
}
]
}
]
}JSON Schema
It’s often necessary for applications to validate JSON objects, to ensure that required properties are present and that additional constraints (such as a price never being less than one dollar) are met. Validation is typically performed in the context of JSON Schema.
- JSON Schema is expressed a schema, which itself is a JSON object.
- JSON Schema is maintained at http://json-schema.org.
- It describes your existing data format.
- If offers clear, human-readable, and machine-readable documentation.
- It provides complete structural validation, which is useful for automated testing and validating client-submitted data.
I want to validate some object:
{
"name": "John Doe",
"age": 35
}{
"$schema": "http://json-schema.org/draft-04/schema#",
"title": "Person",
"description": "A person",
"type": "object",
"properties":
{
"name":
{
"description": "A person's name",
"type": "string"
},
"age":
{
"description": "A person's age",
"type": "number",
"minimum": 18,
"maximum": 64
}
},
"required": ["name", "age"]
}To do this I can define schema
That's it for JSON
Before we start with APIs some HTTP stuff
HTTP


Browser
Webserver
HTTP
HTTP
GET / HTTP/1.1
Host: www.example.comMethod
Location
Protocol version
Host name
HTTP
some example requests:
GET styles.css HTTP/1.1
GET /api/tasks HTTP/1.1
GET /page.html HTTP/1.1
HTTP Response
HTTP/1.1 200 OK
Date: Mon, 23 May 2005 22:38:34 GMT
Content-Type: text/html; charset=UTF-8
Content-Length: 138
Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
ETag: "3f80f-1b6-3e1cb03b"
Accept-Ranges: bytes
Connection: close
<html>
<head>
<title>An Example Page</title>
</head>
<body>
<p>Hello World, this is a very simple HTML document.</p>
</body>
</html>HTTP Verbs
GET
HEAD
OPTION
PUT
DELETE
POST
}
Idepotent verbs
non-idepotent
{
safe
HTTP Status Codes
Successful
It indicates that the REST API successfully carried out whatever action the client requested and that no more specific code in the 2xx series is appropriate.
Unlike the 204 status code, a 200 response should include a response body. The information returned with the response is dependent on the method used in the request, for example:
-
GET an entity corresponding to the requested resource is sent in the response;
-
HEAD the entity-header fields corresponding to the requested resource are sent in the response without any message-body;
-
POST an entity describing or containing the result of the action;
-
TRACE an entity containing the request message as received by the end server.
A REST API responds with the 201 status code whenever a resource is created inside a collection. There may also be times when a new resource is created as a result of some controller action, in which case 201 would also be an appropriate response.
The newly created resource can be referenced by the URI(s) returned in the entity of the response, with the most specific URI for the resource given by a Location header field.
The origin server MUST create the resource before returning the 201 status code. If the action cannot be carried out immediately, the server SHOULD respond with a 202 (Accepted) response instead.
201 (Created)
A 202 response is typically used for actions that take a long while to process. It indicates that the request has been accepted for processing, but the processing has not been completed. The request might or might not be eventually acted upon, or even maybe disallowed when processing occurs.
Its purpose is to allow a server to accept a request for some other process (perhaps a batch-oriented process that is only run once per day) without requiring that the user agent’s connection to the server persist until the process is completed.
The entity returned with this response SHOULD include an indication of the request’s current status and either a pointer to a status monitor (job queue location) or some estimate of when the user can expect the request to be fulfilled.
202 (Accepted)
204 (No Content)
The 204 status code is usually sent out in response to a PUT, POST, or DELETE request when the REST API declines to send back any status message or representation in the response message’s body.
An API may also send 204 in conjunction with a GET request to indicate that the requested resource exists, but has no state representation to include in the body.
The 204 response MUST NOT include a message-body and thus is always terminated by the first empty line after the header fields.
Redirects (3xx)
HTTP Status Codes
The 301 status code indicates that the REST API’s resource model has been significantly redesigned, and a new permanent URI has been assigned to the client’s requested resource. The REST API should specify the new URI in the response’s Location header, and all future requests should be directed to the given URI.
You will hardly use this response code in your API as you can always use the API versioning for new API while retaining the old one.
