RL in Systems-land
Nikhilesh Singh
Many examples taken from David Silver's UCL course
https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLqYmG7hTraZDMOYHWgPebj2MfCFzFObQ

What do these tasks have in common?
- Stock investing
- Playing Go
- Maintaining a power grid
- Attacking an anti-virus program
- Driving a car
- ...
- Life
Decisionmaking!!*
*often sequential and preferably optimal.
A bit of history
- Ideated by Turing, Bellman and others.
- RL, as we know today, can be attributed to:


Andrew Barto
Richard Sutton

These pictures are old, yes, even by Academia standards.

The tipping point!
The 'L'-word

Supervised
Model
Input
\hat{y}
Ground truth
y
Minimize the Loss.
Unsupervised
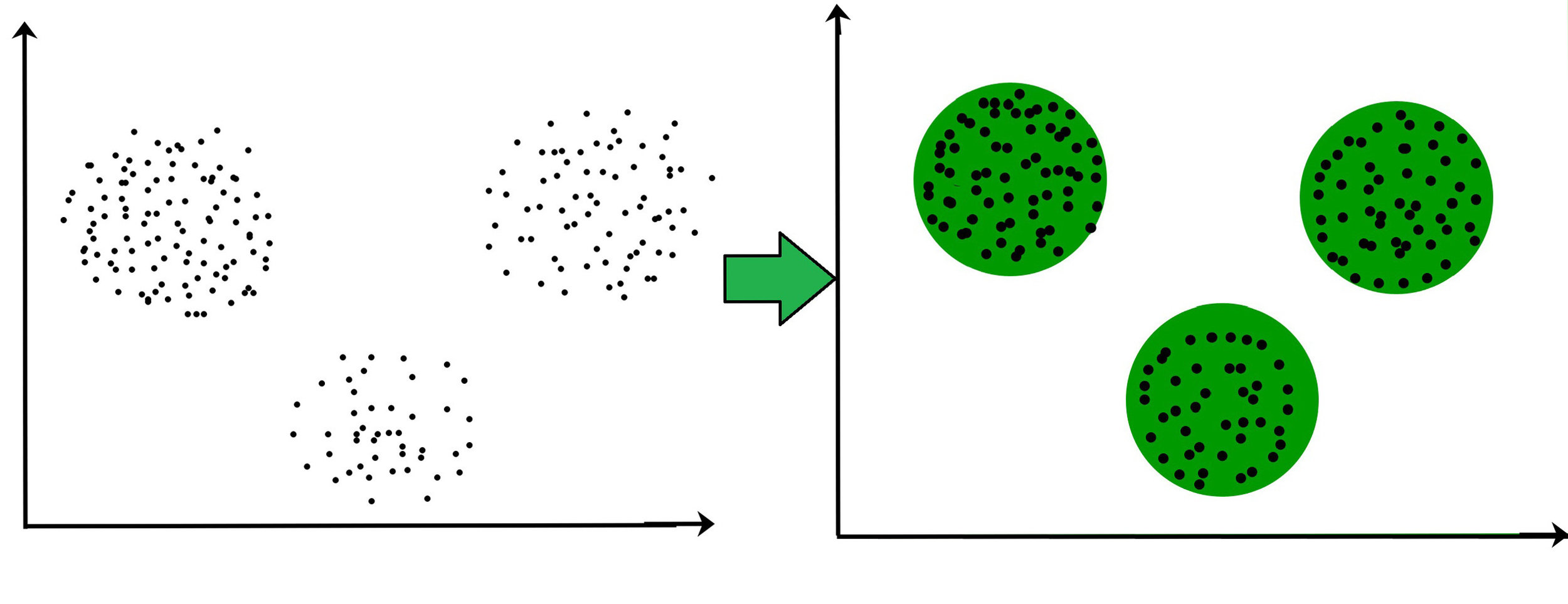
RL

