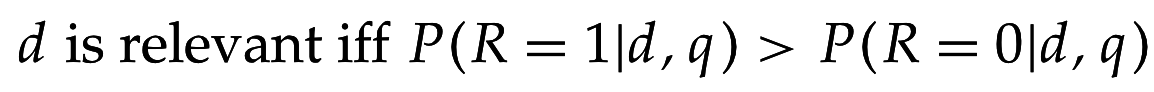
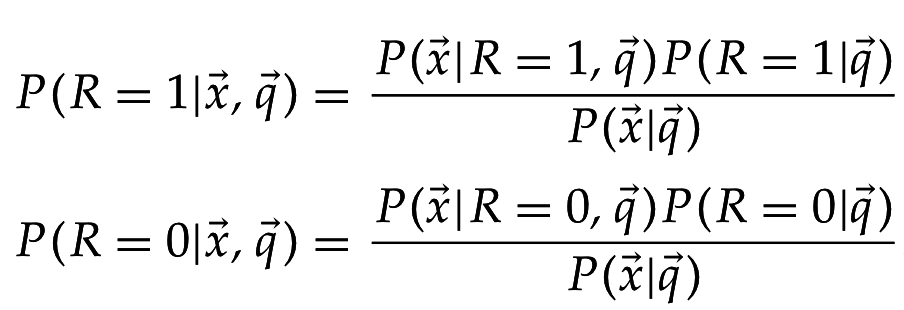
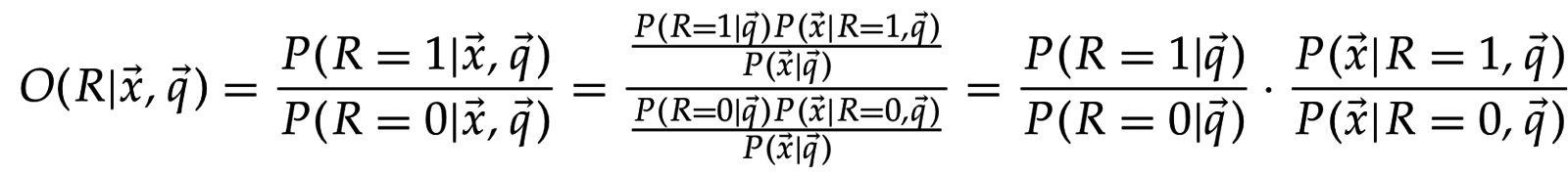
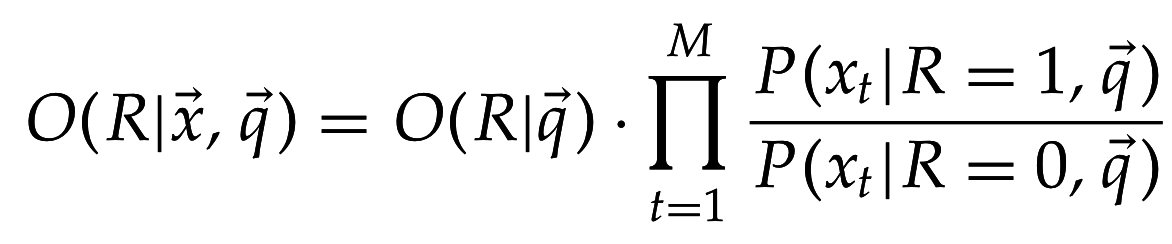
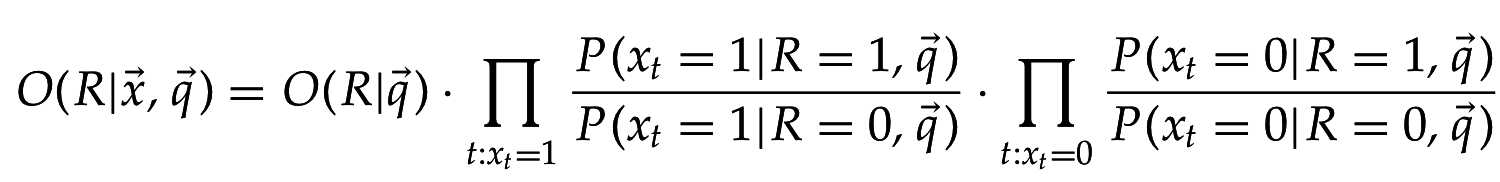
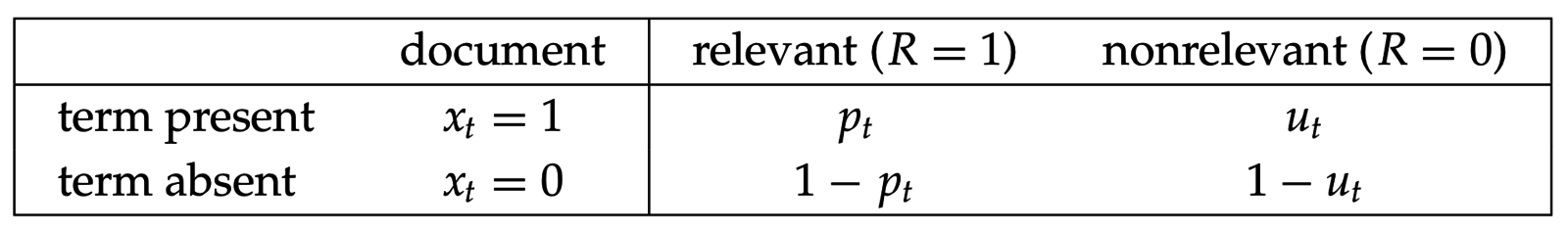
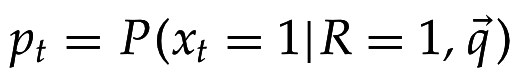
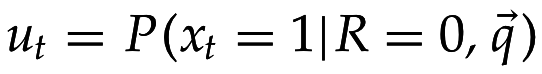
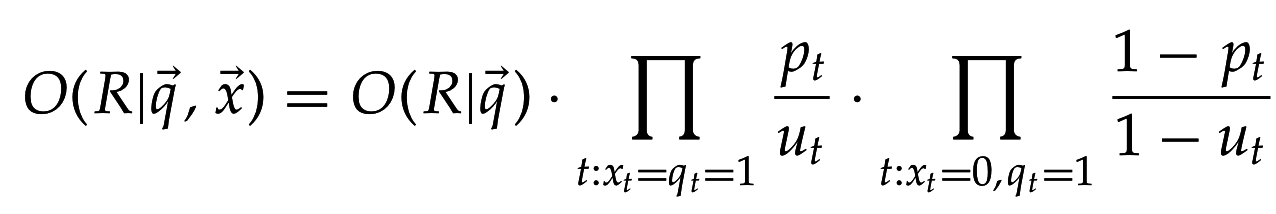
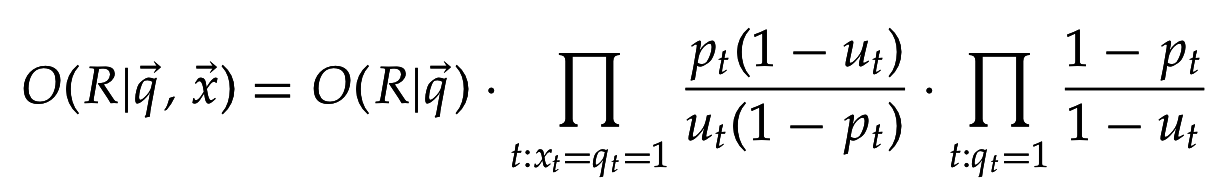
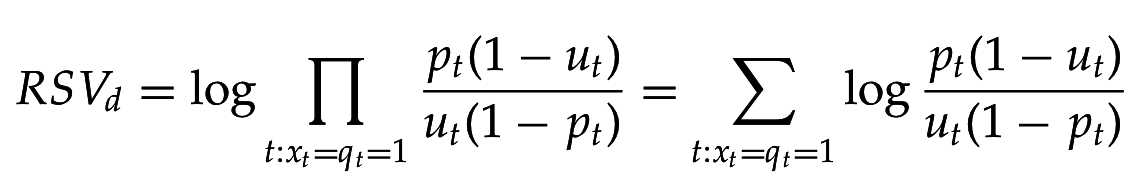
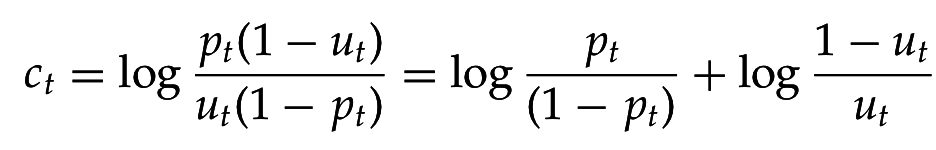
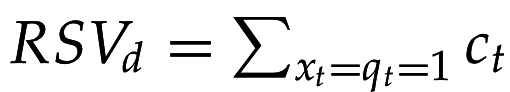
