
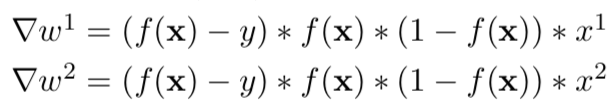
One Fourth Labs
We deliver courseware in AI and related areas
Better optimization, Better activation functions, Better weight initialization, Better regularizer, Better compute, More data
A time line of where we are
-UAT
-Backpropagation
1989-1991
2006
- Revival by Hinton et. al. (Unsupervised Pre-Training)
2019
- Better Learning Algos
- Better Initialization
- Better Activations
- Better Regularization
- More data
- More compute
- More democratization
What are we going to see in this chapter ?
How do you use the gradients?
or
Can you come up with a better update rule ?
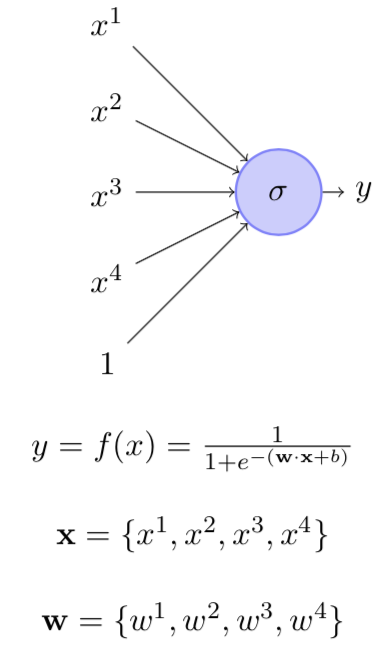
