
Penut Chen (PenutChen)
I love oppai!
Eunsol Choi
Omer Levy
Yejin Choi
Luke Zettlemoyer*
Paul G. Allen School of Computer Science & Engineering, University of Washington
*Allen Institute for Artificial Intelligence, Seattle WA
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers), pages 87-96
Melbourne, Australia, July 15-20, 2018. (C) 2018 Association for Computational Linguistics
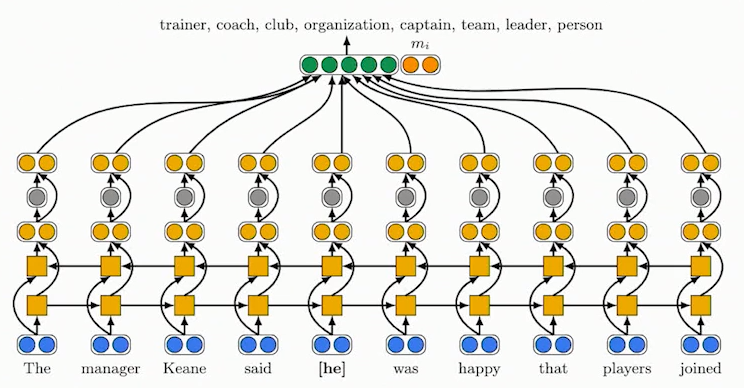
Bill robbed John. He was arrested.
By Penut Chen (PenutChen)




