HADoop
Mini tutorial
Piotr Przetacznik
Bartłomiej Szczepanik
Idea projektu
"In pioneer days they used oxen for heavy pulling, and when one ox couldn't budge a log,
they didn't try to grow a larger ox.
We shouldn't be trying for biger computers,
but for more systems of computers."
- Grace Hopper
hadoop - fakty
- Licencja Apache Commons
- Problem skalowalności aplikacji data-intensive
- skalowanie poziome, nie pionowe
- Hadoop jako ekosystem
podstawowe idee
- GFS - specyfikacja rozproszonego
systemu plików (Google) - Map Reduce
Problemy rdbmsów
- Abstrakcja warstwy fizycznej
- Normalizacja, 12 zasad Codda
- Warunki integralnosci
- ACID
- tranzakcyjnosc
- triggery
Hadoop - inne podejscie
Abstrakcja infrastruktury zamiast
warstwy fizycznej
- rozkład zadań
- rozkład danych
- replikacja
- wysoka dostępność
- nadzorowanie maszyn
- dołączanie maszyn on-line
- brak abstrakcji warstwy fizycznej
- częsciowo rozwiazywany przez
narzędzia takie jak Hive, HBase, Pig
MAp reduce - idea
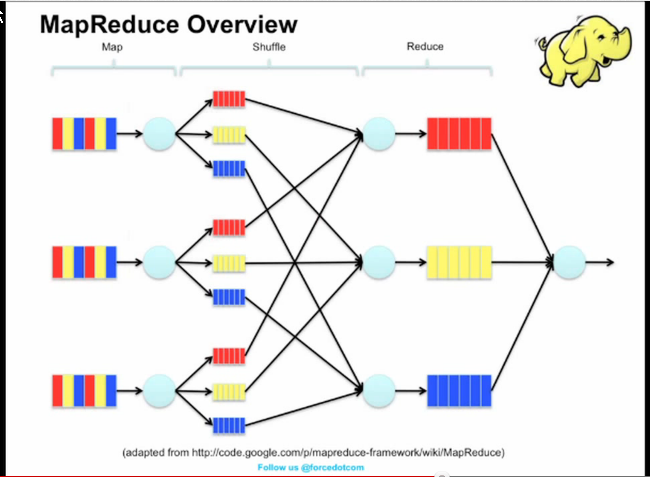
funkcja map
- dane: [1,2,3,4,5]
- funkcja: f(x) = x^2
- wynik: [1,4,9,16,25]
funkcja reduce
-
dane: [1,3,6,2,4]
-
funkcja: f(x, y) = x + y
- suma = f(f(f(f(1, 3), 6), 2), 4)
- suma = f(f(f(1,3),6),f(2,4))
funkcja map w hadoop
map: list<key,value> -> list<key, value>
Input:
file1: "hello world hello moon"
file2: "goodbye world goodnight moon"
file2: "goodbye world goodnight moon"
Ouput:
<hello, 1>; <world, 1>; <hello, 1>; <world, 1>
<goodbye, 1>; <world, 1>; <goodnight, 1>; <moon, 1>
Funkcja reduce w hadoop
reduce: key, list<value> -> list<key, value>
reduce: key, list<value> -> key, value
Input:
<hello, [1, 1]>; <world, [1,1]>; <moon, [1,1]>
<goodbye, [1]>; <goodnight, [1]>;
Ouput:
<hello, 2>; <world, 2>; <moon, 2>;
<goodbye, 1>; <goodnight, 2>
Hadoop - ekosystem
- Common
- Avro
- Map Reduce
- HDFS
- Pig
- Hive
- HBase
- ZooKeeper
- Sqoop
HADoop
By mequrel



