Decoupling GCN with DropGraph Module for Skeleton-Based Action Recognition
Introduction:
The main contributions discussed in the paper are:
- DeCoupling Graph Convolutional Networks(DC-GCN):
- It efficiently enhances the expressiveness of GCNs with zero extra computation cost.
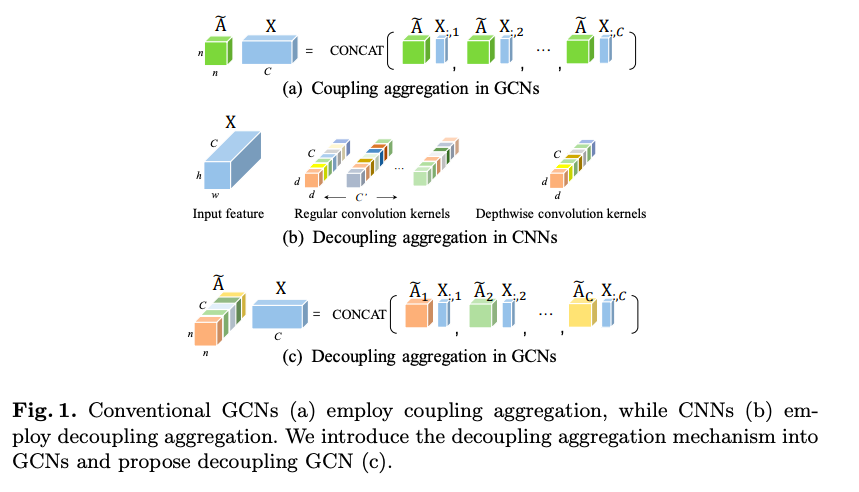
- It is inspired by the decoupling aggregation in CNNs
2 . ADG(Attention Guided DropGraph):
- It effectively relieve the crucial over-fitting problem in GCNs.
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
Reference:https://arxiv.org/pdf/1801.07455.pdf
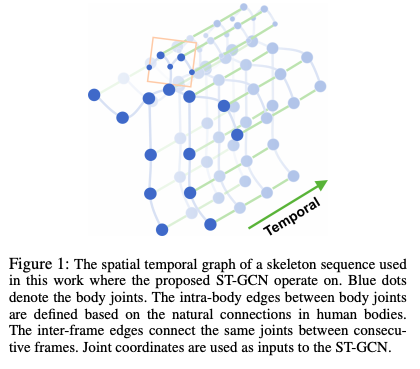
Little Background DeCoupling Mechanism:
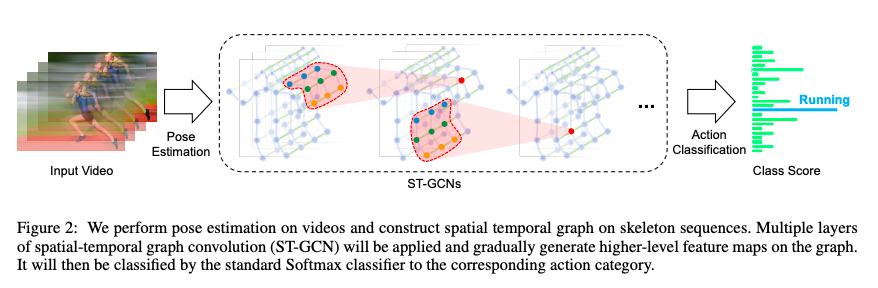
Architecture:
Reference:https://arxiv.org/pdf/1801.07455.pdf
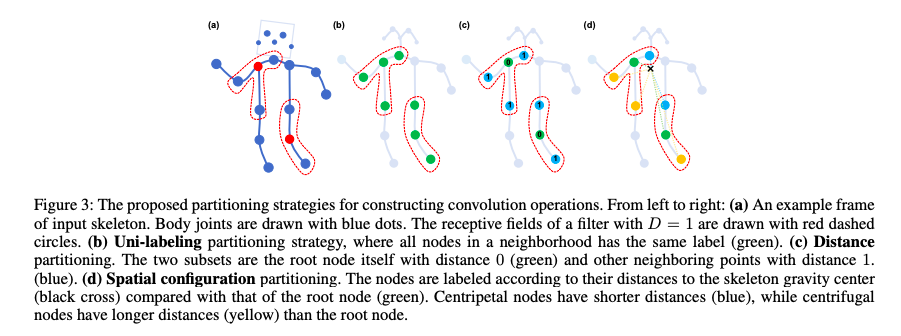
Different Partition Startegies:
Reference:https://arxiv.org/pdf/1801.07455.pdf
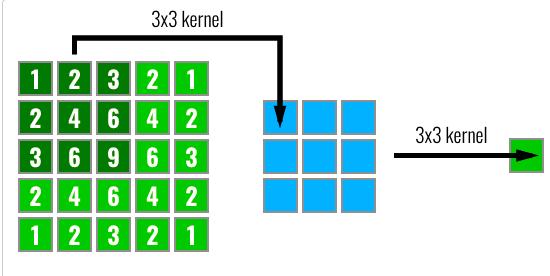
The receptive field in Convolutional Neural Networks (CNN) is the region of the input space that affects a particular unit of the network.

