





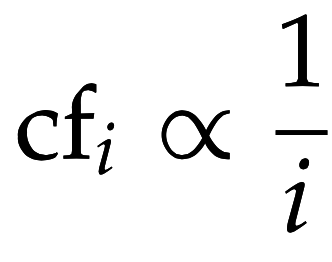






Nikita Zhiltsov
Research fellow at Kazan Federal University (Russia)
Лекция 2
Алгоритмы построения и сжатия индекса
*с т.зр. декомпрессии
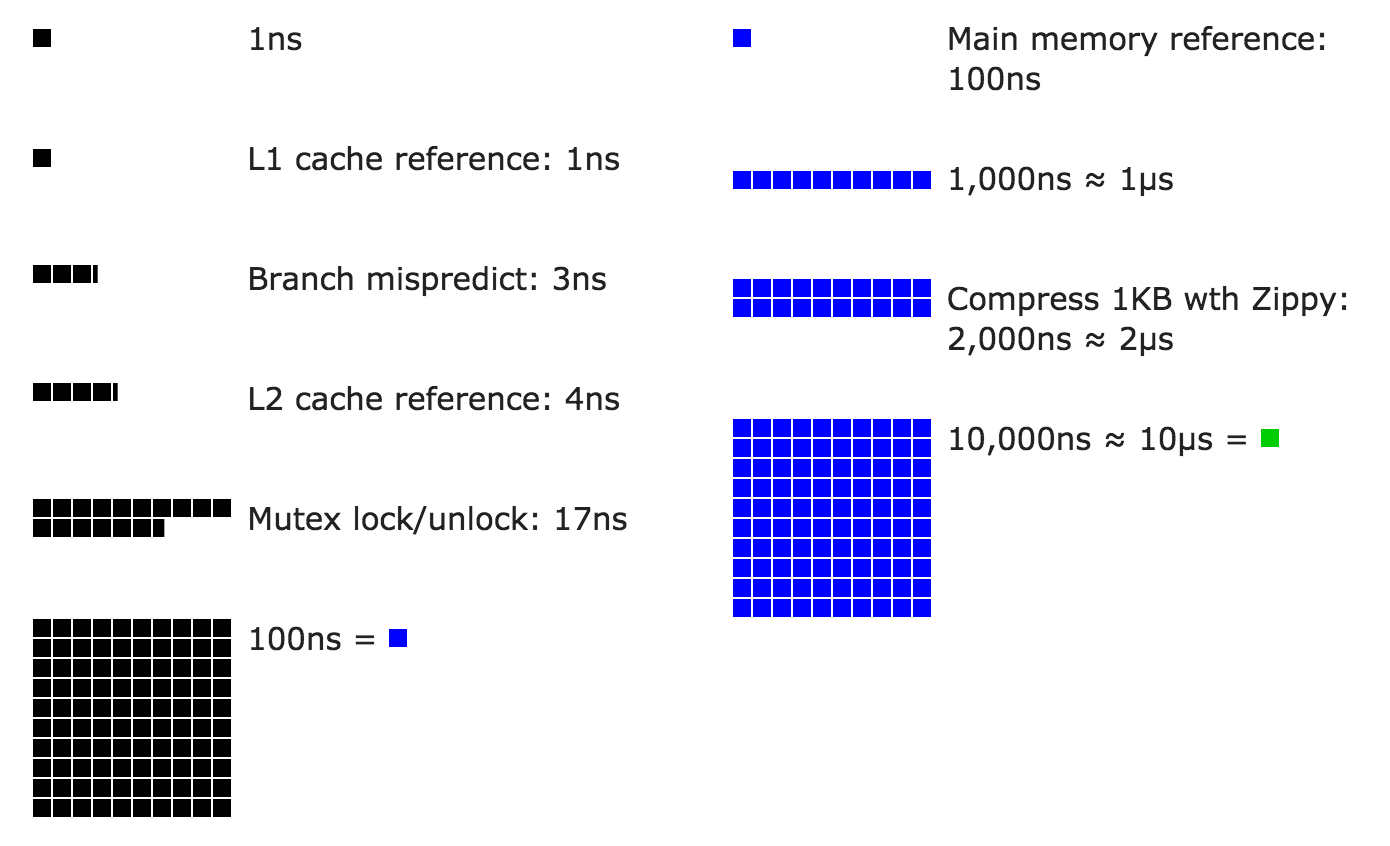
Основная операция - сортировка значений termID-docID.