301 (Moved Permanently)
Client Errors (4xx)
HTTP Status Codes
400 is the generic client-side error status, used when no other 4xx error code is appropriate. Errors can be like malformed request syntax, invalid request message parameters, or deceptive request routing etc.
The client SHOULD NOT repeat the request without modifications.
400 (Bad Request)
A 401 error response indicates that the client tried to operate on a protected resource without providing the proper authorization. It may have provided the wrong credentials or none at all. The response must include a WWW-Authenticate header field containing a challenge applicable to the requested resource.
The client MAY repeat the request with a suitable Authorization header field. If the request already included Authorization credentials, then the 401 response indicates that authorization has been refused for those credentials. If the 401 response contains the same challenge as the prior response, and the user agent has already attempted authentication at least once, then the user SHOULD be presented the entity that was given in the response, since that entity might include relevant diagnostic information.
401 (Unauthorized)
A 403 error response indicates that the client’s request is formed correctly, but the REST API refuses to honor it, i.e. the user does not have the necessary permissions for the resource. A 403 response is not a case of insufficient client credentials; that would be 401 (“Unauthorized”).
Authentication will not help, and the request SHOULD NOT be repeated. Unlike a 401 Unauthorized response, authenticating will make no difference.
403 (Forbidden)
The 404 error status code indicates that the REST API can’t map the client’s URI to a resource but may be available in the future. Subsequent requests by the client are permissible.
No indication is given of whether the condition is temporary or permanent. The 410 (Gone) status code SHOULD be used if the server knows, through some internally configurable mechanism, that an old resource is permanently unavailable and has no forwarding address. This status code is commonly used when the server does not wish to reveal exactly why the request has been refused, or when no other response is applicable.
404 (Not Found)
Server Errors (5xx)
HTTP Status Codes
500 is the generic REST API error response. Most web frameworks automatically respond with this response status code whenever they execute some request handler code that raises an exception.
A 500 error is never the client’s fault, and therefore, it is reasonable for the client to retry the same request that triggered this response and hope to get a different response.
API response is the generic error message, given when an unexpected condition was encountered and no more specific message is suitable.
500 (Internal Server Error)
Some details
Resources are often compress
GET /employees HTTP/1.1
Host: www.domain.com
Accept: text/html
Accept-Encoding: gzip,compress200 OK
Content-Type: text/html
Content-Encoding: gzipFrom 2015 you can use Brotli
GET /employees HTTP/1.1
Host: www.domain.com
Accept: text/html
Accept-Encoding: br,compress200 OK
Content-Type: text/html
Content-Encoding: br- Javascript files compressed with Brotli are 14% smaller than gzip.
- HTML files are 21% smaller than gzip.
- CSS files are 17% smaller than gzip.
CORS (Cross Origin Request Sharing)
GET /resources/public-data/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Connection: keep-alive
Origin: https://foo.exampleThis thing will cause you a lot of pain.
It prevents some attack on website but you have to enable on server that none origin requests can access your resources.
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 00:23:53 GMT
Server: Apache/2
Access-Control-Allow-Origin: *
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Transfer-Encoding: chunked
Content-Type: application/xml
[…XML Data…]Preflight Request

That's it for HTTP
Now finally get to REST
REST
Representational state transfer (REST) is a software architectural style that defines a set of constraints to be used for creating Web services.
Web services that conform to the REST architectural style, called RESTful Web services, provide interoperability between computer systems on the Internet.
RESTful Web services allow the requesting systems to access and manipulate textual representations of Web resources by using a uniform and predefined set of stateless operations
How to do REST API
/devices
/devices/{id}
/configurations
/configurations/{id}
/devices/{id}/configurations
/devices/{id}/configurations/{id}
We create endpoints on our server returning JSON or XML:
Richardson Maturity Model
A model (developed by Leonard Richardson) that breaks down the principal elements of a REST approach into three steps. These introduce resources, http verbs, and hypermedia controls.