Kernel vs Filter :
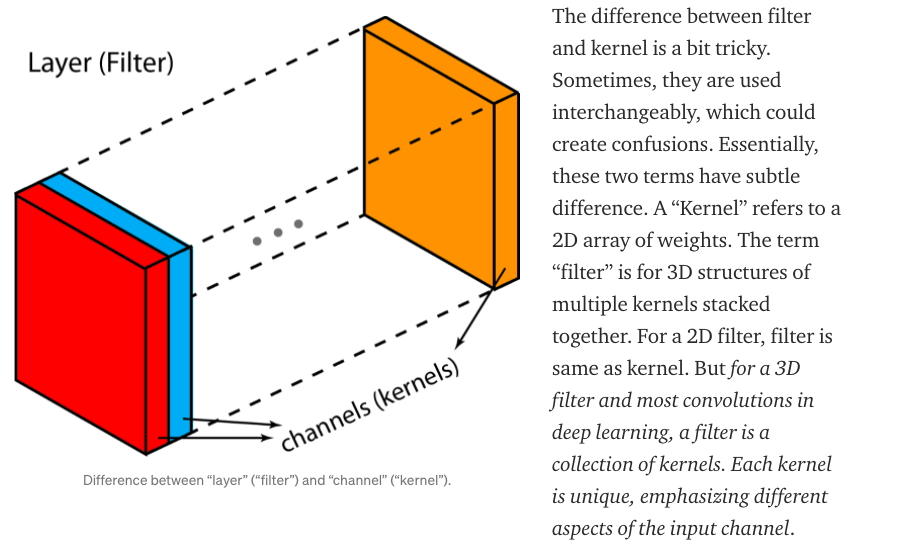
Text
DeCoupling Graph Convolutional Networks(DC-GCN):

DropBlock: A regularization method for convolutional networks
Little Background for DropGraph:
Reference:https://arxiv.org/pdf/1810.12890.pdf

Attention Guided Drop Graph:
The main idea of DropGraph is: when we drop one node, we drop its neighbor node set together

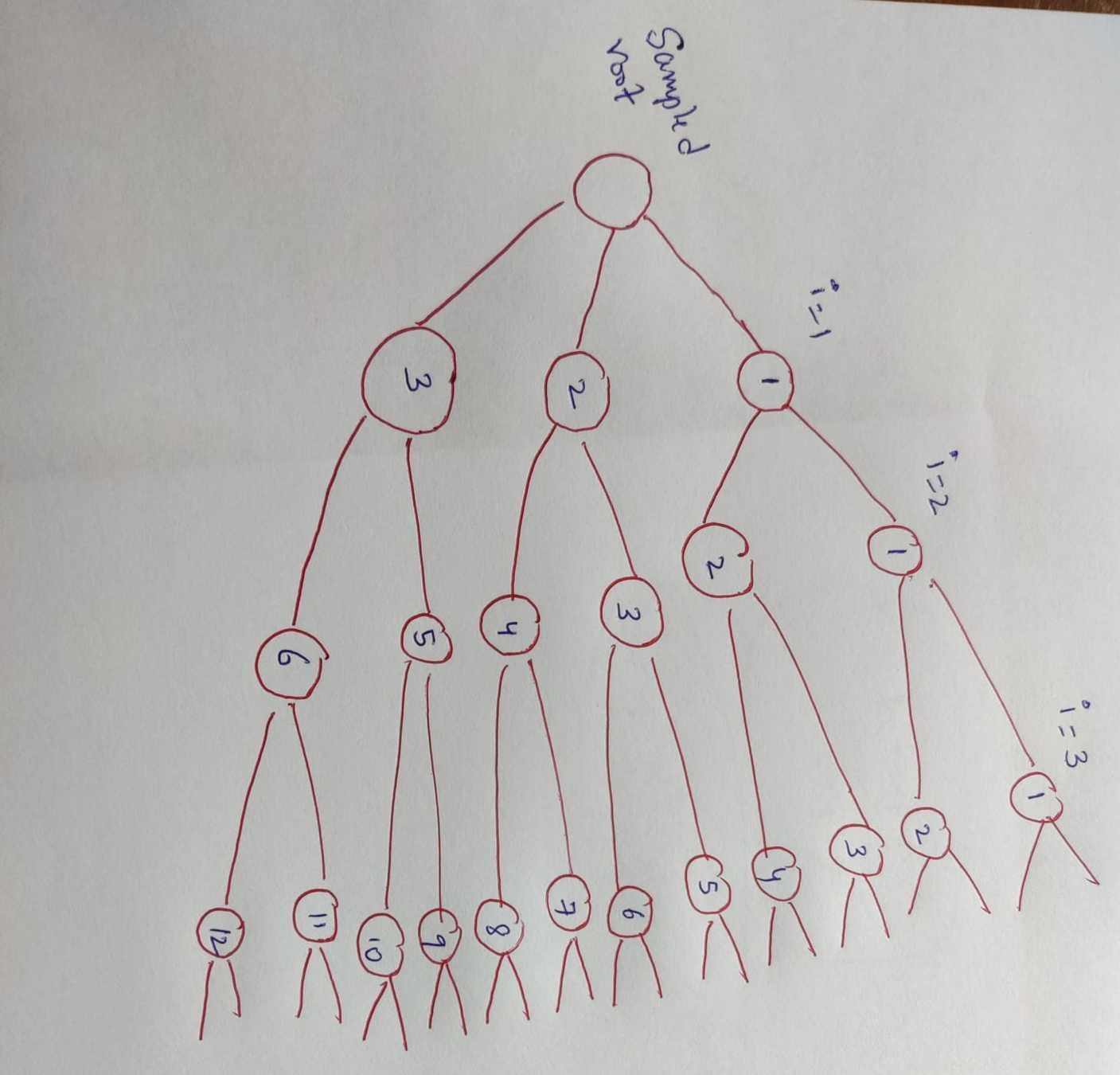
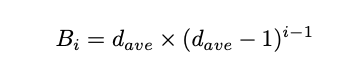
\space B_i=3(3-1)^2 \\
B_i=12
if i=3 and from graph we can say that davg=3
Expected number of nodes in the i th order neighborhood of a randomly sampled node is given by