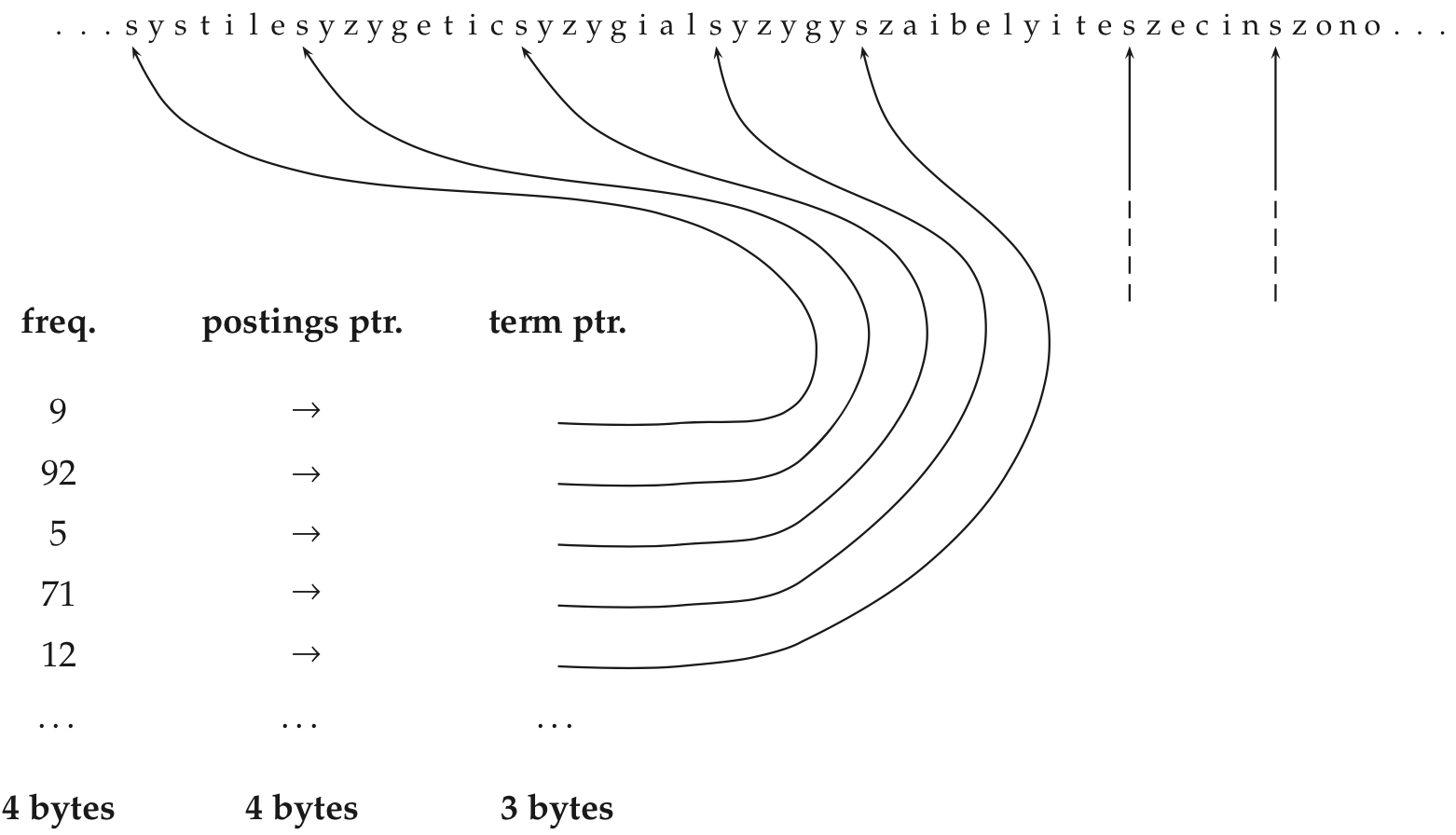
В реальности имеем карту term -> termID
