Wstęp do analizy danych w SI

Część I
⎼ Gromadzenie danych (webcrawler),
⎼ Wczytywanie danych ustrukturyzowanych (pandas, numpy),
⎼ Podstawy wizualizacji danych,
⎼ Oczyszczanie, normalizacja i środkowanie danych,
⎼ Przygotowanie zbiorów uczących.
Część II
⎼ Charakterystyka szeregów czasowych,
⎼ Transformacje sygnałów: wykładnicze, logarytmiczne oraz wygładzanie,
⎼ Autoregresja jedno- i wielowymiarowa,
⎼ Prognozowanie szeregów czasowych: naiwne, z użyciem modeli płytkich i głębokich.
Zaliczenie:
– praca zaliczeniowa prezentująca analizę wybranego problem z użyciem metod statystycznych oraz metod opartych na SI (z użyciem Python)
– preferowana forma pracy to Notatnik Jupyter Notebook
– ustne omówienie (obrona) pracy
Mgr Marcin Kieruzel
Z wykształcenia jestem socjologiem aczkolwiek większość mojej kariery zawodowej zajmuję się branżą IT. Od 2011 r. pracuje jako programista, od kilku 7 lat prowadzę softwear house. Zajmujemy się głównie technologiami webowymi oparty o JavaScript oraz SI. Dodatkowo jestem także trenerem programowania oraz SI. Razem z moją firmą jesteśmy operatorem dużego projektu edukacyjnego LekcjaAI realizowanego razem z firmą Intel oraz Ministerstwem Edukacji.
Czym według was jest analiza danych?
-
Proces pracy z danymi, którego celem jest wyciąganie przydatnych informacji i wiedzy
-
Obejmuje kilka etapów:
-
zbieranie danych (np. z baz danych, sensorów, plików CSV)
-
porządkowanie i czyszczenie (usuwanie błędów, braków, duplikatów)
-
eksploracja i opis (statystyki, wizualizacje, wykresy)
-
wyciąganie wniosków i formułowanie rekomendacji
-
-
Może być:
-
opisowa (co się wydarzyło?)
-
diagnostyczna (dlaczego to się wydarzyło?)
-
predykcyjna (co może się wydarzyć?)
-
preskryptywna (jak powinniśmy działać?)
-
-
Kluczowy element współczesnej nauki, biznesu i technologii (m.in. sztucznej inteligencji).
KDD to skrót od Knowledge Discovery in Databases – czyli odkrywanie wiedzy w bazach danych.
Jest to proces, którego celem jest wydobywanie z dużych zbiorów danych ukrytej, wcześniej nieznanej, a zarazem użytecznej wiedzy.
Proces KDD obejmuje kilka etapów:
-
Selekcja danych – wybór odpowiednich źródeł i fragmentów danych.
-
Czyszczenie i wstępne przetwarzanie – usuwanie błędów, braków i szumów w danych.
-
Transformacja – przygotowanie danych do analizy (np. normalizacja, redukcja wymiarów).
-
Data mining (eksploracja danych) – zastosowanie algorytmów i metod statystycznych/sztucznej inteligencji w celu wykrywania wzorców, zależności, klastrów czy reguł.
-
Interpretacja i ocena – analiza wyników pod kątem ich użyteczności i poprawności.
-
Prezentacja wiedzy – przedstawienie wyników w formie zrozumiałej dla użytkownika (np. raporty, wizualizacje).
