正規表現の
先読みとか後読み
について
さっき作った (@MakeNowJust)
自己紹介
- さっき作った (make now just)
- Twitter: @make_now_just
GitHub: @MakeNowJust - 21歳
- 日本大学文理学部
ドイツ文学科 - プログラミング言語、
形式言語、コンパイラなど - Quineを書くのが好き
- Crystalという
プログラミング言語に
コントリビュートしている
Crystalへのコントリビュート
MakeNowJust/quine
正規表現
とは?
正規表現とは
- 文字列にマッチするパターン
- 英語で書くとregular expression
(regexpとかregexと略されることが多い) - 多くのプログラミング言語で実装されている
- JavaScript, Ruby, Python‥‥
- POSIXにはregex.hが定義されている
どんなところで使われてる?
- テキストエディタの高度な検索
- Webアプリの入力のバリデーション
- ゲノム解析
- パケットの分類
- マルウェアの検出
などなど‥‥
正規表現の
先読み・後読み
とは
正規表現の先読み・後読み
- 正規表現の演算子の一つ
- 先読み: `(?=foo)`、後読み: `(?<=foo)`
- 先読みの出てきた位置から、内容の正規表現に
マッチできたらマッチ - 後読みの場合は、出てきた位置でマッチできたらマッチ
- 文字列を消費しないのが特徴
- マッチできない場合にマッチする
否定先読み・後読みもある
/\b(?<=Pokemon | Surface )Go\b/
- 文字列中に含む「Pokemon」か「Surface」という
単語に続いた「Go」という単語にマッチする正規表現 - マッチの結果に「Pokemon」や「Surface」の部分は
含まれないことに注意
'Go Surface Go'
.match(/\b(?<=Pokemon | Surface )Go\b/)
// => [
// 'Go',
// index: 11,
// input: 'Go Surface Go',
// groups: undefined]/^(?!Java).*Script$/
- 「JavaScript」以外の「○○Script」という文字列に
マッチする - 否定の先読み・後読みを使うと、マッチしないことを
正規表現のパターンに組み込める。
'JavaScript'.search(/^(?!Java).*Script$/) >= 0
// => false
'CoffeeScript'.search(/^(?!Java).*Script$/) >= 0
// => true
'TypeScript'.search(/^(?!Java).*Script$/) >= 0
// => true正規表現の先読み・後読み
- そこそこ便利なのだが、実装されている処理系が少ない
- RubyやJavaなどの実装は不完全
- 後読みの中に任意の正規表現を含められない
- JavaScriptや.NETはちゃんと実装されている
- RubyやJavaなどの実装は不完全
- 実装されている処理系が少ないせいで
あまり使われていない‥‥
ReDoSと
正規表現の
先読み・後読み
ReDoSとは
- 正規表現エンジンの実装によっては、
特定の正規表現に特定の文字列をマッチさせると
処理が非常に重くなることがある - ↑を利用したDoS攻撃のこと
- 基本的な対策: 任意の正規表現を受け取ってサーバー側
で実行しない。 - しかし、これではサーバー側のプログラムにReDoSを
起こす可能性があるような正規表現があった場合に
防げない
→等価だが効率的な正規表現に書き直すことが必要
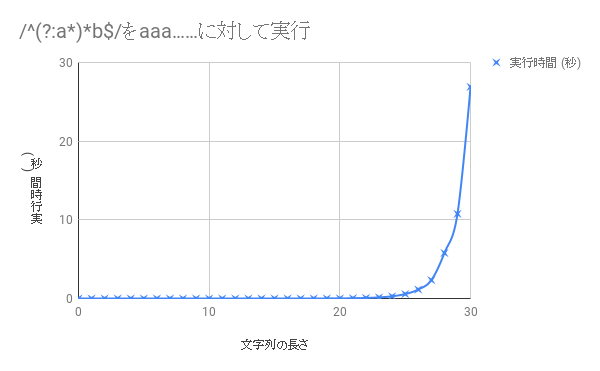
ReDoSを起こす正規表現の例
/^(?:a*)*b$/- このように、 `*` が二重になっているような場合は
ReDoSのおそれがある - この場合は、`a`が並んでいるだけの文字列に
マッチさせたときにO(2^N)に比例する時間がかかる
場合がある
(`N` は文字列の長さ)
後読みを使って改善する
- `*` が二重になっている部分を肯定後読みで囲む
- この例くらいなら `(?:a*)*` を `a*` に書き直せば
いいのでは? と思うかもしれないけど、
実際はもっと複雑でそんなに簡単には書き直せない、
という想定
/(?<=^(?:a*)*)b$/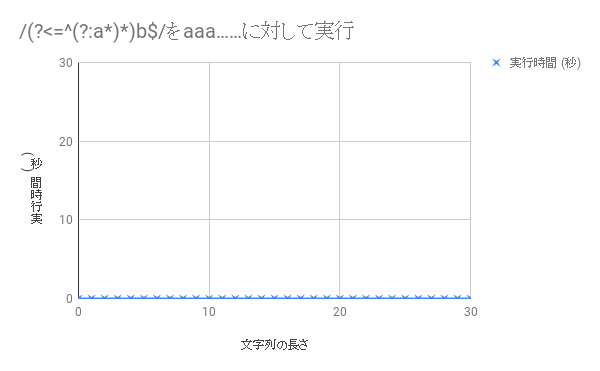
なぜこれで早くなるのか
- `/^(?:a*)*b$/` を aaa…… に対してマッチさせた場合、
正規表現の最後の `b` の部分でバックトラックが起きる - `/(?<=^(?:a*)*)b$/` の場合、
後読みのため `^(?:a*)*` が右から左に実行されるので
バックトラックが起きない。
とはいえ‥‥
- この方法が使えるのは結構限られる
- 例えば `/^b(?:a*)*b$/` のような正規表現の場合
単純に `/(?<=^b(?:a*)*)b$/` としてしまうと遅くなる
- でも、正規表現の後の方でバックトラックが起きて
いると予想できる場合は後読みを使って逆向きに実行
するようにすることでバックトラックの回数を減らせる
可能性がある、ということは覚えておくと便利かも - あと、先読みもマッチすることを確認したらバックトラックが起こらない性質を利用して、アトミック演算子の代わりに使えたりする
そもそも
- 現実問題として、`*` がネストするような正規表現
になっている場合は、正規表現が複雑で別の問題がある
可能性も高い - いくつかの正規表現に分割したり、
それをチェックする用のプログラムを普通に書いた方が
結果的に分かりやすくなって良いのでは?
おまけ:
活動報告
去年の活動
- サイボウズ・ラボ・ユースで
正規表現の後読みを有限状態オートマトンに変換する
研究をさせていただきました - サイボウズ・ラボ・ユースはお金が貰えて
研究が出来て最高!!
- あと世の中にCrystalを普及させるためCrystalの同人誌を
作ったりしていました
ご清聴
ありがとう
ございます
正規表現の先読みとか後読みについて
By Kitsune Tsuyusato

