
Penut Chen (PenutChen)
I love oppai!
\(Sa\check{s}a\ Petrovi\acute{c}\)
School of Informatics University of Edinburgh
sasa.petrovic@ed.ac.uk
\(David\ Matthews\)
School of Informatics University of Edinburgh
dave.matthews@ed.ac.uk
Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, pages 228–232, Sofia, Bulgaria, August 4-9 2013.
c © 2013 Association for Computational Linguistics
Typically considered to be a difficult NLP problem.
I like my men like I like my tea, hot and British.
I like X like I like Y, Z
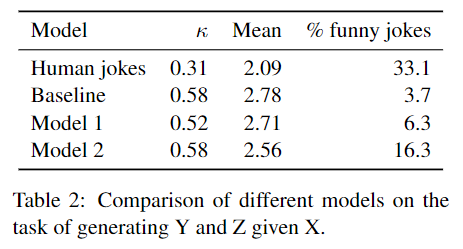
The first fully unsupervised humor generation system.
Double entendre identification using SVM classifier.
Sarcastic sentence identification
One-liner joke recognition
Dirty joke telling robots
Two-liner jokes
Punning riddles model
Equation 1
\(\phi(x,z)=p(x,z)=\frac{f(x,z)}{\Sigma_{x,z}f(x,z)}\)
Equation 2
\(\phi(z)=1/f(z)\)
Equation 3
\(\phi_2(z)=1/senses(z)\)
Equation 4
Equation 5
\(\phi(x,y)=1/sim(x,y)\)
\(sim(x,y)=\frac{\Sigma_zp(z|x)p(z|y)}{\sqrt{\Sigma_zp(z|x)^2*\Sigma_zp(z|y)^2}}\)
I like my relationships like I like my source, open.
I like my coffee like I like my war, cold.
I like my boys like I like my sectors, bad.
Table 3: Example jokes generated by Model 2.
By Penut Chen (PenutChen)