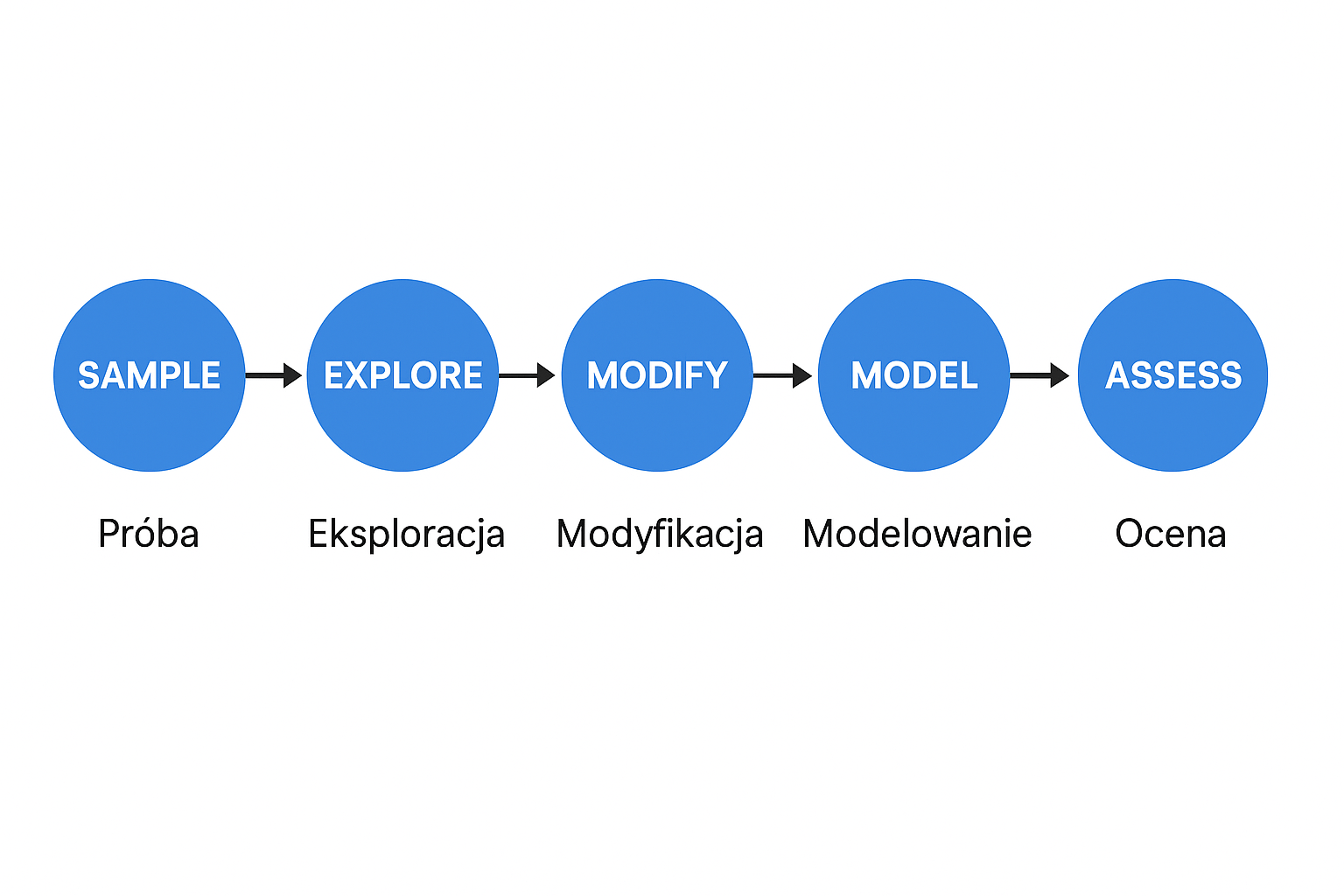
Model SEMMA to metodologia opracowana przez firmę SAS Institute jako uporządkowany schemat pracy w projektach data mining (eksploracji danych).
Nazwa pochodzi od pierwszych liter angielskich słów:
-
S – Sample (Próba)
-
wybranie reprezentatywnej próby danych z całego zbioru, aby móc efektywnie analizować
-
-
E – Explore (Eksploracja)
-
analiza danych wstępna: rozkłady, korelacje, wykresy, wykrywanie anomalii, zależności.
-
celem jest zrozumienie struktury danych i znalezienie potencjalnych wzorców.
-
-
M – Modify (Modyfikacja)
-
przygotowanie danych do modelowania: tworzenie nowych zmiennych, transformacje, selekcja cech, usuwanie nieistotnych atrybutów, normalizacja.
