
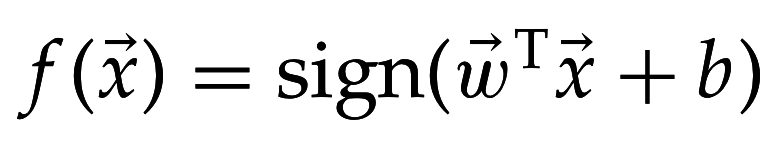
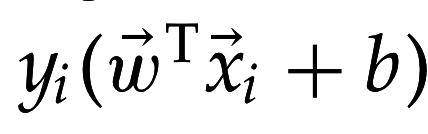
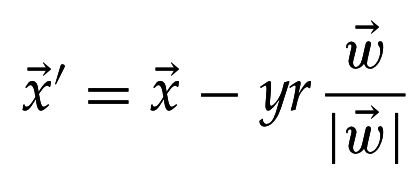
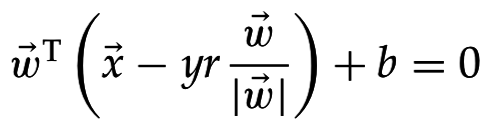
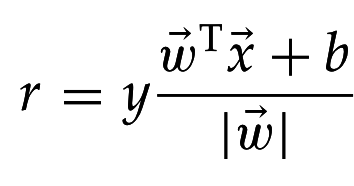
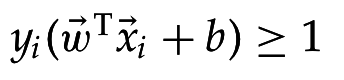
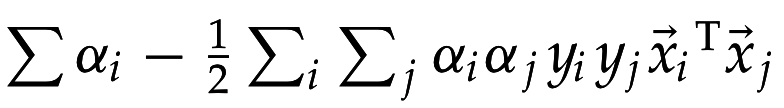
