Go言語の正規表現に
後読みを実装した話
さっき作った (@MakeNowJust)
自己紹介
- Twitter @make_now_just / GitHub @MakeNowJust
- 宇宙海賊合同会社のクルー
- プログラミング言語・形式言語などが好き
- Crystalというプログラミング言語に
コントリビュートするのが趣味
正規表現の後読みに
詳しい方!!!
ところで
6/28にES2018の仕様がリリースされましたね
🎉🎉🎉
ES2018で増えた正規表現関連の機能

https://medium.com/front-end-hacking/javascript-whats-new-in-ecmascript-2018-es2018-17ede97f36d5
RegExp
Lookbehind
Assertions
後読みとは?
正規表現の後読み
-
構文: (?<= ... ) - 直前で括弧の中の正規表現にマッチする場合にマッチ
- マッチしない場合にマッチする否定後読みもある
-
↑の構文: (?<! ... ) - 文字列を消費しない ≒ マッチに含まれない、ことが特徴
"Pokemon Go"、"Surface Go"の"Go"には
マッチするけれど、
"Golang"の"Go"の部分には
マッチしない。
/(?<=Pokemon |Surface )Go/
"example_test.go"のような
"_test.go"で終わる文字列には
マッチしないが、
"example.go"のような、
その他の".go"で終わる文字列には
マッチする。
/^.*(?<!_test)\.go$/
正規表現の/^/と同じで、
文字列の先頭にのみマッチする。
(直前で任意の文字にマッチしない位置は
先頭しかないので)
/(?<!.)/
ね、簡単でしょう?
後読みが実装されている
プログラミング言語
- Perl
- Ruby (鬼雲)
- PHP (PCRE)
- Java
- .NET
ただし、.NET以外は
後読みの中に書けるのは固定の文字列だけなど、
制約がある。
Go言語は‥?
実装したぜ
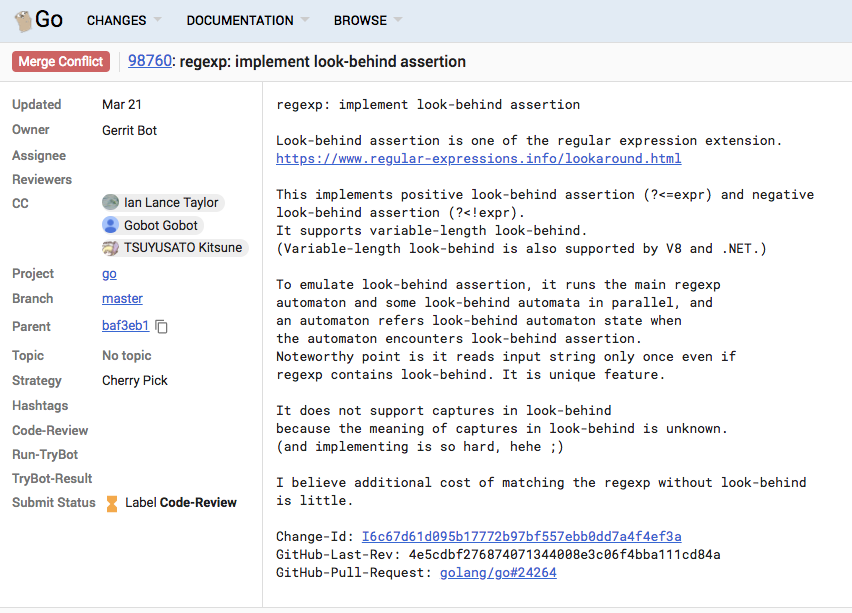
https://go-review.googlesource.com/c/go/+/98760
しかも‥
- (Go言語の正規表現エンジンの特徴である)
マッチ対象の文字列の長さに比例する時間で
マッチを確認できる。 - 後読みの中に任意の正規表現を書くことができる。
もちろん後読みをネストさせることもできる。
↓↓↓
このような特徴を持った正規表現エンジンは
(自分の知る限り)
世界でこれだけ!!!