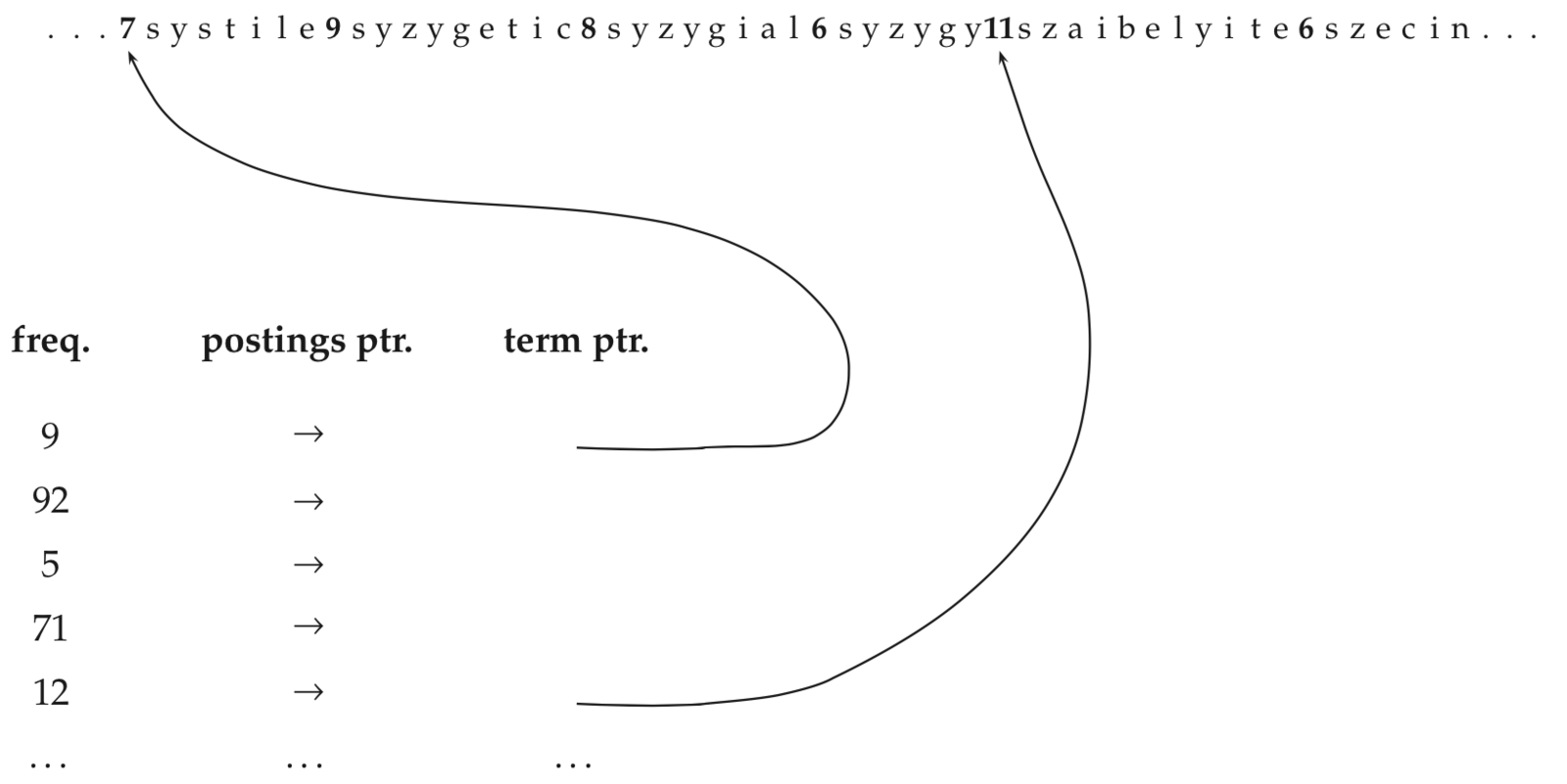
Сколько потребуется памяти для хранения списка termId-docID?
