
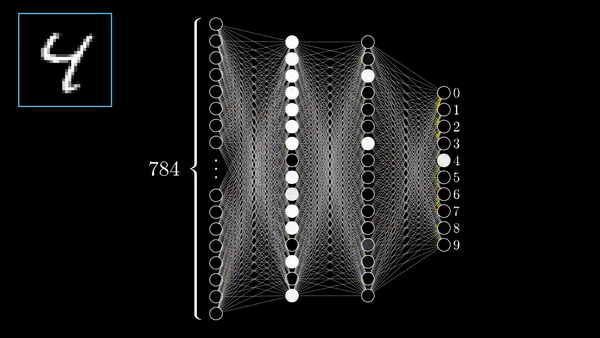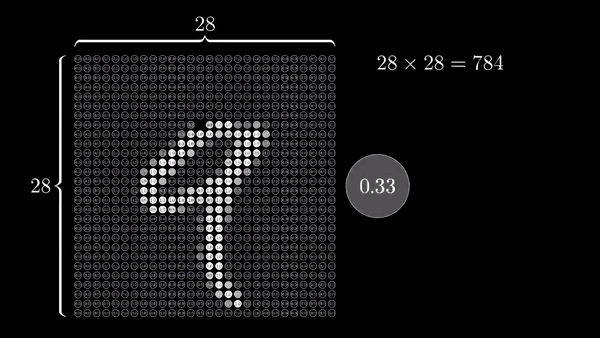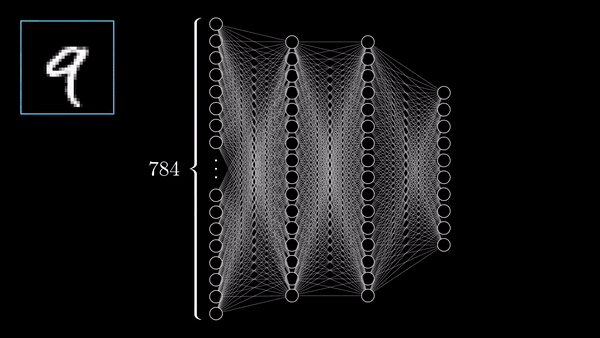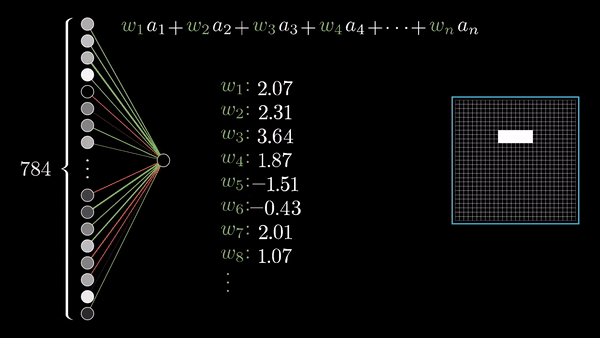
Interactive Intro
Neural Networks
Interactive Intro
Neural Networks

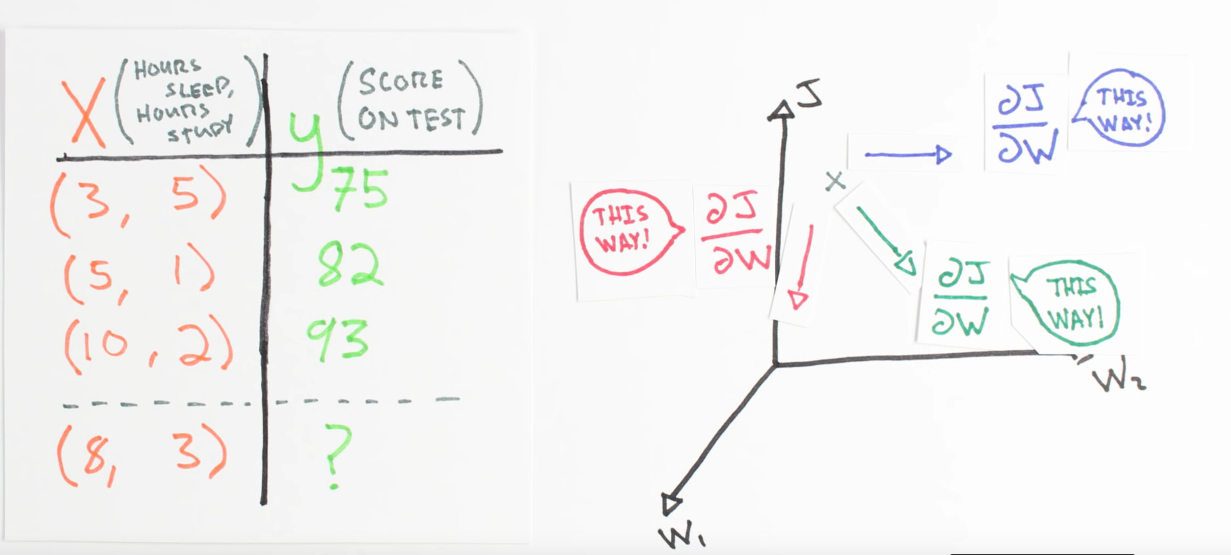
Chapter 1 | Goal Supervised

Interactive Intro
Neural Networks
Chapter 1 | Goal Supervised
Interactive Intro
Neural Networks
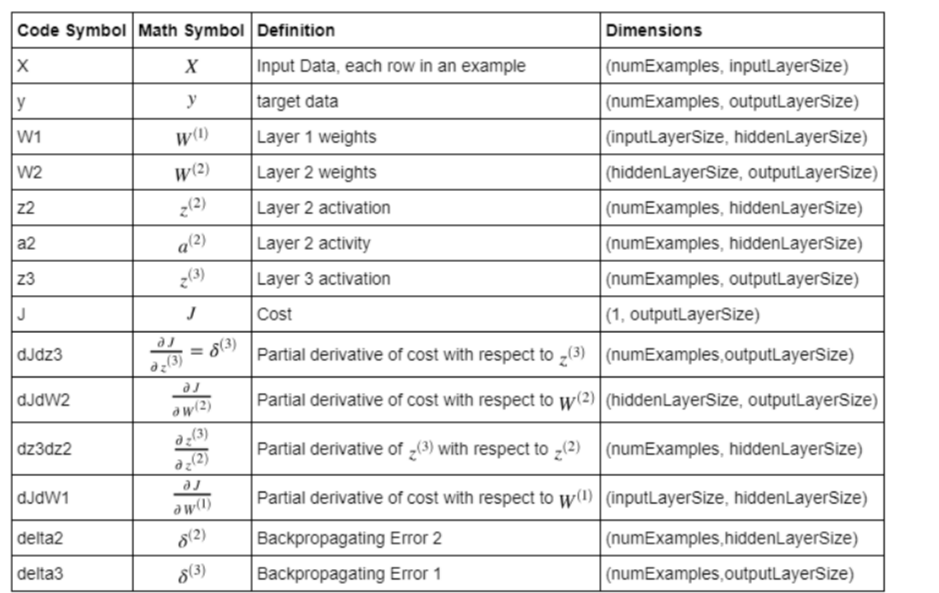
Neuron
Chapter 1 | Goal Supervised
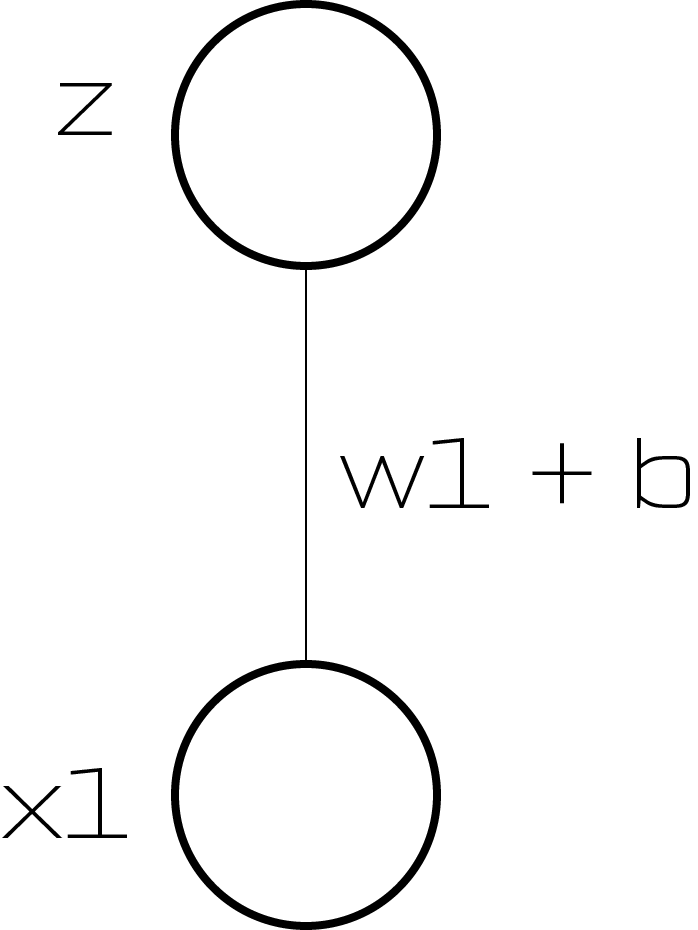
