Regex - Wyrażenia regularne
Definicja regex
Wyrażeniem regularnym nad alfabetem E nazywamy:
- pusty string
- dowolny znak
W ogólnym przypadku dla pustego słowa i dowolnego znaku ich konktatenacje, alternatywe oraz domnknięcie Kleenego nad alfabetem E
Mówiąc prościej - regex to język opisujący wzór do znajdywania i zamieniania ciągów znaków w tekście
Podstawowa zasada kolejności elementów
Regex patrzy na kolejność znaków w ciągu, zatem przy wyszukiwaniu ciągu:
dok
dok
ma drzwi na
kod
Dopasowany zostanie tylko ciąg "dok", a nie "kod", który zawiera te same znaki w tej samej ilości, ale w innej kolejności
Podstawowe operatory regex
Z definicji regexa, możemy wyczytać, że dowolna kombinacja pustego znaku oraz dowolnego innego znaku, jest regexem. Poprzez dowolną kombinacje rozumiemy:
- Domknięcie Kleenego
- Alternatywa
- Konkatenacja
a* = {,a,aa,aaa,aaaa,...} # 0 lub więcej powtórzeń znakua|b = {a, b} # a lub bab = {ab} # połączenie znaku 'a' oraz 'b' w ciąg 'ab'Priorytety
Priorytetem w regexie jest konktatenacja, wiąże ona silniej niż alternatywa czy operator * lub + (1 lub więcej)
# jak widac, zwielokratniany jest tylko pierwszy znak po lewej stronie operatora *
abc* = {ab, abc, abcc, abccc, ...}
# stosujac nawiasy () uzyskujemy efekt grupowania ciągu, który to teraz może być powtórzony
(abc)* = {ε, abc, abcabc, abcabcabc, ...}
# kokatenacja jest silniejsza od alternatywy
Asia|Basia|Kasia = (Asia)|(Basia)|(Kasia) = (A|Ba|Ka)sia = {Asia, Basia, Kasia} Ponadto regex stara się dopasować NAJDŁUŻSZY możliwy ciąg. Aby dopasować NAJKRÓTSZY należy użyć 'lazy quantifiers'
Klasy znaków
Pozwalają na grupowanie znaków i wybór jednego z nich. Klasy znaków można łączyć z różnymi operatorami
# dopasuj jeden ze znaków A, B, K, który jest skonkatenowany z 'sia'
[ABK]sia = {Asia, Basia, Kasia}
# dowolne mała lub duża litera
[A-Za-z]
#dowolna cyfra
[0-9]
#albo kropka albo ! albo ?
[?!.]
#negacja - dopasuje każdy znak za wyjątkiem liter
[^A-Za-z] #Twoj PESEL to: 99112233112 - dopasuje pierwszą cyfre czyli: 9
#dowolny ciąg znaków składający się tylko z małych liter
[a-z]+Kotwica, space boundary, kropka
Kotwica - Określa początek ^ lub koniec stringa $
#zaczyna się albo od 'foo' albo kończy się na 'bar'. UWAGA nie jest równoznaczne z: ^(foo|bar)$
^foo|bar$ = (^foo)|(bar$)
#albo kończy się na lis albo kończy się na król albo jest to dokładnie "ptak"
lis$|ptak|^król = (lis$)|ptak|(^król)
#Operator kropki - oznacza dowolny znak za wyjątkiem nowej lini
#(dopasuje np: 'matma' jak i też 'matka')
mat.a
#Gdy chcemy użyć jako znaku konkretnie kropki należy użyć \ - unieważnienie znaku specjalnego
#(dopasuje 'koniec.' ale nie 'koniec')
koniec.
