Survey on Paper:
A Comprehensive Study on Deep Learning-based Methods for Sign Language Recognition
- A comprehensive, holistic and in-depth analysis of multiple literature DNN-based SLR methods is performed, in order to provide meaningful and detailed insights to the task at hand.
- Two new sequence learning training criteria are proposed, known from the fields of speech and scene text recognition.
- A new pretraining scheme is discussed, where transfer learning is compared to initial pseudo-alignments.
- A new publicly available large-scale RGB+D Greek Sign Language (GSL) dataset is introduced, containing reallife conversations that may occur in different public services. This dataset is particularly suitable for DNN based approaches that typically require large quantities of expert annotated data.
Introduction:
Related Work
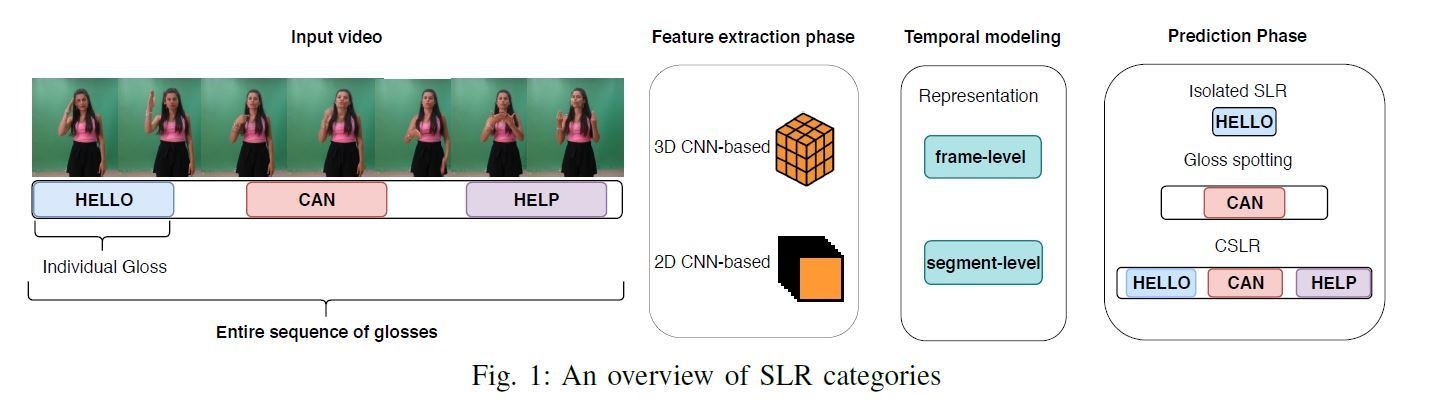
Isolated SLR
Sign Detection In Continuous Streams
Continuous SLR (CSLR)
2D CNN-based CSLR approaches: CNN-HMM, CNN-LSTM-HMM, 2D CNN-LSTM.
3D CNN-based CSLR approaches: C3D, I3D, I3D with Gated RNN, 3D-ResNet.
Publicy available SLR datasets and their properties

