




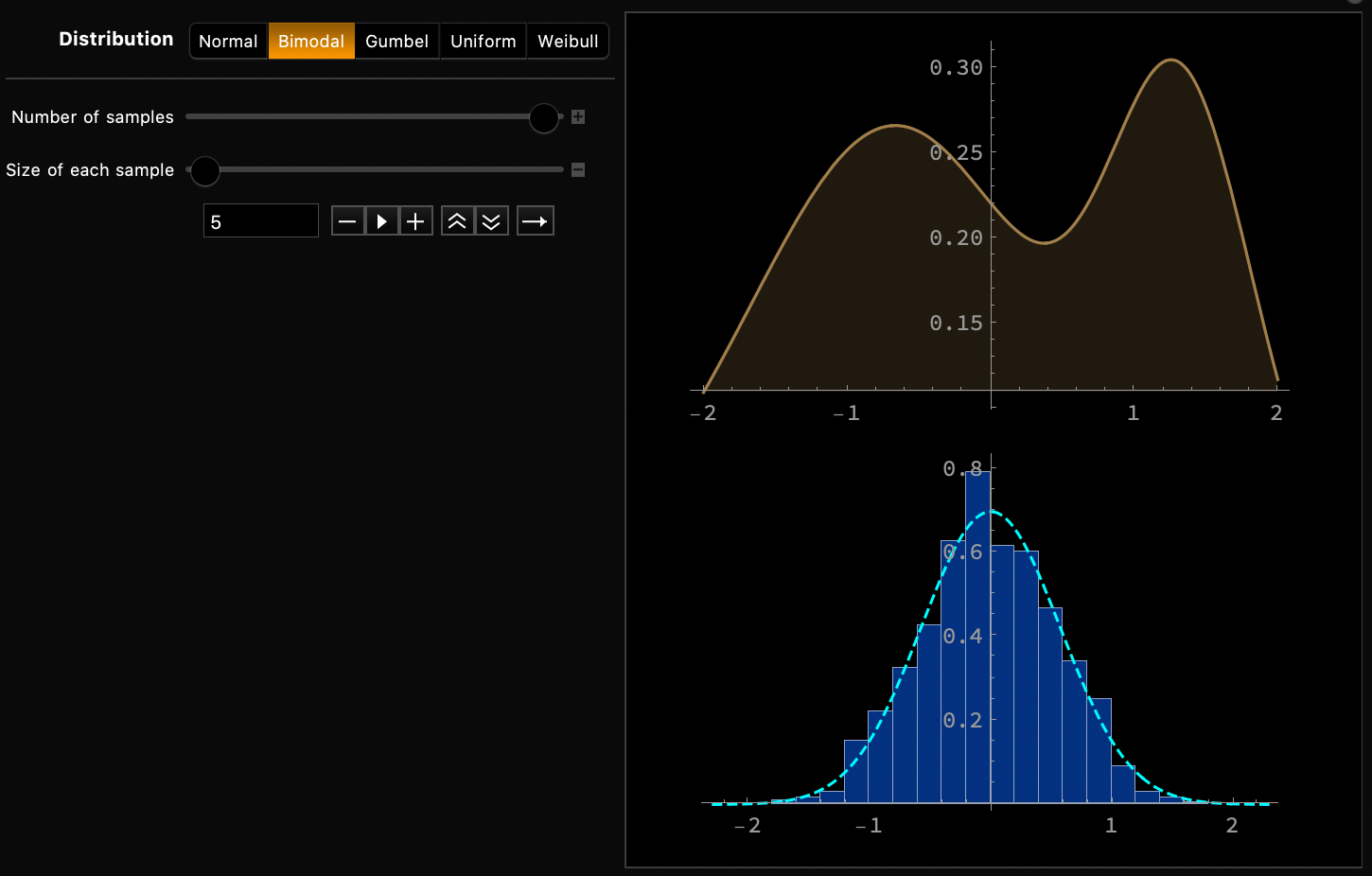











One Fourth Labs
We deliver courseware in AI and related areas
- C F Gauss
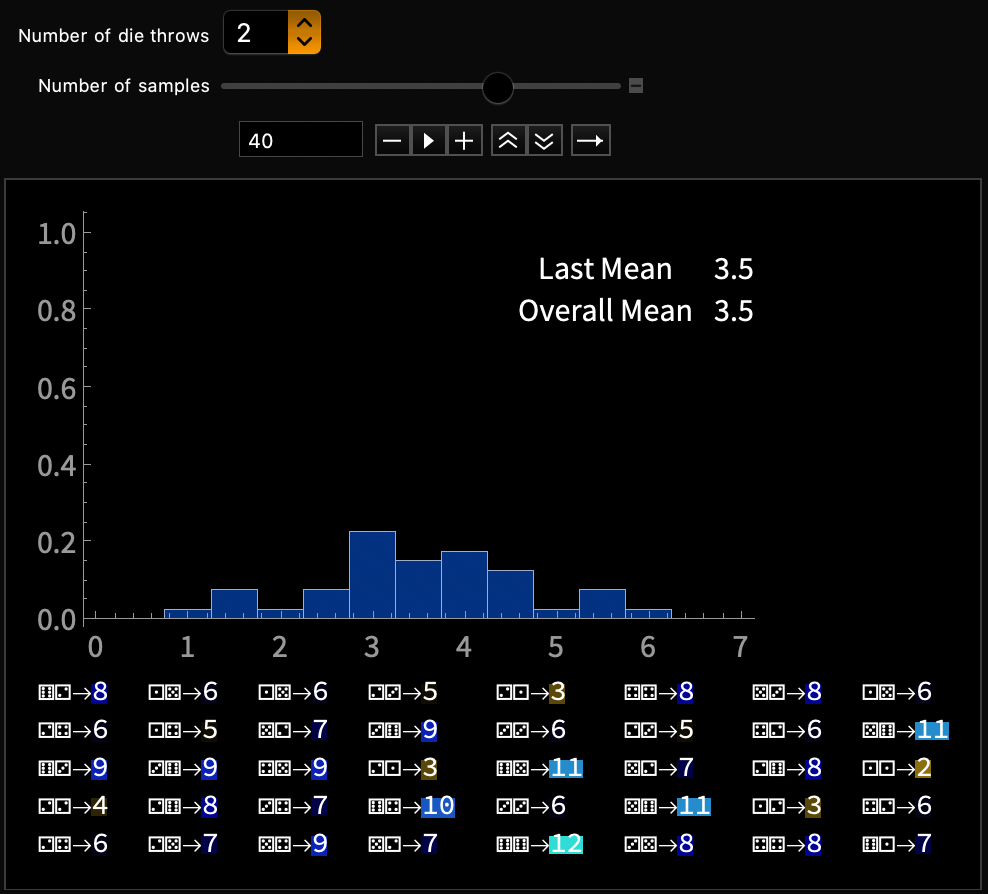
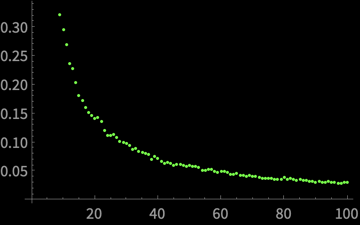
\(y \propto \frac{1}{x}\)
\(\mathrm{var}(\bar{X})\) falls inversely with \(n\)?
\(\mathrm{var}(\bar{X})\) is independent of \(\mu\)?
\(y \propto x^2\)
\(\mathrm{var}(\bar{X})\) is independent of \(\mu\)?
\(\mathrm{var}(\overline{X})\) scales as \(\sigma^2\)?
\(\mathrm{var}(\bar{X})\) is independent of \(\mu\)?
\(\mathrm{var}(\overline{X})\) scales as \(\sigma^2\)?
