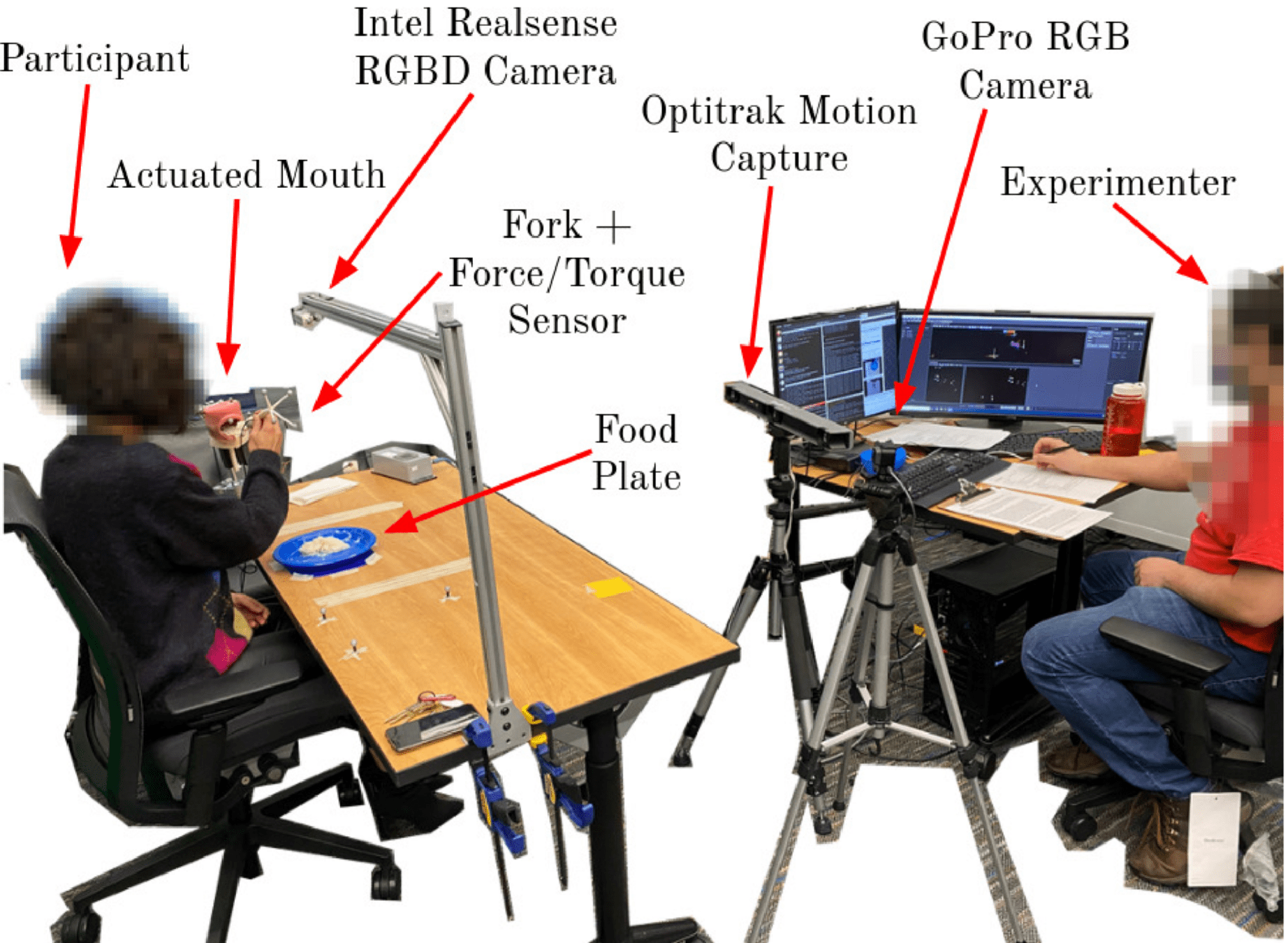
Empowering Physically Assistive Robots
Ethan K. Gordon
Postdoc, University of Pennsylvania
PhD 2023, University of Washington



with Contact-Rich Active Learning
Physically Assistive Robots (PARs)
“If I can have a robot do it, I can learn to adapt to it, but it would be me feeding me, and that would be huge”
Tyler Schrenk
1985-2023


The Promise of PARs:
- Empowerment
- Independence
What is needed for PARs?
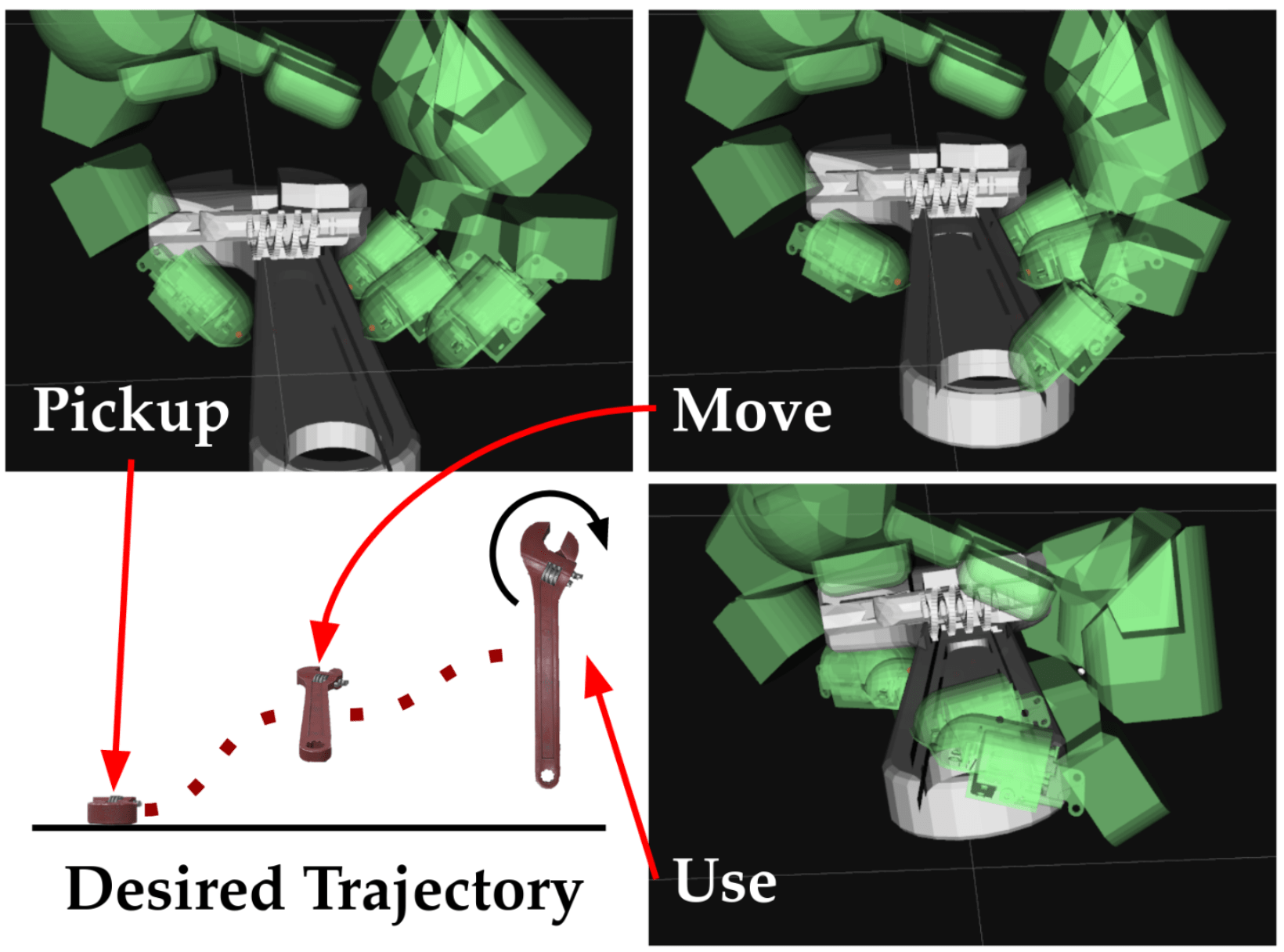
Contact-Rich Manipulation
- Sliding to clean the spoon and bowl
- Shaking to smoothen
- In-Mouth Hand-Off
(vision-denied)
Online Adaptation
- Bite Size Adjustment
What is needed for PARs?
Online Adaptation
- Totally Different Food
- Multi-bite: different shapes for each bite
There is no time for
re-training!
Tractable Adaptability
How can robots adapt at deployment-time
efficiently, safely, and portably?
Policy Space Reduction
Model-Based Methods
Leveraging Haptics
Support
Inform
Multimodal Active Learning
Physically Assistive Robots