Interactive Intro
Neural Networks
Neuron
Chapter 1 | Goal Supervised
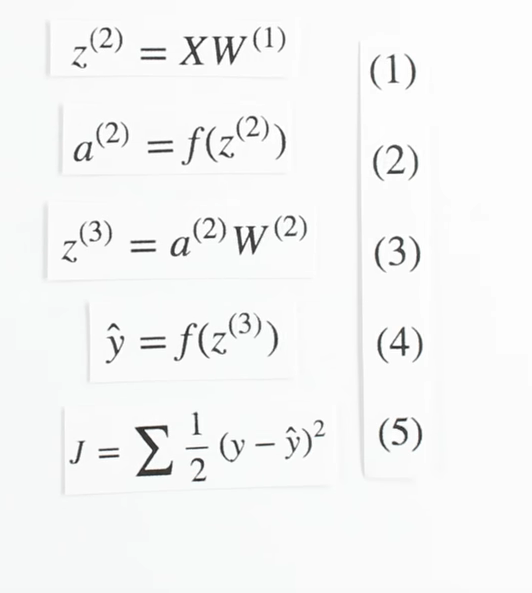
Chapter | Error Calcuation
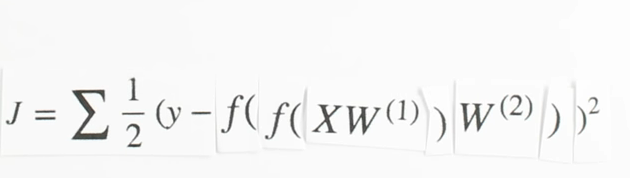
Chapter | Error Calcuation
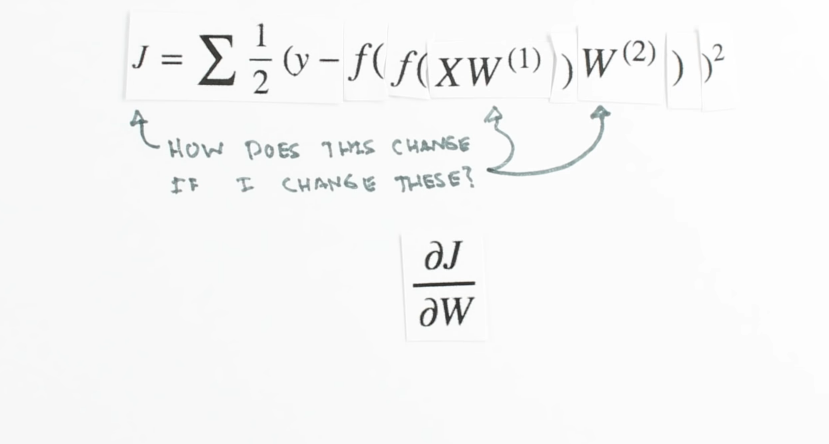
Chapter | Error Calcuation
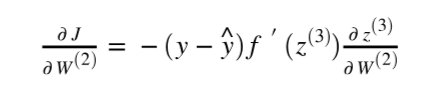
Chapter | Error Calcuation
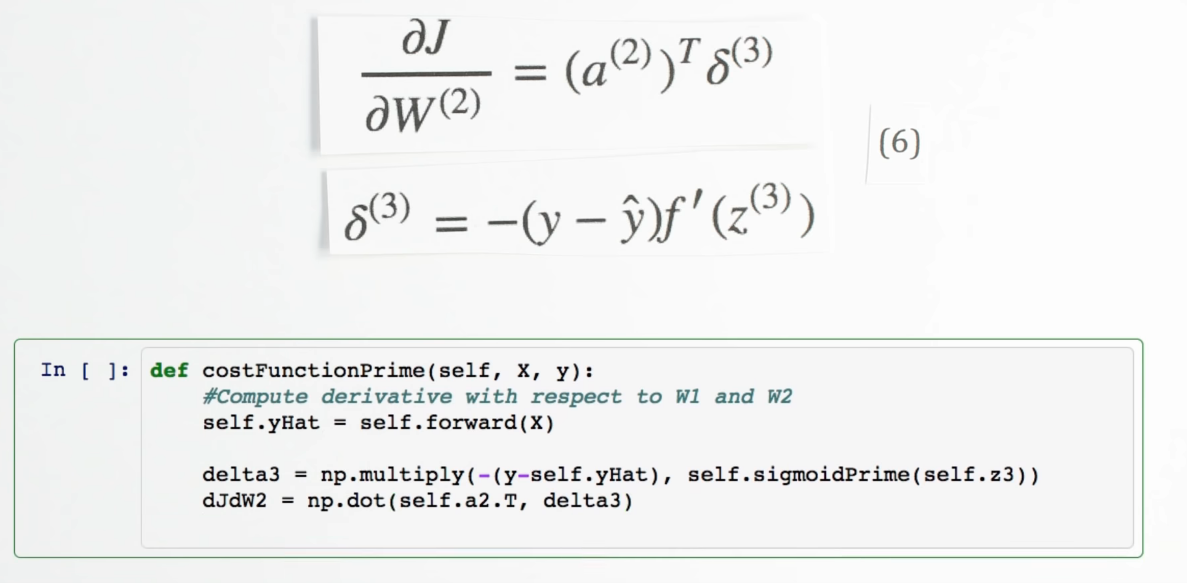
Our final piece of the puzzle is dz3dW2, this term represents the change of z, our third layer activity, with respect to the weights in the second layer.