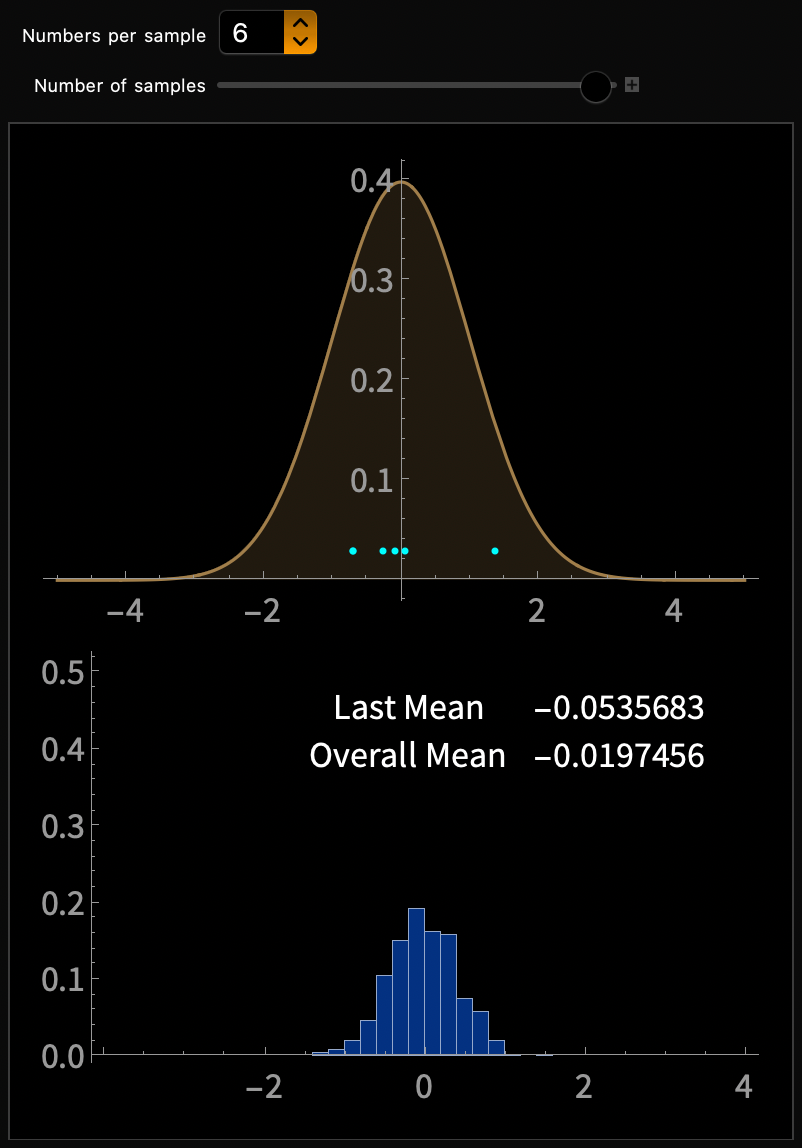
\(\mathcal{N}(0, 1/\sqrt{3})\)
\(\mathrm{Uniform}(-1, 1)\)
\(\mu = 0, \sigma = 1/\sqrt{3}\)
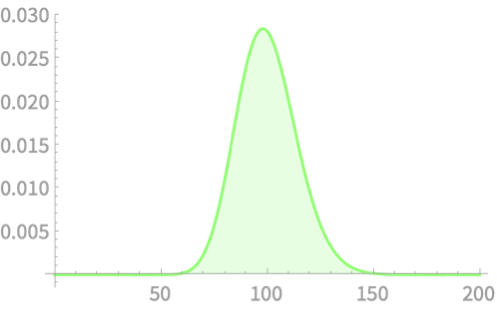
PDF(\(X\))
PDF(\(\overline{X}\))
| x | -3 | -0.5 | 0 | 0.5 | 3 |
| z |
| x | -3 | -0.5 | 0 | 0.5 | 3 |
| z | -3 | -0.5 | 0 | 0.5 | 3 |
| x | -3 | -0.5 | 0 | 0.5 | 3 |
| z |
| x | -3 | -0.5 | 0 | 0.5 | 3 |
| z | -2 | -0.75 | -0.5 | -0.25 | 1 |
| x | -3 | -0.5 | 0 | 0.5 | 3 |
| z | -2 | -0.75 | -0.5 | -0.25 | 1 |
| x | -3 | -0.5 | 0 | 0.5 | 3 |
| z | -3 | -0.5 | 0 | 0.5 | 3 |
| x | -2 | -0.5 | 0 | 0.5 | 2 |
| z |
| x | -2 | -0.5 | 0 | 0.5 | 2 |
| z | -3.46 | -0.87 | 0 | 0.87 | 3.46 |
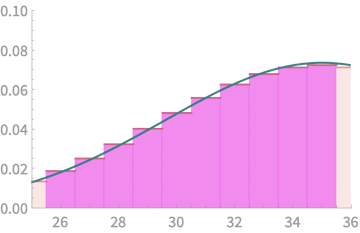
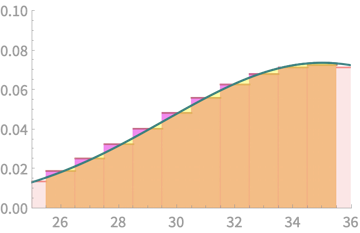
\(k = 10\)
\(0.058\)
\(0.054\)
\(k = 15\)
\(0.109\)
\(0.111\)
\(k = 18\)
\(0.061\)
\(0.065\)
\(X_1\)
\(X_2\)
\(X_3\)
\(X_4\)
\(X_1 + X_2\)
\(X_1 + X_2 + X_3\)
\(X_1 + X_2 + X_3 + X_4\)
\(X_1\)
\(X_2\)
\(X_3\)
\(X_4\)
\(X_1 + X_2\)
\(X_1 + X_2 + X_3\)
\(X_1 + X_2 + X_3 + X_4\)
\(\Omega\)
\(F\)
0
1
