Deep Learning Software Repositories
Martin White advised by Denys Poshyvanyk
Machine Learning
Searching for patterns in data
Software Engineering
Analysis, design, implementation, maintenance, and evolution of software systems
- Code suggestion
- Generating test cases
- Code migration
- Fault localization
- Code clone detection
- Malicious software
- Plagiarism or copyright infringement
- Program debugging
- Automated program repair
How I want to represent...
What I want to represent...
How can we improve representation power?
Deep Learning Software Repositories
Martin White advised by Denys Poshyvanyk
Deep Learning Software Repositories
Artifacts that are produced and archived during the software development lifecycle
Deep Learning Software Repositories
\color{red}{f}:X\rightarrow Y
Deep Learning Software Repositories
Improve representation power
Dissertation
-
Toward deep learning software repositories
-
Deep learning code fragments for code clone detection
-
Sorting and transforming program repair ingredients via deep learning
-
Automated Software Engineering (ASE)
-
Empirical Software Engineering (EMSE)
-
Foundations of Software Engineering (FSE)
-
International Conference on Program Comprehension (ICPC)
-
International Conference on Software Engineering (ICSE)
-
International Conference on Software Maintenance and Evolution (ICSME)
-
Mining Software Repositories (MSR)
-
Transactions on Software Engineering (TSE)
-
Transactions on Software Engineering and Methodology (TOSEM)
SE Conferences and Journals
-
Exploring the use of deep learning for feature location, ICSME'15
-
Combining deep learning with information retrieval to localize buggy files for bug reports, ASE'15
-
Automatically learning semantic features for defect prediction, ICSE'16
-
Guided code synthesis using deep neural networks, FSE'16
-
DeepSoft: A vision for a deep model of software, FSE'16
-
Deep API learning, FSE'16
-
SimilarTech: Automatically recommend analogical libraries across different programming languages, ASE'16
-
Learning a dual-language vector space for domain-specific cross-lingual question retrieval, ASE'16
-
Deep learning code fragments for code clone detection, ASE'16
-
Predicting semantically linkable knowledge in developer online forums via convolutional neural network, ASE'16
-
Replicating parser behavior using neural machine translation, ICPC'17
-
Bug localization with combination of deep learning and information retrieval, ICPC'17
-
Semantically enhanced software traceability using deep learning techniques, ICSE'17
- Automatic text input generation for mobile testing, ICSE'17
- DARVIZ: Deep abstract representation, visualization, and verification of deep learning models, ICSE-NIER'17
-
Domain adaptation for test report classification in crowdsourced testing, ICSE-SEIP'17
-
Easy over hard: A case study on deep learning, FSE'17
-
Are deep learning models the best for source code?, FSE'17
-
Towards accurate duplicate bug retrieval using deep learning, ICSME'17
-
CCLearner: A deep learning-based clone detection approach, ICSME'17
-
Understanding diverse usage patterns from large-scale appstore-service profiles, TSE'17
-
Predicting the delay of issues with due dates in software projects, EMSE'17
Deep Learning Papers
modality
statistical language models are probability distributions over sentences
statistical language models are probability distributions over sentences
statistical language models are probability distributions over sentences
statistical language models are probability distributions over sentences
p(s)=p(w_1,w_2,\ldots,w_m)\approx\prod_1^mp(w_i|w_{i-1})\approx\prod_1^m\frac{c(w_{i-1}w_i)}{c(w_{i-1})}
\text{John read Moby Dick.}
\text{Mary read a different book.}
\text{She read a book by Cher.}
p(\text{John},\text{read},\text{a},\text{book})=\frac{1}{3}\times\frac{1}{1}\times\frac{2}{3}\times\frac{1}{2}\times\frac{1}{2}\approx 0.06
p(\text{Cher},\text{read},\text{a},\text{book})=\frac{0}{3}\times\frac{0}{1}\times\frac{2}{3}\times\frac{1}{2}\times\frac{1}{2}\approx \text{uh oh}
