

































Wilfredo Meneses
Profesor universitario
slides.com/meneboni/programacion-de-bases-de-datos
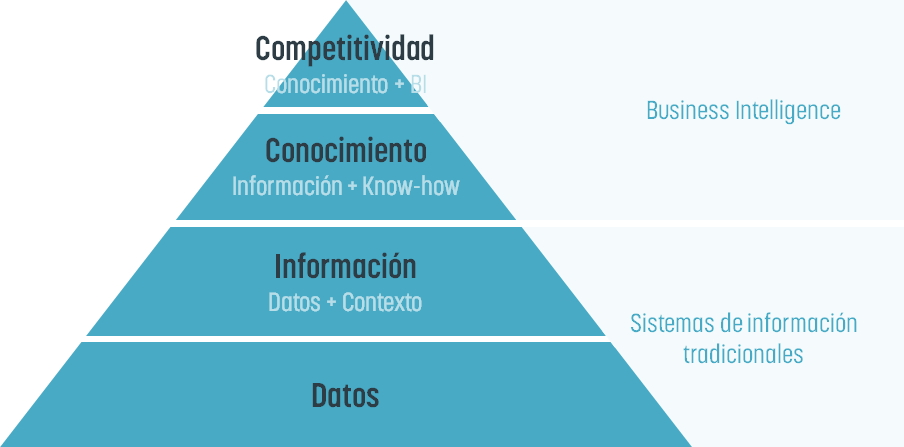
En consecuencia se necesita desarrollar habilidades para analizar problemas y aplicar soluciones con un software que permita extraer la información deseada de la BD. Para ello se requiere SQL
Sabemos que SQL = Structured Query Language / Lenguaje de consulta estructurado
Query /
Consulta
Output /
Salida
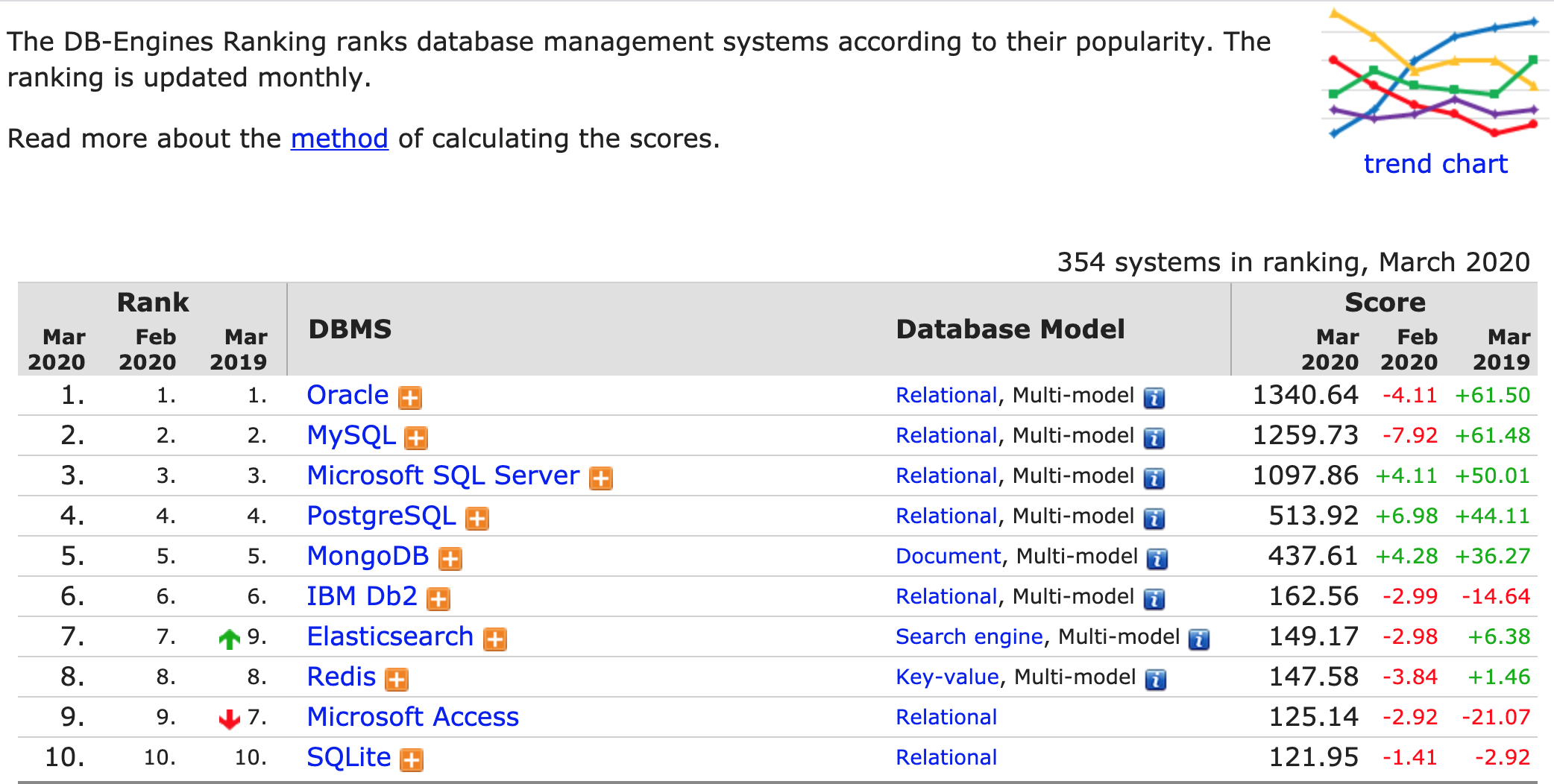
Hay otras plataformas que soportan SQL
Entonces ¿por qué MySQL?
Usado por:
Youtube
Dropbox
Booking.com
DB-Engines Ranking
SQL ejecuta comandos que permiten crear y manipular Bases de Datos relacionales.
Tipos de programación
Procedimental (imperativo)
Orientado a Objeto
Declarativo
Funcional
SQL
Investigue la diferencia entre cada tipo
Significa que mientras programamos no importa cómo queremos que se haga el trabajo, sino que nos enfocamos qué o cuáles resultados queremos
Procedimental (imperativo)
Declarativo - No Procedimental
Cómo
Qué
Lenguajes como C o Java
SQL
Debe seguirse el procedimiento paso a paso
Los algoritmos ya están construidos y hay un optimizador el cual separa las tareas es pasos más pequeños
En SQL nos concentramos en lo que queremos recibir de la base de datos
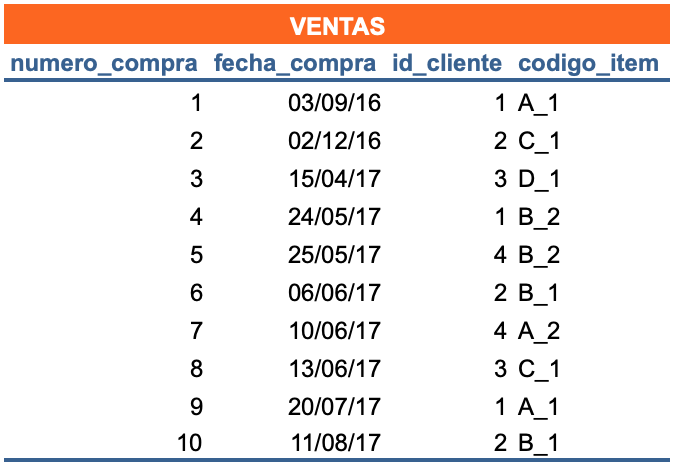
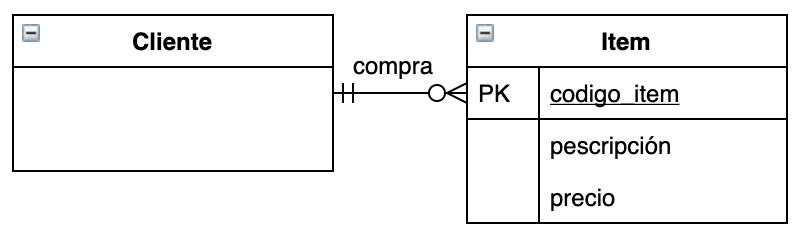
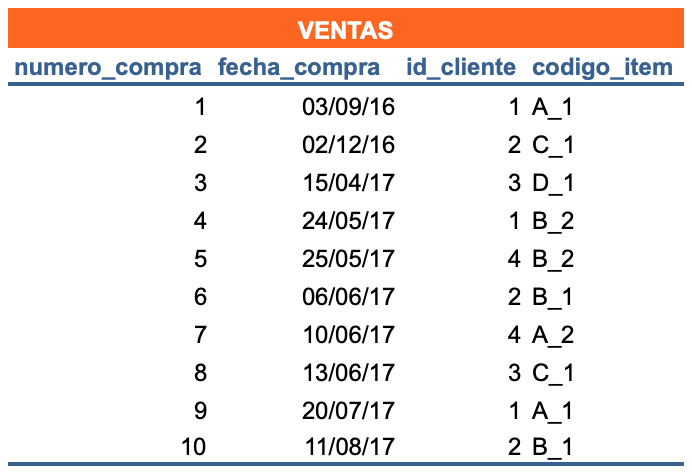
Los cuatro valores de datos formar un registro
registro = fila / Entidad horizontal / Instancia de entidad
record = row
Un campo / field /Entidad vertical = una columna en la tabla contiene información específica acerca de todos los registros en una tabla. Todos los registros de VENTAS tendrán cuatro campos.
Entidad: la unidad más pequeña que puede contener un conjunto significativo de datos
Entidad = objeto de base de datos
El álgebra relacional nos permite recibir datos eficientemente.
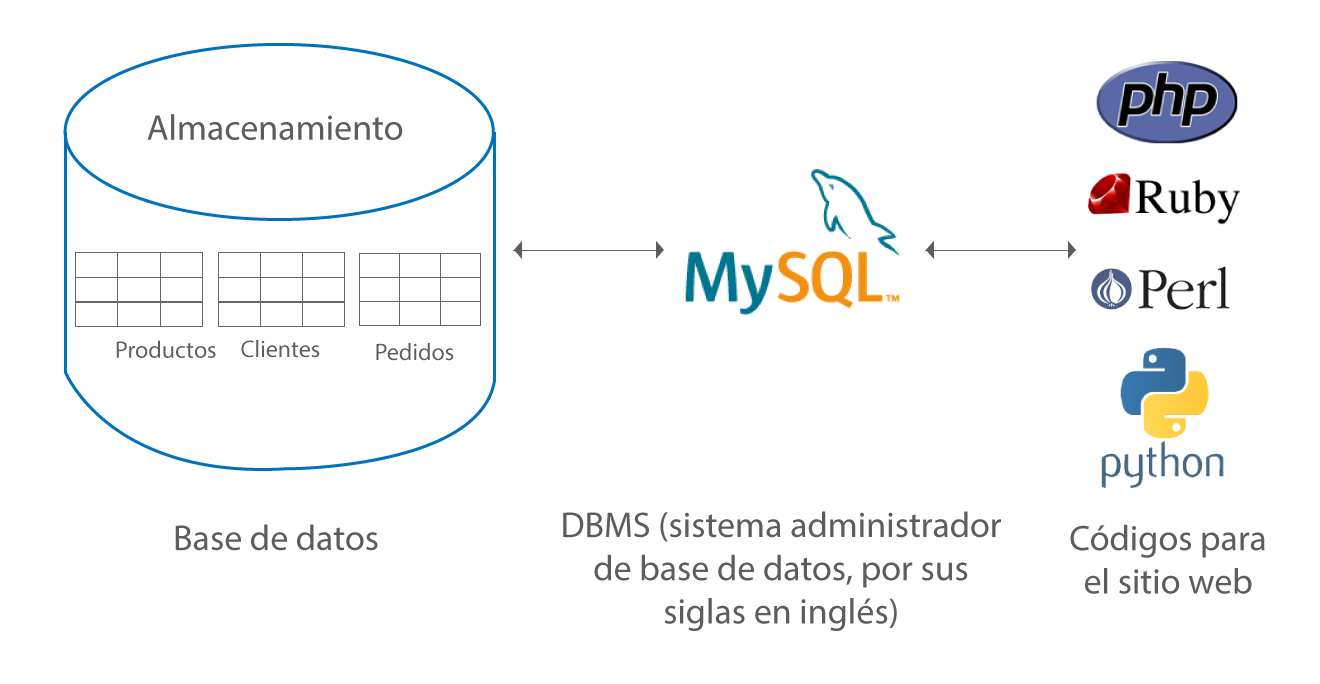
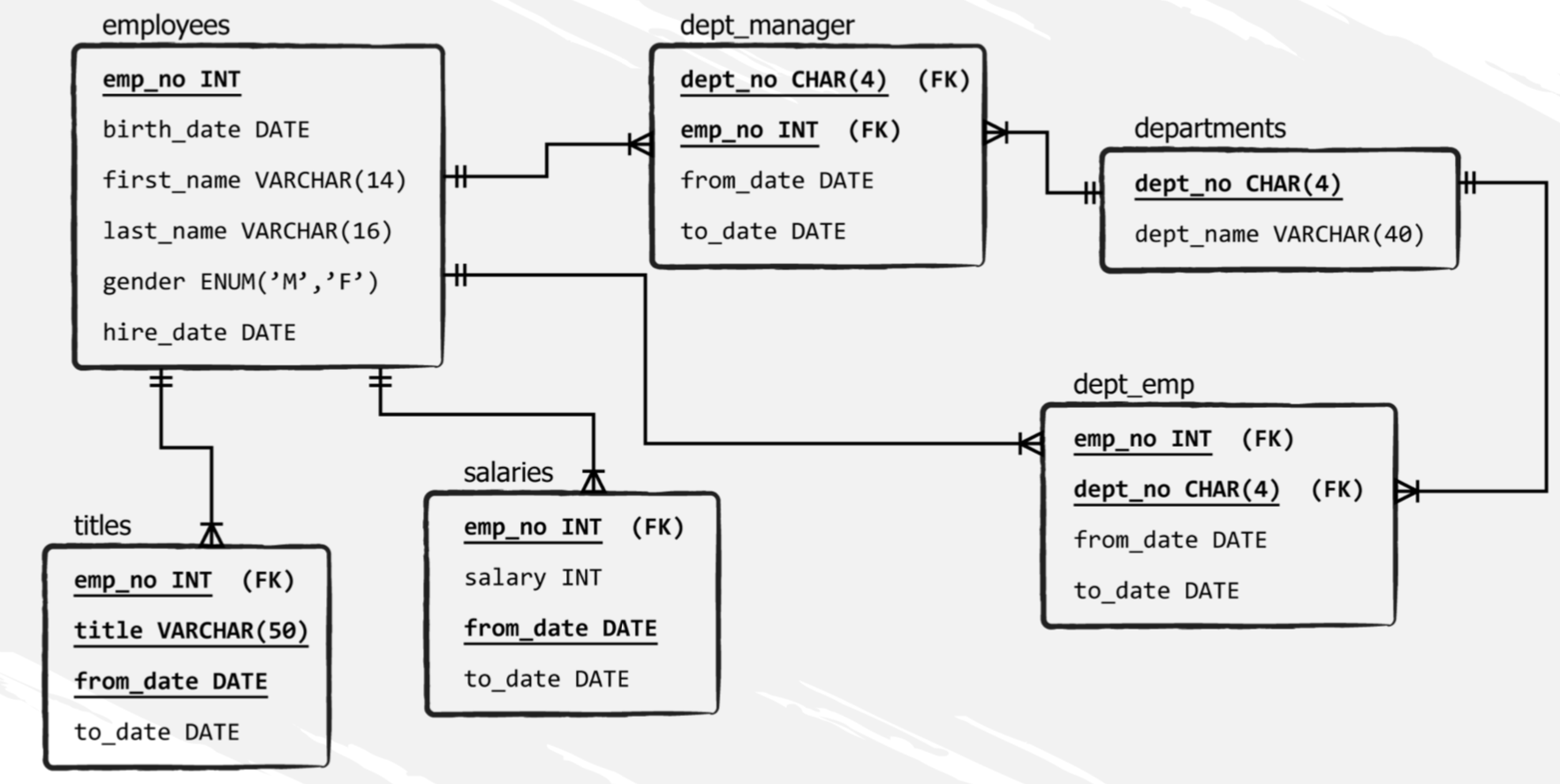
Las tres tablas están relacionadas formando una base de datos relacional cada una con su propio significado: una contiene ventas, otra clientes y la última items.
registro = fila
record = row
Hay dos tipos principales de bases de Datos
Base de datos relacionales
Base de datos no relacionales
considera sistemas más complejos + matemática y programación
Objetivo principal: organizar enormes cantidades de datos que pueden ser recuperados rápidamente.
Eficiente
Compacta
Bien estructurada
Las BD ocupan memoria
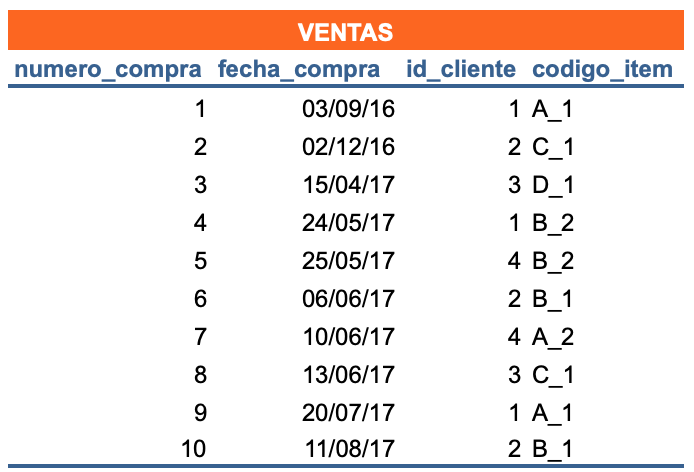
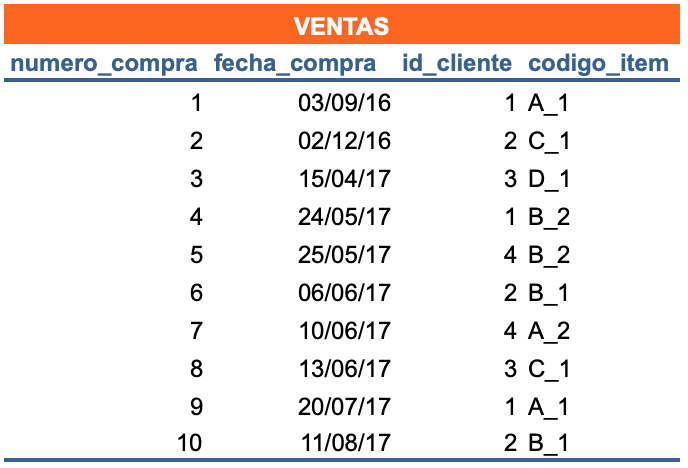
Imagine una BD (como un conjunto) con una única tabla que es consultada de forma recurrente y que cuenta con millones de registros, esto afectarían el rendimiento de la computadora y llevaría mucho tiempo dar respuesta a las solicitudes.