\(P\)
\(\dfrac{1}{|\Omega|}\)
0
1
\(P\)
\(\dfrac{1}{|\Omega|}\)
\(X\)
10 km
40 km
5 km
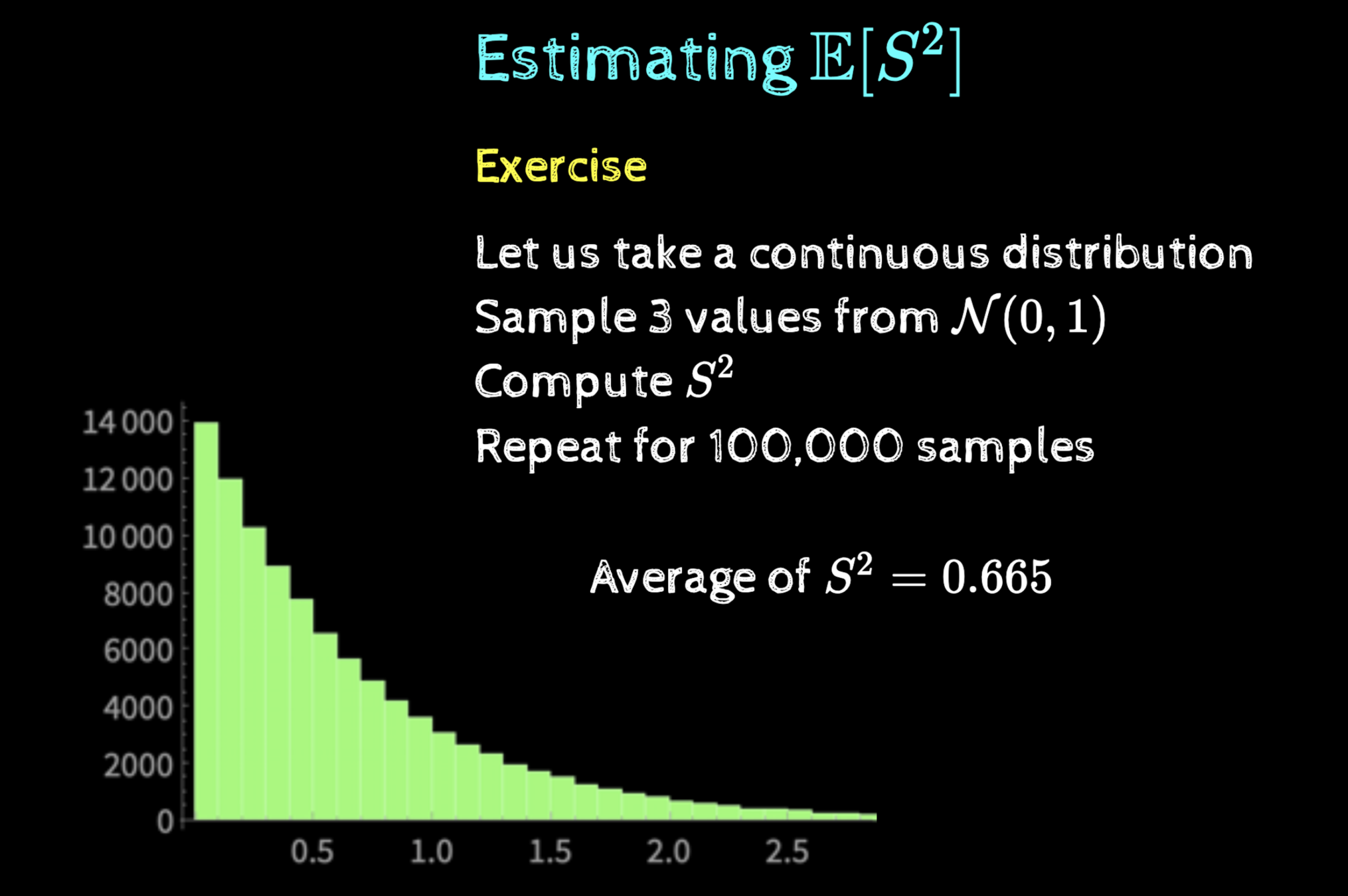
\(Pr(S^2_{mileage})\)
\(X = S^2\)
⚅⚃⚀
⚅⚃⚅
\(\overline{X} = \frac{11}{3}\)
⚀⚂⚂
\(\overline{X} = \frac{7}{3}\)
\(S^2 = \frac{8}{9}\)
\(S^2 = \frac{38}{9}\)
\(\overline{X} = \frac{16}{3}\)
\(S^2 = \frac{8}{9}\)
\(\mathbb{E}[S^2]\) \(= \mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \overline{X})^2}{n}\right]\)
\(\mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \mu)^2}{n}\right] = \) \(\sigma^2\)
\(\mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \mu)^2}{n}\right] = \) \(\sigma^2\)
1
2
3
4
5
6
⚀
⚂
⚃
\(\mathbb{E}[S^2]\) \(= \mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \overline{X})^2}{n}\right]\)
\(\mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \mu)^2}{n}\right] = \) \(\sigma^2\)
1
2
3
4
5
6
⚀
⚂
⚅
\(\mathbb{E}[S^2]\) \(= \mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \overline{X})^2}{n}\right]\)
\(\mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \mu)^2}{n}\right] = \) \(\sigma^2\)