Go言語の
正規表現の
実装
Go言語の正規表現
-
"regexp"パッケージ
- Russ Coxが実装した(はず)
- マッチ対象の文字列の長さに比例する時間で
マッチを確認できることが保証されている。
- 他の正規表現エンジンと比較すると
そんなに速くはない‥‥。
実装がある場所
golang/goのsrc/regexp/以下
https://github.com/golang/go/tree/master/src/regexp
正規表現の実装
正規表現をパース→ASTにする: regexp/syntax/parse.goASTをProgに変換する: regexp/syntax/compile.goProgを実行: regexp/exec.go正確にはProgの実行方法は三種類あり、 与えられた正規表現に応じて最適なものが使われる。 (上のものほど速いが使える適用できる正規表現が少ない。) regexp/onepass.go regexp/backtrack.go regexp/exec.go
Prog
-
コンパイル後の正規表現。
-
regexp/syntax/prog.go で定義。
-
Instという命令列、開始位置、キャプチャの数を 保持する構造体。
Instの種類
-
バイトコードは regexp/syntax/prog.go で定義。 -
InstAlt. InstAltMatch, InstCapture...など -
バイトコードは大きく2種類に分けられる。-
文字を消費するもの: InstRune, InstRuneAny...など -
消費しないもの: InstAlt, InstCapture...など
-
/yes|no/をコンパイルすると‥
-
InstAlt -> 2, 5
-
InstRune 'y' -> 3
-
InstRune 'e' -> 4
-
InstRune 's' -> 7
-
InstRune 'n' -> 6
-
InstRune 'o' -> 7
-
InstMatch
Progの実行
-
現在実行しているInstの位置、 キャプチャの状態を保持した構造体をthreadと呼ぶ。 -
このthreadをリストとして持っておいて、 更新していくことで実行する。
Progの実行(疑似コード)
threads := make([]thread, 0)
threads = prog.add(threads, s, prog.Start, 0)
pos := 0
for len(threads) > 0 {
next := make([]thread, 0)
for _, t := range threads {
next, matched = prog.step(next, s, t.pc, pos)
if matched {
return true
}
}
threads = next
pos += 1
}
return false
prog.addとprog.add
-
prog.add: 文字列を消費しない命令は進めて、 threadを追加する。 -
prog.step: 文字列を消費する命令を進めて、 prog.addを呼び出す。
prog.add(疑似コード)
i := prog.Inst[pc]
switch i.Op {
case InstEmptyWidth:
if ... { // \wや\b、^、$の条件を満たしていれば
return prog.add(threads, s, i.Out, pos)
}
return threads
case InstAlt:
threads = prog.add(threads, s, i.Out, pos)
return prog.add(threads, s, i.Alt, pos)
// case ...: その他の文字列を消費しない命令の処理が入る
default:
// 文字列を消費する命令はstepで処理するのでthreadsに追加
return append(threads, thread{pc: pc})
}
prog.step(疑似コード)
i := prog.Inst[pc]
add := false
switch i.Op {
case InstMatch:
return threads, true
case InstRune:
add = i.Rune === s[pos]
// case ...: その他の文字列を消費する命令の処理が入る
}
if add {
threads = prog.add(threads, s, i.Out, pos)
}
return threads, false
なぜマッチ対象の長さに
比例する時間で動作するのか?
- Progの実行の外側のループは文字列の長さ分しか
回らないはず
&&
threadsの最大の大きさは正規表現に依存する。
→文字列の長さに比例する時間で動作する。
後読みの
実装方法
簡単に思いつく方法
- 命令を逆向きに実行できるようにして、
後読みに遭遇したらそれを呼び出せばいいのでは?