Gradient Descent Update Rule
How do you compute the gradients ?
or
What data should you use for computing the gradients?
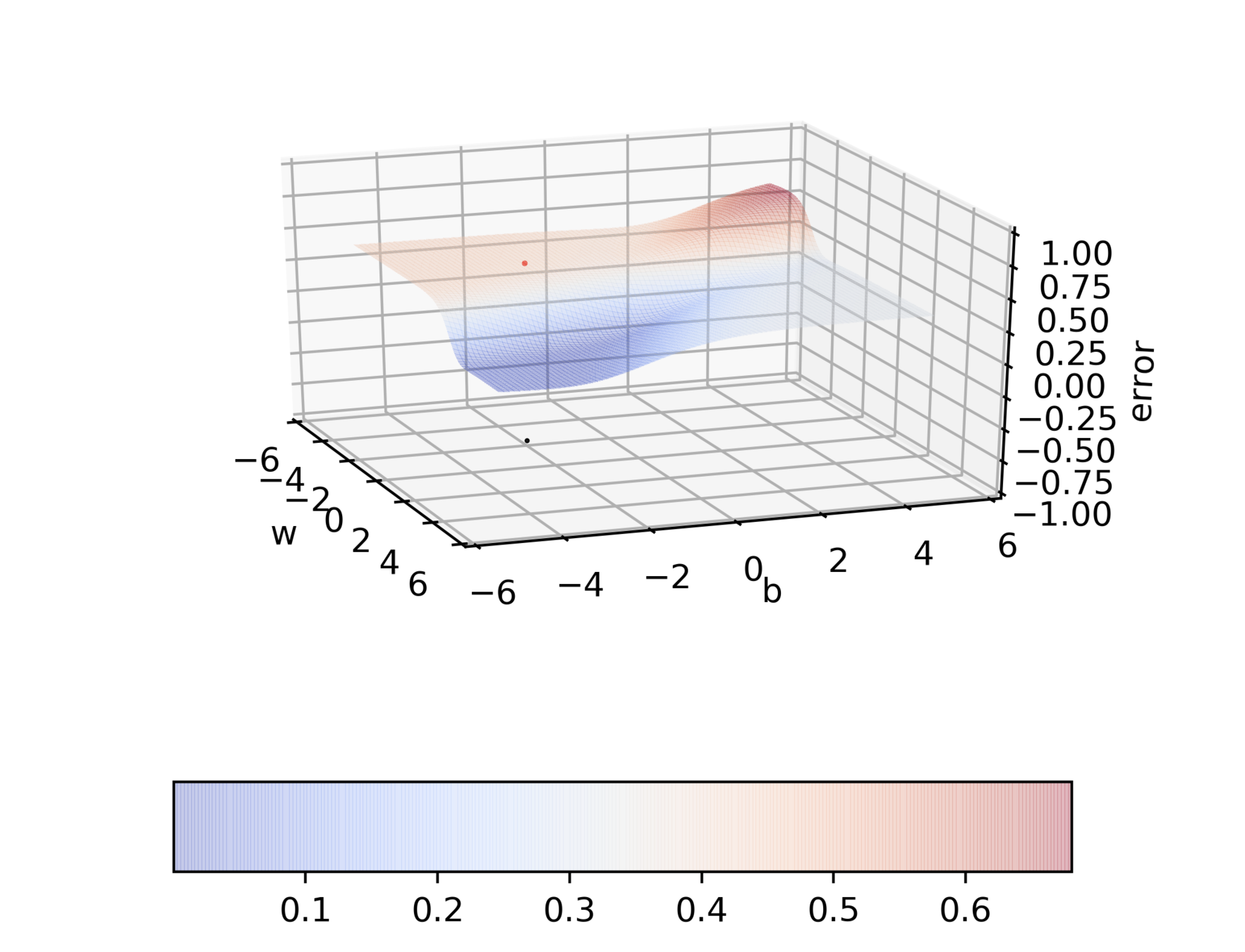
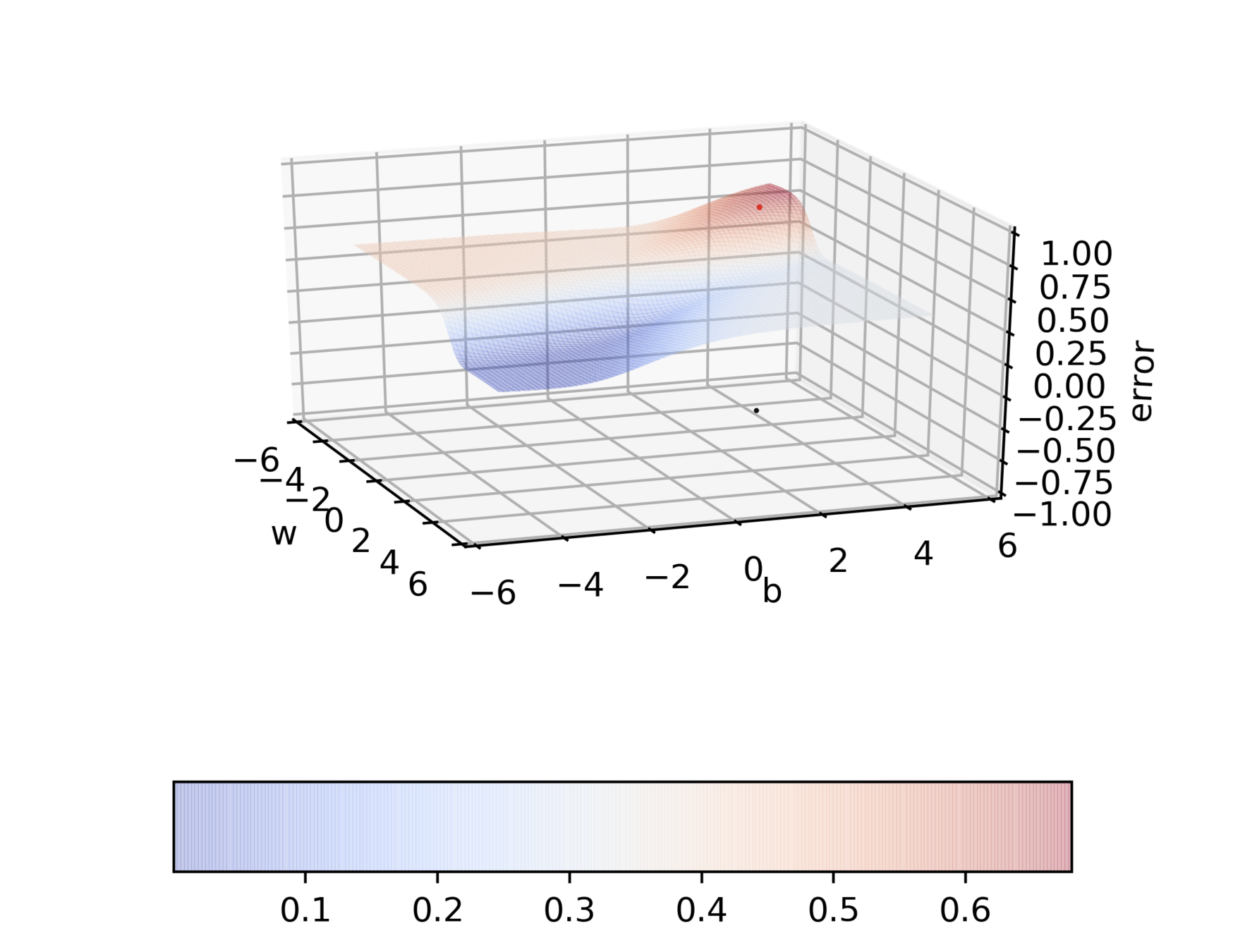
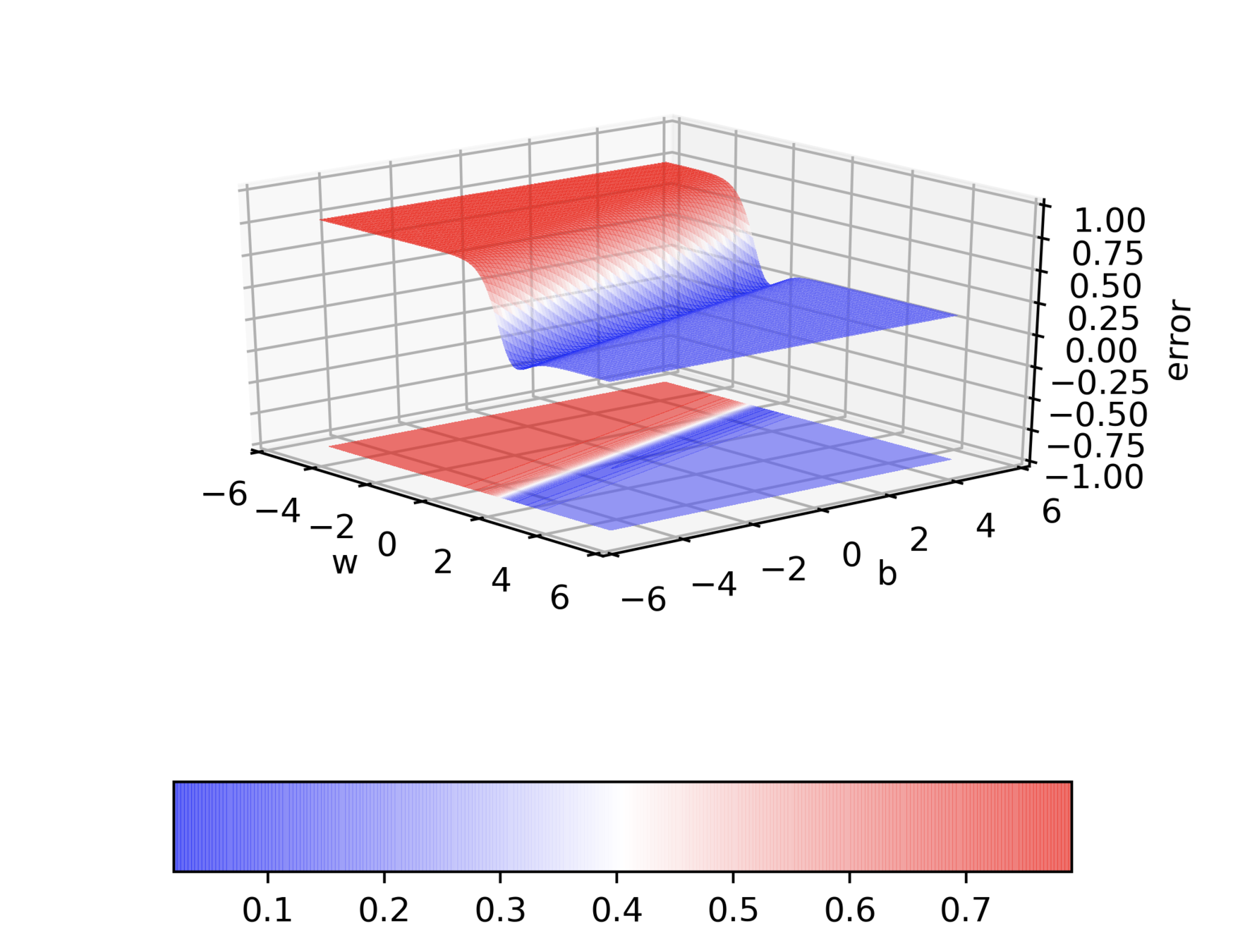
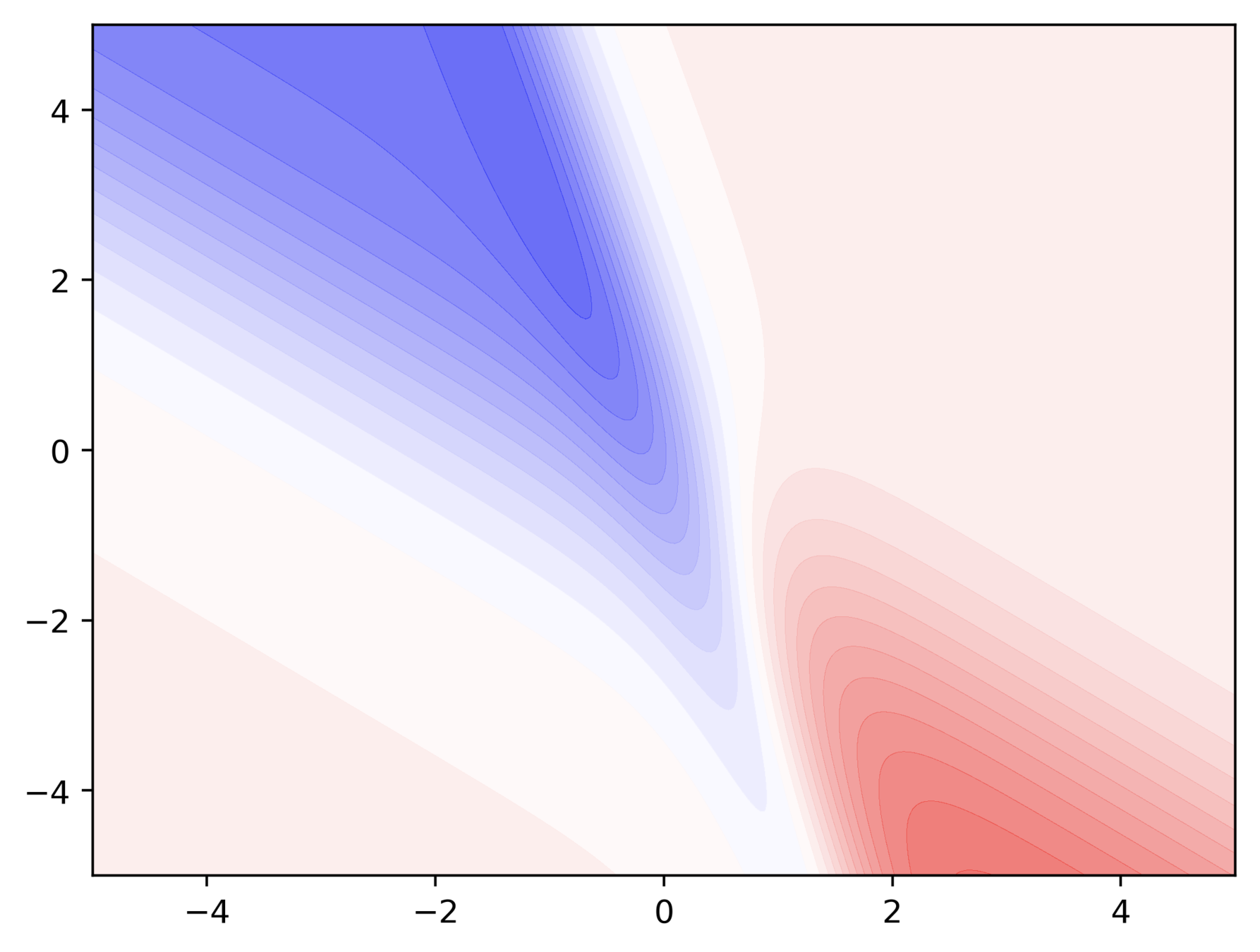
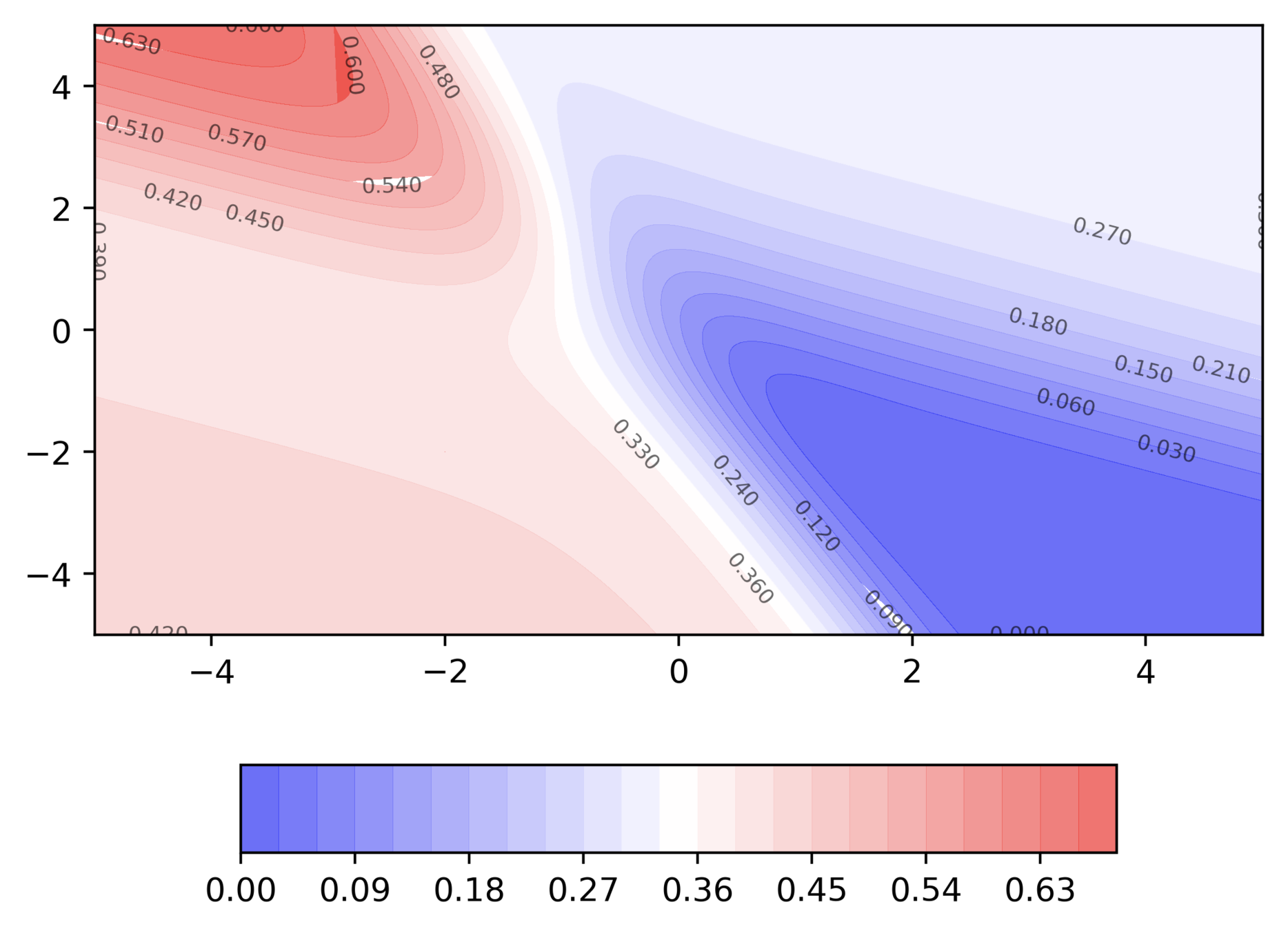
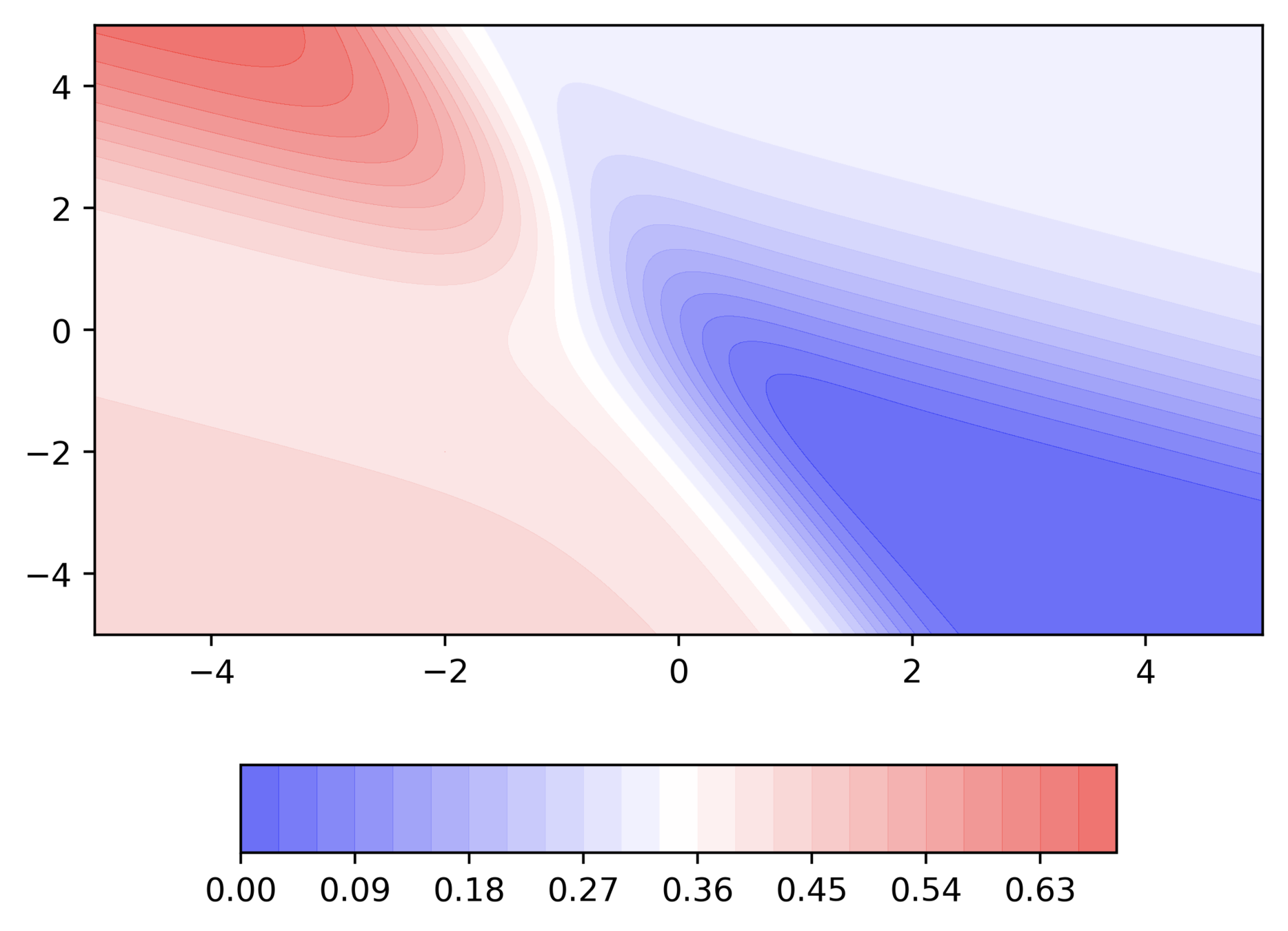
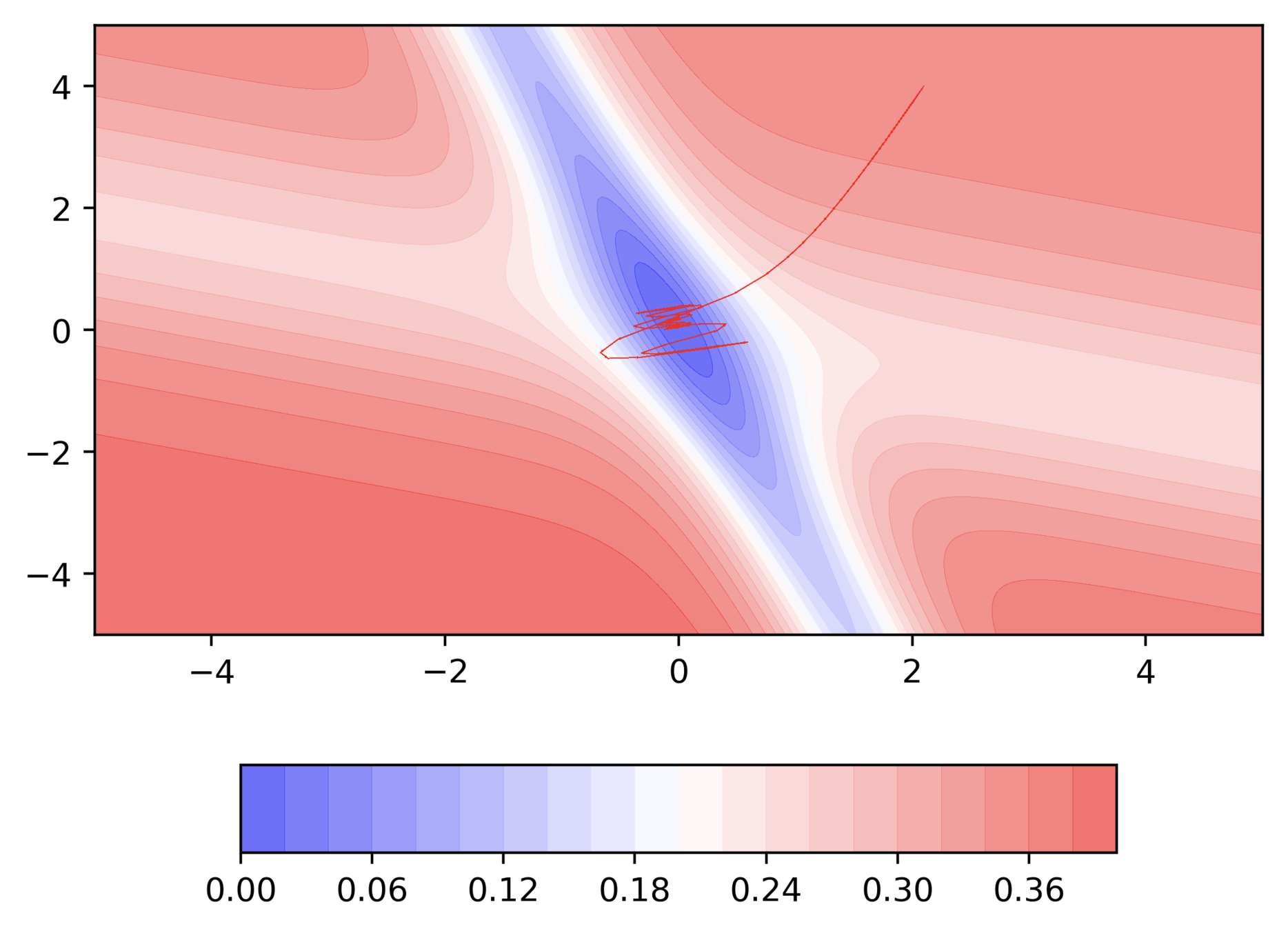
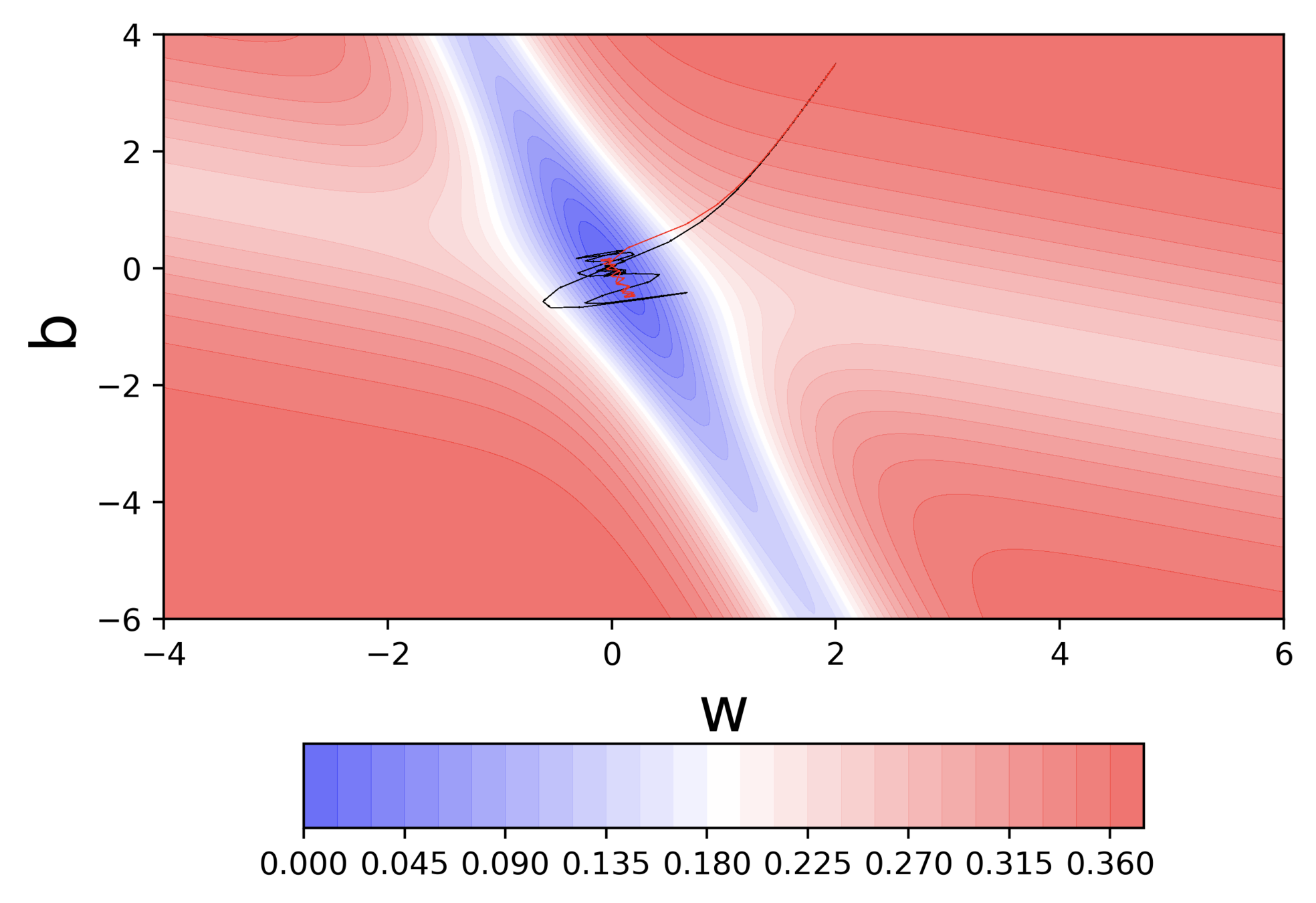
Do you observe something peculiar on different regions of the error surface?
X = [0.5, 2.5]
Y = [0.2, 0.9]def f(w, b, x):
#sigmoid with parameters w, b
return 1.0 / (1.0 + np.exp(-(w*x + b))def error(w, b):
err = 0.0
for x, y in zip(X, Y):
