










































One Fourth Labs
We deliver courseware in AI and related areas
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
E
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
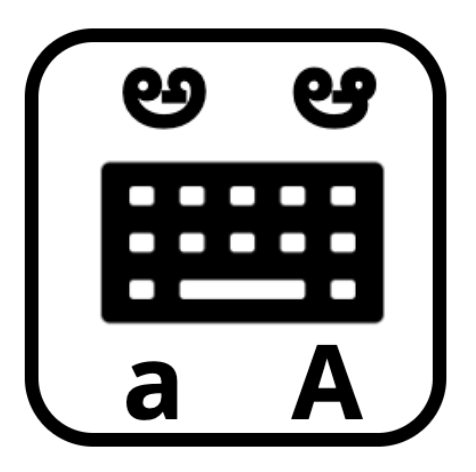
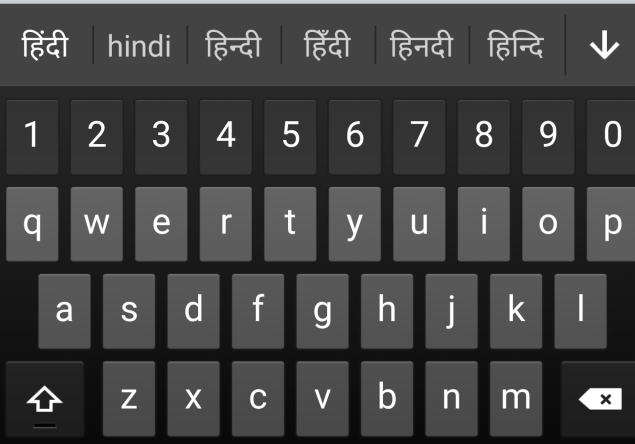
Build swipe based keyboards for all 22 languages
2021
2022
2023
2020
Dataset
Benchmark
Model
Tools