1
2
3
4
5
6
⚀
⚀
⚁
\(\mathbb{E}[S^2]\) \(= \mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \overline{X})^2}{n}\right]\)
\(\mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \mu)^2}{n}\right] = \) \(\sigma^2\)
1
2
3
4
5
6
⚀
⚀
⚁
1
2
3
4
5
6
⚀
⚂
⚅
1
2
3
4
5
6
⚀
⚂
⚃
\(\mathbb{E}[S^2]\) \(= \mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \overline{X})^2}{n}\right]\)
\(\mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \mu)^2}{n}\right] = \) \(\sigma^2\)
\( \sum_{i=1}^n(X_i - \mu)^2\)
\( =\sum_{i=1}^n((X_i - \overline{X})+(\overline{X} - \mu))^2\)
\( =\sum_{i=1}^n((X_i - \overline{X})^2+(\overline{X} - \mu)^2 + 2(X_i - \overline{X})(\overline{X} - \mu))\)
\(0\)
\( =\sum_{i=1}^n(X_i - \overline{X})^2+ \sum_{i =1}^n(\overline{X} - \mu)^2\)
\(\mathbb{E}[S^2]\) \(= \mathbb{E}\left[\frac{\sum_{i = 1}^n(X_i - \overline{X})^2}{n}\right]\)
\(\mathbb{E}[\sigma^2 - S^2]\)
\( = \mathbb{E}[\frac{1}{n}\sum_{i=1}^n (X_i - \mu)^2 - \frac{1}{n} \sum_{i = 1}^n(X_i - \overline{X})^2]\)