Example
p(\color{red}{\text{John}},\text{read},\text{a},\text{book})=\color{red}{\frac{1}{3}}\times\frac{1}{1}\times\frac{2}{3}\times\frac{1}{2}\times\frac{1}{2}\approx 0.06
\text{\color{red}{John} read Moby Dick.}
\text{\color{red}{John read} Moby Dick.}
p(\color{red}{\text{John}},\color{red}{\text{read}},\text{a},\text{book})=\frac{1}{3}\times\color{red}{\frac{1}{1}}\times\frac{2}{3}\times\frac{1}{2}\times\frac{1}{2}\approx 0.06
\text{John \color{red}{read Moby} Dick.}
p(\text{John},\color{red}{\text{read}},\color{red}{\text{a}},\text{book})=\frac{1}{3}\times\frac{1}{1}\times\color{red}{\frac{2}{3}}\times\frac{1}{2}\times\frac{1}{2}\approx 0.06
\text{Mary \color{red}{read a} different book.}
\text{She \color{red}{read a} book by Cher.}
p(\text{John},\text{read},\color{red}{\text{a}},\color{red}{\text{book}})=\frac{1}{3}\times\frac{1}{1}\times\frac{2}{3}\times\color{red}{\frac{1}{2}}\times\frac{1}{2}\approx 0.06
\text{John read Moby Dick.}
\text{Mary read \color{red}{a different} book.}
\text{She read \color{red}{a book} by Cher.}
p(\text{John},\text{read},\text{a},\color{red}{\text{book}})=\frac{1}{3}\times\frac{1}{1}\times\frac{2}{3}\times\frac{1}{2}\times\color{red}{\frac{1}{2}}\approx 0.06
\text{Mary read a different \color{red}{book.}}
\text{She read a \color{red}{book by} Cher.}
p(\text{John},\text{read},\text{a},\text{book})=\frac{1}{3}\times\frac{1}{1}\times\frac{2}{3}\times\frac{1}{2}\times\frac{1}{2}\approx 0.06
\text{Mary read a different book.}
\text{She read a book by Cher.}
p(\color{red}{\text{Cher}},\text{read},\text{a},\text{book})=\color{red}{\frac{0}{3}}\times\frac{0}{1}\times\frac{2}{3}\times\frac{1}{2}\times\frac{1}{2}\approx \text{uh oh}
\text{She read a book by \color{red}{Cher}.}

Statistical NLP and Software Engineering
- Recent research applied NLP techniques to software corpora
- Software language models—modeling sequential SE data
- Code suggestion [Hindle'12,Tu'14,Franks'15]
- Deriving readable string test inputs [Afshan'13]
- Improving search over code bases [Movshovitz-Attias'13]
- Improving error reporting [Campbell'14]
- Generating feasible test cases [Tonella'14]
- Improving stylistic consistency [Allamanis'14]
- Code migration [Nguyen'13,Nguyen'14,Nguyen'14]
- Code review [Hellendoorn'15]
- Fault localization [Ray'15]
Neural Networks
Neural networks comprise neuron-like processing units
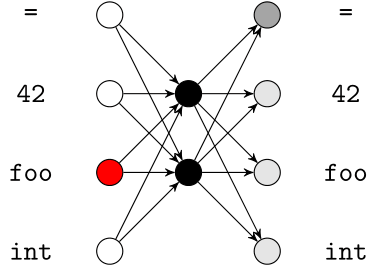
Keywords. Deep Architecture, Deep Learning
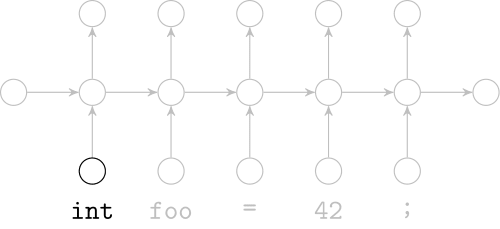
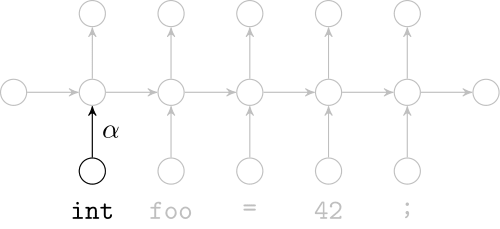
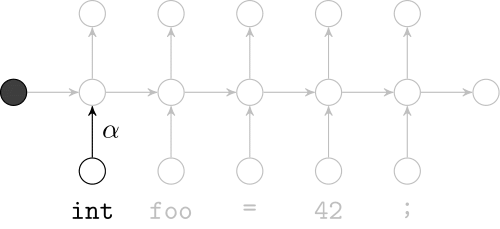
Recurrent Neural Networks
Model sequences of terms in a source code corpus
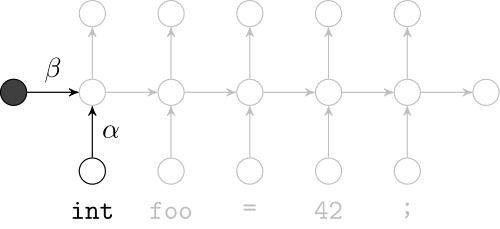
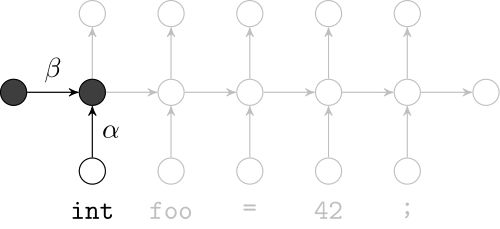
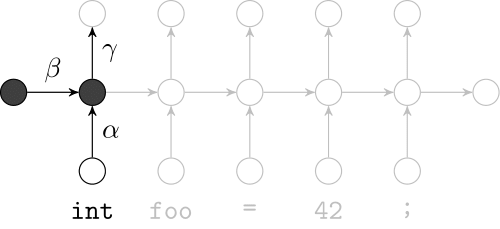
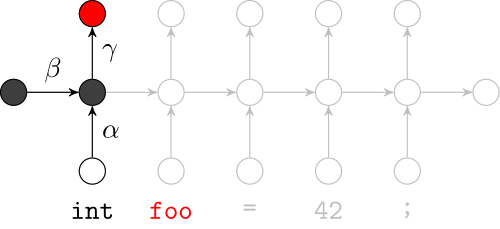
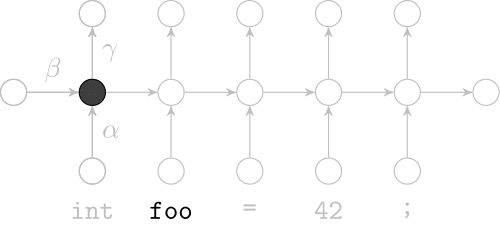
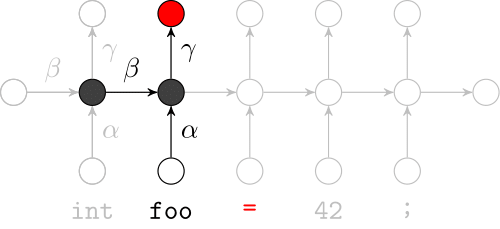
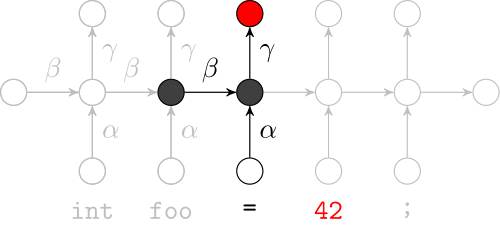
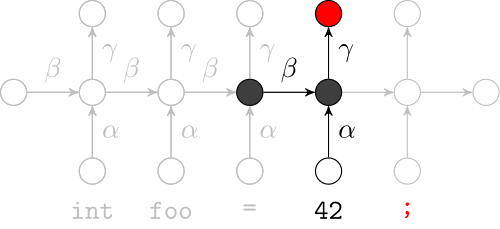
Extrinsic Evaluation: Top-k
- Code suggestion engines recommend the next token given the context
static File ClassLoaderHelper
static File mapAlternativeName
static File _localctx
static File predindex
static File _sharedContextCache- Designed comparative experiments to measure significance
- Language models were treatments; sentences in the test corpus were experimental units; and top-k scores were responses
- Null hypothesis stated there was no difference in performance
- (Two-tailed) research hypothesis stated there was a difference
RQ1. Do deep learners significantly outperform state-of-the-practice models at code suggestion on our dataset?
RQ2. Are there any distinguishing characteristics of the test documents on which the deep learners achieve considerably better performance?
@Extension
public class CustomMatrixListener extends ... {
public CustomMatrixListener() {
...
@Override
public void onCompleted ... {| Model | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| Interpolated 8-gram | 49.7 | 71.3 | 78.1 |
| Interpolated 8-gram 100-cache | 4.8 | 69.5 | 78.5 |
