










One Fourth Labs
We deliver courseware in AI and related areas
bad aesthetics
bad aesthetics
data of some 20 farms in one state or district such that one farm has a very high production and hence is an outlier (at least 10 times the production of the second maximum in the data)
replace the data in the table with the same data as on the previous slide
replace the data in the table with the same data as on the previous slide
fill in the values of xx, yy and zz
replace the data in the table with the same data as on the previous slide
fill in the values of xx, yy and zz
put a cross on the outlier
fragments: table, IQR, cross, L_75, highlight 15th element in the data, L_25, highlight 5th element in the data, IQr^new
1 2 3 4 5 6 7 8 9 10
the tables will have the following columns: x, x-x_bar, (x-x_bar)^2
the columns will appear one by one
framgments: one column at a time, quote
bad aesthetics
bad aesthetics
compute the values of xx and yy
bad aesthetics
bad aesthetics
1 2 3 4 5 6 7 8 9 10
We will have to change this example
In this example there is no data which is at +2,+3 or -2,-3 SD. Create a new example where there is some data at 2,3SD and -2,-3 SD and change the plot accordingly
Remember to divide by n-1 while computing the variance
for the data shown on slide 83 show a table showing the computation of z scores
The table will have two columns: x_i and z_i (give formula of z_i)
the mean and std. dev of the data at the bottom of the table
show a table with patient data containing 3 attributes: annual income (INR), weight (kg) and height (feet)
(a sample of 10 points)
write the range of each column below the column
Show an ML system which takes these 3 as inputs and predicts Health Risk/ No Risk (similar to a diagram that we used in one of the earlier lectures
| 2L | 65 | 5.8 |
| 5L | 60 | 5.5 |
| 10L | 75 | 6 |
| 8L | 70 | 5.3 |
| 4L | 54 | 5.2 |
| 7L | 60 | 5.3 |
| 1L | 50 | 5.3 |
| 20L | 72 | 6.2 |
| 7L | 82 | 6.1 |