Если termId-docID храним как int (4Б) =>
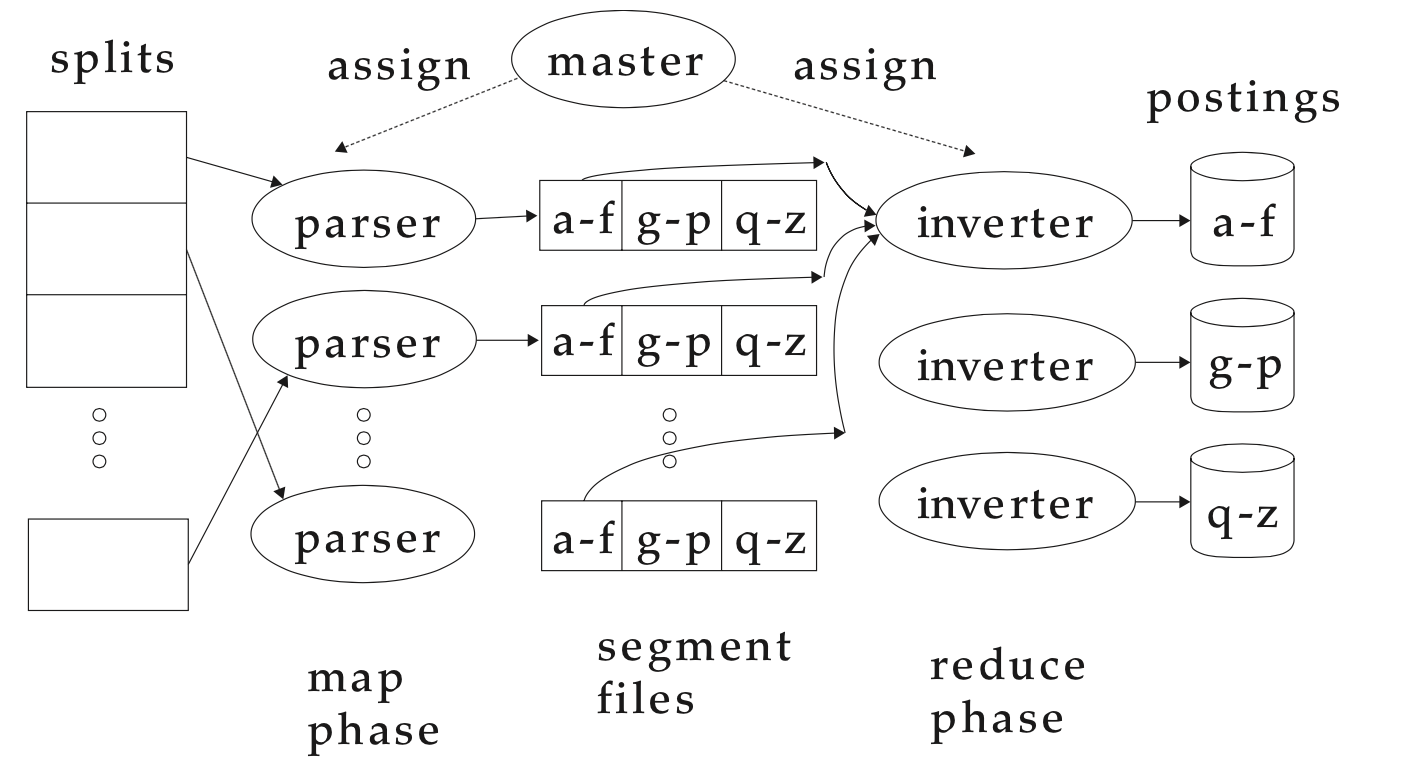
Сложность алгоритма
BSBI-Invert по числу лексем T?
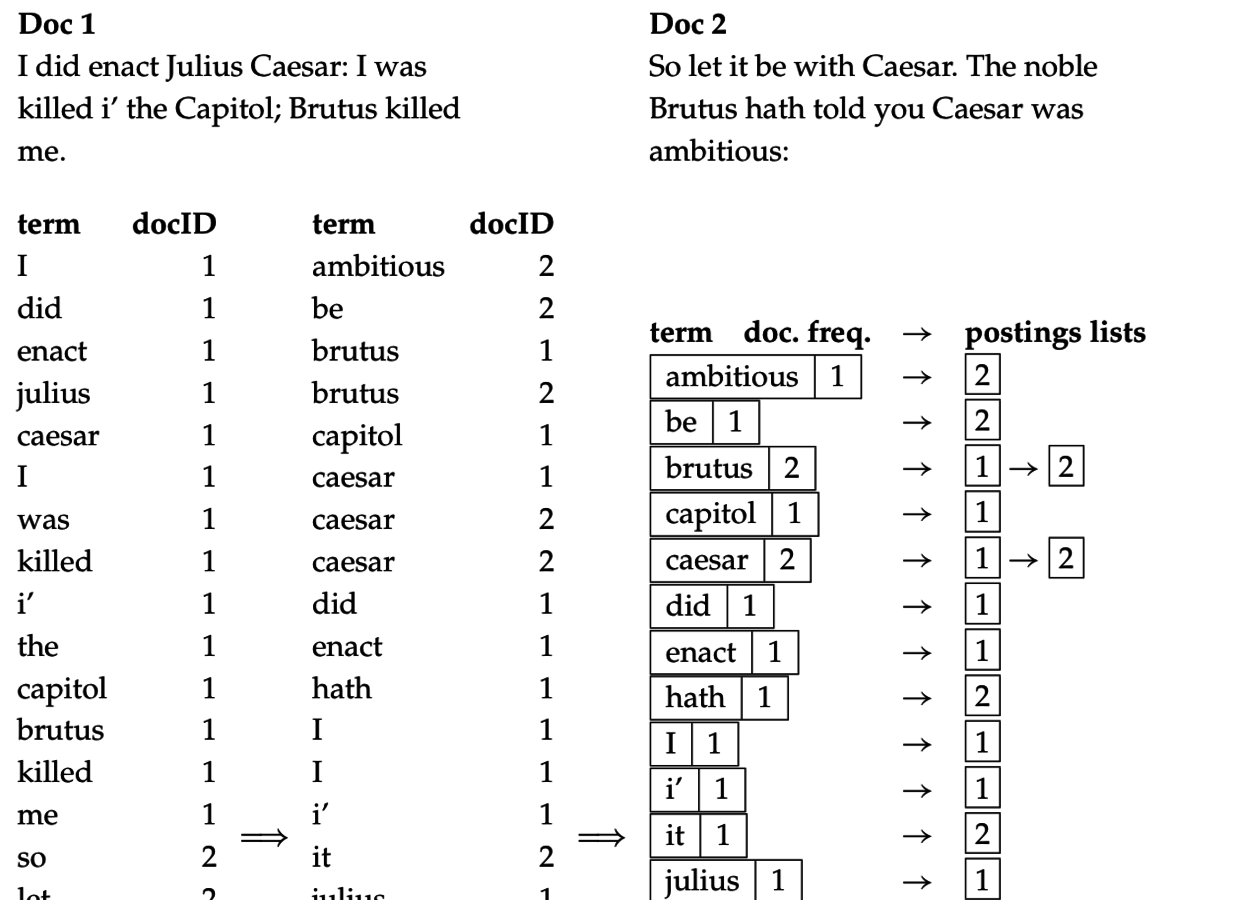
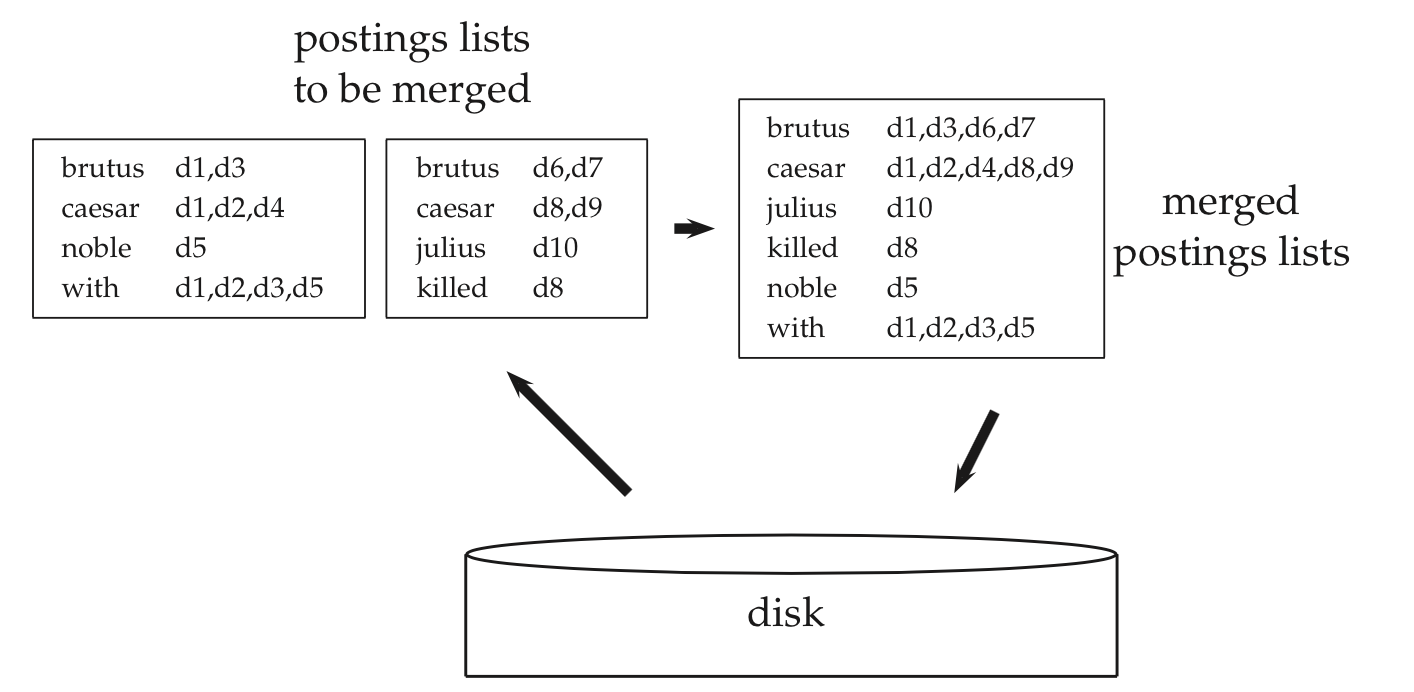
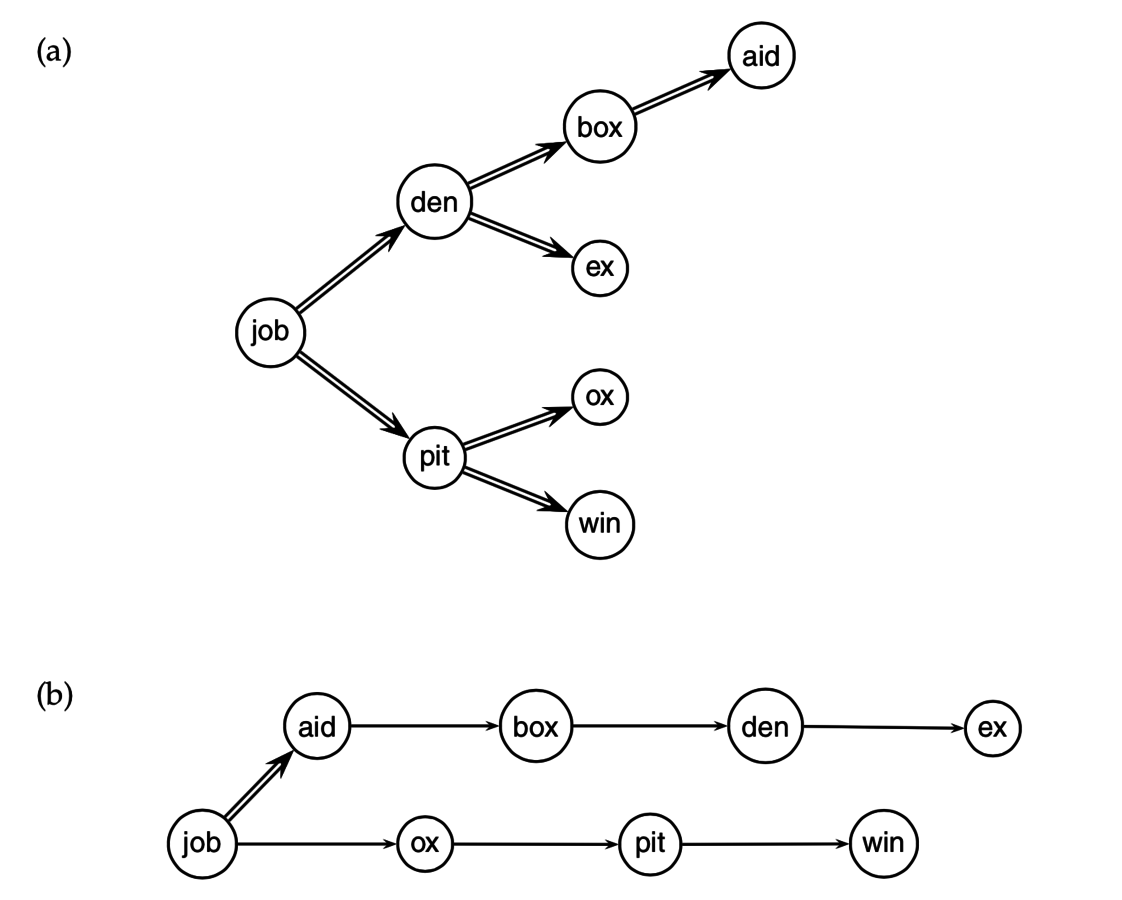