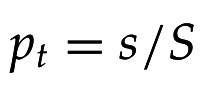
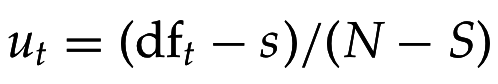
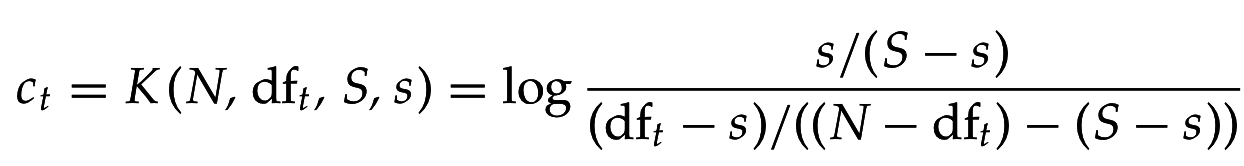
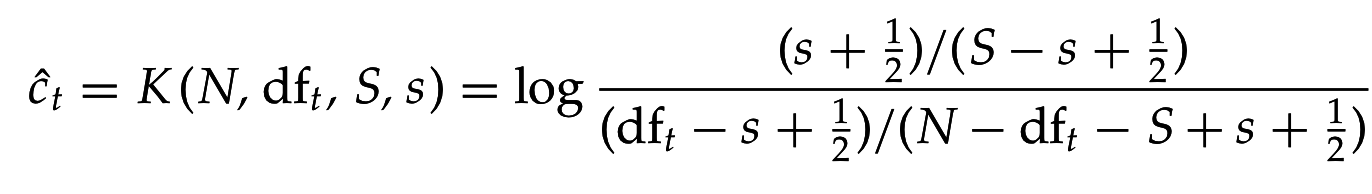
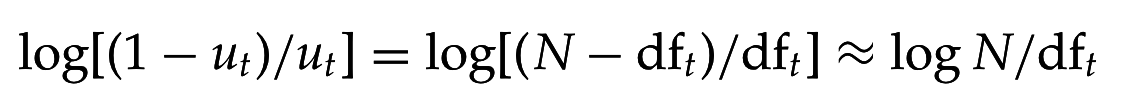
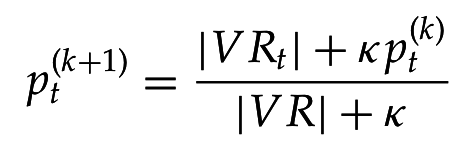
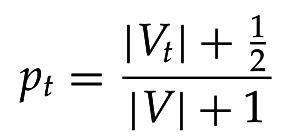
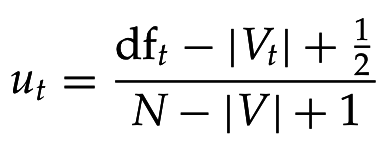
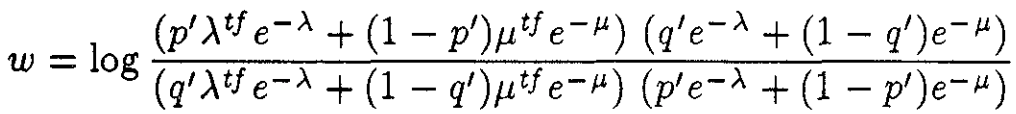
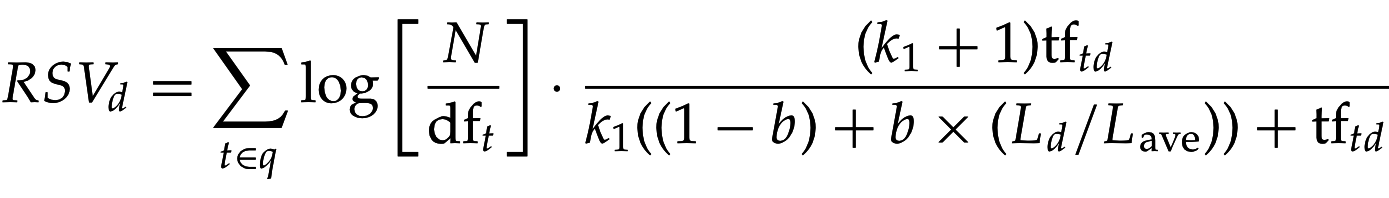
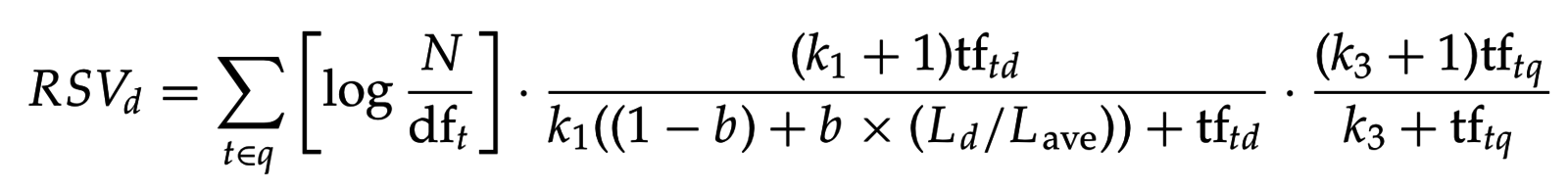

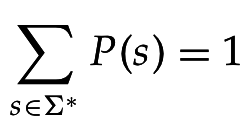
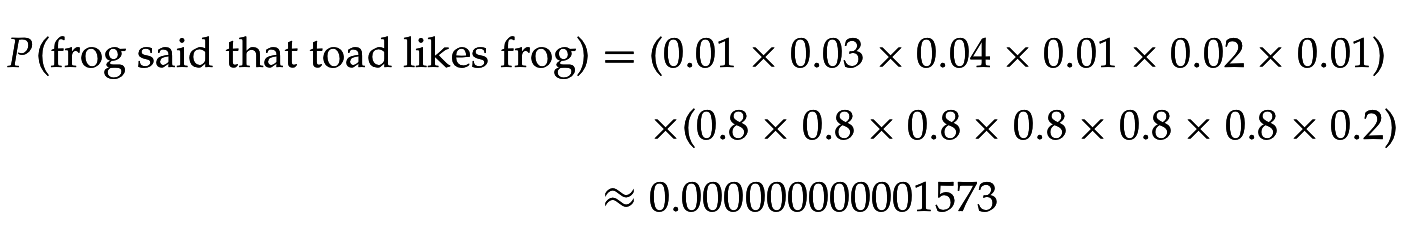

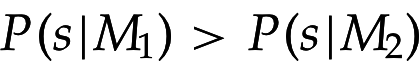