Summary
-
The Promise of Physically Assistive Robotics
-
Robot-Assisted Feeding: User-Defined Metrics
-
Food Bite Acquisition as a Contextual Bandit
- Policy space reduction a priori
- Haptics as post hoc bandit context
-
Active Learning with Dynamic Contact
-
Community-Based Participatory Design
-
Research @ Ai2: Safety and Interpretability
Multimodal Active Learning
Physically Assistive Robots
Do we need autonomy? What kind?
Community-Based Participatory Research
It is important to ask users, observational and qualitative research before experimentation.
Time Per Bite:
- Caretaker: ~20s
- Preferred: <2min
- Teleoperated Robot: 5-40min
Why Single-Utensil Feeding?
It's intuitive and familiar.
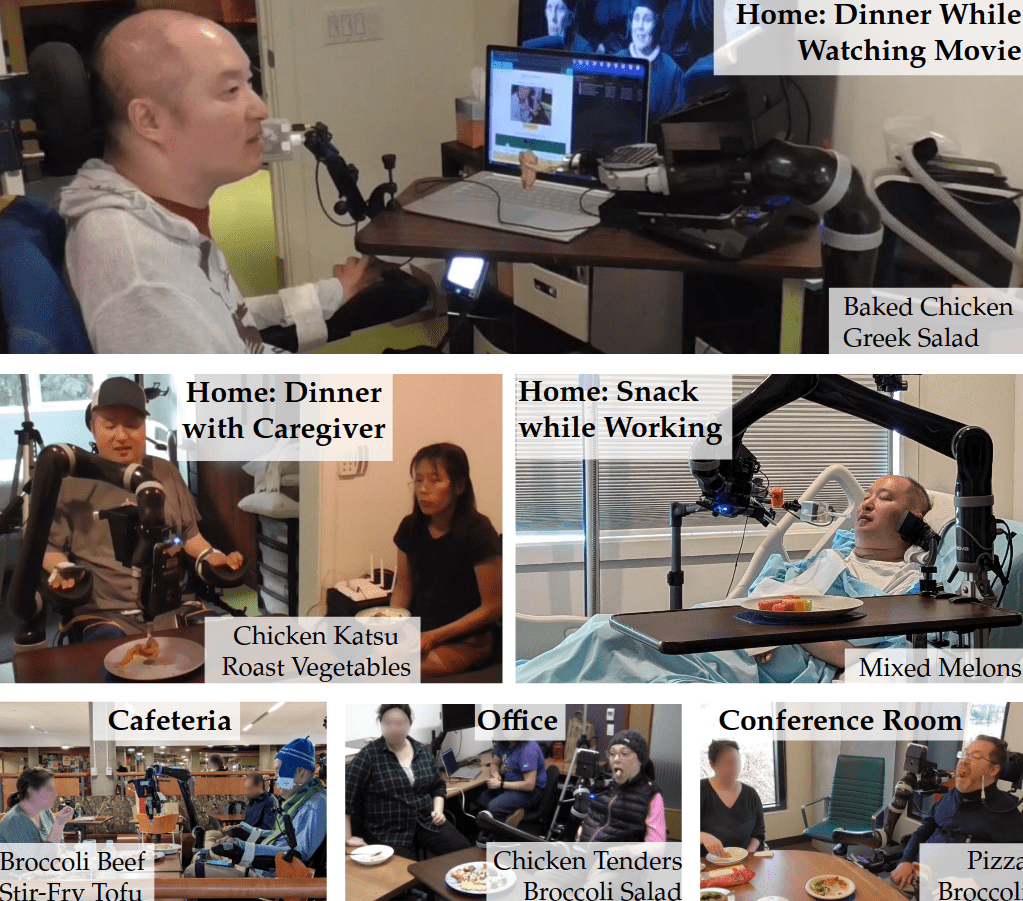
The Assistive Dexterous Arm (ADA)
User Studies Capture Diversity
T. Bhattacharjee, E.K. Gordon et al, “Is more autonomy always better?...", HRI 2020Acceptance is User-Dependent, But High
Users with more limited mobility had a preference for greater autonomy, even if it experienced errors.
T. Bhattacharjee, E.K. Gordon et al, “Is more autonomy always better?...", HRI 2020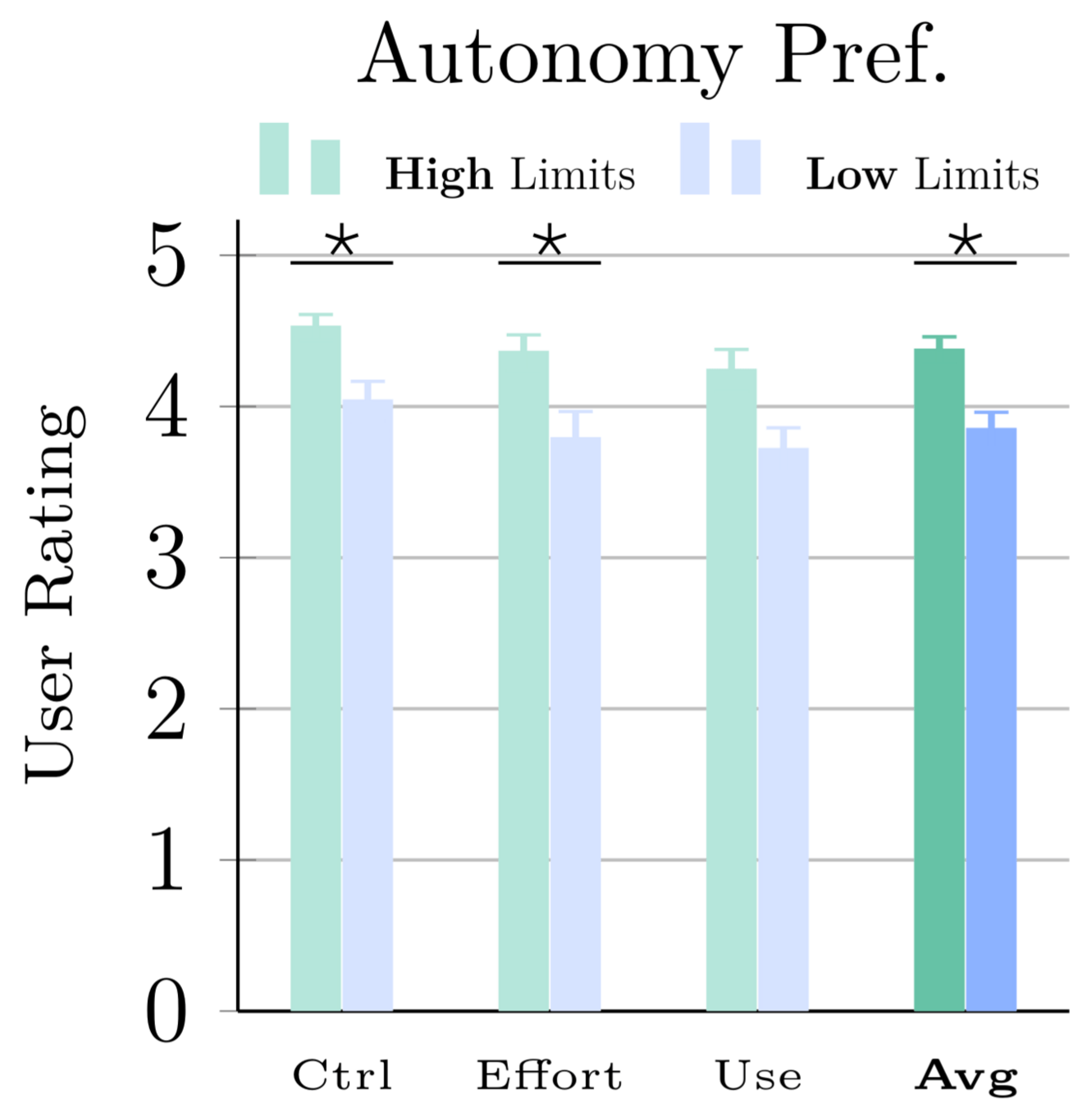
Autonomy Preference Given Errors
User Rating
User Studies Capture Metrics
Trade-off between autonomy (with chance of error) and high-effort manual control.
What errors are tolerable? Minimum Food Acquisition Success Rate: 80%
T. Bhattacharjee, E.K. Gordon et al, “Is more autonomy always better?...", HRI 2020Summary
-
The Promise of Physically Assistive Robotics
-
Robot-Assisted Feeding: User-Defined Metrics
-
Food Bite Acquisition as a Contextual Bandit
- Policy space reduction a priori
- Haptics as post hoc bandit context
-
Active Learning with Dynamic Contact