#operator space boundary \b - gwarantuje znalezienie konkretnego wyrazu, a nie podciągu w innym wyrazie
#w zdaniu "Tomek to lubi" znajdzie wystąpienie "to"
#w zdaniu "Tomek kupił toner" nie znajdzie wystąpienia "to" gdyż jest ono tylko podciągiem słowa "toner"
\bto\b
#operator space boundary \B - wymusza znalezienie podciągu nie będącego samodzielnym wyrazem
#w zdaniu "Tomek to lubi" nie znajdzie znajdzie wystąpienie "to" gdyż jest ono tylko samodzielne
#w zdaniu "Tomek kupił toner" znajdzie wystąpienia "to" gdyż jest ono podciągiem słowa "toner"
\Bto\B
Ilość powtórzeń
Można zdefiniować konkretną ilość powtórzeń lub jej przedział
#zamiast używać operatora * można użyć {n,m}
aaa # dokładnie 3 razy 'a'
aaaa* # co najmniej 3 razy 'a'
a{3} # dokładnie 3 razy 'a'
a{3,} # co najmniej 3 razy 'a'
a{3,5} # co najmniej 3, maksymalnie 5 razy 'a'
[a-z]{3}# co najmniej 3 razy dowolna mała literaMatch vs search
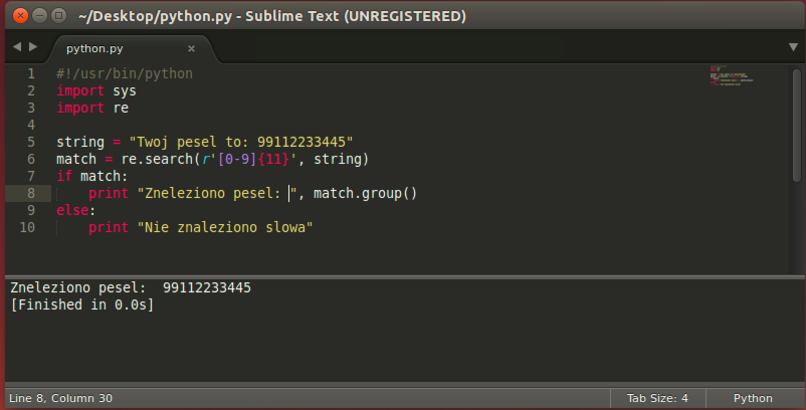
Match dopasuje tylko gdy wzór będzie na początku stringa, search w dowolnym miejscu stringa. W poniższym przykładzie funkcja search znazła PESEL, natomiast to samo wywołanie funkcji match zwrociłoby: Nie znaleziono słowa
Group vs groups
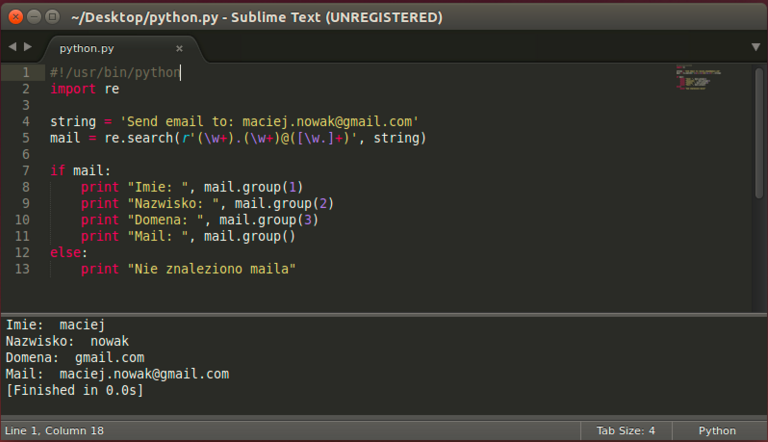
Różnica między group a groups polega na tym, że groups zwróci wynik w postaci krotki. Dodatkowo group można wywołać z numerem dopasowania group(i), a groups nie, tylko groups()
Unicode
Regex pozwala na stosowanie Unicode, tzn. znaku z konkretnego zbioru czy to znaki matematyczne czy znaki z języka arabskiego lub też greckiego i oznacza się je tak:
- \p{Math_Symbol} - dopuszczalne symbole matematyczne
- \p{L} dowolna litera z dowolnego języka
- \p{Greek} - litery z języka greckiego
- \p{Arabic} - litery z języka arabskiego
Przykłady Regex z życia
#PESEL:
[09]{11}
#NIP: [09]{3}[09]{3}[09]{2}[09]{2} = ([09]{3}){2}[09]{2}[09]{2}
#TABLICE REJESTRACYJNE:
[AZ]{2}([AZ]|[09])[09]{4} = [AZ]{2}[AZ09][09]{4}
#CZAS 14:40.37:
([01][09]|2[03]):[05][09]\. [05][09]|23:59 \. 60
#DATA 21-10-2015:
([19]|[12][09]|3[01])([19]|1[02])[12][09]{3}
#LICZBY SZESNASTKOWE:
[AFaf19][AFaf09]*|0Wyrażenia regularne
By madjer22