fx = f(w, b, x)
err += 0.5* (fx - y) ** 2
return errdef grad_b(w, b, x, y):
fx = f(w, b, x)
return (fx - y) * fx * (1 - fx)
def do_gradient_descent():
w, b, eta = -2, -2, 1.0
max_epochs = 1000
for i in range(max_epochs):
dw, db = 0, 0
for x, y in zip(X, Y) :
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
w = w - eta * dw
b = b - eta * db
def grad_w(w, b, x, y):
fx = f(w, b, x)
return (fx - y) * fx * (1 - fx) * x
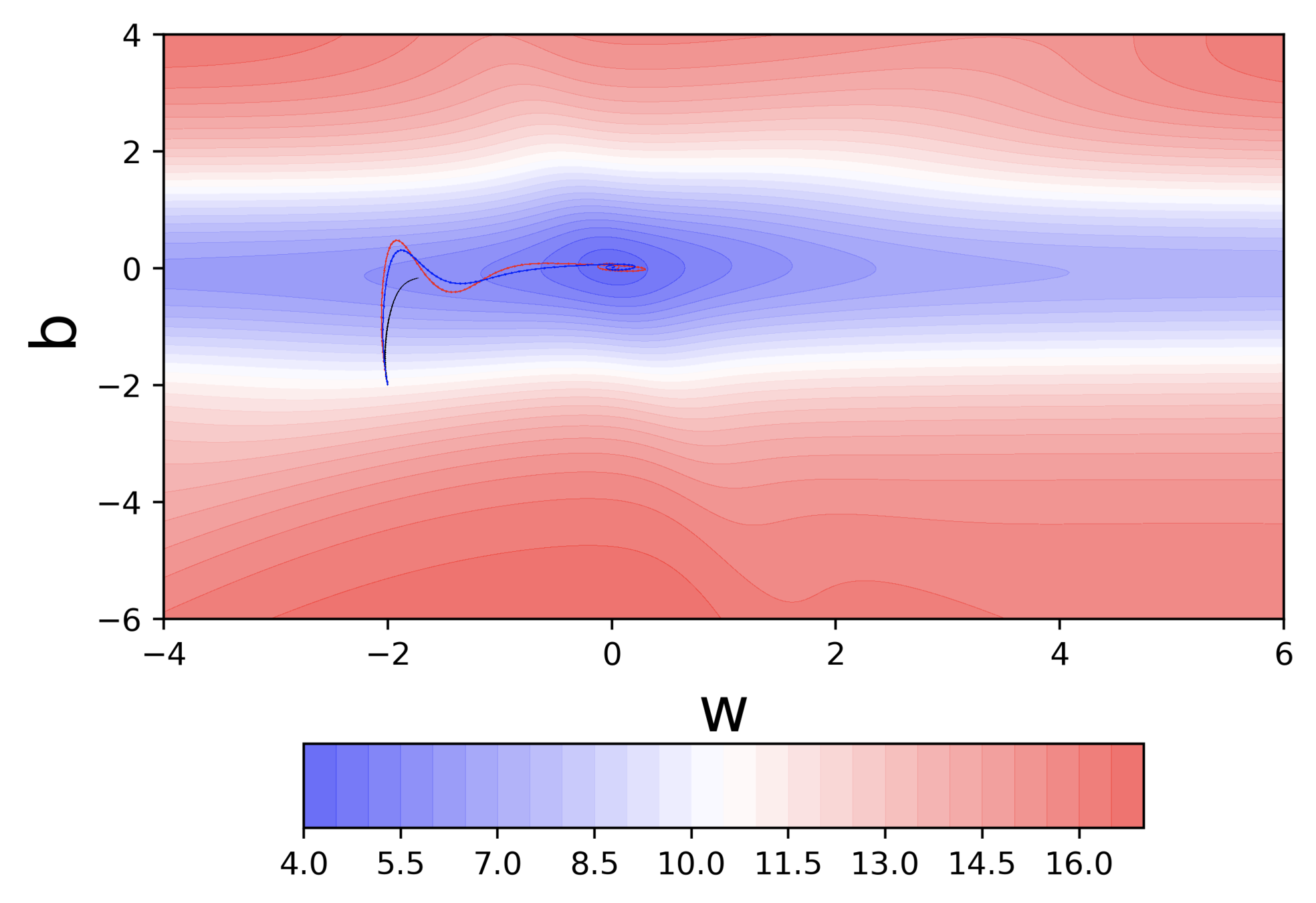
Why is the behaviour different on different surfaces ?
Gradient Descent Update Rule
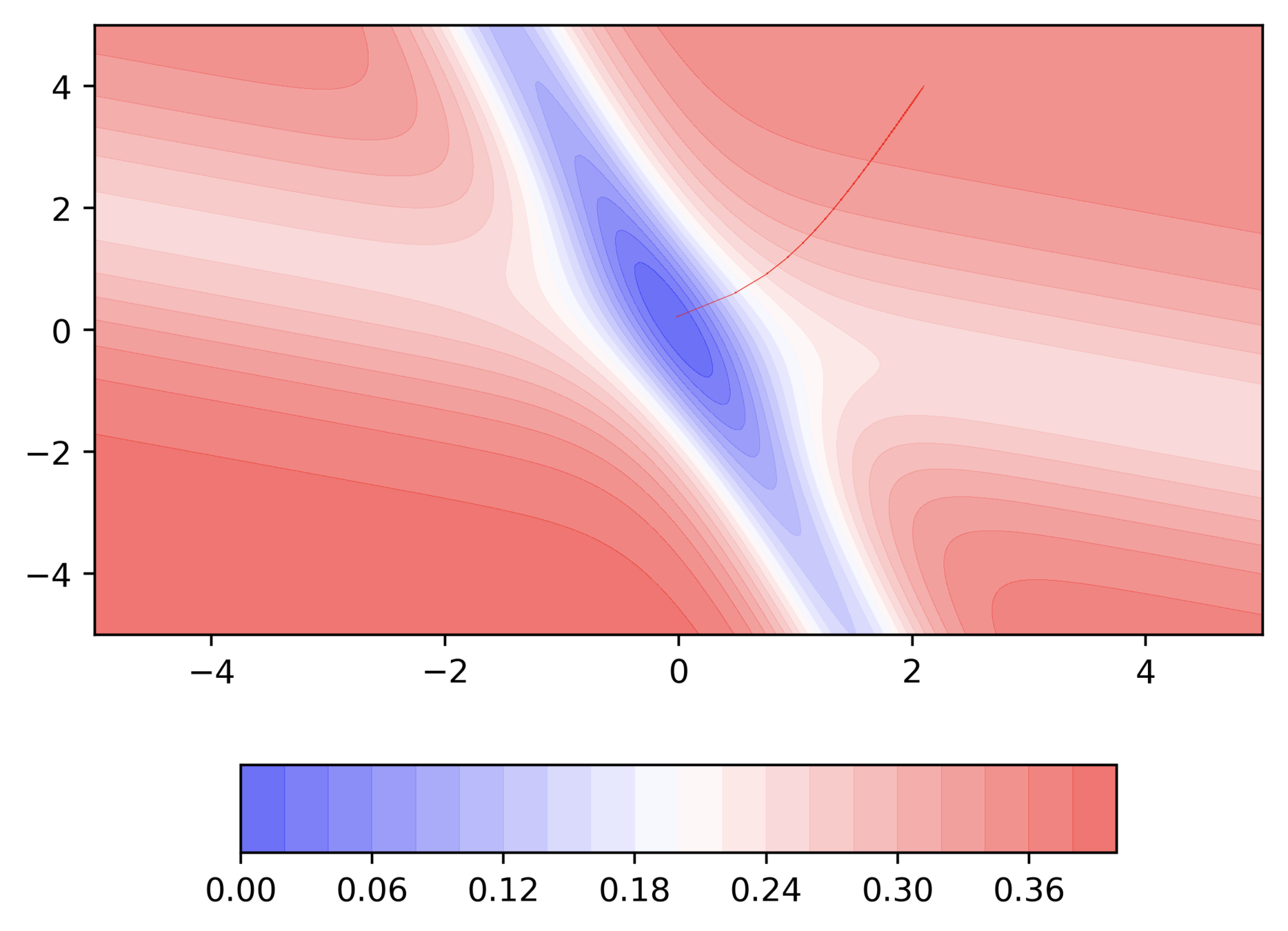
Do we observe the same behaviour if we start from a different initialization ?