| Static (400, 5) | 61.1 | 78.4 | 81.4 |
| Dynamic (300, 20) | 72.2 | 88.4 | 92.0 |
Research Questions
Dissertation
-
Toward deep learning software repositories
-
Deep learning code fragments for code clone detection
-
Sorting and transforming program repair ingredients via deep learning
Code Clones
A code fragment is a contiguous segment of source code. Code clones are two or more fragments that are similar with respect to a clone type.
Type I Clones
Identical up to variations in comments, whitespace, or layout [Roy'07]
if (a >= b) {
c = d + b; // Comment1
d = d + 1;}
else
c = d - a; //Comment2if (a>=b) {
// Comment1'
c=d+b;
d=d+1;}
else // Comment2'
c=d-a;
if (a>=b)
{ // Comment1''
c=d+b;
d=d+1;
}
else // Comment2''
c=d-a;Type II Clones
Identical up to variations in names and values, comments, etc. [Roy'07]
if (a >= b) {
c = d + b; // Comment1
d = d + 1;}
else
c = d - a; //Comment2if (m >= n)
{ // Comment1'
y = x + n;
x = x + 5; //Comment3
}
else
y = x - m; //Comment2'A parameterized clone for this fragment is
Type III Clones
Modifications include statement(s) changed, added, or deleted [Roy'07]
public int getSoLinger() throws SocketException {
Object o = impl.getOption(SocketOptions.SO_LINGER);
if (o instanceof Integer) {
return((Integer) o).intValue();
}
else return -1;
}public synchronized int getSoTimeout() // This statement is changed
throws SocketException {
Object o = impl.getOption(SocketOptions.SO_TIMEOUT);
if (o instanceof Integer) {
return((Integer) o).intValue();
}
else return -0;
}Type IV Clones
Syntactically dissimilar fragments with similar functionality [Roy'07]
int i, j=1;
for (i=1; i<=VALUE; i++)
j=j*i;int factorial(int n) {
if (n == 0) return 1 ;
else return n * factorial(n-1) ;
}
Now consider a recursive function that calculates the factorial
Code Clone Detection Techniques
Techniques can be classified by their source code representation
- Text. Apply slight transformations; compare sequences of text
- Token. Lexically analyze the code; compare subsequences of tokens
- Tree. Measure the similarity of subtrees in syntactical representations
- Graph. Consider the semantic information of the source code
- Metrics. Gather different metrics for fragments; compare them
Motivation
public int getSoLinger() throws SocketException {
Object o = impl.getOption(SocketOptions.SO_LINGER);
if (o instanceof Integer) {
return((Integer) o).intValue();
}
else return -1;- They depend on generic, handcrafted features to represent code
- Frequency of keywords
- Indentation pattern
- Length of source code line
- Number of shared/different AST nodes
- q-Level atomic tree patterns in parse trees
- Frequency of semantic node types in PDGs
- Geometry characteristics of CFGs
- Many approaches consider either structure or identifiers but none of the existing techniques model both sources of information
Our new set of techniques fuse and use
Learning-based Paradigm
- Learn. Induce compositional representations of code; compare
- Distinguished from token-based techniques; maps terms to continuous-valued vectors and uses context
- Distinguished from tree-based techniques; operates on identifiers and learns discriminating features
Learning-based Code Clone Detection
Couples deep learners to front end compiler stages
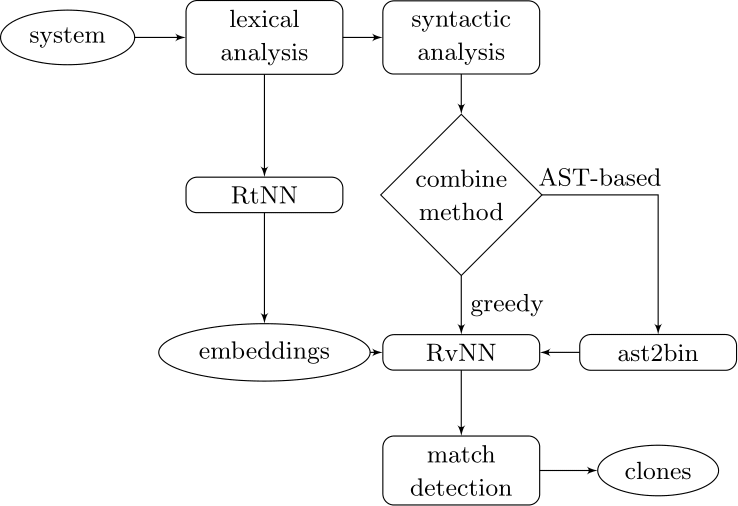
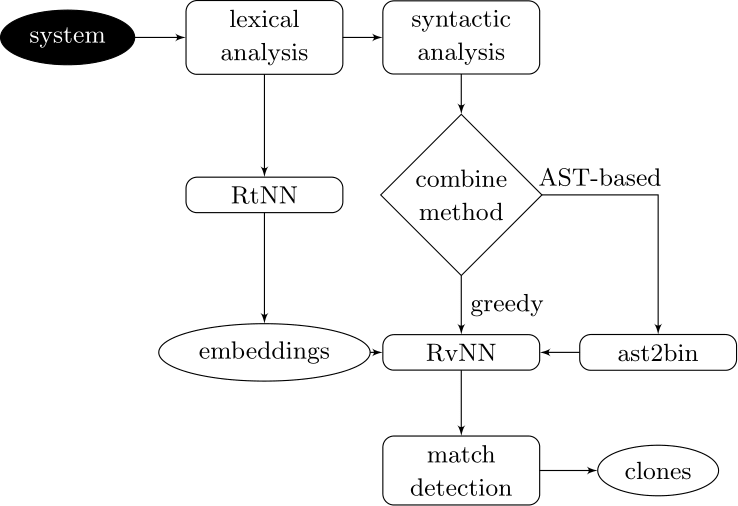
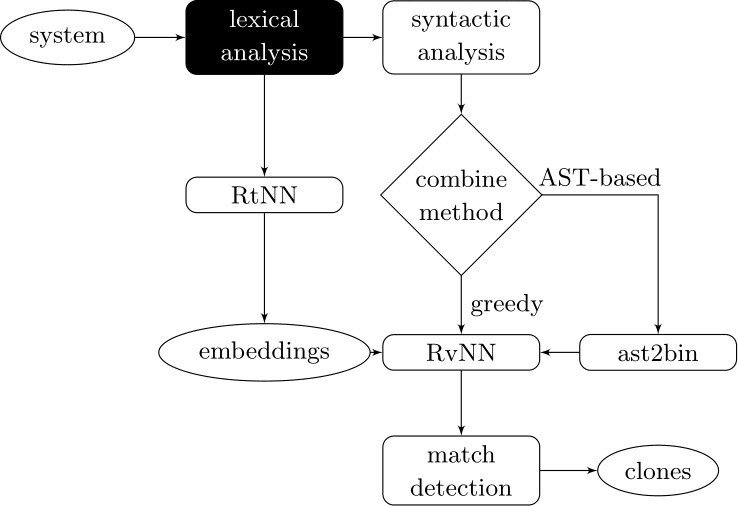
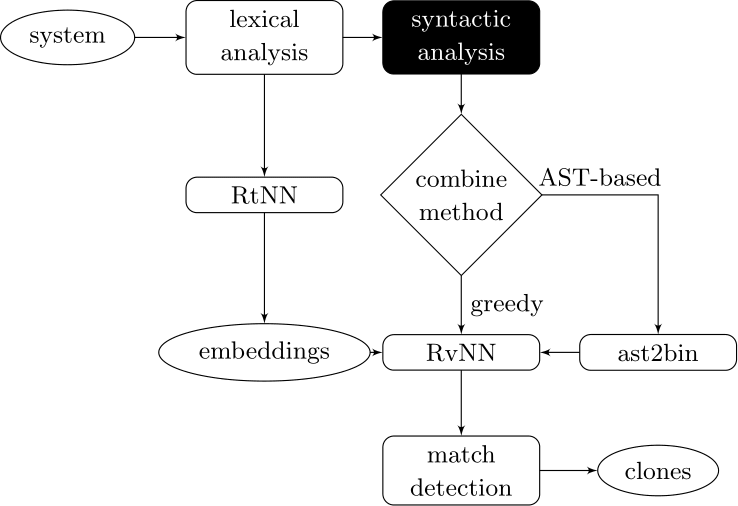
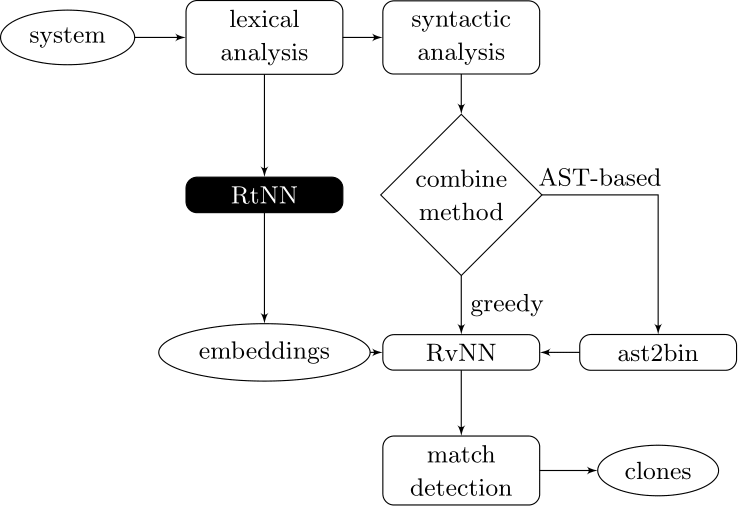
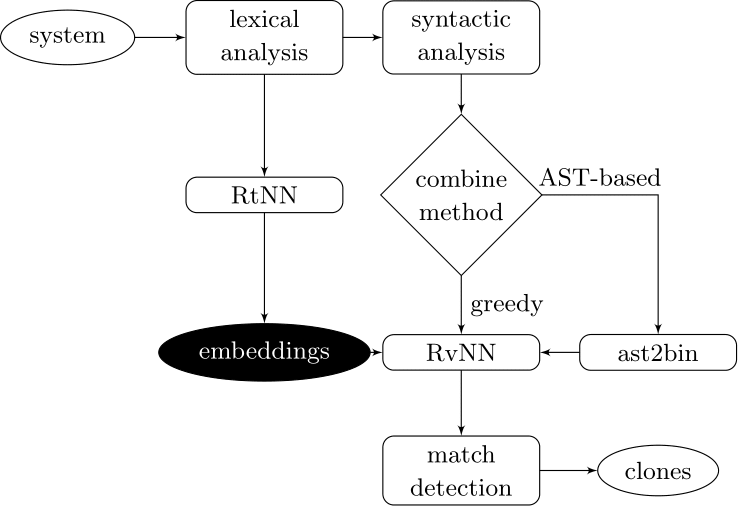
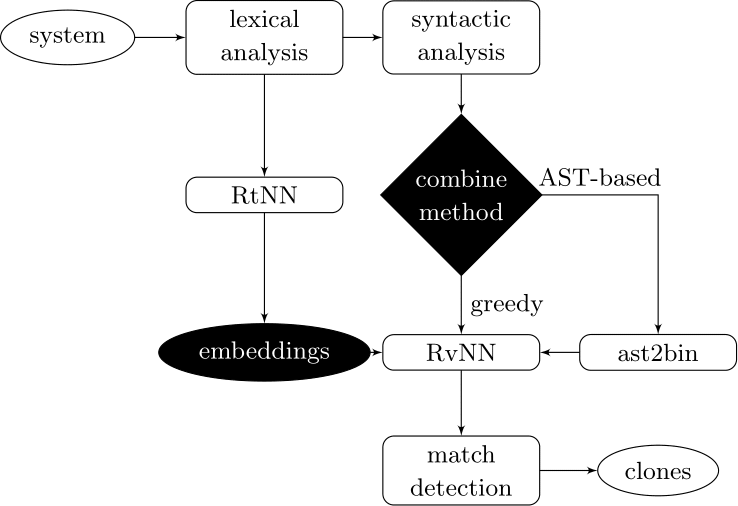
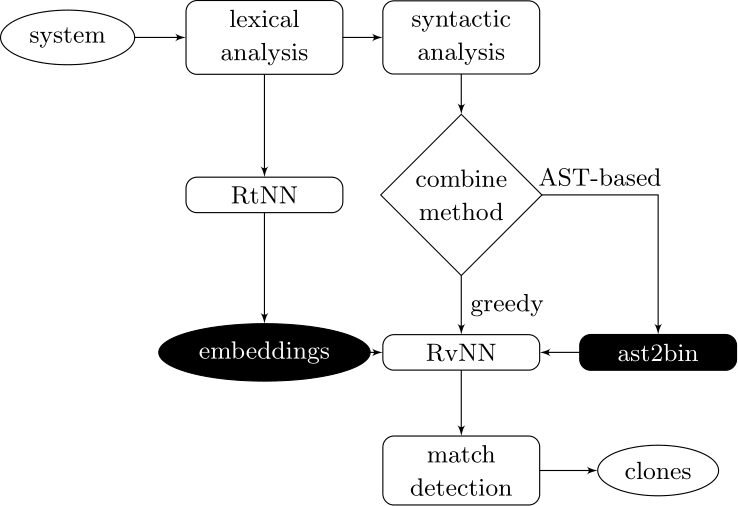
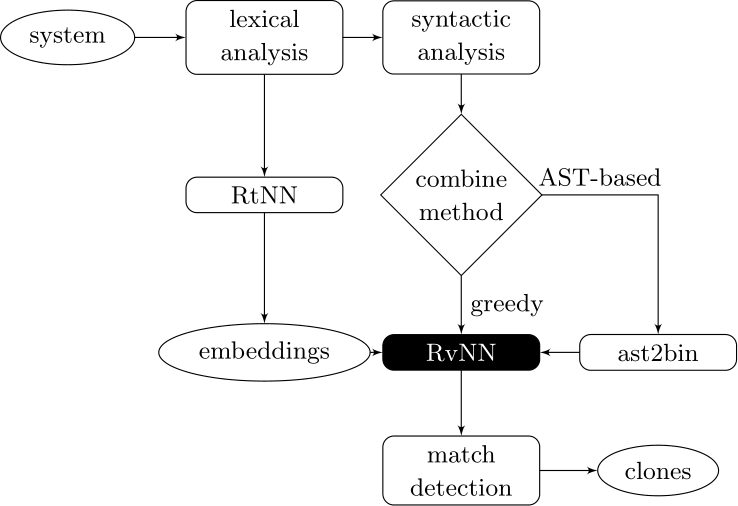
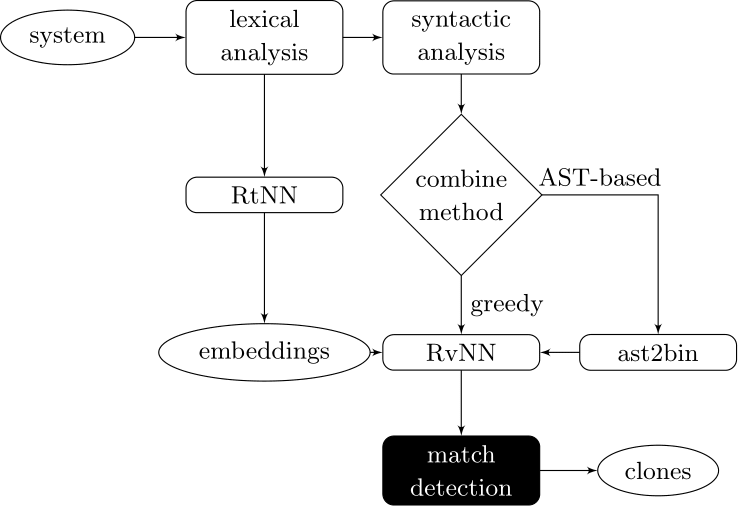
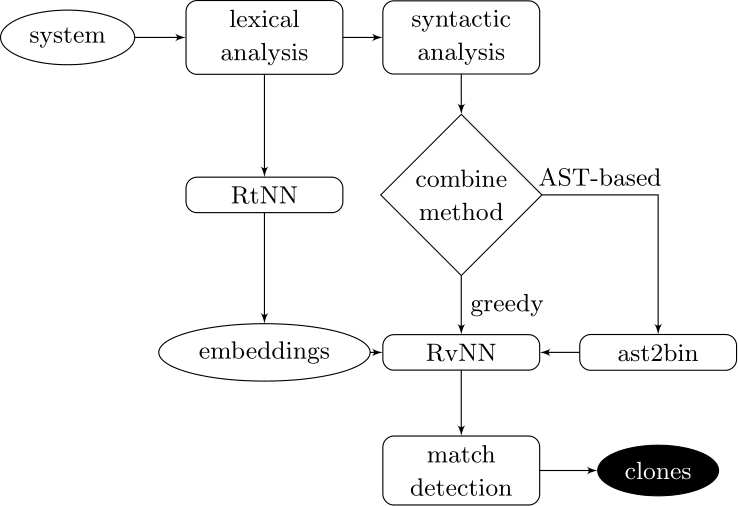
Deep Learning Code at the Lexical Level
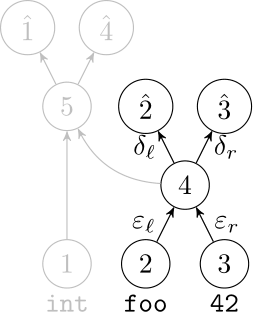
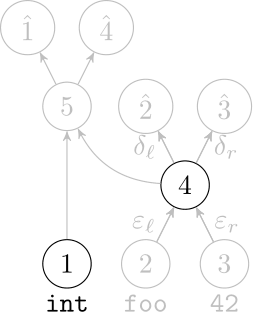
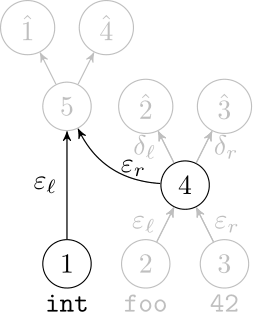
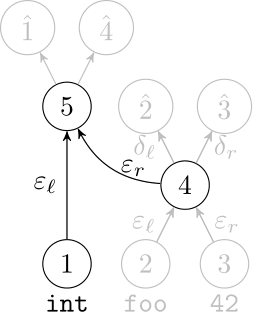
We use a recurrent neural network to map terms to embeddings
y(i)=g(\gamma f({\color{red}\alpha} t(i)+\beta z(i-1)))