| 3L | 67 | 5.9 |
Income (INR)
Height (Feet)
Weight (Kgs)
In addition to the table on the previous slide show a table where all the 3 columns are now in their standardised form
| 2L | 65 | 5.8 |
| 5L | 60 | 5.5 |
| 10L | 75 | 6 |
| 8L | 70 | 5.3 |
| 4L | 54 | 5.2 |
| 7L | 60 | 5.3 |
| 1L | 50 | 5.3 |
| 20L | 72 | 6.2 |
| 7L | 82 | 6.1 |
| 3L | 67 | 5.9 |
| -0.86 | -0.05 | 0.37 |
| -0.31 | -0.56 | -0.42 |
| 0.6 | 0.97 | 0.89 |
| 0.24 | 0.46 | -0.95 |
| -0.49 | -1.18 | -1.21 |
| 0.05 | -0.56 | -0.95 |
| -1.04 | -1.59 | -0.95 |
| 2.44 | 0.66 | 1.42 |
| 0.05 | 1.69 | 1.16 |
| -0.68 | 0.15 | 0.63 |
Income (INR)
Height (Feet)
Weight (Kgs)
Income (INR)
Height (Feet)
Weight (Kgs)
| -0.86 | -0.05 | 0.37 |
| -0.31 | -0.56 | -0.42 |
| 0.6 | 0.97 | 0.89 |
| 0.24 | 0.46 | -0.95 |
| -0.49 | -1.18 | -1.21 |
| 0.05 | -0.56 | -0.95 |
| -1.04 | -1.59 | -0.95 |
| 2.44 | 0.66 | 1.42 |
| 0.05 | 1.69 | 1.16 |
| -0.68 | 0.15 | 0.63 |
Income (INR)
Height (Feet)
Weight (Kgs)