Why does this behavior bother us ?
Initialise
\(w, b \)
Iterate over data:
\(w_{t+1} = w_{t} - \eta \Delta w_{t} \)
till satisfied
\(b_{t+1} = b_{t} - \eta \Delta b_{t} \)
randomly
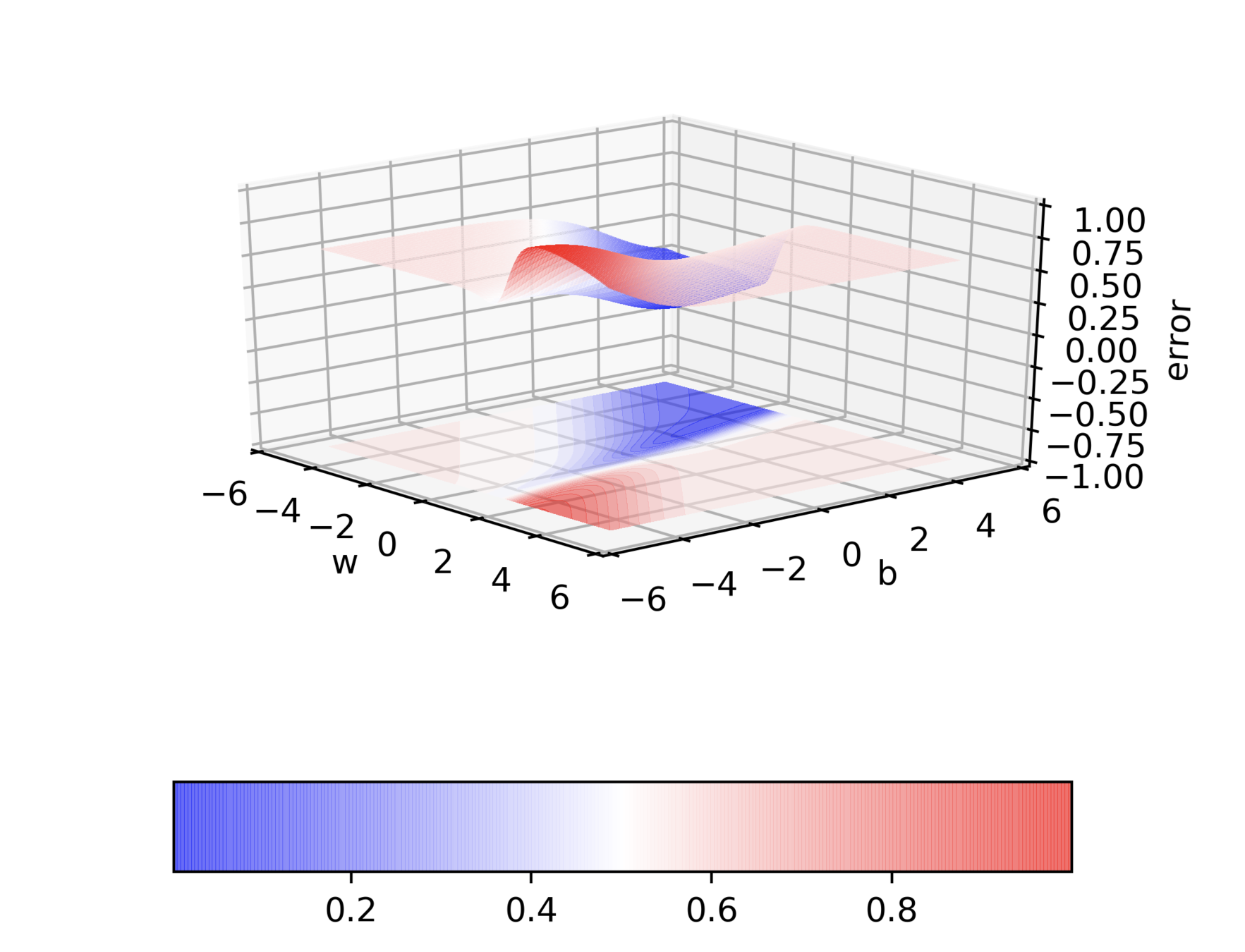
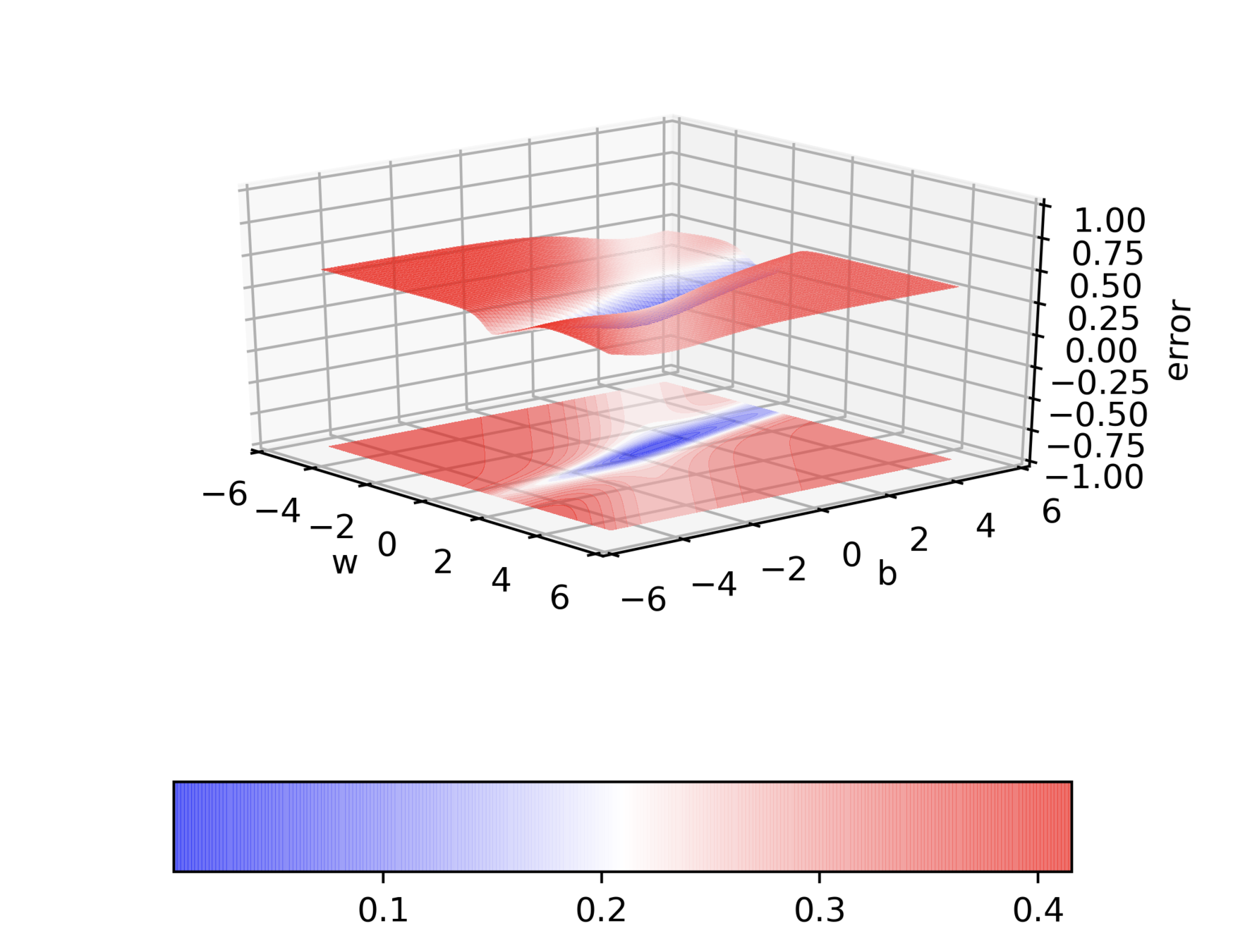
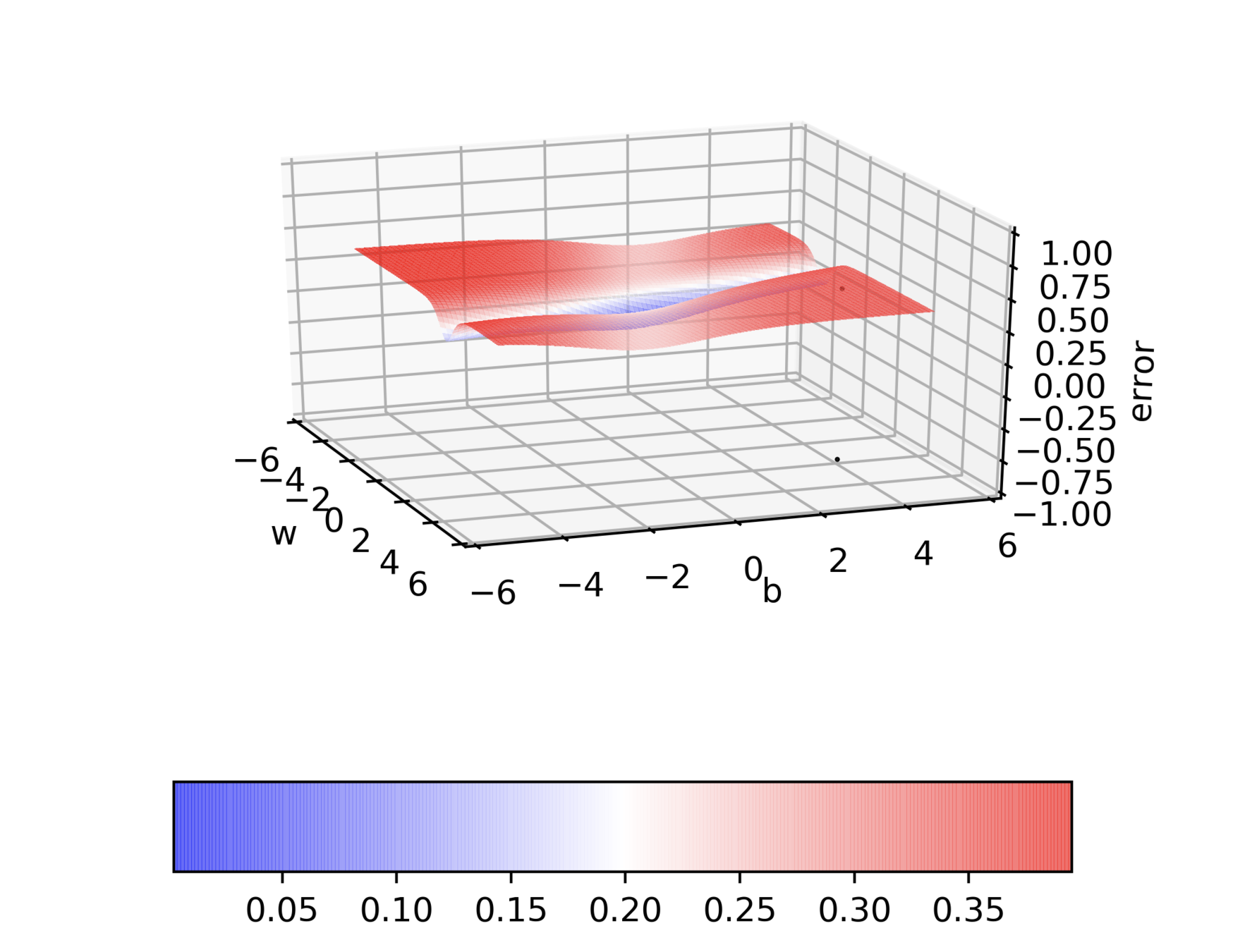
Can we visualize things in 2D instead of 3D ?