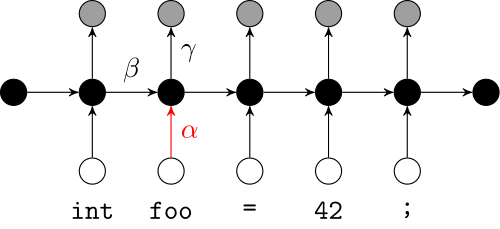
What we would like to have is not only embeddings for terms but also embeddings for fragments
\color{white}{y(i)=g(\gamma f({\alpha}} t(i)\color{white}{+\beta z(i-1)))}
y(i)=g(\gamma f({\color{red}\alpha} t(i)+\beta z(i-1)))
\color{white}{y(i)=g(\gamma f(}{\color{red}\alpha} t(i)\color{white}{+\beta z(i-1)))}
\color{white}{y(i)=g(\gamma f(}{\color{red}\alpha} t(i)\color{white}{+\beta} z(i-1)\color{white}{))}
\color{white}{y(i)=g(\gamma f(}{\color{red}\alpha} t(i)\color{white}{+}\beta z(i-1)\color{white}{))}
\color{white}{y(i)=g(\gamma f(}{\color{red}\alpha} t(i)+\beta z(i-1)\color{white}{))}
\color{white}{y(i)=g(\gamma} f({\color{red}\alpha} t(i)+\beta z(i-1))\color{white}{)}
\color{white}{y(i)=g(}\gamma f({\color{red}\alpha} t(i)+\beta z(i-1))\color{white}{)}
\color{white}{y(i)=}g(\gamma f({\color{red}\alpha} t(i)+\beta z(i-1)))
Recursive Autoencoders
Generalize recurrent neural networks by modeling structures
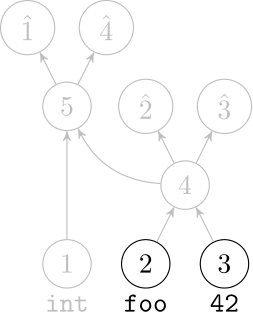
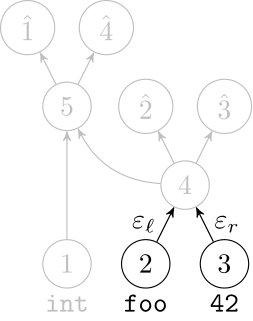
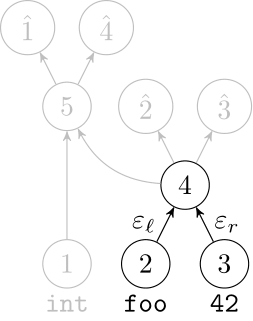
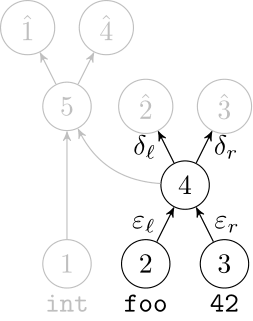
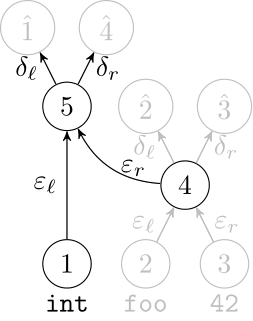
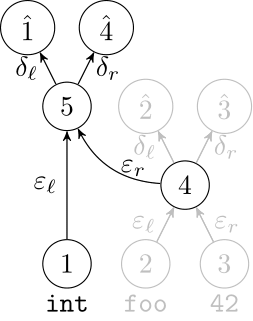
Deep Learning Code at the Syntax Level
We use a recursive autoencoder to encode sequences of embeddings
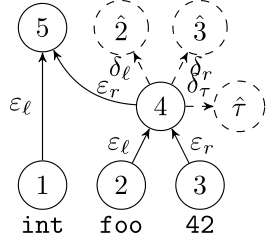
y=[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r] f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r]))
AST-based encoding
Greedy encoding
\color{white}{y=[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r] f([{\varepsilon_{\ell}},{\varepsilon_{r}}]} [x_{\ell};x_r]\color{white}{))}
y=[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r] f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r]))
\color{white}{y=[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r] f(}[\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r]\color{white}{))}
\color{white}{y=[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r]} f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r])\color{white}{)}
\color{white}{y=[\hat{x_{\ell}};\hat{x_{r}}]=g(}[\delta_{\ell};\delta_r] f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r])\color{white}{)}
\color{white}{y=[\hat{x_{\ell}};\hat{x_{r}}]=}g([\delta_{\ell};\delta_r] f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r]))
\color{white}{y=}[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r] f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r]))
| System | Files | LOC | Tokens | Vocab. |
| ANTLR 4 | 514 | 104,225 | 701,807 | 5,826 |
| Apache Ant 1.9.6 | 1,218 | 136,352 | 888,424 | 16,029 |
| ArgoUML 0.34 | 1,908 | 177,493 | 1,172,058 | 17,205 |
| CAROL 2.0.5 | 184 | 12,022 | 80,947 | 2,210 |
| dnsjava 2.0.0 | 196 | 24,660 | 169,219 | 3,012 |
| Hibernate 2 | 555 | 51,499 | 365,256 | 5,850 |
| JDK 1.4.2 | 4,129 | 562,120 | 3,512,807 | 45,107 |
| JHotDraw 6 | 984 | 58,130 | 377,652 | 4,803 |
Empirical Study
| System | Files | LOC | Tokens | Vocab. |
| ANTLR 4 | 514 | 104,225 | 701,807 | 5,826 |
| Apache Ant 1.9.6 | 1,218 | 136,352 | 888,424 | 16,029 |
| ArgoUML 0.34 | 1,908 | 177,493 | 1,172,058 | 17,205 |
| CAROL 2.0.5 | 184 | 12,022 | 80,947 | 2,210 |
| dnsjava 2.0.0 | 196 | 24,660 | 169,219 | 3,012 |
| Hibernate 2 | 555 | 51,499 | 365,256 | 5,850 |
| JDK 1.4.2 | 4,129 | 562,120 | 3,512,807 | 45,107 |
| JHotDraw 6 | 984 | 58,130 | 377,652 | 4,803 |
| System | Files | LOC | Tokens | Vocab. |
| ANTLR 4 | 514 | 104,225 | 701,807 | 5,826 |
| Apache Ant 1.9.6 | 1,218 | 136,352 | 888,424 | 16,029 |
| ArgoUML 0.34 | 1,908 | 177,493 | 1,172,058 | 17,205 |
| CAROL 2.0.5 | 184 | 12,022 | 80,947 | 2,210 |
| dnsjava 2.0.0 | 196 | 24,660 | 169,219 | 3,012 |
| Hibernate 2 | 555 | 51,499 | 365,256 | 5,850 |
| JDK 1.4.2 | 4,129 | 562,120 | 3,512,807 | 45,107 |
| JHotDraw 6 | 984 | 58,130 | 377,652 | 4,803 |
Empirical Validation
- Research questions
- RQ3. Are our source code representations suitable for detecting fragments that are similar with respect to a clone type?
