








One Fourth Labs
We deliver courseware in AI and related areas
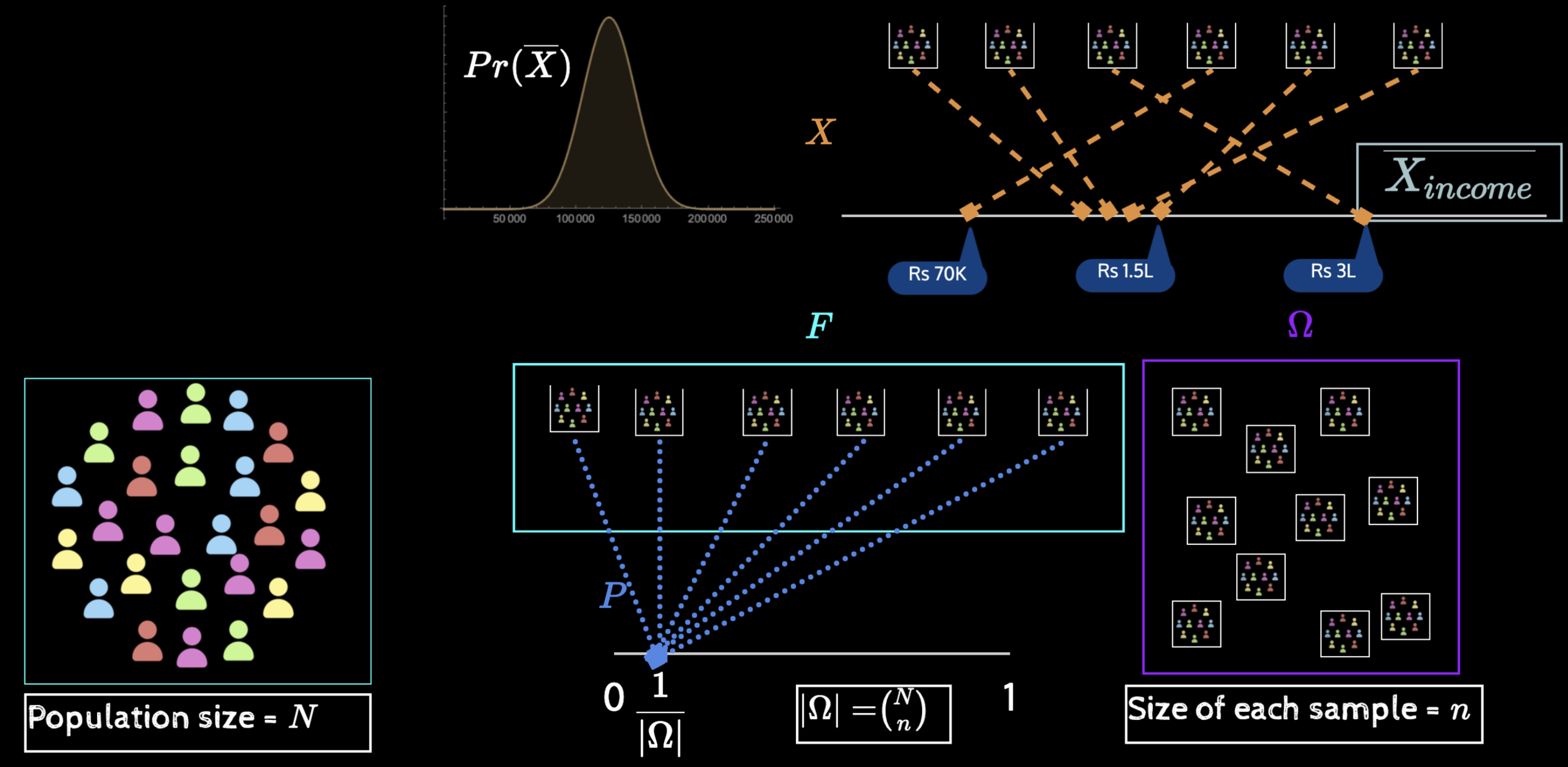
\(\mu_{income}, \sigma_{income}\)
\(\mu_{income}, \sigma_{income}\)
+
28
120
38
27
111
2
53
85
18
72.5
74.5
73
74
72
73.5
74
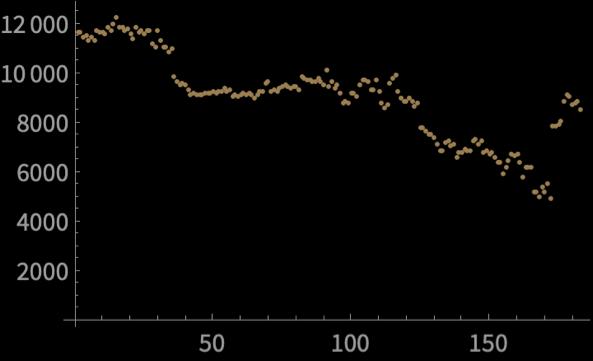
Source: StackOverflow
28
120
38
27
111
2
53
85
18
Observed data
Rule or function
Estimator
Value
Estimate
Population parameter
28
120
38
27
111
2
53
85
18
Observed data
52
36
81
152
50
98
5
97
15
83
4
Rule or function
Estimator
Value
Estimate
Population parameter
0
1
2
-4
