Tokenizacja i segmentacja
Czym jest tokenizacja?
Tokenizacja jest procesem w wyniku którego z podanego ciągu tekstowego (zdania/zdań) powstają podzielone kawałki tego tekstu. Te kawałki tekstu nazywają się: tokeny. Program, który wykonuje tokenizacje nazywamy tokenizatorem.
Tokeny mogą być dzielone w tekście m.in.:
- białymi znakami (np.: spacja)
- znakami interpunkcyjnymi
- tagami (znacznikami)
Przykład tokenizacji
Ei mutat utamur explicari quo. Duo at quem scripta, pertinax indoctum mel an, est ne duis populo appareat
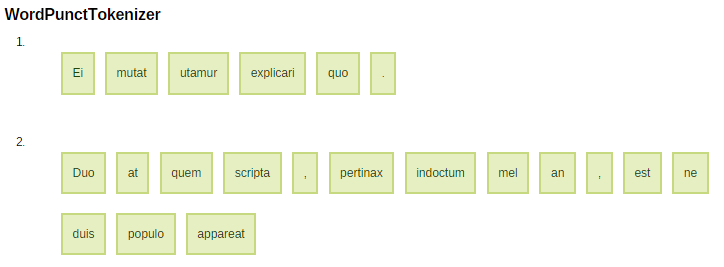
Sentencja
Tokenizacja
Przykład tokenizacji
Ei mutat utamur explicari quo. Duo at quem scripta, pertinax indoctum mel an, est ne duis populo appareat
Sentencja
Tokenizacja

Problemy tokenizacji
Protokoły, adresy URL
Problemem dla wielu tokenizatorów jest rozpoznawanie adresów URL różnych protokołów, niektóre potrafią wydzielić adres. Problemem jednak jest jednak rozpoznanie adresu w protokole.
Patterns

Tokenizer
https://www.wmi.amu.edu.pl/pl/kontakt
ftp://www.wmi.amu.edu.pl/
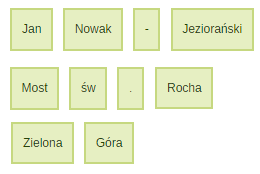
Nazwy własne
Tokenizatory mają też problemy z nazwami własnymi, są to m.in.: nazwiska, nazwy obiektów czy też nazwy geograficzne. Rozwiązaniem jest wprowadzenie bazy wiedz nazw własnych w konkretny językum (większość dostępnych jest po angielsku).
Patterns
Tokenizer
Jan Nowak-Jeziorański
Most św. Rocha
Zielona Góra
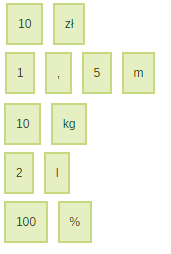
Miary
Kolejnym źródłem kłopotów stają się miary takie jak: waluty, jednostki wagi, odległośći pojemności, procenty itp. Unikatowe jednostki miar ("m", "kg", "l") powinny być z zasady rozpoznawane wszędzie, jednak tak nie jest. Poza tym problemem staje się też liczba rzeczywista, a znak "%", który piszę się bez spacji, jest także dzielony przez tokenizer.
Patterns
Tokenizer
10 zł
1,5 m
10 kg
2 l
100%
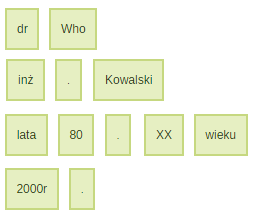
Przedrostki, spacje i końcówki
Tytuły, stopnie zawodowe czy też naukowe, a także różne inne skróty, chociażby znak "." używanych w datach; potrafią być kłopotliwe. Najwięcej problemów budzi jednak znak spacji, który czasami powinien być splitem, a czasami nie.
Patterns
Tokenizer
dr Who
inż. Kowalski
lata 80. XX wieku
2000r.
Przykłady wyrażeń regularnych
Rozpoznawanie znacznika
/<p\b[^>]*>(.*?)<\/p>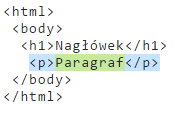
Wzorzec na przykładzie znacznika <p> języka HTML
Przykład użycia
/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$Wzorzec dowolnego znacznika HTML
Rozpoznawanie maila
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/Wzorzec
Przykłady użycia