- RQ4. Is there evidence that our learning-based approach is capable of recognizing clones that are undetected or suboptimally reported by a structure-oriented technique?
- Estimated precision at different levels of granularity to answer RQ3; synthesized qualitative data across two techniques for RQ4
- Data collection procedure
- ANTLR, RNNLM Toolkit, Eclipse JDT
- Generated both file- and method-level corpora
- Analysis procedure
- Two Ph.D students evaluated file- and method-level samples
- We adapted a taxonomy of editing scenarios [Roy'09]
Empirical Results
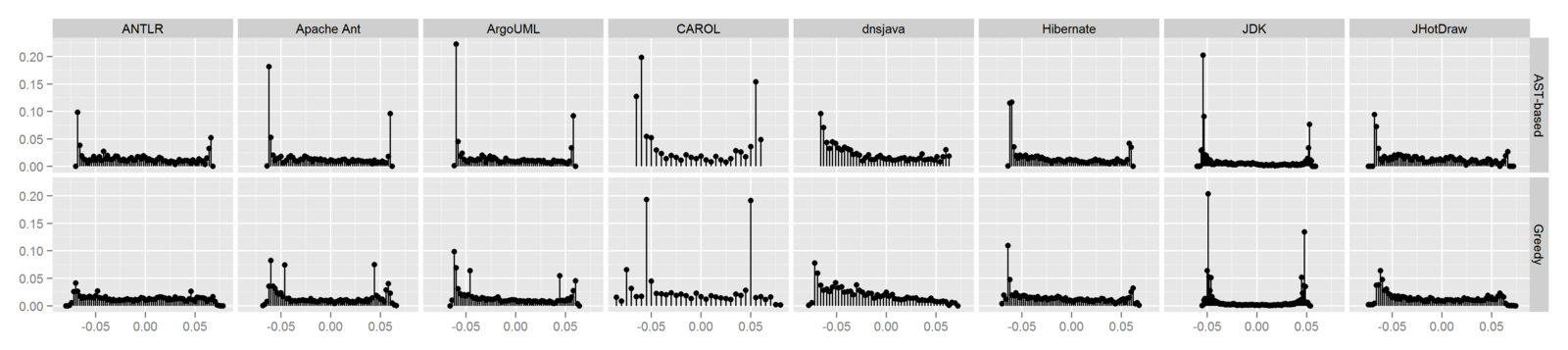
- RQ3. Are our source code representations suitable for detecting fragments that are similar with respect to a clone type?
- Sampled 398 from 1,500+ file pairs, 480 from 60,000+ method pairs
- 93% of file- and method-level candidates evaluated to be true positives
- RQ4. Is there evidence that our compositional, learning-based approach is capable of recognizing clones that are undetected or suboptimally reported by a traditional, structure-oriented technique?
- We selected the prominent structure-oriented tool Deckard [Jiang'07]
- Suboptimally reported: jhotdraw0
- Undetected: hibernate0
- More examples in our online appendix
Dissertation
-
Toward deep learning software repositories
-
Deep learning code fragments for code clone detection
-
Sorting and transforming program repair ingredients via deep learning
Automated Program Repair
Transformation of an unacceptable behavior of a program execution into an acceptable one according to a specification.
Our learning-based approach couples learners to front-end compiler stages
Automated program repair is hard.
Automated program repair is really hard.
Background
Generate-and-validate repair techniques (generally) search for statement-level modifications and validate patches against the test suit
Correct-by-construction repair techniques use program analysis and program synthesis to construct code with particular properties
public final class MathUtils {
public static boolean equals(double x, double y) {
return (Double.isNaN(x) && Double.isNaN(y)) || x == y;
}
}public final class MathUtils {
public static boolean equals(double x, double y) {
return equals(x, y, 1);
}
}if (max_range_endpoint < eol_range_start)
max_range_endpoint = eol_range_start;
printable_field = xzalloc(max_range_endpoint/CHAR_BIT+1);
if (max_range_endpoint < eol_range_start)
max_range_endpoint = eol_range_start;
if (1)
printable_field = xzalloc(max_range_endpoint/CHAR_BIT+1);if (AAA)
max_range_endpoint = BBB;
if (CCC)
printable_field = xzalloc(max_range_endpoint/CHAR_BIT+1);if (0)
max_range_endpoint = eol_range_start;
if (!(max_range_endpoint == 0))
printable_field = xzalloc(max_range_endpoint/CHAR_BIT+1);S. Mechtaev, J. Yi, and A. Roychoudhury, Angelix: Scalable Multiline Program Patch Synthesis via Symbolic Analysis, ICSE 2016.
The Plastic Surgery Hypothesis
Large programs contain the seeds of their own repair [Martinez'14,Barr'14]
- Line-level. Most redundancy is localized in the same file [Martinez'14]
- Token-level. Repairs need never invent a new token [Martinez'14]
On the problem of navigating complex fix spaces, we use code similarities to intelligently select and adapt program repair ingredients
Technical Approach
-
Recognition
-
Learning
-
Repair
Recognition
-
Build source code model
-
Build corpora
-
Normalize corpora
package org.apache.commons.math.util;
import java.math.BigDecimal;
import java.math.BigInteger;
import java.util.Arrays;
import org.apache.commons.math.MathRuntimeException;
import org.apache.commons.math.exception.util.Localizable;
import org.apache.commons.math.exception.util.LocalizedFormats;
import org.apache.commons.math.exception.NonMonotonousSequenceException;
/**
* Some useful additions to the built-in functions in {@link Math}.
* @version $Revision$ $Date$
*/
public final class MathUtils {
/** Smallest positive number such that 1 - EPSILON is not numerically equal to 1. */
public static final double EPSILON = 0x1.0p-53;
/** Safe minimum, such that 1 / SAFE_MIN does not overflow.