Por cada consulta deben recuperarse todos los registros de la tabla lo cual resultaría frustrante.
¿Para saber quién compró en un fecha determinada? Debe obtenerse toda la BD
Solución: consultar porciones de esos registros divididos en varias tablas. Tres tablas
ventas
clientes
items
(id_cliente)
(codigo_item)
(fecha_compra)
(nombre, apellido)
Solución: para dar respuesta a quién compró en una fecha determinada ni siquiera necesitamos de la entidad items, lo que hace más óptima la consulta.
ventas
clientes
(id_cliente)
(fecha_compra)
(nombre, apellido)
Tres tablas = 3 relaciones
ventas
clientes
items
Cuando combinamos la base de datos y sus relaciones existentes obtenemos el término famoso sistema manejador de base de datos relacionales RDBMS (Relational Database Management System).
Imagina que eres dueño de una tienda y que te has dado cuenta que la facturación diaria se está incrementando de forma beneficiosa y que tienes más de un millón de filas con datos. Entonces lo que necesitas es una base de Datos, pero no sabes nada acerca de las bases de datos. ¿A quién llamas?
1. ¿Un especialista SQL?
2. ¿Un diseñador de BD?
Traza el sistema de bases de datos completo en un lienzo usando una herramienta de visualización. Hay dos maneras:
Diagrama Entidad Relación
Esquema Relacional
Útil cuando tienes certeza de la estructura y organización de la BD
clientes
| id_cliente |
|---|
| nombre |
| apellido |
| numero_qiejas |
Clientes
| id_cliente |
|---|
| nombre |
| apellido |
| numero_quejas |
Items
| codigo_item |
|---|
| item |
| precio_unitario |
| id_empresa (FK) |
| sede |
| telefono |
Ventas
| numero_compra |
|---|
| fecha_compra |
| id_cliente (FK) |
| codigo_item (FK) |
Empresas
| id_empresa |
|---|
| nombre_empresa |
| telefono_sede |
| id_empresa (FK) |
El esquema de BD, resulta de la combinación de esquemas relacionales
Diseño de Bases de Datos + creación + manipulación = database management (manejo de base de datos)
Es la persona que diariamente cuida y da mantenimiento de la base de datos.
Primary Key: una columna (o un conjunto de columnas) cuyo valor existe y es único para cada registro en una tabla se llama clave primaria.
X
X
X
Error
Error
Error
Unique Key: se usa cada vez que desea especificar que no desea ver datos duplicados en un campo determinado
Valores Nulos
Primary Key
Unique Key
No
Sí
Número de keys
0, 1, 2, ...
1
Múltiples columnas
Sí
Sí
Las relaciones le indican qué cantidad de datos de un campo de clave foránea se puede ver en la columna de clave primaria de la tabla con la que se relacionan los datos y viceversa
Primary key
Foreign Key
Relación ono-a-muchos: Un valor de la columna id_cliente en la tabla "Clientes" se puede encontrar muchas veces en la columna id_cliente en la tabla "Ventas".
Clientes
| id_cliente |
|---|
| nombre |
| apellido |
| numero_quejas |
Ventas
| numero_compra |
|---|
| fecha_compra |
| id_cliente (FK) |
| codigo_item (FK) |
1 cliente
1 compra
> 1 compra
1 compra
1 compra
Número mínimo de instancias de la tabla "Clientes" que pueden asociarse con la entidad "Ventas"
Clientes
| id_cliente |
|---|
| nombre |
| apellido |
| numero_quejas |
Ventas
| numero_compra |
|---|
| fecha_compra |
| id_cliente (FK) |
| codigo_item (FK) |
mínimo = 1 cliente = máximo
1 compra
1 compra
1 compra
Número mínimo de instancias de la tabla "Clientes" que pueden asociarse con la entidad "Ventas"
Clientes
| id_cliente |
|---|
| nombre |
| apellido |
| numero_quejas |
Ventas
| numero_compra |
|---|
| fecha_compra |
| id_cliente (FK) |
| codigo_item (FK) |
Ventas a clientes: muchos-a-uno
Clientes a ventas : uno-a-muchos
Clientes
| id_cliente |
|---|
| nombre |
| apellido |
| numero_quejas |
Ventas
| numero_compra |
|---|
| fecha_compra |
| id_cliente (FK) |
| codigo_item (FK) |
Restricciones de cardinalidad (cardinality constraints)
Para mayor información, leer el material de lectura obligatoria sobre MER, disponible en el espacio virtual de Diseño de Bases de Datos.
Base de Datos = esquema
Clientes
| id_cliente |
|---|
| nombre |
| apellido |
| numero_quejas |
Items
| codigo_item |
|---|
| item |
| precio_unitario |
| id_empresa (FK) |
| sede |
| telefono |
Ventas
| numero_compra |
|---|
| fecha_compra |
| id_cliente (FK) |
| codigo_item (FK) |
Empresas
| id_empresa |
|---|
| nombre_empresa |
| telefono_sede |
| id_empresa (FK) |
Ventas
CREATE DATABASE [IF NOT EXISTS] nombre_base_de_datos;
-- Ctrl + shift + enter para ejecutar
CREATE DATABASE IF NOT EXISTS ventas;
-- Sinónimo de la instrucción anterior
CREATE SCHEMA IF NOT EXISTS ventas;
-- Usar la base de datos
USE ventas;string
apellido
'Meneses'
length / longitud
size / tamaño
7 símbolos
7 bytes
string
apellido
'Meneses'
length / longitud
size / tamaño
7 símbolos
7 bytes
Tipo de dato string
Caracter
CHAR
Almac. / Storage
Ejemplo
Fijo
CHAR(7)
CHAR(7): 7 representa el número máximo de símbolos que es
permitido usar para escribir un valor en este formato
length
Símbolos
size
bytes
'Meneses'
7
7
'Li'
2
7
Tipo de dato string
Caracter
CHAR
Almac. / Storage
Ejemplo
Fijo
CHAR(7)
length
Símbolos
size
bytes
'Meneses'
7
7
'Li'
2
7
VARCHAR
Caracter variable
Variable
VARCHAR(7)
'Meneses'
7
7
'Li'
2
3
Tipo de dato string
Caracter
CHAR
Tamaño máximo
255
VARCHAR
Caracter variable
65,535
Se adapta al valor insertado
50% más rápido
Tipo de dato string
Caracter
CHAR
Ejemplo
VARCHAR
Caracter variable
ENUM
"Enumerado"
ENUM
CHAR(7)
VARCHAR(7)
ENUM('M', 'F')
MySQL mostrará un error si intentamos insertar cualquier valor diferente de 'M' o 'F'
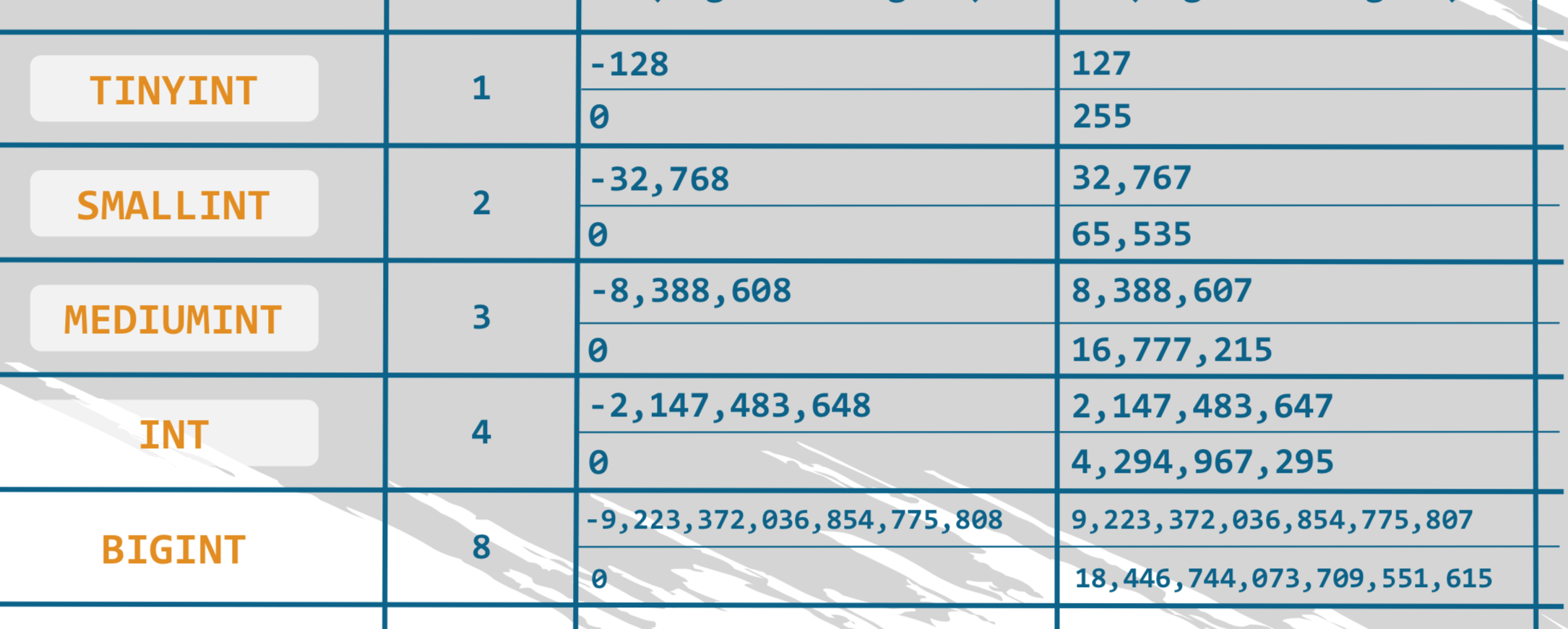
Tipos de datos numéricos
integer
fix-point
floating-point
números enteros sin punto decimal. Ejemplo: 5; 15; -200; 1,000
INTEGER
INT
Tipo de dato numérico
size
(bytes)
Valor mínimo
(Con signo / sin signo)
Valor máximo
(Con signo / sin signo)
Con signo
Sín signo
Si el rango abarcado incluye
valores positivos y negativos
Si se permite que los enteros sean solo positivos
Nota: los tipos de datos enteros de forma predeterminada son "con signo". Si se desea utilizar un rango que contenga solo valores positivos, "sin signo", hay que especificar esto en la consulta (lo veremos más adelante)
¿Por qué no usar BIGINT todo el tiempo?
La respuesta viene con la idea de mejorar la eficiencia en términos de velocidad de procesamiento de la computadora
Por ejemplo: Si está seguro de que, en una determinada columna, no necesitará un número entero menor que 0 o mayor que 100, TINYINT haría el trabajo a la perfección y no necesitaría más espacio de almacenamiento.
Un tipo entero más pequeño puede aumentar la velocidad de procesamiento
Precisión: se refiere al número de dígitos en un número.
Escala: se refiere al número de dígitos a la derecha del punto decimal en un número
número
10.523
Precisión
3
Escala
5
35.875
3
5
Ejemplo: DECIMAL(5, 3)
Dato con punto fijo: representa el valores exactos.
10.523
10.5
DECIMAL(5, 3)
10.500
10.5236789
10.524
Dato con punto fijo: representa el valores exactos.
1234567
DECIMAL(7)
Cuando únicamente se especifica un dígito entre paréntesis, se tratará como la precisión del tipo de dato
DECIMAL(7, 0)
Es lo mismo que
DECIMAL = NUMERIC
Ejemplo: salario
NUMERIC (p, s)
precisión: p = 7
escala: s = 2
Ejemplo NUMERIC (p, s) $75,000.50
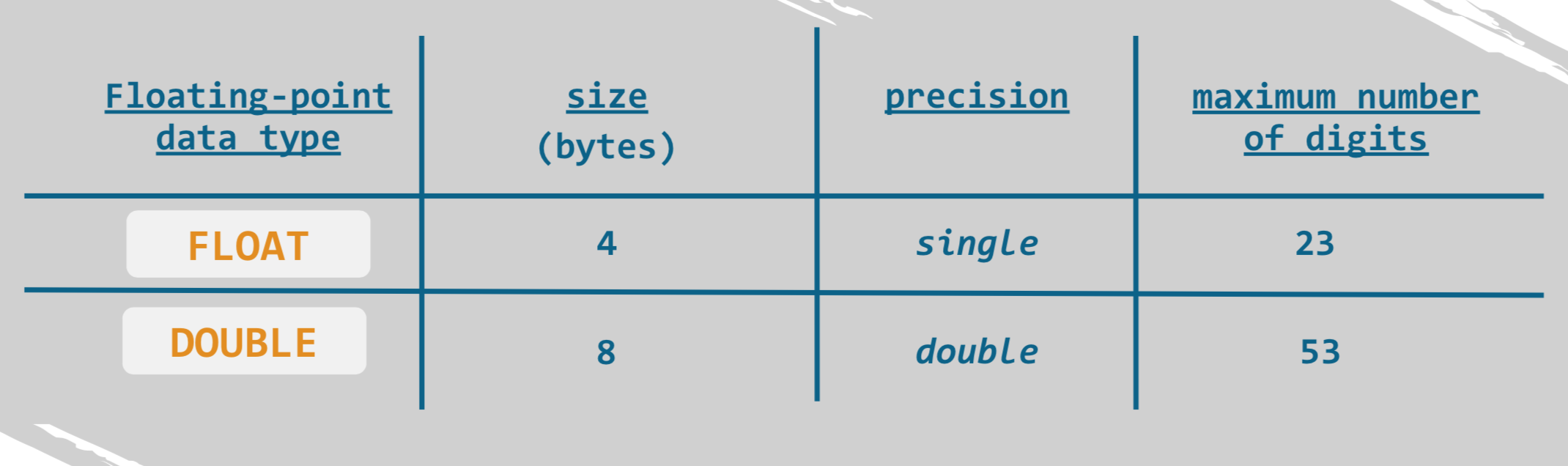
FLOAT (5, 3)
Tipo de dato de punto-flotante
- utilizado sólo para valores aproximados
- tiene como objetivo equilibrar el rango y la precisión (=> "flotante")
10.523
10.5236789
10.524 No hay warning
10.524 Es un valor aproximado
FLOAT (5, 3)
La principal diferencia entre el tipo de punto fijo y el tipo de punto flotante está en la forma en que el valor se representa en la memoria de la computadora
10.524
10.5236789
10.524
DECIMAL (5, 3)
10.5236789
Tipos de datos numéricos
integer
fix-point
floating-point
INTEGER
DECIMAL
NUMERIC
FLOAT
DOUBLE
La diferencia entre el float y el double es técnica
Un programador presta atención acerca cuál debe ser el tipo de dato exacto
DATE
Usado para representar una fecha en el formato AAAA-MM-DD. Rango: 1 de enero de 1000 al 31 de diciembre de 9999
Ejemplo: '2018-07-25'
DATETIME
Fecha y hora, AAAA-MM-DD HH: MM: SS [.fracción]
Rango: 0 - 23: 59: 59.999999
Ejemplo: '2018-07-25 9:30:00'
DATETIME
representa la fecha que se muestra en el calendario y la hora que se muestra en el reloj
VS
TIMESTAMP
Utilizado para un momento exacto y bien definido.
Rango: 1 de enero de 1970 UTC - 19 de enero de 2038, 03:14:07 UTC
- registra el momento en el tiempo como el número de segundos transcurridos después del 1 de enero de 1970 00:00:00 UTC.
Ejemplo: 25 de julio de 2018: 1,535,155,200
48 años
TIMESTAMP
Representa un momento en el tiempo como un número le permite obtener fácilmente la diferencia entre dos valores TIMESTAMP
Inicio
Fin
TIMESTAMP
DATETIME
TIMESTAMP
DATE
VARCHAR
CHAR
INTEGER
DECIMAL
INTEGER
NUMERIC
FLOAT
DOUBLE
Los datos deber ser escritos entre comillas
Los datos sin comillas
Tipos de Datos Númericos
Tipos cadena, fecha y hora
Encontramos estos tipos de datos o similares en otros SGBD
BLOB
Objeto binario grande
- Se refiere a un archivo de datos binarios - datos con 1 y 0
- Implica guardar archivos en un registro
CREATE TABLE nombre_tabla (
nombre_columna_1 tipo_dato restricción,
nombre_columna_1 tipo_dato restricción,
...
nombre_columna_n tipo_dato restricción
);
El nombre de la tabla puede coincidir con el nombre de la Base de Datos y debe contener mínimo un campo.
AUTO_INCREMENT: le libera de tener que insertar todos los números de compra manualmente a través del comando INSERT en una etapa posterior
| numero_compra |
|---|
| 1 |
| 2 |
| 3 |
| ... |
| n |
CREATE TABLE ventas
(
numero_compra INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
fecha_compra DATE NOT NULL,
id_cliente INT,
codigo_item VARCHAR(10) NOT NULL
);Cree la tabla "clientes" en la base de datos "ventas". Deje que contenga las siguientes 5 columnas: id_cliente, nombre, apellido, email y numero_quejas. Deje que los tipos de datos de id_cliente y numero_quejas sean enteros, mientras que los tipos de datos de todas las demás columnas serán VARCHAR de 255.
Siempre que desee hacer referencia a un objeto SQL en sus consultas, debe especificar la base de datos a la que se aplica
USE ventas
SELECT * FROM clientesSELECT * FROM ventas.clientesTambién puede especificar la base de datos
Instrucción DROP
Usada para eliminar objetos existentes
DROP TABLE ventas;DROP tipo_objeto nombre_objeto;
Son reglas específicas, o límites, que definimos en nuestras tablas
CREATE TABLE ventas
(
numero_compra INT NOT NULL AUTO_INCREMENT,
fecha_compra DATE NOT NULL,
id_cliente INT,
codigo_item VARCHAR(10) NOT NULL,
PRIMARY KEY (numero_compra)
);Apunta a una columna de otra tabla y, por lo tanto, vincula las dos tablas
Clientes
| id_cliente |
|---|
| nombre |
| apellido |
| numero_quejas |
Ventas
| numero_compra |
|---|
| fecha_compra |
| id_cliente (FK) |
| codigo_item (FK) |
Tabla padre = tabla referenciada
Tabla hija = referencia tabla
Recuerde, este no es un requisito obligatorio: estas dos claves pueden tener dos nombres completamente diferentes. ¡Lo importante es que los tipos de datos y la información coincidan! Es una práctica común usar, si no el mismo, nombres similares para ambas claves.
