












































One Fourth Labs
We deliver courseware in AI and related areas
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
E
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
v 2.0
Sep'21
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
IndicNLU Challenge: Benchmark for Indian languages
Mar'22
Monolingual Corpus v 1.0
Pre-trained Model
Sep'20
Dec'20
Build a dataset for all 22 constitutionally recognised languages
Build a joint transliteration model for all 22 languages
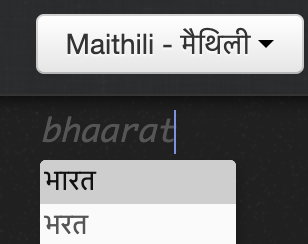
Build romanised keyboards for all 22 languages
Build swipe based keyboards for all 22 languages
Dec'21
Mar'22
Jun'22
Sep'22
IndicTranslate Challenge: A benchmark for 11 Indic languages
Build swipe based keyboards for all 22 languages
Dec'21
E
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
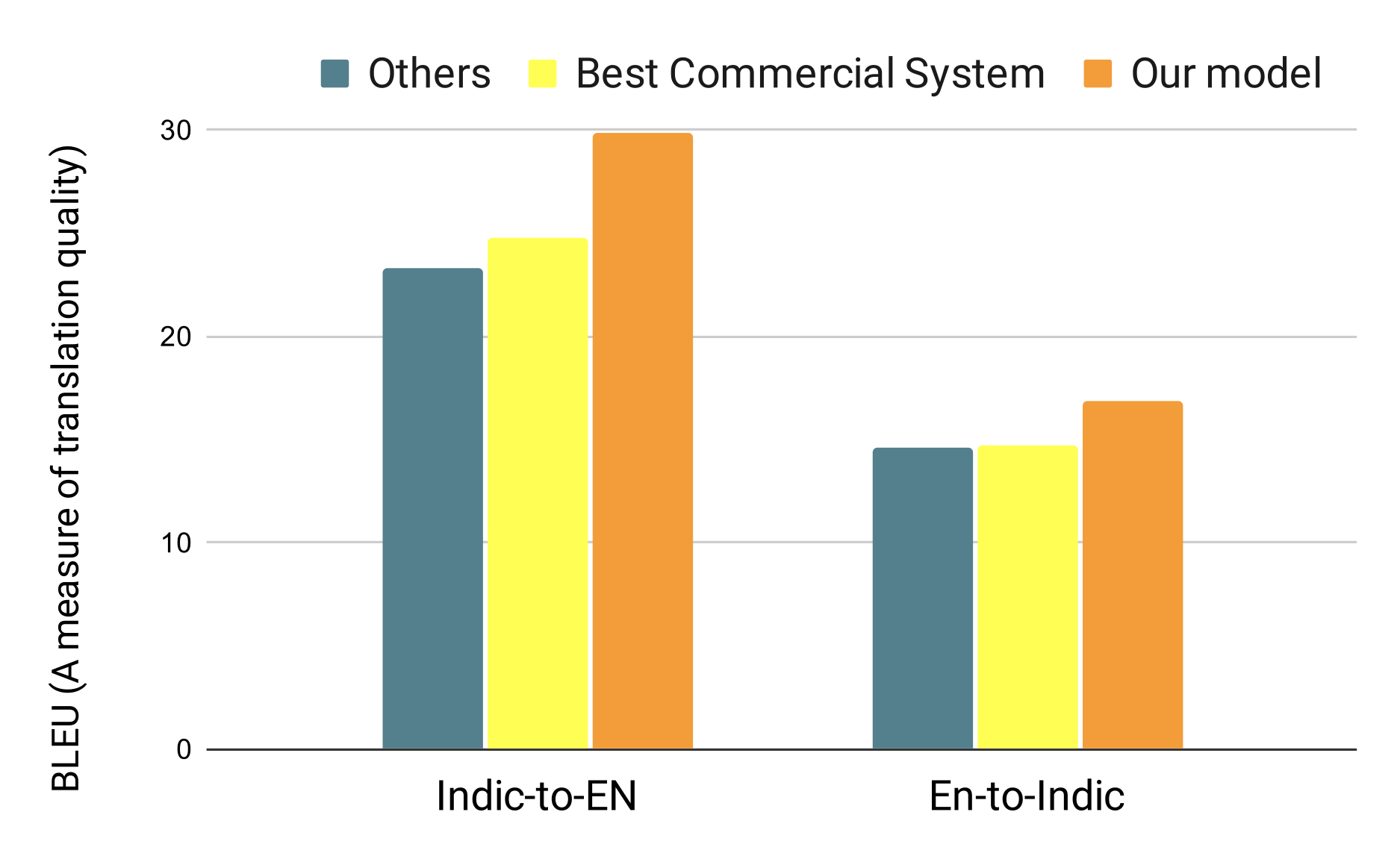
46M parallel sentences
Joint translation model competing with commercial systems
Apr'21
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
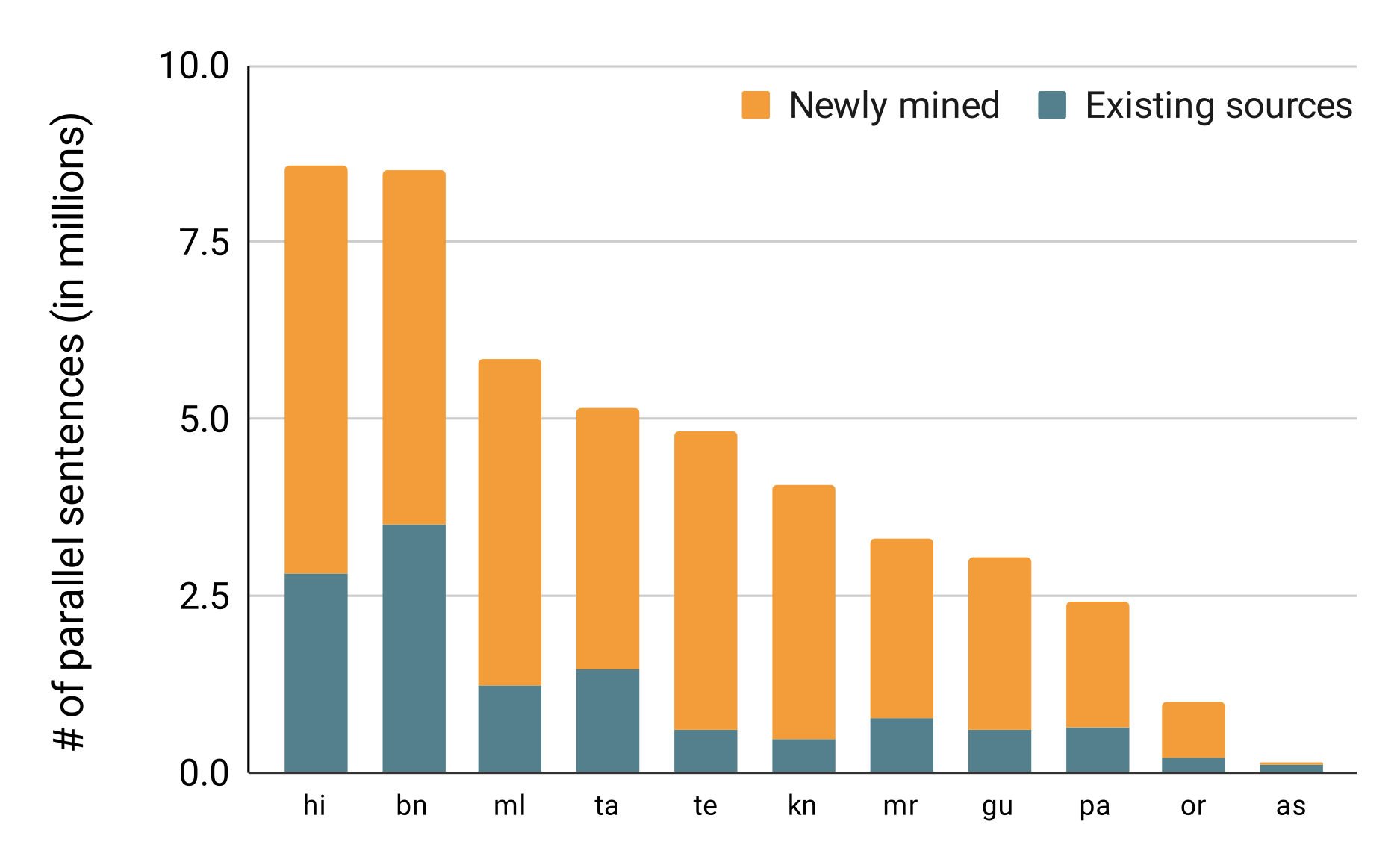
75M parallel sentences, 15 languages
Jun'22
A joint model for Indic-Indic translation v2.0
Mar'23
Build swipe based keyboards for all 22 languages
Joint pre-trained models for 22 Indian languages
Sep'21
Dec'21
Mine and align speech-to-text parallel data for 22 Indian languages
ASR system for NPTEL videos
Dec'22
Dec'23
Speech interface for input tools
Build swipe based keyboards for all 22 languages