* <p>In IEEE 754 arithmetic, this is also the smallest normalized
* number 2<sup>-1022</sup>.</p>
*/
public static final double SAFE_MIN = 0x1.0p-1022;MathUtils.java
Recognition
-
Build source code model
-
Build corpora
-
Normalize corpora
org apache commons math ode events public EventHandler int STOP 0 int RESET_STATE 1 int RESET_DERIVATIVES 2
org apache commons math ode nonstiff public MidpointIntegrator RungeKuttaIntegrator private static final double STATIC_C
org apache commons math distribution org apache commons math MathException public ContinuousDistribution Distribution
org apache commons math distribution org apache commons math MathException public HasDensity P double density P x
org apache commons math genetics java util List public PermutationChromosome T List T decode List T sequence
org apache commons math optimization java io Serializable public GoalType Serializable MAXIMIZE MINIMIZE
org apache commons math linear public AnyMatrix boolean isSquare int getRowDimension int getColumnDimension
org apache commons math stat ranking public TiesStrategy SEQUENTIAL MINIMUM MAXIMUM AVERAGE RANDOM
org apache commons math genetics public CrossoverPolicy ChromosomePair crossover Chromosome first Chromosome second
org apache commons math distribution public DiscreteDistribution Distribution double probability double x
org apache commons math stat ranking public NaNStrategy MINIMAL MAXIMAL REMOVED FIXED
org apache commons math stat ranking public RankingAlgorithm double rank double data
org apache commons math genetics public SelectionPolicy ChromosomePair select Population population
org apache commons math genetics public StoppingCondition boolean isSatisfied Population population
org apache commons math genetics public MutationPolicy Chromosome mutate Chromosome original
org apache commons math public Field T T getZero T getOne
org apache commons math optimization general public ConjugateGradientFormula FLETCHER_REEVES POLAK_RIBIERE
org apache commons math random public RandomVectorGenerator double nextVector
org apache commons math random public NormalizedRandomGenerator double nextNormalizedDouble
org apache commons math genetics public Fitness double fitnessFile-level corpus
Recognition
-
Build source code model
-
Build corpora
-
Normalize corpora
org apache commons math ode events public EventHandler int STOP <INT> int RESET_STATE <INT> int RESET_DERIVATIVES <INT>
org apache commons math ode nonstiff public MidpointIntegrator RungeKuttaIntegrator private static final double STATIC_C
org apache commons math distribution org apache commons math MathException public ContinuousDistribution Distribution
org apache commons math distribution org apache commons math MathException public HasDensity P double density P x
org apache commons math genetics java util List public PermutationChromosome T List T decode List T sequence
org apache commons math optimization java io Serializable public GoalType Serializable MAXIMIZE MINIMIZE
org apache commons math linear public AnyMatrix boolean isSquare int getRowDimension int getColumnDimension
org apache commons math stat ranking public TiesStrategy SEQUENTIAL MINIMUM MAXIMUM AVERAGE RANDOM
org apache commons math genetics public CrossoverPolicy ChromosomePair crossover Chromosome first Chromosome second
org apache commons math distribution public DiscreteDistribution Distribution double probability double x
org apache commons math stat ranking public NaNStrategy MINIMAL MAXIMAL REMOVED FIXED
org apache commons math stat ranking public RankingAlgorithm double rank double data
org apache commons math genetics public SelectionPolicy ChromosomePair select Population population
org apache commons math genetics public StoppingCondition boolean isSatisfied Population population
org apache commons math genetics public MutationPolicy Chromosome mutate Chromosome original
org apache commons math public Field T T getZero T getOne
org apache commons math optimization general public ConjugateGradientFormula FLETCHER_REEVES POLAK_RIBIERE
org apache commons math random public RandomVectorGenerator double nextVector
org apache commons math random public NormalizedRandomGenerator double nextNormalizedDouble
org apache commons math genetics public Fitness double fitnessNormalized file-level corpus
Learning
-
Train language model
-
Encode fragments
-
Cluster identifiers
Neural network language model
Learning
-
Train language model
-
Encode fragments
-
Cluster identifiers
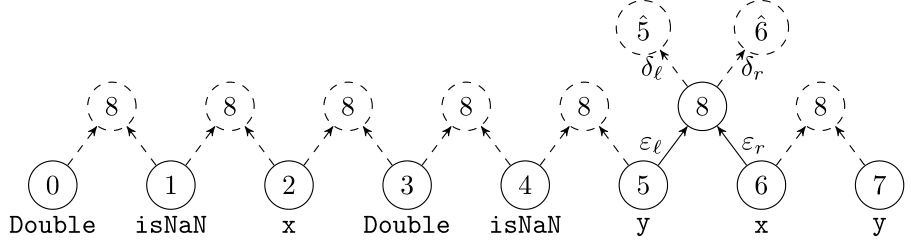
return (Double.isNaN(x) && Double.isNaN(y)) || x == y;Learning
-
Train language model
-
Encode fragments
-
Cluster identifiers
Math-63 Identifiers' Embeddings
vecAbsoluteTolerance
vecRelativeTolerance
maxStep
minStep
nSteps
scalRelativeTolerance
scalAbsoluteTolerance
blockColumn
blockEndRow
blockStartColumn
columnsShift
iRow
jColumn
blockRow
absAsinh
cosaa
defaultMaximalIterationCount
tolerance
y3
x3
cosab
sinb
absAtanh
dstWidth
srcEndRow
pBlock
srcBlock
srcWidth
absoluteAccuracy
functionValueAccuracy
yMin
relativeAccuracy
oldt
oldx
oldDelta
delta
tol1
steadyStateThreshold
maxDenominator
upperBounds
SAFE_MIN
MIN_VALUE
stop
NEGATIVE_INFINITY
DEFAULT_EPSILON
accuracy
maxAbsoluteValue
tol
stepEnd
dstPos
srcPos
mIndex
srcRow
srcStartRow
cosa
sina
cotanFlag
cosb
lastTime
blockEndColumn
blockStartRow
nextGeneration
population
populationLimit
rln10b
rln10a
absSinh
endIndex
rowsShift
maxColSum
minRatioPositions
errfac
stopTime
eps
iterationCount
chromosomes
maxDegree
outBlock
totalEvaluations
Repair
-
Core repair loop
-
Sorting ingredients
-
Transforming ingredients
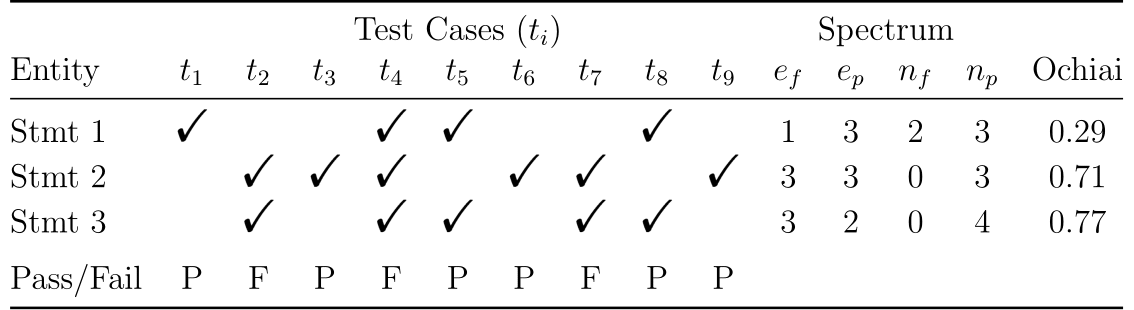
Stmt 1
Stmt 2
Stmt 3
Pass/Fail
Entity
T
1
T
2
T
3
T
4
T
5
P
F
P
F
P
Test Cases
Fault Localization
Repair Operators
- InsertOp
- RemoveOp
- ReplaceOp
Repair
-
Core repair loop
-
Sorting ingredients
-
Transforming ingredients
MathUtils::equals(double, double)
public final class MathUtils {
/** Safe minimum, such that 1 / SAFE_MIN does not overflow.
* <p>In IEEE 754 arithmetic, this is also the smallest normalized
* number 2<sup>-1022</sup>.</p>
*/
public static final double SAFE_MIN = 0x1.0p-1022;
/**
* Returns true iff they are equal as defined by
* {@link #equals(double,double,int) equals(x, y, 1)}.
*
* @param x first value
* @param y second value
* @return {@code true} if the values are equal.
*/
public static boolean equals(double x, double y) {
return (Double.isNaN(x) && Double.isNaN(y)) || x == y;
}
public static boolean equals(double x, double y, double eps) {
return equals(x, y, 1) || FastMath.abs(y - x) <= eps;
}
}Repair
-
Core repair loop
-
Sorting ingredients
-
Transforming ingredients
DeepRepair Patch
--- a/src/main/java/org/apache/commons/math/util/MathUtils.java
+++ b/src/main/java/org/apache/commons/math/util/MathUtils.java
@@ -181,7 +181,7 @@
}
public static boolean equals(double x, double y) {
- return ((Double.isNaN(x)) && (Double.isNaN(y))) || (x == y);
+ return (equals(x, y, 1)) || ((FastMath.abs((y - x))) <= (SAFE_MIN));
}
public static boolean equalsIncludingNaN(double x, double y) {Human-written Patch
--- a/src/main/java/org/apache/commons/math/util/MathUtils.java
+++ b/src/main/java/org/apache/commons/math/util/MathUtils.java
@@ -414,7 +414,7 @@ public final class MathUtils {
* @return {@code true} if the values are equal.
*/
public static boolean equals(double x, double y) {
+ return equals(x, y, 1);
- return (Double.isNaN(x) && Double.isNaN(y)) || x == y;
}Empirical Validation
- Research questions
- RQ5. Do code similarities based on deep learning improve fix space navigation as compared to jGenProg?
- RQ6. Does ingredient transformation using embeddings based on deep learning effectively transform repair ingredients as compared to jGenProg?
- RQ7. Does DeepRepair, our learning-based approach that uses code similarities and transforms repair ingredients, improve fix space navigation as compared to jGenProg?
- RQ8. Does DeepRepair generate higher quality patches?