-3
-2
-1
3
4
0
1
2
-4
-3
-2
-1
3
4
0
1
2
-4
-3
-2
-1
3
4
0
1
2
-4
-3
-2
-1
3
4
0
1
2
-4
-3
-2
-1
3
4
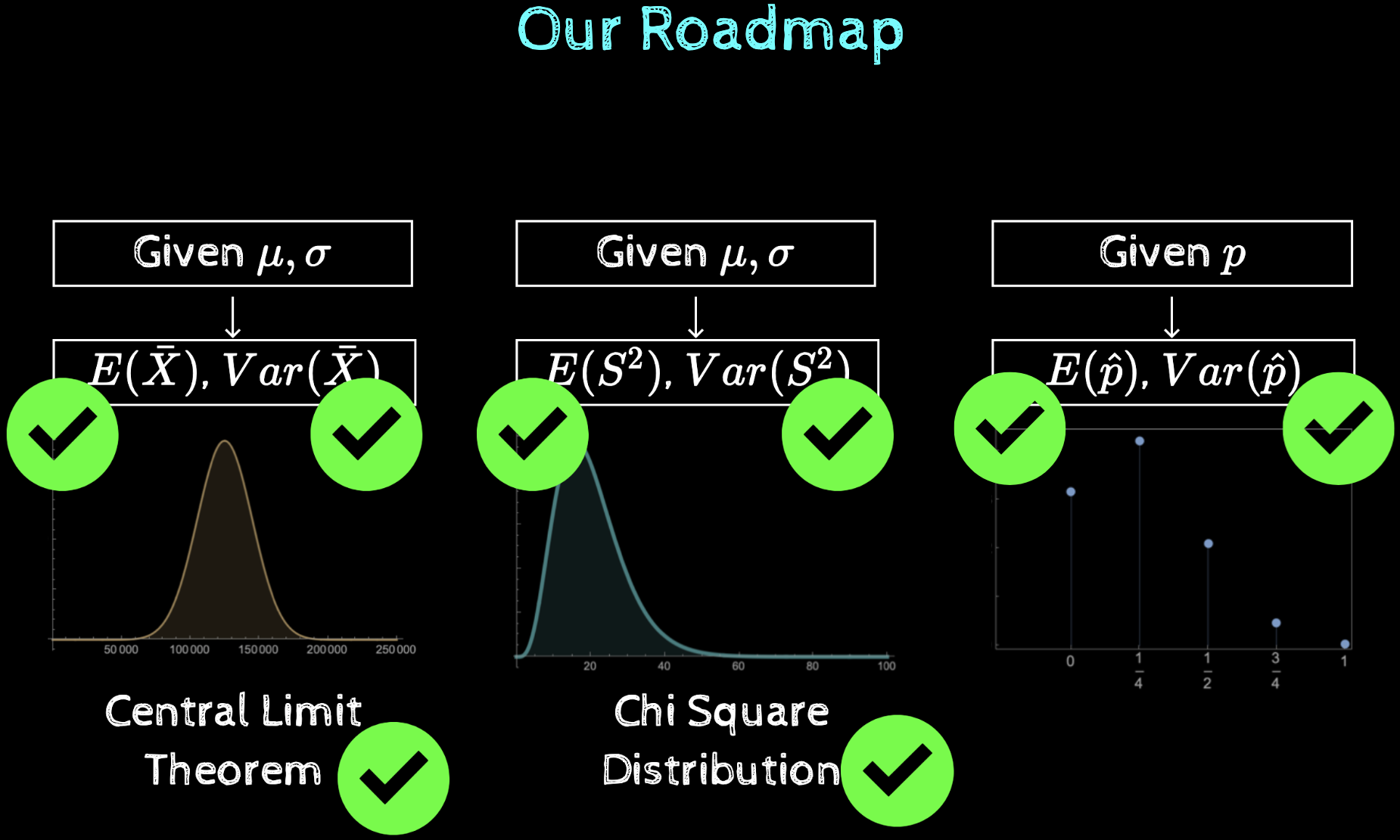
\(\mathbb{E}[\overline{X}] = \mu\)
\(\mathbb{E}[\hat{p}] = p\)
\(\mathbb{E}[S^2_{n - 1}] = \sigma^2\)
\(\mathrm{sd}(\overline{X}) = \frac{\sigma}{\sqrt{n}}\)
\(\mathrm{sd}(\hat{p}) = \sqrt{\frac{p(1-p)}{n}}\)
\(\mathrm{sd}(S^2_{n - 1}) = \frac{\sqrt{2}\sigma^2}{\sqrt{n}}\)
\(\mathbb{E}[\overline{X}] = \mu\)
\(\mathrm{sd}(\overline{X}) = \frac{\sigma}{\sqrt{n}}\)
\(\mathbb{E}[\overline{X}] = \mu\)
