Metody komputerowej analizy stylometrycznej tekstów w języku polskim
prowadzący: dr inż. Tomasz Walkowiak
Maciej Baj
spis treści
1. Schemat systemu
2. GUI
3. Model rekordu
4. Proces uczenia
5. Proces klasyfikacji
6. Szczegóły klasyfikacji
7. Wynik klasyfikacji
8. Demonstracja
9. Badania
10. Plany
schemat systemu
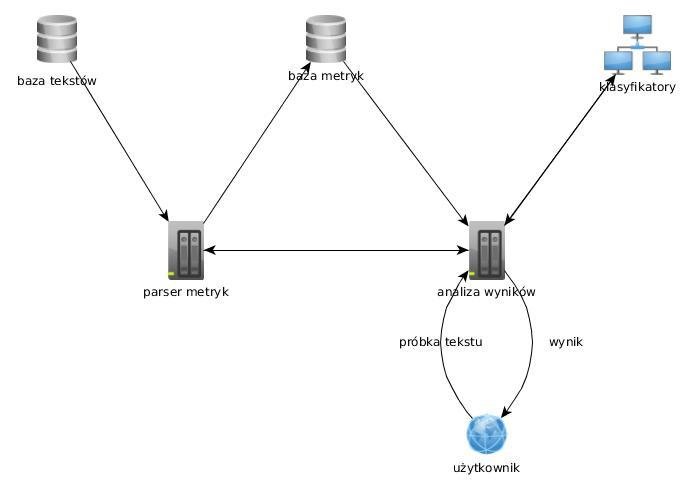
Działanie systemu
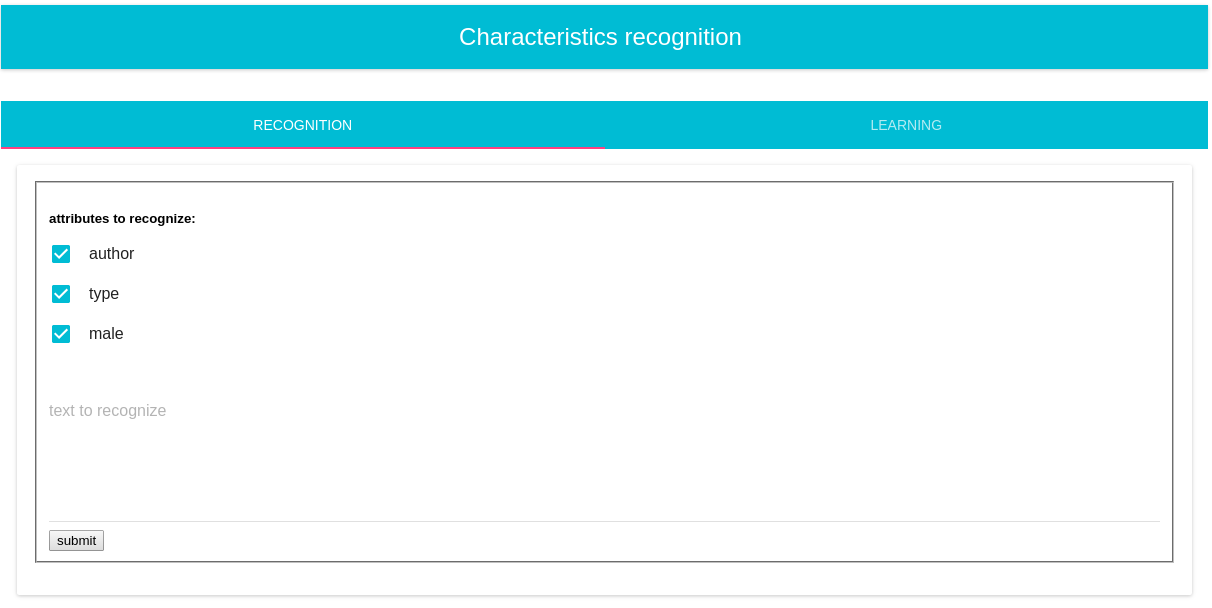
GUI- klasyfikacja
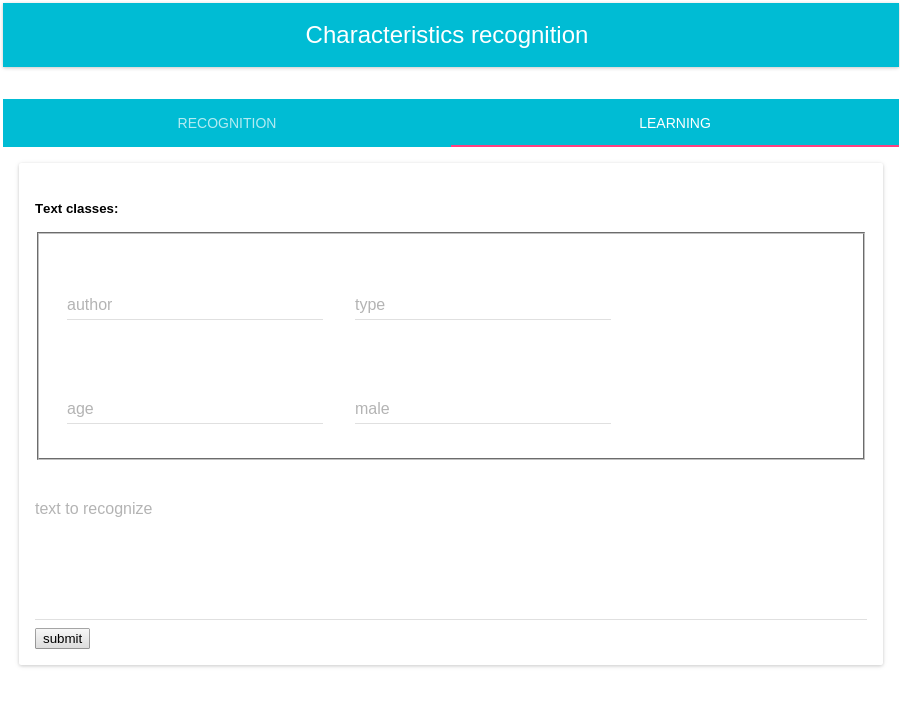
GUI- uczenie
Model rekordu
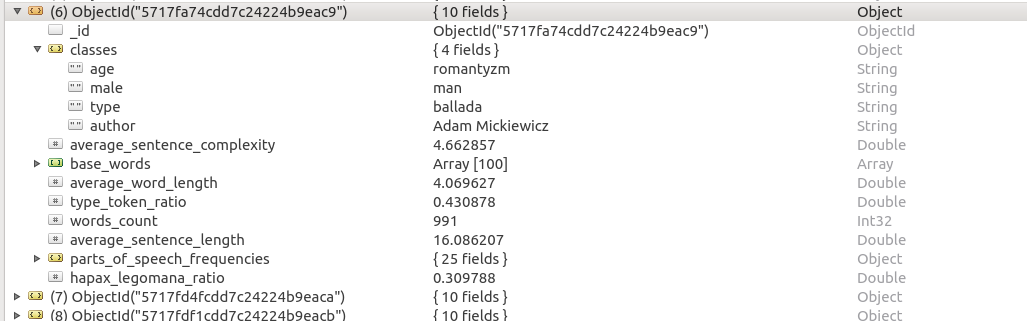
Model rekordu
classes: dictionary
average_sentence_complexity: double
base_words: Array<dictionary>
average_word_length: double
type_token_ratio: double
words_count: integer
average_sentence_length: double
parts_of_speech_frequencies: dictionary
hapax_legomana_ratio: double
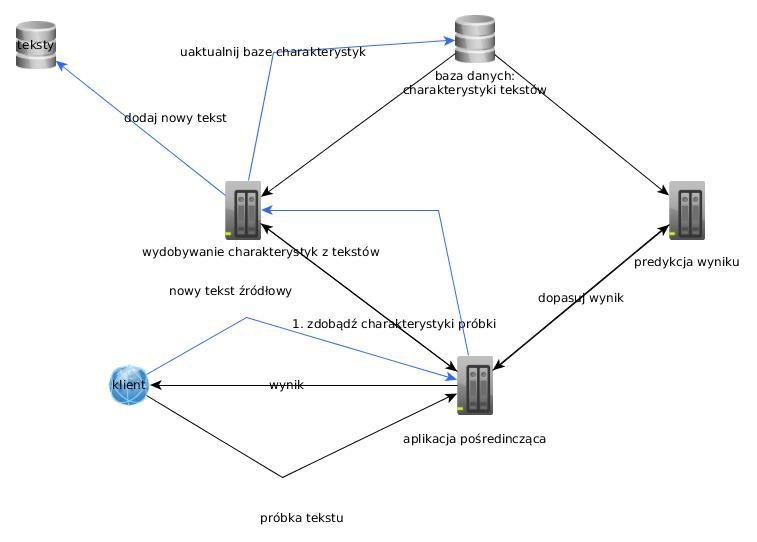
Proces uczenia
komunikacja z NLP REST API
1. Przesłanie tekstu do systemu
2. Rozpoczęcie procesu WCRFT na wskazanym pliku
3. Cykliczne sprawdzanie statusu zadania
4. Pobranie wyniku w formacie XML
5. Na podstawie tematów wyrazów:
- obliczenie cech numerycznych
- najczęstszych słów
- częstotliwości części mowy
6. Zapis rekordu do bazy danych (wraz z klasami)
Proces klasyfikacji
kroki 1-5: bez zmian
6. Dla każdej zadanej klasy:
- pobierz wszystkie rekordy zawierające daną klasę
- stwórz zbiór uczący oraz zbiór możliwych wyników