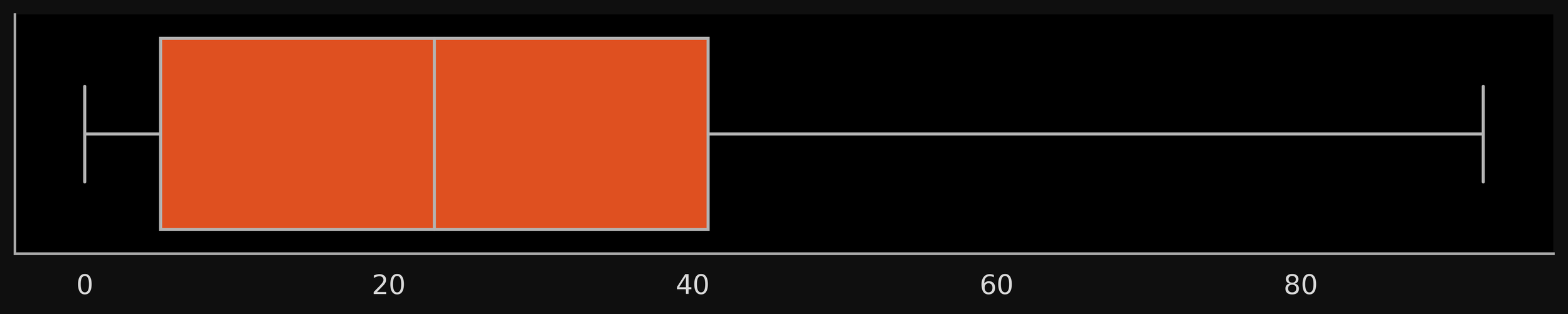
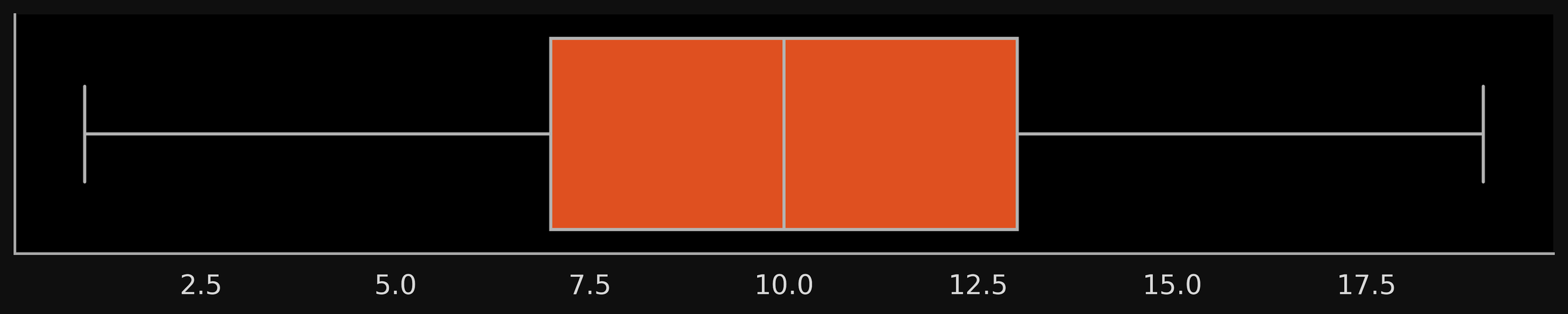
choose some data which has at least few outliers only on one side
plot corresponding to the data on the previous slide but matching the description of Variant1 in the gitbook
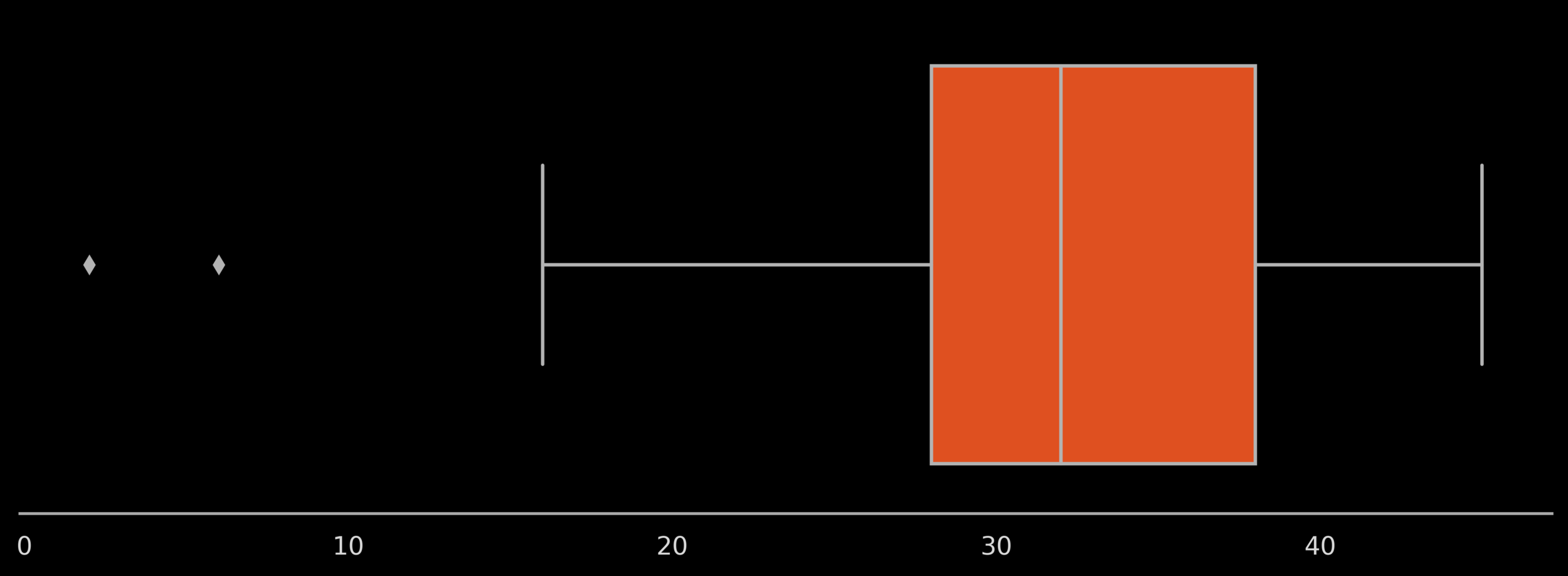
choose same data as previous slide
plot corresponding to the data on the previous slide but matching the description of Variant1 in the gitbook
also mark the 5 numbers on the plot
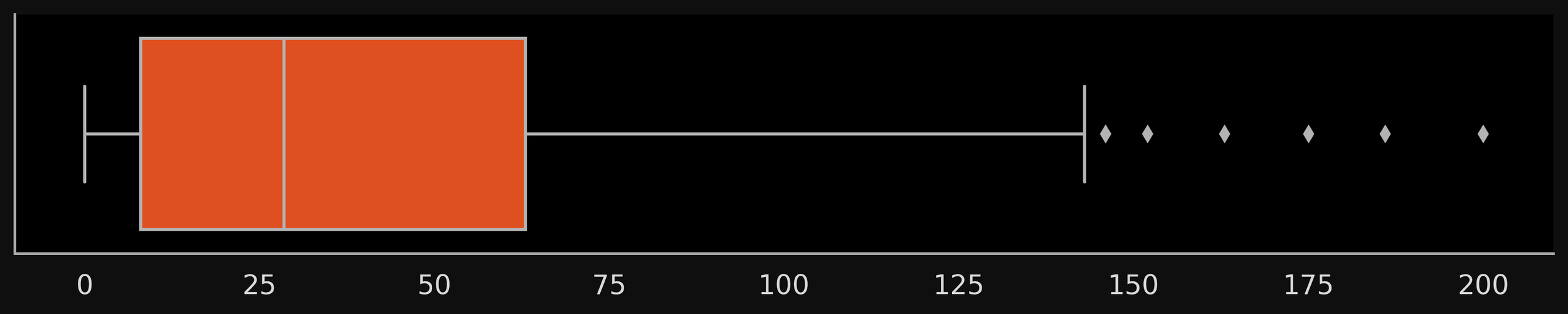
choose same data as previous slide
plot corresponding to the data on the previous slide but matching the description of Variant3 in the gitbook
show box plot for left-skewed, right-skewed and symmetric data
the position of the median should be clearly highlighted in the plot
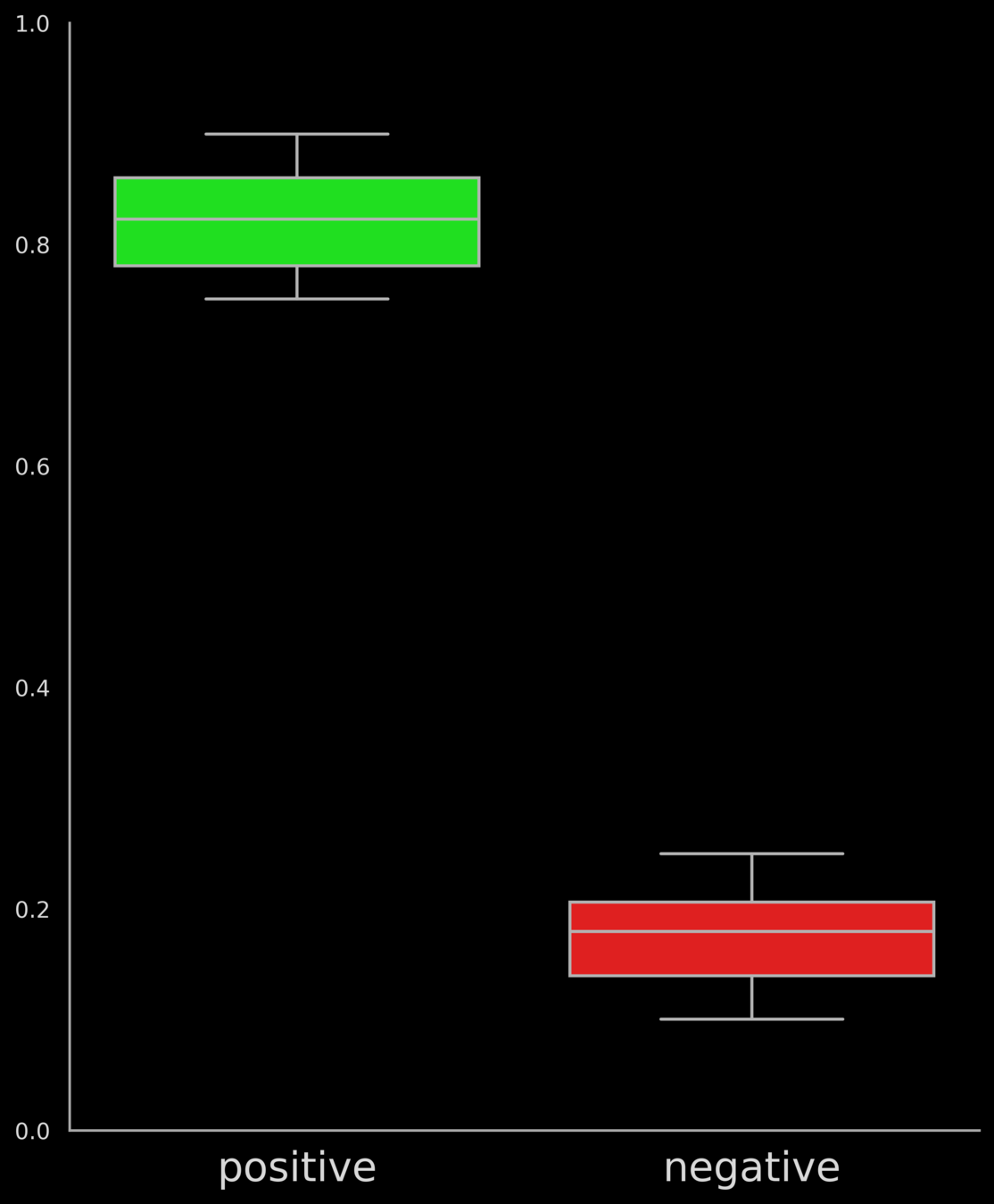
show ML system for distinguishing between positive and negative reviews (we had such a diagram in one of the earlier lectures)
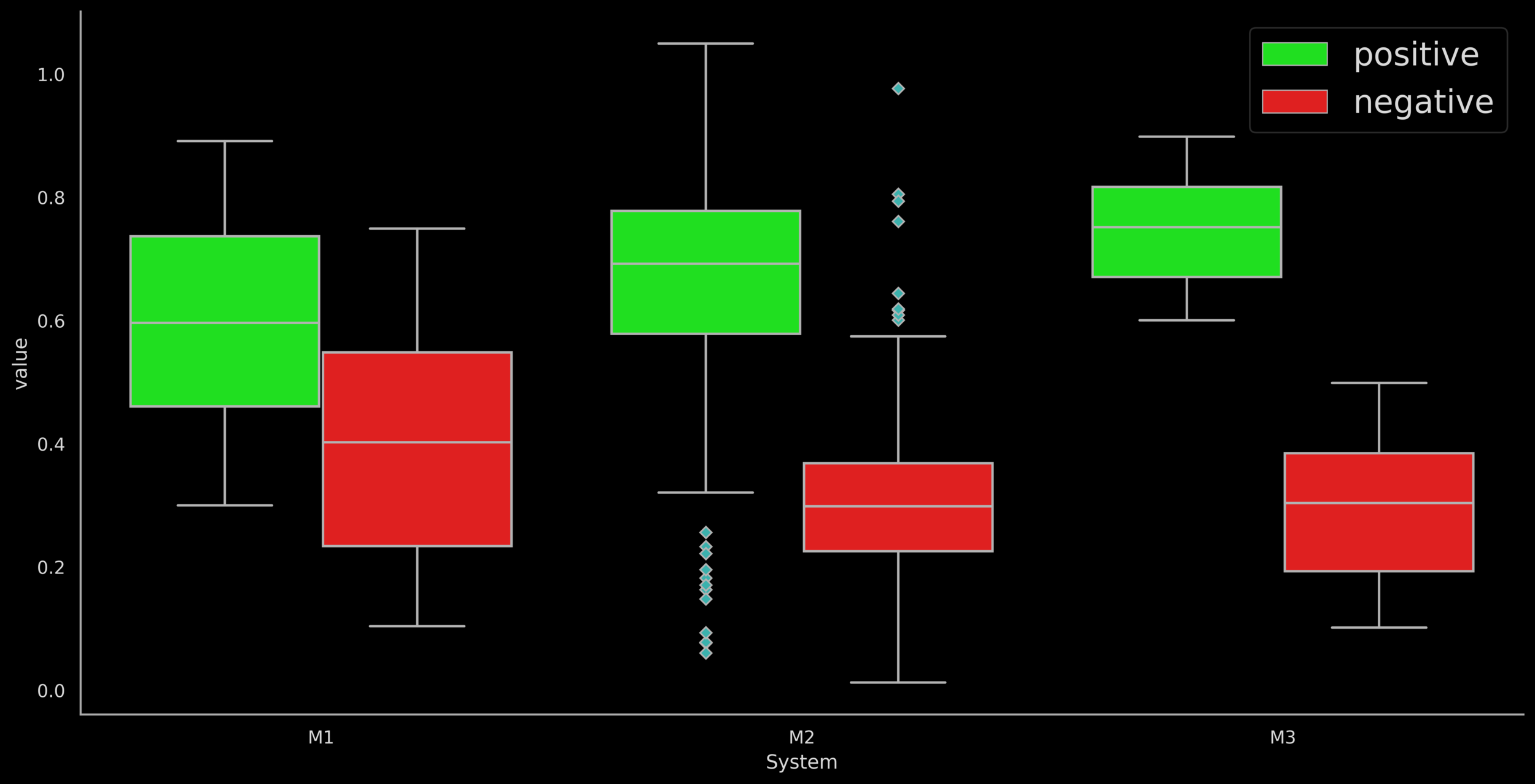
compare plots of five systems as given by Ananya
Ananya's notes: For comparing : (Please note that I have plotted for comparing 3 systems instead of 5 since I didn't have a description of M3 and M4 and felt adding those made the plot look more cluttered without much new information.)
| Age | Height | Weight | Cholesterol | Sugar level | .... ..... |
|---|---|---|---|---|---|
| 32 | 165 | 75 | 124 | 108 | ... |
| 24 | 172 | 81 | 112 | 98 | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| Age | Height | Weight | Cholesterol | Sugar level | .... ..... |
|---|---|---|---|---|---|
| 32 | 165 | 75 | 124 | 108 | ... |
| 24 | 172 | 81 | 112 | 98 | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| Age | Height | Weight | Cholesterol | Sugar level | .... ..... |
|---|---|---|---|---|---|
| 32 | 165 | 75 | 124 | 108 | ... |
| 24 | 172 | 81 | 112 | 98 | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
By One Fourth Labs
PadhAI One: FDS Week 3 (MK)