\(\mathrm{sd}(\overline{X}) = \frac{\sigma}{\sqrt{n}}\)
\(\mathbb{E}[\overline{X}] = \mu\)
\(\mathrm{sd}(\overline{X}) = \frac{\sigma}{\sqrt{n}}\)
\(\mathbb{E}[\hat{p}] = p\)
\(\mathrm{sd}(\hat{p}) = \sqrt{\frac{p(1-p)}{n}}\)
\(\mathbb{E}[\hat{p}] = p\)
\(\mathrm{sd}(\hat{p}) = \sqrt{\frac{p(1-p)}{n}}\)
\(\mathbb{E}[\hat{p}] = p\)
\(\mathrm{sd}(\hat{p}) = \sqrt{\frac{p(1-p)}{n}}\)
\(\mathrm{sd}(\hat{p}) < \sqrt{\frac{0.5(1-0.5)}{n}} = \frac{1}{2\sqrt{n}}\)
\(\mathbb{E}[\hat{p}] = p\)
\(\mathrm{sd}(\hat{p}) = \sqrt{\frac{p(1-p)}{n}}\)
\(\mathrm{sd}(\hat{p}) < \sqrt{\frac{0.5(1-0.5)}{n}} = \frac{1}{2\sqrt{n}}\)
\(\frac{1}{2\sqrt{n}} = 0.05 \Rightarrow n = 100 \)
\(\mathbb{E}[\hat{p}] = p\)
\(\mathrm{sd}(\hat{p}) = \sqrt{\frac{p(1-p)}{n}}\)
\(\mathrm{sd}(\hat{p}) < \sqrt{\frac{0.5(1-0.5)}{n}} = \frac{1}{2\sqrt{n}}\)
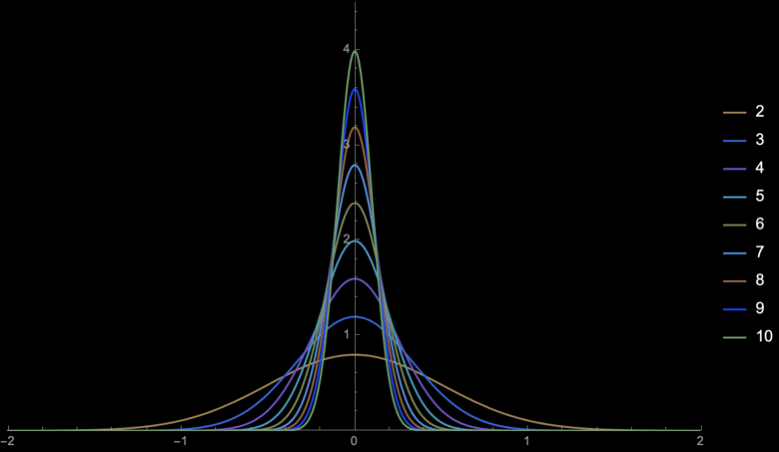
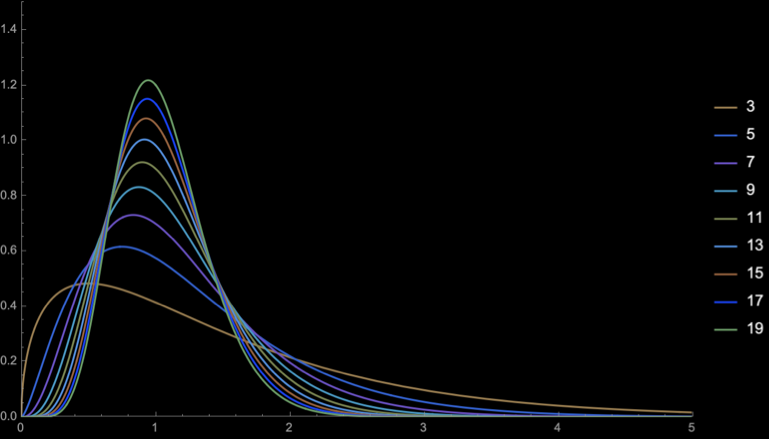
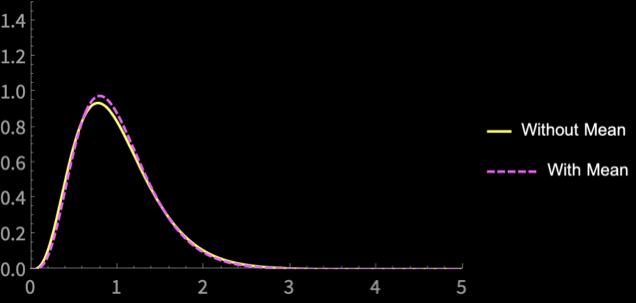
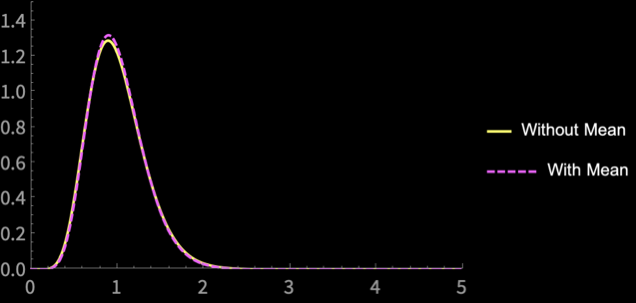
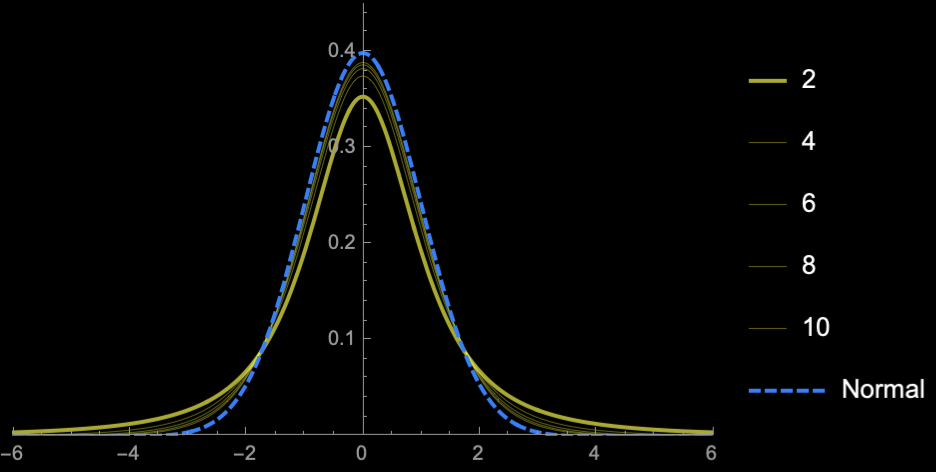
\(\mathbb{E}[S^2_{n - 1}] = \sigma^2\)
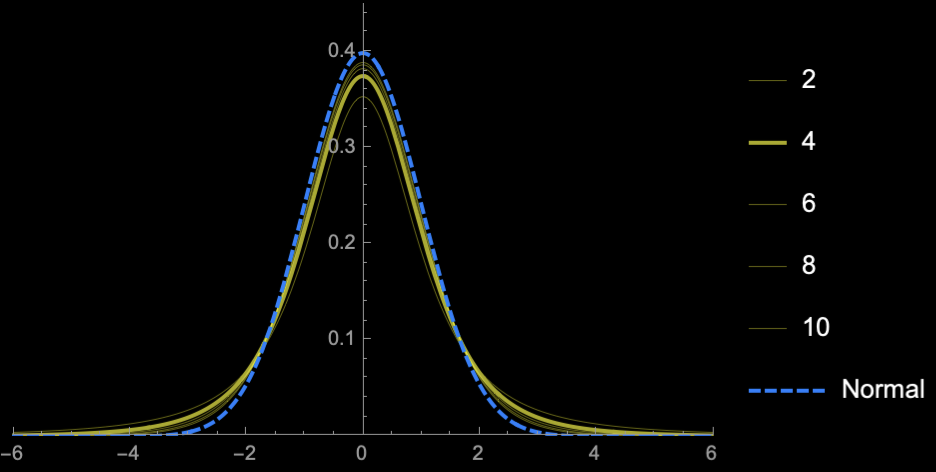