SLR Approaches
- SubUNets
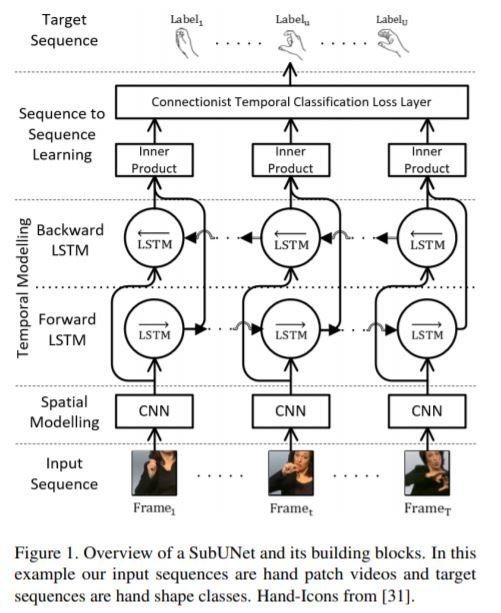
- Solves simultaneous alignment and recognition problems.
- The system is series of specialized systems, termed SubUNets with each SubUNet processes the frames of the video independently.
- Allow to inject domain-specific expert knowledge into the system regarding suitable intermediate representations.
- Allow to implicitly perform transfer learning between different interrelated tasks.
SLR Approaches
2. GoogLeNet+TConvs
- Feature extractor : GoogleNet
- Extra temporal module,TConvs (two 1D CNN layers and two maxpooling layers ) after the GoogleNet to capture finegrained dependencies inside a gloss between frames.
- Bidirectional RNN to capture the context information between gloss segments.
SLR Approaches
3. I3D+BLSTM
- Extended version of GoogLeNet, which contains several .
- 3D convolutional layers followed by 3D max-pooling layers.
- Makes feasible to learn spatio-temporal features from videos, while it leverages efficient known architecture designs and parameters.
- In order to bring this model in CSLR setup, the spatio-temporal feature sequence is processed by an BLSTM, modeling the longterm temporal correlations.
- The whole architecture is trained iteratively with a dynamic pseudo-label decoding method.
SLR Approaches
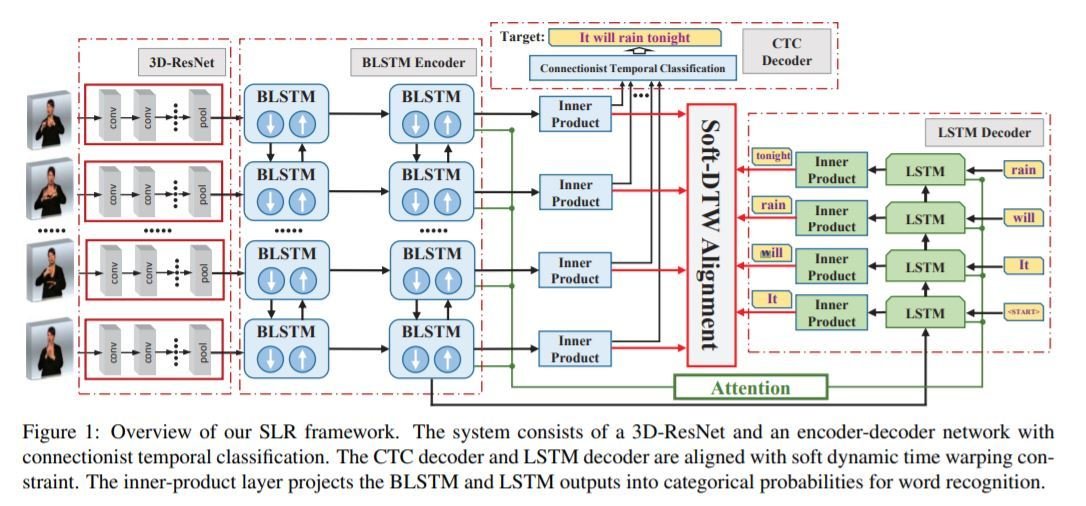
4. 3D-ResNet+BLSTM
- Feature extractor : Lightweight 3D CNN .
- BLSTM for sequence learning.
- Decoding Strategies : CTC criterion and attention decoder RNN.
Text

Problem Addressed By CTC and EnStimCTC

Gloss Test Accuracy in percentage Isolated SLR

Fine tuning in CSLR datasets: Results are reported in WER

Reported results in continuous SI SLR datasets, as measured in WER. Pretraining is performed on the respective isolated.

Reported results in continuous SD SLR datasets, as measured in WER. Pretraining is performed on the respective isolated.

Validation WER of the implemented architectures on Phoenix SD dataset trained with EnStimCTC loss

Conclusion
- In-depth analysis of the most characteristic DNN-based SLR model architectures was conducted.
- A new publicly available large-scale RGB+D dataset was introduced for the Greek SL, suitable for SLR benchmarking.
- Two CTC variations known from other application fields, EnCTC & StimCTC, were evaluated for CSLR and it was noticed that their combination tackled two important issues, the ambiguous boundaries of adjacent glosses and intra-gloss dependencies.
- 3D CNN-based architectures were more effective in isolated SLR
- 2D CNN-based models with an intermediate per gloss representation achieved superior results in the majority of the CSLR datasets.
- GoogLeNet+TConvs, with the proposed pretraining scheme and EnStimCTC criterion, yielded state-ofthe-art results on CSL SI.
Future Work
- Efficient ways for integrating depth information that will guide the feature extraction training phase can be devised.
- To investigate the incorporation of more sequence learning modules, like attention-based approaches, in order to adequately model inter-gloss dependencies.
- Future SLR architectures may be enhanced by fusing highly semantic representations that correspond to the manual and non-manual features of SL, similar to humans.
- Finally, it would be of great importance for the Deaf-non Deaf communication to bridge the gap between SLR and SL translation. Advancements in this domain will drive research to SL translation as well as SL to SL translation, which have not yet been thoroughly studied.
deck
By Manideep Ladi cs20m036