-
-
M – Model (Modelowanie)
-
zastosowanie algorytmów data mining (np. drzewa decyzyjne, sieci neuronowe, regresja, SVM, klastrowanie) do budowy modeli predykcyjnych lub opisowych.
-
-
A – Assess (Ocena)
-
ocena jakości modelu i jego użyteczności biznesowej, porównywanie różnych podejść, walidacja wyników.
-
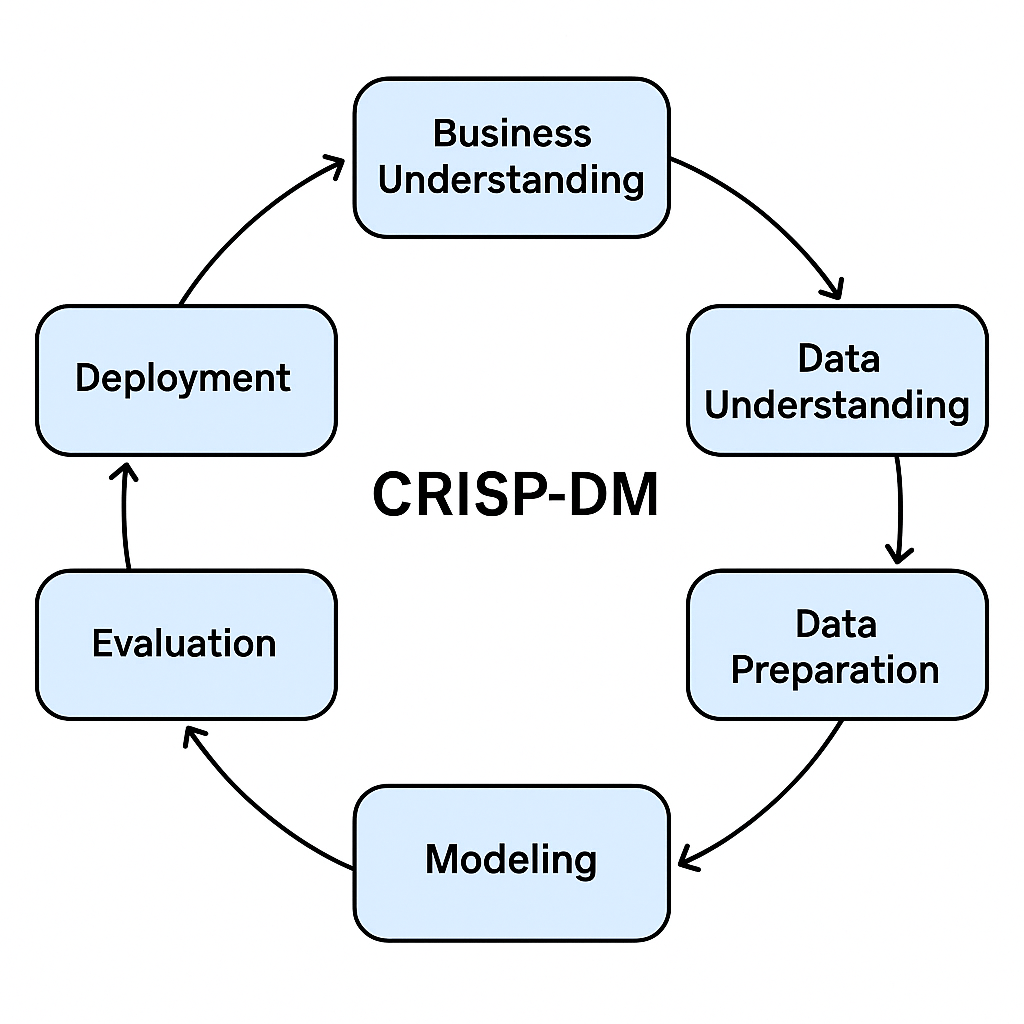
CRISP-DM to najczęściej stosowana metodologia prowadzenia projektów data mining i analizy danych.