where
d_{avg} =2e/n
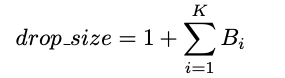
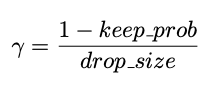
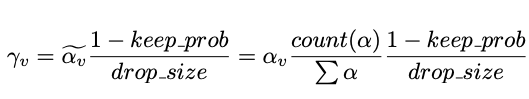
The average expanded drop size is estimated as:
For conventional Dropout:
\gamma = 1-keep\_prob
For DropGraph:
Attention-guided drop mechanism:
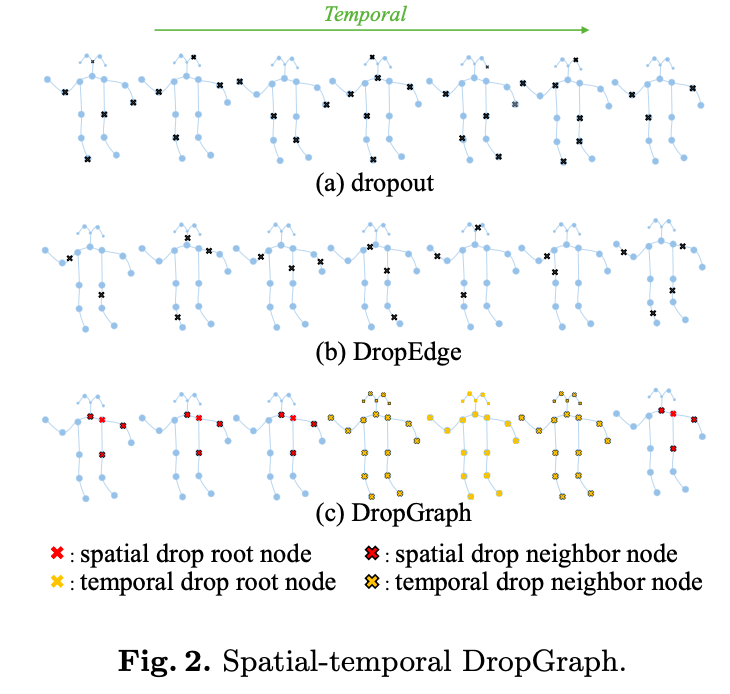
Spatial-temporal DropGraph:
Experiments:
| NTU-RGBD | NTU-RGBD-120 | Northwestern-UCLA |
|---|---|---|
| 56,880 action samples in 60 action classes performed by 40 distinct subjects | 114,480 action samples in 120 action classes performed by 106 distinct subjects | 1494 video clips covering 10 categories performed by 10 different subjects |