-
Community-Based Participatory Design
-
Research @ Ai2: Safety and Interpretability
Multimodal Active Learning
Physically Assistive Robots
Data Driven Bite Acquisition
R. Feng, Y. Kim, G. Lee, E. K. Gordon, et al, "...Generalizing skewering strategies...", ISRR 2019
Food simulation is hard*, but we can collect real data. What if we just RL-train a policy?
Example: 10 trajectories x 16 food types
85 person-hours
- Is it portable? Yes
- Is it safe? Yes, but limited
- Is it adaptable? Not really...
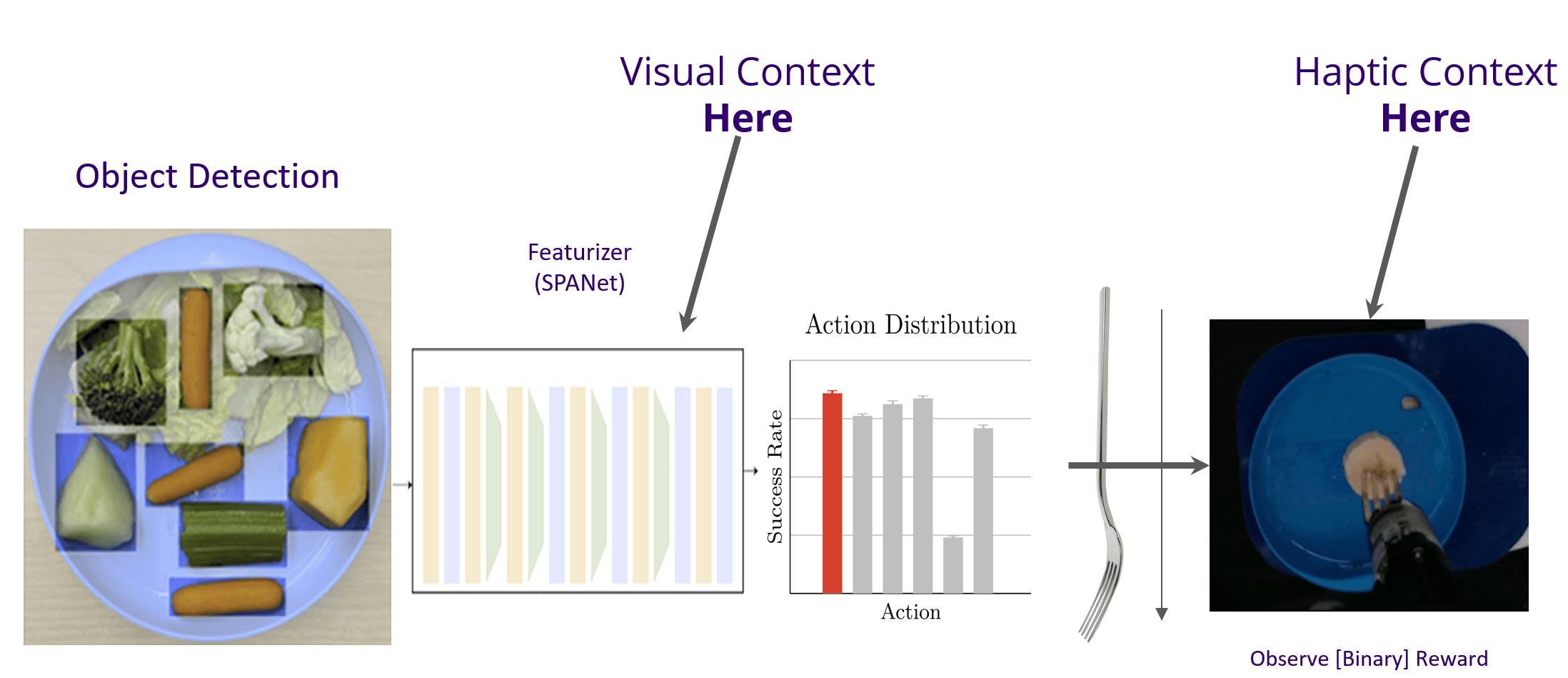
Data Driven Bite Acquisition
E. Heiden et al, “DiSECt", RSS 2021
(only planar cutting)
Online Learning with Policy Space Reduction
Hierarchy and Bandits
Leveraging Expert Data
T. Bhattacharjee et al, “Towards Robotic Feeding...", R-AL 2019
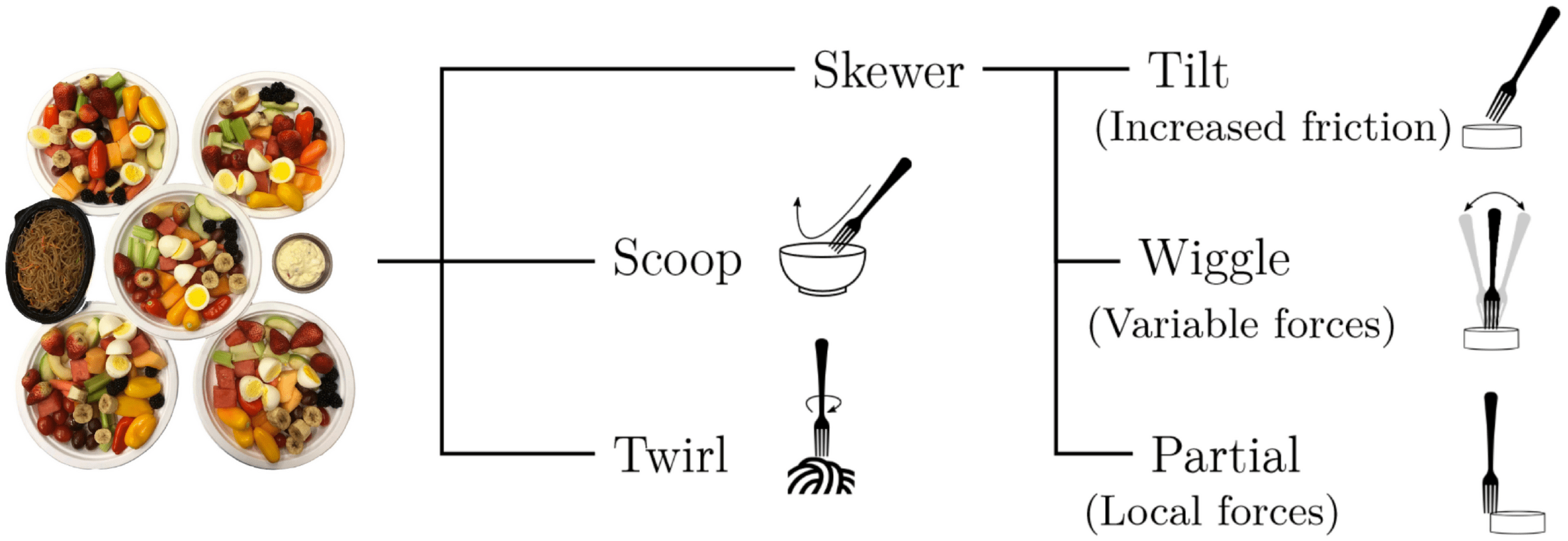
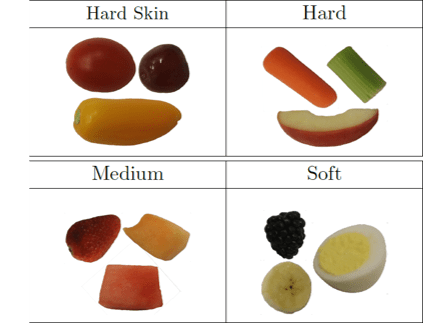
Qualitative Taxonomy
Insights:
Discrete classes of strategies
Lots of variations within those classes
Imitation Learning for Policy Space Reduction
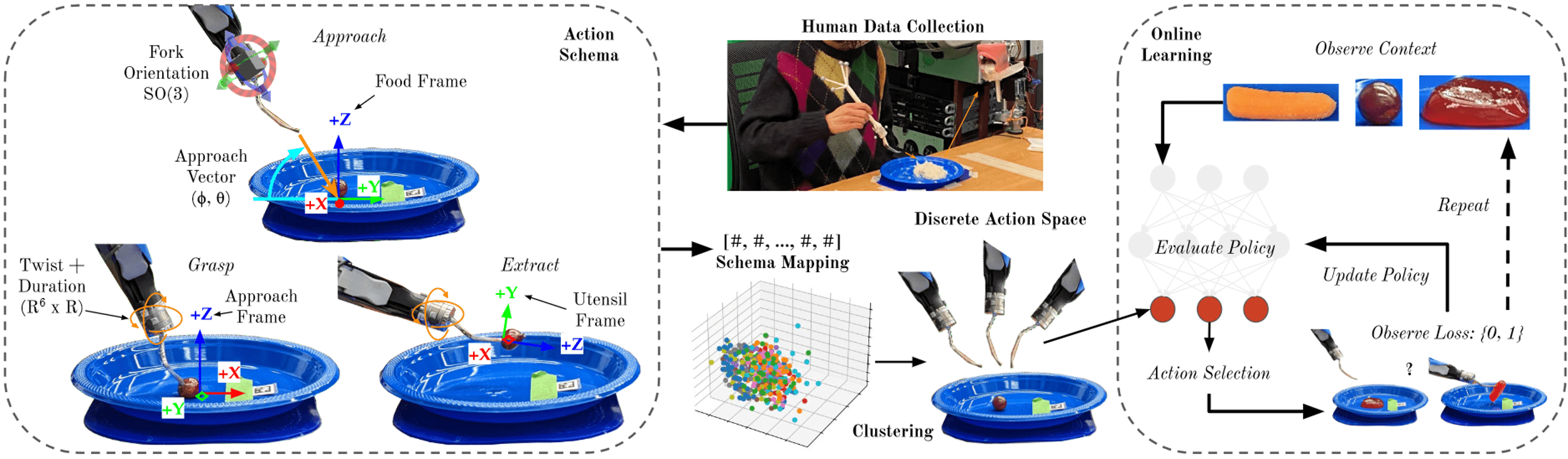
E. K. Gordon, A. Nanavati et al, “Towards General Single-Utensil...", CoRL 2023
Splines and force/torque thresholds.
Comparable with Euclidean Metric.
Emergent Behavior
Wiggling
Tilting
High Pressure
Scooping
E. K. Gordon, A. Nanavati et al, “Towards General Single-Utensil...", CoRL 2023
Is this expressive enough?
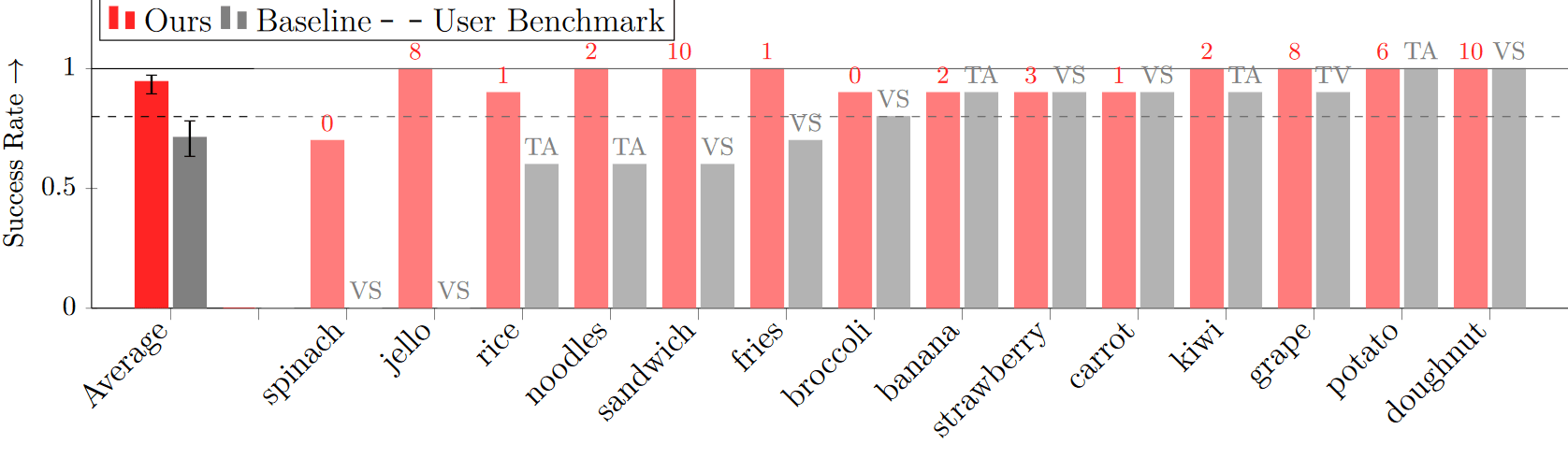
Yes!
(Note the 80% acceptance threshold)
E. K. Gordon, A. Nanavati et al, “Towards General Single-Utensil...", CoRL 2023
Online learning with a discrete action space maps cleanly on the contextual bandit setting.
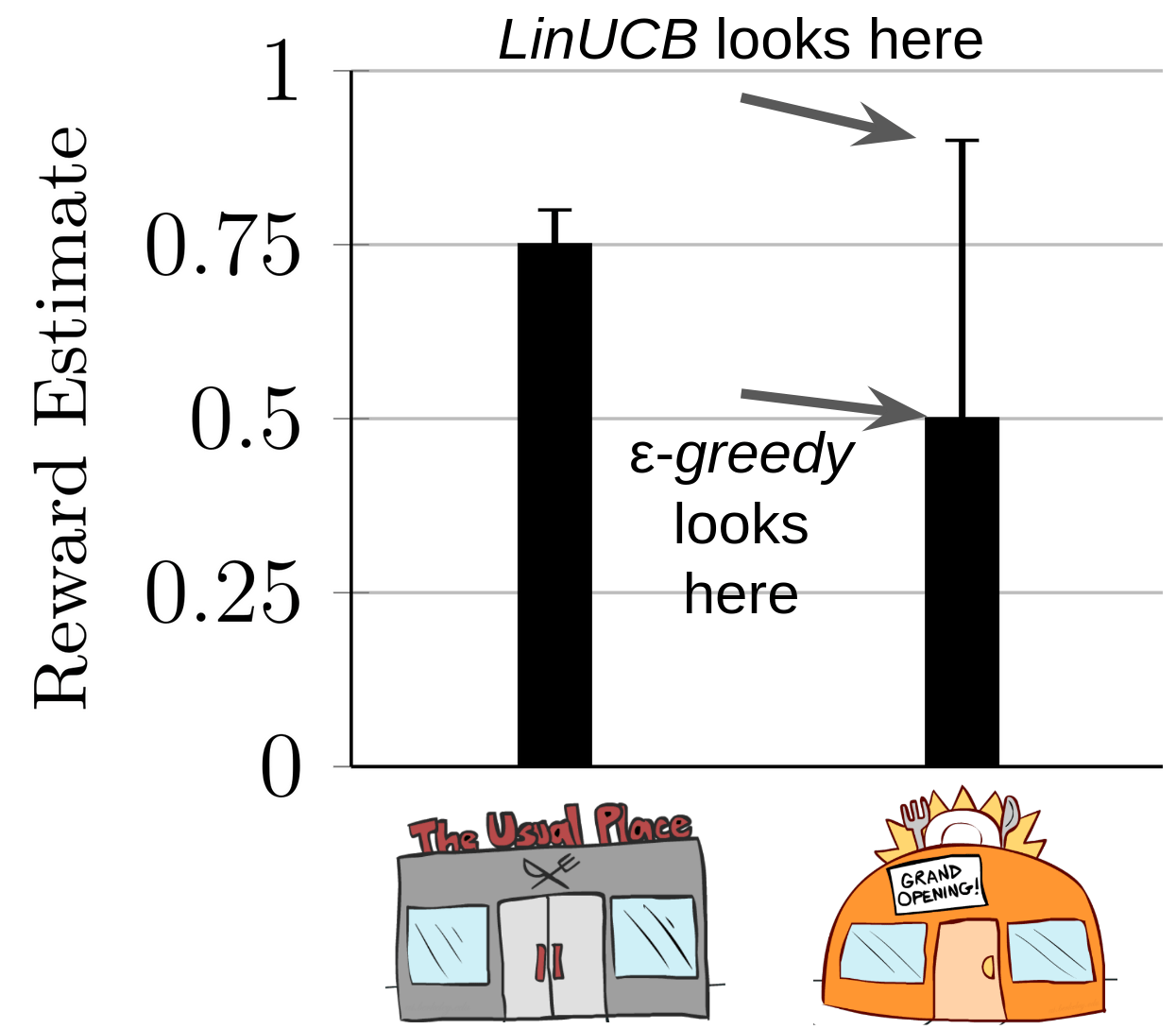
The Multi-Arm Bandit (MAB)