La clave externa (foránea) mantiene la integridad referencial dentro de la base de datos
ON DELETE CASCADE
Si se ha eliminado un valor específico de la clave primaria de la tabla primaria, también se eliminarán todos los registros de la tabla secundaria que se refieran a este valor.
CREATE TABLE ventas
(
numero_compra INT NOT NULL AUTO_INCREMENT,
fecha_compra DATE NOT NULL,
id_cliente INT,
codigo_item VARCHAR(10) NOT NULL,
PRIMARY KEY (numero_compra)
);
ALTER TABLE ventas
ADD FOREIGN KEY (id_cliente) REFERENCES clientes(id_cliente) ON DELETE CASCADE;
ALTER TABLE ventas
DROP FOREIGN KEY ventas_ibk1;Instrucción ALTER
Usada para modificar objetos existentes
ALTER TABLE ventas
ADD COLUMN fecha_compra DATE;| numero_compra | fecha_compra |
|---|---|
ventas
Keywords
Objetos o bases de datos no pueden tener nombres que coincidan con palabras claves (reservadas) de SQL.
CREATE TABLE alter (numero_compra int);
Error
Casi nunca se programa solo. Es más común la programación en equipo.
Clean code (código limpio)
Código que es entendible, lo que significa que puede ser legible, lógico y modificable.
Buen código no es el que una computadora entiende, es el que los humanos pueden entender.
Cuando se asigna nombre a variables u objetos SQL:
Legible
1. Usar software apropiado que reorganice el código y color de las palabras de forma consistente.
Es poco profesional unir código escrito en el mismo lenguaje, pero con diferentes estilos
2. Usar la herramienta para reformater script de Workbench (Ctrl + B)
3. Intervenir manualmente y hacer los ajustes según tus gustos
USE ventas;
CREATE TABLE IF NOT EXISTS test (
numeros INT(10),
palabras VARCHAR(10)
);
SELECT
*
FROM
test;
DROP TABLE test;Comentarios: líneas de texto que Workbench no ejecutará como código. Es un mensaje para cualquiera que lea nuestro código.
/* ... */ Comentario multilínea
# o -- Comentario de línea
/*
Comentario 1
Comentario 2
*/
# Comentario 3
-- Comentario 4
/*(8)*/ SELECT /*9*/ DISTINCT /*11*/ TOP
/*(1)*/ FROM
/*(3)*/ JOIN
/*(2)*/ ON
/*(4)*/ WHERE
/*(5)*/ GROUP BY
/*(6)*/ WITH {CUBE | ROLLUP}
/*(7)*/ HAVING
/*(10)*/ ORDER BY
/*(11)*/ LIMIT VT significa "tabla virtual" y muestra cómo se producen diversos datos a medida que se procesa la consulta.
1. FROM: se realiza un producto cartesiano (combinación cruzada) entre las dos primeras tablas de la cláusula FROM y, como resultado, se genera la tabla virtual VT1.
2. ON: El filtro ON se aplica a VT1. Solo las filas para las cuales es VERDADERO se insertan en VT2.
/*(8)*/ SELECT /*9*/ DISTINCT /*11*/ TOP
/*(1)*/ FROM
/*(3)*/ JOIN
/*(2)*/ ON
/*(4)*/ WHERE
/*(5)*/ GROUP BY
/*(6)*/ WITH {CUBE | ROLLUP}
/*(7)*/ HAVING
/*(10)*/ ORDER BY
/*(11)*/ LIMIT 3. OUTER (join): si se especifica OUTER JOIN (a diferencia de CROSS JOIN o INNER JOIN), las filas de la tabla o tablas conservadas para las que no se encontró una coincidencia se agregan a las filas de VT2 como filas externas, generando VT3. Si aparecen más de dos tablas en la cláusula FROM, los pasos 1 a 3 se aplican repetidamente entre el resultado de la última combinación y la siguiente tabla en la cláusula FROM hasta que se procesen todas las tablas.
Logical Query Processing Phase
/*(8)*/ SELECT /*9*/ DISTINCT /*11*/ TOP
/*(1)*/ FROM
/*(3)*/ JOIN
/*(2)*/ ON
/*(4)*/ WHERE
/*(5)*/ GROUP BY
/*(6)*/ WITH {CUBE | ROLLUP}
/*(7)*/ HAVING
/*(10)*/ ORDER BY
/*(11)*/ LIMIT 4. WHERE: El filtro WHERE se aplica a VT3. Solo las filas para las cuales es VERDADERO se insertan en VT4.
5. GROUP BY: Las filas de VT4 se organizan en grupos según la lista de columnas especificada en la cláusula GROUP BY. Se genera VT5.
6. CUBO | ROLLUP: los supergrupos (grupos de grupos) se agregan a las filas de VT5, generando VT6.
7. HAVING: El filtro HAVING se aplica a VT6. Sólo los grupos para los cuales es TRUE se insertan en VT7.
/*(8)*/ SELECT /*9*/ DISTINCT /*11*/ TOP
/*(1)*/ FROM
/*(3)*/ JOIN
/*(2)*/ ON
/*(4)*/ WHERE
/*(5)*/ GROUP BY
/*(6)*/ WITH {CUBE | ROLLUP}
/*(7)*/ HAVING
/*(10)*/ ORDER BY
/*(11)*/ LIMIT 8. SELECCIONAR: se procesa la lista SELECCIONAR, generando VT8.
9. DISTINTO: las filas duplicadas se eliminan de VT8. Se genera VT9.
10. ORDER BY: Las filas de VT9 se ordenan según la lista de columnas especificada en la cláusula ORDER BY. Se genera un cursor (VC10).
/*(8)*/ SELECT /*9*/ DISTINCT /*11*/ TOP
/*(1)*/ FROM
/*(3)*/ JOIN
/*(2)*/ ON
/*(4)*/ WHERE
/*(5)*/ GROUP BY
/*(6)*/ WITH {CUBE | ROLLUP}
/*(7)*/ HAVING
/*(10)*/ ORDER BY
/*(11)*/ LIMIT 11. TOP: El número especificado o el porcentaje de filas se selecciona desde el principio de VC10. La tabla VT11 se genera y se devuelve a la persona que llama. LIMIT tiene la misma funcionalidad que TOP en algunos dialectos de SQL como Postgres y Netezza.
¡Es hora de pasar al siguiente nivel! ¡Comenzaremos a manipular datos en MySQL!
Para este propósito, utilizará un gran conjunto de datos que se puede encontrar en GitHub. Los programadores lo utilizan con frecuencia para mejorar y profundizar en SQL. Esto significa que este conjunto de datos es la mejor opción posible para sentar las bases del trabajo con MySQL y bases de datos relacionales.
Aprovecharemos su complejidad resolviendo varias tareas desafiantes. Estas tareas serán un ejercicio interesante que lo convertirá en un usuario competente de SQL.
Nota: la mayor complejidad hasta aquí es que la BD está en inglés, pero con un conocimiento básico bastará.
Hemos reorganizado el script de la base de datos en un archivo SQL que puede descargar y ejecutar. Por favor, acceda al enlace disponible aquí:
https://www.dropbox.com/s/asqkku6qwflkw6u/employees.sql?dl=0
Una vez que el proceso de descarga esté listo, abra el archivo de script desde Workbench como abriría otros archivos SQL y ejecute el código.
En esta sección:
La sentencia SELECT (una de las más importantes de SQL y MySQL):
SELECT columna_1, columna_2,... columna_n FROM nombre_tabla;
SELECT first_name, last_name
FROM employees;SELECT *
FROM employees;Ejercicio 1. Seleccione la información de la columna "dept_no" de la tabla "departments".
Ejercicio 2. Seleccione todos los datos de la tabla "departments".
Nos permitirá establecer una condición sobre la cual especificaremos qué parte de los datos queremos recuperar de la base de datos
SELECT columna_1, columna_2,... columna_n
FROM nombre_tabla
WHERE condición;
Ejemplo: Si volvemos a la tabla 'employees' y queremos información solamente de los empleados con nombre 'Denis', sería:
SELECT
*
FROM
employees
WHERE
first_name = 'Denis';Ejercicio 3. Seleccione todas las personas de la tabla de "employees" cuyo primer nombre (first_name) es "Elvis".
Operador igual (=)
En SQL, hay muchas otras palabras clave y símbolos de enlace, llamados operadores, que puede usar con la cláusula WHERE
Vamos a estudiar los más comunes
Permite combinar lógicamente dos instrucciones en el bloque de condición. Realmente estrecha más los resultados.
Ejemplo: queremos obtener los empleados con el nombre 'Denis' y género masculino 'male'
SELECT columna_1, columna_2,... columna_n
FROM nombre_tabla
WHERE condición_1 AND condición_2;
'Denis'
'M'
SELECT
*
FROM
employees
WHERE
first_name = 'Denis' AND gender = 'M';Ejemplo: queremos obtener los empleados con el nombre 'Denis', género masculino 'male' y contratados el '1990-05-21'
SELECT
*
FROM
employees
WHERE
first_name = 'Denis' AND gender = 'M' AND hire_date = '1990-05-21';Ejercicio 4. Obtener una lista de empleadas cuyo nombre es Kellie
AND
La condición se establece en columnas diferentes. Enlaza ambos criterios que deben cumplirse.
OR
La condición se establece en la misma columna y combina el resultado de ambos criterios
Ejemplo: queremos obtener los empleados con el nombre 'Denis' o 'Elvis'
SELECT
*
FROM
employees
WHERE
first_name = 'Denis' OR first_name = 'Elvis';Debemos conocer el orden lógico que debe cumplirse cuando se usan ambos operadores en el mismo bloque WHERE
AND > OR
Analicemos la diferencia entre las dos instrucciones siguientes:
SELECT
*
FROM
employees
WHERE
last_name = 'Denis' AND gender = 'M' OR gender = 'F';
-- PODEMOS CAMBIAR LA PRECEDENCIA CON PARENTESIS
SELECT
*
FROM
employees
WHERE
last_name = 'Denis' AND (gender = 'M' OR gender = 'F');Ejercicio 5. Recupere una lista con todas las empleadas cuyo primer nombre sea Kellie o Aruna.
Analice el resultado de la siguiente consulta
SELECT
*
FROM
employees
WHERE
first_name = 'Denis' AND first_name = 'Elvis';Ejercicio 5. Obtener una lista de empleadas cuyo nombre es Kellie o Aruna
Ejemplo: extraer los empleados con nombre Cathie, Mark o Nathan
SELECT
*
FROM
employees
WHERE
first_name = 'Cathie' OR first_name = 'Mark' OR first_name = 'Nathan'; Ejemplo: extraer los empleados con nombre Cathie, Mark o Nathan
SELECT
*
FROM
employees
WHERE
first_name = 'Cathie' OR first_name = 'Mark' OR first_name = 'Nathan'; IN permite a SQL retornar lo escrito entre paréntesis, si existen en nuestra tabla.
SELECT
*
FROM
employees
WHERE
first_name IN ('Cathie', 'Mark', 'Nathan'); Usando IN (en menor tiempo que el anterior)
Ejemplo: extraer los empleados cuyo nombre no sea Cathie, Mark o Nathan
SELECT
*
FROM
employees
WHERE
first_name = 'Cathie' OR first_name = 'Mark' OR first_name = 'Nathan'; SELECT
*
FROM
employees
WHERE
first_name NOT IN ('Cathie', 'Mark', 'Nathan'); Ejercicio 6: Use el operador IN para seleccionar a todas las personas de la tabla de "employees", cuyo primer nombre es "Denis" o "Elvis".
Ejercicio 7. Extraiga todos los registros de la tabla de "employees", aparte de aquellos con empleados llamados John, Mark o Jacob.
Sirve para buscar patrones
Ejemplo: deseamos una lista de personas cuyo nombre inicia con 'Mar' que podría ser parte de nombres como Mark, Martin, Margarret, etc.
SELECT
*
FROM
employees
WHERE
first_name LIKE 'Mar%'; Si removemos al 'M' se mostrarían los que inician con 'ar'
SELECT
*
FROM
employees
WHERE
first_name LIKE 'ar%'; % sustituye una secuencia de caracteres
¿Qué sucede en estos casos?
SELECT
*
FROM
employees
WHERE
first_name LIKE '%ar'; SELECT
*
FROM
employees
WHERE
first_name LIKE '%ar%'; ¿Qué sucede en este caso?
SELECT
*
FROM
employees
WHERE
first_name LIKE ('Mar_'); _ sustituye un caracter
Los empleados cuyo nombre no incluye la palabra 'Mar'
SELECT
*
FROM
employees
WHERE
first_name NOT LIKE '%Mar%';Recuerde que MySQL no es sensible a mayúsculas y minúsculas.
Ejercicio 8. Al trabajar con la tabla de "employees", use el operador LIKE para seleccionar los datos de todas las personas, cuyo primer nombre comienza con "Mark"; especifique que el nombre puede ser sucedido por cualquier secuencia de caracteres.
Ejercicio 9. Recupere una lista con todos los empleados que fueron contratados en el año 2000.
Ejercicio 10. Recupere una lista con todos los empleados cuyo número de empleado esté escrito con 5 caracteres y comience con "1000".
% sustituye una secuencia de caracteres
LIKE ('Mar%')
Mark, Martin, Margare
_ sustituye un caracter
LIKE ('Mar_')
Mark, Marv, Marl
* entregará una lista de todas las columnas en una tabla
SELECT * FROM employees;
Más adelante veremos que se puede usar para contar todas las filas de una tabla
Ejercicio 11. Extraiga a todos los individuos de la tabla de "employees" cuyo primer nombre contiene "Jack".
Ejercicio 12. Una vez que haya hecho eso, extraiga otra lista que contenga los nombres de los empleados que no contengan "Jack".
Nos ayuda a designar el intervalo al que pertenece un valor dado
SELECT
*
FROM
employees
WHERE
hire_date BETWEEN '1990-01-01' AND '2000-01-01';'1990-01-01' Y '2000-01-01' se incluirán en la lista recuperada de registros
Ejemplo: seleccionar las personas contratadas entre el primero de enero de 1990 y el primero de enero de 2000
Se refiere a un intervalo compuesto de dos partes:
- un intervalo por debajo del primer valor indicado
- un segundo intervalo por encima del segundo valor
SELECT
*
FROM
employees
WHERE
hire_date NOT BETWEEN '1990-01-01' AND '2000-01-01';- la fecha de contratación es anterior a '1990-01-01' o
- la fecha de contratación es posterior a ‘2000-01-01'
- No se usa solo para valores de fecha
- También podría aplicarse a cadenas y números
Ejercicio 13. Seleccione toda la información de la tabla de "salaries" con respecto a contratos de 66,000 a 70,000 dólares por año.
Ejercicio 14. Recupere una lista con todas las personas cuyo número de empleado no esté entre "10004" y "10012".
Ejercicio 15. Seleccione los nombres de todos los departamentos con números entre "d003" y "d006".
IS NOT NULL: se usa para extraer valores que no son nulos
SELECT columna_1, columna_2,... columna_n
FROM nombre_tabla
WHERE nombre_columna IS NOT NULL;
Ejemplo: Extraer información de los empleados cuyo nombre no es nulo.
SELECT
*
FROM
employees
WHERE
first_name IS NOT NULL;IS NULL: se usa para extraer valores que son nulos
SELECT columna_1, columna_2,... columna_n
FROM nombre_tabla
WHERE nombre_columna IS NULL;
Ejemplo: Extraer información de los empleados cuyo nombre es nulo.
SELECT
*
FROM
employees
WHERE
first_name IS NULL;Ejercicio 16: Seleccione los nombres de todos los departamentos cuyo valor de número de departamento no sea nulo.
| SQL | |
|---|---|
| = | igual a |
| > | mayor que |
| >= | mayor o igual que |
| < | menor que |
| <= | menor o igual que |
| <> , != | no igual, diferente de |
Empleados con nombre igual a 'Mark'
Empleados con nombre diferente de 'Mark'
SELECT
*
FROM
employees
WHERE
first_name = 'Mark'; SELECT
*
FROM
employees
WHERE
first_name <> 'Mark'; Empleados contratados después del 1 de enero de 2000
SELECT
*
FROM
employees
WHERE
hire_date > '2000-01-01'; Empleados contratados del 1 de enero de 2000 en adelante
SELECT
*
FROM
employees
WHERE
hire_date >= '2000-01-01'; Ejercicio 17: Recupere una lista con datos sobre todas las empleadas que fueron contratadas en el año 2000 o después.
Sugerencia: si resuelve la tarea correctamente, SQL debería devolver 7 filas.
Ejercicio 19: Extraiga una lista con los salarios de todos los empleados superiores a $ 150,000 por año.
SELECT: puede recuperar filas de una columna designada, dados algunos criterios
SELECT DISTINCT columna_1, columna_2,... columna_n FROM nombre_tabla;
SELECT DISTINCT: selecciona todos los valores de datos distintos
SELECT
gender
FROM
employees;SELECT DISTINCT
gender
FROM
employees;Ejercicio 20. Obtenga una lista con todas las diferentes "fechas de contratación" de la tabla "empleados".
Funciones agregadas: se aplican en varias filas de una sola columna de una tabla y devuelven una salida de un solo valor
COUNT()
SUM()
MIN()
MAX()
AVG()
cuenta el número de registros no nulos en un campo
suma todos los valores no nulos en una columna
devuelve el valor mínimo de toda la lista
devuelve el valor máximo de toda la lista
calcula el promedio de todos los valores no nulos que pertenecen a una determinada columna de una tabla
COUNT()
cuenta el número de registros no nulos en un campo
Se usa frecuentemente en combinación con la palabra reservada "DISTINCT"
SELECT COUNT(nombre_columna) FROM nombre_tabla;
Los paréntesis después de COUNT() deben comenzar justo después de la palabra clave, no después de un espacio en blanco
Ejemplo: cuantos empleados están registrados en nuestra BD
SELECT
COUNT(emp_no)
FROM
employees;SELECT
COUNT(first_name)
FROM
employees;Lo mismo ¿por qué?