Can we do a few exercises?
Can we do a few exercises?
Can we do a few exercises?
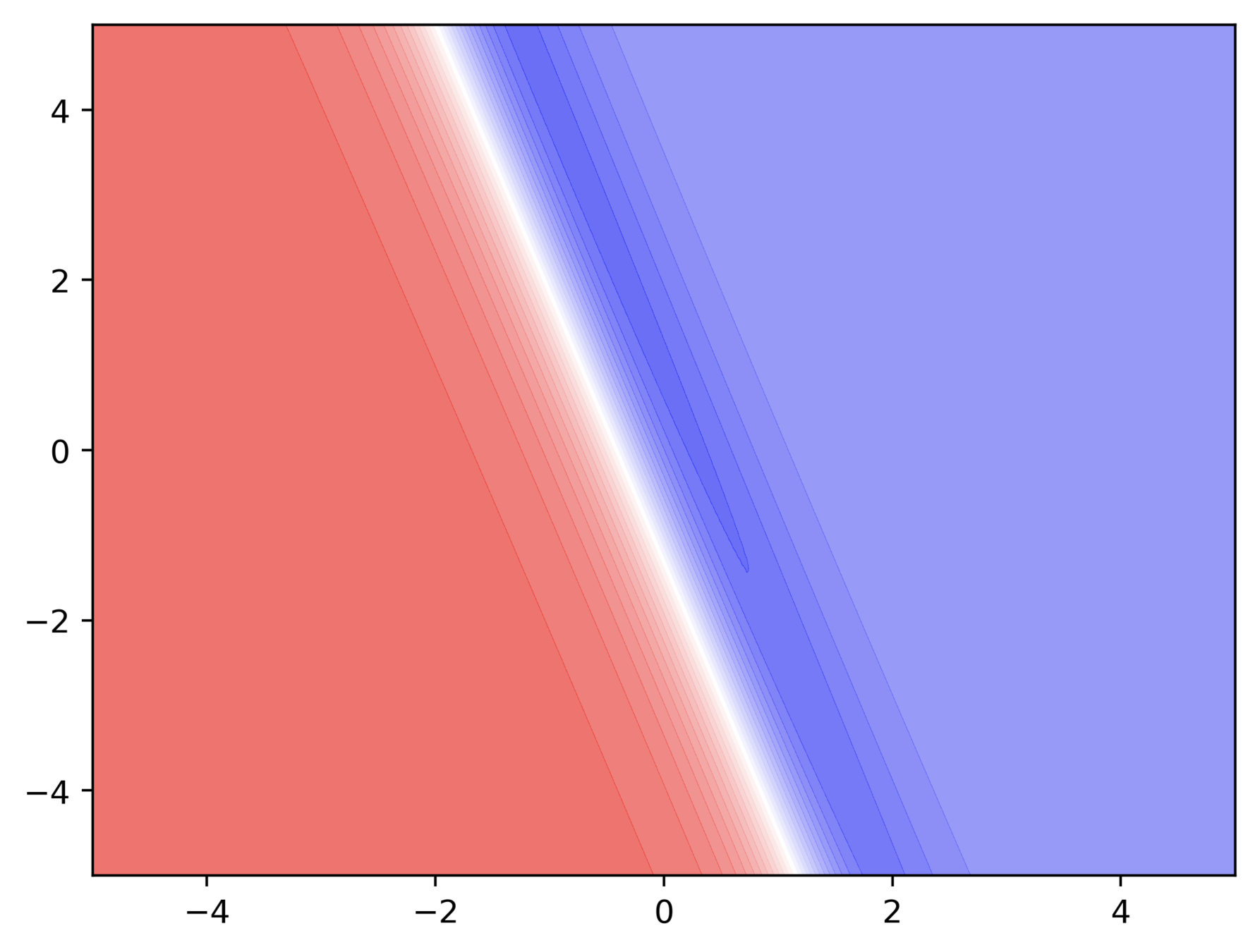
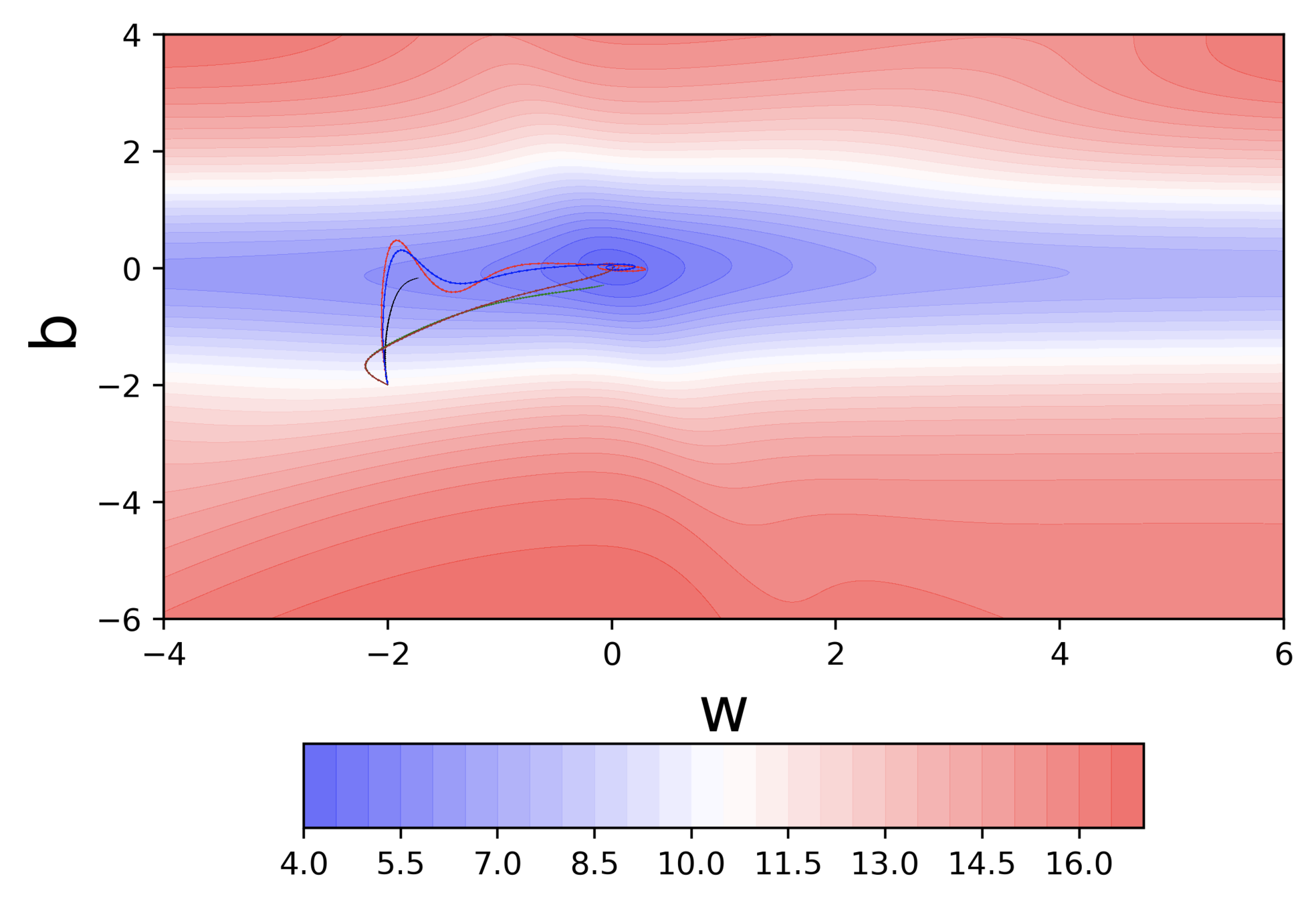
Can we visualize Gradient Descent on a 2d error surface ?
Why do we need a better algorithm ?
Issues
It takes a lot of time to navigate regions having gentle slope (because the gradient in these regions is very small)
Intuitive Solution
If I am repeatedly being asked to go in the sam direction then I should probably gain some confidence and start taking bigger steps in that direction
How do we convert this intuition into a set of mathematical equations
Gradient Descent Update Rule
Momentum based Gradient Descent Update Rule
Can we dissect the equations in more detail ?
Exponentially decaying weighted sum
Let' see the code for this
X = [0.5, 2.5]
Y = [0.2, 0.9]def f(w, b, x):
#sigmoid with parameters w, b
return 1.0 / (1.0 + np.exp(-(w*x + b))def error(w, b):