green = eco-friendly = efficient
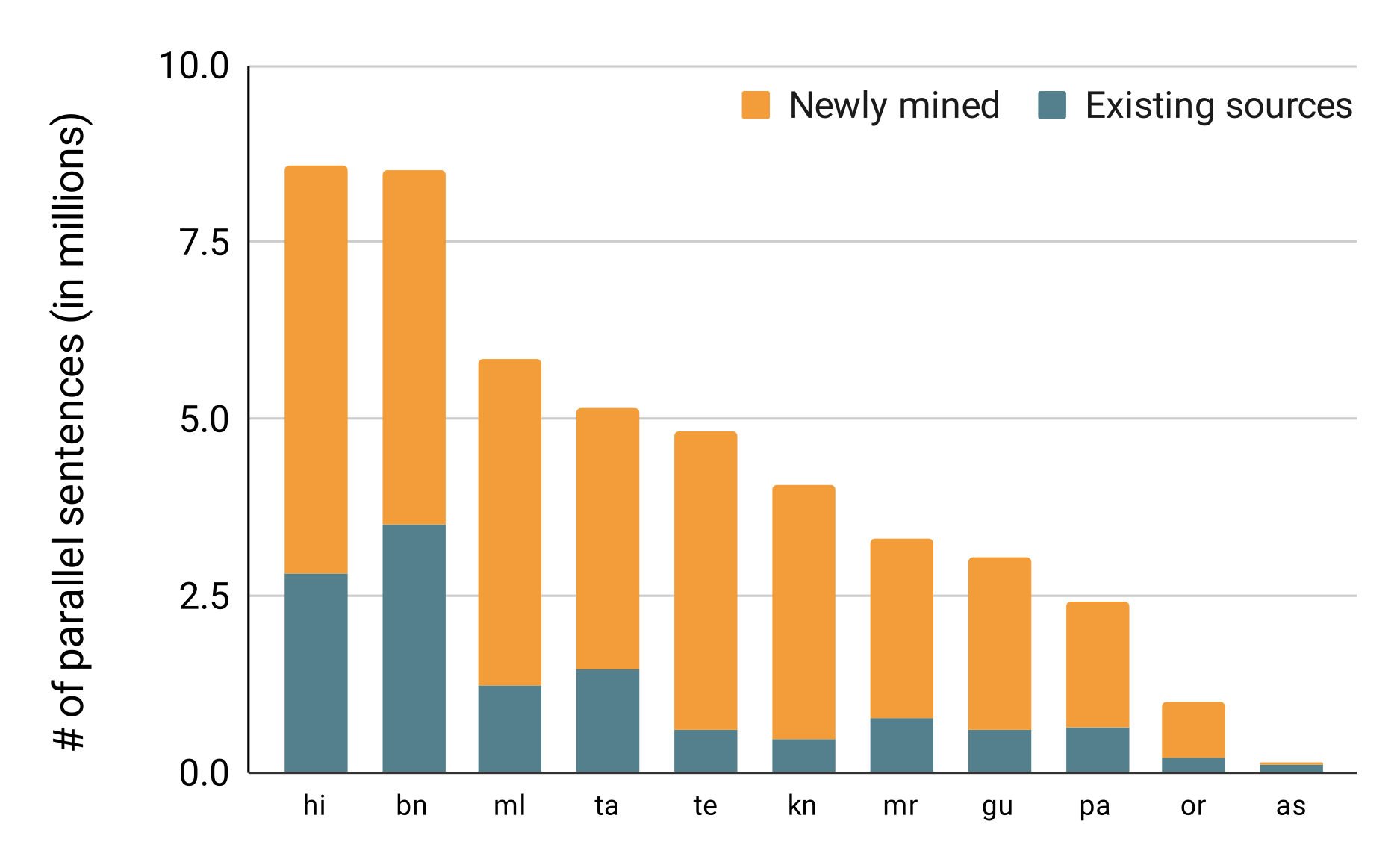
v 1.0, 46M sentences, 12 languages
v 1.0, 9B tokens, 12 languages
v 1.0, 2 languages
v 2.0, 20B tokens, 15 languages
v 1.0, 22 languages
v 1.0, 22 languages
v 2.0, 75M sentences, 15 languages
v 1.0, 22 languages
v 1.0, 2000 hours, 22 languages
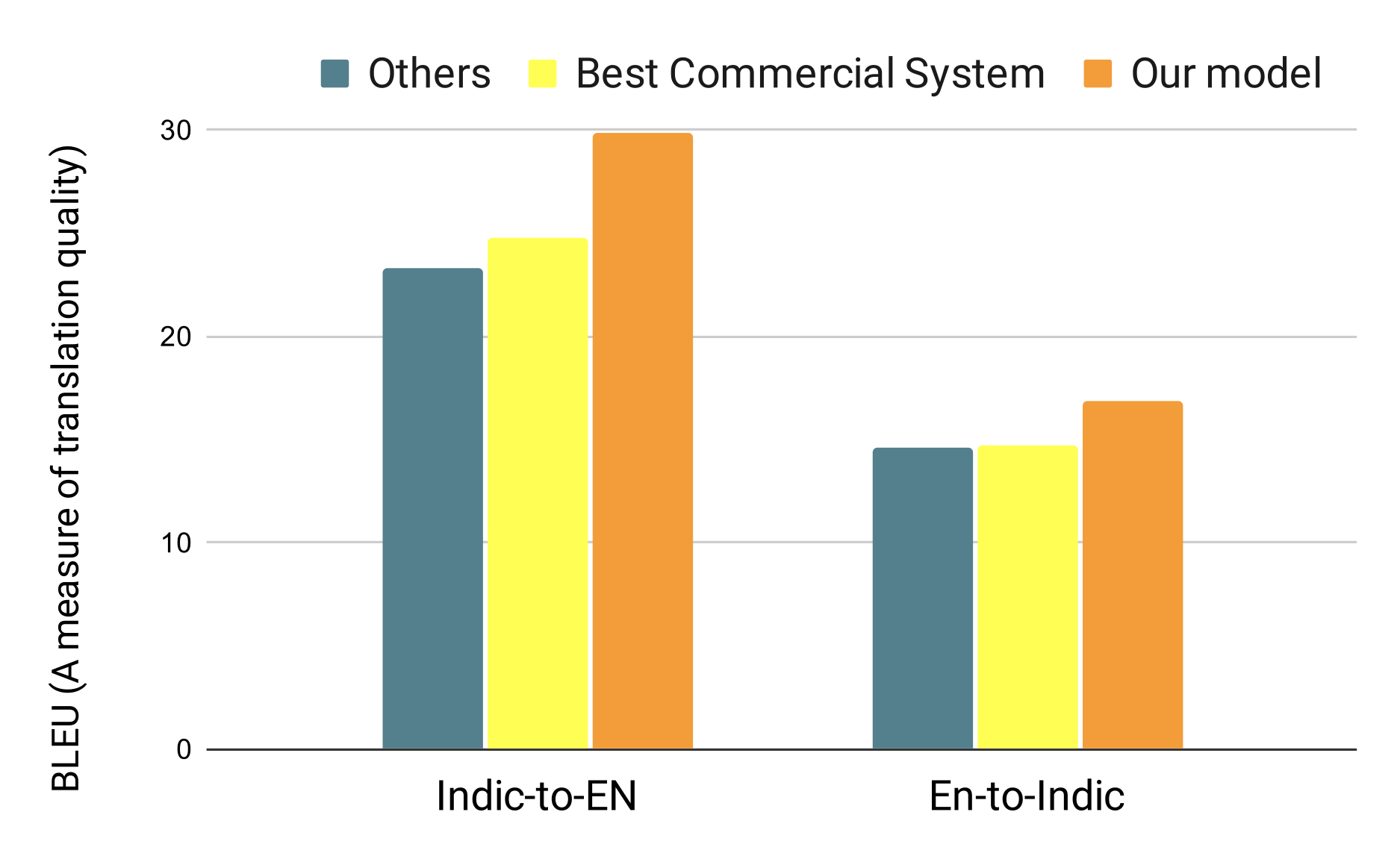
v 3.0, 15 languages, green translation