COUNT(DISTINCT)
SELECT COUNT(DISTINCT nombre_columna) FROM nombre_tabla;
Ejemplo: ¿cuántos nombres distintos podemos encontrar en la tabla 'employees'?
SELECT
COUNT(DISTINCT first_name)
FROM
employees;Observe que la palabra reservada DISTINCT se coloca entre los paréntesis y a la izquierda del nombre del campo
Ejercicio 21. ¿Cuántos contratos anuales con un valor superior o igual a $ 100,000 se han registrado en la tabla de salarios?
Ejercicio 22. ¿Cuántos gerentes tenemos en la base de datos de "empleados"? Use el símbolo de estrella (*) en su código para resolver este ejercicio.
ASC, abreviatura de "ASCENDING", se agrega de forma implícita
SELECT
*
FROM
employees
ORDER BY first_name;DESC, abreviatura de "DESCENDING"
SELECT
*
FROM
employees
ORDER BY first_name DESC;No solo se usa para cadenas sino con otros tipos como números. Además se pueden incluir múltiples columnas.
SELECT
*
FROM
employees
ORDER BY first_name, last_name ASC;Ejercicio 23. Seleccione todos los datos de la tabla "employees", ordenándolos por "hire_date" en orden descendente.
SELECT nombre_columna(s)
FROM nombre_tabla
WHERE condiciones
GROUP BY nombre_columna(s)
ORDER BY nombre_columna(s);
SELECT
first_name
FROM
employees;Al agregar GROUP BY se seleccionan solo valores distintos para el nombre
SELECT
first_name
FROM
employees
GROUP BY first_name;1275 filas, equivalente a: (vea el tiempo de respuesta)
SELECT DISTINCT
first_name
FROM
employees;300024 filas
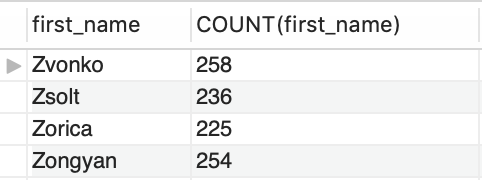
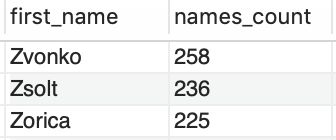
En esta instrucción la función de agregación se agrupa por nombres, así obtenemos el conteo de veces que cada nombre es encontrado en la tabla employees.
SELECT
first_name, COUNT(first_name)
FROM
employees
GROUP BY first_name; Con la cláusula de ordenamiento
SELECT
first_name, COUNT(first_name)
FROM
employees
GROUP BY first_name
ORDER BY first_name DESC;Veamos la salida de la última instrucción
SELECT
first_name, COUNT(first_name)
FROM
employees
GROUP BY first_name
ORDER BY first_name DESC;Un alias es usado para renombrar una selección de la consulta
selección 1
selección 2
SELECT
first_name, COUNT(first_name) AS names_count
FROM
employees
GROUP BY first_name
ORDER BY first_name DESC;Refina la salida de registros que no satisfacen una determinada condición
SELECT nombre_columna(s)
FROM nombre_tabla
WHERE condiciones
GROUP BY nombre_columna(s)
HAVING condiciones
ORDER BY nombre_columna(s);
HAVING es como WHERE pero aplicado al bloque GROUP BY
SELECT
*
FROM
employees
WHERE
hire_date >= '2000-01-01';SELECT
*
FROM
employees
HAVING
hire_date >= '2000-01-01';o
Ejemplo:
WHERE vs HAVING
Después de HAVING, puede tener una condición con una función agregada, mientras que WHERE no puede usar funciones agregadas dentro de sus condiciones
Ejemplo: queremos extraer una lista con todos lo nombres (first_name) que aparecen más de 250 veces en la tabla employees
SELECT
first_name, COUNT(first_name) AS names_count
FROM
employees
WHERE
COUNT(first_name) > 250
GROUP BY first_name
ORDER BY first_name DESC;SELECT
first_name, COUNT(first_name) AS names_count
FROM
employees
GROUP BY first_name
HAVING
COUNT(first_name) > 250
ORDER BY first_name DESC;Esta es la forma correcta, se usa having porque vamos a filtrar usando función de agregación
Ejercicio 24: seleccionar todos los empleados para quienes el salario promedio sea mayor que 120,000 por año. (101) registros
Ejercicio 25: compare la salida obtenida de ambas consultas.
sql_mode=only_full_group_by
SELECT
*, AVG(salary)
FROM
salaries
WHERE
salary > 120000
GROUP BY emp_no
ORDER BY emp_no;
SELECT
*, AVG(salary)
FROM
salaries
GROUP BY emp_no
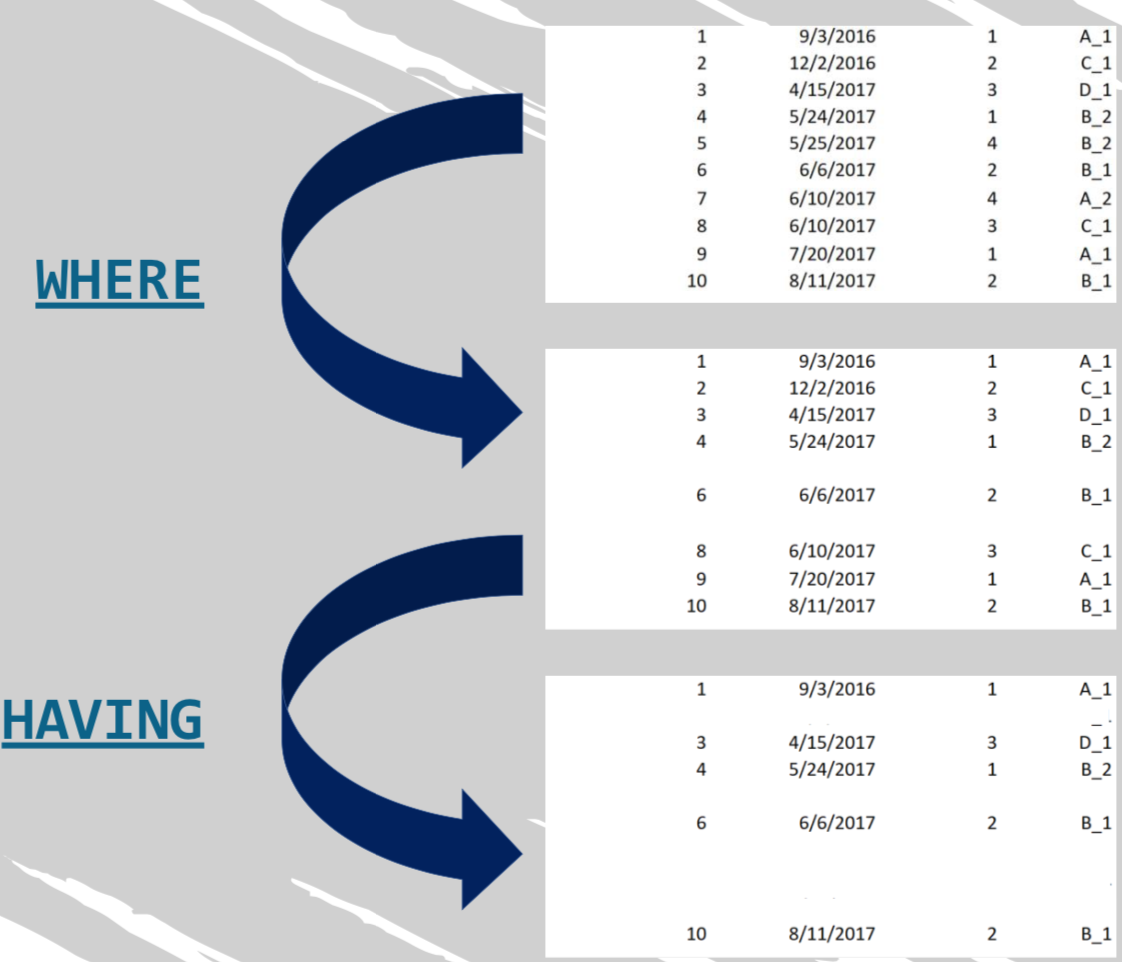
HAVING AVG(salary) > 120000;Where
Permite establecer un conjunto de condiciones que se refieren a un subconjunto de individual de filas.
Se aplica antes de reorganizar la salida en grupos
Reorganiza la salida en grupos
(GROUP_BY)
Ejemplo: extraer una lista de los nombre de empleados que aparecen menos que 200 veces. Permita que los datos se refieran a personas contratadas después del primero de enero de 1999.
SELECT
first_name, COUNT(first_name) AS name_count
FROM
employees
WHERE
hire_date > '1999-01-01'
GROUP BY first_name
HAVING COUNT(first_name) < 200
ORDER BY first_name DESC;HAVING
No puede tener una condición de agregación y no agregación en la cláusula HAVING
SELECT nombre_columna(s)
FROM nombre_tabla
WHERE condiciones
GROUP BY nombre_columna(s)
HAVING conditions
ORDER BY nombre_columna(s);
SELECT
first_name, COUNT(first_name) AS name_count
FROM
employees
GROUP BY first_name
HAVING COUNT(first_name) < 200 AND hire_date > '1999-01-01'
ORDER BY first_name DESC;¿Cuál es el problema aquí?
Para funciones de agregación
Usar GROUP BY - HAVING
Para condiciones generales
Usar WHERE
Ejercicio 26:
Seleccione los números de empleados de todas las personas que hayan firmado más de 1 contrato después del 1 de enero de 2000.
Sugerencia: Para resolver este ejercicio, use la tabla "dept_emp".
SELECT
emp_no
FROM
dept_emp
WHERE
from_date > '2000-01-01'
GROUP BY emp_no
HAVING COUNT(from_date) > 1
ORDER BY emp_no;SELECT nombre_columna(s)
FROM nombre_tabla
WHERE condiciones
GROUP BY nombre_columna(s)
HAVING condiciones
ORDER BY nombre_columna(s)
LIMIT número ;
Ejemplo:
Seleccione los números de empleados de los 10 (empleados) mejores pagados
SELECT
emp_no
FROM
salaries
ORDER BY salary DESC
LIMIT 10;Ejercicio 27:
Seleccione las primeras 100 filas de la tabla "dept_emp".
Antes de entrar al tema de subconsultas vamos a repasar la sentencia INSERT y UNION que son esenciales para temas avanzados de esta clase
INSERT INTO nombre_tabla (columna_1, columna_2, ..., columna_n) VALUES (valor_1, valor_2, ..., valor_n);
INSERT INTO employees
(
emp_no,
birth_date,
first_name,
last_name,
gender,
hire_date
) VALUES
(
999901,
'1986-04-01',
'John',
'Smith',
'M',
'2011-01-01'
);
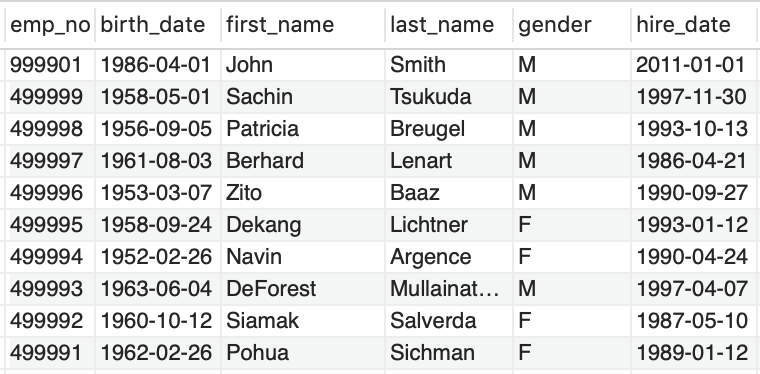
-- Para verificar la inserción
SELECT
*
FROM employees
ORDER BY emp_no DESC
LIMIT 10;Lo números se detallan sin comillas como convención. MySQL convierte de forma automática de String a number, pero consume tiempo.
INSERT INTO employees
(
birth_date,
emp_no,
first_name,
last_name,
gender,
hire_date
) VALUES
(
'1973-3-26',
999902,
'Patricia',
'Lawrance',
'F',
'2005-01-01'
);INSERT INTO employees
VALUES
(
999903,
'1977-09-14',
'Johnathan',
'Creek',
'M',
'1999-01-01'
);Ejercicio 28: Seleccione diez registros de la tabla de "titles" para tener una mejor idea sobre su contenido.
Sugerencia: ¡Para resolver este ejercicio, deberá insertar datos en solo 3 columnas!
Ejercicio 28: Seleccione diez registros de la tabla de "titles" para tener una mejor idea sobre su contenido.
SELECT
*
FROM
titles
LIMIT 10;
insert into titles
(
emp_no,
title,
from_date
)
values
(
999903,
'Senior Engineer',
'1997-10-01'
);
SELECT
*
FROM
titles
ORDER BY emp_no DESC;Ejercicio 29: Inserte información sobre el individuo con el número de empleado 999903 en la tabla "dept_emp". Él / Ella está trabajando para el departamento número 'd005', y comenzó a trabajar el 1 de octubre de 1997; su contrato es por tiempo indefinido.
Sugerencia: use la fecha "9999-01-01" para designar que el contrato es por un período indefinido.
Ejercicio 29: Inserte información sobre el individuo con el número de empleado 999903 en la tabla "dept_emp". Él / Ella está trabajando para el departamento número 'd005', y comenzó a trabajar el 1 de octubre de 1997; su contrato es por tiempo indefinido.
Sugerencia: use la fecha "9999-01-01" para designar que el contrato es por un período indefinido.
SELECT
*
FROM
dept_emp
ORDER BY emp_no DESC
LIMIT 10;
INSERT INTO dept_emp
(
emp_no,
dept_no,
from_date,
to_date
)
VALUES
(
999903,
'd005',
'1997-10-01',
'9999-01-01'
);INSERT INTO tabla_2 (columna_1, columna_2, ..., columna_n)
SELECT columna_1, columna_2, ..., columna_n
FROM tabla_1
WHERE condición;
SELECT
*
FROM
departments
LIMIT 10;
DROP TABLE departments_dup;
CREATE TABLE departments_dup(
dept_no CHAR(4) NOT NULL,
dept_name VARCHAR(40) NOT NULL
);
SELECT
*
FROM
departments_dup;
INSERT INTO departments_dup(
dept_no,
dept_name
)
SELECT
*
FROM
departments;Para explicar esta sección vamos a crear la tabla employees_dup que es un duplicado de la tabla employees y vamos a insertar en employees_dup los registros disponibles en employees
DROP TABLE IF EXISTS employees_dup;
CREATE TABLE employees_dup (
emp_no INT,
birth_date DATE,
first_name VARCHAR(14),
last_name VARCHAR(16),
gender ENUM('M', 'F'),
hire_date DATE
);
INSERT INTO employees_dup
SELECT
e.*
FROM
employees e
LIMIT 20;Vamos a duplicar el primer registro de employees_dup y verificamos.
INSERT INTO employees_dup VALUES
('10001', '1953-09-02', 'Georgi', 'Facello', 'M', '1986-06-26');
-- Verificamos que el registro se haya duplicado
SELECT
*
FROM
employees_dup;UNION ALL suele combinar algunas declaraciones SELECT en una sola salida.
- Puedes considerarlo como una herramienta que te permite unificar tablas
SELECT
N columnas
FROM tabla_1
UNION ALL SELECT
N columnas
FROM
tabla_2;
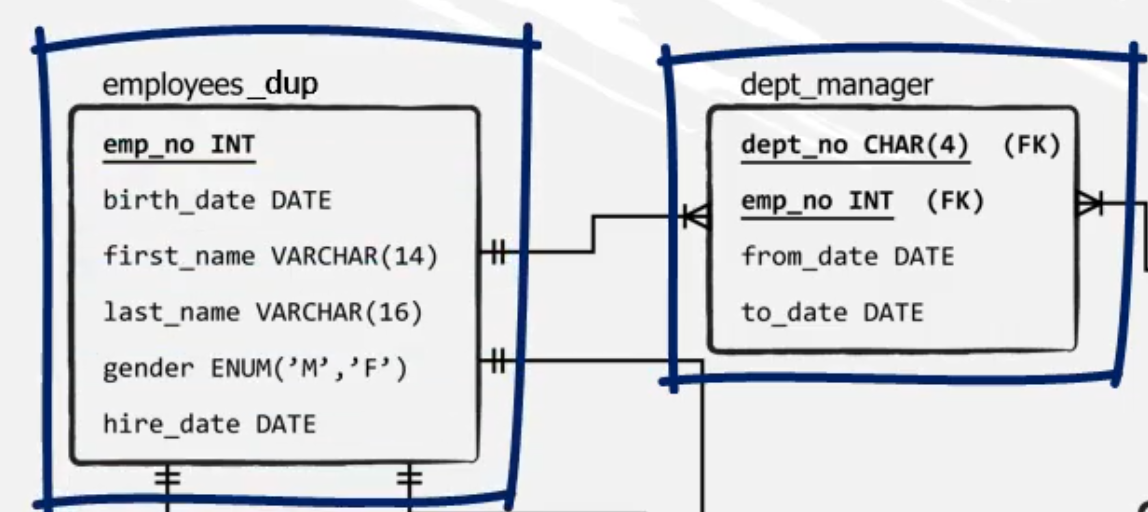
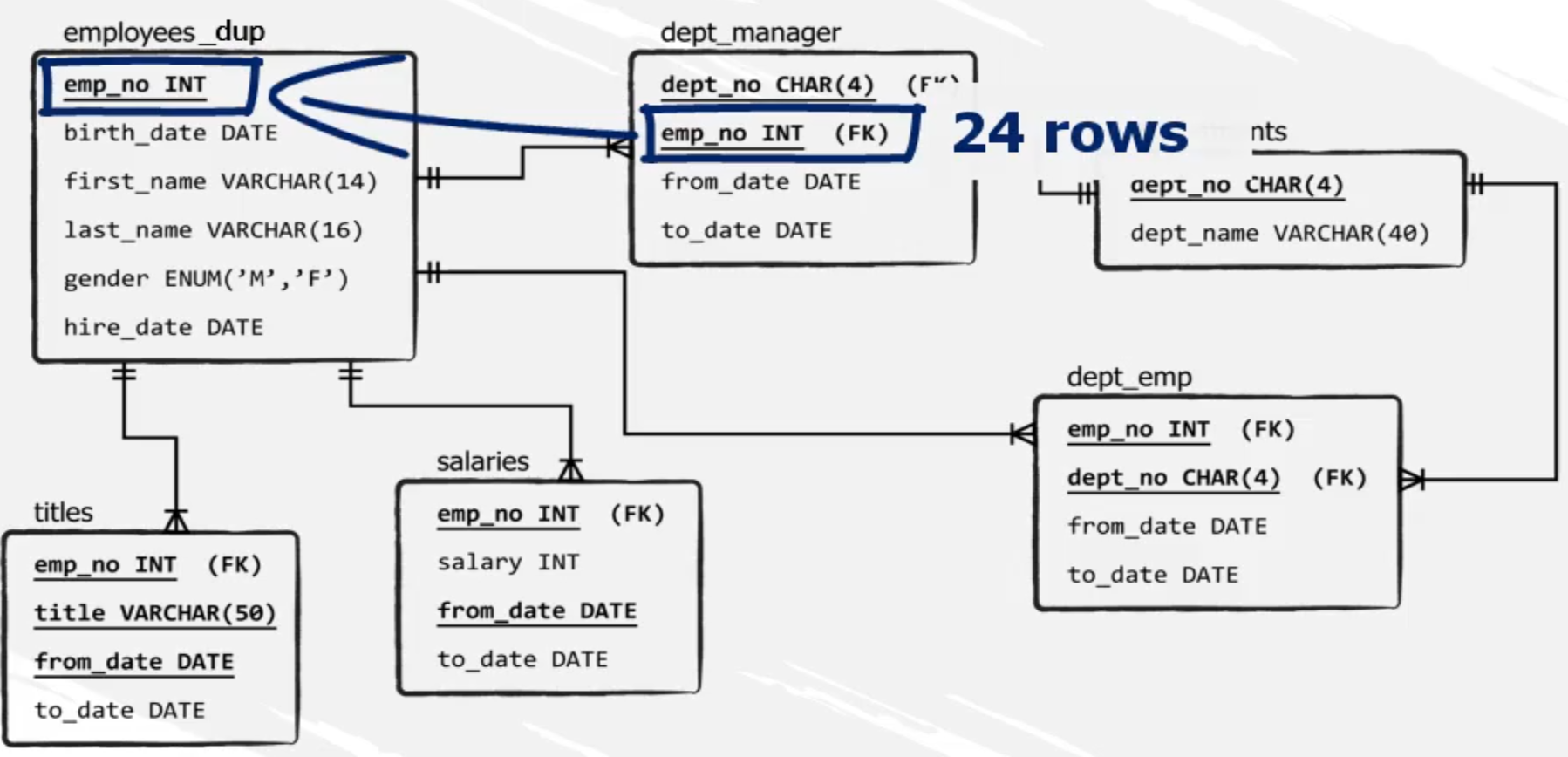
Ejemplo: a los registros de la tabla dept_manager (dept_no, from_date) queremos adjuntarle los registros de la tabla employees_dup (emp_no, first_name, last_name) para el empleado 10001.