Skrót oznacza Cross Industry Standard Process for Data Mining – czyli branżowy standardowy proces eksploracji danych.
-
Business Understanding (Zrozumienie problemu biznesowego)
-
Określenie celów projektu, wymagań biznesowych i kryteriów sukcesu.
-
Przykład: „Chcemy przewidywać, którzy klienci odejdą z naszej firmy”.
-
-
Data Understanding (Zrozumienie danych)
-
Zbieranie dostępnych danych, badanie ich jakości, wykrywanie braków i anomalii.
-
Przykład: analiza źródeł danych, tworzenie pierwszych statystyk opisowych.
-
-
Data Preparation (Przygotowanie danych)
-
Oczyszczanie danych, łączenie różnych źródeł, transformacje, wybór cech (feature engineering).
-
Ten etap często zajmuje najwięcej czasu w całym projekcie.
-
-
Modeling (Modelowanie)
-
Wybór i trenowanie modeli (np. drzewa decyzyjne, regresja, sieci neuronowe).
-
Dostosowanie parametrów i porównanie podejść.
-
-
Evaluation (Ewaluacja)
-
Ocena jakości modeli pod kątem trafności, stabilności i zgodności z celem biznesowym.
-
Ważne: nawet dobry model matematycznie może być bezużyteczny biznesowo.
-
-
Deployment (Wdrożenie)
-
Przeniesienie rozwiązania do praktyki (np. system rekomendacji, scoring klientów).
-
Może to być raport, dashboard albo zintegrowany system produkcyjny.
-
-
CRISP-DM – standard branżowy, mocno podkreśla cele biznesowe i wdrożenie.
-
SEMMA – metoda SAS, skupiona na modelowaniu danych.
-
KDD – ogólny proces odkrywania wiedzy w bazach, bardziej naukowy.
Czym różnią się metody statystyczne od SI?
Analiza danych w SI / Python vs. metody statystyczne
Statystyka tradycyjna
-
Koncentruje się na modelach matematycznych i testach hipotez
-
Często zakłada określone rozkłady (np. normalny)
-
Nacisk na wyjaśnienie zależności i istotność statystyczną
-
Typowe narzędzia: regresja liniowa, testy t, ANOVA
Analiza danych w SI / Python vs. metody statystyczne
Analiza danych w SI / Python
-
Praktyczne podejście – nacisk na predykcję i działanie na dużych zbiorach danych
-
Wykorzystuje algorytmy uczenia maszynowego (np. drzewa decyzyjne, sieci neuronowe)
-
Radzi sobie z danymi nienumerycznymi (obrazy, teksty, dźwięki)
-
Często mniej zależy od klasycznych założeń statystycznych
-
Python = ekosystem narzędzi (numpy, pandas, scikit-learn, tensorflow, pytorch)
Analiza danych w SI / Python vs. metody statystyczne
Różnica w podejściu
-
Statystyka: „Jakie są związki i dlaczego?”
-
SI / Python: „Czy możemy przewidzieć i wykorzystać te dane w praktyce?”
Data Science vs Data Analysis
Data Science (nauka o danych, danetyka)
To szersza i bardziej zaawansowana dziedzina, która obejmuje również analizę danych, ale idzie dalej.
-
Cel: nie tylko zrozumieć dane, ale też budować modele predykcyjne i generować nowe informacje.
-
Typowe zadania:
-
Analiza danych (tak jak analitycy).
-
Budowanie i trenowanie modeli uczenia maszynowego (machine learning).
-
Praca z dużymi zbiorami danych (big data).
-
Eksperymenty i symulacje.
-
Odpowiadanie na pytania typu: "Którzy klienci najprawdopodobniej odejdą?"
-
-
Narzędzia: Python, R, biblioteki ML (scikit-learn, TensorFlow, PyTorch), narzędzia do big data (Spark, Hadoop).
Data Analysis (analiza danych)
To bardziej skoncentrowana i węższa dziedzina.
-
Cel: zrozumieć dane historyczne i odpowiedzieć na konkretne pytania biznesowe.