BSBI-Invert = сортировка
termID-docID + группировка по termID
Храним свой словарь для каждого блока
Сложность алгоритма по числу лексем T:
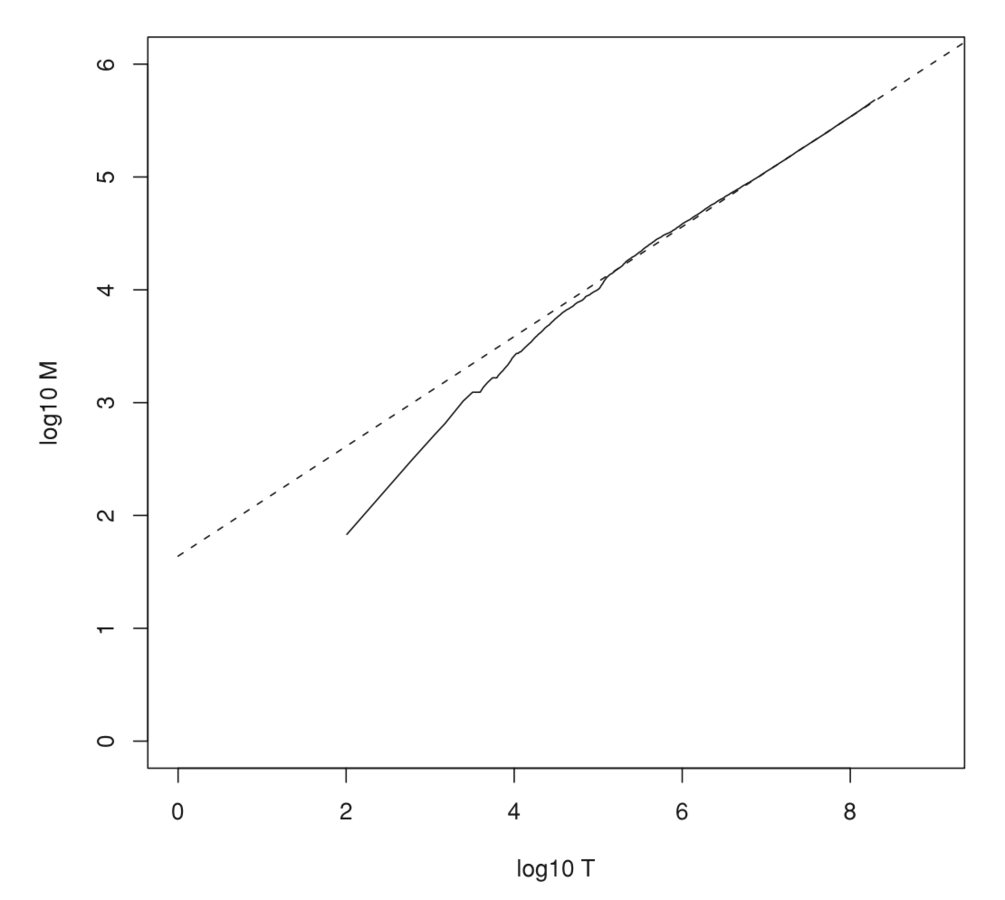
Оценка размера словаря по размеру коллекции
