Learning to classify a subject-line quality for email marketing using Data Mining techniques
MASTER IN INFORMATICS AND COMPUTING ENGINEERING


Supervisor: Vera Lucia Miguéis Oliveira e Silva
Second supervisor: Ivo Pereira
Maria João dos Santos Aguiar e Mira Paulo
Background
1
- Easy Recovery of Investments.
- Supports an easy way of measuring campaign success.
- The most cost-effective way of reach customers.







EMAIL MARKETING
One of the most preferred methods of contact by firms.
Problem
2
OPEN RATES
EMAIL OVERLOAD
MARKETING STRATEGIES FAIL

Customers do not have either time or interest in reading all the received content.
9999...

Goal
3
SENDER NAME & SUBJECT-LINE
Using Data Mining techniques, develop a model capable of classifying a certain subject-line, regarding its quality, from 1 to 5 stars.
The only factors recipients will see at first glance when opening the mail box are:
Related Work
Literature Review
4
- Studies using Data Mining techniques are limited to a set of techniques;
- Studies using secondary data do not evaluate the impact of using personalized messages, neither the impact of the country and business sector to which the campaign is sent;
- Secondary studies are not applied to specific business problems.
Related Tools
5
- There exists several websites seeking to help customers on choosing the best subject-line, but contain merely descriptive guidelines;
- MailChimp, Market leader in marketing automation, offers an insufficient tool;
- Solutions in the market continue to be scarce and become easily outdated.
Implementation
6
1.
2.
3.
To predict the subject quality taking into account not only structural but also content features, which could impact the overall subject quality.
Goals
To compare performance results regarding distinct data mining techniques.
To increase E-goi customers engagement with the E-goi platform, through an innovative and helpful service capable of analyzing a subject-line quality.
7
DATA RESTRICTIONS
- Comprised of 140. 000 email campaigns;
- Sent to at least 100 subscribers;
- Sent over one week before data collection;
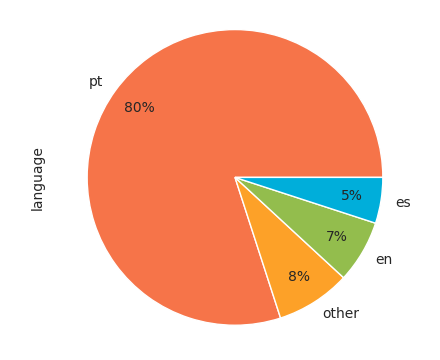
- PT, EN or ES languages.
VARIABLES
- Subject-line,
- Open Rate,
- Country,
- Sector
Data Understanding
Most relevant languages
8
Classes Creation
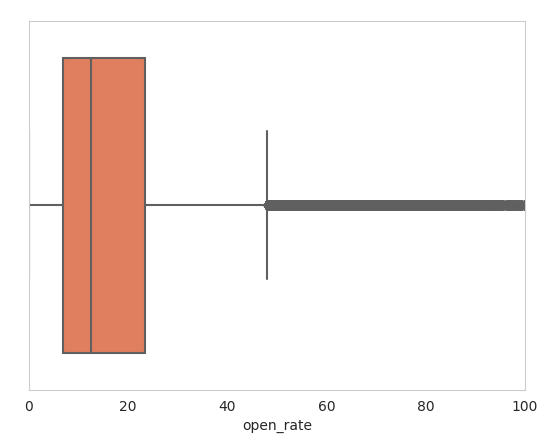
quality\_class = \left
\{\begin{matrix}
if & OR \geq 22.4 & ,5 \\
if & 22.4 > OR \geq 13.7 & ,4\\
if & 13.7 > OR \geq 9.37 & ,3\\
if & 9.37 > OR \geq 5.41 & ,2\\
else, & 1 &
\end{matrix}
\right.
Equal width binning technique.
9
Open Rate Distribution
Feature Construction
SUBJECT LINE
STRUCTURAL FEATURES
CONTENT FEATURES
PAST PERFORMANCE
BAG OF WORDS
or
10
Structural Features
- Number of words
- Number of characters
- Upper Case Percentage
- Punctuation
- Prefixes
- Emojis
- Personalization
- Special characters
- Numbers
- Currency
FEATURES
11
Content Features
1st Approach: Past Performance
- Number of lemmas
- Lemmas Past Performance
- Average
- Weighted Average
- Maximum
FEATURES

12
Content Features
2nd Approach: Bag of Words
- List of TF-IDF values (relavence)
TERM FREQUENCY–INVERSE DOCUMENT FREQUENCY.
FEATURES

