
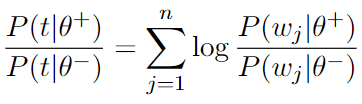
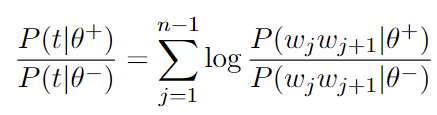
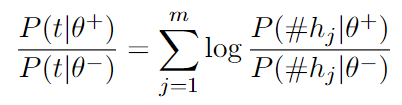

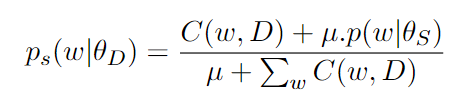
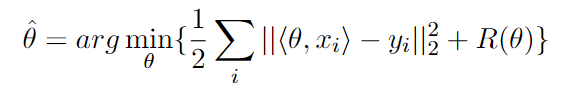
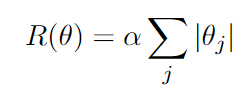
Penut Chen (PenutChen)
I love oppai!
Identifying Misinformation in Microblogs
Vahed Qazvinian
Emily Rosengren
Dragomir R. Radev
Qiaozhu Mei
University of Michigan
Ann Arbor, MI
{vahed,emirose,radev,qmei}@umich.edu
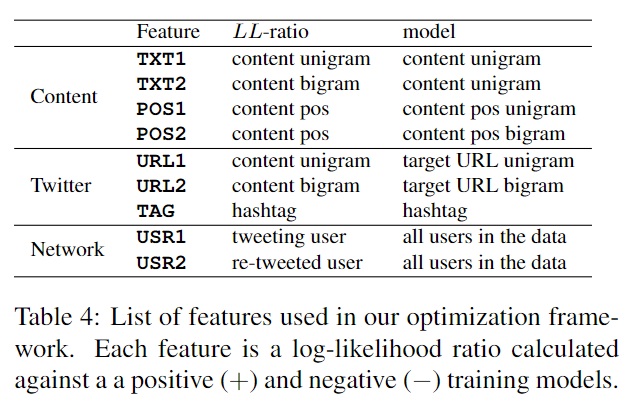
Unigram-Lexical Features (TXT1)
Bigram-Based Lexical Features (TXT2)
Using Bayesian smoothing with Dirichlet priors
\(\alpha\) is a parameter that controls the amount of regularization.
By Penut Chen (PenutChen)