| Kinect V2 | Kinect V2 | Kinect |
| 3 cameras from different horizontal angles: −45 , 0 , 45 | 32 setups, and every different setup has a specific location and background | Captured by three Kinect cameras |
| Two protocols 1) Cross-Subject (Xsub): Training data comes from 20 subjects, and the remaining 20 subjects are used for validation. 2) Cross-View (X-view): Training data comes from the camera 0 and 45 , and validation data comes from camera −45 |
Two protocols 1) Cross-Subject (X-sub): Training data comes from 53 subjects, and the remaining 53 subjects are used for validation. 2) Cross-Setup (X-setup): picking all the samples with even setup IDs for training, and the remaining samples with odd setup IDs for validation |
One protocol Training data comes from the first two cameras, and samples from the other camera are used for validation |
1) Datasets:
2) Model Setting:
- Backbone as ST-GCN.
- Batch size is 64.
- SGD as Optimizer.
- Trained the model for 100 epochs.
- momentum of 0.9 and weight decay of 1e-4.
- The learning rate is set as 0.1 and is divided by 10 at epoch 60 and 80.
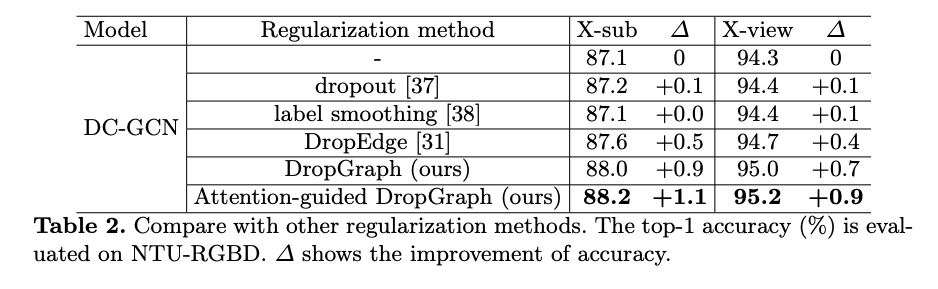
Comparision of regularization methods:
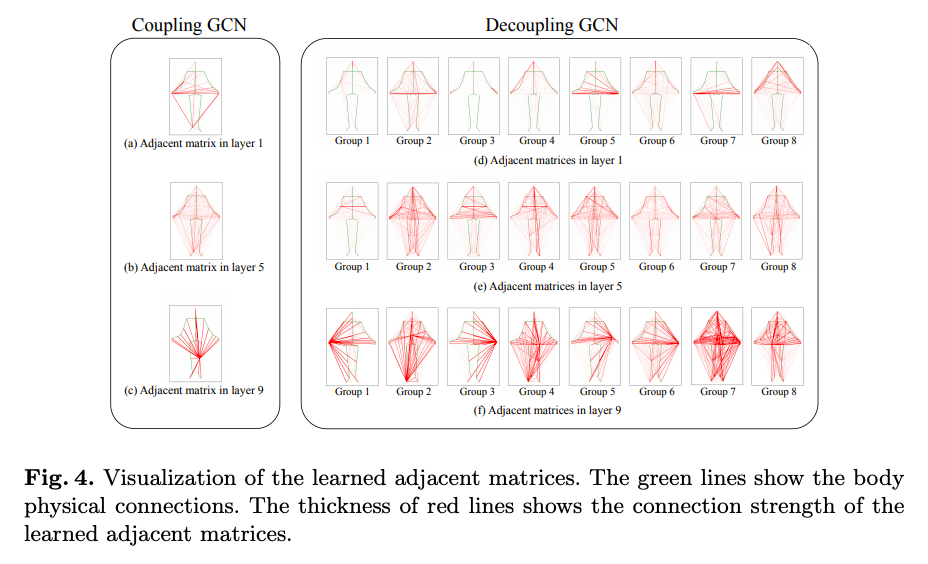