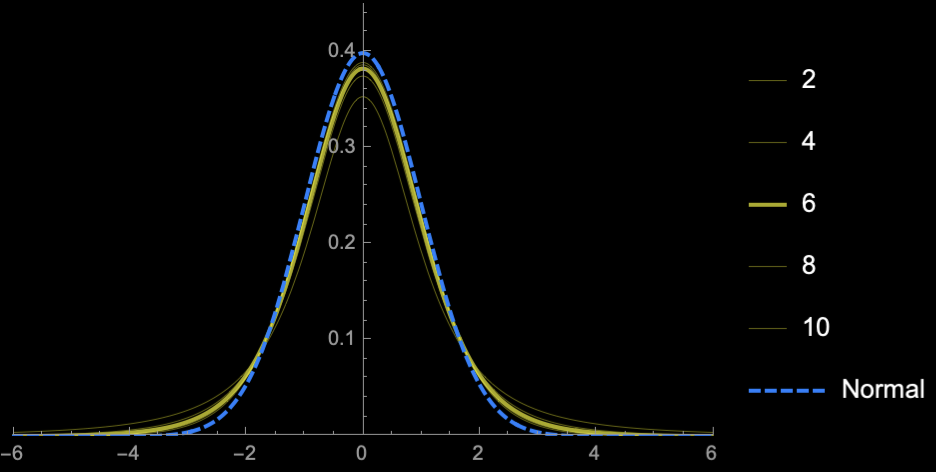
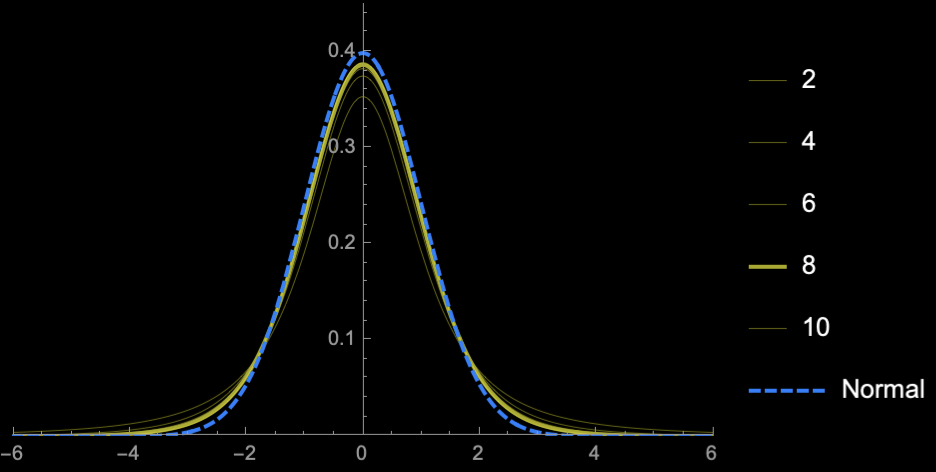
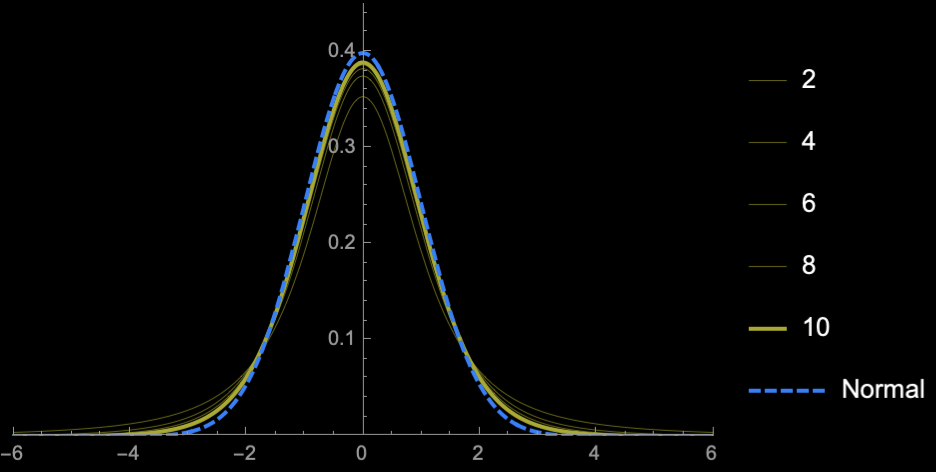
\(\mathrm{sd}(S^2_{n - 1}) = \frac{\sqrt{2}\sigma^2}{\sqrt{n}}\)
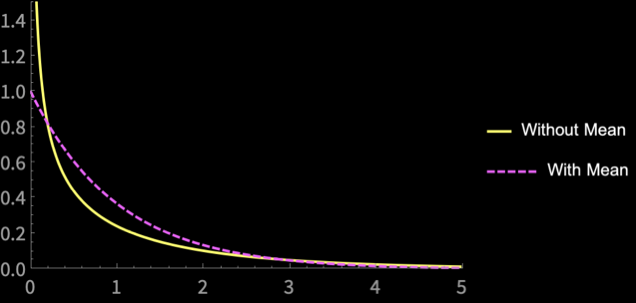
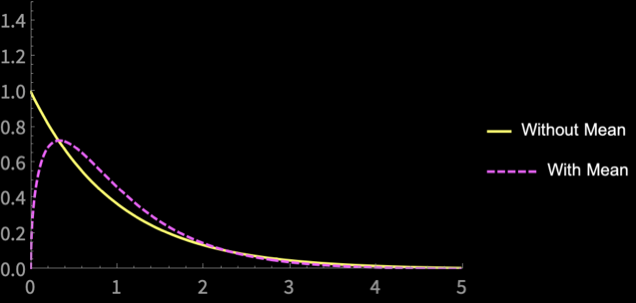
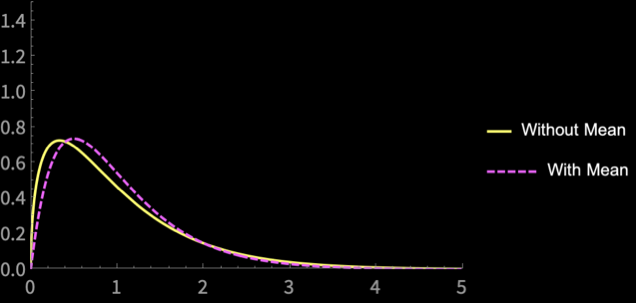
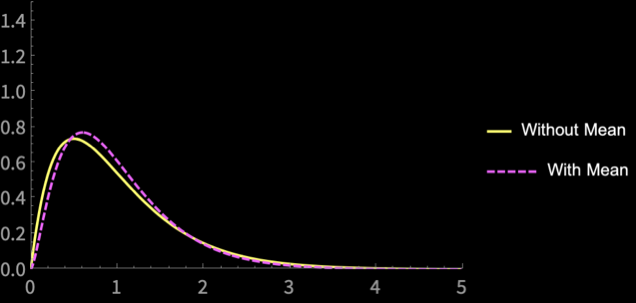
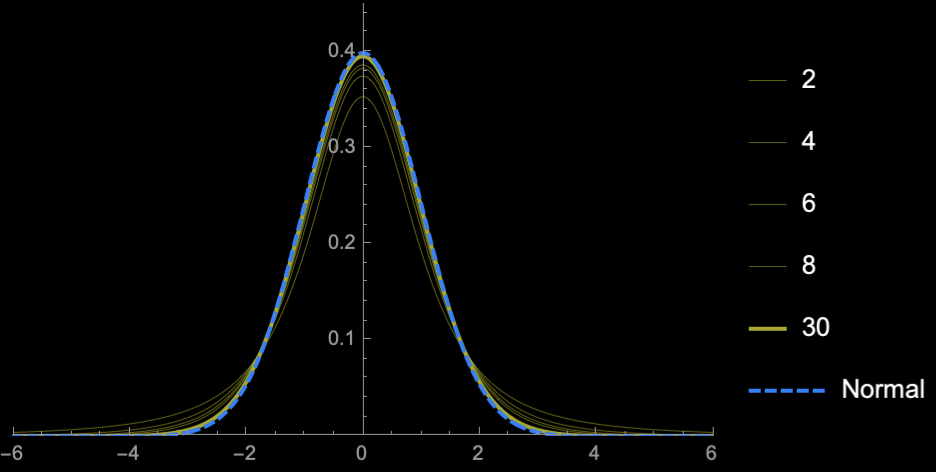
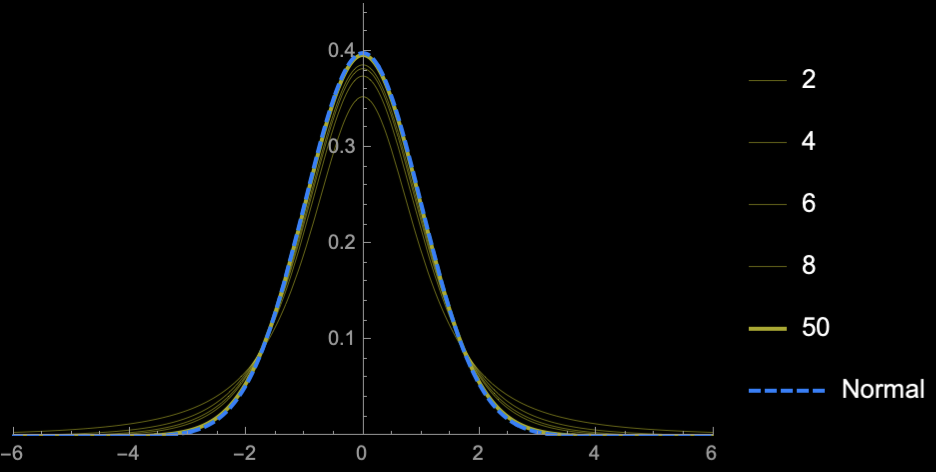
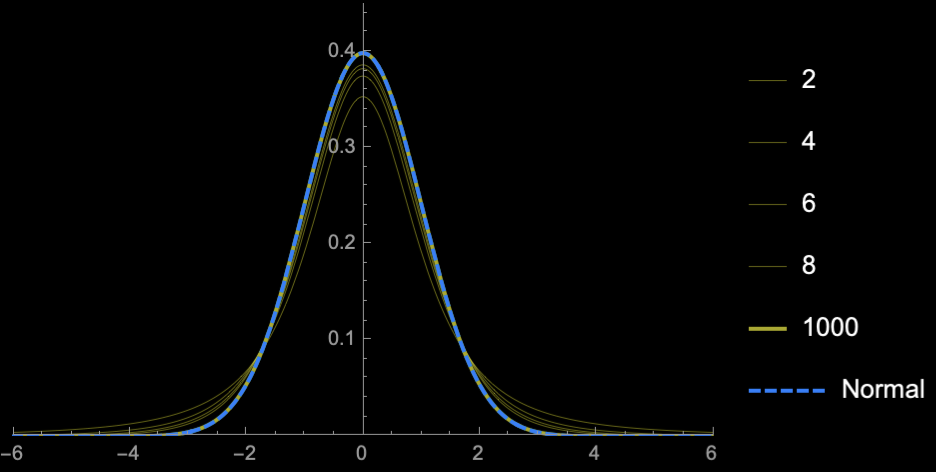
\(n = 2\)
\(n = 3\)
\(n = 4\)
\(n = 5\)
\(n = 10\)
\(n = 20\)
0
1
2
-4
-3