\(r \sim\)
\( \mathcal{N}(0.5, 1)\)
Reward
\( \mathcal{N}(0.8, 1)\)
\( \mathcal{N}(0.1, 1)\)
Interaction Protocol:
- Select \(a = \pi(a_{0\ldots t}, r_{0\ldots t})\)
- Observe \(r\)
- Update \(\pi\)
\(a =\)
\(1\)
\(2\)
\(3\)

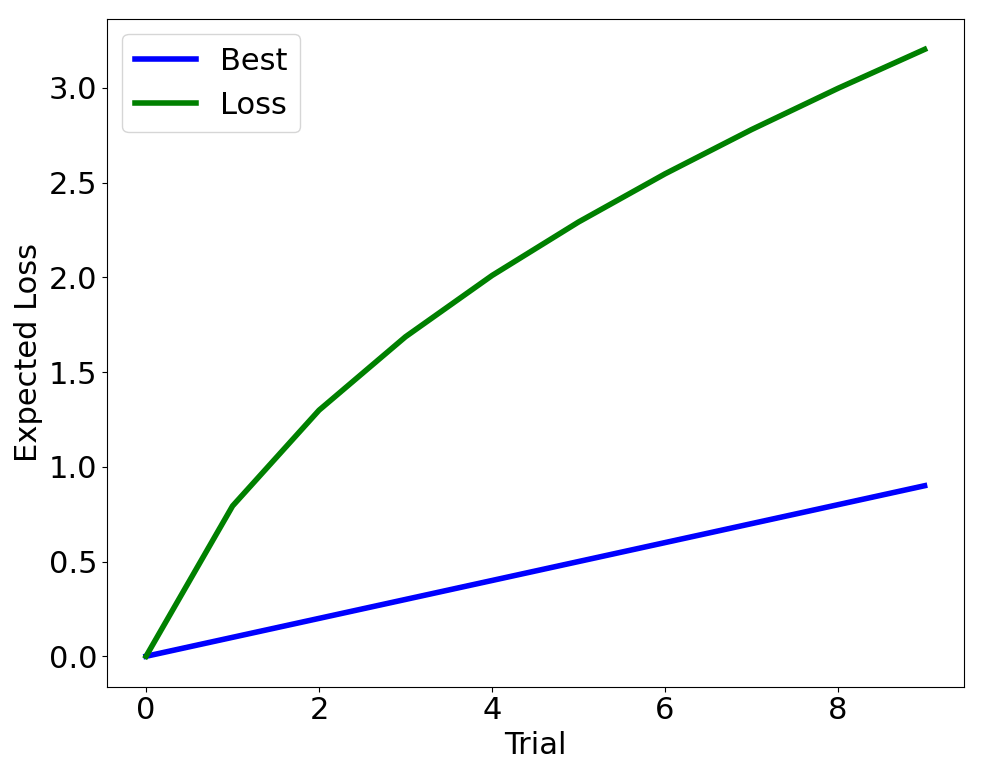
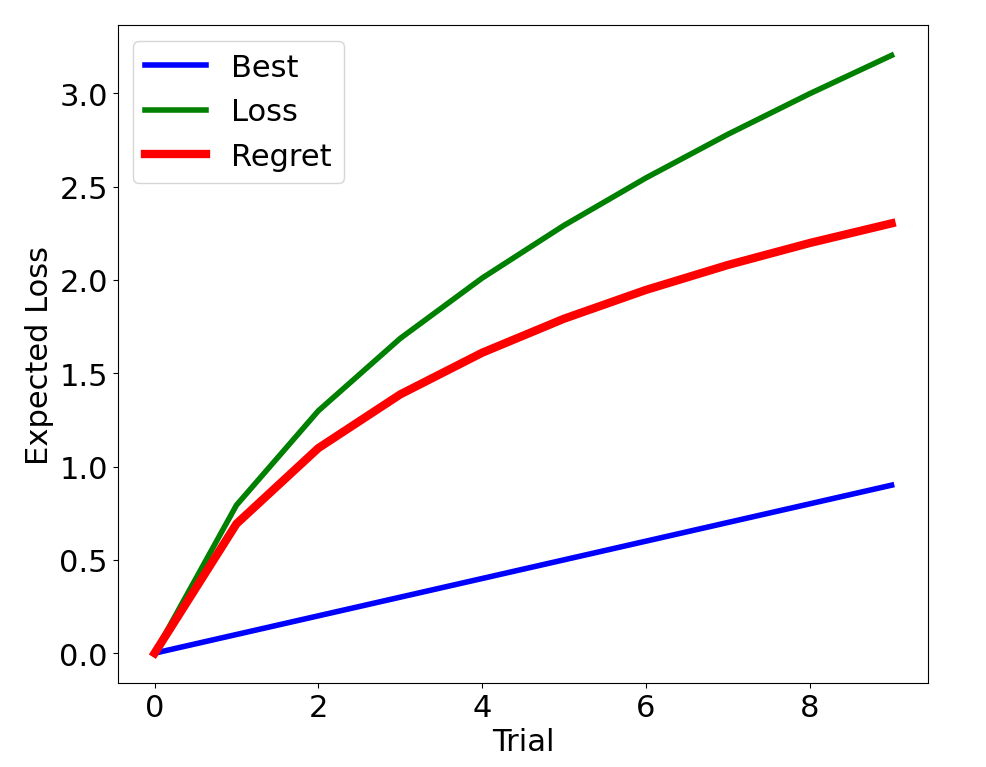
Metric: Regret: \(\mathbb{E}[r(a^*) - r(a_t)]\)
Test time metric, balances exploration vs. exploitation,
often theoretically bounded
The (Stochastic) Contextual Bandit
\(r \sim\)
\( \mathcal{N}(\mu_1(c), \sigma)\)
Reward
Interaction Protocol:
- Observe \(c_t\)
- Select \(a_t = \pi(c_t)\)
- Observe \(r(a_t, c_t)\)
- Update \(\pi\)
\(a =\)
\(1\)
\(2\)
\(3\)
\( \mathcal{N}(\mu_2(c), \sigma)\)
\( \mathcal{N}(\mu_3(c), \sigma)\)

\(c_t\)
Bite Acquisition as a Contextual Bandit
Discrete Actions \(a\)
Visual Context: \(c_t\)

\(r\): Success/Failure \(\{1, 0\}\)
E. K. Gordon et al, “Adaptive robot-assisted feeding...", IROS 2020
Eye-in-Hand RGBD
SegmentAnything
ResNet Features
Post Hoc Haptics for Bite Acquisition
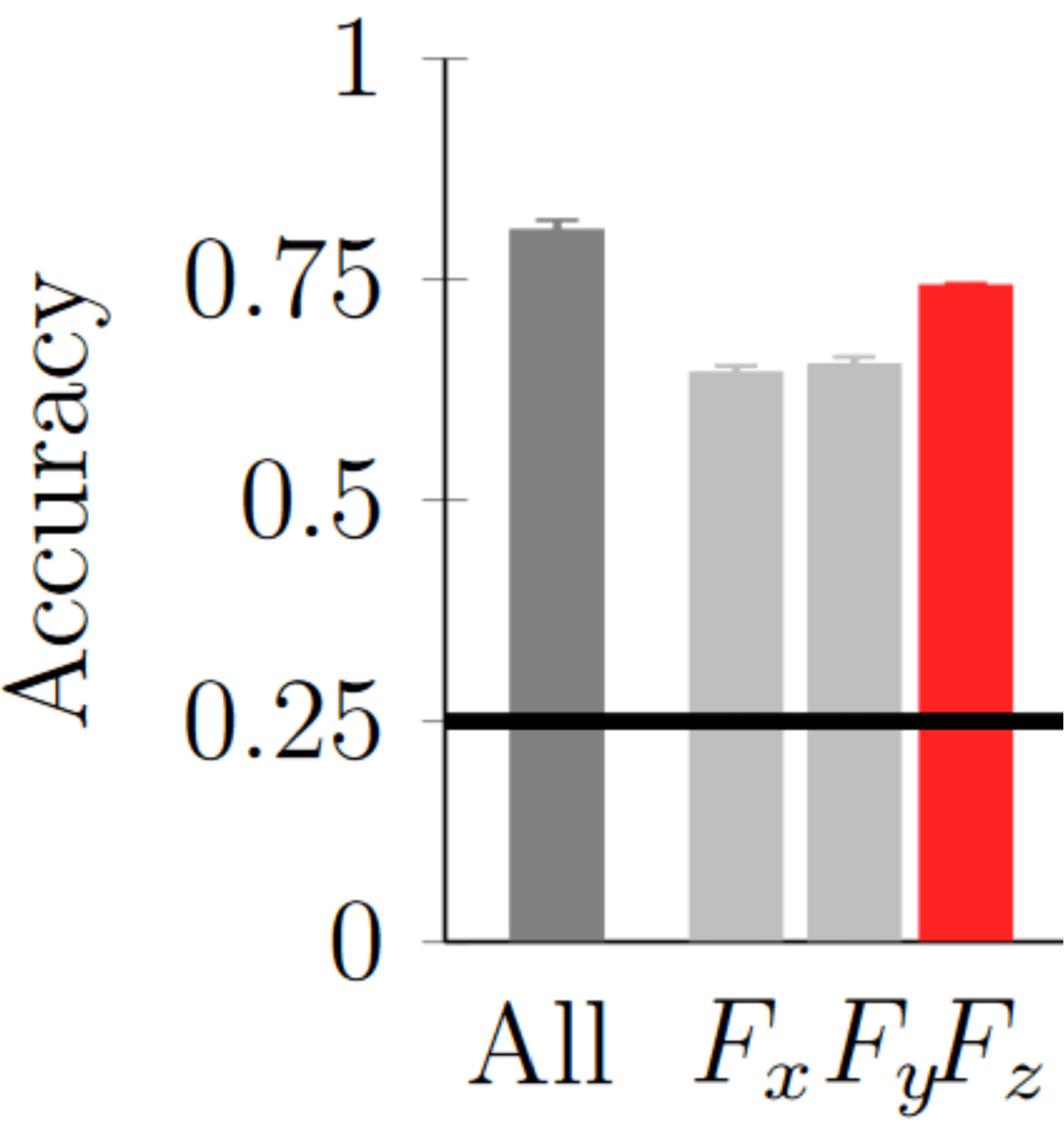
Haptic data is really good for food classification.
55ms of force data:
T. Bhattacharjee et al, R-AL 2019 ; E. Gordon et al, "Leveraging post hoc context...", ICRA 2021Supervised vs. Bandit Learning
\(l_a(c) = [0, 1, 1, 1, 1, 1, 1, 1, 1, 1]\)
Supervised Learning sees \(l_a(c) \forall a\)
Full Feedback
\(c\)
Bandit Algorithm sees \(l_{a_t}(c)\)
Bandit Feedback (Harder)
No counterfactual.
E. Gordon et al, "Leveraging post hoc context...", ICRA 2021Regret: \(O(\sqrt{T})\)
Regret: \(O(\dim a \dim c * \sqrt{T})\)
Post Hoc Haptics for Bite Acquisition
E. Gordon et al, "Leveraging post hoc context...", ICRA 2021Consider a joint loss model:
\(r_a + \epsilon = f_{\theta^*}(c) = g_{\phi^*}(p)\)
\(\epsilon \sim \mathcal{N}\)
visual context
haptic context
\(f_\theta(c, a) = [0.9, 0.1, 0.5, 0.8, \ldots]\)
Once either model is learned, the other model reduces from bandit feedback to full feedback
Example:
After only 1 action, robot determines that kiwi \(\approx\) banana, and can impute the counterfactual.
Observe \(a=1 \rightarrow [0, ?, ?, ?, \ldots]\)
\(g_\phi(p, a) = [0.8, 0.2, 0.4, 0.7, \ldots]\)
Can provide the counterfactual
Regret: \(O(\dim c) \rightarrow O(\min(\dim c,\dim p))\)
Are the 11 actions tractable for learning?
E. Gordon et al, "Leveraging post hoc context...", ICRA 2021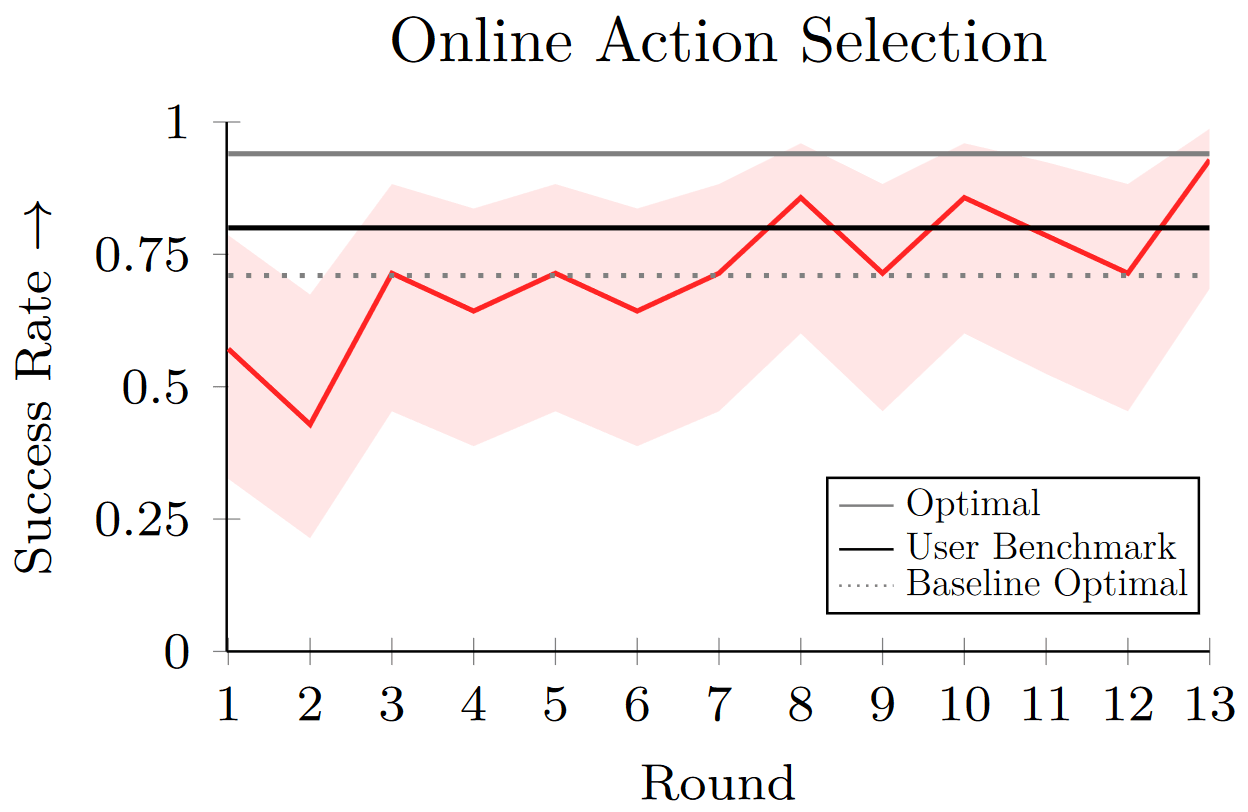
Yes
New foods take ~7-8 actions to learn to user satisfaction.
Summary
-
The Promise of Physically Assistive Robotics
-
Robot-Assisted Feeding: User-Defined Metrics
-
Food Bite Acquisition as a Contextual Bandit
- Policy space reduction a priori
- Haptics as post hoc bandit context
-
Active Learning with Dynamic Contact
-
Community-Based Participatory Design
-
Research @ Ai2: Safety and Interpretability
Multimodal Active Learning
Physically Assistive Robots
Active Tactile Exploration Through Contact