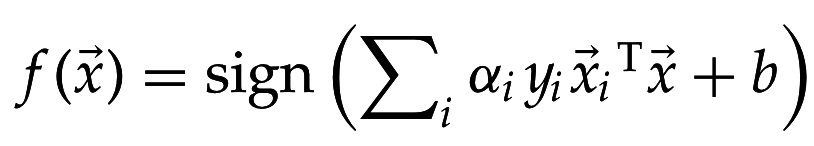

Nikita Zhiltsov
Research fellow at Kazan Federal University (Russia)
Лекция 6
Машинное обучение ранжированию
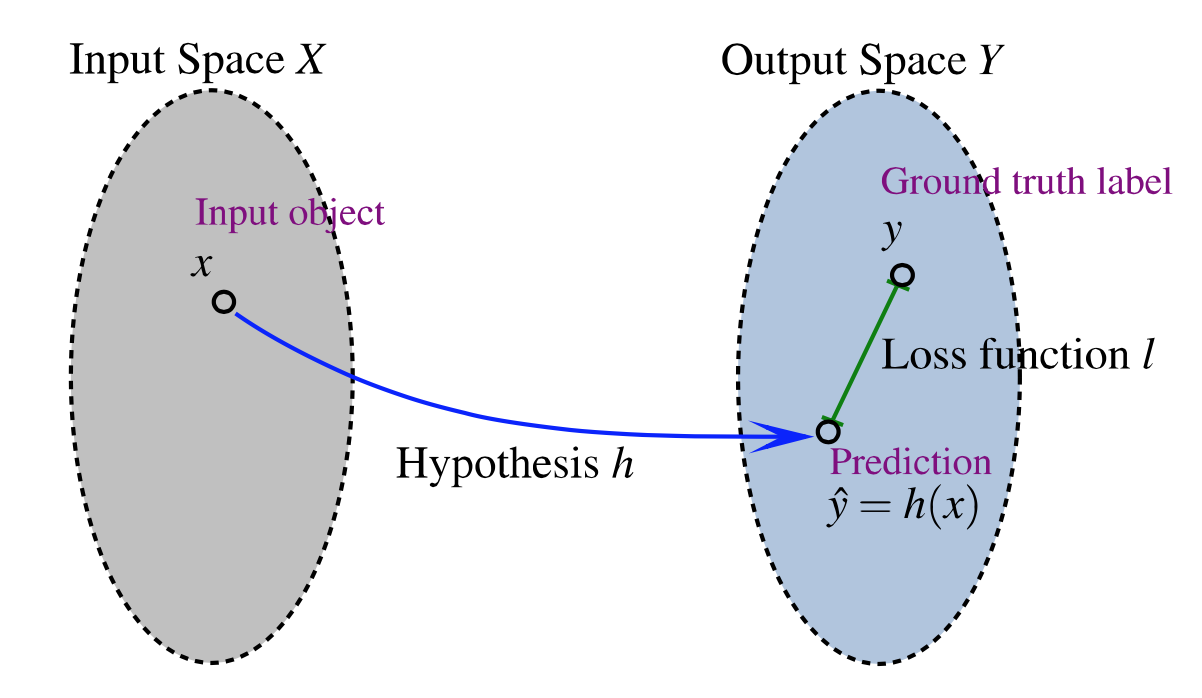
Цель: выбрать функцию h из H, минимизирующую L
*MAP и NDCG - дискретные и недифференцируемые функции