Rozpoznawanie adresu strony
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/Wzorzec
Przykłady użycia


Rozpoznawanie polskiego kodu pocztowego
/^[0-9]{2}-[0-9]{3}$Wzorzec
Przykłady użycia

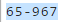
Przykłady tokenizatorów online
Zdania testowe
The Laws of the Game were originally codified in England by The Football Association in 1863. Association football is governed internationally by the International Federation of Association Football (FIFA; French: Fédération Internationale de Football Association), which organises World Cups for both men and women every four years.
Tokenizator nr 1
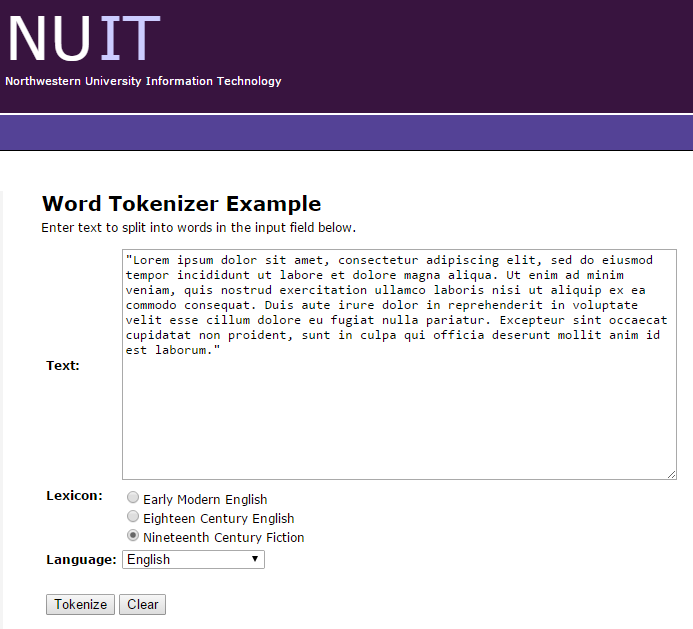
http://morphadorner.northwestern.edu/wordtokenizer/example/
1
Tokenizer ten jest wart uwagi ze względu na to iż rozpoznaje język, co przekłada się na lepszy podział tekstu w danym języku. Ponadto w swoich podziałach wyznacza wyrazy oraz dzielące je punktory.
Tokenizator nr 1 - test
53 words in 2 sentences found.
S#W#TokenType
| 1 | 1 | The | token |
| 1 | 2 | Laws | token |
| 1 | 3 | of | token |
| 1 | 4 | the | token |
| 1 | 5 | Game | token |
| 1 | 6 | were | token |
| 1 | 7 | originally | token |
| 1 | 8 | codified | token |
| 1 | 9 | in | token |
| 1 | 10 | England | token |
| 1 | 11 | by | token |
| 1 | 12 | The | token |
| 1 | 13 | Football | token |
| 1 | 14 | Association | token |
| 1 | 15 | in | token |
| 1 | 16 | 1863. | number |
| 2 | 1 | Association | token |
| 2 | 2 | football | token |
| 2 | 3 | is | token |
| 2 | 4 | governed | token |
| 2 | 5 | internationally | token |
| 2 | 6 | by | token |
| 2 | 7 | the | token |
| 2 | 8 | International | token |
| 2 | 9 | Federation | token |
| 2 | 10 | of | token |
| 2 | 11 | Association | token |
| 2 | 12 | Football | token |
| 2 | 13 | ( | punctuation |
| 2 | 14 | FIFA | token |
| 2 | 15 | ; | punctuation |
| 2 | 16 | French | token |
| 2 | 17 | : | punctuation |
| 2 | 18 | Fédération | token |
| 2 | 19 | Internationale | token |
| 2 | 20 | de | token |
| 2 | 21 | Football | token |
| 2 | 22 | Association | token |
| 2 | 23 | ) | punctuation |
| 2 | 24 | , | punctuation |
| 2 | 25 | which | token |
| 2 | 26 | organises | token |
| 2 | 27 | World | token |
| 2 | 28 | Cups | token |