-2
-1
3
4
0
1
2
-4
-3
-2
-1
3
4
\(\overline{X}\)
\(\overline{X} + \frac{\sigma}{\sqrt{n}}\)
\(\overline{X} - \frac{\sigma}{\sqrt{n}}\)
\(\overline{X}\)
\(\overline{X} + \delta\)
\(\overline{X} - \delta\)
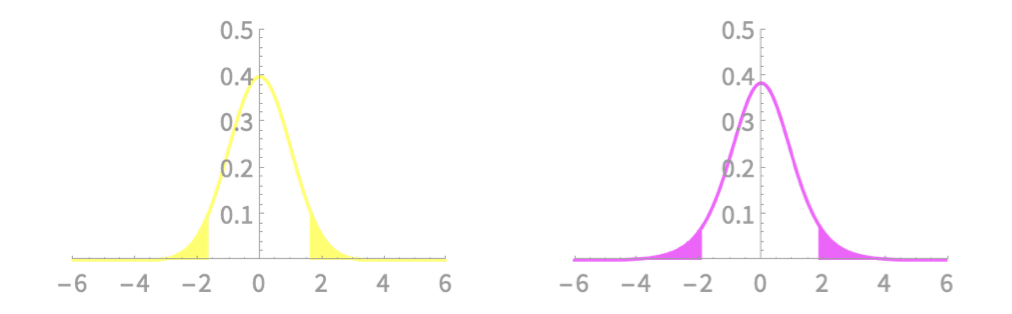
\(\frac{-I}{2}\)
\(\frac{I}{2}\)
\(\frac{-I}{2}\)
\(\frac{I}{2}\)
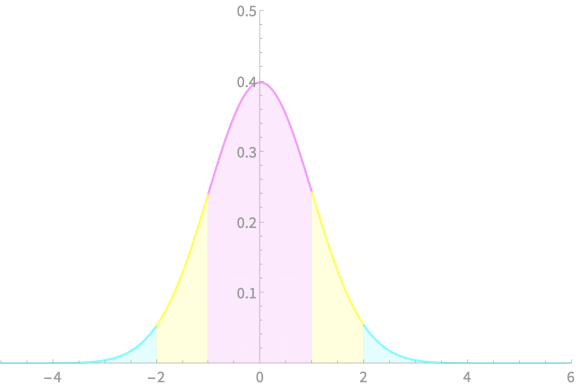
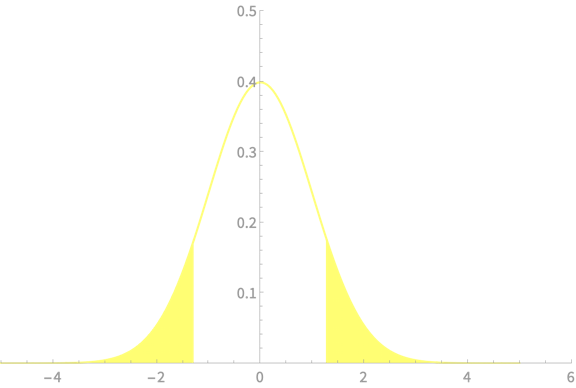
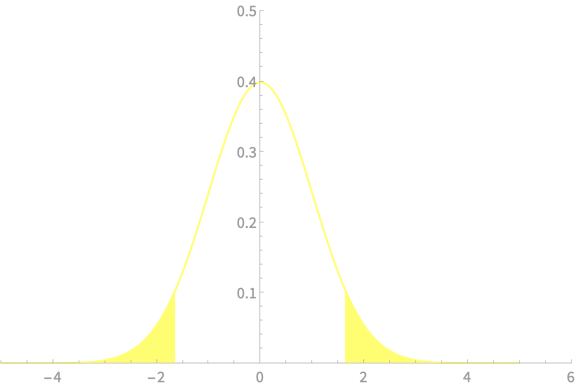
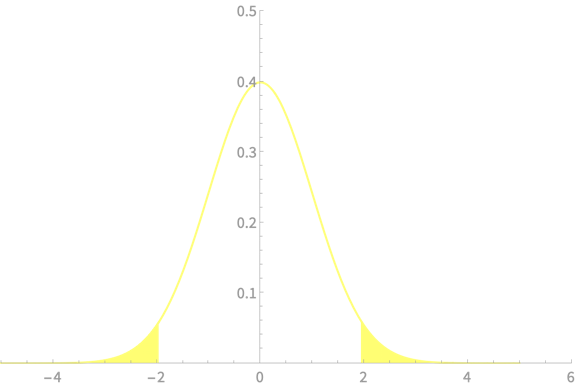
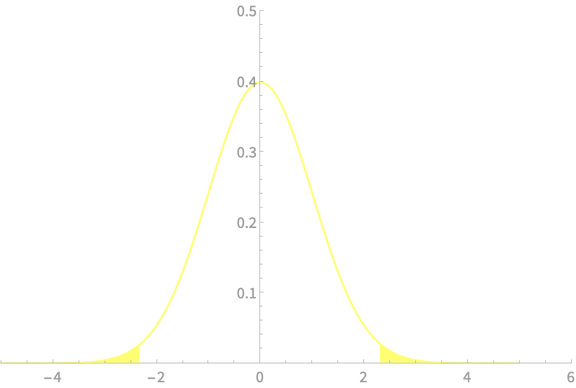
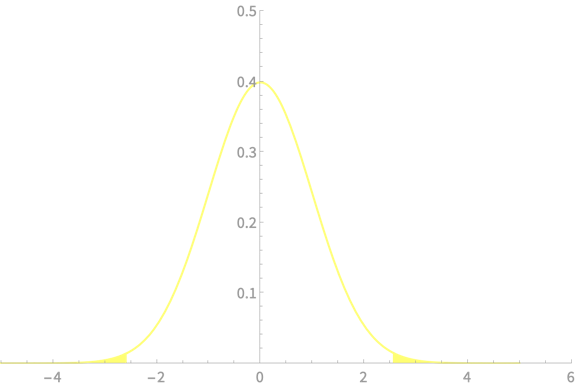