- →文字列の長さに比例する時間で動作しなくなる。
発想の転換
- 後読みの部分をその他とは並列に動作させておいて、
後読みに遭遇したところでそれがマッチしているか
参照できるようにする。
追加する命令
-
InstRepeatAny: /.*/と同じ。 後読みが任意の位置から始まるようにするために必要。 -
InstMatchProc: n番目の後読みがマッチしたことを保存する。 -
InstCheckProc: n番目の後読みがマッチしていた場合、 次の命令に進む。 -
InstMatchProc/InstCheckProcは文字を消費しない命令 - その他、Progに後読みの開始位置を保持するフィールドForkを追加する。
Progの実行(疑似コード)
threads := make([]thread, 0)
matched = make([]bool, len(prog.Fork))
for fork := range prog.Fork {
threads = prog.add(threads, s, fork, 0, matched)
}
threads = prog.add(threads, s, prog.Start, 0, matched)
pos := 0
for len(threads) > 0 {
next := make([]thread, 0)
matched = make([]bool, len(prog.Fork))
for _, t := range threads {
next, matched = prog.step(next, s, t.pc, pos, matched)
// 以下、変わらない
prog.add(疑似コード)
i := prog.Inst[pc]
switch i.Op {
case InstMatchProc:
matched[i.Arg] = true
return threads
case InstCheckProc:
if matched[i.Arg] {
threads = prog.add(threads, s, i.Out, pos)
}
return threads
// case ...: 他の命令は省略
default:
// 文字列を消費する命令はstepで処理するのでthreadsに追加
return append(threads, thread{pc: pc})
}
prog.step(疑似コード)
prog.addの引数にmatchedを追加するだけ
なので省略。
意外と簡単に
実装できる
学術的な
アレとか
コレとか
Go言語の正規表現エンジンは
いわゆるVM型とはちょっと違う
Go言語の正規表現エンジン
は一体何なのか?
- あえて言うなら非決定性有限状態オートマトン(NFA)の
実行を模倣する機械。 - NFA: 複数の状態へ並列に遷移して、
どれかの状態が受理状態になったら受理とみなす
オートマトン。
後読みを実装するためにやったことは
- Go言語の正規表現エンジンにBounded Concurrencyの
機能を追加した。 - Bounded Concurrencyはオートマトンの拡張の一つで
複数の状態を並列に、各状態に依存しながら遷移する
ことができるオートマトン。 - これを使うと後読みを自然(?)に実装できる。
ちなみに先読みの場合は、
- ブーリアン有限状態オートマトン(BFA)という
オートマトンを使うことができる。 - BFAは、NFAにANDの演算を追加したもの。
- 先読みはこのANDに対応する。
- Bounded Concurrencyとは比例する状態数で
逆順の文字列にマッチするBFAを構築できることが
知られている。
参考文献
- 森畑 明昌. (2012). 先読み付き正規表現の有限状態オートマトンへの変換. コンピュータ ソフトウェア, 29(1), 147–158. Retrieved from http://ci.nii.ac.jp/naid/130004549254
-
Brzozowski, J. A., & Leiss, E. (1980). On equations for regular languages, finite automata, and sequential networks. Theoretical Computer Science, 10(1), 19–35. https://doi.org/10.1016/0304-3975(80)90069-9
-
Automata DORON DRUSINSKY, F., & Harel, D. (1994). On the power of bounded concurrency I.
めっちゃ急ぎで書いたので
信用しすぎないように
言い訳の
ターン
で、このPull Requestって
マージされてないよね?
なぜマージされないのか
- どうやって実装したのかを説明しろと
言われているが、英語で説明するのが
かったるすぎる。 - 微妙に実装にオーバーヘッドがあり、
後読みを含んでいない正規表現が
5%くらい遅くなるような気がする。 - ↑後読みなんて大して使わないのに
あえてマージする意味あるか? という疑念。
みなさんは後読みがあったら
使いますか?
おしまい
Go言語の正規表現に後読みを実装した話
By Kitsune Tsuyusato
Go言語の正規表現に後読みを実装した話
golang.tokyo #16 (https://golangtokyo.connpass.com/event/92225/)で話すスライドですhttps://golangtokyo.connpass.com/event/92225/)で話すスライドです