13
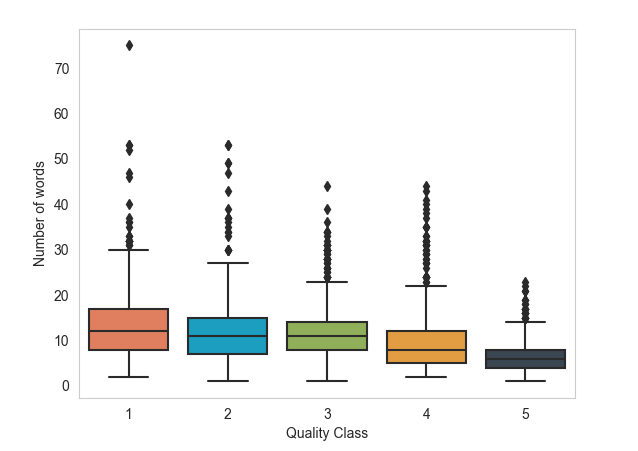
Data Exploration
Feature: Number of words
14
Data Exploration
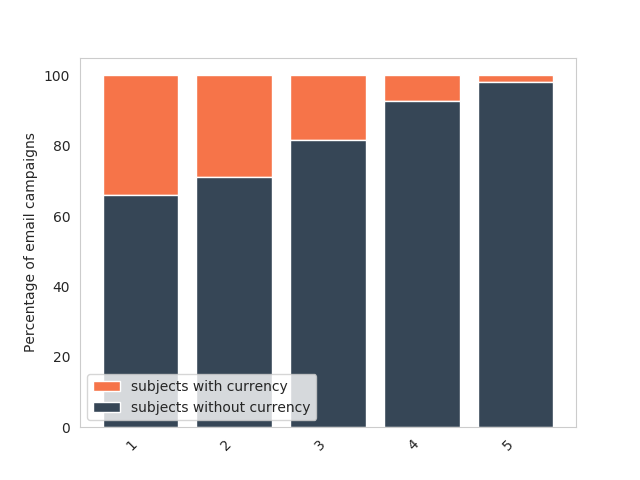
Feature: Currency
15
Data Exploration
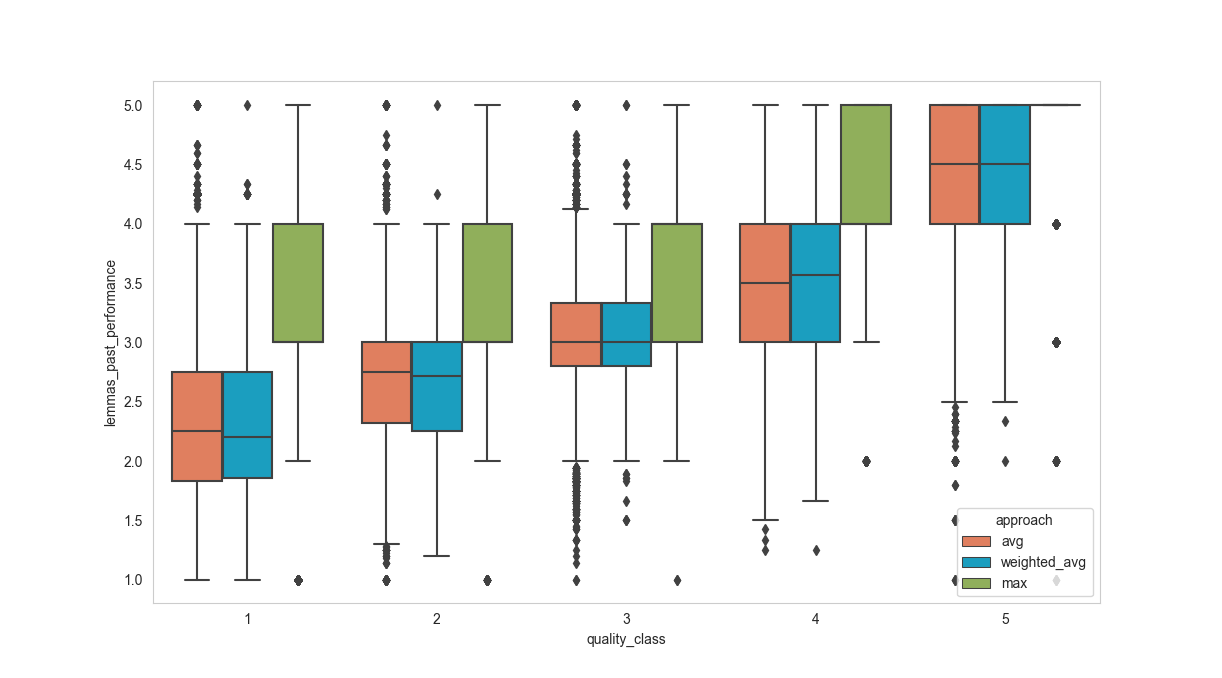
Feature: Lemmas Past Performance
16
Data Exploration
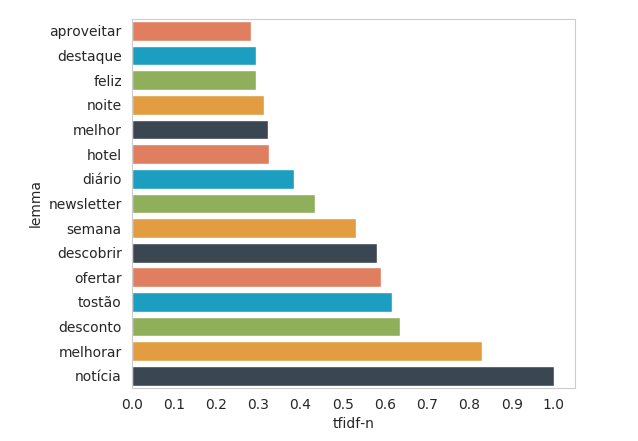
17
Modeling
1.
Sector + Country + Structural Features
5 DISTINCT EXPERIMENTS
2.
2.1
2.2
2.3
Sector + Country + Structural Features + Past Performance Features
Weighted Average
Average
Maximum
3.
Sector + Country + Structural Features + Bag of Words Features
- Naive Bayes
- Support Vector Machine
- Random Forest
- Decision Tree
- Gradient Boosting
- Neural Network
6 ALGORITHMS
18
Nested Cross Validation