- Data collection procedure
- Analysis procedure
Data Collection Procedure
- Recognition
- Spoon
- File-, type-, and executable-level corpora
- Normalized chars, floats, ints, and strings
- Learning
- word2vec
- Recursive autoencoders
- k-means and simulated annealing
- Repair
- Defects4J: 6 Java projects including 374 buggy program revisions
- GZoltar (Ochiai); Astor 3-hour evolutionary loop
- 20,196 trials (374 revisions, 6 strategies, 3 scopes, 3 seeds)
- 2,616 days (62,784 hours) of computation time
- SciClone :sparkles:
Analysis Procedure
- Quantitative (Effectiveness)
- Compare # test-adequate patches using Wilcoxon with Bonferroni
- Compute difference between sets of test-adequate patches
- Compare # attempts to generate test-adequate patches using Mann-Whitney with Bonferroni
- Compute # attempts to generate a compilable ingredient
- Qualitative (Correctness)
- Correctness
- Confidence
- Readability
Empirical Results
- DeepRepair finds compilable ingredients faster than jGenProg
- Neither yields test-adequate patches in fewer attempts (on average)
- Nor finds significantly more patches than jGenProg
- Notable differences between DeepRepair and jGenProg patches
- No significant difference in quality
Conclusion
- Dissertation
- Deep Learning Software Repositories, NSF SHF: Small
- Toward Deep Learning Software Repositories, MSR'15
- Deep Learning Fragments for Clone Detection, ASE'16
- Sorting and Transforming Repair Ingredients, Under Review
- Generating Reproducible and Replayable Bug Reports, ICPC'15
- Mining Android App Usages for Generating Scenarios, MSR'15
- Main contributions
- Introduce deep learning to software engineering
- Empirical study validating effectiveness of deep learning
- Introduce learning-based paradigm for code clone detection
- First approach ever that transforms program repair ingredients
- Future work
Deep Learning Software Repositories
Improve representation power
Deep Learning Software Repositories
Martin White advised by Denys Poshyvanyk
Backups
ML
SE
Dissertation
-
Toward deep learning software repositories
-
Deep learning code fragments for code clone detection
-
Sorting and transforming program repair ingredients via deep learning
Deep Learning Software Repositories, NSF SHF: Small.
M. White, C. Vendome, M. Linares-Vasquez, and D. Poshyvanyk. Toward Deep Learning Software Repositories. Proceedings of the 12th Working Conference on Mining Software Repositories (MSR'15).
M. White. Deep Representations for Software Engineering. Proceedings of the 37th International Conference on Software Engineering (ICSE'15) - Volume 2.
-
C. Corley, K. Damevski, N. Kraft, Exploring the use of deep learning for feature location, ICSME'15
-
A. Lam, A. Nguyen, H. Nguyen, T. Nguyen, Combining deep learning with information retrieval to localize buggy files for bug reports, ASE'15
-
S. Wang, T. Liu, L. Tan, Automatically learning semantic features for defect prediction, ICSE'16
-
C. Alexandru, Guided code synthesis using deep neural networks, FSE'16
-
H. Dam, T. Tran, J. Grundy, A. Ghose, DeepSoft: A vision for a deep model of software, FSE'16
-
X. Gu, H. Zhang, D. Zhang, S. Kim, Deep API learning, FSE'16
-
C. Chen, Z. Xing, SimilarTech: Automatically recommend analogical libraries across different programming languages, ASE'16
-
G. Chen, C. Chen, Z. Xing, B. Xu, Learning a dual-language vector space for domain-specific cross-lingual question retrieval, ASE'16
-
M. White, M. Tufano, C. Vendome, D. Poshyvanyk, Deep learning code fragments for code clone detection, ASE'16
-
B. Xu, D. Ye, Z. Xing, X. Xia, G. Chen, S. Li, Predicting semantically linkable knowledge in developer online forums via convolutional neural network, ASE'16
-
C. Alexandru, S. Panichella, H. Gall, Replicating parser behavior using neural machine translation, ICPC'17
-
A. Lam, A. Nguyen, H. Nguyen, T. Nguyen, Bug localization with combination of deep learning and information retrieval, ICPC'17
-
J. Guo, J. Cheng, J. Cleland-Huang, Semantically enhanced software traceability using deep learning techniques, ICSE'17
- P. Liu, X. Zhang, M. Pistoia, Y. Zheng, M. Marques, L. Zeng, Automatic text input generation for mobile testing, ICSE'17
-
A. Sankaran, R. Aralikatte, S. Mani, S. Khare, N. Panwar, N. Gantayat, DARVIZ: Deep abstract representation, visualization, and verification of deep learning models, ICSE-NIER'17
-
J. Wang, Q. Cui, S. Wang, Q. Wang, Domain adaptation for test report classification in crowdsourced testing, ICSE-SEIP'17
-
X. Liu, X. Lu, H. Li, T. Xie, Q. Mei, H. Mei, F. Feng, Understanding diverse usage patterns from large-scale appstore-service profiles, TSE'17
-
M. Choetkiertikul, H. Dam, T. Tran, A. Ghose, Predicting the delay of issues with due dates in software projects, EMSE'17
statistical language models are probability distributions over sentences
statistical language models are probability distributions over sentences
statistical language models are probability distributions over sentences
statistical language models are probability distributions over sentences
statistical language models are probability distributions over sentences
s
p(s)
p(w_1,w_2,\ldots,w_m)
p(w_1,w_2,\ldots,w_m)=p(w_1)p(w_2|w_1)\cdots p(w_m|w_1,\ldots,w_{m-1})
p(\text{John read a book})
\text{John read a book}
p(\text{John},\text{read},\text{a},\text{book})
p(\text{John},\text{read},\text{a},\text{book})=p(\text{John})p(\text{read}|\text{John})\cdots p(\text{book}|\text{John},\text{read},\text{a})
p(w_1,w_2,\ldots,w_m)=\prod_1^mp(w_i|w_1,\ldots,w_{i-1})
p(w_1,w_2,\ldots,w_m)=\prod_1^mp(w_i|w_1,\ldots,w_{i-1})\approx \prod_1^mp(w_i|w_{i-n+1},\ldots,w_{i-1})
p(w_1,w_2,\ldots,w_m)\approx \prod_1^mp(w_i|w_{i-n+1},\ldots,w_{i-1})
p(w_1,w_2,\ldots,w_m)\approx \prod_1^mp(w_i|w_{i-n+1},\ldots,w_{i-1})\approx \prod_1^m\frac{c(w_{i-1}w_i)}{c(w_{i-1})}
p(w_i|w_{i-1})=\frac{c(w_{i-1}w_i)+1}{c(w_{i-1})+|\mathcal{V}|}
p(\text{John},\text{read},\text{a},\text{book})=\frac{1+1}{3+11}\times\frac{1+1}{1+11}\times\frac{2+1}{3+11}\times\frac{1+1}{2+11}\times\frac{1+1}{2+11}\approx 0.0001
p(\text{Cher},\text{read},\text{a},\text{book})=\frac{0+1}{3+11}\times\frac{0+1}{1+11}\times\frac{2+1}{3+11}\times\frac{1+1}{2+11}\times\frac{1+1}{2+11}\approx 0.00003
Smoothing
Smoothing adjusts MLEs, e.g., hallucinate data
Reconsider the example using this new distribution
Back-off and interpolation are two methods for redistributing mass
p_B(w_i|w_{i-n+1}^{i-1\color{white}{+n}})=
p_I(w_i|w_{i-n+1}^{i-1\color{white}{+n}})=
\delta(w_i|w_{i-n+1}^{i-1\color{white}{+n}})+\beta(w_{i-n+1}^{i-1\color{white}{+n}})p_I(w_i|w_{i-n+2}^{i-1\color{white}{+n}})
\delta(w_i|w_{i-n+1}^{i-1\color{white}{+n}})
\beta(w_{i-n+1}^{i-1\color{white}{+n}})p_B(w_i|w_{i-n+2}^{i-1\color{white}{+n}})
c(w_{i-n+1}^{i-1\color{white}{+n}})>k
\text{otherwise}
p(w_i|w_{i-1})=\frac{c(w_{i-1}w_i)}{c(w_{i-1})}
Intrinsic Evaluation - Perplexity
toward deep learning software deep
toward deep learning software learning
toward deep learning software expressive
toward deep learning software represent
toward deep learning software neural
toward deep learning software model
toward deep learning software artifacts
toward deep learning software language
toward deep learning software repositories
toward deep learning software engineering
toward deep learning software network
toward deep learning software context
toward deep learning software recurrent
toward deep learning software semantics
toward deep learning software probability
toward deep learning software deep
toward deep learning software learning
toward deep learning software expressive
toward deep learning software represent
toward deep learning software neural
toward deep learning software model
toward deep learning software artifacts
toward deep learning software language
toward deep learning software repositories
toward deep learning software engineering
toward deep learning software network
toward deep learning software context
toward deep learning software recurrent
toward deep learning software semantics
toward deep learning software probability
The average branching factor is a general proxy for quality
\data\
ngram 1=18
ngram 2=32
ngram 3=34
\1-grams:
-1.092146 </s>
-99 <s> -0.157377
-1.092146 ( -0.454680
-1.304235 ) -0.120574
-1.304235 + -0.120574
-1.304235 - -0.120574
-1.304235 1 -0.120574
-1.092146 2 -0.830539
-1.092146 ; -0.830539
-1.304235 < -0.120574
-1.304235 else -0.120574
-1.304235 fib
-1.304235 if -0.120574
-1.092146 int -0.120574
-1.304235 n -0.120574
-1.304235 return -0.120574
-1.304235 {
-1.304235 } -0.120574
\2-grams:
-1.188102 <s> if -0.076840
-1.062487 <s> int -0.076840
-0.606226 <s> return -0.076840
-1.188102 <s> { -0.076840
-1.461612 <s> } -0.024134
-0.961783 ( int -0.076840
-0.232397 ( n -0.024134
-0.914066 ) </s>
-1.007861 ) + -0.076840
-0.914066 ) ; -0.076840
-1.007861 ) { -0.076840
-0.552804 + fib -0.076840
-0.799116 - 1 -0.076840
-0.738769 - 2 -0.076840
-0.552804 1 ) -0.076840
-0.065701 2 ) -0.076840
-0.063375 ; </s>
-0.517557 < 2 -0.076840
-0.552804 else { -0.076840
-1.092146 fib ( -0.024134
-0.517557 if ( -0.076840
-0.799116 int fib -0.076840
-0.799116 int n -0.076840
-1.007861 n ) -0.076840
-1.007861 n - -0.076840
-0.914066 n ; -0.076840
-1.007861 n < -0.076840
-0.799116 return fib -0.076840
-0.799116 return n -0.076840
-1.092146 { </s>
-0.738769 } </s>
-0.799116 } else -0.076840
\3-grams:
-0.380268 <s> if (
-0.529852 <s> int fib
-0.669302 <s> return fib
-0.669302 <s> return n
-0.638407 <s> { </s>
-0.762903 <s> } </s>
-0.689770 <s> } else
-0.529852 ( int n
-1.031994 ( n -
-0.832825 ( n <
-0.401453 ) + fib
-0.052449 ) ; </s>
-0.638407 ) { </s>
-0.638407 + fib (
-0.401453 - 1 )
-0.054348 - 2 )
-0.611822 1 ) +
-0.737081 2 ) ;
-0.786849 2 ) {
-0.054348 < 2 )
-0.638407 else { </s>
-0.803133 fib ( int
-0.256530 fib ( n
-0.185218 if ( n
-0.638407 int fib (
-0.611822 int n )
-0.577938 n ) </s>
-0.669302 n - 1
-0.630830 n - 2
-0.052449 n ; </s>
-0.380268 n < 2
-0.638407 return fib (
-0.577938 return n ;
-0.401453 } else {
\end\ARPA Language Model File
Expressiveness. Context. Semantics.