- dokonaj klasyfikacji
Szczegóły klasyfikacji
Trójetapowa klasyfikacja
- charakterystyki numeryczne
- częstości występowań części mowy
- ilość wspólnych słów porównywanych zbiorów
Charakterystyki numeryczne
def select_numerical_characteristics(input):
return [
input["average_sentence_length"],
input["average_sentence_complexity"],
input["average_word_length"],
input["type_token_ratio"],
input["hapax_legomana_ratio"]
]Części mowy
"parts_of_speech_frequencies" : {
"adv" : 0.0194174757281553,
"praet" : 0.0776699029126214,
"imps" : 0.0291262135922330,
"pred" : 0.0097087378640777,
"interp" : 0.1067961165048544,
"subst" : 0.3398058252427185,
"qub" : 0.0388349514563107,
"comp" : 0.0291262135922330,
"conj" : 0.0873786407766990,
"adj" : 0.1359223300970874,
"prep" : 0.0970873786407767,
"fin" : 0.0291262135922330
},def pick_parts_of_speech_common_for_all(authors_parts_of_speech_frequencies, example_frequencies):
parts_common_for_all = map(lambda x: x.keys(), authors_parts_of_speech_frequencies)
parts_common_for_all.append(example_frequencies.keys())
return set.intersection(*map(set, parts_common_for_all))tylko część wspólna dla wszystkich rekordów zawierających daną klasę
Najczęstsze słowa
"base_words" : [
{
"i" : 7
},
{
"w" : 4
},
{
"na" : 3
},
{
"się" : 3
},
{
"rok" : 2
},
{
"co" : 2
},
{
"być" : 2
}
....Wynik
[{
"age": {
"numerical_classification": "mloda polska",
"top_common_words": "mloda polska",