En el esquema relacional vemos que las tablas difieren en el número de columnas y tienen nombres distintos en su mayoría.
Ejemplo: a los registros de la tabla dept_manager queremos adjuntarle los registros de la tabla employees_dup.
Para cumplir la regla de UNION ALL de que las columnas deben tener el mismo nombre, estar en el mismo orden y deben contener tipos de datos relacionados, simplemente rellenamos los campos faltantes en cada tabla
SELECT
e.emp_no,
e.first_name,
e.last_name,
NULL AS dept_no,
NULL AS from_date
FROM
employees_dup e
WHERE
e.emp_no = 10001
UNION ALL SELECT
NULL AS emp_no,
NULL AS first_name,
NULL AS last_name,
m.dept_no,
m.from_date
FROM
dept_manager m;26 filas
Al unir dos tablas organizadas idénticamente
- UNION muestra solo valores distintos en la salida
- UNION usa más recursos MySQL (potencia computacional y espacio de almacenamiento)
- UNION ALL recupera los duplicados también
Con UNION se omiten los duplicados
SELECT
e.emp_no,
e.first_name,
e.last_name,
NULL AS dept_no,
NULL AS from_date
FROM
employees_dup e
WHERE
e.emp_no = 10001
UNION SELECT
NULL AS emp_no,
NULL AS first_name,
NULL AS last_name,
m.dept_no,
m.from_date
FROM
dept_manager m;25 filas
Buscando mejores resultados? - use UNION
¿Buscas optimizar el rendimiento? - opta por UNION ALL
Subconsultas: son consultas incrustadas en una consulta. Es decir, son consultas internas (INNER QUERY), consultas anidadas (NESTED QUERY) o selección interna (INNER SELECT)
SUBCONSULTA = CONSULTAS INTERNAS = CONSULTAS ANIDADAS = SELECCIÓN INTERNA
La consulta externa es OUTER QUERY
Ejemplo: seleccione el nombre (first_name) y apellido (last_name) de los empleados (employees) cuyos números de empleados (emp_no) aparecen en la tabla gerentes de departamentos (dept_manager)
Podemos visualizar los emp_no (números de empleados) que aparecen en la tabla dept_manager (24), pero para obtener el nombre y apellido también debemos consultar la tabla employees. Una forma de solución sería con subconsultas.
Ejemplo: seleccione el nombre (first_name) y apellido (last_name) de los empleados (employees) cuyos números de empleados (emp_no) aparecen en la tabla gerentes de departamentos (dept_manager)
SELECT
e.first_name, e.last_name
FROM
employees e
WHERE
e.emp_no IN (SELECT
dm.emp_no
FROM
dept_manager dm);A esto llamamos: Subconsultas anidadas con IN dentro de un WHERE
Una subconsulta siempre debe colocarse entre paréntesis
1) El motor SQL comienza ejecutando la consulta interna
2) Luego usa su salida devuelta, que es intermedia, para ejecutar la consulta externa
Una subconsulta puede devolver un solo valor (un escalar), una sola fila, una sola columna o una tabla completa
- Puede tener más de una subconsulta en su consulta externa
- Es posible anidar consultas internas dentro de otras consultas internas. En ese caso, el motor SQL ejecutaría primero la consulta más interna y luego cada consulta posterior, hasta que ejecute la última consulta más externa
Ejercicio: Extraiga la información sobre todos los gerentes de departamento que fueron contratados entre el 1 de enero de 1990 y el 1 de enero de 1995.
Ejercicio: Extraiga la información sobre todos los gerentes de departamento que fueron contratados entre el 1 de enero de 1990 y el 1 de enero de 1995.
SELECT
*
FROM
dept_manager
WHERE
emp_no IN (SELECT
emp_no
FROM
employees
WHERE
hire_date BETWEEN '1990-01-01' AND '1995-01-01'); Solución 1:
Ejercicio: Extraiga la información sobre todos los gerentes de departamento que fueron contratados entre el 1 de enero de 1990 y el 1 de enero de 1995.
SELECT
*
FROM
employees
WHERE
(hire_date BETWEEN '1990-01-01' AND '1995-01-01')
AND emp_no IN (SELECT
emp_no
FROM
dept_manager);Solución 2:
EXISTS comprueba si ciertos valores de fila (consulta externa) se encuentran dentro de una subconsulta
- Esta comprobación se realiza fila por fila
- Devuelve un valor booleano
Si el valor de la fila de la subconsulta existe
Si el valor de la fila de la subconsulta no existe
True
False
se extrae el registro correspondiente de la consulta externa
no se extrae ningún valor de fila de la consulta externa
Ejemplo: seleccione el nombre (first_name) y apellido (last_name) de los empleados (employees) cuyos números de empleados (emp_no) aparecen en la tabla gerentes de departamentos (dept_manager)
SELECT
e.first_name, e.last_name
FROM
employees e
WHERE
EXISTS( SELECT
*
FROM
dept_manager dm
WHERE
e.emp_no = dm.emp_no);Prueba la existencia de valores de fila
Más rápido en recuperar grandes cantidades de datos
Búsquedas entre valores
Más rápido con conjuntos de datos pequeños
EXISTS
IN
ORDER BY (consultas anidadas)
Es más profesional aplicar ORDER BY en la consulta externa.
- Es lógicamente más aceptable ordenar la versión final de su conjunto de datos
SELECT
e.first_name, e.last_name
FROM
employees e
WHERE
EXISTS( SELECT
*
FROM
dept_manager dm
WHERE
e.emp_no = dm.emp_no)
ORDER BY e.emp_no;Algunas, aunque no todas, las consultas anidadas pueden reescribirse usando JOIN, que son más eficientes en general
Esto es cierto especialmente para consultas internas que utilizan la cláusula WHERE
Subconsultas
- Permite una mejor estructuración de la consulta externa. Por lo tanto, cada consulta interna se puede considerar de forma aislada, de ahí el nombre de SQL - ¡Lenguaje de consulta estructurado!
- En algunas situaciones, el uso de subconsultas es mucho más intuitivo en comparación con el uso de JOIN complejas
- Muchos usuarios prefieren las subconsultas simplemente porque ofrecen una legibilidad de código mejorada
Ejercicio: Seleccione la información completa para todos los empleados cuyo cargo es Asistente de ingeniero (Assistant Engineer).
Sugerencia: Para resolver este ejercicio, use la tabla 'employees'.
Ejercicio: Seleccione la información completa para todos los empleados cuyo cargo es Asistente de ingeniero (Assistant Engineer).
Solución
SELECT
*
FROM
employees e
WHERE
EXISTS( SELECT
*
FROM
titles t
WHERE
t.emp_no = e.emp_no
AND title = 'Assistant Engineer');Ejercicio: Asigne el número de empleado 110022 como gerente de todos los empleados desde el 10001 hasta el 10020 y el empleado número 110039 como gerente de todos los empleados desde el 10021 al 10040.
Solución:
SELECT
A.*
FROM
(SELECT
e.emp_no AS Employee_ID,
MIN(de.dept_no) AS Depatment,
(SELECT
emp_no
FROM
dept_manager
WHERE
emp_no = 110022) AS Manager_ID
FROM
employees e
JOIN
dept_emp de ON e.emp_no = de.emp_no
WHERE
e.emp_no <= 10020
GROUP BY e.emp_no
ORDER BY e.emp_no) AS A
UNION
SELECT
B.*
FROM
(SELECT
e.emp_no AS Employee_ID,
MIN(de.dept_no) AS Depatment,
(SELECT
emp_no
FROM
dept_manager
WHERE
emp_no = 110039) AS Manager_ID
FROM
employees e
JOIN
dept_emp de ON e.emp_no = de.emp_no
WHERE
e.emp_no >= 10021
GROUP BY e.emp_no
ORDER BY e.emp_no
LIMIT 20) AS B;Ejercicio-parte 1: Comenzando su código con "DROP TABLE", cree una tabla llamada “emp_manager” (emp_no – integer, not null; dept_no – CHAR de 4, null; manager_no – integer, not null).
Resuelva
Ejercicio-parte 2:
Llene emp_manager con datos sobre los empleados, el número del departamento en el que están trabajando y sus gerentes.
Su esqueleto de consulta debe ser:
Insertar en emp_manager SELECT
U. *
FROM
(A)
UNION (B) UNION (C) UNION (D) AS U;
A y B deben ser los mismos subconjuntos utilizados en la última clase (subconsultas SQL anidadas en SELECT y FROM). En otras palabras, asigne el número de empleado 110022 como gerente a todos los empleados de 10001 a 10020 (esto debe ser el subconjunto A), y el número de empleado 110039 como gerente a todos los empleados de 10021 a 10040 (esto debe ser el subconjunto B).
Use la estructura del subconjunto A para crear el subconjunto C, donde debe asignar el número de empleado 110039 como gerente al empleado 110022.
Siguiendo la misma lógica, cree el subconjunto D. Aquí debe hacer lo contrario: asignar el empleado 110022 como gerente al empleado 110039.
Su salida debe contener 42 filas.
¡Buena suerte!
Podemos usar un índice para aumentar la velocidad de las búsquedas relacionadas con una tabla
CREATE INDEX nombre_índice ON nombre_tabla (columna_1, columna_2, ...);
Estos deben ser campos de su tabla por los cuales
buscará con frecuencia (esto se llama optimización)
Ejemplo:
¿Cuántas personas han sido contratadas después del primero de enero de 2000?
SELECT
*
FROM
employees
WHERE
hire_date > '2000-01-01';
CREATE INDEX i_hire_date ON employees(hire_date);
SELECT
*
FROM
employees
WHERE
hire_date > '2000-01-01';
Vamos a crear índice sobre el WHERE
El tiempo de respuesta es mucho menor
CREATE INDEX nombre_índice ON nombre_tabla (columna_1, columna_2, ...);
¡Elija cuidadosamente las columnas que optimizarían su búsqueda!
Seleccionar todos los empleados que llevan el nombre "Georgi Facello"
SELECT
*
FROM
employees
WHERE
first_name = 'Georgi'
AND last_name = 'Facello';CREATE INDEX i_composite ON employees(first_name, last_name);
SELECT
*
FROM
employees
WHERE
first_name = 'Georgi'
AND last_name = 'Facello';El tiempo de respuesta es mucho menor
Las claves primarias (PRIMARY KEY) y UNIQUE son índices en MySQL
Los especialistas en SQL siempre buscan un buen equilibrio entre la mejora de la velocidad de búsqueda y los recursos utilizados para su ejecución.
Conjunto de datos (dataset o tablas) pequeñas
Conjunto de datos (dataset o tablas) grandes
Los costos de tener un índice podrían ser más alto que los beneficios
Un índice bien optimizado puede tener un impacto positivo en el proceso de búsqueda
Ejercicio: Elimine el índice "i_hire_date".
ALTER TABLE employees
DROP INDEX i_hire_date;Ejercicio:
Seleccione todos los registros de la tabla de "salaries" de personas cuyo salario sea superior a $ 89,000 por año.
Luego, cree un índice en la columna "salary" de esa tabla y verifique si ha acelerado la búsqueda de la misma instrucción SELECT.
Ejercicio:
Seleccione todos los registros de la tabla de "salaries" de personas cuyo salario sea superior a $ 89,000 por año.
Luego, cree un índice en la columna "salary" de esa tabla y verifique si ha acelerado la búsqueda de la misma instrucción SELECT.
SELECT
*
FROM
salaries
WHERE
salary > 89000;
CREATE INDEX i_salary ON salaries(salary);
SELECT
*
FROM
salaries
WHERE
salary > 89000;Solución
La declaración COMMIT (Compromiso)
- Guarda la transacción en la base de datos
- Los cambios no se pueden deshacer
La cláusula ROLLBACK
- Te permite dar un paso atrás
- Los últimos cambios realizados no contarán
- Vuelve al último estado no comprometido (non-committed)
Utilizado para guardar el estado de los datos en la base de datos en el momento de su ejecución
Se referirá al estado correspondiente a la última vez que ejecutó el COMMIT
- ROLLBACK tendrá un efecto en la última ejecución que se haya realizado.
- No puede restaurar los datos a un estado correspondiente a un COMMIT anterior.
En este caso todos los ROLLBACK restauran los datos del último COMMIT, por lo que los COMMIT anteriores al décimo COMMIT ya no pueden manipularse
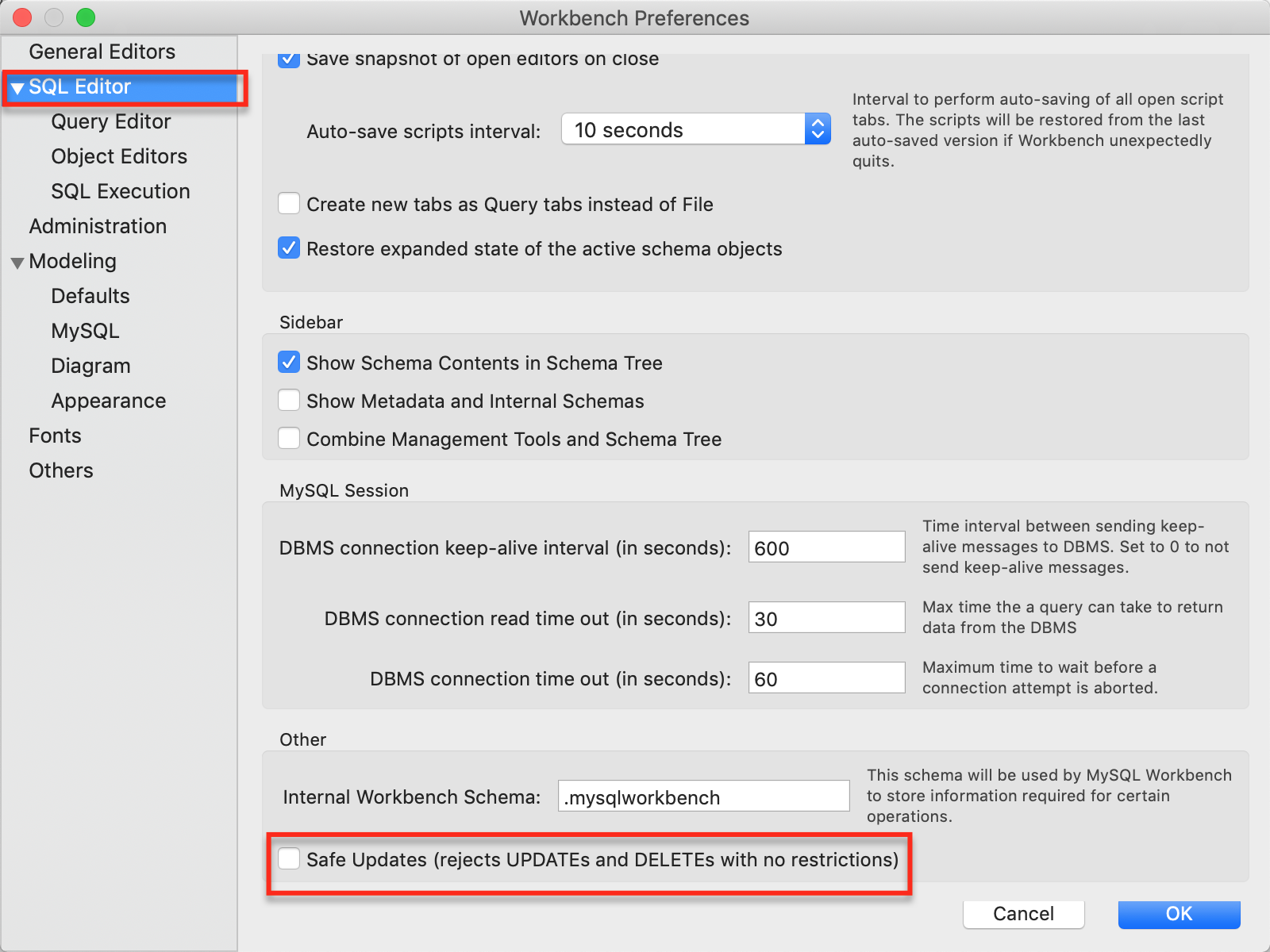
Hay que expandir las funcionalidades de Workbench, para ello vaya al menú edit/preferences. Seleccione la sección SQL Editor y desactive la opción Safe Updates
Lo que hicimos anteriormente fue quitar la opción que impide la actualización y eliminación sin restricciones (condiciones) esta opción impide que borremos datos de forma inesperada en alguna instrucción de eliminación o actualización, por ejemplo imagine un DELETE sin WHERE borraría todo, por lo que esta opción impide ese tipo de errores, pero también quita la posibilidad de controlar el estado de los datos en nuestra Base de Datos, lo cual es precisamente el objetivo de esta clase, por eso la hemos desactivado.
