





















Nawfal Tachfine
Data Scientist
Data Scientist
formulate
problem
get data
build and clean dataset
study dataset
train model
+ feature selection
+ algorithm selection
+ hyperparameter optimization
automatically serve predictions to any given information system
Data - source refresh rate, enrichment
Model - stability, maintainability
Operations - scalability, resilience, availability
Resources - no dedicated developers
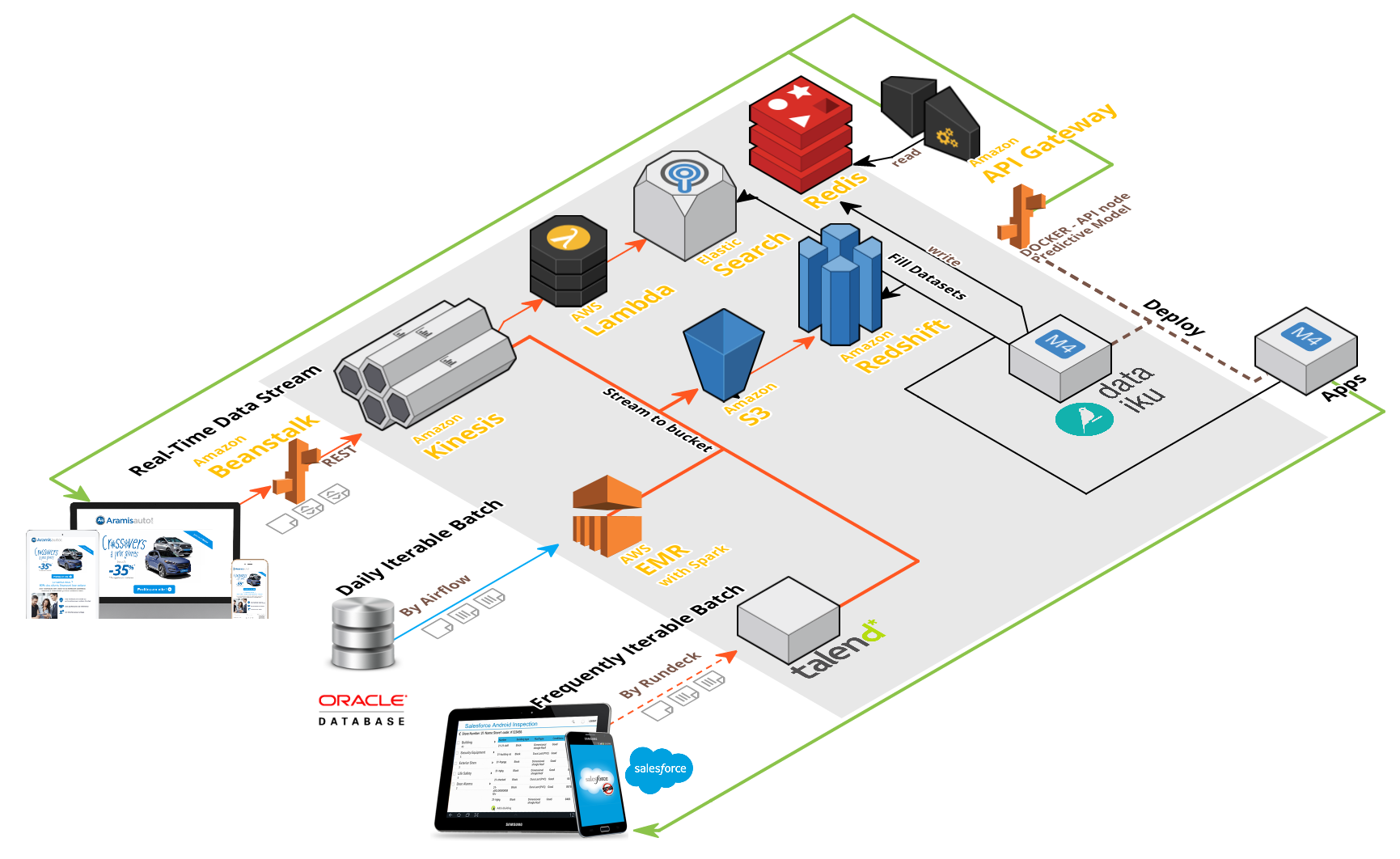
start from final use case and work your way back to data preparation
On demand - client/server architecture
Complete features → REST API
Partial features → enrichment necessary
Lookup sufficient → REST API + key-value data store
Complex enrichment from database → API usable but slow
Trigger-based (time/event) → batch mode
Computationally efficient
Can serve predictions directly to destination
Think about your production use-case as early as possible.
@app.route('/api/v1.0/aballone', methods=['POST'])
def index():
query = request.get_json()['inputs']
data = prepare(query)
output = model.predict(data)
return jsonify({'outputs': output})
if __name__ == '__main__':
app.run(host='0.0.0.0')
query
prediction
query
predictions
partial features
full features
features
predictions
leads
features
scores
lookup
score
features
scores
@NawfalTachfine
By Nawfal Tachfine