v 3.0, 25B tokens, 22 languages
green language model
v 2.0, 4000 hours, 22 languages, green ASR Models
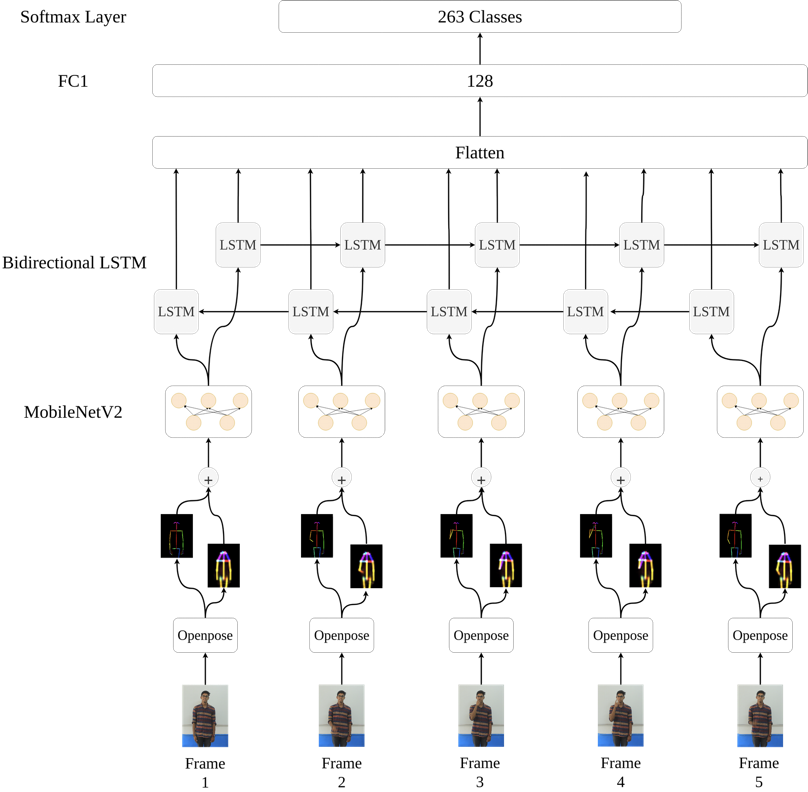
263 signs, 4000+ videos
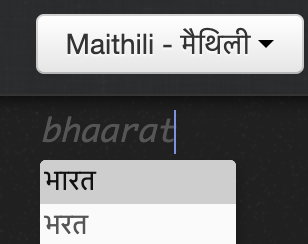
swipe keyboards - 22 languages
sign language
crowdsourcing tool
sign language recognition in video calls
Build swipe based keyboards for all 22 languages
By One Fourth Labs
The AI4Bharat Initiative