Build swipe based keyboards for all 22 languages
2021
2022
2023
2020
Dataset
Benchmark
Model
Tools
green = eco-friendly = efficient
v 1.0, 9B tokens, 12 languages
v 1.0, 2 languages
v 1.0, 46M sentences, 12 languages
v 2.0, 20B tokens, 15 languages
v 1.0, 22 languages
v 1.0, 22 languages
v 2.0, 75M sentences, 15 languages
v 3.0, 25B tokens, 22 languages
v 1.0, 2000 hours, 22 languages
v 1.0, 22 languages
v 3.0, 15 languages, green translation
green language model
v 2.0, 4000 hours, 22 languages, green ASR Models
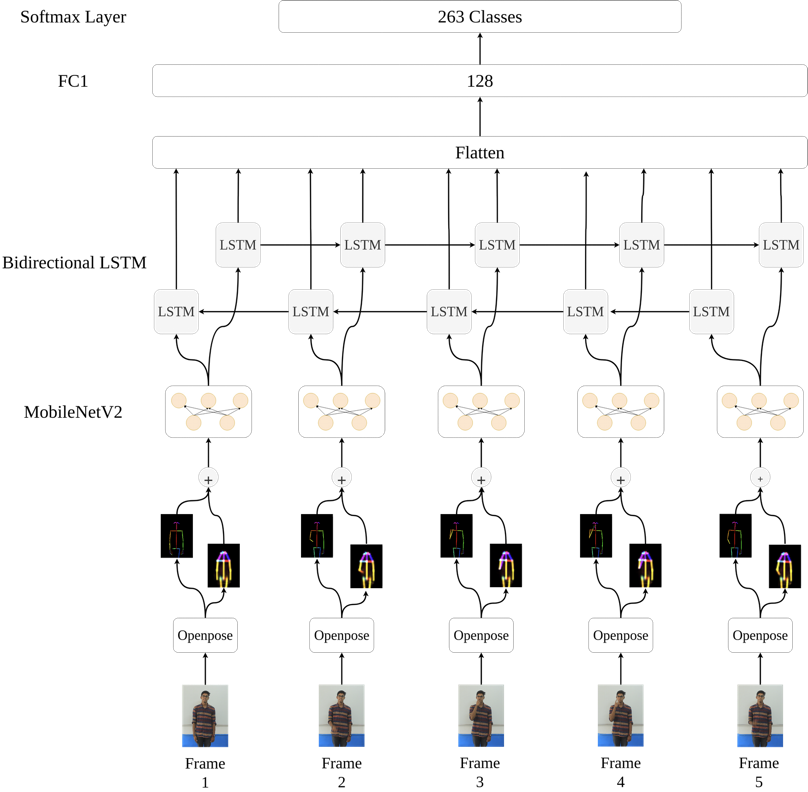
263 signs, 4000+ videos
swipe based keyboards, 22 languages
integration with video calling apps
Build swipe based keyboards for all 22 languages
By One Fourth Labs
The AI4Bharat Initiative