Chapter | Error Calcuation
Z three is the matrix product of our activities, a two, and our weights, w two. The activities from layer two are multiplied by their correspond weights and added together to yield z3. If we focus on a single synapse for a moment, we see a simple linear relationship between W and z, where a is the slope. So for each synapse, dz/dW(2) is just the activation, a on that synapse!
Chapter | Error Calcuation
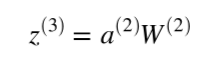
z2
z3
Chapter | Error Calcuation
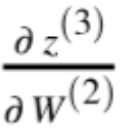
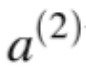
Chapter | Error Calcuation
def costFunctionPrime(self, X, y):
self.yHat = self.forward(X)
delta3 = np.multiply(-(y-self.yHat), self.sigmoidPrime(self.z3))
dJdW2 = np.dot(self.a2.T, delta3)Chapter | Error Calcuation
def costFunctionPrime(self, X, y):
self.yHat = self.forward(X)
delta3 = np.multiply(-(y-self.yHat), self.sigmoidPrime(self.z3))
dJdW2 = np.dot(self.a2.T, delta3)Chapter | Error Calcuation
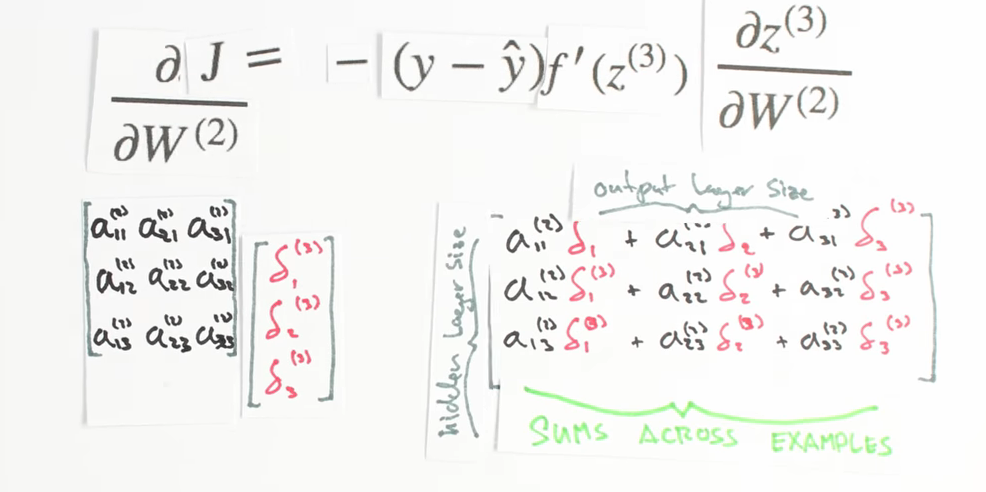
Chapter | Error Calcuation
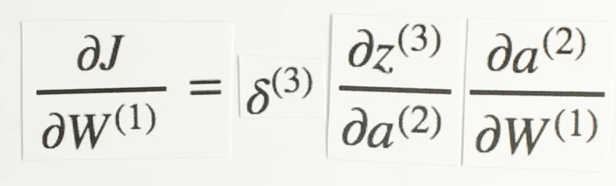
Chapter | Error Calcuation
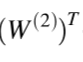
Chapter | Error Calcuation
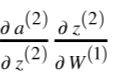
Chapter | Error Calcuation
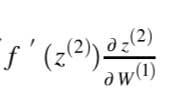
Chapter | Error Calcuation
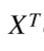
Chapter | Error Calcuation
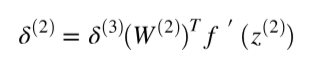
Chapter | Error Calcuation
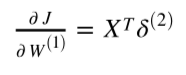