How RL differs?
- No supervisor, only rewards as feedback.
- Delayed feedback.
- Sequential (
Independent and Identically distributed). - Attributes are indexed by time, because of sequentiality.
- Actions have ripple effects (read Karma!).
Terminologies
1. Agent
- The RL agent. Relax, it's just an algorithm.
2. Environment
- The universe the agent is in.
- For example, the game it is playing or the room a robot is learning to walk in.
- Can be fully or partially available to the agent.
3. Actions
- The actions the agent takes, literally.
- Can be discrete or continuous.
Actions for Super Mario
- Move Left
- Move Right
- Jump
- ...
4. Rewards
- Scalar feedback at time t,
- Hypothesis: All goals can be described
as the maximization of cumulative rewards.
R_t
Rewards for Super Mario
- Goal: Save the princess.
- -ve reward for losing life.
- +ve reward for gaining game score.
- Super +ve reward for saving the princess.
5. States
- Environment State: State of the environment.
- Agent State: State of the agent in the environment.
- Information State: The information held at a moment.
Which way, Captain?

Stick'em with the pointy end
The agent state description.
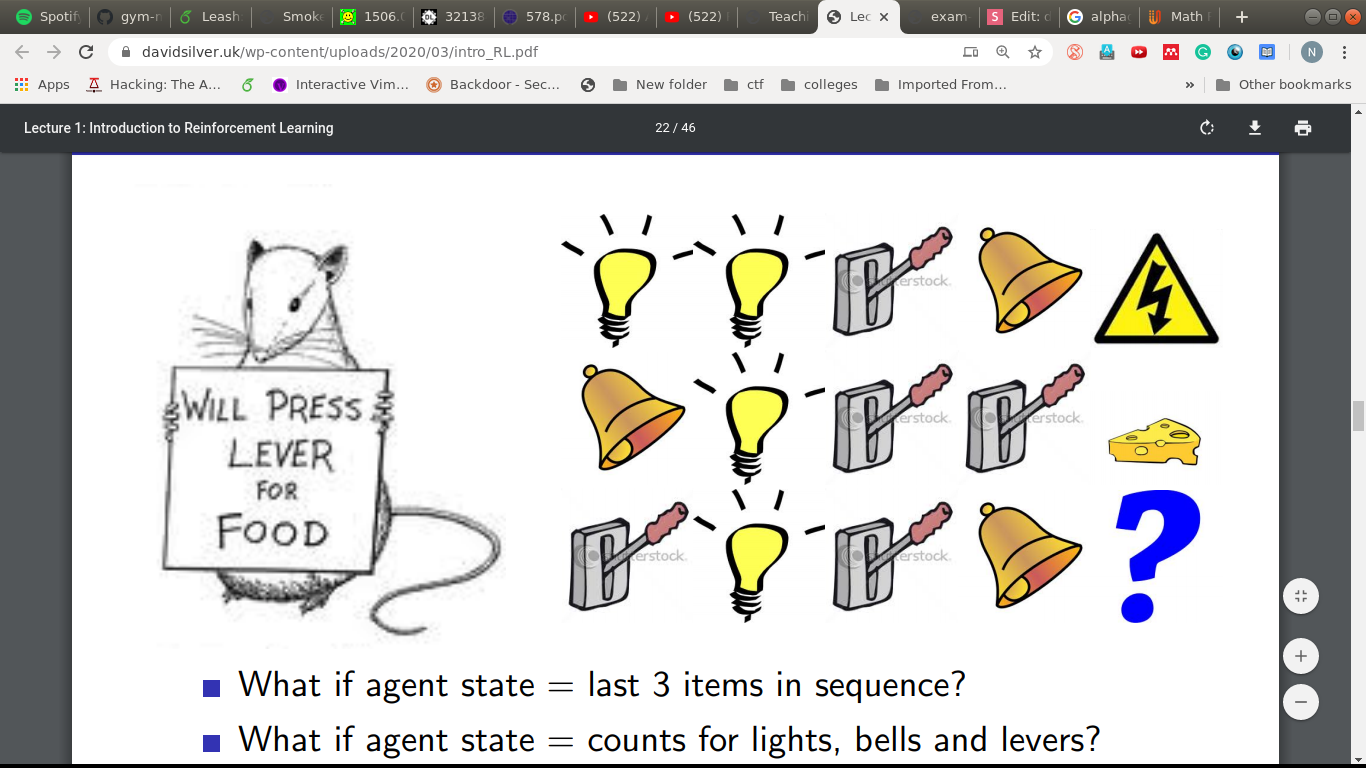
What if,
- Agent state = last 3 items?
- Agent state = counts of bells, lights and levers?
- Agent state = entire sequence?