Se utiliza para actualizar los valores de registros existentes en una tabla
UPDATE nombre_tabla
SET columna_1 = valor_1, columna_2 = valor_2 ... WHERE condiciones;
- No tenemos que actualizar cada valor del registro en cuestión, basta con fijar las columnas que deseamos modificar
- Al ejecutarse un UPDATE podemos decir que hemos actualizado de forma permanente el/los registros específicos
- Si no proporciona una condición WHERE, todas las filas de la tabla se actualizarán
Ejemplo 1: actualizar la información del empleado número: 999901
USE employees;
SELECT
*
FROM
employees
WHERE
emp_no = 999901;
UPDATE employees
SET
first_name = 'Stella',
last_name = 'Parkinson',
birth_date = '1900-12-31',
gender = 'F'
WHERE
emp_no = 999901;Ejemplo 2: actualizar la tabla departments_dup y luego hacer un rollback
SET SQL_SAFE_UPDATES = 0;
SET autocommit=0;
TRUNCATE departments_dup;
INSERT INTO departments_dup
SELECT * FROM departments;
SELECT
*
FROM
departments_dup
ORDER BY dept_no;
COMMIT;
UPDATE departments_dup
SET
dept_no = 'd001',
dept_name= 'Quality Control';
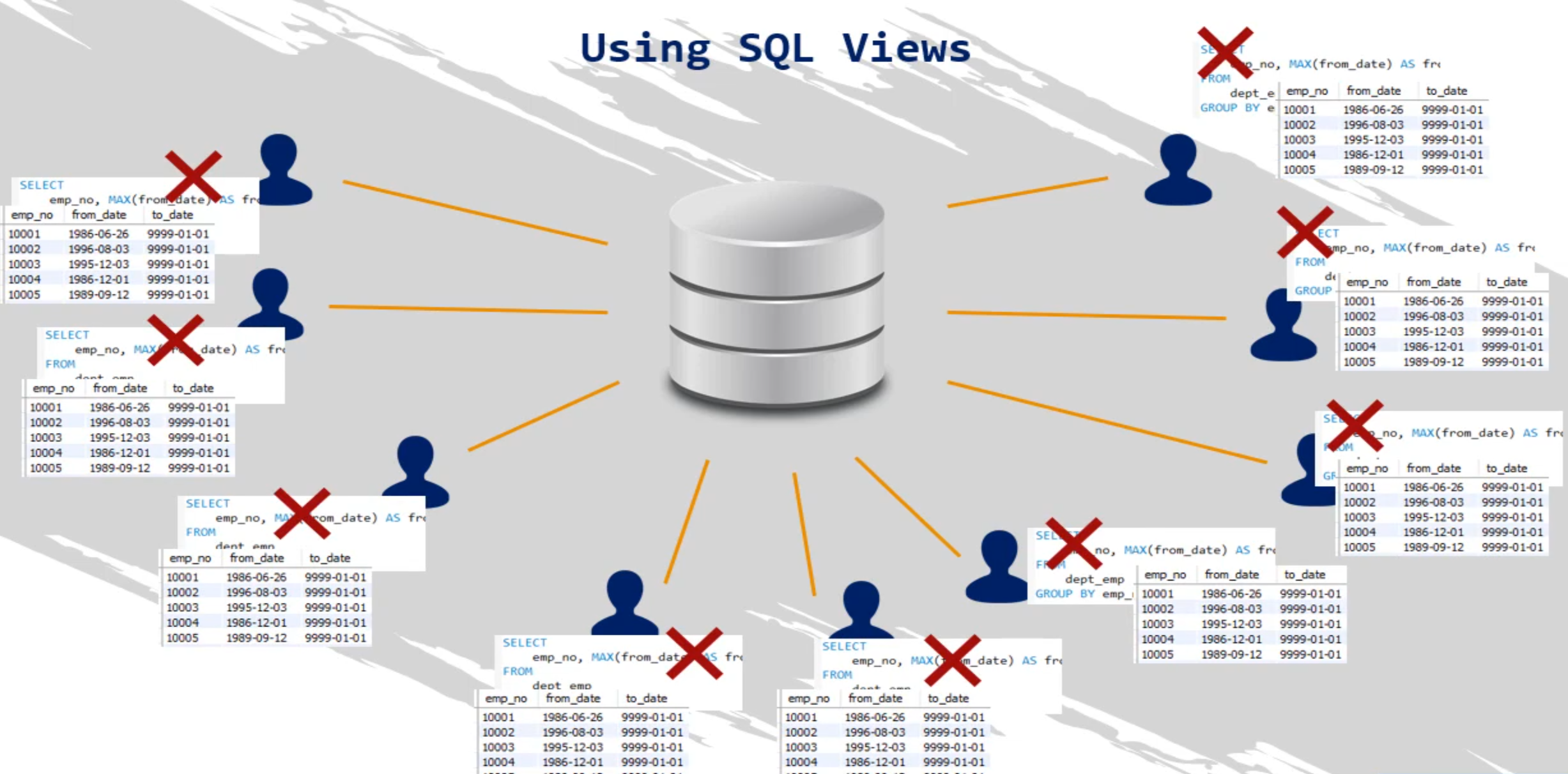
ROLLBACK;Es una una tabla virtual cuyo contenido se obtiene de una tabla o tablas existentes, llamadas tablas base
La recuperación ocurre a través de una declaración SQL, incorporada en la vista
Obtener el código de los empleados que han sido registradas más de una vez en la tabla dept_emp
USE employees;
-- Esta linea permite agregar columnas en el SELECT sin necesidad de agrupar
-- por esas columnas
SET GLOBAL sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
SELECT
emp_no, from_date, to_date, COUNT(emp_no) AS num
FROM
dept_emp
GROUP BY emp_no
HAVING num > 1;¿Por qué crear una vista de la consulta anterior?
- La vista en sí no contienen ningún dato real; los datos se almacenan físicamente en la tabla base
- La vista simplemente muestran los datos contenidos en la tabla base
CREATE VIEW nombre_vista AS SELECT
columna_1, columna_2,... columna_n FROM
nombre_tabla;
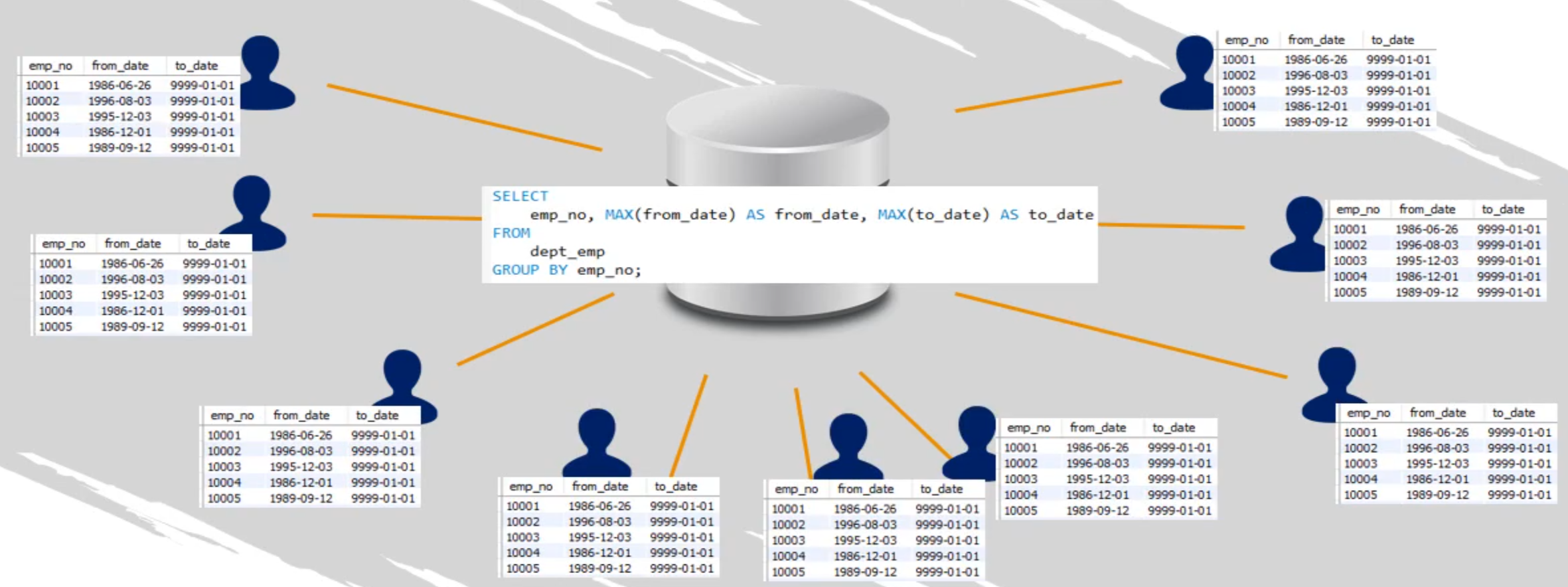
Imagine que desea visualizar solo el período que abarca el último contrato de cada empleado
CREATE OR REPLACE VIEW v_dept_emp_lastest_date AS
SELECT
emp_no, MAX(from_date) AS from_date, MAX(to_date) AS to_date
FROM
dept_emp
GROUP BY emp_no;
SELECT * FROM employees.dept_emp_latest_date; Crear vistas puede parecer redundante, porque solo bastaría con ejecutar directamente la consulta SQL y obtener los datos
Una vista actúa como un acceso directo para escribir la misma instrucción SELECT cada vez que se realiza una nueva solicitud.
- Ahorran mucho tiempo de codificación
- No ocupan memoria adicional
- Actúan como una tabla dinámica porque reflejan instantáneamente datos y cambios estructurales en la tabla base
Por ejemplo si actualiza en la tabla base el campo to_date del emp_no 10001dicho cambio se refleja al consulta la vista
- No olvide que no son conjuntos de datos físicos reales, lo que significa que no podemos insertar o actualizar la información que ya se ha extraído.
- Deberían verse como tablas de datos virtuales temporales que recuperan información de las tablas base
Ejercicio: Cree una vista que extraiga el salario promedio de todos los gerentes registrados en la base de datos. Redondea este valor al centavo más cercano.
Ejercicio: Cree una vista que extraiga el salario promedio de todos los gerentes registrados en la base de datos. Redondea este valor al centavo más cercano.
Solución:
CREATE OR REPLACE VIEW v_manager_avg_salary AS
SELECT
ROUND(AVG(s.salary))
FROM
salaries s INNER JOIN dept_manager m
ON s.emp_no = m.emp_no;
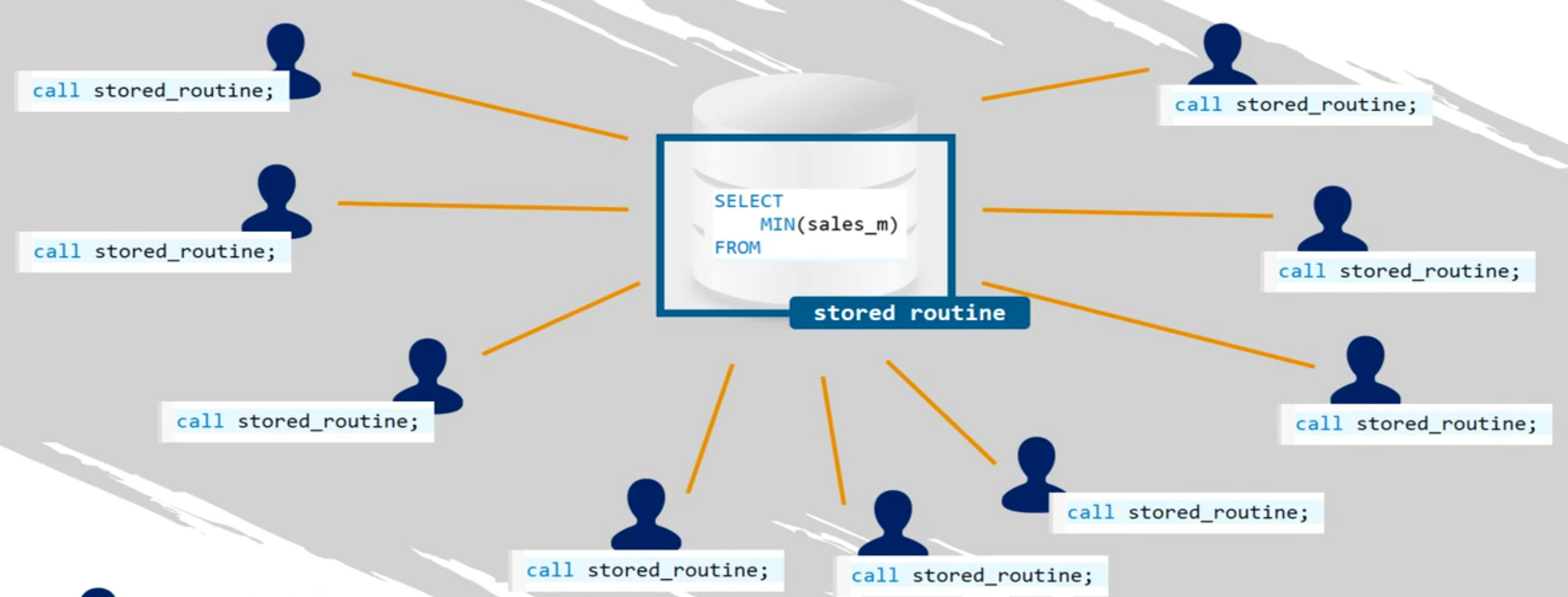
SELECT * from employees.v_manager_avg_salary;rutina (en un contexto que no sea informática): es una acción habitual o fija, o una serie de acciones, que se repite periódicamente
rutina almacenada
Es una declaración SQL, o un conjunto de declaraciones SQL, que se pueden almacenar en el servidor de bases de datos
- Cada vez que un usuario necesita ejecutar la consulta en cuestión, puede llamar (call), hacer referencia (reference) o invocar la rutina (invoke)
stored rutines
stored procedures
functions
= procedimientos almacenados
= son funciones definidas por el usuario
No es AVG, SUM, MAX, MIN, etc. (Agregación)
(stored procedure)
Punto y coma (;)
- Se usa para terminar una declaración
- Técnicamente, también pueden llamarse delimitador
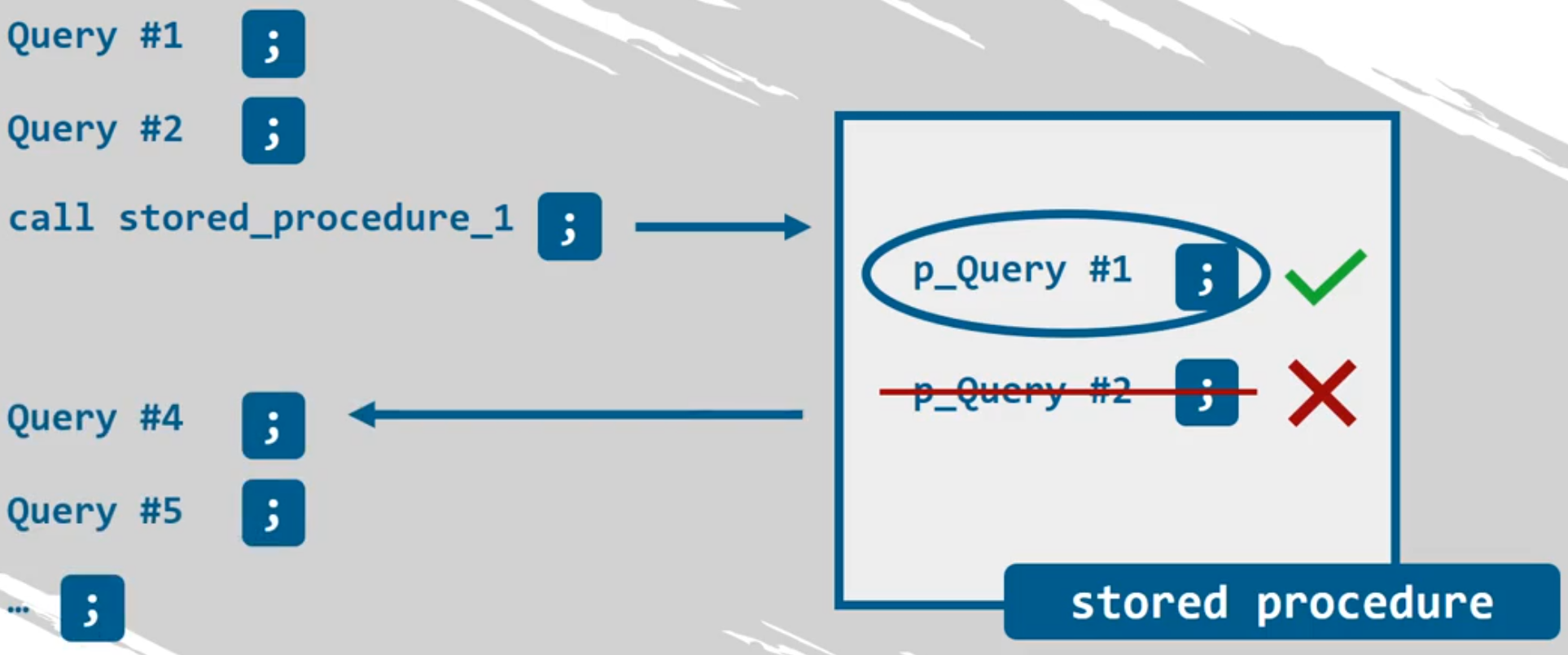
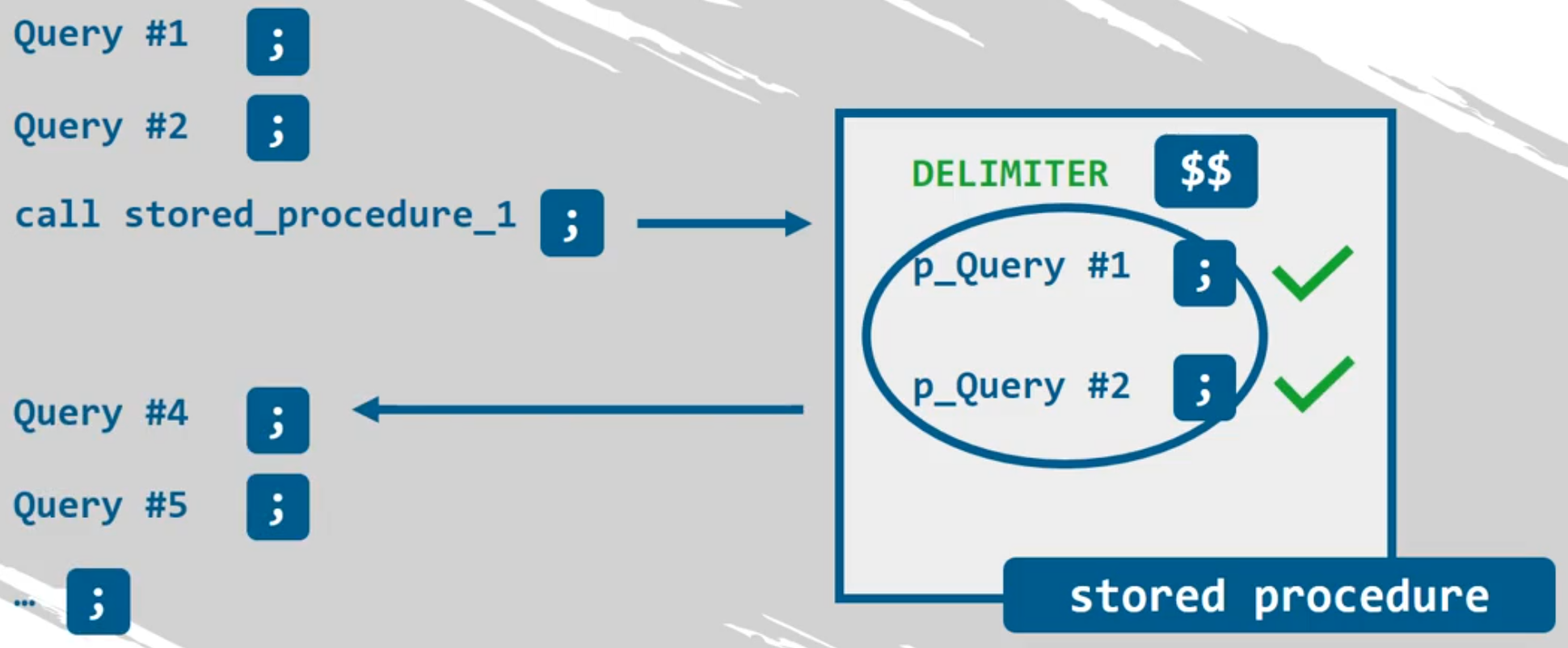
Escribiendo DELIMITER $$, podrá usar los símbolos de dólar como delimitador y así no nos confundimos con el punto y coma que hemos venido usando.