-
Typowe zadania:
-
Czyszczenie i przygotowanie danych.
-
Tworzenie raportów i wizualizacji.
-
Obliczanie statystyk opisowych (np. średnia, mediana, korelacje).
-
Odpowiadanie na pytania typu: "Jakie były przychody w zeszłym miesiącu?" albo "Który produkt sprzedaje się najlepiej?"
-
-
Narzędzia: Excel, SQL, Tableau, Power BI, Python/R (na poziomie analitycznym).
Co robię jako specjalista od sztucznej inteligencji?

Jak to widzi społeczeństwo?

Co myślą inni programiści?
Co ja właściwie robię?


Czym jest regresja?
-
Metoda analizy danych, która bada zależność jednej zmiennej (tzw. zmiennej zależnej) od jednej lub wielu innych zmiennych (tzw. niezależnych / predyktorów).
-
Celem regresji jest:
-
opis tej zależności,
-
przewidywanie wartości zmiennej zależnej,
-
czasem także wyjaśnienie, które czynniki są najważniejsze.
-
Subtitle
Rodzaje regresji
-
Regresja liniowa – zakłada prostą zależność (liniową) między zmiennymi.
-
przykład: wzrost a waga → im wyższy ktoś jest, tym średnio większa ma masa ciała.
-
-
Regresja wieloraka – wiele zmiennych niezależnych (np. cena mieszkania ~ metraż + lokalizacja + wiek budynku).
-
Regresja nieliniowa – zależność nie jest prostą linią, np. krzywa wzrostu populacji.
-
W uczeniu maszynowym istnieją też uogólnienia (np. regresja logistyczna, regresja ridge/lasso).
Subtitle
Prosty przykład (intuicyjny)
-
Mamy dane: temperatura a sprzedaż lodów.
-
Regresja liniowa dopasowuje prostą:
„Gdy temperatura rośnie o 1°C, sprzedaż rośnie średnio o X sztuk”.
Subtitle
Subtitle
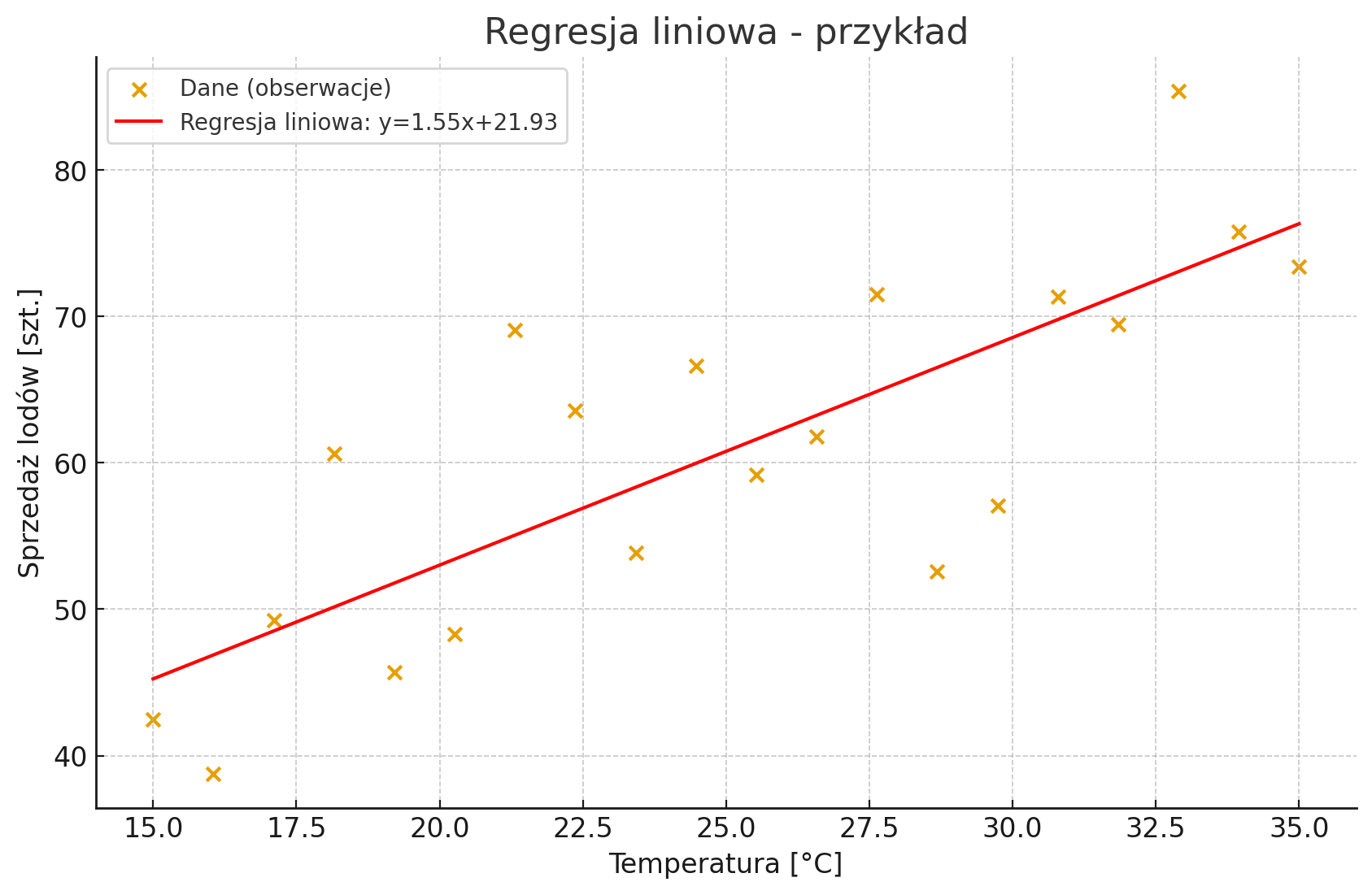