Зависимость линейна по log-log шкале
Зависимость, восстановленная по методу наименьших квадратов (пунктир):
Т.о. с ростом коллекции размера словаря растет, и для больших коллекций он весьма велик => необходимость сжатия словаря
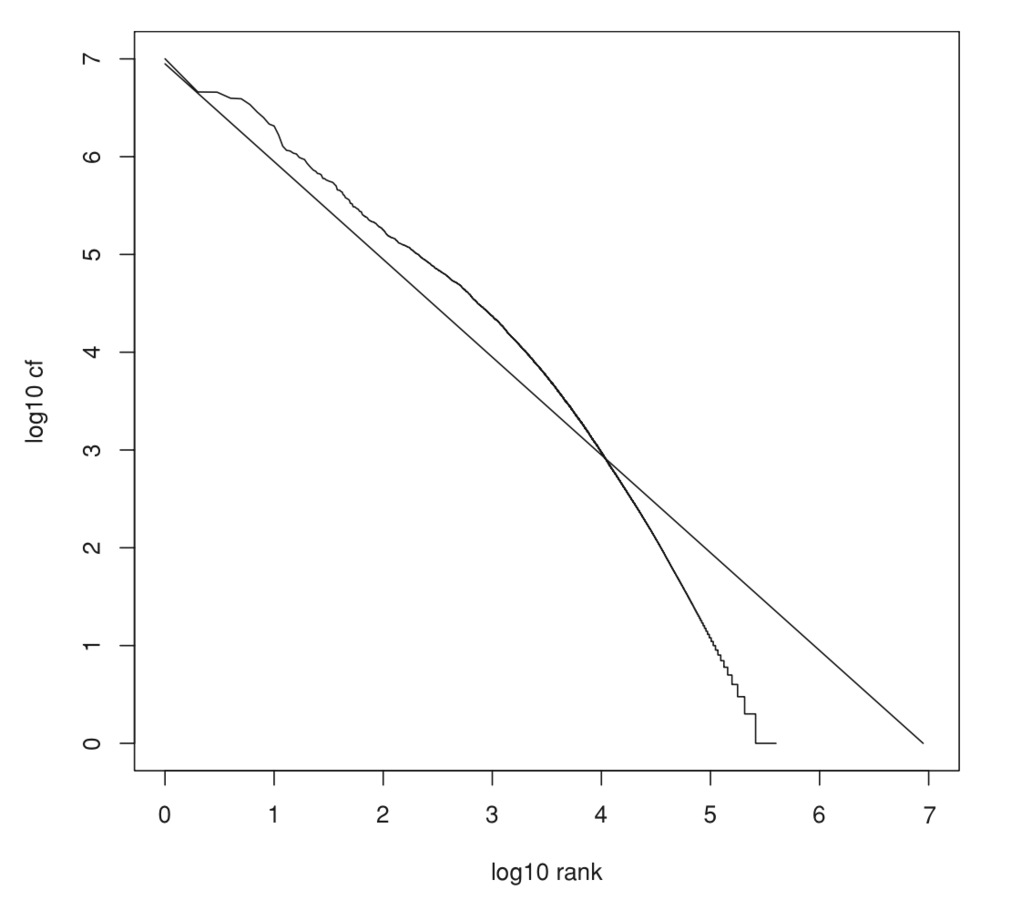
Распределение частоты терминов в коллекции
- частота термина в коллекции
- ранг термина по частоте термина в коллекции
Зависимость линейна в log-log пространстве