| 2 | 29 | for | token |
| 2 | 30 | both | token |
| 2 | 31 | men | token |
| 2 | 32 | and | token |
| 2 | 33 | women | token |
| 2 | 34 | every | token |
| 2 | 35 | four | token |
| 2 | 36 | years | token |
| 2 | 37 | . | punctuation |
Tokenizator nr 2
http://text-processing.com/demo/tokenize/
2
Tokenizator wyświetla wynik podziału sentencji wg różnych kryteriów, są to:
- TreebankWordTokenizer
- WordPunctTokenizer
- PunctWordTokenizer
- WhitespaceTokenizer
"Pod maską" ma silnik NLTK dla Pythona.
Tokenizator nr 2 - test
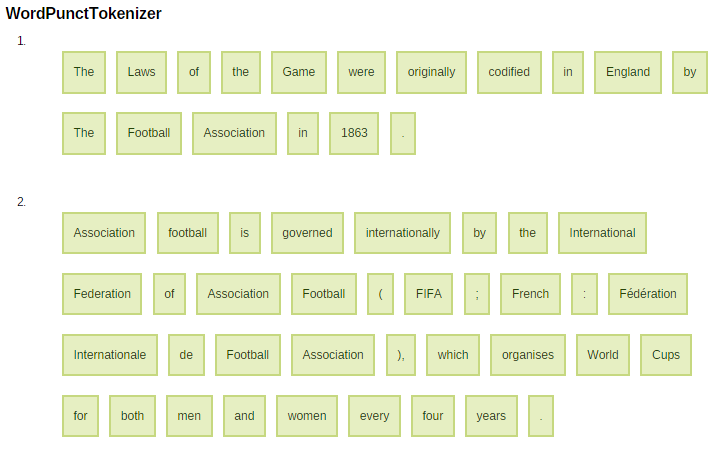
Co to jest segmentacja?
Segmentacja jak nazwa wskazuje, to segmentowanie czegoś. Mówiąć ściślej jest wstępnym procesem dla tokenizacji, to dzielenie tekstu na fragmenty - zdania. Bardzo ważnym problemem segmentacji jest zbadanie czy kropka kończy zdanie.
Segmentation Rules eXchange
Język oparty o XML, któy ma za zadanie tworzyć zasady segmentacji
SRX - Elementy
reguły dla zbioru języków
<languagerules>
<languagerule>
<rule>
<maprules>
reguły dla konkretnego języka
pojedyncza reguła
mapa reguł wiążąca reguły z językiem
SRX - Przykład
Reguła, która zapobiega łamaniu zdania po kropce poprzedzonej regexem (jak w kodzie)
<languagerules>
<languagerule languagerulename="default">
<rule break="no">
<beforebreak>([A-Z]\.){2,}</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
<rule break="yes">
<beforebreak>\.</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
</languagerule>
</languagerules>Zdanie testowe
I'm in the U.K. for now. But I plan to move to Papua New Guinea.
Po segmentacji
[I'm in the U.K. for now.]
[ But I plan to move to Papua New Guinea.]
[I'm in the U.K.]
[ for now.]
[ But I plan to move to Papua New Guinea.]
Bez pierwszej reguły
Wnioski
- język naturalny ma wpływ na tokenizacje
- wyrażenia regularne są bardzo pomocne w tokenizacji
- proces tokenizacji powinien być oparty na zbiorze zasad, które zawierają konkretne zachowania dla danego języka naturalnego lub też są zachowaniami ogólnymi dla rodziny języków
- segmentacja to początkowy faza wykonywana przed procesem tokenizacji
- tokenizacja musi się zmierzyć z wieloma problemami, które nie są oczywiste i jednoznaczne
Tokenizacja i segmentacja
By madjer22