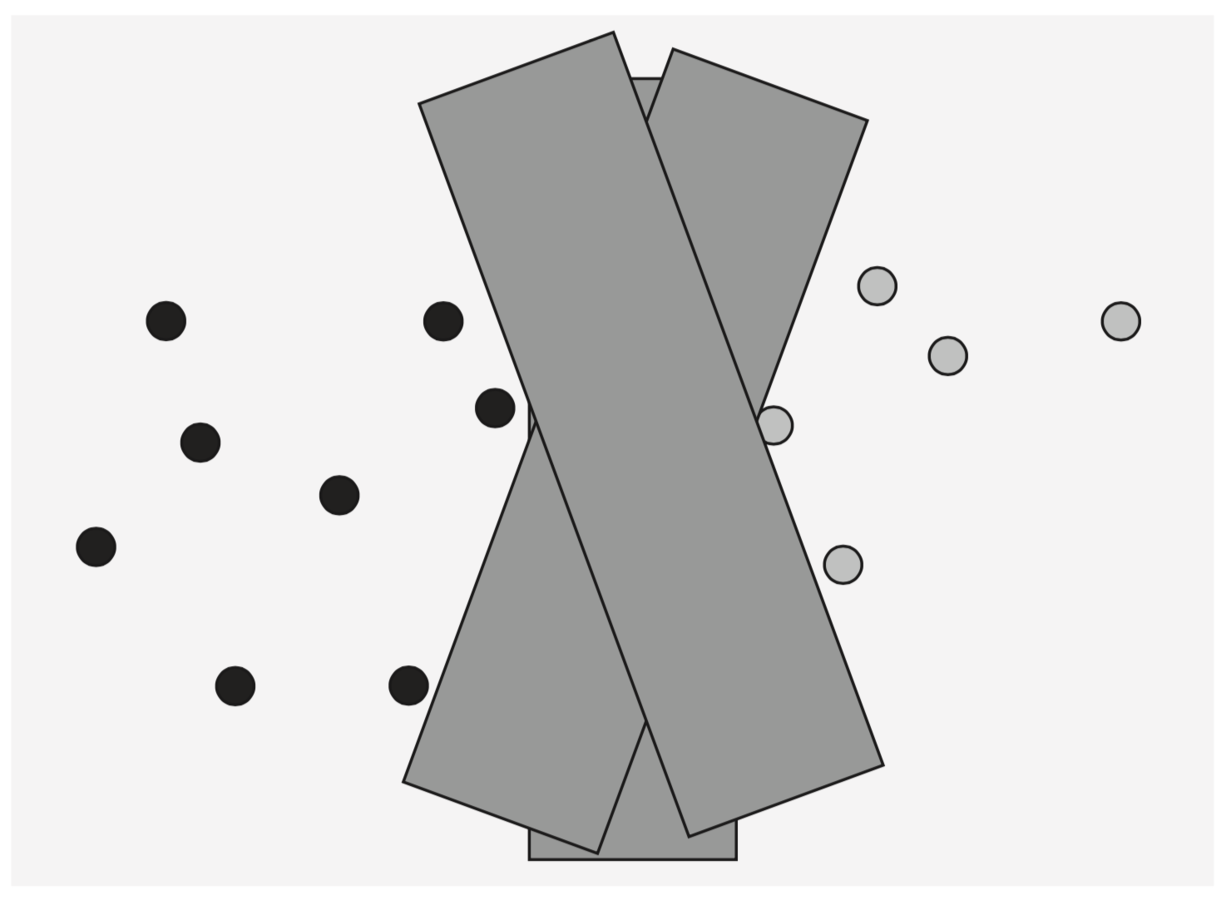
Если можно провести гиперплоскость, разделив множества из разных классов => линейный классификатор
Принимает решение на основе:
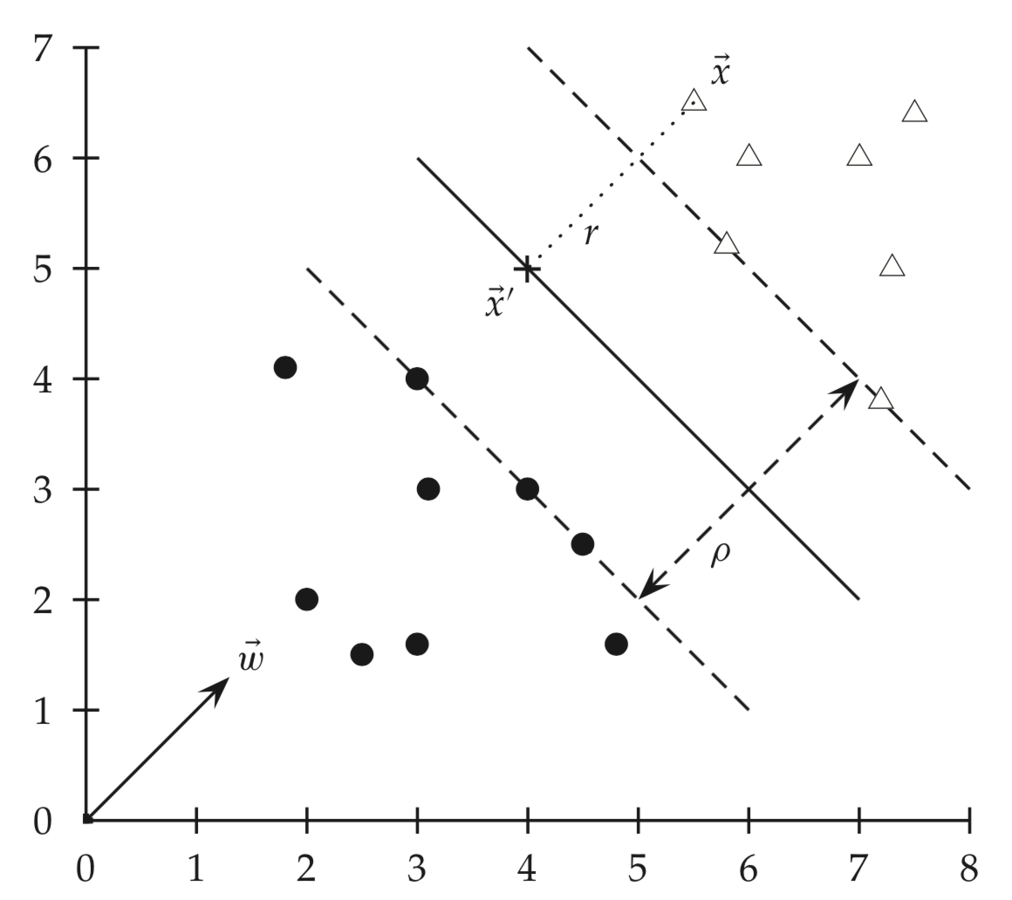
Функциональный зазор для :
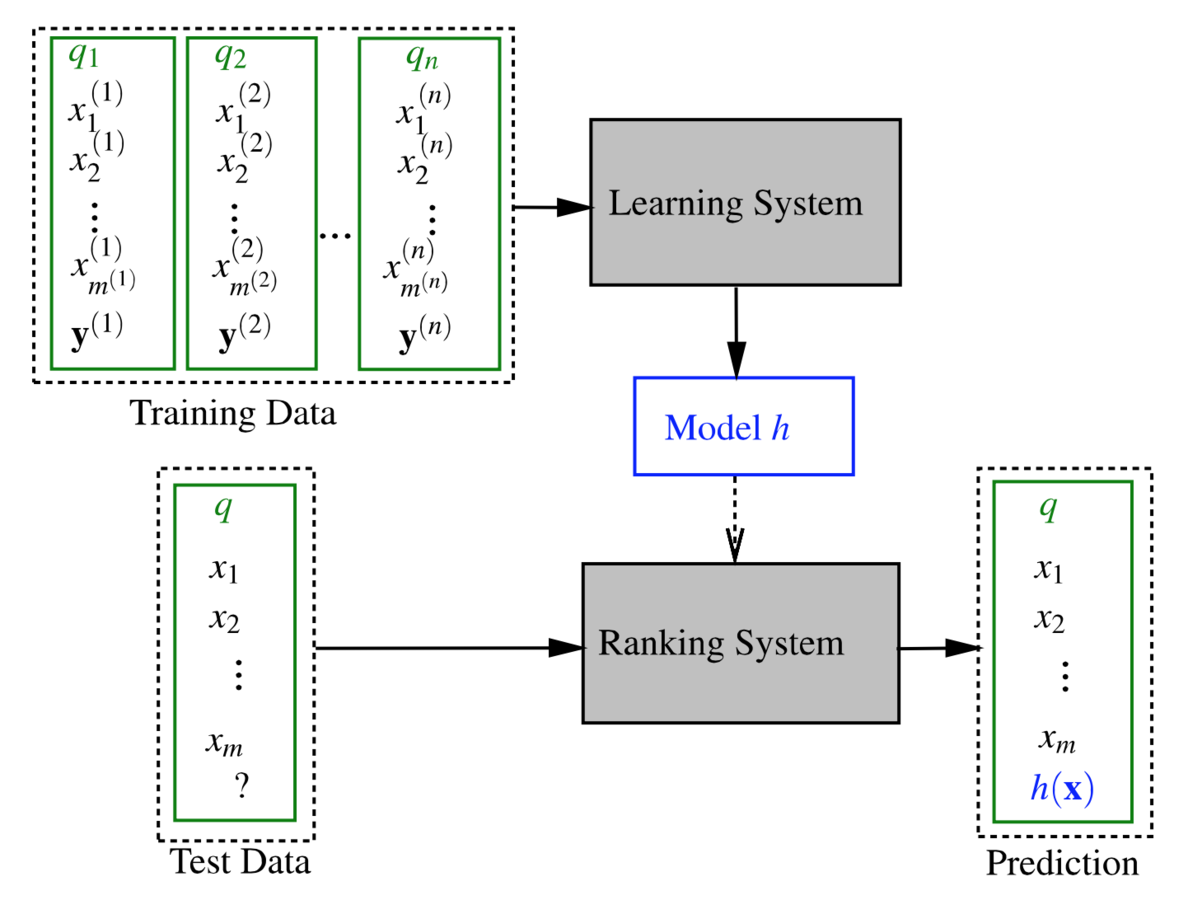
Дано тренировочное множество:
Масштабируя w и b зазор можно сделать сколь угодно большим
Из определения Евклидова расстояния уравнение ближайшей точки на гиперплоскости:
Из уравнения гиперплоскости:
=>
Геометрический зазор - максимальная ширина полосы между опорными векторами двух классов. Инвариантен относительно масштабирования.