The full picture
The full picture
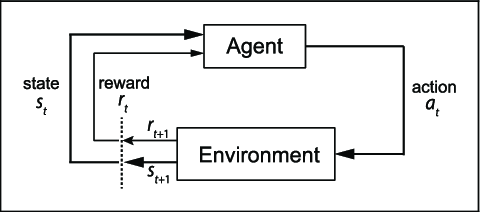
But, how does the agent take actions?

RL agent attributes
- Policy
- Value Function
- Model
Policy ( )
- Agent's Behavior.
- Mapping from states to actions.
- Deterministic:
- Stochastic:
\pi
a = \pi(s)
\pi(a|s) = \mathcal{P}(A_t =a |S_t =s )
Value Function
- Expected future rewards.
- How good a state is?
V_\pi(s) = E_\pi(R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots | S_t=s )
V(s,a)
= E_\pi(R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots | S_t=s, A_t=a )
Model
- The agent can try to model the environment.
- Based on the model, it can try to predict next state and immediate reward.
An Example
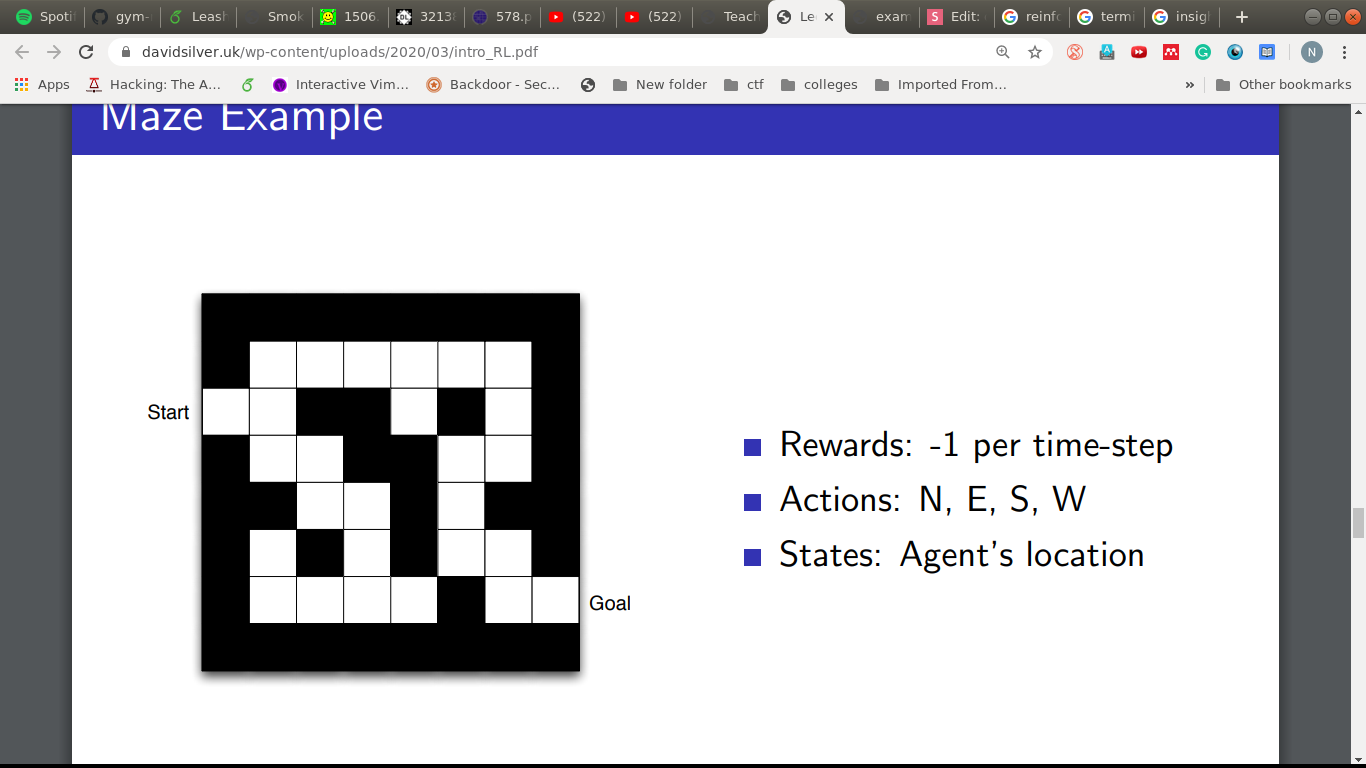
S
D
- Goal: Reach D in the least timesteps
- Env: This maze.
- Rewards: -1 per time-step
- State: Agent's location
- Actions: Up, Down, Left, Right
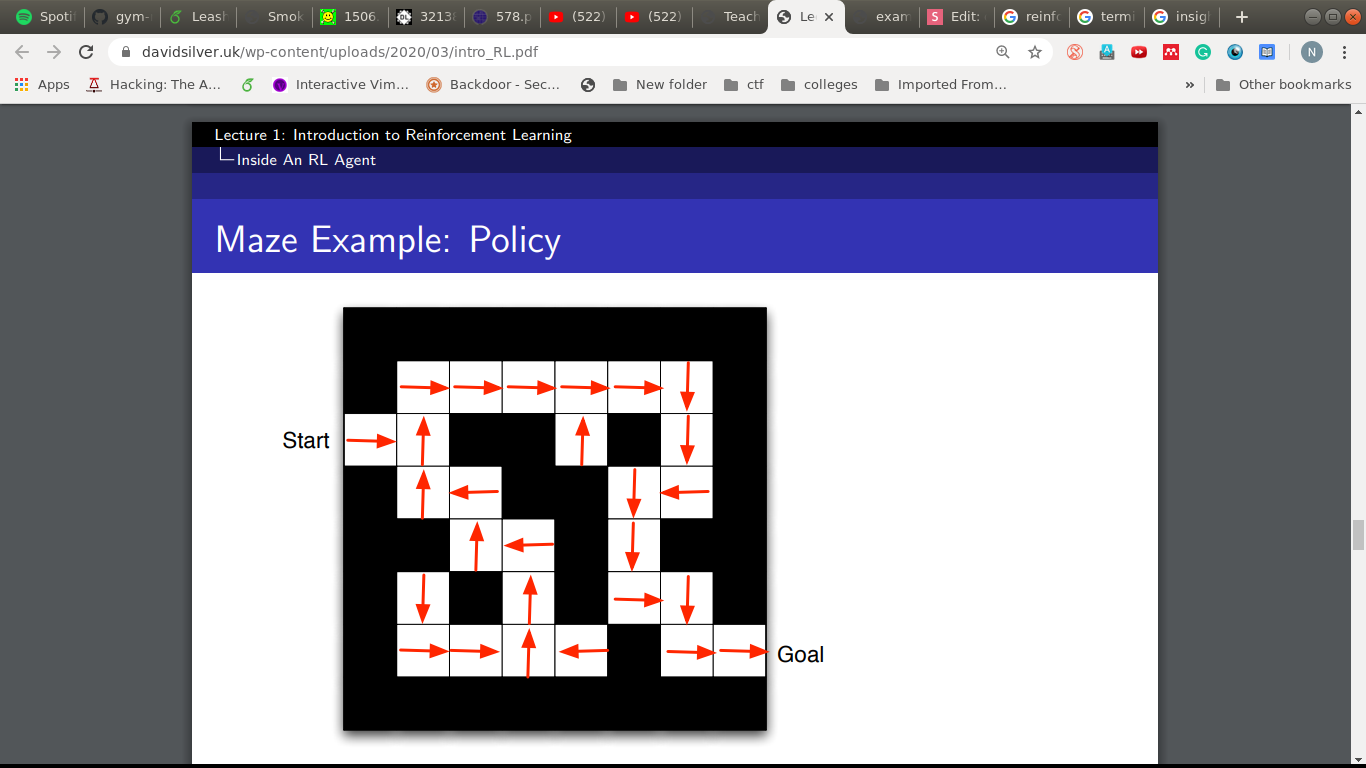
Policy
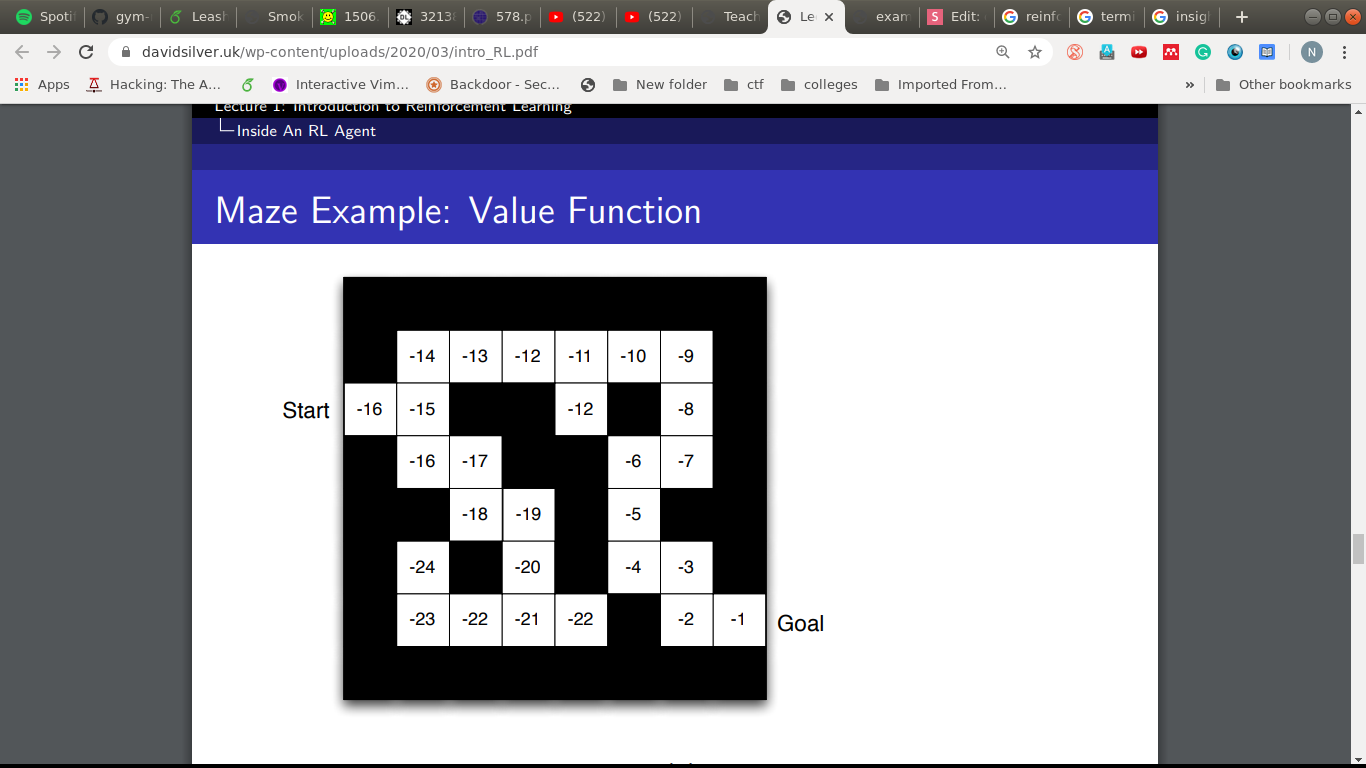
Value Function
Model

- Value-Based
- No policy (implicit)
- Value Function
- Policy-Based
- Policy
- No Value Function
- Actor Critic
- Policy
- Value Function
RL Agent Taxonomy
- Model Free
- Policy and/or Value Function
- No model
- Model-Based
- Policy and/or Value Function
- Model
RL Agent Taxonomy
To explore or exploit?
- Allow randomness to explore.
- Decay randomness as you learn.
- Well, like restaurants, right Gargi?
Part one done...

Tasks
- Pick a problem in your domain where you think RL can help or you want to have a shot at with RL.
- What is the environment?
- What is the Goal?
- How can the agent interact with the environment? Actions?
- How do you define a state?
- How do you distribute the rewards?
- Do let us know and we can put it on next deck of slides!!
Resources
sysDL_rl1
By Nikhilesh Singh