def costFunctionPrime(self, X, y):
#Compute derivative with respect to W and W2 for a given X and y:
self.yHat = self.forward(X)
delta3 = np.multiply(-(y-self.yHat), self.sigmoidPrime(self.z3))
dJdW2 = np.dot(self.a2.T, delta3) + self.W2
delta2 = np.dot(delta3, self.W2.T)*self.sigmoidPrime(self.z2)
dJdW1 = np.dot(X.T, delta2) + self.W1
Chapter | Error Calcuation
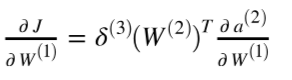
Chapter | Error Calcuation
Chapter | Error Calcuation
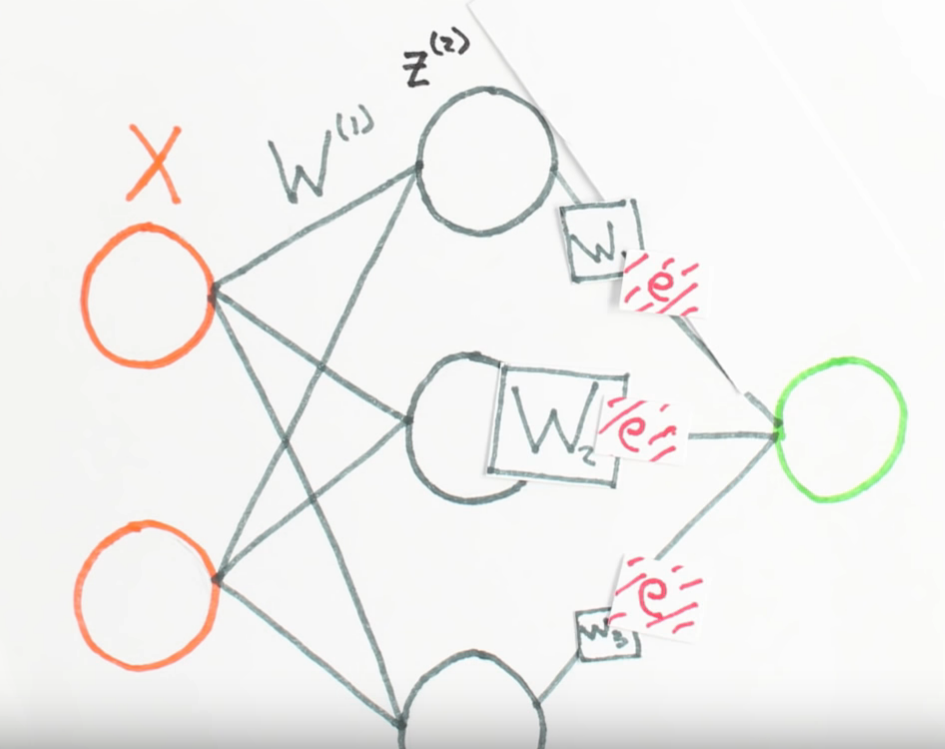
Chapter | Error Calcuation