Частота термина в коллекции быстро падает с увеличением ранга => очень много редких терминов
♢ - спецсимвол, заменяющий префикс
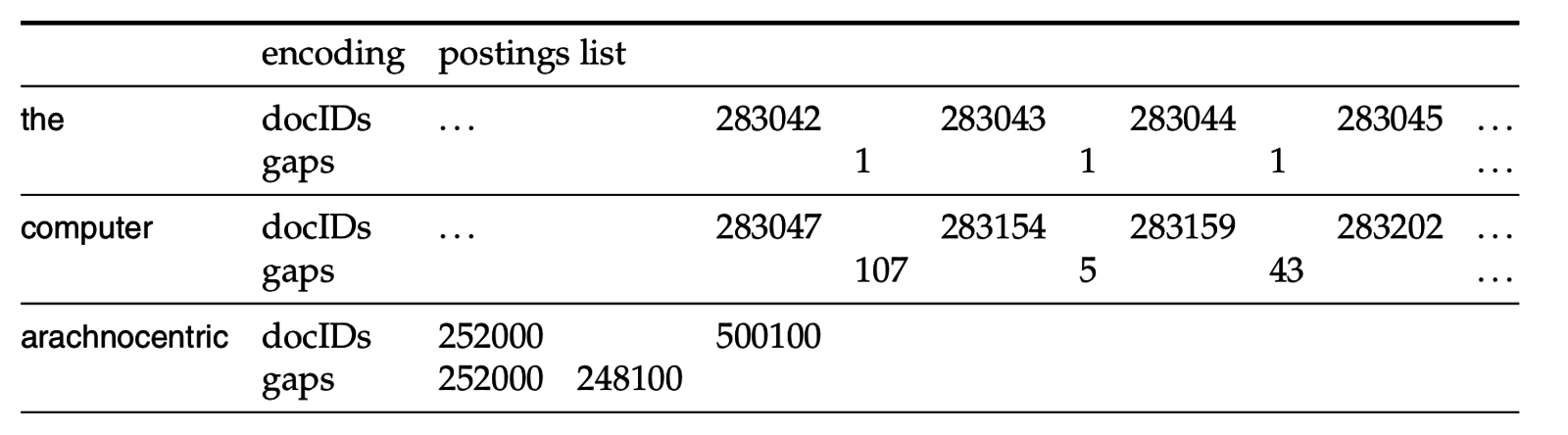
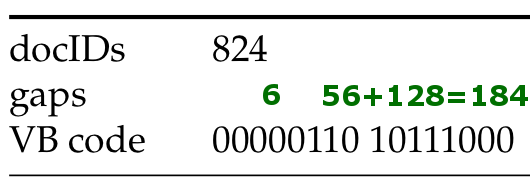
Reuters RCV1 сжимается еще на 17%
By Nikita Zhiltsov