Oto wizualny przykład regresji liniowej; punkty pokazują zależność między temperaturą a sprzedażą lodów, a czerwona linia to dopasowany model regresji.
Na slajdzie możesz opisać to tak:
-
Punkty = zebrane dane (obserwacje).
-
Linia = model regresji liniowej.
-
Interpretacja: wraz ze wzrostem temperatury rośnie przewidywana sprzedaż lodów.
Szeregi czasowe
-
Szereg czasowy to zbiór danych uporządkowanych w czasie – każda obserwacja ma przypisany znacznik czasu (np. dzień, godzinę, rok).
-
Przykłady:
-
liczba pasażerów linii lotniczej w kolejnych miesiącach,
-
temperatura mierzona codziennie,
-
kurs waluty lub ceny akcji na giełdzie,
-
liczba użytkowników logujących się do aplikacji w ciągu tygodnia.
-
Spróbujmy się zastanowić co by się stało gdybyśmy wyłączyli analizę szeregów czasowych?
Cechy szeregów czasowych
-
Trend – długoterminowa tendencja wzrostowa/spadkowa (np. globalny wzrost temperatur).
-
Sezonowość – regularne wahania związane z porą dnia, roku, świętami (np. wzrost sprzedaży w grudniu).
-
Cykle – dłuższe, mniej regularne fluktuacje (np. cykle gospodarcze).
-
Szum – losowe zakłócenia i nieprzewidywalne wahania.
Problem oznaczania czasu?
Co oznacza sformułowanie za dwa miesiące?
Jak wygląda prognozowanie?
-
Zbieranie danych historycznych
-
np. ceny akcji z ostatnich 5 lat, liczba klientów dziennie, zużycie energii miesięcznie.
-
-
Analiza danych
-
sprawdzenie trendu, sezonowości, cykli, szumów, anomalii, braków.
-
wizualizacja → wykres liniowy, wykres sezonowy.
-
-
Przygotowanie danych
-
uzupełnianie braków, oczyszczanie danych, standaryzacja.
-
dzielenie danych na zbiór treningowy i testowy.