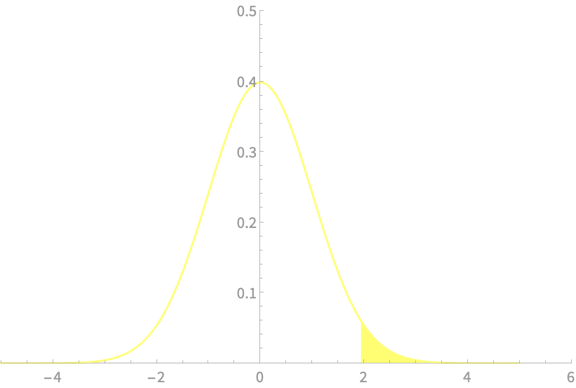
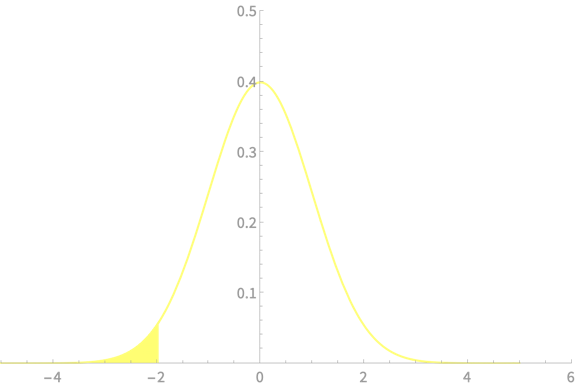
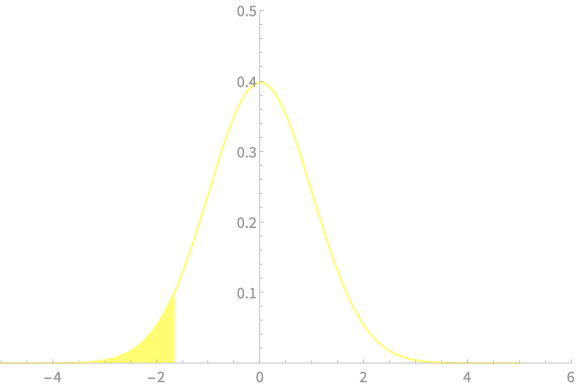
\(-z_{\alpha/2}\)
\(z_{\alpha/2}\)
\(\alpha = 0.2\)
\(z_{\alpha/2} = 1.28\)
\(\alpha = 0.1\)
\(z_{\alpha/2} = 1.65\)
\(\alpha = 0.05\)
\(z_{\alpha/2} = 1.96\)
\(\alpha = 0.02\)
\(z_{\alpha/2} = 2.33\)
\(\alpha = 0.01\)
\(z_{\alpha/2} = 2.58\)
\(\alpha = 0.01\)
\(z_{\alpha/2} = 2.58\)
\(\mu\)
\(\alpha = 0.01\)
\(z_{\alpha/2} = 2.58\)
\(\mu\)
\(\alpha = 0.9, \sigma = 1, n = 25\)
\(\mu < \overline{X} + 0.33\)