err = 0.0
for x, y in zip(X, Y):
fx = f(w, b, x)
err += 0.5* (fx - y) ** 2
return errdef grad_b(w, b, x, y):
fx = f(w, b, x)
return (fx - y) * fx * (1 - fx)
def do_gradient_descent():
w, b, eta = -2, -2, 1.0
max_epochs = 1000
for i in range(max_epochs):
dw, db = 0, 0
for x, y in zip(X, Y) :
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
w = w - eta * dw
b = b - eta * db
def grad_w(w, b, x, y):
fx = f(w, b, x)
return (fx - y) * fx * (1 - fx) * x
def do_momentum_gradient_descent():
w, b, eta, max_epochs = -2, -2, 1.0, 1000
v_w, v_b = 0, 0
for i in range(max_epochs):
dw, db = 0, 0
for x, y in zip(X, Y) :
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
v_w = gamma*v_w + eta * dw
v_b = gamma*v_b + eta * dw
w = w - v_w
b = b - v_w
Momentum based Gradient Descent Update Rule
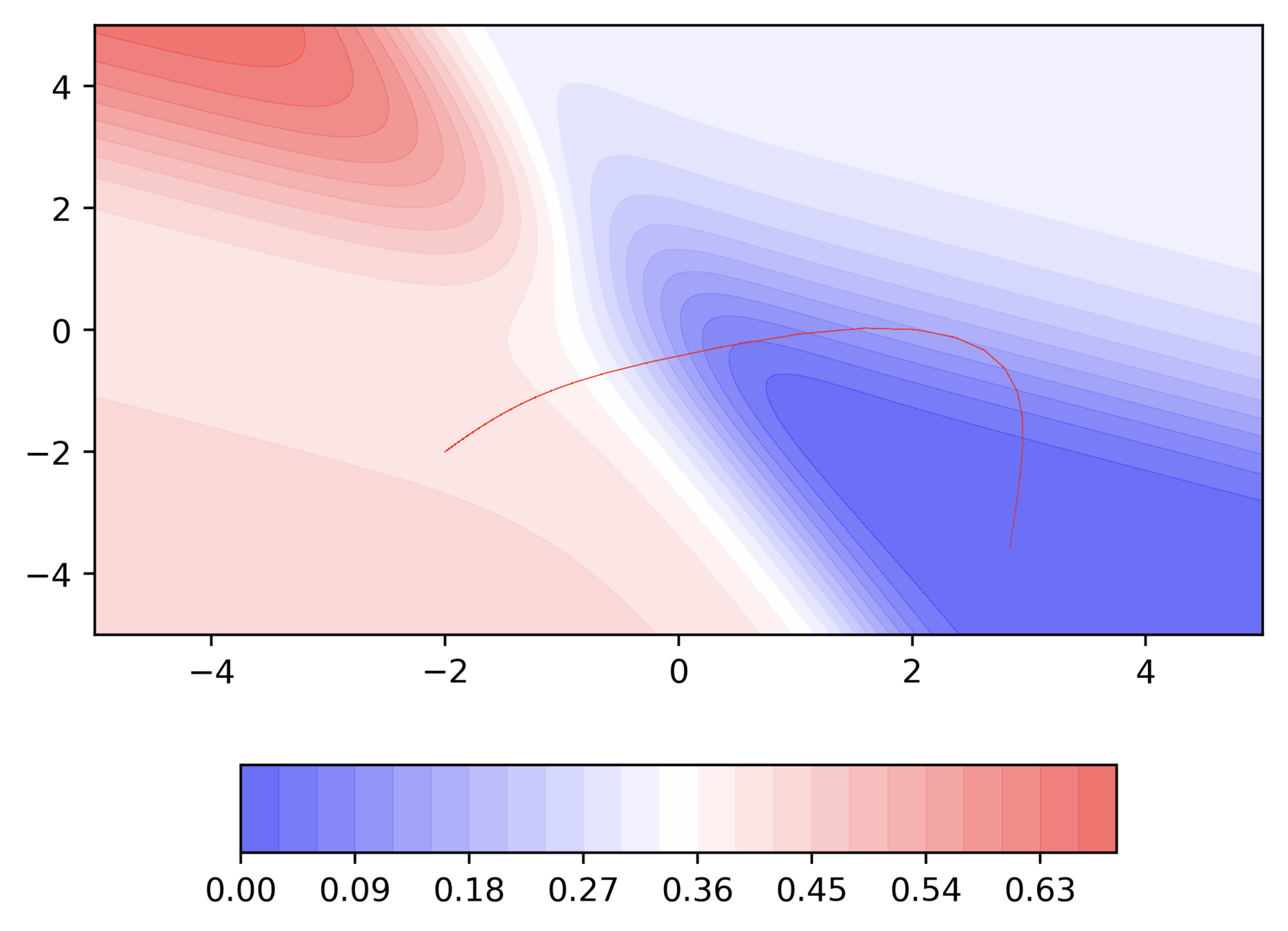
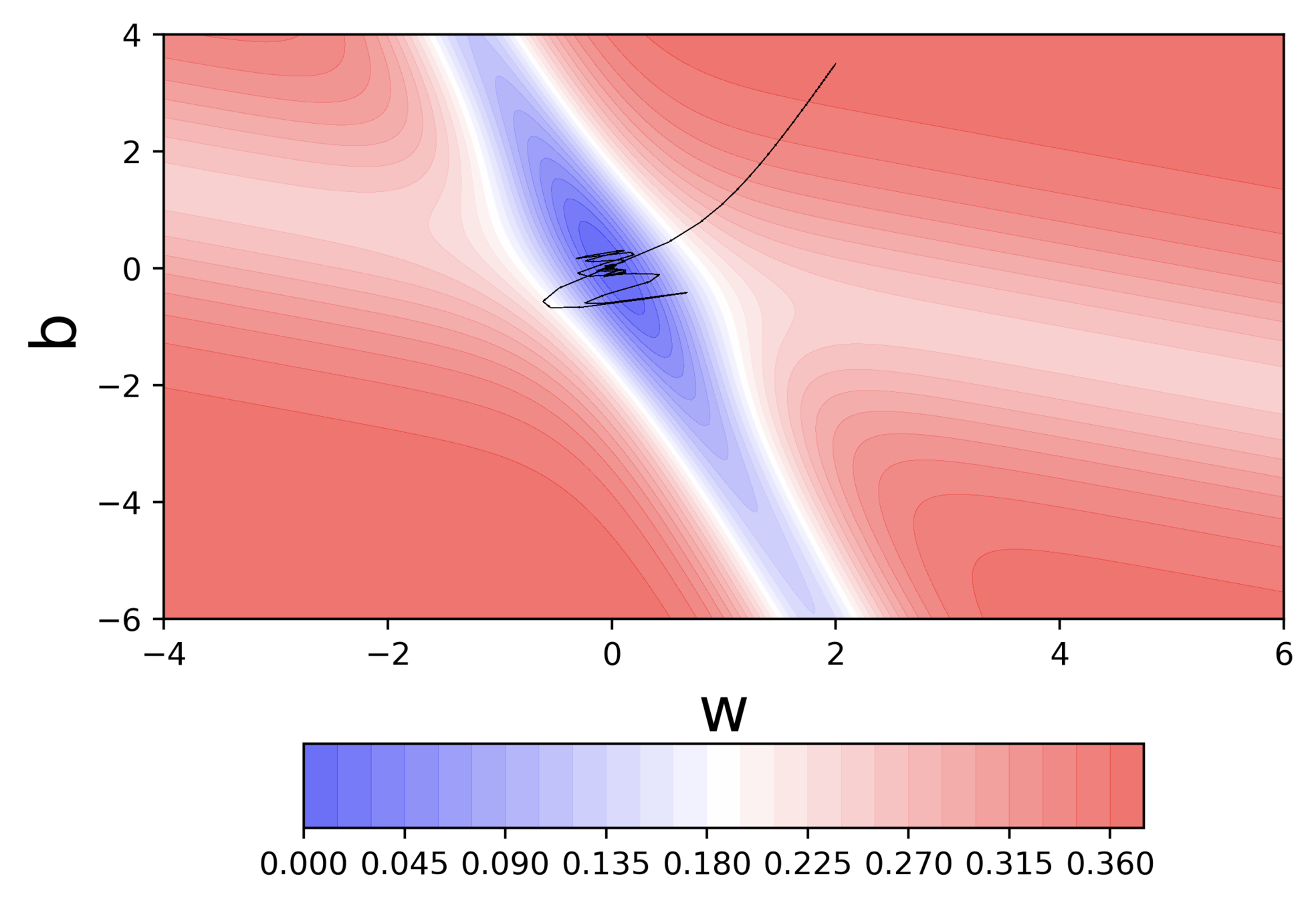
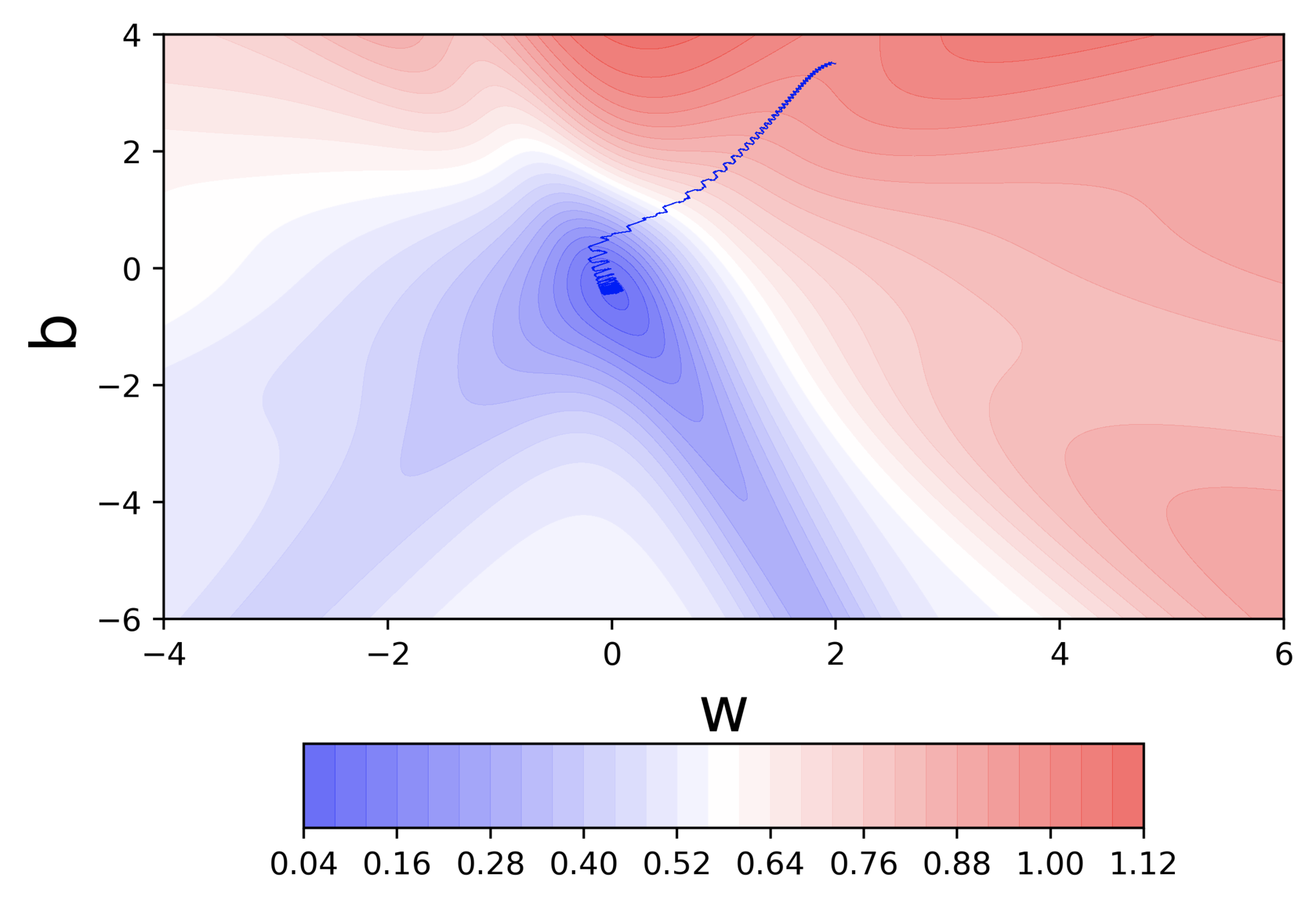