Или эквивалентно:
=> минимизация квадратичной функции при линейных ограничениях
опорные векторы!
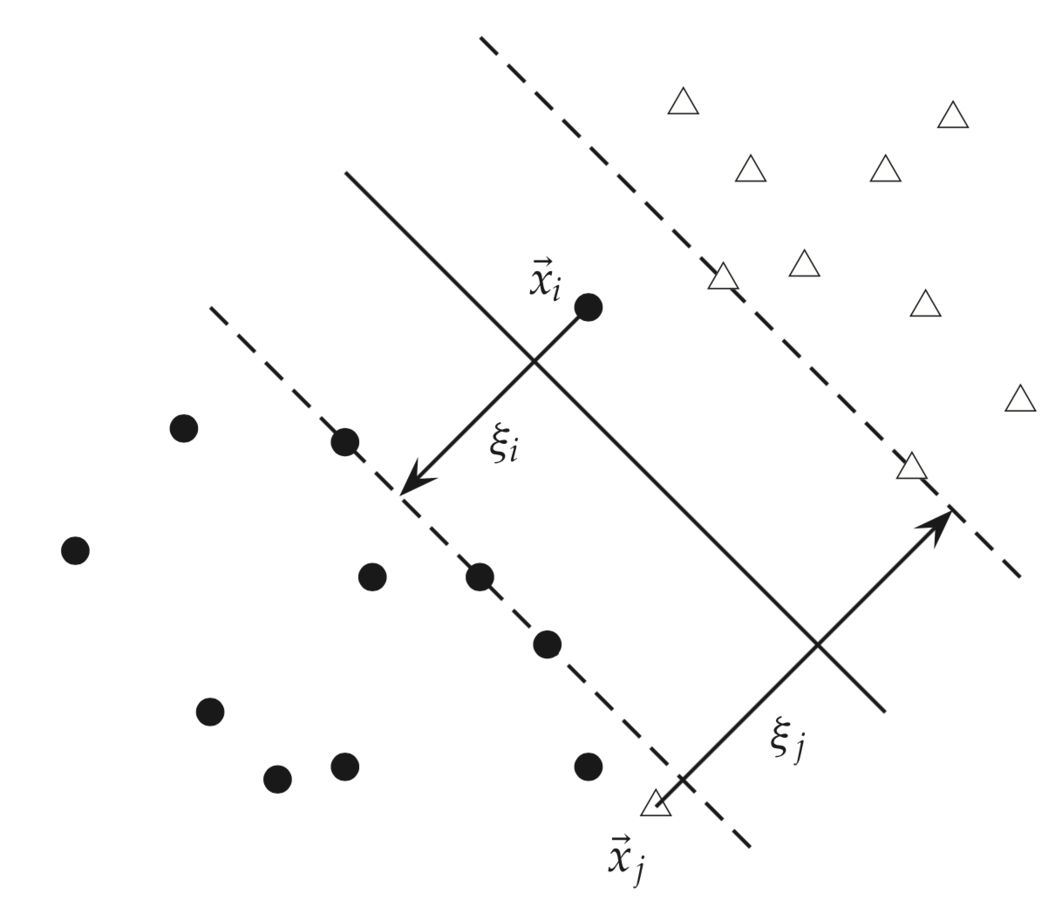
Если множество классов не разделимо линейно, вводятся фиктивные переменные
=> Минимизировать
при условии
C - параметр регуляризации
train.dat
By Nikita Zhiltsov