"parts_of_speech_frequencies_classification": "barok"
}
}, {
"male": {
"numerical_classification": "man",
"top_common_words": "man",
"parts_of_speech_frequencies_classification": "man"
}
}, {
"type": {
"numerical_classification": "sonet",
"top_common_words": "hymn",
"parts_of_speech_frequencies_classification": "sonet"
}
}, {
"author": {
"numerical_classification": "Adam Mickiewicz",
"top_common_words": "Jan Kasprowicz",
"parts_of_speech_frequencies_classification": "Adam Mickiewicz"
}
}]Demonstracja


Badania
skuteczność klasyfikacji w zależności od:
- użytego klasyfikatora
- długości próbki
- skuteczności odgadywania różnych klas
- szczegółowe badanie charakterystyk numerycznych
Plany
konstrukcja systemu
- wprowadzanie dowolnych klas
- implementacja klasyfikacji wykorzystującej częstości występowania słów
- implementacja klasyfikacja w oparciu o najrzadziej występujące słowa
- obróbka tekstu wejściowego
- analiza plików
- zamiana NLP API na coś własnego?
- poprawki w GUI
- udostępnienie systemu do powszechnego użytku
koniec kwietnia
Plany
praca magisterska
- opis systemu
- konstrukcja zbioru uczącego
- przeprowadzenie badań
- opis wyników
maj
- poprawianie pracy magisterskiej
czerwiec
bibliografia
WCRFT- http://nlp.pwr.wroc.pl/redmine/projects/wcrft/wiki
Dziękuję
metody komputerowej analizy stylometrycznej tekstów w języku polskim- podsumowanie
By Maciej Baj