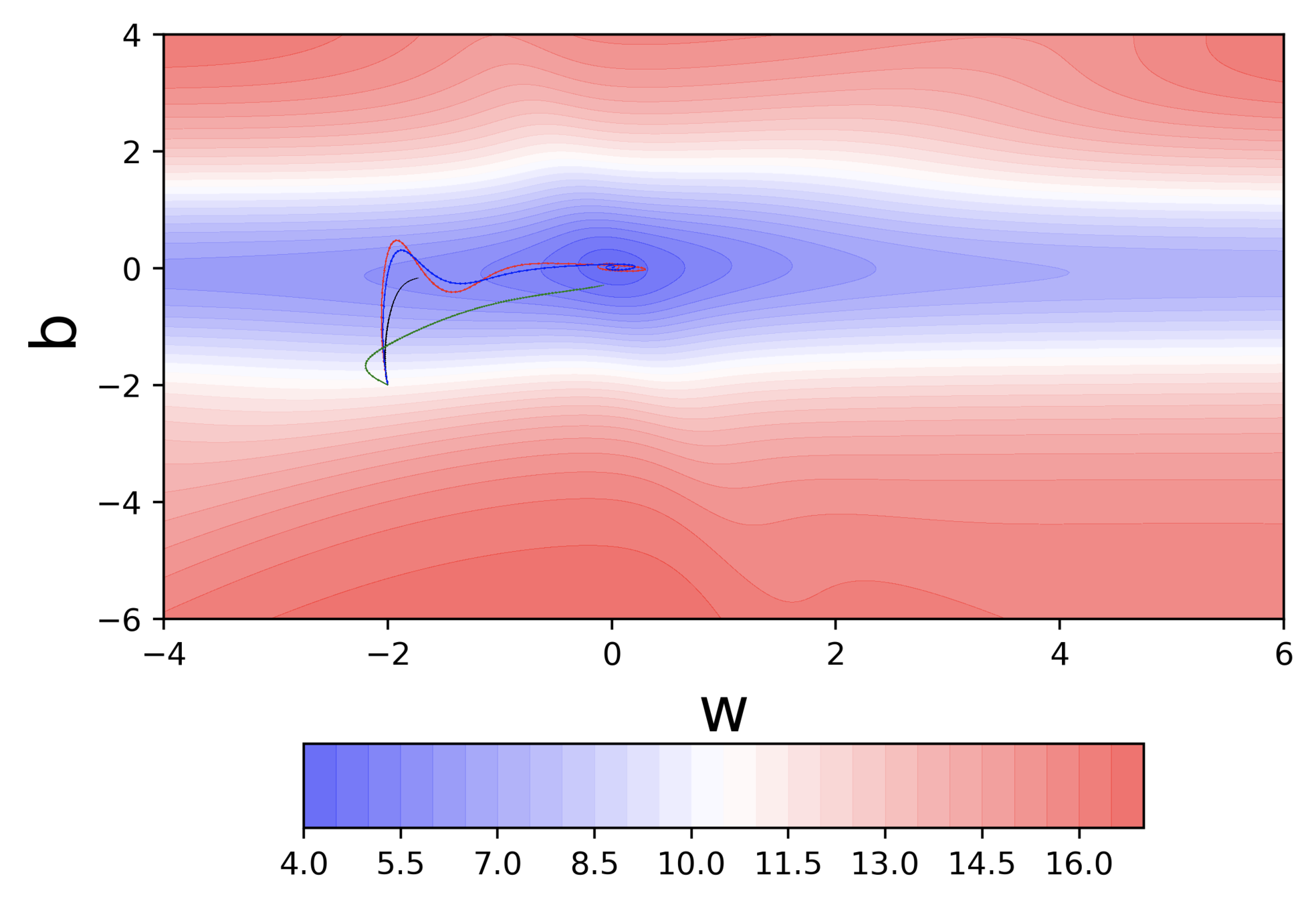
Let's run this code
Let us make a few observations and ask some questions
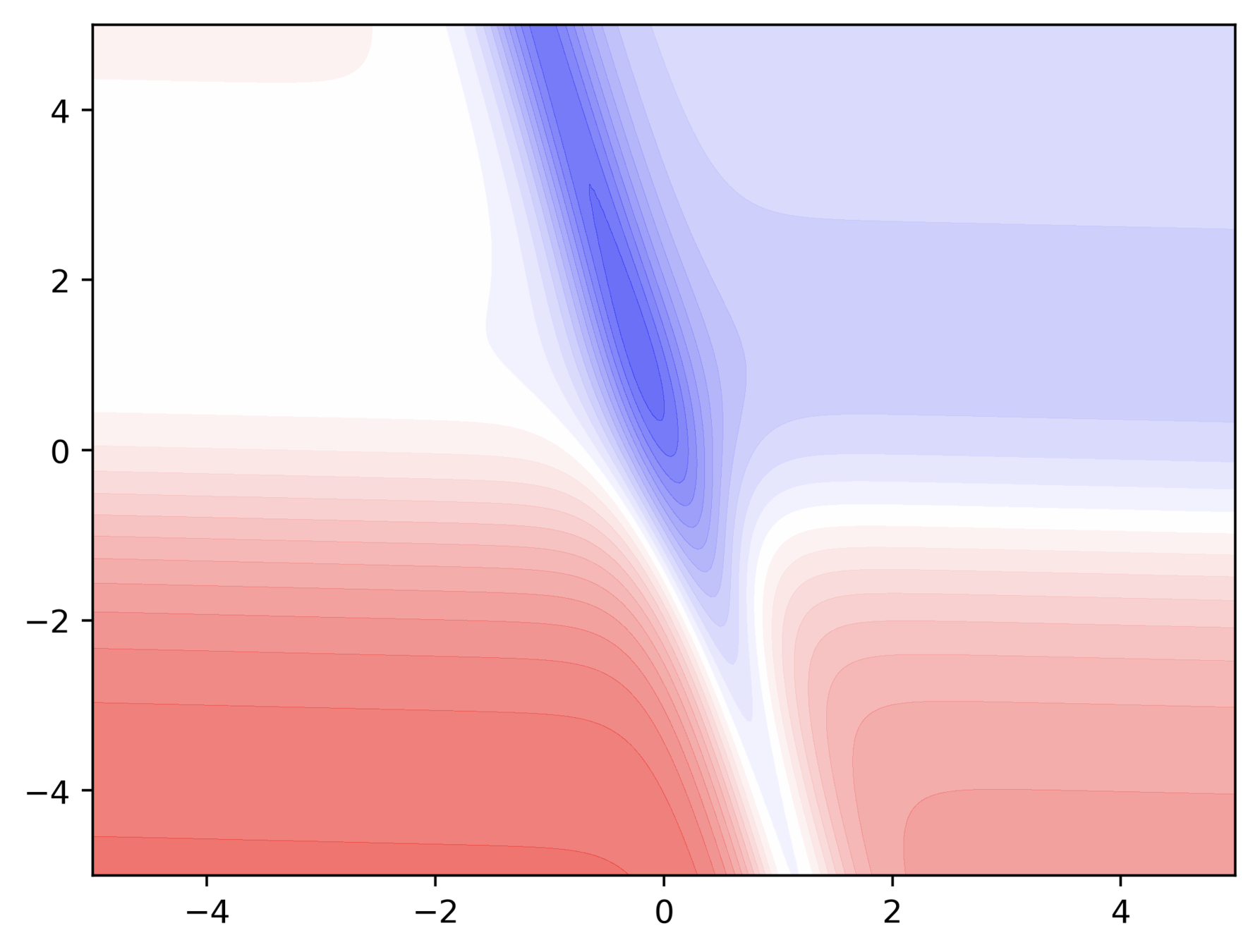
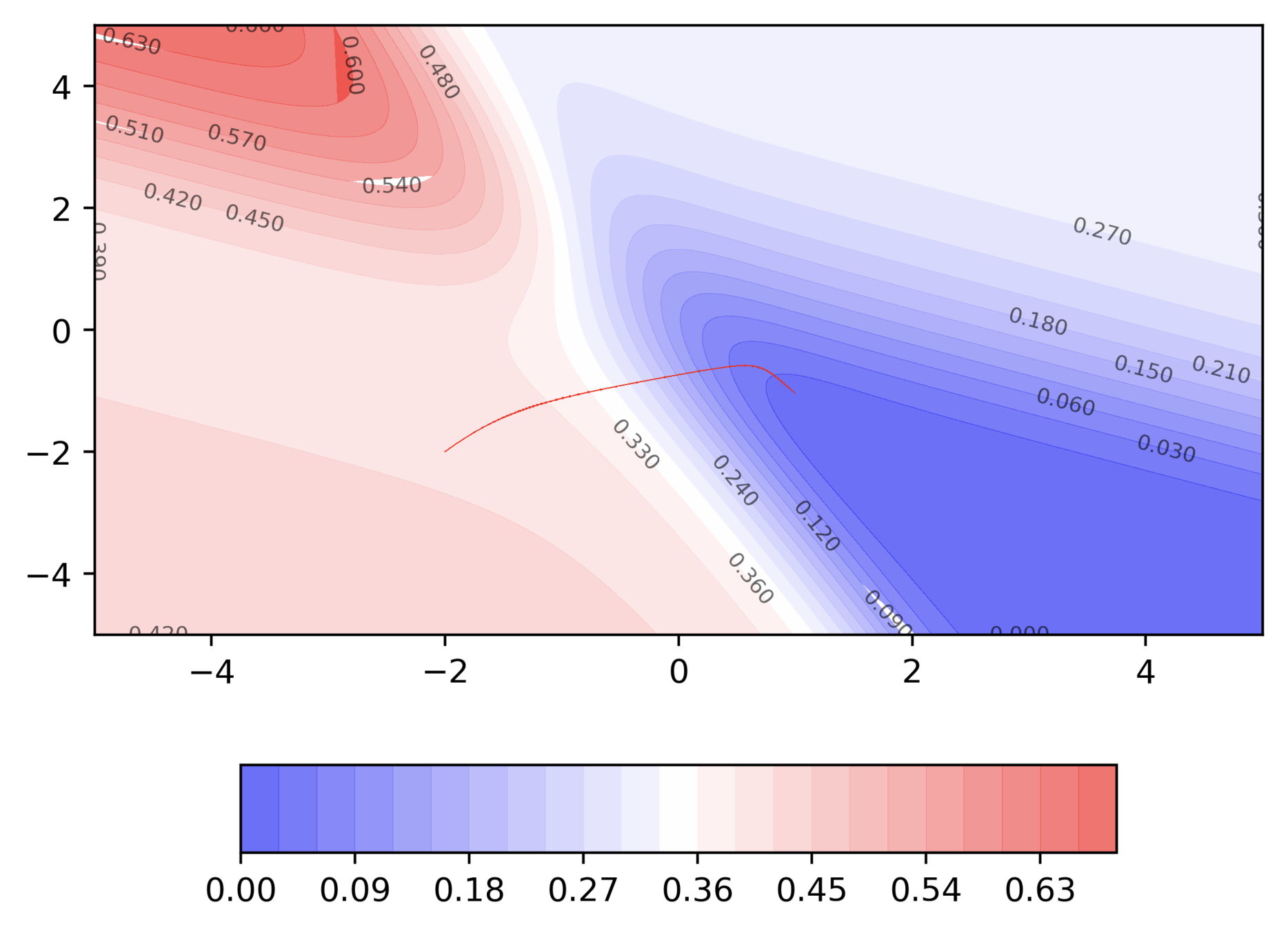
Observations
Even in the regions having gentle slopes, momentum based gradient descent is able to take large steps because the momentum carries it along
Questions
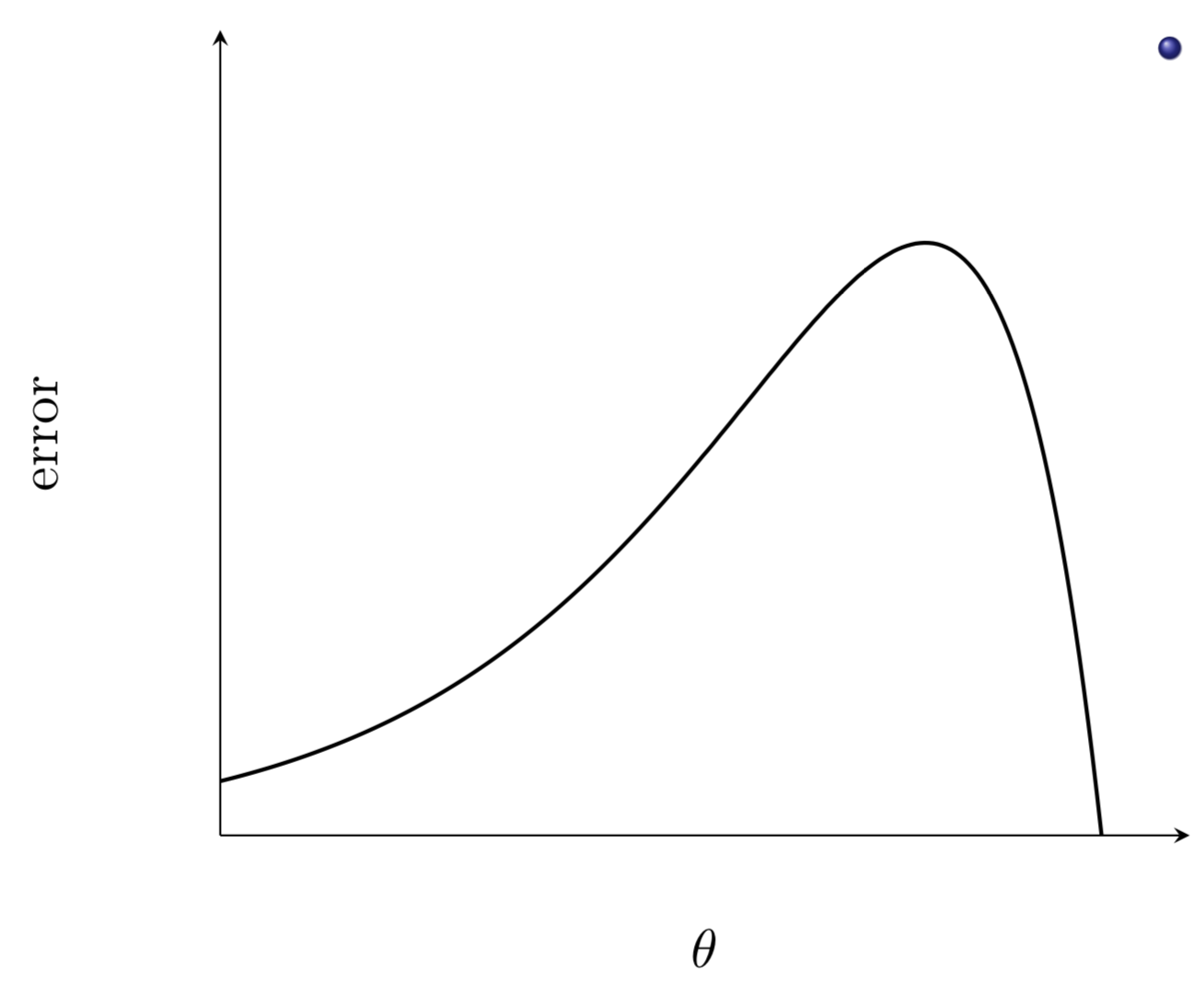
- Is moving fast always good?
- Would there be a situation where momentum would cause us to run pass our goal?
Would there be cases where momentum could be detrimental ?
What are some observations that we make ?
Can we see this from a different perspective ?
Some more insights into what is happening
Can we do something to reduce the oscillations in Momentum based GD ?
Momentum based Gradient Descent Update Rule
NAG Update Rule
Can we try to understand the equations in terms of the loss surface ?