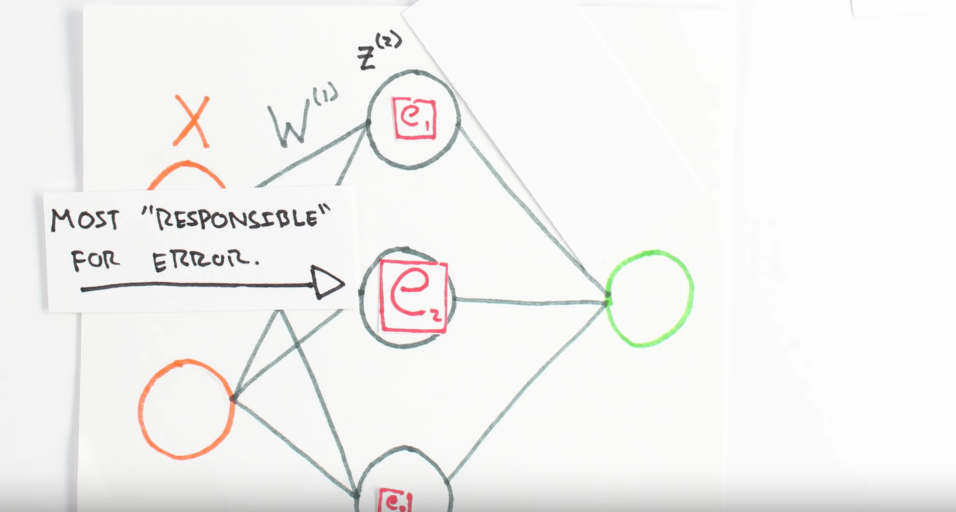
Chapter | Error Calcuation
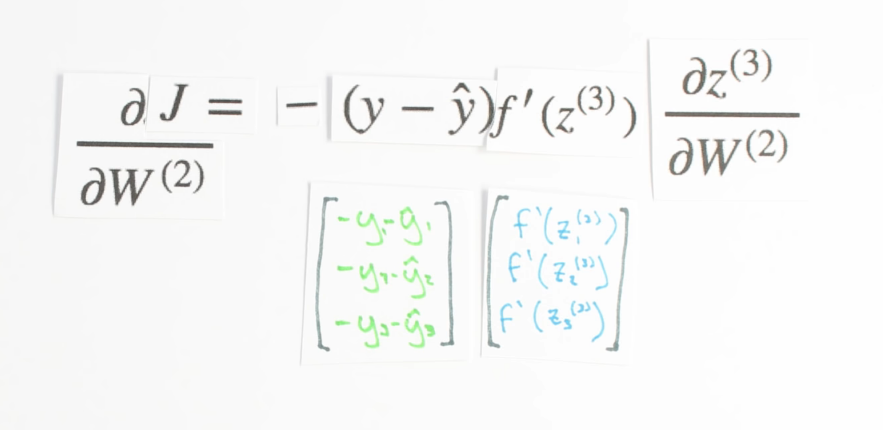
Chapter | Error Calcuation
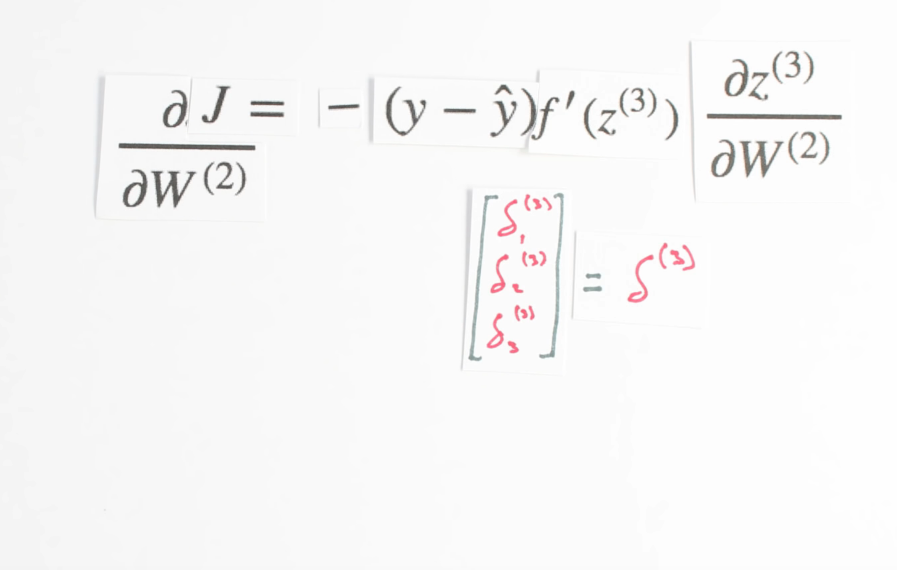
Chapter | Error Calcuation
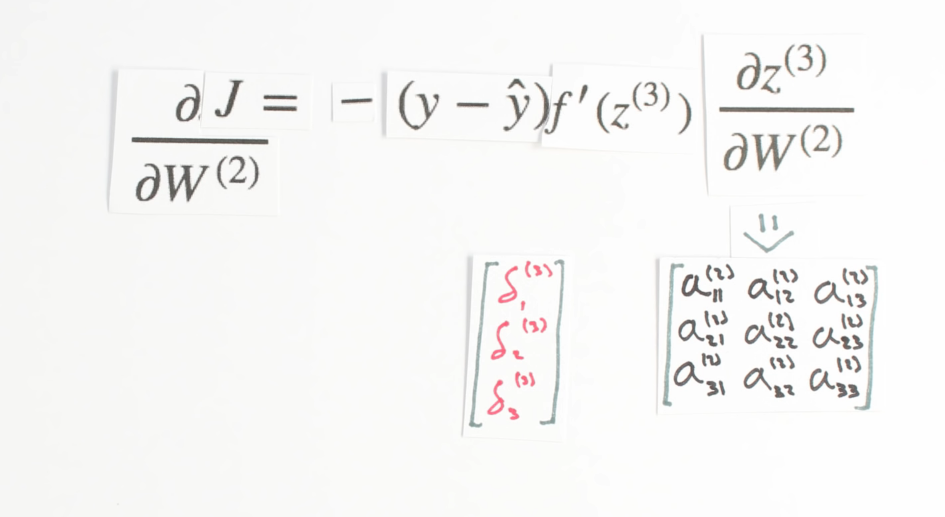
Chapter | Error Calcuation
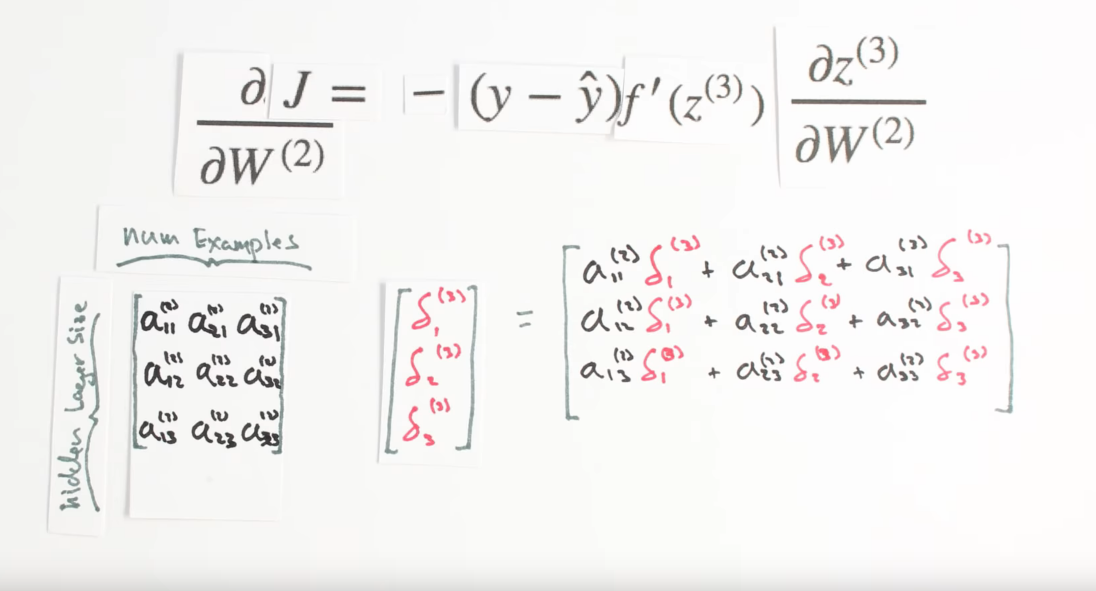
Chapter | Error Calcuation

Chapter | Error Calcuation
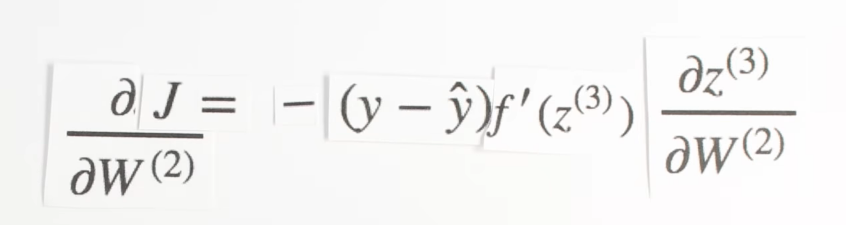
Chapter | Error Calcuation
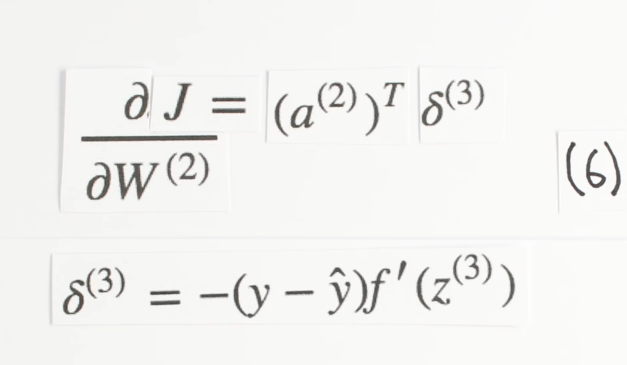
Chapter | Error Calcuation