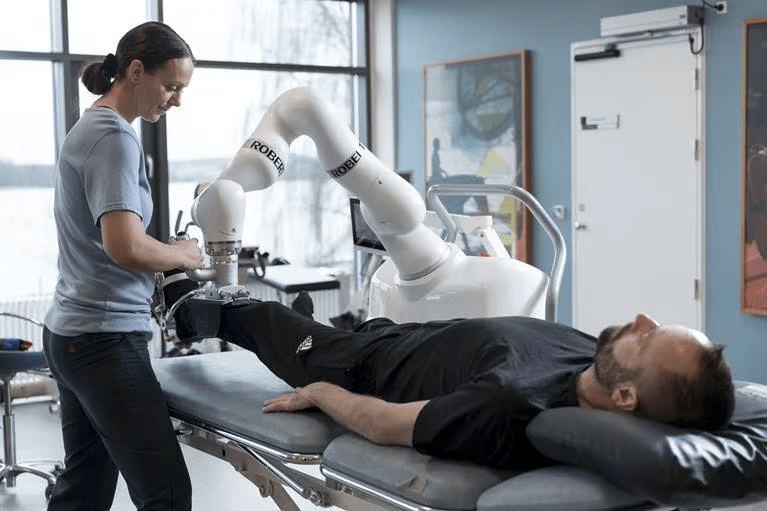
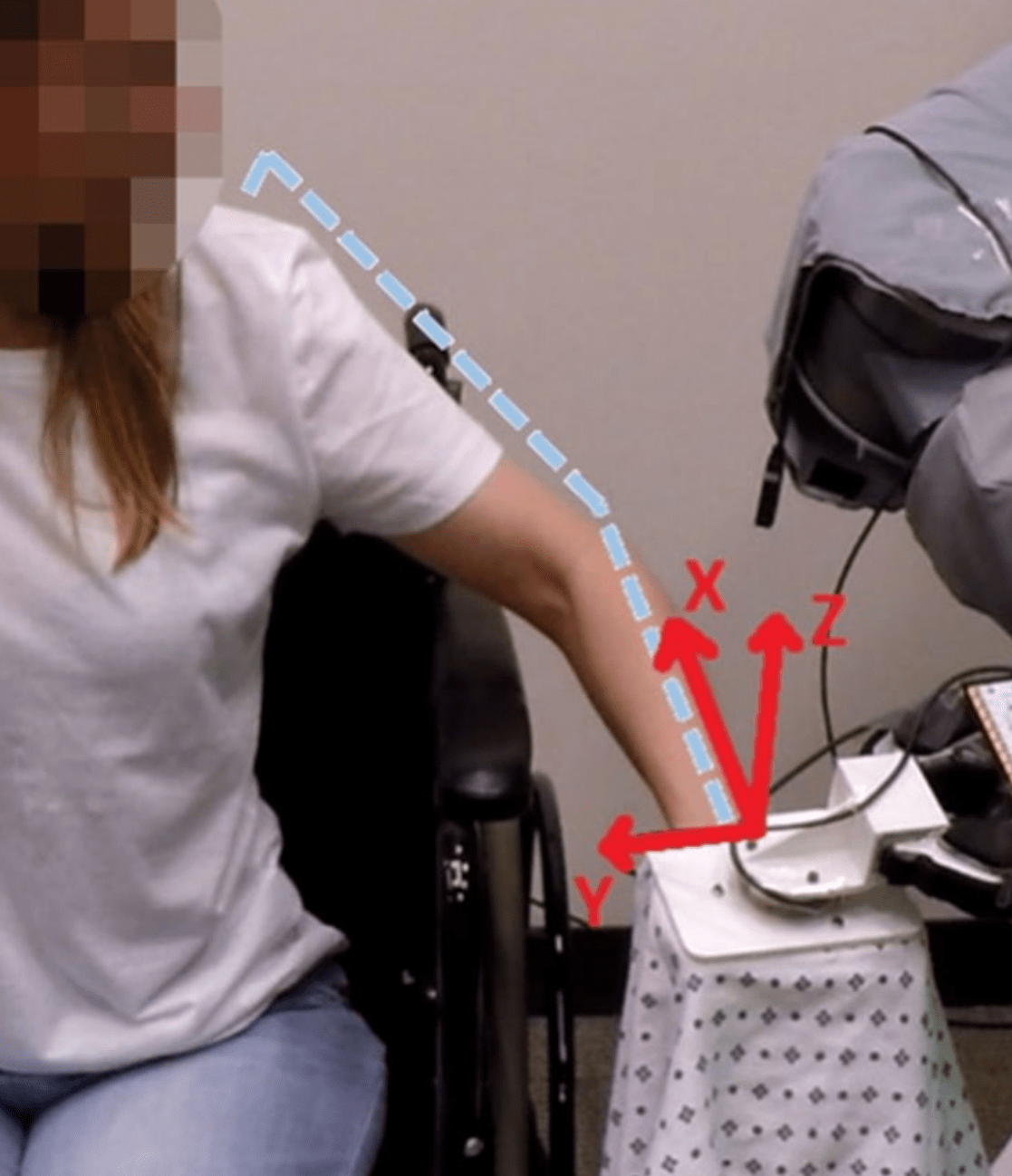
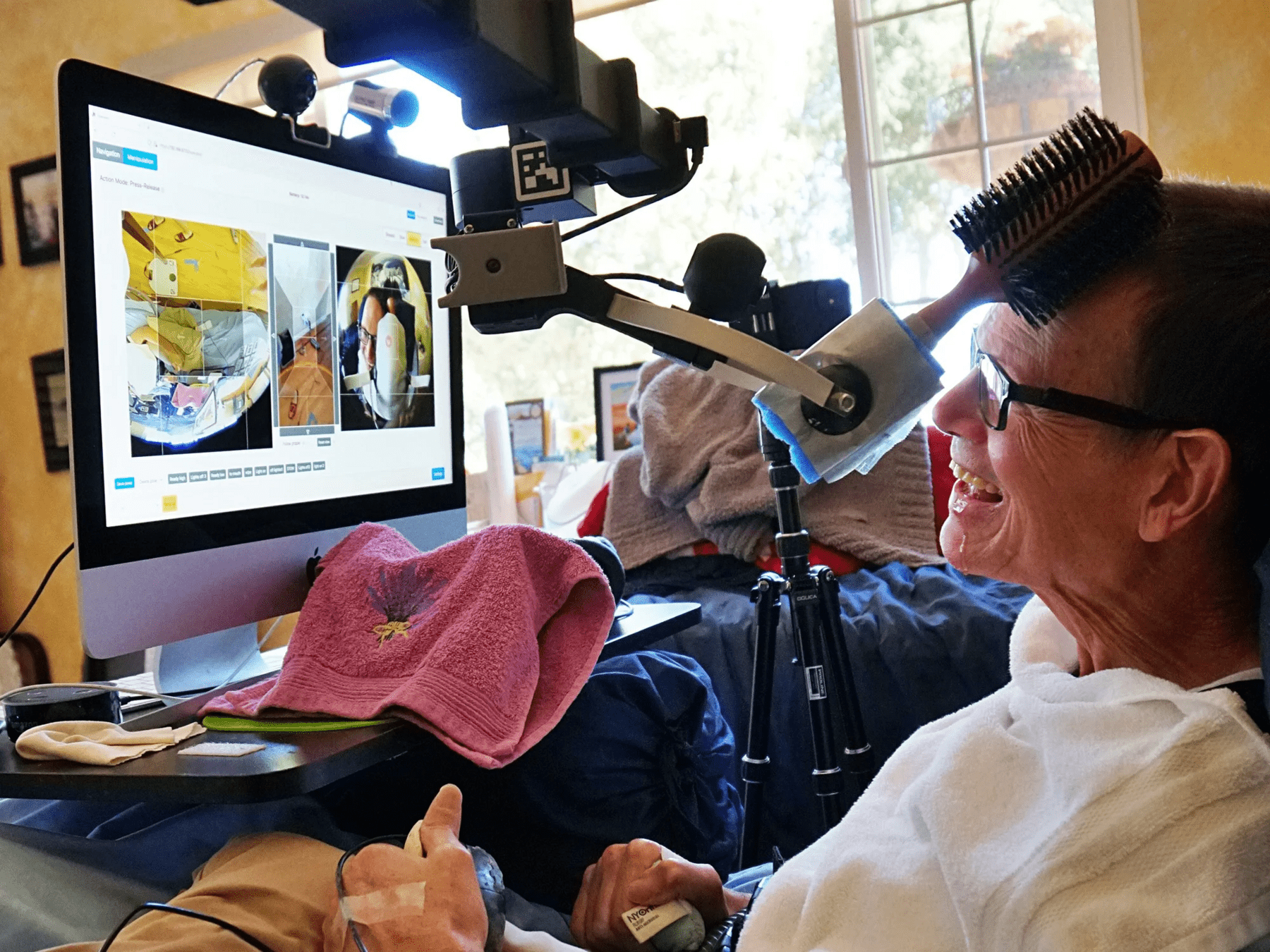
[1] Kapusta et al, Autonomous Robots 2019; [2] Hello Robot; [3] KukaDressing
Grooming
Rehabilitation
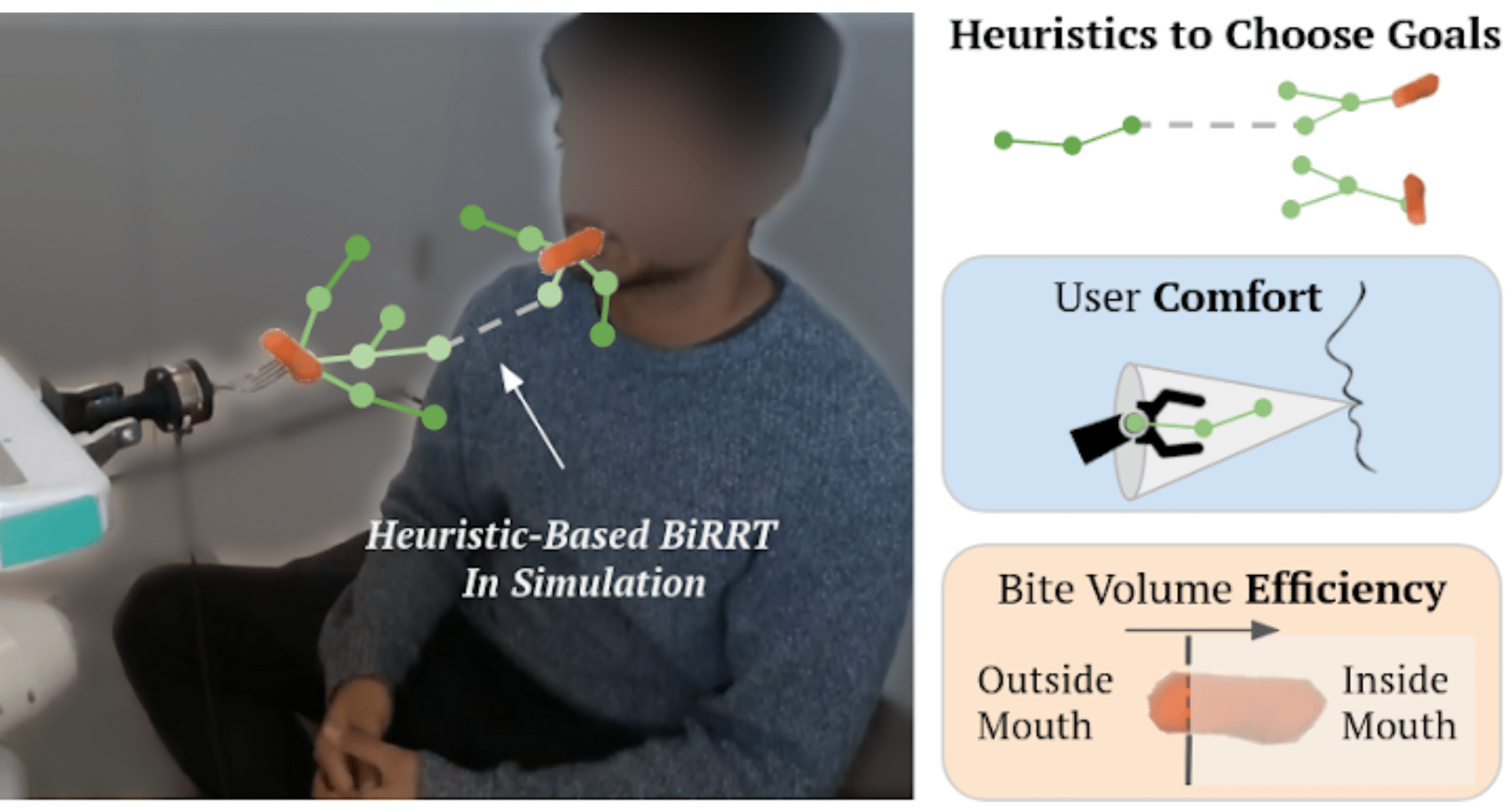
How can we perform active learning with:
Dynamic Objects?
Visual Occlusions?
Robust Simulation Tools?
Can a robot do this?
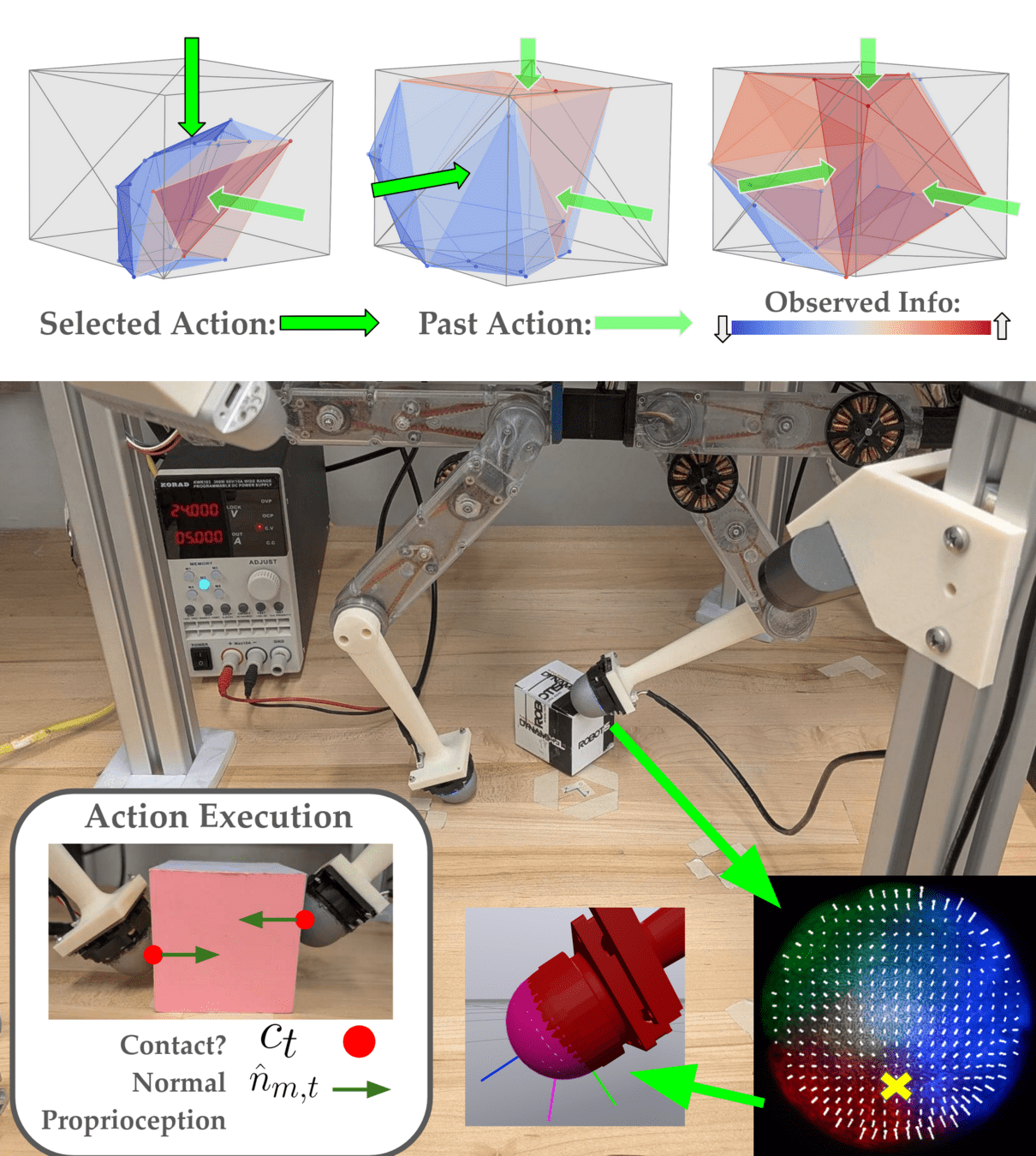
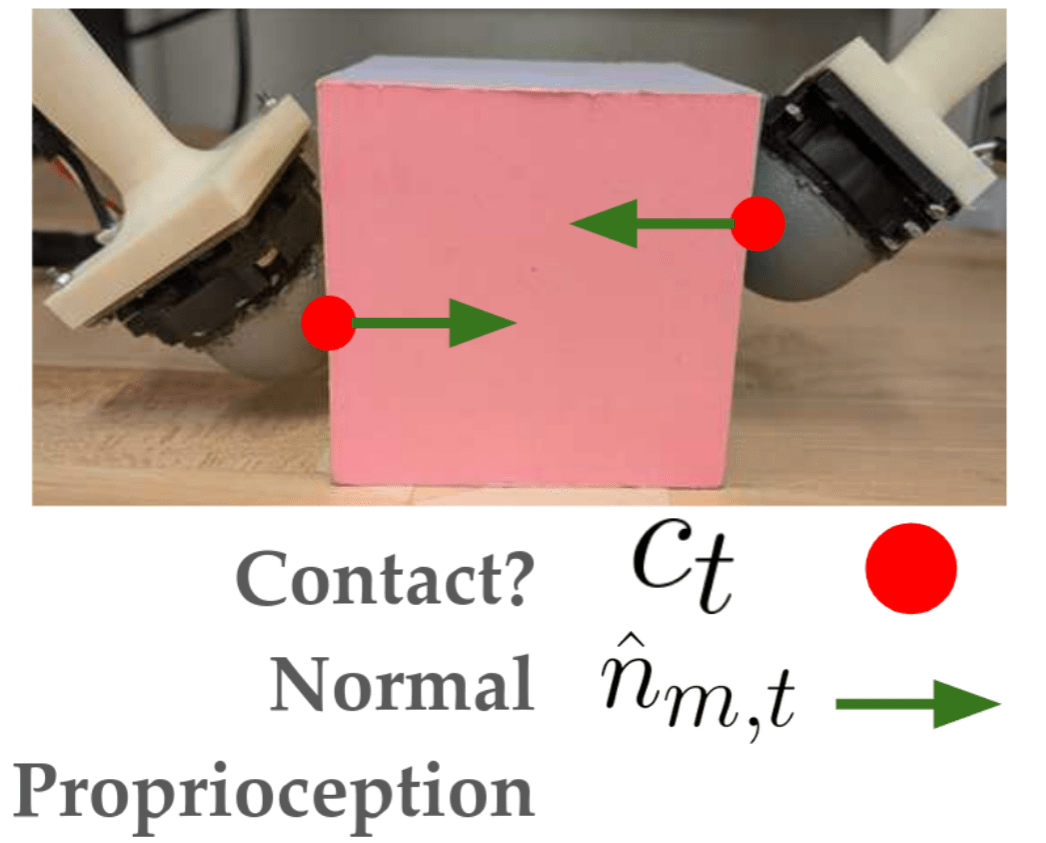
Dynamic Object System Identification
Choose:
-
Robot Trajectory \(r_t\)
Measure:
Find:
-
Object Geometry \(\theta^*\)
-
Object Pose \(x^*_T\)
Previous Work in Tactile SysID
Static Objects: "assume a sensor that can detect contact before causing movement" [2]
Utilizes 2D OR discrete object priors.
Spatially Sparse Data -> Active Learning
[1] Hu et al, Biomimetic Intelligence and Robotics 2024 ; [2] Xu et al. "TANDEM3D...", ICRA 2023
Likelihood Through Contact Dynamics
E.K. Gordon et al, "Active Tactile Exploration...", ICRA 2026

