Penut Chen (PenutChen)
I love oppai!
Jeffrey Pennington
Richard Socher
Christopher D. Manning
Computer Science Department, Stanford University
Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532-1543
October 25-29, 2014, Doha, Qatar. (C)2014 Association for Computational Linguistics
\(F(w_i,w_j,\tilde w_k)=\frac{P_{ik}}{P_{jk}}\)
(1)
\(F(w_i-w_j,\tilde w_k)=\frac{P_{ik}}{P_{jk}}\)
(2)
\(F((w_i-w_j)^T\tilde w_k)=\frac{P_{ik}}{P_{jk}}\)
(3)
\(F((w_i-w_j)^T\tilde w_k)=\frac{F(w^T_i\tilde w_k)}{F(w^T_j\tilde w_k)}\)
\(F(w_i^T\tilde w_k)=P_{ik}=\frac{X_{ik}}{X_i}\)
\(w_i^T\tilde w_k=log(P_{ik})=log(X_{ik})-log(X_i)\)
(4)
(5)
(6)
\(w_i^T\tilde w_k+b_i+\tilde b_k=log(X_{ik})\)
(7)
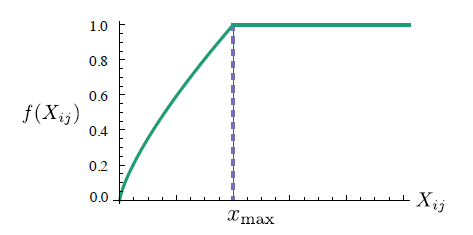
\(J=\sum_{i,j=1}^{V}f(X_{ij})(w_i^T\tilde w_j+b_i+\tilde b_j-logX_{ij})^2\)
(8)
| Model | Size | WS353 | MC | RG | SCWS | RW |
|---|---|---|---|---|---|---|
| SVD | 6B | 35.3 | 35.1 | 42.5 | 38.3 | 25.6 |
| SVD-S | 6B | 56.5 | 71.5 | 71.0 | 53.6 | 34.7 |
| SVD-L | 6B | 65.7 | 72.7 | 75.1 | 56.5 | 37.0 |
| CBOW | 6B | 57.2 | 65.6 | 68.2 | 57.0 | 32.5 |
| SG | 6B | 62.8 | 65.2 | 69.7 | 58.1 | 37.2 |
| GloVe | 6B | 65.8 | 72.7 | 77.8 | 53.9 | 38.1 |
| SVD-L | 42B | 74.0 | 76.4 | 74.1 | 58.3 | 39.9 |
| GloVe | 42B | 75.9 | 83.6 | 82.9 | 59.6 | 47.8 |
| CBOW | 100B | 68.4 | 79.6 | 75.4 | 59.4 | 45.5 |
| Model | Dev | Test | ACE | MUC7 |
|---|---|---|---|---|
| Discrete | 91.0 | 85.4 | 77.4 | 73.4 |
| SVD | 90.8 | 85.7 | 77.3 | 73.7 |
| SVD-S | 91.0 | 85.5 | 77.6 | 74.3 |
| SVD-L | 90.5 | 84.8 | 73.6 | 71.5 |
| HPCA | 92.6 | 88.7 | 81.7 | 80.7 |
| HSMN | 90.5 | 85.7 | 78.7 | 74.7 |
| CW | 92.2 | 87.4 | 81.7 | 80.2 |
| CBOW | 93.1 | 88.2 | 82.2 | 81.1 |
| GloVe | 93.2 | 88.3 | 82.9 | 82.2 |
By Penut Chen (PenutChen)