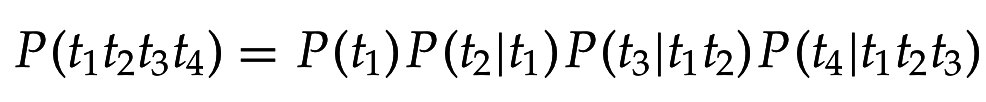
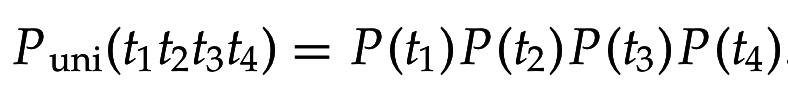
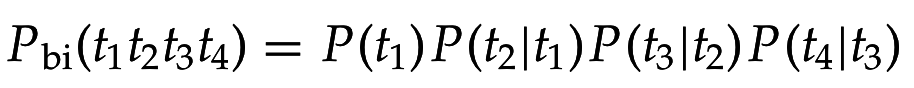
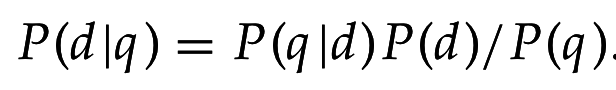
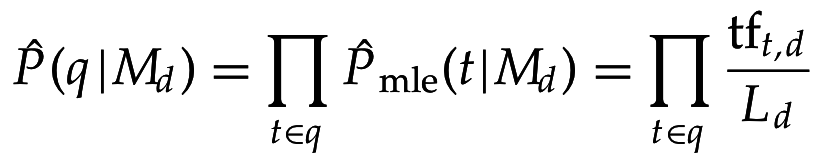
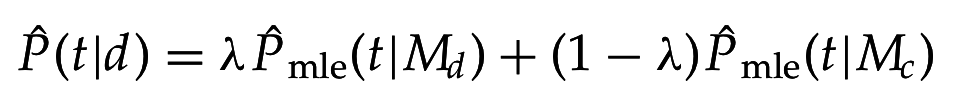
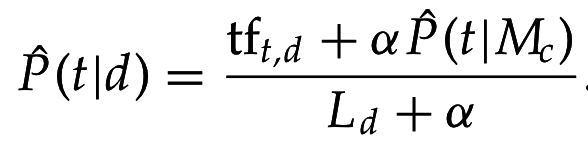
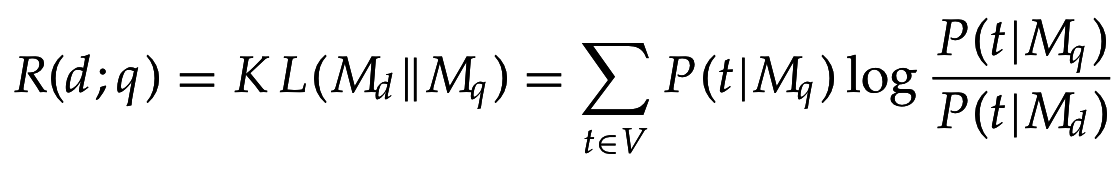
Nikita Zhiltsov
Research fellow at Kazan Federal University (Russia)
Лекция 4
Вероятностные модели поиска и языковое моделирование
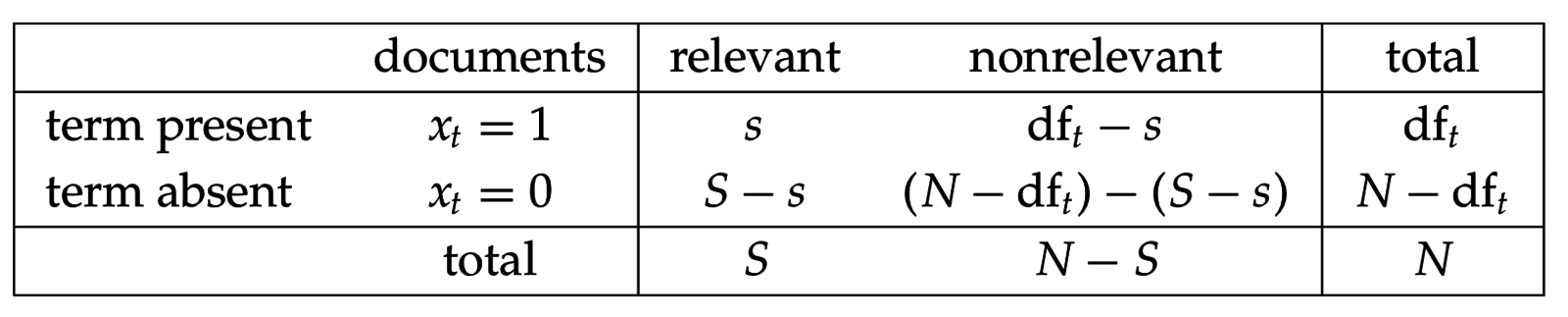
Пусть - случайная индикаторная переменная: =1 если документ d релевантен q, =0 иначе.
Модель бинарных потерь: потеря (loss) - вернуть нерелевантный документ или не вернуть релевантный документ
Теорема. Принцип вероятностного ранжирования оптимален в смысле байесовского риска - мат. ожидания для модели бинарных потерь
=> зная истинное распределение , можно оптимально ранжировать по , но оно неизвестно, можем только оценивать
Применим теорему Байеса:
Вместо оценивания для ранжирования достаточно оценить шансы (odds):
Ввиду "наивного" предположения о независимости появления терминов:
или после перегруппировки множителей:
- вероятность появления термина t в документе, релевантном запросу q
- вероятность появления термина t в нерелевантном документе
Предположим, что термин не из запроса с одинаковой вероятностью встретится как релевантном, так и нерелевантном документе, т.е. для
Отношение 2х шансов: шанс термина запроса появиться в (не)релевантном документе
Со сглаживанием:
4. Оцениваем по методу максимального правдоподобия и сглаживаем по предыдущей оценке:
5. Возвращаемся к шагу 2, пока пользователь не закончит поиск.
