NLP applications @ welt.de
Berlin NLP Meetup
30 August 2018
Stoyan Stoyanov
welt.de
whoami

Motivation
- https://www.welt.de
- 150M Visits per Month and growing
Motivation
- Corpus of 5m+ articles
- A lot of already annotated text
- User generated content
Click Predictions
- Number of clicks in the first hour
- How long from publication to first social media interactions (or comments)
- Category, Locations, Names, Organizations
Click Predictions (cont'd)
- Publication date
- Freshness
- Position
Content Matching
- Match coupons for specific content
- Ads
- Recommendations
SEO
- Reducing duplicate content
- Text mining
- Theme pages
Let's talk about text mining.
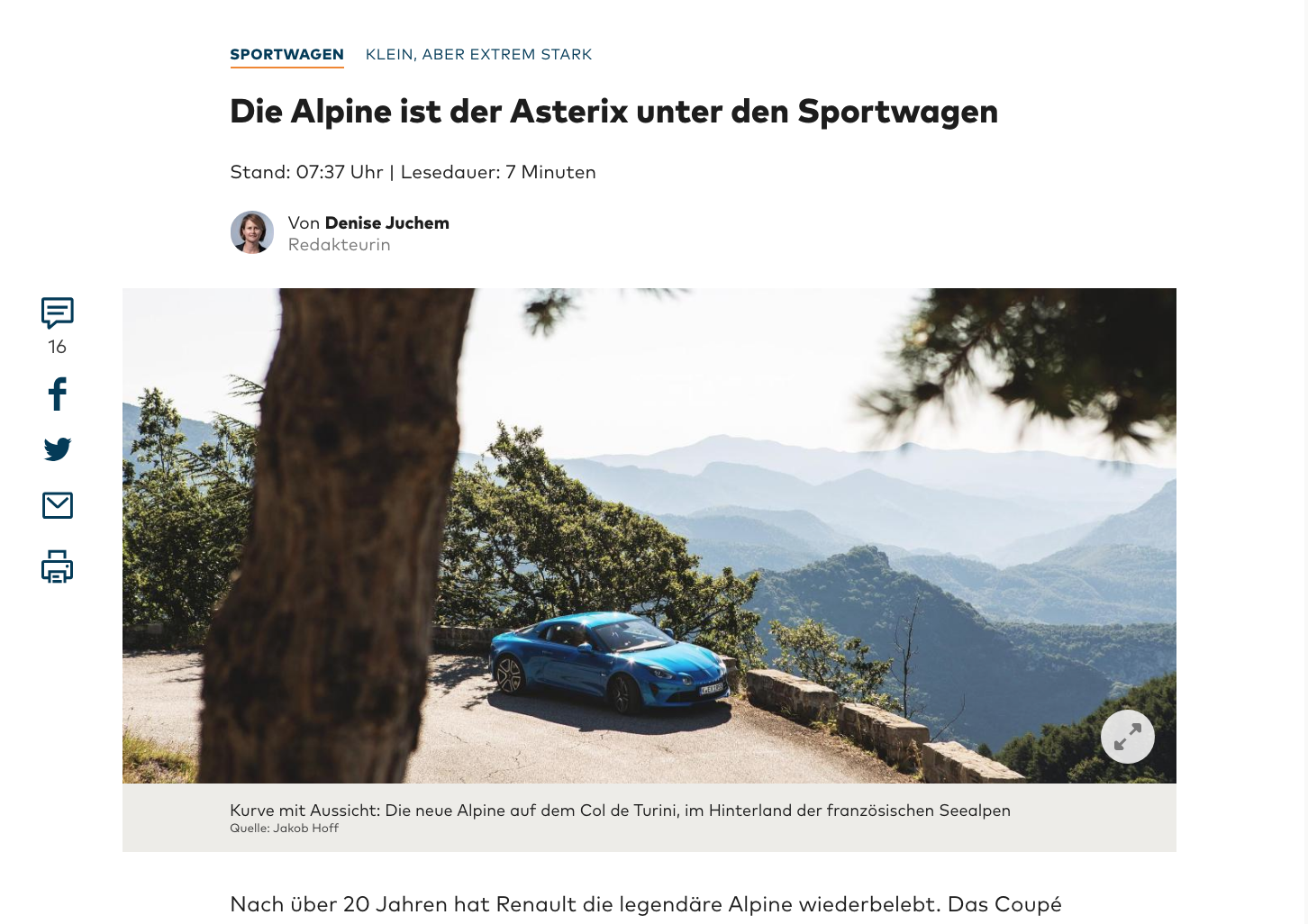
Nach über 20 Jahren hat Renault(ORG) die legendäre Alpine(ORG) wiederbelebt. Das Coupé konkurriert mit deutschen Sportwagen, ist aber leichter und agiler. Eine Ausfahrt durch die Haarnadelkurven des Col de Turini(LOC).
Das erste Pflichtspiel unter Trainer Lucien Favre(PER) geriet zum Drama. Dortmund(ORG) war bereits mausetot, erreichte am Ende aber dennoch die zweite Pokalrunde. Erst rettete Neuzugang Witsel(PER) den BVB(ORG) in die Verlängerung, dann traf Reus(PER)
So how we can achieve this? Let's simplify a bit.
Linear-chain CRF
Output: "1 (quantity) cup (unit) of (other) coffee (name)"
Input: "1 cup of coffee"
Linear-chain CRF
- features depend on
- the current label
- the previous label
Feature Functions
- $$ f_{1}(s, i, l_{i}, l_{i-1}) = 1$$
-
If current label is quantity and its position is 0
- ("1 cup of coffee", 0, "quantity", "")
- weight = 0.25
Feature Functions
- $$ f_{2}(s, i, l_{i}, l_{i-1}) = 1$$
-
If current label is unit and previous is quantity
- ("1 cup of coffee", 1, unit, quantity)
- weight = 0.30
Linear-chain CRF
score(t|s) = \sum_{j=1}^{m}\sum_{i=1}^{n}\lambda_{j}f_{j}(s,i,t,t_{i-1})
p(t|s)=\dfrac{e^{(\sum_{j=1}^{m}\sum_{i=1}^{n}\lambda_{j}f_{j}(s,i,t,t_{i-1}))}}{\sum_{t^\prime\in t} e^{(\sum_{j=1}^{m}\sum_{i=1}^{n}\lambda_{j}f_{j}(s,i,t^\prime,t^\prime_{i-1}))}}