\(m_0\)
\(\ldots\)
\(x_5\)?
We measure contact at \(t=0\).
(Learning) Where is the object at \(t=5\)?
(Information) How certain are we?
Likelihood: \(\mathbb{P}(m_0 | x_5) = \mathbb{P}(m_0 | x_0 = f^{-5}(x_5))\)
That's a backwards simulation.
Measurement Model: \(\mathbb{P}(m_t | x_t)\)
Difficulty #1: It is impossible to simulate Coulomb friction backwards.
(much less differentiate it backwards)
Dynamics: \(x_{t+1} = f(x_t)\)
Online Learning as Trajectory Optimization
E.K. Gordon et al, "Active Tactile Exploration...", ICRA 2026
Avoid Difficulty #1 by optimizing the entire trajectory:
\(\mathbb{P}(m_0 | x_5) \rightarrow \mathbb{P}(m_0 | \tau=[x_0,\ldots,x_5])\mathbb{P}(\tau)\)
Loss \(\mathcal{L} := -\sum_t\log\mathbb{P}(m_t | x_t) + ||x_t - f(x_{t-1})||^2\)
Difficulty #2: contact dynamics \(f\) often have near-0 or near-\(\infty\) gradients.
(Approximately) Minimizing Graph Distance
B. Bianchini et al, "Generalization Bounded...", L4DC 2022; E.K. Gordon et al, "Active Tactile Exploration...", ICRA 2026
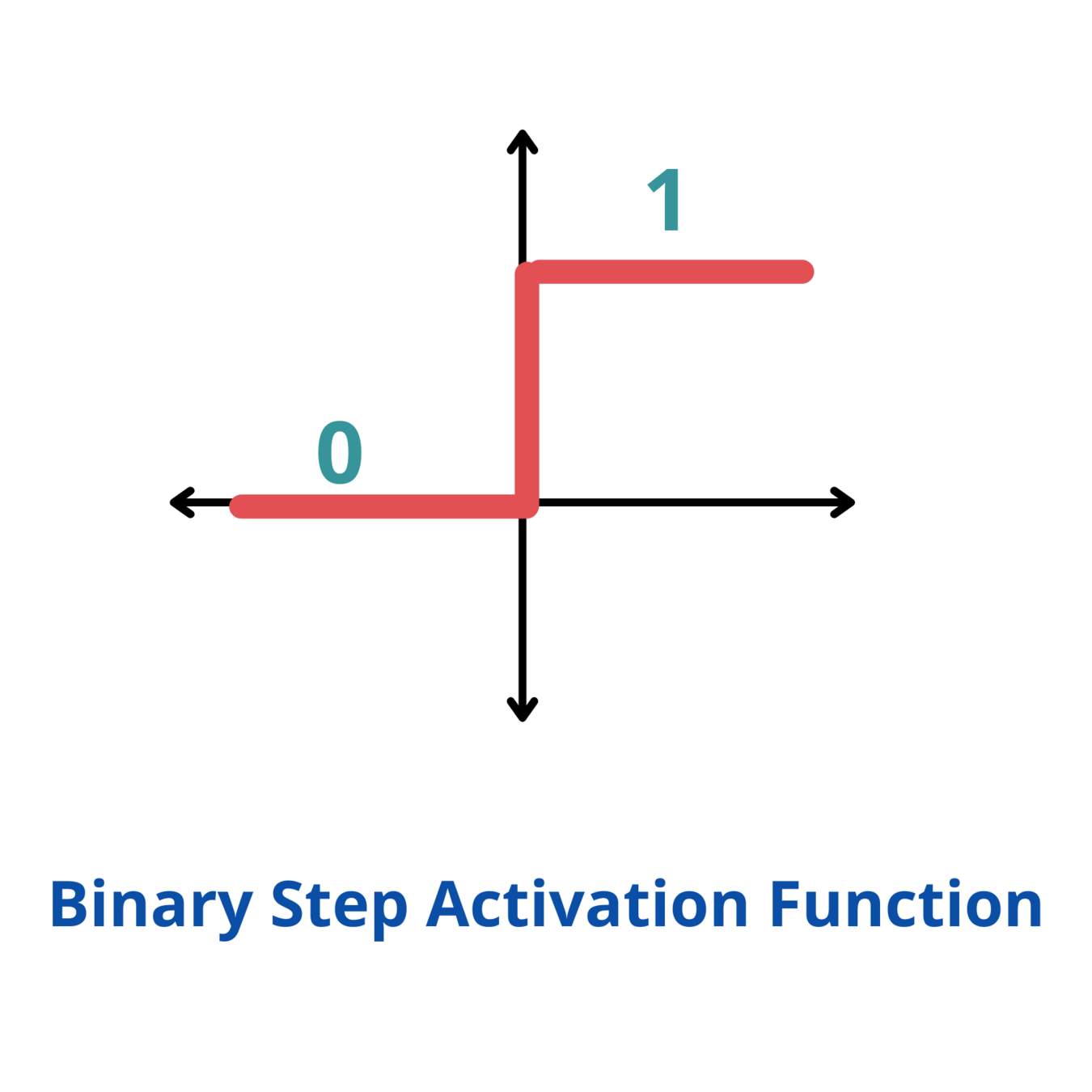
Analogy: \(y = H(x-\theta)\)
\(\theta\)
\(x\)
\(y\)
\(\mathcal{D}\)
Mean Square Error
\(\mathcal{L}_{MSE} = \sum_\mathcal{D}||y_{\mathcal{D}} - H(x_\mathcal{D}-\theta)||^2\)
MSE
GD
Alternative: Graph Distance
\(\mathcal{L}_{GD} = \sum_\mathcal{D}\min_x||(x_{\mathcal{D}}, y_{\mathcal{D}}) - (x, H(x-\theta))||^2\)
Problem: look at \(\nabla_\theta \mathcal{L}_{MSE}\).
It is 0 almost everywhere!
Trade-Off:
- Pro: Loss gradient is finite (or bounded) everywhere.
- Con: Potentially expensive inner optimization loop.
Learning with a Violation-Implicit Loss
Inner Opt (QP) over contact forces.
\(\mathbb{P}(m_t | x_t)\)
Quantifying Information Without a Prior
\(\Theta\)
\(\mathcal{L}\)
\(\tilde{\Theta}\)
\(\Theta\)
\(\mathcal{L}\)
\(\tilde{\Theta}\)
Maximum Likelihood Estimate: \(\tilde{\Theta} = \arg\min_\Theta\mathcal{L}(\Theta)\)
\(\rightarrow \frac{d\mathcal{L}}{d\Theta}(\tilde{\Theta}) = 0\)
Information \(\rightarrow\) How certain am I? Ideally: answer without a strong prior.
How certain is this?
Noise Floor
Low Info
High Info
Past (Observed) Information:
\(\mathcal{I} := \sum_{m_t}\nabla_{\Theta}\mathcal{L}\left(\nabla_{\Theta}\mathcal{L}\right)^T\)
Future (Fisher) Information:
\(\mathcal{F} := Var_{m_t}\left[\nabla_{\Theta}\mathcal{L}\right]\)
\(= \mathbb{E}_{m_t}\left[\nabla_{\Theta}\mathcal{L}\left(\nabla_{\Theta}\mathcal{L}\right)^T\right] \)
EIG \(:= \log\det(\mathcal{F}\mathcal{I}^{-1} + \mathbf{I})\)
E.K. Gordon et al, "Active Tactile Exploration...", ICRA 2026
Expected Information Gain (EIG)
Learn; Compute
Observed Info \(\mathcal{I}\)
Sample Actions + Simulate
Expected Fisher Info \(\mathcal{F}\)
\(\max EIG := \log\det\left(\mathcal{F}\mathcal{I}^{-1} + \mathbf{I}\right)\)
Choose actions where simulated, expected Fisher info is distinct from Observed info.
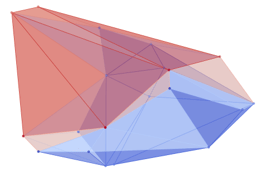
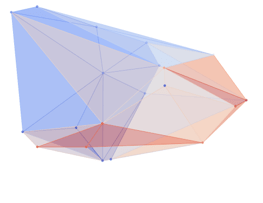
Computing Fisher Information
No avoiding Difficulty #1, we need \(\nabla_{x_5}\mathbb{P}(m_0 | x_5)\) to compute \(\mathbb{E}_{m_0}[(\nabla_{x_5}\mathbb{P}(m_0 | x_5))^2]\)
E.K. Gordon et al, "Active Tactile Exploration...", ICRA 2026
"Quasi-Static" Solution: pretend \(\nabla_{x_5}x_0 = \mathbf{I}\)
\(\mathcal{F} = \sum_t \mathbb{E}_{m_t}[(\nabla_{x_t}\mathbb{P}(m_t|x_t))^2]\)
Pro: Easy to compute
For Gaussian measurement model, no sampling required for \(\mathbb{E}\)
Information Maximization In Action
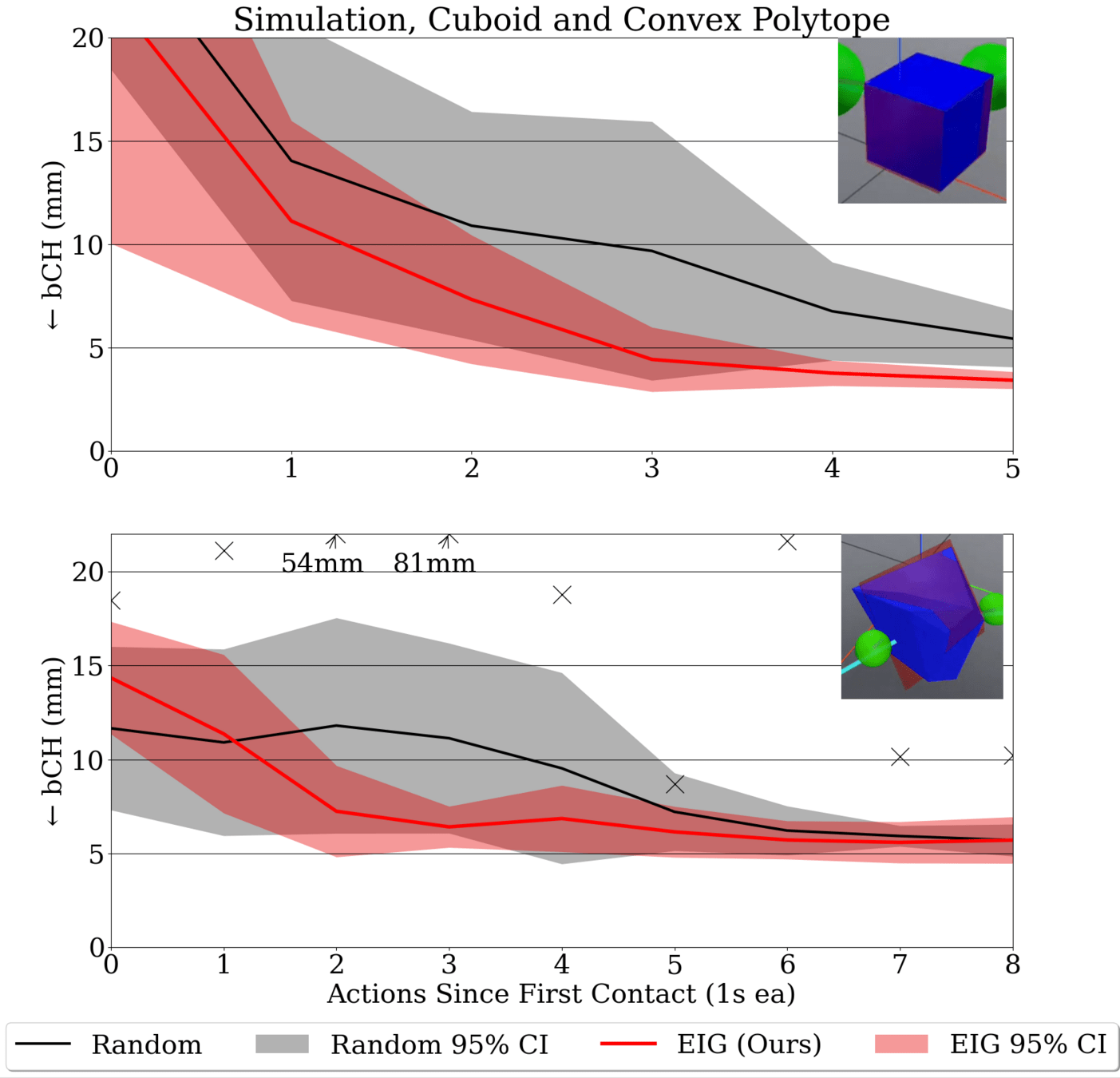
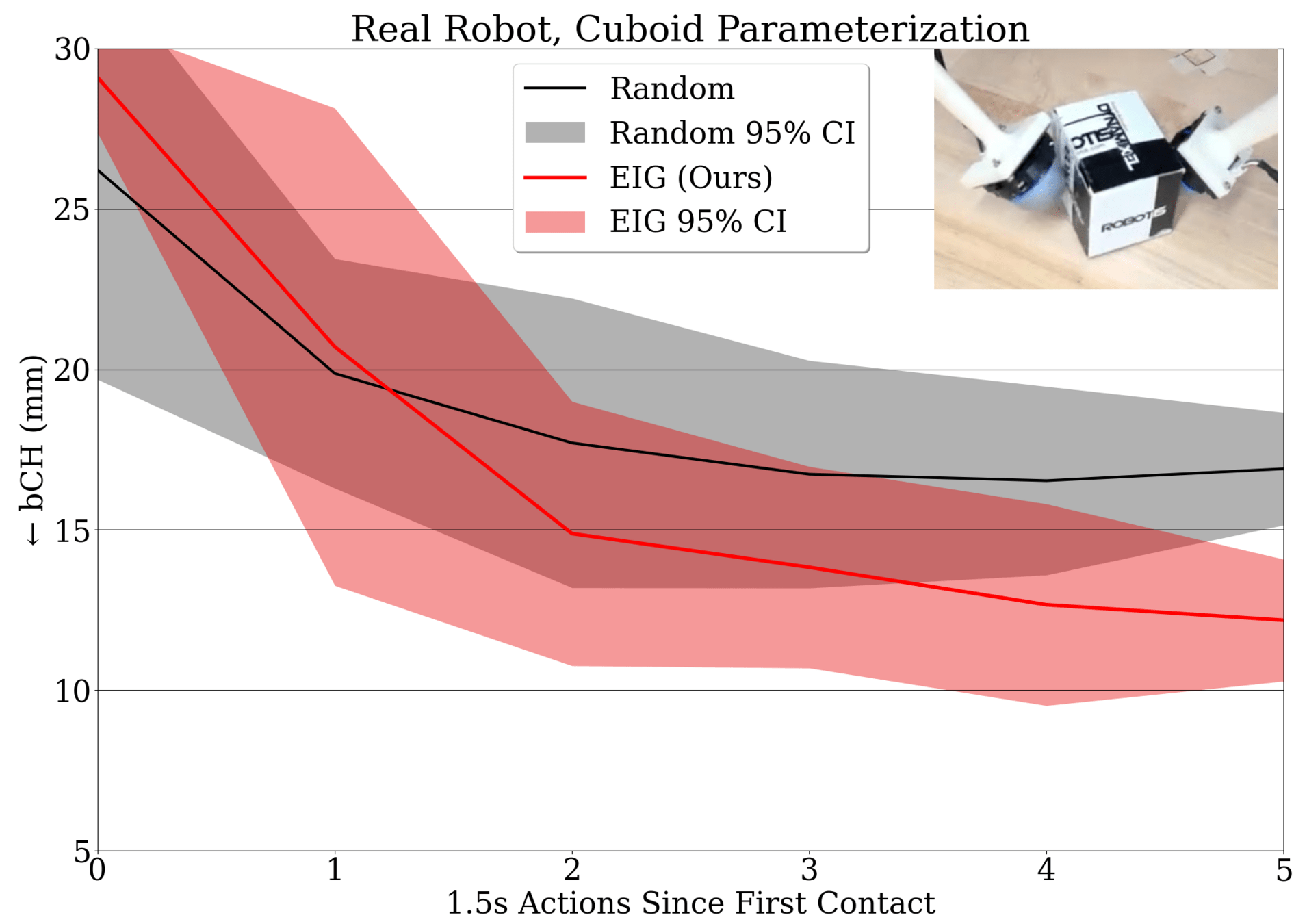
E. Gordon et al, "Active Tactile Exploration...", ICRA 2026
Information Through Marginalization