4. Уточняем оценки (ненайденные документы считаются нерелевантными):
5. Возвращаемся к шагу 2, пока ранжирование не меняется.
S. Robertson, S. Walker. Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval (1994)
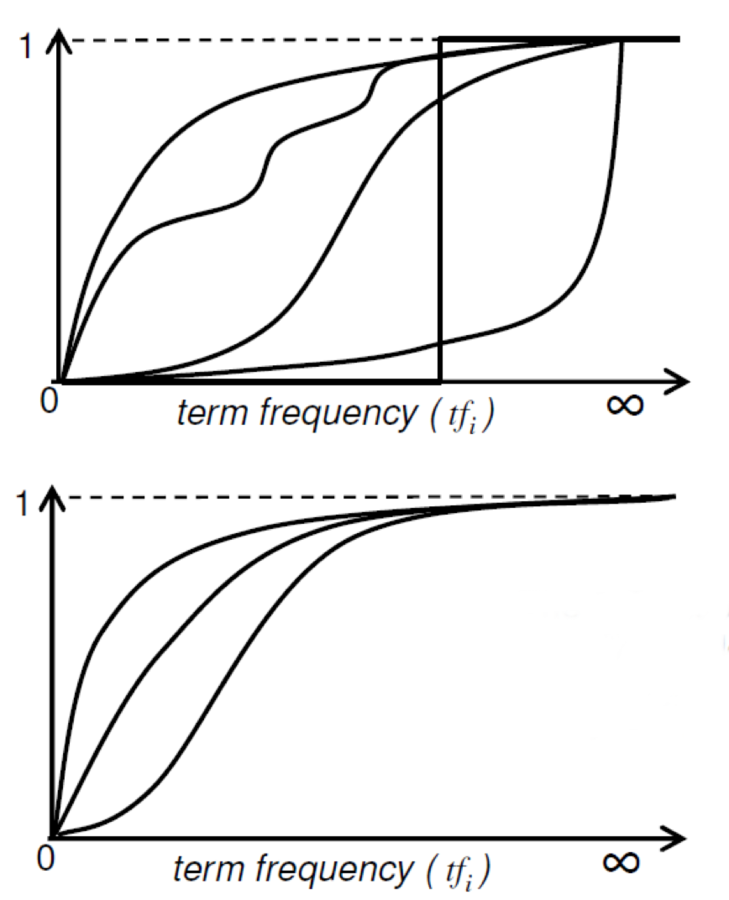
Заменяем на кривую со схожими свойствами:
Нелинейная функция по tf
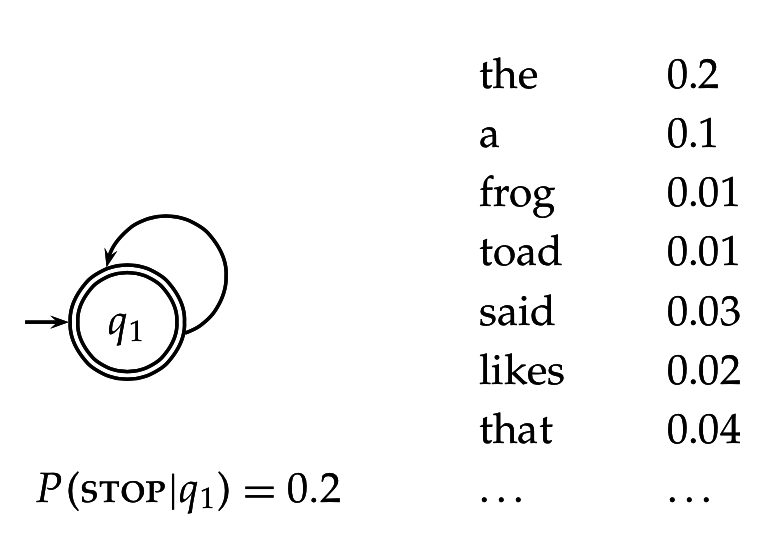
Конечный автомат, генерирующий строки из некоторого алфавита
Язык автомата - полная совокупность строк, которые он может сгенерировать