Chapter | Error Calcuation
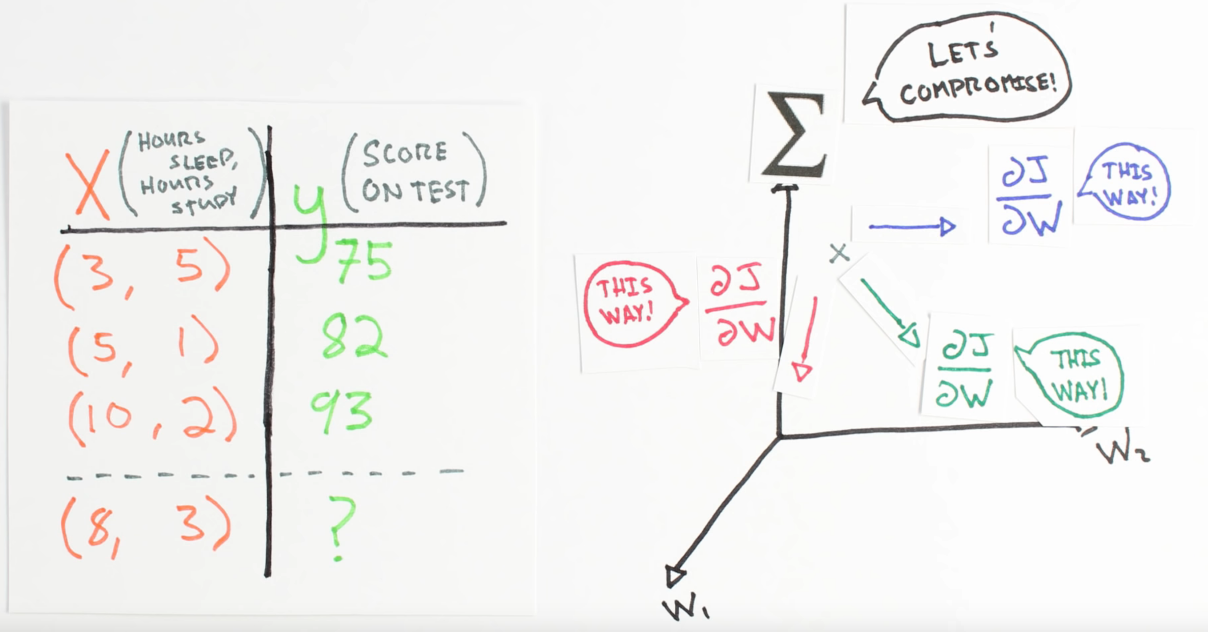
Chapter | Error Calcuation
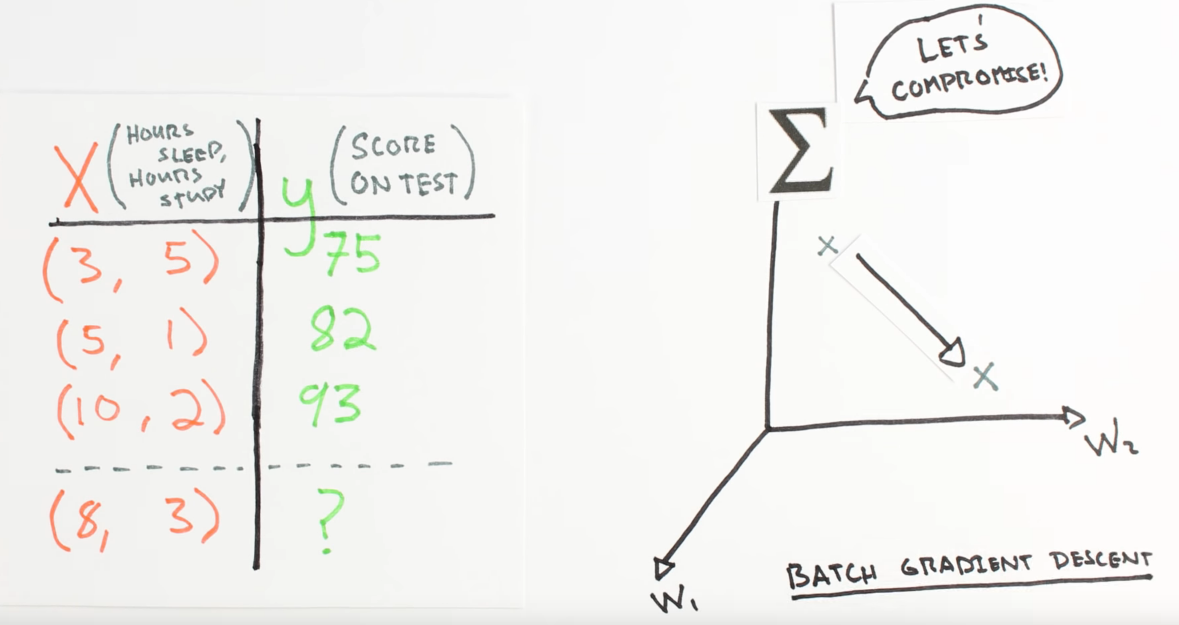
Chapter | Error Calcuation
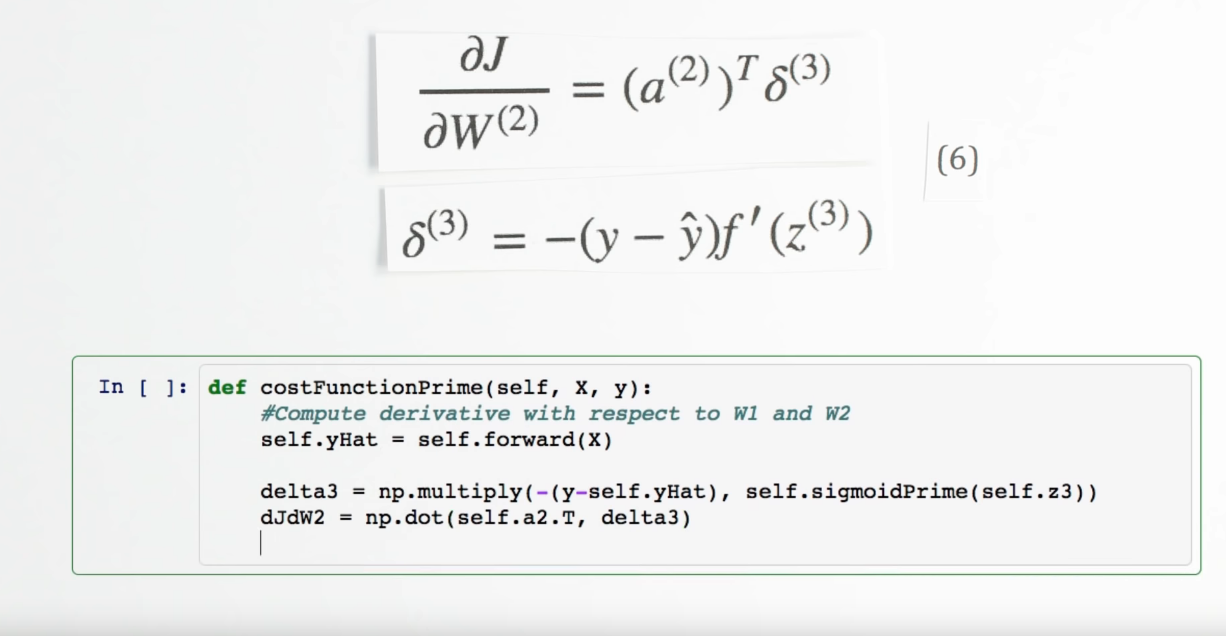
Chapter | Error Calcuation
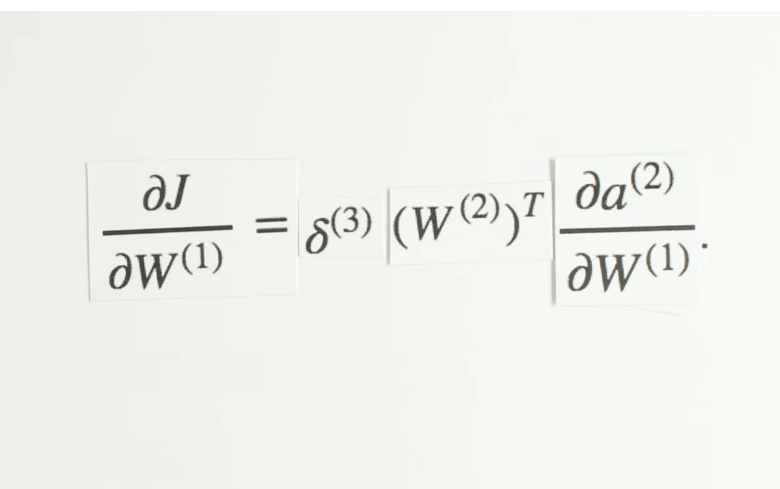
Chapter | Error Calcuation
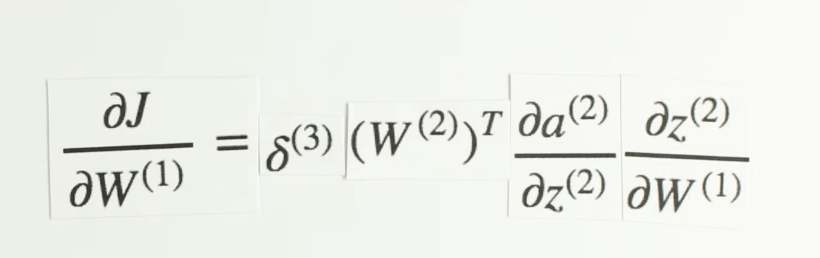
Chapter | Error Calcuation
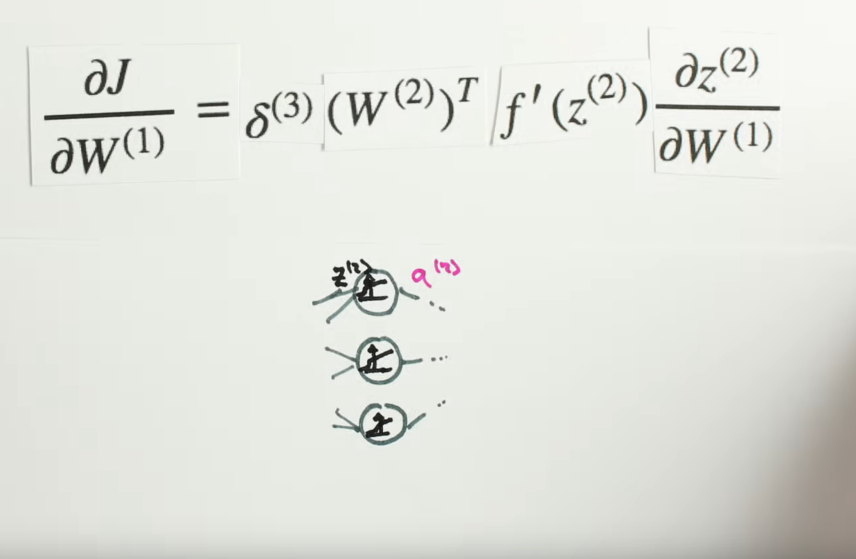
Chapter | Error Calcuation
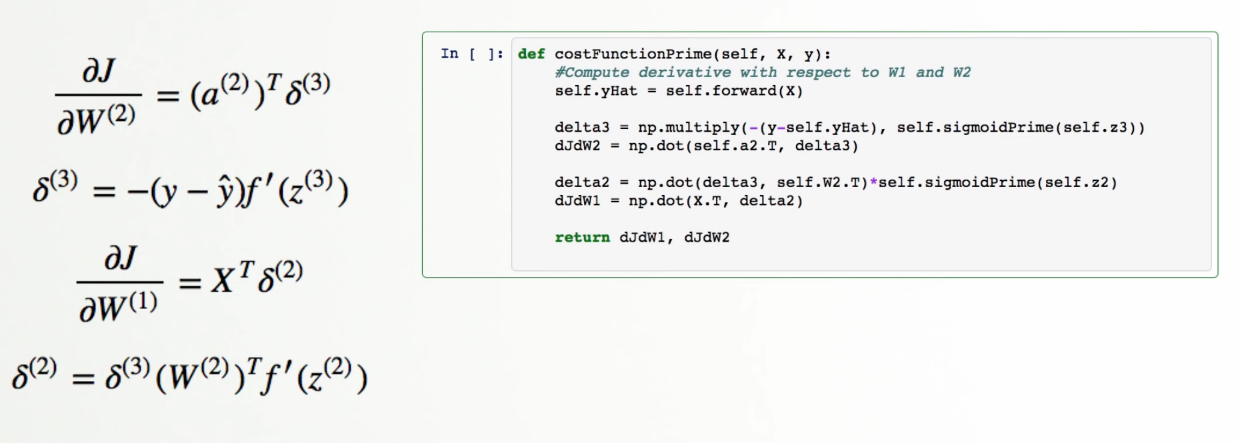
Neural Network Layers
By Marina Goto