Si el delimitador es el punto y coma, se ejecutan las Query #1 y Query #2, pero al llamar al procedimiento almacenado solo se ejecuta p_Query #1 porque encuentra el punto y coma e inmediatamente sale del procedimiento y p_Query #2 nunca se ejecutará.
Para solucionar el problema anterior se cambia el delimitador en la definición del procedimiento almacenado con $$ o //
Ejemplo sencillo de procedimiento almacenado sin tablas
DELIMITER $$
CREATE PROCEDURE HolaMundo()
BEGIN
SELECT "Hola Mundo";
SELECT "Wilfredo";
END$$
DELIMITER ;
CALL HolaMundo();
DROP PROCEDURE IF EXISTS HolaMundo;Modificar un procedimiento almacenado
DELIMITER $$
CREATE PROCEDURE HolaMundo()
BEGIN
SELECT "Hola Mundo";
END$$
DELIMITER ;Realmente lo que debemos hacer es escribir el código PA (Procedimiento Almacenado) con los ajustes, eliminar el PA anterior y ejecutar la creación del nuevo.
Veamos un ejemplo muy general
Cuerpo (Body) del PA
Consulta (Query)
Puede o no tener parámetros
Desde este momento $$ ya no actuará como delimitador
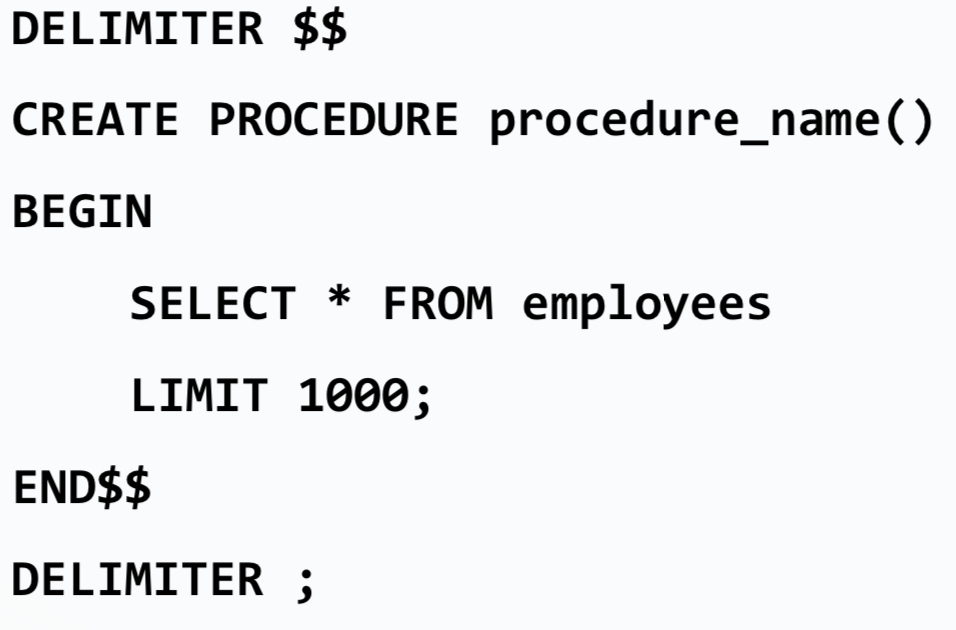
Ejemplo: retornar las primeras 1000 filas de la tabla employees
-- Cuando se elimina un procedimiento que no tiene parámetros
-- se pueden omitir los paréntesis al final del nombre
DROP PROCEDURE IF EXISTS select_employees;
DELIMITER $$
CREATE PROCEDURE select_employees()
BEGIN
SELECT
*
FROM
employees
LIMIT 1000;
END$$
DELIMITER ;Para ejecutar el procedimiento almacenado que acabamos de crear
call employees.select_employees();
-- o puede ser así aprovechando que antes hemos ejecutado
-- el comando USE employees
call select_employees();Ejercicio: retornar las primeras 1000 filas de la tabla salaries
Ejercicio:
Cree un procedimiento que proporcione el salario promedio de todos los empleados.
Luego, llame al procedimiento.
Borrar un procedimiento almacenado
DROP PROCEDURE IF EXISTS select_salaries;
Ejemplo: imagine que desea obtener las columnas: first_name, last_name, salary, from_date y to_date de un empleado en particular
DELIMITER $$
USE employees $$
CREATE PROCEDURE emp_salary(IN p_emp_no INTEGER)
BEGIN
SELECT
e.first_name, e.last_name, s.salary, s.from_date, s.to_date
FROM
employees e
JOIN
salaries s
ON e.emp_no = s.emp_no
WHERE
e.emp_no = p_emp_no;
END$$
DELIMITER ;
CALL emp_salary(11300);Ejemplo: imagine que desea obtener las columnas: first_name, last_name, y el salario promedio de un empleado en particular
DELIMITER $$
USE employees $$
CREATE PROCEDURE avg_emp_salary(IN p_emp_no INTEGER)
BEGIN
SELECT
e.first_name, e.last_name, AVG(s.salary)
FROM
employees e
JOIN
salaries s
ON e.emp_no = s.emp_no
WHERE
e.emp_no = p_emp_no;
END$$
DELIMITER ;
CALL avg_emp_salary(11300);Representará la variable que contiene el valor de salida de la operación ejecutada por la consulta del procedimiento almacenado
SELECT
AVG(salary), MAX(salary)
INTO @avg_salary, @max_salary
FROM
salaries;
SELECT @avg_salary, @max_salary;DELIMITER $$
USE employees $$
CREATE PROCEDURE emp_avg_salary_out(IN p_emp_no INTEGER, OUT p_avg_salary DECIMAL(10, 2))
BEGIN
SELECT
AVG(s.salary)
INTO p_avg_salary FROM
employees e
JOIN
salaries s
ON e.emp_no = s.emp_no
WHERE
e.emp_no = p_emp_no;
END$$
DELIMITER ;
set @p_avg_salary = 0;
call employees.emp_avg_salary_out(11300, @p_avg_salary);
SELECT @p_avg_salary;Ejercicio: obtener el salario promedio de un empleado en particular y almacenar el resultado en un parámetro de salida
DROP PROCEDURE IF EXISTS name_and_last_name;
DELIMITER $$
CREATE PROCEDURE name_and_last_name(IN p_emp_no INT, OUT p_first_name VARCHAR(14), OUT p_last_name VARCHAR(16))
BEGIN
SELECT
first_name, last_name
INTO p_first_name, p_last_name FROM
employees
WHERE
emp_no = p_emp_no;
END$$
DELIMITER ;
SET @first_name = '';
SET @last_name = '';
CALL name_and_last_name(11300, @first_name, @last_name);
SELECT @first_name, @last_name;Ejercicio: Obtener el nombre y apellido de un empleado cualquiera
Cada vez que crea un procedimiento que contiene parámetros tanto IN como OUT, recuerde que debe usar la estructura SELECT-INTO en la consulta
del cuerpo de este objeto!
Ejercicio: Cree un procedimiento llamado "emp_info" que utilice como parámetros el nombre y el apellido de un individuo y devuelva su número de empleado.
DROP PROCEDURE IF EXISTS calculator;
DELIMITER $$
CREATE PROCEDURE calculator(IN p_num1 INT, IN p_num2 INT, p_operator CHAR(1))
BEGIN
IF p_operator = '+' THEN
SELECT p_num1 + p_num2;
ELSEIF p_operator = '-' THEN
SELECT p_num1 - p_num2;
ELSEIF p_operator = '*' THEN
SELECT p_num1 * p_num2;
ELSEIF p_operator = '/' THEN
SELECT p_num1 / p_num2;
ELSE
SELECT 'OPERADOR DESCONOCIDO';
END IF;
END$$
DELIMITER ;
CALL calculator(8, 4, '/');Para más información: https://www.mysqltutorial.org/mysql-if-statement/
Dos tipos:
Estructura de base de datos inicial para esta clase
DROP DATABASE IF EXISTS test;
CREATE DATABASE test;
USE test;
CREATE TABLE accounts(
id INT PRIMARY KEY,
balance NUMERIC(7, 2)
);
INSERT INTO accounts VALUES(1, 300.00);
INSERT INTO accounts VALUES(2, 800.00);
SELECT * FROM accounts;DROP PROCEDURE IF EXISTS withdraw;
DELIMITER $$
CREATE PROCEDURE withdraw()
BEGIN
DECLARE test INT;
SET test := 7;
SELECT test;
END$$
DELIMITER ;
CALL withdraw();Declarar variables en procedimientos almacenados
DROP PROCEDURE IF EXISTS withdraw;
DELIMITER $$
CREATE PROCEDURE withdraw(IN account_id INT, IN amount NUMERIC(7, 2), OUT success BOOL)
BEGIN
DECLARE current_balance NUMERIC(7, 2) default 0.0;
SELECT balance INTO current_balance FROM accounts WHERE id = account_id;
IF current_balance >= amount THEN
UPDATE accounts SET balance = balance - amount WHERE id = account_id;
SET success = true;
ELSE
SET success = false;
END IF;
END$$
DELIMITER ;
CALL withdraw(1, 50.00, @success);
SELECT @success;Implementar withdraw
SELECT 3;
SELECT 'Juan';
SET @user = "Juan";
SELECT @user;
set @some_value = 99;
select @some_value;
set @min_value = 300.00;
select * from accounts where balance > @min_value;SELECT * FROM plants;
SHOW ERRORS;
SELECT balance INTO @current_balance FROM accounts WHERE id = 7;
SHOW WARNINGS;
SELECT @current_balance;DROP PROCEDURE IF EXISTS withdraw;
DELIMITER $$
CREATE PROCEDURE withdraw(IN account_id INT, IN amount NUMERIC(7, 2), OUT success BOOL)
BEGIN
DECLARE current_balance NUMERIC(7, 2) default 0.0;
DECLARE EXIT HANDLER FOR 1146
BEGIN
SELECT "LA TABLA NO EXISTE";
END;
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
SHOW ERRORS;
END;
DECLARE EXIT HANDLER FOR SQLWARNING
BEGIN
SHOW WARNINGS;
END;
START TRANSACTION;
SELECT balance INTO current_balance FROM accounts WHERE id = account_id FOR UPDATE;
IF current_balance >= amount THEN
UPDATE accounts SET balance = balance - amount WHERE id = account_id;
SET success = true;
ELSE
SET success = false;
END IF;
COMMIT;
END$$
DELIMITER ;
CALL withdraw(1, 50.00, @success);
SELECT @success;Ver documentación oficial sobre como manejar diversos avisos y errores: https://dev.mysql.com/doc/refman/8.0/en/declare-handler.html
Hemos visto en los conceptos anteriores las instrucciones de MySQL que nos permiten definir estructuras condicionales dentro de los procedimientos almacenados.
Ahora veremos qué comandos disponemos para repetir bloques de instrucciones.
La primer estructura repetitiva que disponemos y es común a la mayoría de los lenguajes de programación es el 'while'.
WHILE condición DO
lista_de_sentencias
END WHILE;
DELIMITER $$
CREATE PROCEDURE whiledemo()
BEGIN
DECLARE count INT DEFAULT 0;
DECLARE numbers VARCHAR(30) DEFAULT "";
WHILE count < 10 DO
SET numbers = CONCAT(numbers, count);
SET count := count + 1;
END WHILE;
SELECT numbers;
END$$
DELIMITER ;
DROP PROCEDURE whiledemo;
CALL whiledemo();[etiqueta:] LOOP
lista_de_sentencias
END LOOP [etiqueta]
DELIMITER $$
CREATE PROCEDURE loopdemo()
BEGIN
DECLARE count INT DEFAULT 0;
DECLARE numberlist VARCHAR(30) DEFAULT "";
the_loop: LOOP
IF count =10 THEN
LEAVE the_loop;
END IF;
SET numberlist := CONCAT(numberlist, count);
IF count != 9 THEN
SET numberlist := CONCAT(numberlist, ", ");
END IF;
SET count := count + 1;
END LOOP;
SELECT numberlist;
END$$
DELIMITER ;
DROP PROCEDURE loopdemo;
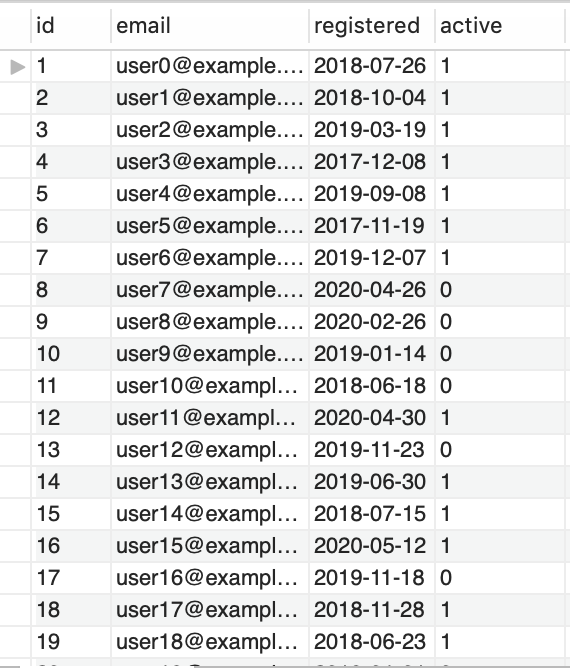
CALL loopdemo();Crear un procedimiento que permita agregar 1000 registros aleatorios a la tabla users de la base de datos test como se muestra a continuación:
DROP PROCEDURE testdata;
DELIMITER $$
CREATE PROCEDURE testdata()
BEGIN
DECLARE NUMROWS INT DEFAULT 1000;
DECLARE count INT DEFAULT 0;
DECLARE registered_value DATE DEFAULT NULL;
DECLARE email_value VARCHAR(40) DEFAULT NULL;
DECLARE active_value BOOLEAN DEFAULT FALSE;
DROP TABLE IF EXISTS users;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(40) NOT NULL,
registered DATE NOT NULL,
active BOOL DEFAULT FALSE
);
WHILE count < NUMROWS DO
SET registered_value = DATE(NOW()) - INTERVAL FLOOR(1000*RAND()) DAY;
SET active_value = ROUND(RAND());
SET email_value = CONCAT("user", count, "@example.com");
INSERT INTO users (email, registered, active) VALUES (email_value, registered_value, active_value);
SET count := count + 1;
END WHILE;
END$$
DELIMITER ;
DROP PROCEDURE IF EXISTS testdata;
CALL testdata();
SHOW TABLES;
SELECT * FROM users;Los cursores nos permiten almacenar una conjunto de filas de una tabla en una estructura de datos que podemos ir recorriendo de forma secuencial.
El primer paso que tenemos que hacer para trabajar con cursores es declararlo. La sintaxis para declarar un cursor es:
DECLARE nombre_cursor CURSOR FOR sentencia_select
Una vez que hemos declarado un cursor tenemos que abrirlo con OPEN.
OPEN nombre_cursor
Una vez que el cursor está abierto podemos ir obteniendo cada una de las filas con FETCH. La sintaxis es la siguiente:
FETCH [[NEXT] FROM] nombre_cursor INTO nombre_variable [, nombre_variable] ...