19
Evaluation
What is the most accurate model we can get regarding the business challenge?
Percentage of the correctly labeled subjects to the total of subjects.
Seek a balance between Precision and Recall, avoiding false negatives and false positives, for each of the five classes.
ACCURACY
F1 SCORE
20
Evaluation
Perfect Recall
Perfect Precision
F1\_Score = 2 \times \frac{\left (Precision \times Recall \right)}{\left (Precision + Recall \right)}
21
Results
| Exp. 1 | Random Forest | 60.4% | 60.2% |
|---|---|---|---|
| Exp. 2.1 | Random Forest | 61.7% | 62.1% |
| Exp. 2.2 | Random Forest | 62.2% | 62.4% |
| Exp. 2.3 | Random Forest | 61.5% | 61.8% |
| Exp. 3 | Random Forest | 60.3% | 60.6% |
EXPERIMENT
ALGORITHM
ACCURACY
F1 SCORE
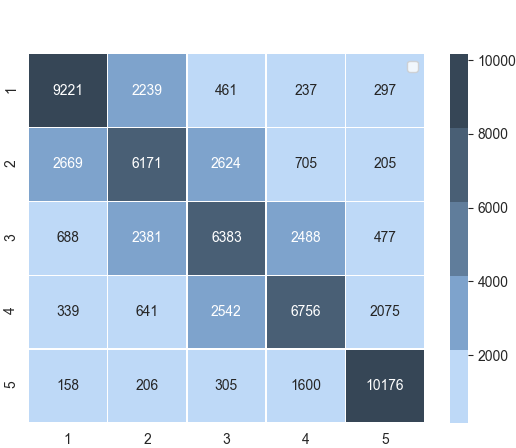
PREDICTED
ACTUAL
Confusion matrix : Experiment 2.2
22
Deployment
23
Conclusions
1.
2.
3.
New agnostic tool for supporting customers on creating engaging and relevant subject-lines, contributing to more emails opened and, thus, more successful marketing campaigns.
First tool embedded into a marketing automation platform, and prepared for adjusting itself to the natural evolution of trends and patterns over time.
25
Effective prediction of the subject quality: 62.4% in terms of Accuracy and 62.2% in terms of F1 Score.
RANDOM 20%
4.
Research paper submitted to International Journal of Production Economics.
Difficulties
26



- Time and day of the week the email campaign was delivered;
- Sender recognition and reputation;
- Customer database quality;
- Subjectiveness when talking about an interesting email campaign.
Thank you
Maria João Mira Paulo
THESIS
By Maria João Mira Paulo