Ongoing Work
"Quasi-Static" Solution won't work for more dynamic systems.
Can we do better? Yes, through marginalization.
\(\approx softmax_{\tau\sim MCMC}\left(\log \mathbb{P}(m_0 | x_0)\right) \cdot \left(\nabla_{x_T}||f(x_{T-1}) - x_T||_2^2\right)\)
\(=\nabla_{x_T} \log\int_{\tau}\mathbb{P}(m_0 | \tau)\mathbb{P}(\tau| x_T)\)
We want \(\nabla_{x_T} \log\mathbb{P}(m_0 | x_T)\)
Con: We introduce sampling. However...
Pros:
- No gradient of \(f\) required
- For sampling: we already have a good guess of \(\tau\) from the learning algorithm
Journal Extension in the works...
Information Through Marginalization
We want \(\nabla_{x_T} \log\mathbb{P}(m_t | x_T)\)
Ongoing Work
\(=\nabla_{x_T} \log\int_{x_t}\mathbb{P}(m_t | x_t)\mathbb{P}(x_t | x_T)\)
Assume:
\(\mathbb{P}(x_t | x_T) \propto \exp(f(x_t, x_T))\)
\(\approx\nabla_{x_T} \log\sum_{x_t\sim U}\mathbb{P}(m_t | x_t)\mathbb{P}(x_t | x_T)\)
\(=softmax_{x_t\sim U}\left(\log \mathbb{P}(m_t | x_t)+ f(x_t, x_T)\right) \cdot \left(\nabla_{x_T}f(x_t, x_T)\right)\)
\(=softmax_{x_t\sim MCMC}\left(\log \mathbb{P}(m_t | x_t)\right) \cdot \left(\nabla_{x_T}f(x_t, x_T)\right)\)
No gradient through sampling
At the cost of sampling trajectories \(x_t\) (via MCMC), we bypass the inverse Jacobian.
(If we have a good guess \(\tilde{x}_t\), MCMC should be quick)
Summary
-
The Promise of Physically Assistive Robotics
-
Robot-Assisted Feeding: User-Defined Metrics
-
Food Bite Acquisition as a Contextual Bandit
- Policy space reduction a priori
- Haptics as post hoc bandit context
-
Active Learning with Dynamic Contact
-
Community-Based Participatory Design
-
Research @ Ai2: Safety and Interpretability
Multimodal Active Learning
Physically Assistive Robots
Community-Based Participatory Design
E. Gordon et al, "An adaptable, safe, and portable robot-assisted feeding system.", HRI Companion 2024Community-Based Participatory Design
A. Nanavati, E. Gordon et al, "Lessons learned from designing...", HRI 2025Summary
-
The Promise of Physically Assistive Robotics
-
Robot-Assisted Feeding: User-Defined Metrics
-
Food Bite Acquisition as a Contextual Bandit
- Policy space reduction a priori
- Haptics as post hoc bandit context
-
Active Learning with Dynamic Contact
-
Community-Based Participatory Design
-
Research @ Ai2: Safety and Interpretability