Visulaization of learned Adj Matirces in Coupling GCN and Decoupling GCN
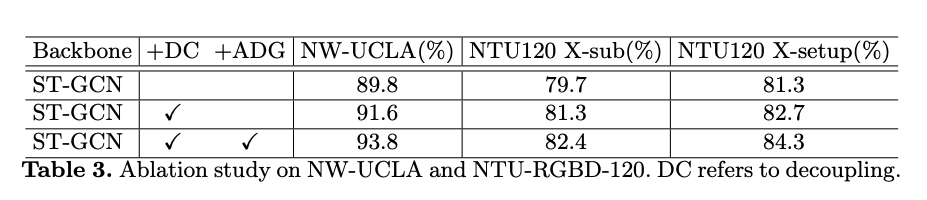
Ablation Study:
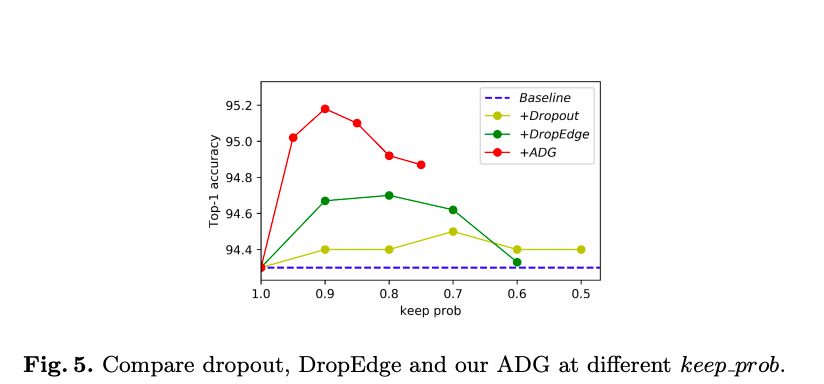
Keep_Probability vs Accuracy:
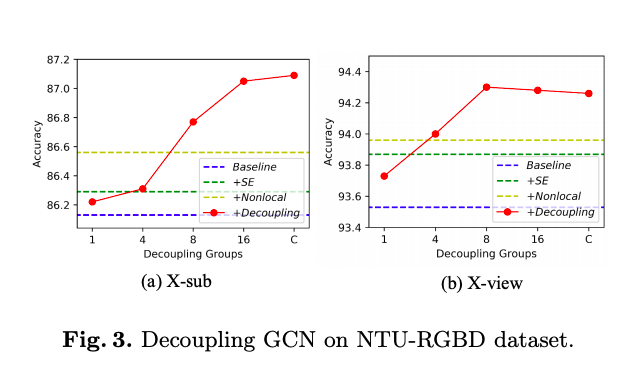
Decoupling groups vs Accuracy:
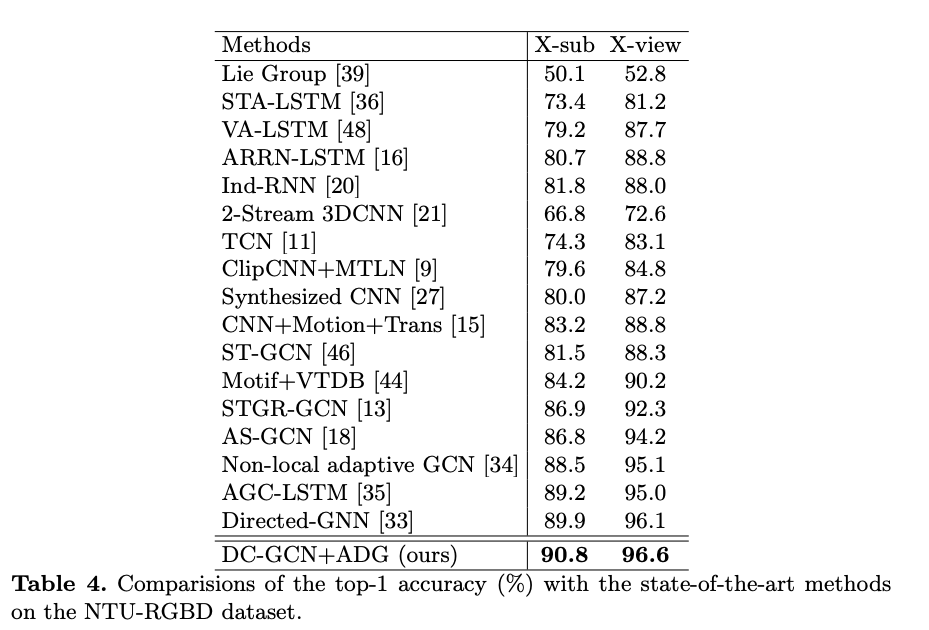
Comparision with State of the art methods:
a) Using NTU-RGBD:

b) Using NW-UCLA:
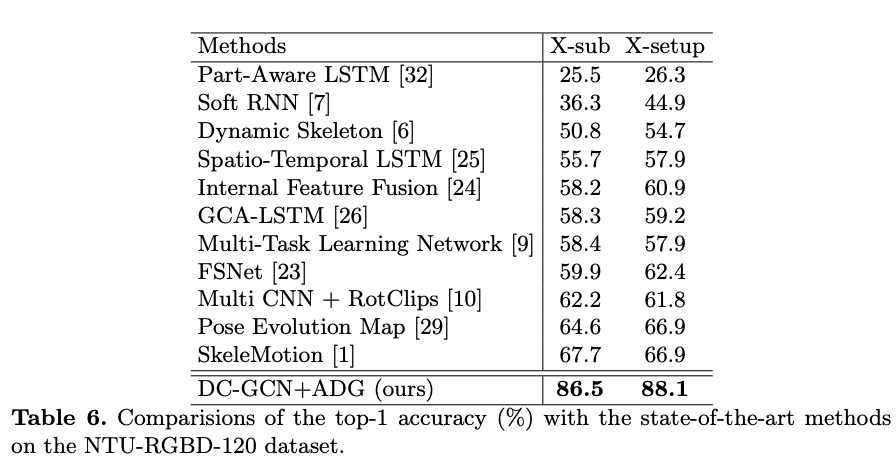
a) Using NTU-RGBD-120:
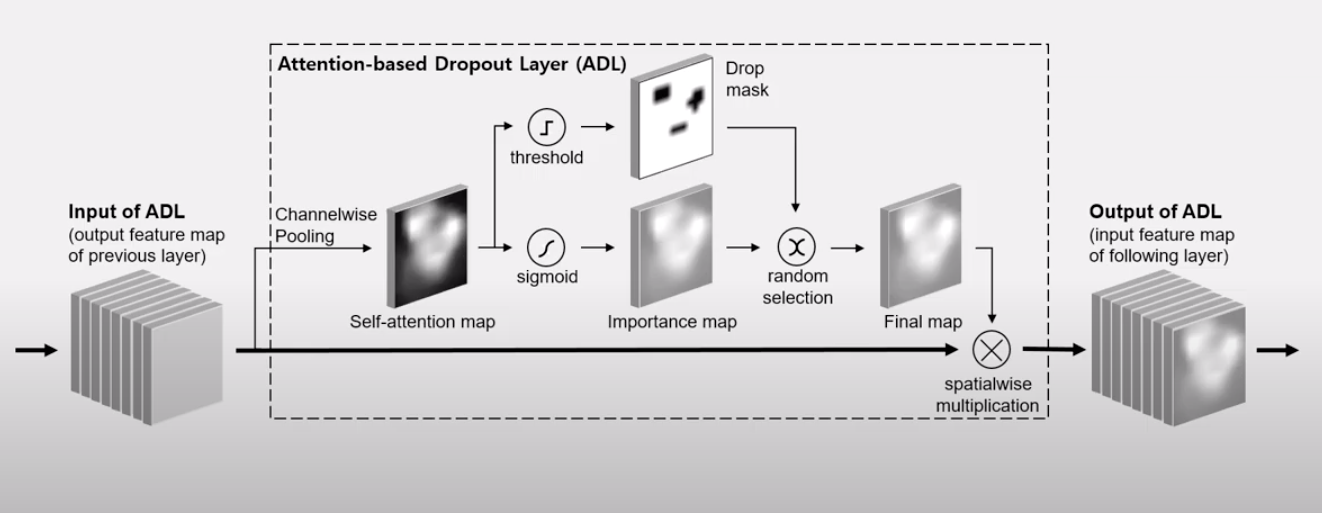
More info on attention based dropout layer:
Decoupling GCN with DropGraph Module for Skeleton-Based Action Recognition
By Manideep Ladi cs20m036