-
-
Wybór modelu prognozowania
-
Statystyczne: średnia ruchoma, wygładzanie wykładnicze, ARIMA, SARIMA.
-
Uczące się: regresja, drzewa decyzyjne, sieci neuronowe (RNN, LSTM).
-
-
Uczenie i dopasowanie modelu
-
model uczy się wzorców z danych historycznych.
-
-
Ocena jakości prognozy
-
porównanie przewidywań z danymi testowymi, miary błędu (np. MAE, RMSE, MAPE).
-
-
Prognoza na przyszłość
-
model generuje przewidywane wartości na kolejne okresy.
-
wyniki często pokazuje się na wykresie: dane historyczne + prognoza (z niepewnością).
-
Na czym polega Feature Engineering?
-
Feature engineering to proces tworzenia i modyfikowania cech (features) w danych tak, aby model uczenia maszynowego mógł lepiej uczyć się i przewidywać.
-
W uczeniu maszynowym „features” = cechy opisujące dane (kolumny w tabeli, np. wiek, dochód, liczba zakupów).
-
Dobór i jakość cech mają ogromny wpływ na skuteczność modelu.
- Selekcja cech – wybór tylko tych, które są istotne (np. „wiek” ważniejszy niż „ulubiony kolor”).
- Tworzenie nowych cech
-
np. z daty „2023-10-01” → „dzień tygodnia”, „miesiąc”, „czy weekend”.
- z pola „cena” i „ilość” → „wartość transakcji”.Transformacje matematyczne
-
logarytmowanie (dla danych o dużym zakresie),
-
normalizacja / standaryzacja wartości.
-
Kodowanie danych kategorycznych
-
zamiana np. „miasto = Warszawa, Kraków, Gdańsk” → wektory liczbowe (one-hot encoding
-
- Radzenie sobie z brakami danych
-
uzupełnianie średnią, medianą lub specjalnym wskaźnikiem.
Metody klasyczne (statystyczne)
-
Średnia ruchoma (Moving Average)
-
prognoza = średnia z ostatnich obserwacji,
-
prosta i intuicyjna, dobra jako „baseline”.
-
-
Wygładzanie wykładnicze (Exponential Smoothing, Holt-Winters)
-
nadaje większą wagę najnowszym obserwacjom,
-
rozszerzenia (Holt-Winters) pozwalają uwzględniać trend i sezonowość.
-
Metody klasyczne (statystyczne)
-
ARIMA (Autoregressive Integrated Moving Average)
-
klasyczny model: uwzględnia autoregresję (AR), różnicowanie (I) i średnią ruchomą (MA),
-
dobry przy trendach, ale bez wyraźnej sezonowości.
-
-
SARIMA (Seasonal ARIMA)
-
rozwinięcie ARIMA o komponent sezonowy,
-
popularne do prognoz z cyklami rocznymi/miesięcznymi.
-
Metody uczenia maszynowego
-
Regresja liniowa / wieloraka
-
można ją stosować do szeregów po odpowiednim przygotowaniu cech (feature engineering).
-
-
Drzewa decyzyjne i lasy losowe (Random Forest, Gradient Boosting)
-
potrafią uchwycić nieliniowe zależności i interakcje.
-
-
XGBoost / LightGBM / CatBoost
-
nowoczesne, bardzo wydajne algorytmy boostingowe, często używane w konkursach Kaggle.
-
Metody głębokiego uczenia (Deep Learning)
-
RNN (Recurrent Neural Networks)
-
sieci neuronowe z pamięcią, dobrze nadają się do sekwencji czasowych.
-
-
LSTM (Long Short-Term Memory)
-
wariant RNN lepiej radzący sobie z długimi zależnościami w czasie.
-
-
GRU (Gated Recurrent Units)
-
uproszczona alternatywa dla LSTM, często szybsza.
-
-
Transformery (np. Temporal Fusion Transformer)
-
najnowsze podejścia, pozwalają modelować bardzo złożone zależności i duże dane czasowe.
-
Ws
By noinputsignal
Private