NAG Update Rule
Let's see the code for this
X = [0.5, 2.5]
Y = [0.2, 0.9]def f(w, b, x):
#sigmoid with parameters w, b
return 1.0 / (1.0 + np.exp(-(w*x + b))def error(w, b):
err = 0.0
for x, y in zip(X, Y):
fx = f(w, b, x)
err += 0.5* (fx - y) ** 2
return errdef grad_b(w, b, x, y):
fx = f(w, b, x)
return (fx - y) * fx * (1 - fx)
def do_gradient_descent():
w, b, eta = -2, -2, 1.0
max_epochs = 1000
for i in range(max_epochs):
dw, db = 0, 0
for x, y in zip(X, Y) :
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
w = w - eta * dw
b = b - eta * db
def grad_w(w, b, x, y):
fx = f(w, b, x)
return (fx - y) * fx * (1 - fx) * x
def do_nag_gradient_descent():
w, b, eta, max_epochs = -2, -2, 1.0, 1000
v_w, v_b, gamma = 0, 0, 0.9
for i in range(max_epochs):
dw, db = 0, 0
#Compute the lookahead value
w = w - gamma*v_w
b = b - gamma*v_b
for x, y in zip(X, Y) :
#Compute derivatives using the lookahead value
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
#Now move further in the direction of that gradient
w = w - eta * dw
b = b - eta * db
#Now update the history
v_w = gamma * v_w + eta * dw
v_b = gamma * v_b + eta * db
NAG Update Rule
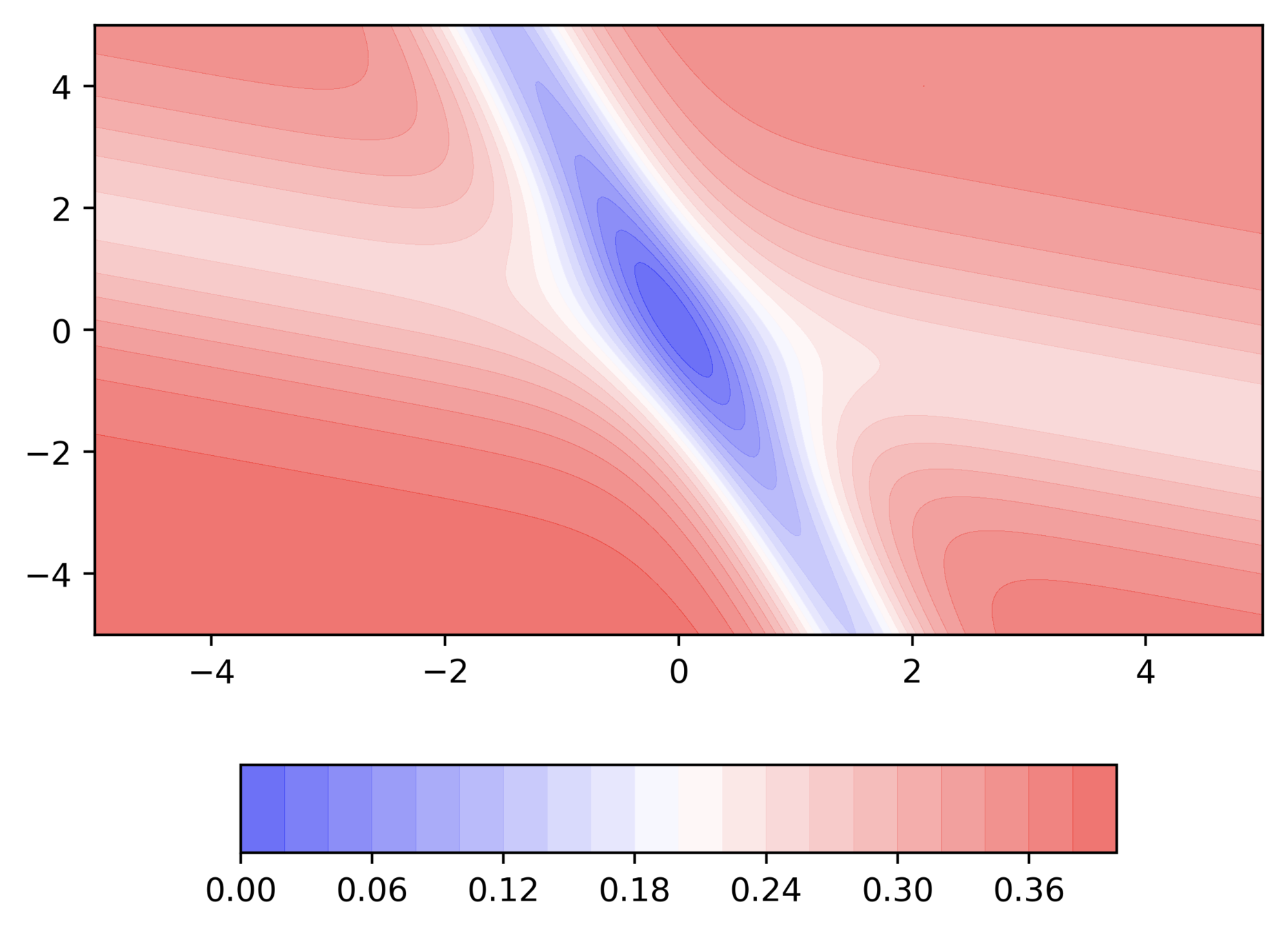
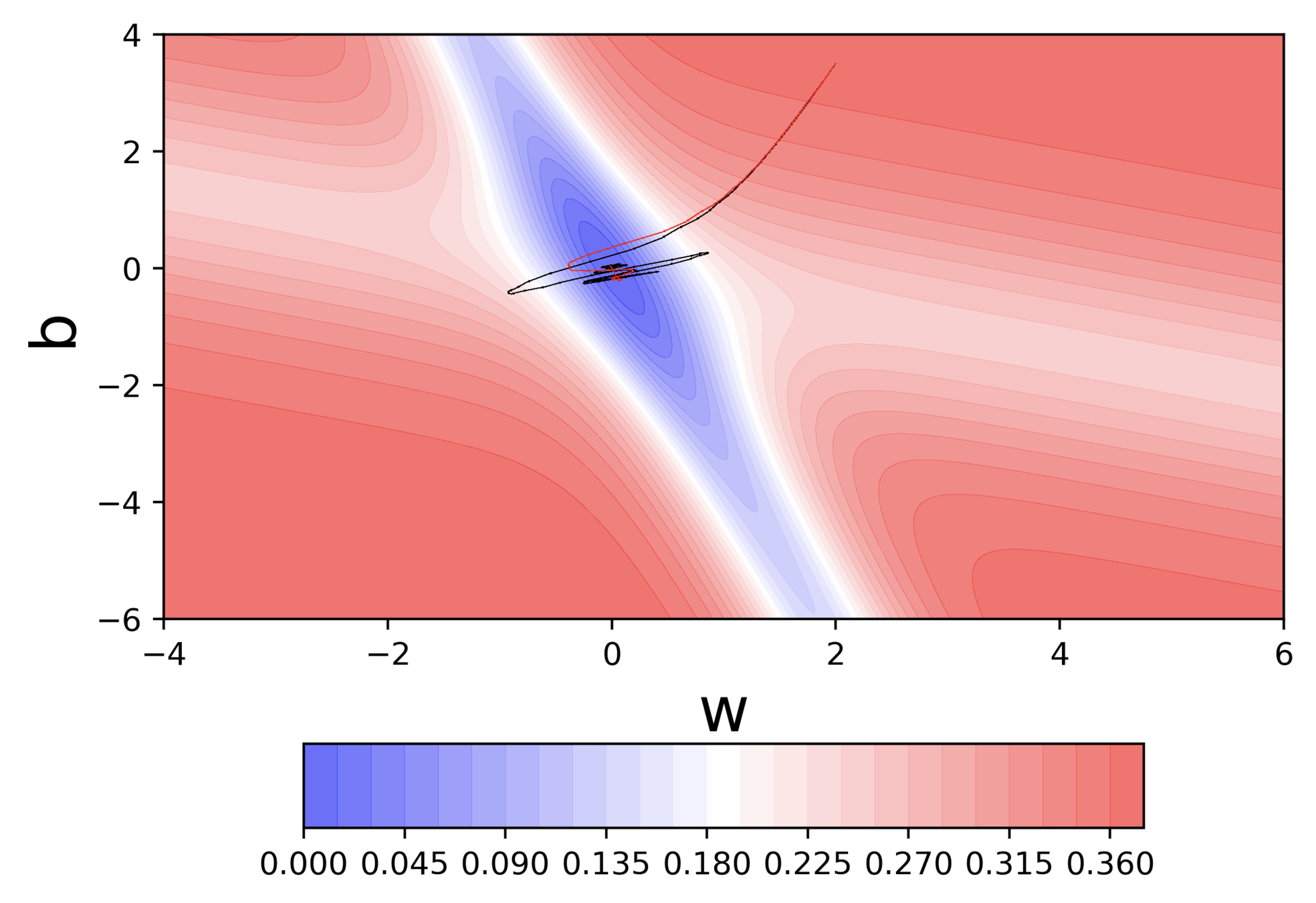
Let's run this code
def do_nag_gradient_descent():
w, b, eta, max_epochs = -2, -2, 1.0, 1000
v_w, v_b, gamma = 0, 0, 0.9
for i in range(max_epochs):
dw, db = 0, 0
#Compute the lookahead value
w = w - gamma*v_w
b = b - gamma*v_b
for x, y in zip(X, Y) :
#Compute derivatives using the lookahead value
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
#Now move further in the direction of that gradient
w = w - eta * dw
b = b - eta * db
#Now update the history
v_w = gamma * v_w + eta * dw
v_b = gamma * v_b + eta * db
What are some observations that we make ?
Hence the oscillations are smaller and the chances of escaping the minima valley also smaller
Could we not have overcome the limitation of GD by increasing the learning rate
It would be good to have a learning rate which could adjust to the gradient!
What are we going to see in this chapter ?
How do you use the gradients?
or
Can you come up with a better update rule ?
Gradient Descent Update Rule
How do you compute the gradients ?
or
What data should you use for computing the gradients?
How many updates are we making ?
X = [0.5, 2.5]
Y = [0.2, 0.9]def f(w, b, x):
#sigmoid with parameters w, b
return 1.0 / (1.0 + np.exp(-(w*x + b))def error(w, b):
err = 0.0
for x, y in zip(X, Y):
fx = f(w, b, x)
err += 0.5* (fx - y) ** 2
return errdef grad_b(w, b, x, y):
fx = f(w, b, x)
return (fx - y) * fx * (1 - fx)
def do_gradient_descent():
w, b, eta = -2, -2, 1.0
max_epochs = 1000
for i in range(max_epochs):
dw, db = 0, 0
for x, y in zip(X, Y) :
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
w = w - eta * dw
b = b - eta * db
def grad_w(w, b, x, y):
fx = f(w, b, x)
return (fx - y) * fx * (1 - fx) * x
Can we make stochastic updates?
def do_gradient_descent():
w, b, eta = -2, -2, 1.0
max_epochs = 1000
for i in range(max_epochs):
dw, db = 0, 0
for x, y in zip(X, Y) :
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
w = w - eta * dw
b = b - eta * db
def do_stochastic_gradient_descent():
w, b, eta = -2, -2, 1.0
max_epochs = 1000
for i in range(max_epochs):
dw, db = 0, 0
for x, y in zip(X, Y) :
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
w = w - eta * dw
b = b - eta * db
Advantage
Disadvantage
How is this different from Batch GD ?
Doesn't it make sense to use more than one point or a mini-batch of points?
def do_gradient_descent():
w, b, eta = -2, -2, 1.0
max_epochs = 1000
for i in range(max_epochs):
dw, db = 0, 0
for x, y in zip(X, Y) :
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
w = w - eta * dw
b = b - eta * db
def do_stochastic_gradient_descent():
w, b, eta = -2, -2, 1.0
max_epochs = 1000
for i in range(max_epochs):
dw, db = 0, 0
for x, y in zip(X, Y) :
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
w = w - eta * dw
b = b - eta * db
def do_mini_batch_gradient_descent():
w, b, eta = -2, -2, 1.0
max_epochs = 1000
mini_batch_size = 0
num_points_seen = 0
for i in range(max_epochs):
dw, db = 0, 0
for x, y in zip(X, Y) :
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
num_points_seen += 1
if num_points_seen % mini_batch_size == 0:
w = w - eta * dw
b = b - eta * db
How does this perform when compared to stochastic SGD ?
What is an epoch and what is a step ?
| Algorithm | # of steps in one epoch |
|---|---|
| Batch gradient descent | 1 |
| Stochastic gradient descent | N |
| Mini-Batch gradient descent | N/B |
Can we have stochastic versions of NAG and Momentum based SGD ?
def do_nag_gradient_descent():
w, b, eta, max_epochs = -2, -2, 1.0, 1000
v_w, v_b, gamma = 0, 0, 0.9
for i in range(max_epochs):
dw, db = 0, 0
#Compute the lookahead value
w = w - gamma*v_w
b = b - gamma*v_b
for x, y in zip(X, Y) :
#Compute derivatives using the lookahead value
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
#Now move further in the direction of that gradient
w = w - eta * dw
b = b - eta * db
#Now update the history
v_w = gamma * v_w + eta * dw
v_b = gamma * v_b + eta * db
def do_stochastic_momentum_gradient_descent():
w, b, eta, max_epochs = -2, -2, 1.0, 1000
v_w, v_b = 0, 0
for i in range(max_epochs):
dw, db = 0, 0
for x, y in zip(X, Y) :
dw += grad_w(w, b, x, y)
db += grad_b(w, b, x, y)
v_w = gamma*v_w + eta * dw
v_b = gamma*v_b + eta * db
w = w - v_w
b = b - v_b
How do the stochastic versions of the 3 algorithms look like ?
What are we going to see in this chapter ?
How do you use the gradients?
or
Can you come up with a better update rule ?
Gradient Descent Update Rule
How do you compute the gradients ?
or
What data should you use for computing the gradients?
Why do we need a different learning rate for every feature ?
Can we have a different learning rate for each parameter which takes care of the frequency of features ?
How do we convert this intuition into an equation ?
Intuition: Decay the learning rate for parameters in proportion to their update history (fewer updates, lesser decay)
Adagrad
Let's compare this to vanilla, momentum based, nesterov gradient descent
What do we observe ?
Advantage
Disadvantage
How do you convert this intuition into an equation?
Intuition: Why not decay the denominator and prevent its rapid growth ?
Adagrad
RMSProp
How does this compare to Adagrad ?
Does it make sense to use a cumulative history of gradients ?
Momentum based Gradient Descent Update Rule
RMSProp
Adam
How does this perform compared to RMSProp ?
Which algorithm do we use in practice ?
(c) One Fourth Labs
Algorithms
Strategies
Initialise
\(w, b \)
Iterate over data:
\(w_{111} = w_{111} - \eta \Delta w_{111} \)
till satisfied
\(w_{112} = w_{112} - \eta \Delta w_{112} \)
\(w_{313} = w_{313} - \eta \Delta w_{313} \)
....
By One Fourth Labs