\( = \mathbb{E}[\frac{1}{n}\sum_{i=1}^n ((X_i^2 -2X_i\mu + \mu^2) - (X_i^2 - 2X_i\overline{X} + \overline{X}^2))]\)
\( = \mathbb{E}[\frac{1}{n}\sum_{i=1}^n (\mu^2 - \overline{X}^2 + 2X_i(\overline{X}-\mu)]\)
\( = \mathbb{E}[\mu^2 - \overline{X}^2 +\frac{1}{n} \sum_{i = 1}^n 2X_i(\overline{X}-\mu)]\)
\( = \mathbb{E}[\mu^2 - \overline{X}^2 +2\overline{X}(\overline{X}-\mu)]\)
\( = \mathbb{E}[\mu^2 + \overline{X}^2 -2\overline{X}\mu]\)
\( = \mathbb{E}[(\overline{X} - \mu)^2]\)
\( = \mathrm{Var}(\overline{X})\)
\( = \frac{\sigma^2}{n}\)
\(\mathbb{E}[\sigma^2 - S^2]\)
\( = \frac{\sigma^2}{n}\)
\( = \frac{\sigma^2}{n}\)
\(\mathbb{E}[S^2] = \frac{n - 1}{n} \sigma^2\)
\(\mathbb{E}[S^2] = \frac{n - 1}{n} \sigma^2\)
\(\mathbb{E}[S^2_{n-1}] = \sigma^2\)
\(\mathbb{E}[S^2_{n}] = \frac{n - 1}{n}\sigma^2\)
\(\mathbb{E}[S^2_{n-1}] = \sigma^2\)
\(\mathbb{E}[S^2_{n}] = \frac{n - 1}{n}\sigma^2\)
\(S^2_{n}\) \(= \frac{\sum_{i = 1}^n (X_i - \overline{X})^2}{n}\)
\(S^2_{n-1}\) \(= \frac{\sum_{i = 1}^n (X_i - \overline{X})^2}{n-1}\)
\(S^2_{n}\) \(= \frac{\sum_{i = 1}^n (X_i - \overline{X})^2}{n}\)