Linear-chain CRF
1 (quantity) cup (unit) of (other) coffee (name)
score(t|s)=
(0.3+0+0+0)+
(0+0.25+0+0)=0.55
Linear-chain CRF
1 (quantity) cup (quantity) of
(quantity) coffee (quantity)
1 (quantity) cup (quantity) of (quantity) coffee (name)
1 (quantity) cup (name) of (name) coffee (name)
1 (name) cup (name) of (name) coffee (name)
..
tags^{words}=4^4
Conditional Random Fields
- Define feature functions with random weights
- Learn from training data (e.g. with gradient descent)
- Calculate the probabilities of every possible tagging sequence for the sentence in our training set
Conditional Random Fields (cont'd)
- Learn from training data
- Calculate the difference between the real contribution of a function and the model contribution
- Adjust the features' weights
- Calculate the difference between the real contribution of a function and the model contribution
Parameter Estimation
\lambda_{i} = \lambda_{i} + \alpha(\sum_{j=1}^{n}f_{j}(s,i,t,t_{j-1})-\sum_{t^\prime} p(t^\prime|s)\sum_{j=1}^{n}f_{j}(s,i,t^\prime,t^\prime_{j-1}))

NER@welt
- Stanford NLP
- NER
- POS (We need the Nouns)
- Training with welt' articles
- Integration in the CMS
- Testing with an existing manual labeling
Other techniques that we use..
The coordinates of a tag
TF-IDF
tfidf(w,d)=tf\cdot\log(\dfrac{N+1}{N_{w}+1}) + 1
Stemming
"our", "meet", "today", "wa", "wors", "than", "yesterday", ",", "i", "'m", "scare", "of", "meet", "the", "client", "tomorrow"
Lemmas
"our", "meeting", "today", "be", "bad", "than", "yesterday", ",", "i", "be","scared", "of", "meet", "the", "client", "tomorrow"
Multinominal Naive Bayes
- Simple text classification
- Ideal for prototyping
- Very fast
- Easy to implement

Mixing all signals together
- NER
- TF-IDF
- The position of a tag in the article structure
- Category
Our toolbox
- Go as an alternative to Python
- Stanford NLP
- Spot Instances
- Scikit-learn
The future
- Data Science as part of our culture
- Road to deep learning

NLP@Welt
By Stoyan Stoyanov
NLP@Welt
My work with NLP at welt.de