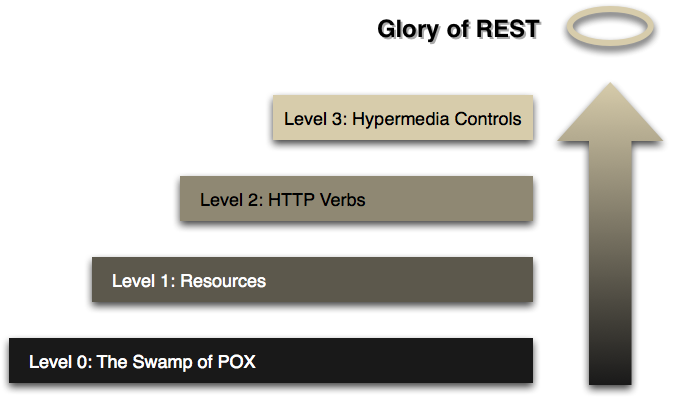
Think nouns, not verbs.
The main difference between REST-styled APIs and RPC/SOAP-styled APIs is the difference between nouns and verbs. RESTful APIs are based on nouns — you’re performing actions on endpoints that are things. RPC/SOAP endpoints, on the other hand, are verbs — they’re things that are meant to do something. Consider this example:
GET /employees
GET /employees/123
POST /employeesGET /getAllEmployees
GET /getEmployeeWithId
POST /createEmployeeIdempotent REST API
the context of REST APIs, when making multiple identical requests has the same effect as making a single request – then that REST API is called idempotent.
When you design REST APIs, you must realize that API consumers can make mistakes. They can write client code in such a way that there can be duplicate requests as well. These duplicate requests may be unintentional as well as intentional some time (e.g. due to timeout or network issues). You have to design fault-tolerant APIs in such a way that duplicate requests do not leave the system unstable.
-
POST is NOT idempotent.
-
GET, PUT, DELETE, HEAD, OPTIONS and TRACE are idempotent.
HTTP GET, HEAD, OPTIONS and TRACE
GET, HEAD, OPTIONS and TRACE methods NEVER change the resource state on server. They are purely for retrieving the resource representation or meta data at that point of time. So invoking multiple requests will not have any write operation on server, so GET, HEAD, OPTIONS and TRACE are idempotent.
GET /orders
HTTP PUT
Generally – not necessarily – PUT APIs are used to update the resource state. If you invoke a PUT API N times, the very first request will update the resource; then rest N-1 requests will just overwrite the same resource state again and again – effectively not changing anything. Hence, PUT is idempotent.
PUT /orders/1
HTTP DELETE
When you invoke N similar DELETE requests, first request will delete the resource and response will be 200 (OK) or 204 (No Content). Other N-1 requests will return 404 (Not Found). Clearly, the response is different from first request, but there is no change of state for any resource on server side because original resource is already deleted. So, DELETE is idempotent.
DELETE /orders/1
REST without PUT and CQRS
HTTP verb PUT can be used for idempotent resource updates (or resource creations in some cases) by the API consumer. However, use of PUT for complex state transitions can lead to synchronous cruddy CRUD. It also usually throws away a lot of information that was available at the time the update was triggered - what was the real business domain event that triggered this update? With “REST without PUT” technique, the idea is that consumers are forced to post new 'nounified' request resources.
REST without PUT and CQRS
Changing a customer’s mailing address is a POST to a new “ChangeOfAddress” resource, not a PUT of a “Customer” resource with a different mailing address field value. The last bit means that we can reduce our API consumers’ expectations of atomic consistency - if we POST a “ChangeOfAddress”, then GET the referenced Customer, it's clearer that the update may not have been processed yet and the old state may be still there (asynchronous API). GETing the “ChangeOfAddress” resource that was created with “201” response will return details related to the event, and a link to the resources that were updated or that will be updated.
BFF - Backend for frontend
Some developers think that API should be as simple as possible. This leads to many requests on the server and slow applications.
The current trend is to create complex APIs that the application can use right away.
This trend is called BFF.
To summaryse
GET /products returns product
POST /products creates new product
PUT /products/1 updates product
DELETE /products/1 deletes product
or
POST /productDescriptionUpdate updates product
Any questions?
That's it for today.
PB138 JSON and REST APIS
By Lukáš Grolig