\(S^2_{n-1}\) \(= \frac{\sum_{i = 1}^n (X_i - \overline{X})^2}{n-1}\)
\(S^2_{n}\) \(= \frac{\sum_{i = 1}^n (X_i - \overline{X})^2}{n}\)
\(S^2_{n-1}\) \(= \frac{\sum_{i = 1}^n (X_i - \overline{X})^2}{n-1}\)
\(0\)
\(Q\)
\(Q\)
\(Q\)
\(Q\)
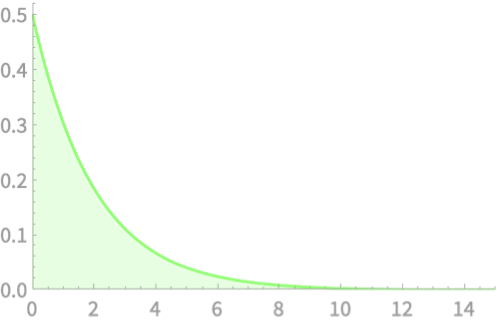
\(Q = Z_1^2\)
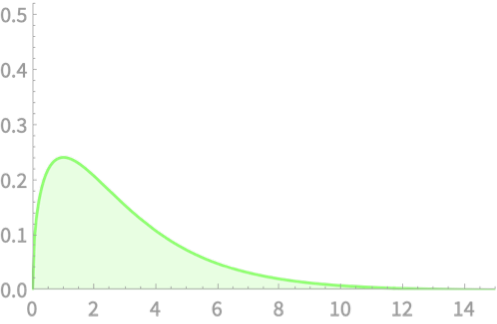
\(Q = Z_1^2 + Z_2^2\)
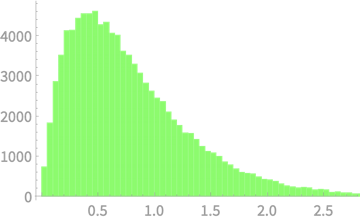
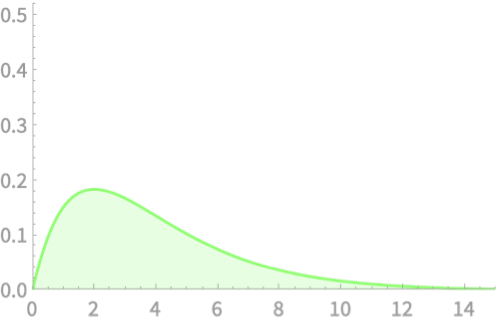
\(Q = Z_1^2 + Z_2^2 + Z_3^2\)
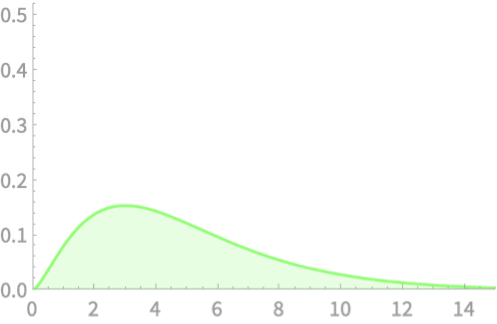
\(Q = Z_1^2 + Z_2^2 + Z_3^2 + Z_4^2\)
\(Q = Z_1^2 + Z_2^2 + Z_3^2 + Z_4^2 + Z_5^2\)
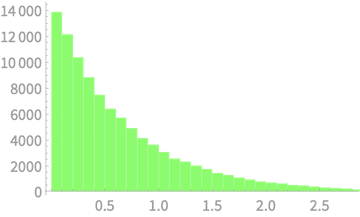
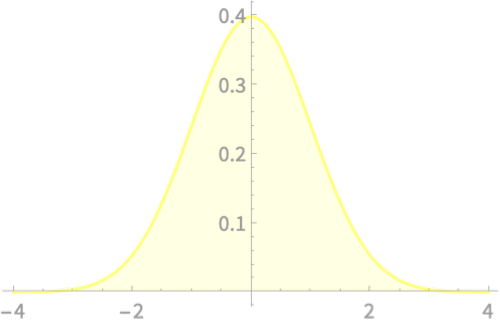
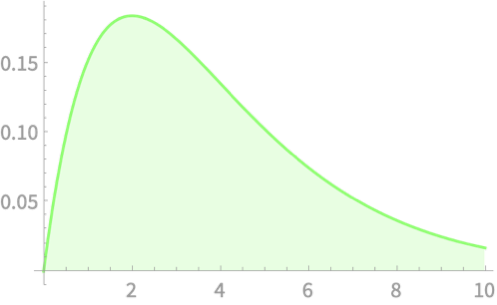
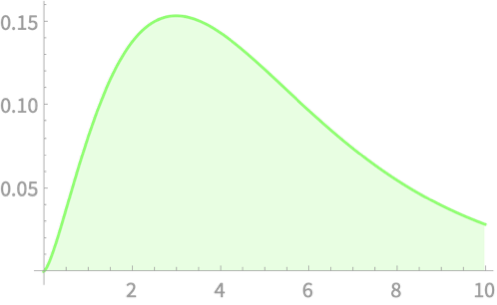
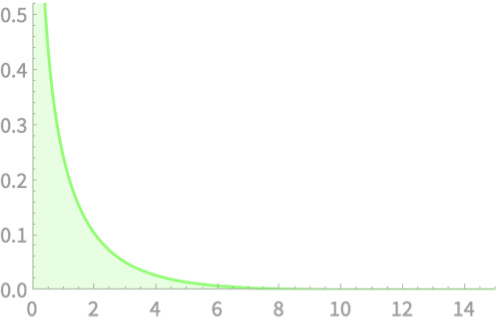
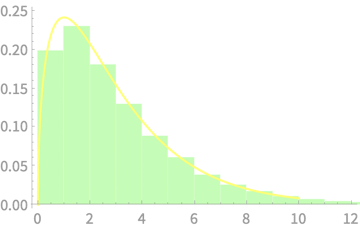
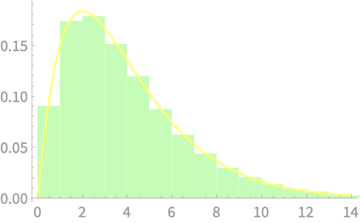
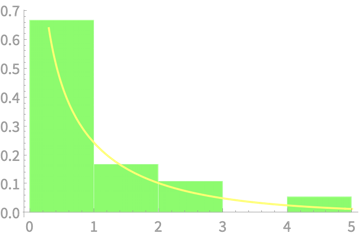
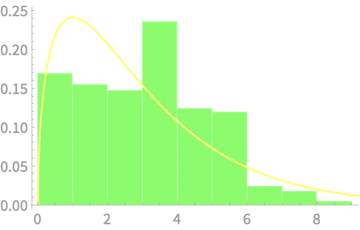
\(Q \sim \chi^2(1)\)
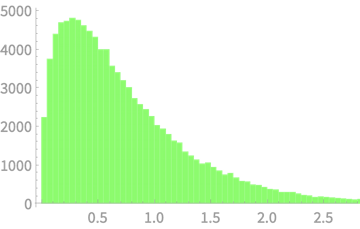