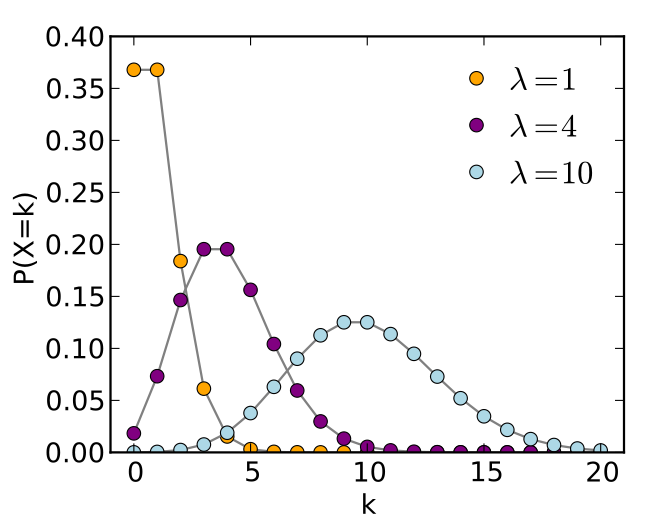
Языковая модель - функция, приписывающая каждому термину из словаря некоторую вероятность (мультиномиальное распределение)
Можно вычислить вероятность порождения каждой строки:
Вводится вероятность остановки
см. практическое задание 7
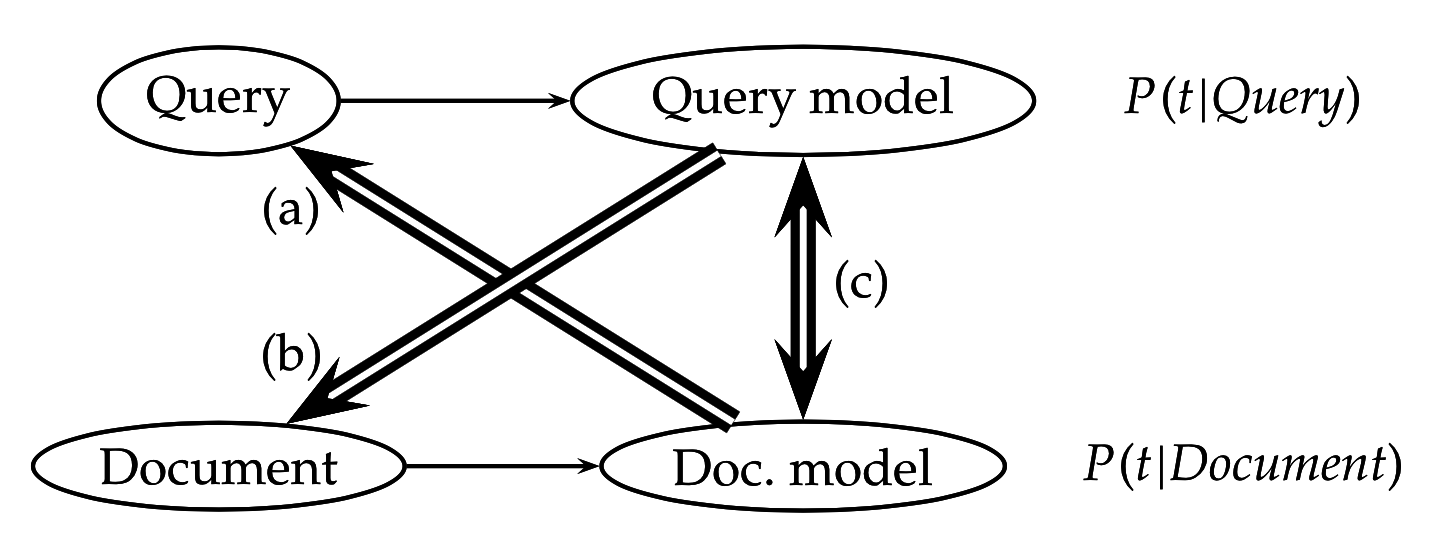
а) Модель правдоподобия запроса (query likelihood)
b) Модель правдоподобия документа
c) Модель сравнения, по KL-дивергенции:
By Nikita Zhiltsov