\(\overline{X} - 0.39 < \mu < \overline{X} +0.39\)
25, 28, 24, 29, 33, 36, 31, 45, 50, 36, 29, 33, 24, 24, 18, 24, 20, 25, 23, 27, 35
25, 28, 24, 29, 33, 36, 31, 45, 50, 36, 29, 33, 24, 24, 18, 24, 20, 25, 23, 27, 35
\(t_{n-1,\alpha/2}\)
\(-t_{n-1,\alpha/2}\)
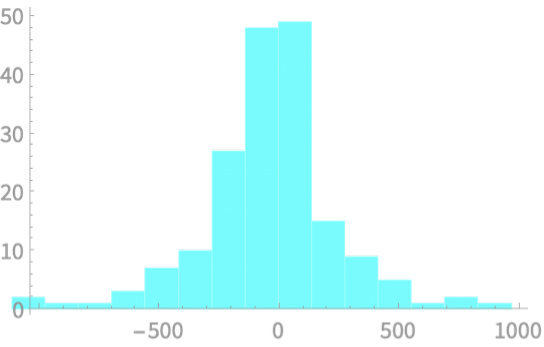
Stats secret:
I chose numbers with mean 100 and standard deviation 25
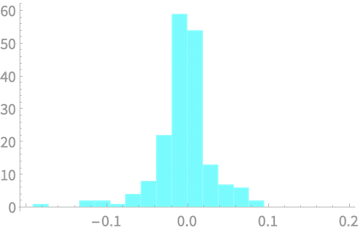
Stats secret:
I sampled from \(\mathcal{N}(0, 1)\)
Source: StackOverflow
By One Fourth Labs
PadhAI One: Distribution Sample Statistics - Part 2



