Video Representation Learning
by Dense Predictive Coding
Reference:https://arxiv.org/pdf/1909.04656.pdf
Brief Overview of the paper:
- The objective of this paper is self-supervised learning of spatio- temporal embeddings from video, suitable for human action recognition.
- Introduces the Dense Predictive Coding (DPC) framework for selfsupervised representation learning on videos.
- Proposed a curriculum training scheme to predict further into the future with progressively less temporal context.
- Evaluated the approach by first training the DPC model on the Kinetics-400 dataset with self-supervised learning, and then finetuning the representation on a downstream task, i.e. action recognition.
What is Self Supervised Learning?

Courtesy:The image taken from Exploring Neurons (Anuj Shah)
- Method of machine learning that can be regarded as an intermediate form of supervised and unsupervised learning.
- Data is fuel for any model to learn better but annotated data difficult to get due to different reasons like cost etc.. and we have huge volumes of unlabelled data in every format like images ,videos, text etc...Self supervised learning is a way of using that data.

Different Types of Self-Supervised Representation Learning
Courtesy:The image taken from Exploring Neurons (Anuj Shah)
Introduction:
- Videos are very appealing as a data source for selfsupervision there is almost an infinite supply available.
- DPC model is designed to predict the future representations based on the recent past . It is inspired by previous research on learning word embeddings.
- Dense Predective Coding is trained by using a variant of noise contrastive estimation (NCE), therefore, in practice, the model has never been optimized to predict the exact future, it is only asked to solve a multiple choice question, i.e. pick the correct future states from lots of distractors.
Action Recognition with two-stream architectures
Related Work:
- Recently, the two-stream architecture (two separate streams, convnet for spatial and temporal component of a video) has been a foundation for many competitive methods.
- The authors show that optical flow is a powerful representation that improves action recognition dramatically.
- Other modalities like audio signal can also benefits visual representation learning.

Gif Courtesy: https://www.robots.ox.ac.uk/~vgg/research/DPC/dpc.html
Dense Predictive Coding:
- The goal is to predict a slowly varying semantic representation based on the recent past.
Gif Courtesy: https://www.robots.ox.ac.uk/~vgg/research/DPC/dpc.html
Framework:
- A video clip is partitioned into multiple non-overlapping blocks x\(_1\); x\(_2\);..... x\(_n\), with each block containing an equal number of frames.
- First, a non-linear encoder function f(.) maps each input video block x\(_t\) to its latent representation z\(_t\).
- Then an aggregation function g(.) temporally aggregates t consecutive latent representations into a context representation c\(_t\).
z\(_t\) = f(x\(_t\)) , c\(_t\) = g(z\(_1\); z\(_2\);.....; z\(_t\)) - Then there is a predictive function \(\phi\)(.) to predict the future. \(\phi\)(.) takes the context representation as the input and predicts the future clip representation:
\(\hat{z}\)\(_{t+1}\) = \(\phi\)(c\(_t\)) = \(\phi\)(g(z\(_1\); z\(_2\); ......; z\(_t\))), \(\hat{z}\)\(_{t+2}\) = \(\phi\)(c\(_{t+1}\)) = \(\phi\)(g(z\(_1\); z\(_2\);.......; z\(_t\); \(\hat{z}\)\(_{t+1}\)))
Gif Courtesy: https://www.robots.ox.ac.uk/~vgg/research/DPC/dpc.html
Contrastive Loss:
- For the predictive task, loss based on NCE is used.
- NCE over feature embeddings encourages the predicted representation \(\hat{z}\) to be close to the ground truth representation z.
- The similarity of the predicted and ground-truth pair (Pred-GT pair) is computed by the dot product \( \hat{z}_{i,k}^T z_{j,m}\).
- The objective is to optimize: L = \(-\sum_{i,k} \big[ log \frac{exp(\hat{z}_{i,k}^T z_{i,k})}{\sum_{j,m} exp(\hat{z}_{i,k}^T z_{j,m}} \big] \).
- The loss encourages the positive pair to have a higher similarity than any negative pairs.
Curriculum Learning Strategy:
- Progressively increasing the number of prediction steps of the model.
- 5pred3, 4pred4.
Self Supervised Training
- 30 fps videos with uniform temporal downsampling by factor 3.
- Consecutive frames grouped into 8 video blocks where each block consists of 5 frames.
- Every video block 0.5s.
- ‘5pred3’.
- Data Augmentation.
- Adam optimizer, initial learning rate 10\(^3\) and weight decay 10\(^5\).
Experiments & Analysis
- Datasets:
- The self-supervised model trained either on UCF101 or K400.
- Performance evaluation: action classification on UCF101 and HMDB51.
- UCF101(13K videos spanning over 101 human action classes),
- HMDB51(7K videos from 51 human action classes)
- Kinetics-400(306K video clips for 400 human action classes) datasets.
- Evaluation methodology:
- Action classifier:

Gif Courtesy: https://www.robots.ox.ac.uk/~vgg/research/DPC/dpc.html
Performance Analysis
- Ablation Study on Architecture

Gif Courtesy: https://www.robots.ox.ac.uk/~vgg/research/DPC/dpc.html
- Benefits of Large Datasets

Gif Courtesy: https://www.robots.ox.ac.uk/~vgg/research/DPC/dpc.html
- Self-Supervised vs. Classification Accuracy

- Benefits of Predicting Further into the Future
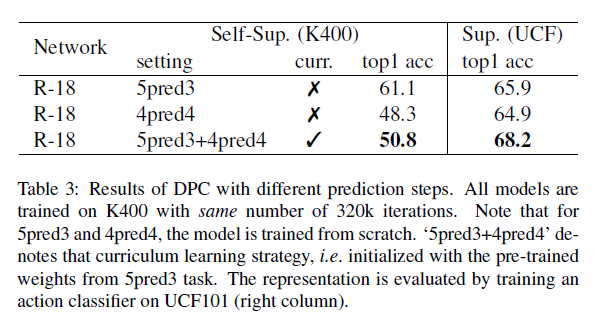
Gif Courtesy: https://www.robots.ox.ac.uk/~vgg/research/DPC/dpc.html
Comparison with State-of-the-art Methods

Gif Courtesy: https://www.robots.ox.ac.uk/~vgg/research/DPC/dpc.html
Conclusion
- Introduced the Dense Predictive Coding (DPC) framework.
- Outperforms the existing state of the art methods.
Future Work
- Methods like masked CNN and attention-based methods are also promising in aggregating the temporal information. So, they can be tested.
- To explore how optical flow can be trained jointly with DPC to further enhance the representation quality.
Video Representation Learning by Dense Predictive Coding
By Manideep Ladi cs20m036