Improving capacity improves representation power. Improving representation power may improve the performance at real tasks.
Intrinsic Evaluation: Perplexity (PP)
- Baseline
- Varied n-gram order from two to nine
- 5-gram back-off (PP = 19.8911)
- Interp. 8-gram (PP = 19.9815)
- Interp. 8-gram w/ 100-token unigram cache (PP = 12.2209)
- Varied n-gram order from two to nine
- Static networks
- Varied hidden layer size and number of levels of context
- 300, 20 (PP = 10.1960)
- 400, 5 (PP = 10.1721)
- Committees of models (PP = 9.5326)
- Varied hidden layer size and number of levels of context
- Dynamic networks
- Online models (PP = 3.5958)
Dissertation
-
Toward deep learning software repositories
-
Deep learning code fragments for code clone detection
-
Sorting and transforming program repair ingredients via deep learning
M. White, M. Tufano, C. Vendome, and Denys Poshyvanyk. Deep Learning Code Fragments for Code Clone Detection. Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering (ASE'16).
Code Clone Detection
- An important problem for software maintenance and evolution
- Detecting library candidates
- Aiding program comprehension
- Detecting malicious software
- Detecting plagiarism or copyright infringement
- Detecting context-based inconsistencies
- Searching for refactoring opportunities
- Different techniques for detecting code clones
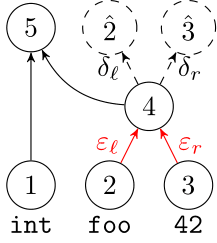
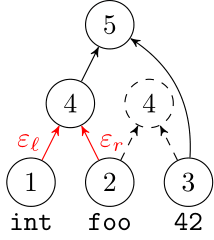
ast2bin
- ASTs have any number of levels comprising nodes with arbitrary degree
- ast2bin fixes the size of the input, and recursion models different levels

Case I
Case II
Case II
Use a grammar to handle nodes with degree greater than two
Case I
Establish a precedence to handle nodes with degree one
- TypeDeclaration
- MethodDeclaration
- OtherType
- ExpressionStatement
- QualifiedName
- SimpleType
- SimpleName
- ParenthesizedExpression
- Block
- ArtificialType
Empirical Results - RQ3
- RQ3. Are our source code representations suitable for detecting fragments that are similar with respect to a clone type?
- Sampled 398 from 1,500+ file pairs, 480 from 60,000+ method pairs
| System | AST-based | Greedy | AST-based | Greedy |
| ANTLR | 97 | 100 | 100 | 100 |
| Apache Ant | 92 | 93 | 100 | 100 |
| ArgoUML | 90 | 100 | 100 | 100 |
| CAROL | 100 | 100 | 100 | 100 |
| dnsjava | 47 | 100 | 73 | 87 |
| Hibernate | 100 | 100 | 53 | 70 |
| JDK | 90 | 100 | 100 | 100 |
| JHotDraw | 100 | 100 | 100 | 100 |
File-level
Method-level
Precision Results (%)
Empirical Results - RQ4
- RQ4. Is there evidence that our compositional, learning-based approach is capable of recognizing clones that are undetected or suboptimally reported by a traditional, structure-oriented technique?
- We selected the prominent structure-oriented tool Deckard [Jiang'07]
- Suboptimally reported: jhotdraw0
- Undetected: hibernate0
- More examples in our online appendix
Future Work: Match Detection at Scale
- (Pre-)activations
- Initialize using (small) random weights
- Small Hamming balls around a given fragment for other fragments in the repository
- Binary codes for fast search and less memory
Future Work: Type Prediction
- Learning framework is extensible, e.g., nonterminals' types can influence the training procedure
- The types are automatically imputed by the compiler
- Everything remains entirely unsupervised
Dissertation
-
Toward deep learning software repositories
-
Deep learning code fragments for code clone detection
-
Sorting and transforming program repair ingredients via deep learning
M. White, M. Tufano, M. Martinez, M. Monperrus, and D. Poshyvanyk. Sorting and Transforming Program Repair Ingredients via Deep Learning Code Similarities. Under Review.
High-level Plan
- Deep Learning Code Fragments for Automated Program Repair
- Synthesized in terms of the ingredients of a repair system
- What aspect do we plan to attack? Informing search over fix spaces
- What family of repair techniques do we plan to use? Behavioral repair
- What language do we plan to use? Java
- What class of bugs do we plan to support? WIP
- What oracles do we plan to use? Test cases/suite
- What tools do we plan to use? Astor
- How do we plan to evaluate the approach? WIP
- Unlock a new bug, make a repair stage go faster, or propose better patches
Automated program repair is hard.
Automated program repair is really hard.
Why did I pick automated program repair?
Repair
-
Core Repair Loop
-
Sorting Ingredients
-
Transforming Ingredients
Fault Localization
J. Xuan and M. Monperrus, Learning to Combine Multiple Ranking Metrics for Fault Localization, ICSME 2014.
Five DeepRepair Configurations
ED
(E)xecutable-level similarity ingredient sorting
(D)efault ingredient application (no ingredient transformation)
(T)ype-level similarity ingredient sorting
(D)efault ingredient application (no ingredient transformation)
TD
(R)andom ingredient sorting
(E)mbeddings-based ingredient transformation
RE
(E)xecutable-level similarity ingredient sorting
(E)mbeddings-based ingredient transformation
EE
(T)ype-level similarity ingredient sorting
(E)mbeddings-based ingredient transformation
TE
Empirical Results - RQ5 (ED and TD)
- Do code similarities based on deep learning improve fix space navigation as compared to jGenProg?
- Key result
- DeepRepair finds compilable ingredients faster than jGenProg
- Neither yields test-adequate patches in fewer attempts (on average)
- Nor finds significantly more patches than jGenProg
- Notable differences between DeepRepair and jGenProg patches
ED
(E)xecutable-level similarity ingredient sorting
(D)efault ingredient application (no ingredient transformation)
(T)ype-level similarity ingredient sorting
(D)efault ingredient application (no ingredient transformation)
TD
Empirical Results - RQ6 (RE)
- Does ingredient transformation using embeddings based on deep learning effectively transform repair ingredients as compared to jGenProg?
- Key result
- The embeddings-based ingredient transformation algorithm neither yields test-adequate patches in fewer attempts (on average)
- Nor finds significantly more patches than jGenProg
- Notable differences between DeepRepair and jGenProg patches
(R)andom ingredient sorting
(E)mbeddings-based ingredient transformation
RE
Empirical Results - RQ7 (EE and TE)
- Does DeepRepair, our learning-based approach that uses code similarities and transforms repair ingredients, improve fix space navigation as compared to jGenProg?
- Key result
- Finds compilable ingredients faster than jGenProg
- Neither yields test-adequate patches in fewer attempts (on average)
- Nor finds significantly more patches than jGenProg
- Finds a complementary set of patches
(E)xecutable-level similarity ingredient sorting
(E)mbeddings-based ingredient transformation
EE
(T)ype-level similarity ingredient sorting
(E)mbeddings-based ingredient transformation
TE
Empirical Results - RQ8 (manual assessment)
- Does DeepRepair generate higher quality patches?
- Key result
- No significant difference in quality was reported
- Although judges did notice differences in the patches generated by the approaches, no significant difference in readability was reported
dissertation
By martingwhite
dissertation
dissertation