Bringing Foundation Models into the Home
- How can we make it safer?
- How can we make it more interpretable?
- How can it adapt from deployment data?

Learned Uncertainty
Images
\(\mathcal{L}\)
Used privileged simulator information to compute
observed info \(\approx\) uncertainty.
Have the VLA try to learn that uncertainty explicitly.
States
Observed Information:
\(\mathcal{I} := \sum_{m_t}\nabla_{\Theta}\mathcal{L}\left(\nabla_{\Theta}\mathcal{L}\right)^T\)
Model-Based Distillation
Dataset \(\mathcal{D}\)
Perception
World Model + Policy
\(\mathcal{L}\)
Run Classical Techniques on World-Model:
- Information Quantification (Observed and \(\mathbb{E}_\pi\))
- Generate / efficiently sample fine-tuning sim data.
- Offline MPC when compute or connectivity are limited (portability).
Safety and Active Exploration
As et al, "ActSafe...", ICLR 2025Beneficial to play optimistically w.r.t. loss
Safer to play pessimistically w.r.t. model parameters
Identify loss components that are safety-critical (pessimistic) vs. performance-critical (optimistic).
Residual Active Learning at Test Time
Residual Policy
\(a\)
- Augment the baseline, frozen foundation model with a smaller residual policy.
- Update the residual policy at deployment time
- The residual policy can use the previous techniques and use past data to minimize regret.

\(a + \tilde{a}\)
\(\mathcal{L}\)
Thank you!










DAIR Lab
Amal Nanavati



Empowering Physically Assistive Robots
Ethan K. Gordon
Postdoc, University of Pennsylvania
PhD 2023, University of Washington
with Contact-Rich Active Learning
Ethan AI2 Job Talk
By Michael Posa
Ethan AI2 Job Talk
45min