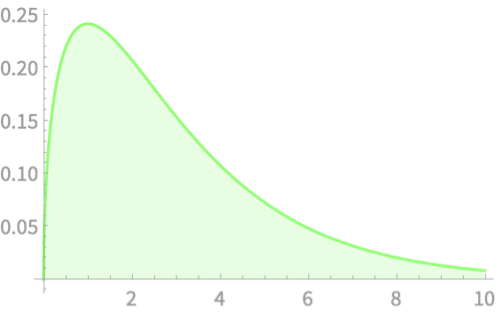
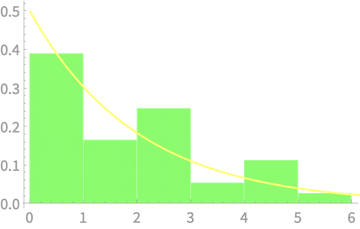
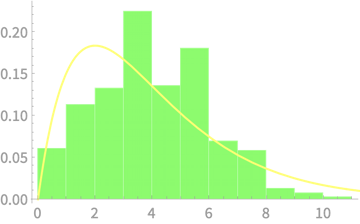
\(Q \sim \chi^2(2)\)
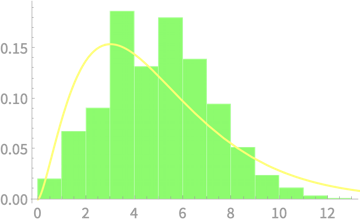
\(Q \sim \chi^2(3)\)
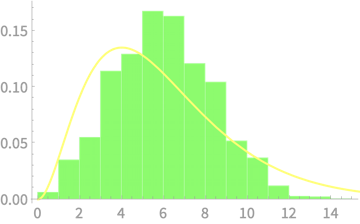
\(Q \sim \chi^2(4)\)
\(Q \sim \chi^2(5)\)
\(Q = Z_1^2 + Z_2^2 + Z_3^2 + Z_4^2\)
\(Q \sim \chi^2(4)\)
\(Q = Z_1^2\)
\(Q \sim \chi^2(1)\)
\(Q = Z_1^2 + Z_2^2\)
\(Q \sim \chi^2(2)\)
\(Q = Z_1^2 + Z_2^2\)
\(Q \sim \chi^2(2)\)
\(Q = Z_1^2\)
\(Q \sim \chi^2(1)\)
\(\sigma^2(Z^2) = \mathbb{E}[Z^4] - (\mathbb{E}[Z^2])^2\)
\(= 3 - 1 = 2\)
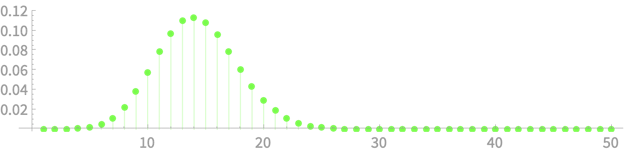
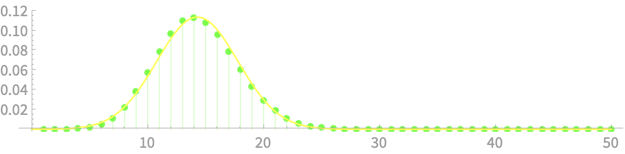
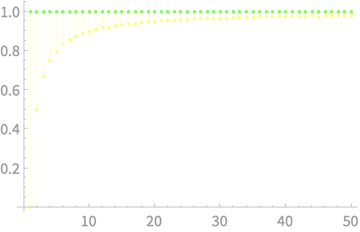
\(\sim \chi^2(n)\)
\(\sim \chi^2(1)\)
\(\sim \chi^2(n)\)
\(\sim \chi^2(1)\)
\(\sim \chi^2(n-1)\)
\(\mathrm{var}(aX) = a^2\mathrm{var}(X)\)
\(n = 2\)
\(n = 3\)
\(n = 4\)
\(n = 5\)
\(n = 7\)
\(n = 8\)
True
False
True
False
True
False
True
False
True
False
By One Fourth Labs
PadhAI One: Distribution Sample Statistics - Part 2