Cuando hemos terminado de trabajar con un cursor tenemos que cerrarlo.
CLOSE nombre_cursor
DELIMITER $$
CREATE PROCEDURE cursortest()
BEGIN
DECLARE the_email VARCHAR(40) DEFAULT NULL;
DECLARE cur1 CURSOR FOR SELECT email FROM users ORDER BY id;
OPEN cur1;
FETCH cur1 INTO the_email;
CLOSE cur1;
SELECT the_email;
END$$
DELIMITER ;
CALL cursortest();
DROP PROCEDURE cursortest;
SELECT * FROM users;Crear un procedimiento que obtenga los usuarios (users) activos registrados hace un año y que luego agregue el email en una tabla que deberá crear manualmente con el nombre leads y dos campos: la clave (id) y el email
SELECT DATE(NOW()) - INTERVAL 1 YEAR;
SELECT email FROM users WHERE active = TRUE AND registered > DATE(NOW()) - INTERVAL 1 YEAR;
CREATE TABLE leads(
id INT AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(40) NOT NULL
);
SET sql_safe_updates = 0;
DELIMITER $$
CREATE PROCEDURE cursortest()
BEGIN
DECLARE the_email VARCHAR(40) DEFAULT NULL;
DECLARE finished BOOL DEFAULT FALSE;
DECLARE cur1 CURSOR FOR SELECT email FROM users WHERE active = TRUE AND registered > DATE(NOW()) - INTERVAL 1 YEAR;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET finished := TRUE;
TRUNCATE leads;
OPEN cur1;
the_loop: LOOP
FETCH cur1 INTO the_email;
IF finished = TRUE THEN
LEAVE the_loop;
END IF;
INSERT INTO leads(email) VALUES(the_email);
END LOOP the_loop;
CLOSE cur1;
END$$
DELIMITER ;
CALL cursortest();
DROP PROCEDURE cursortest;
SELECT * FROM users;
SELECT COUNT(*) FROM leads;CASE case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list]
...
[ELSE statement_list]
END CASE
-- EJEMPLO DE UNA CALCULADORA BÁSICA
DROP PROCEDURE IF EXISTS calculator;
DELIMITER $$
CREATE PROCEDURE calculator(IN p_num1 INT, IN p_num2 INT, IN p_operator CHAR(1))
BEGIN
CASE p_operator
WHEN '+' THEN SELECT p_num1 + p_num2;
WHEN '-' THEN SELECT p_num1 - p_num2;
WHEN '*' THEN SELECT p_num1 * p_num2;
WHEN '/' THEN SELECT FORMAT(p_num1 / p_num2, 2);
END CASE;
END$$
DELIMITER ;
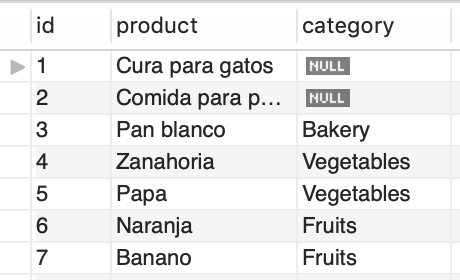
CALL calculator(8, 4, '/');Cree la tabla products con tres campos: id, product y category. Los registros se muestran en la imagen. Luego cree tres tablas fruits, bakey y vegetables con un campo id y product por cada una. Se requiere un procedimiento que recorra cada fila de products y según la categoría (category) inserte el producto en la tabla correspondiente. Para el caso de los productos sin asignar categoría deberá retornarlos separados por coma.
DROP TABLE IF EXISTS products;
CREATE TABLE products (
id INT PRIMARY KEY AUTO_INCREMENT,
product VARCHAR(40) NOT NULL,
category ENUM('Bakery', 'Fruits', 'Vegetables')
);
INSERT INTO products (product, category) VALUES ('Cura para gatos', NULL);
INSERT INTO products (product, category) VALUES ('Comida para perros', NULL);
INSERT INTO products (product, category) VALUES ('Pan blanco', 'Bakery');
INSERT INTO products (product, category) VALUES ('Banano', 'Fruits');
INSERT INTO products (product, category) VALUES ('Naranja', 'Fruits');
INSERT INTO products (product, category) VALUES ('Zanahoria', 'Vegetables');
INSERT INTO products (product, category) VALUES ('Papa', 'Vegetables');
CREATE TABLE fruits(
id INT PRIMARY KEY,
product VARCHAR(40) NOT NULL
);
CREATE TABLE vegetables(
id INT PRIMARY KEY,
product VARCHAR(40) NOT NULL
);
CREATE TABLE bakery(
id INT PRIMARY KEY,
product VARCHAR(40) NOT NULL
);
SELECT id, product, category FROM products;
SHOW TABLES;
DELIMITER $$
CREATE PROCEDURE filltables(OUT unassigned LONGTEXT)
BEGIN
DECLARE the_id INT;
DECLARE the_product VARCHAR(40);
DECLARE the_category ENUM('Bakery', 'Fruits', 'Vegetables');
DECLARE finished BOOL DEFAULT FALSE;
DECLARE cur CURSOR FOR SELECT id, product, category FROM products;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET finished := TRUE;
SET unassigned := "";
OPEN cur;
the_loop: LOOP
FETCH cur INTO the_id, the_product, the_category;
IF finished = TRUE THEN
LEAVE the_loop;
END IF;
CASE the_category
WHEN 'Fruits' THEN
INSERT INTO fruits(id, product) VALUES(the_id, the_product);
WHEN 'Vegetables' THEN
INSERT INTO vegetables(id, product) VALUES(the_id, the_product);
WHEN 'Bakery' THEN
INSERT INTO bakery(id, product) VALUES(the_id, the_product);
ELSE
SET unassigned := CONCAT(unassigned, the_product, ', ');
END CASE;
END LOOP;
CLOSE cur;
END$$
DELIMITER ;
DROP PROCEDURE IF EXISTS filltables;
CALL filltables(@unassigned);
SELECT @unassigned;
SELECT * FROM fruits;
SELECT * FROM bakery;
SELECT * FROM vegetables;Crear un procedimiento que retorne una lista de emails de la tabla users y una lista de frutas de la tabla fruits. Es decir, se trabajará con dos cursores.
DELIMITER $$
CREATE PROCEDURE test(OUT emails TEXT, OUT fruits TEXT)
BEGIN
BEGIN
DECLARE the_email VARCHAR(40);
DECLARE finished BOOL DEFAULT FALSE;
DECLARE users_cursor CURSOR FOR SELECT email FROM users;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET finished := TRUE;
SET emails := "";
OPEN users_cursor;
the_loop: LOOP
FETCH users_cursor INTO the_email;
IF finished = TRUE THEN
LEAVE the_loop;
END IF;
SET emails = CONCAT(emails, ', ', the_email);
END LOOP;
CLOSE users_cursor;
END;
BEGIN
DECLARE the_product VARCHAR(40);
DECLARE finished BOOL DEFAULT FALSE;
DECLARE fruits_cursor CURSOR FOR SELECT product FROM fruits;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET finished := TRUE;
SET fruits := "";
OPEN fruits_cursor;
fruits_loop: LOOP
FETCH fruits_cursor INTO the_product;
IF finished = TRUE THEN
LEAVE fruits_loop;
END IF;
SET fruits = CONCAT(fruits, the_product , ', ');
END LOOP fruits_loop;
CLOSE fruits_cursor;
END;
END$$
DELIMITER ;
DROP PROCEDURE IF EXISTS test;
CALL test(@emails, @fruits);
SELECT @emails, @fruits;
SELECT product FROM fruits;Sugerencias:
- Para ordenar resultados de forma aleatoria use: ORDER BY RAND()
- Puede usar dos cursores en el mismo ciclo
1. Cree manualmente una tabla (llamada Palabras) que contenga dos columnas y una clave primaria: una columna para la lista de sustantivos y una columna una lista de adjetivos, ejemplo:
1 perrito caliente 2 plátanos rápidos 3 nube naranja 4 cortina encantadora
.....
Escriba un procedimiento que devuelva datos en dos variables "out" (Puede llamarlo crear_listas): una lista contendrá todos los sustantivos unidos con comas, la otra contendrá todos los adjetivos unidos por comas.
Opcional: modifique el procedimiento para que no haya una coma extra adicional al inicio o final de las listas.
2. Escriba un procedimiento almacenado que cree una tabla llamada "estrellas" que contenga una columna de tipo TEXT (nombre) y otra columna para la clave (id). Haga que el procedimiento llene la tabla seleccionando un adjetivo y un sustantivo al azar y que los una con un espacio entre ellos, ejemplos:
Nube caliente Perro encantador
.....
Opcional: mayúsculas las primeras letras de las dos palabras.
3. Agregue a la tabla "estrellas" dos columnas una fecha de nacimiento y una fecha de fallecimiento (ambas de tipo date). Cree otro procedimiento (crear_estrellas_con_fechas) que complete las fechas de nacimiento y muerte de la siguiente manera.
La fecha de nacimiento debe ser aleatoria entre 20 y 80 años atrás.
La fecha de fallecimiento debe ser aleatoria entre 19 años después de la fecha de nacimiento y hoy.
La fecha de fallecimiento solo se debe completar en el 40% de las veces, al azar. Es decir, todas las filas tienen un 40% de posibilidad de tener fecha de fallecimiento.
Un desencadenador (o Trigger) es una clase especial de procedimiento almacenado que se ejecuta automáticamente cuando se produce un evento en el servidor de bases de datos.
Un trigger es un objeto de la base de datos que está asociado con una tabla y que se activa cuando ocurre un evento sobre la tabla.
Los eventos que pueden ocurrir sobre la tabla son:
Entonces, un trigger se asocia a un evento (insert, update o delete) sobre una tabla.
CREATE
TRIGGER nombre_del_trigger
momento_del_trigger evento_trigger
ON nombre_tabla FOR EACH ROW
cuerpo_del_trigger
momento_del_trigger: { BEFORE | AFTER }
evento_trigger: { INSERT | UPDATE | DELETE }
Ejemplo: se tiene la tabla ventas (sales) con los campos: id, product y value. Deseamos llevar un registro de todos los cambios de valor (value) de la venta. Imagine que la venta 1 que actualmente es de 15.00 sufre uno o varios cambios en el valor, sería ideal almacenar esas modificaciones, esto como mecanismo de control interno de la empresa, la tabla se debe llamar sales_update con los campos: id, product_id, change_at, before_value, after_value
Ejemplo: se tiene la tabla products con los campos: id y value. Necesitamos validar que en el campo value el valor máximo sea 100.0, es decir que si el usuario ingresa 130 para el valor de un producto, automáticamente se fije el valor en 100.0 desde el servidor.
Ejemplo: se tiene la tabla products con los campos: id y value. Necesitamos validar que en el campo value el valor máximo sea 100.0, es decir que si el usuario ingresa 130.0 para el valor de un producto, automáticamente se fije el valor en 100.0 desde el servidor.
Solución:
DROP TABLE IF EXISTS products;
CREATE TABLE products(
id INT AUTO_INCREMENT PRIMARY KEY,
value NUMERIC(10, 2) NOT NULL
);
DELIMITER $$
CREATE TRIGGER before_product_insert BEFORE INSERT ON products
FOR EACH ROW
BEGIN
IF NEW.value > 100.0 THEN
SET NEW.value := 100.0;
END IF;
END$$
CREATE TRIGGER before_product_update BEFORE UPDATE ON products
FOR EACH ROW
BEGIN
IF NEW.value > 100.0 THEN
SET NEW.value := 100.0;
END IF;
END$$
DELIMITER ;
INSERT INTO products(value) VALUES(130);
INSERT INTO products(value) VALUES(99.9);
UPDATE products SET value = 130 WHERE id = 2;
SELECT * FROM products;Cree una tabla de animales (animals) que incluya una columna de tipo texto (varchar o text) llamada "animal_name".
Cree un procedimiento almacenado que prevenga la inserción de cualquier nombre de animal que contenga la palabra "perro". Por ejemplo: "Perro Pastor Alemán", "Perro Bulldog", etc.
Si alguien intenta insertar una palabra que incluya "perro", el trigger automáticamente insertará en su lugar "$$$" y debería registrar el intento incluyendo el nombre del animal en una tabla llamada "violations" con la fecha y hora en que ocurrió.
Definidas por el usuario
Funciones vs Procedimientos Almacenados
Procedimientos almacenados
Funciones
Funciones
DELIMITER $$
CREATE FUNCTION nombre_función(parametro tipo_dato) RETURNS tipo_dato
BEGIN
SELECT ... RETURN nombre_variable END$$ DELIMITER ;
Aunque no hay
parámetros de salida, hay un
"Valor de retorno" y se obtiene después de ejecutar la consulta contenida en el cuerpo de la función
Puede ser de cualquier tipo
Funciones
-- FUNCIONES
SELECT LEAST(6, 4, 9);
-- CODIGO BASE PARA EXPLICAR EJEMPLOS DE FUNCIONES
USE test;
DROP TABLE IF EXISTS sales;
CREATE TABLE sales(
id INT AUTO_INCREMENT PRIMARY KEY,
sold_at DATETIME,
transaction_value NUMERIC(10, 2)
);
SELECT NOW() - INTERVAL ROUND(3 * RAND()) DAY;
SELECT 10000 * RAND();
DROP PROCEDURE IF EXISTS filltable;
DELIMITER $$
CREATE PROCEDURE filltable()
BEGIN
DECLARE count INT DEFAULT 0;
TRUNCATE sales;
WHILE count < 20 DO
INSERT INTO sales(sold_at, transaction_value)
VALUES(NOW() - INTERVAL ROUND(3 * RAND()) DAY, 10000 * RAND());
SET count := count + 1;
END WHILE;
END$$
DELIMITER ;
CALL filltable();
SELECT * FROM sales;
-- COMO TRABAJAN LAS FUNCIONES
SELECT DATE(sold_at), SUM(transaction_value) FROM sales GROUP BY DATE(sold_at);
SELECT DATE('2020-06-09 20:27:20');
SET @tax = 15;
-- Esto varia segun los datos aleatorios
SET @day = '2020-06-09';
SELECT SUM(transaction_value) * ((100-@tax)/100) FROM sales WHERE DATE(sold_at) = @day;
SET GLOBAL log_bin_trust_function_creators = 1;
/* Una rutina se considera "determinista" si siempre produce el mismo resultado para los
mismos parámetros de entrada y NO DETERMINISTA de lo contrario*/
DELIMITER $$
CREATE FUNCTION sales_after_tax(tax FLOAT, day DATE) RETURNS NUMERIC(10,2)
BEGIN
DECLARE result NUMERIC(10,2);
SELECT SUM(transaction_value) * ((100-tax)/100) FROM sales WHERE DATE(sold_at) = day INTO result;
RETURN result;
END$$
DELIMITER ;
SELECT sales_after_tax(15, '2020-06-09');
Permite que las sesiones del cliente adquieran bloqueos de tabla explícitamente con el fin de cooperar con otras sesiones para acceder a la tabla o para evitar que otras sesiones modifiquen las tablas durante los períodos en que una sesión requiere acceso exclusivo a ellas.
Una transacción SQL es un conjunto de sentencias SQL que se ejecutan formando una unidad lógica de trabajo (LUW del inglés Logic Unit of Work), es decir, en forma indivisible o atómica.
Una transacción SQL finaliza con un COMMIT, para aceptar todos los cambios que la transacción ha realizado en la base de datos, o un ROLLBACK para deshacerlos.
Algunos Sistemas Gestores de Bases de Datos, como MySQL (si trabajamos con el motor InnoDB) tienen activada por defecto la variable AUTOCOMMIT. Esto quiere decir que automáticamente se aceptan todos los cambios realizados después de la ejecución de una sentencia SQL y no es posible deshacerlos.
MySQL nos permite realizar transacciones en las tablas si hacemos uso del motor de almacenamiento InnoDB (MyISAM no permite el uso de transacciones).
El uso de transacciones nos permite realizar operaciones de forma segura y recuperar datos si se produce algún fallo en el servidor durante la transacción, pero por otro lado las transacciones pueden aumentar el tiempo de ejecución de las instrucciones.
Las transacciones deben cumplir las cuatro propiedades ACID.
Las propiedades ACID garantizan que las transacciones se puedan realizar en una base de datos de forma segura. Decimos que un Sistema Gestor de Bases de Datos es ACID compliant cuando permite realizar transacciones.
ACID es un acrónimo de Atomicity, Consistency, Isolation y Durability
Atomicidad: Esta propiedad quiere decir que una transacción es indivisible, o se ejecutan todas la sentencias o no se ejecuta ninguna.
Consistencia: Esta propiedad asegura que después de una transacción la base de datos estará en un estado válido y consistente.
Aislamiento: Esta propiedad garantiza que cada transacción está aislada del resto de transacciones y que el acceso a los datos se hará de forma exclusiva. Por ejemplo, si una transacción que quiere acceder de forma concurrente a los datos que están siendo utilizados por otra transacción, no podrá hacerlo hasta que la primera haya terminado.
Durabilidad: Esta propiedad quiere decir que los cambios que realiza una transacción sobre la base de datos son permanentes.
Cuando dos transacciones distintas intentan acceder concurrentemente a los mismos datos pueden ocurrir los siguientes problemas:
Dirty Read (Lectura sucia). Sucede cuando una segunda transacción lee datos que están siendo modificados por una transacción antes de que haga COMMIT.
Nonrepeateable Read (Lectura No Repetible). Se produce cuando una transacción vuelve a leer datos que leyó previamente y encuentra que han sido modificados por otra transacción.
Phantom Read (Lectura fantasma). Este error ocurre cuando una transacción lee unos datos que no existían cuando se inició la transacción.
Para evitar que sucedan los problemas de acceso concurrente que hemos comentado en el punto anterior podemos establecer diferentes niveles de aislamiento.
Read Uncommited. En este nivel no se realiza ningún bloqueo, por lo tanto, permite que sucedan los tres problemas
Read Commited. En este caso los datos leídos por una transacción pueden ser modificados por otras transacciones, por lo tanto, se pueden dar los problemas Phantom Read y Non Repeteable Read.
Repeateable Read. En este nivel ningún registro leído con un SELECT puede ser modificado en otra transacción, por lo tanto, sólo puede suceder el problema del Phantom Read.
Serializable. En este caso las transacciones se ejecutan unas detrás de otras, sin que exista la posibilidad de concurencia.
El nivel de aislamientno que utiliza InnoDB por defecto es Repeateable Read.
By Wilfredo Meneses



