


Penut Chen (PenutChen)
I love oppai!
Ilya Sutskever
Oriol Vinyals
Quoc V. Le
{ilyasu, vinyals, qvl}@google.com
10757025 陳威廷
10757011 吳家豪
10757019 楊敘
CoRR, September 2014
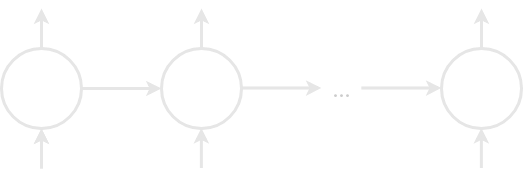
\(h_t=sigm(W^{hx}x_t+W^{hh}h_{t-1})\)
\(y_t=W^{yh}h_t\)
\(y_1\)
\(y_2\)
\(y_T\)
\(x_1\)
\(x_2\)
\(x_T\)
\(h_1\)
\(h_2\)
\(h_{T-1}\)
\(p(y_1, ..., y_{T'} | x_1, ..., x_T) = \displaystyle\prod_{t=1}^{T'}p(y_t|v, y_1, ..., y_{t-1})\)
\(1/|\mathcal{D}|\displaystyle\sum_{(T,S)\in\mathcal{D}}\log p(T|S)\)
\(\hat{T}=\arg\displaystyle\max_T p(T|S)\)
\(c\)
\(b\)
\(a\)
\(\alpha\)
\(\beta\)
\(\gamma\)
\(c\)
\(b\)
\(a\)
\(\alpha\)
\(\beta\)
\(\gamma\)
| Method | Test BLEU Score (NTST14) |
|---|---|
| Bahdanau et al. | 28.45 |
| Baseline System | 33.30 |
| Single forward LSTM, beam size 12 | 26.17 |
| Single reversed LSTM, beam size 12
|
30.59 |
| Ensemble of 5 reversed LSTMs, beam size 1 | 33.00 |
| Ensemble of 2 reversed LSTMs, beam size 12 | 33.27 |
| Ensemble of 5 reversed LSTMs, beam size 2 | 34.50 |
| Ensemble of 5 reversed LSTMs, beam size 12 | 34.81 |
Table 1: The performance of the LSTM on WMT'14 English to French test set (ntst14).
| Method | Test BLEU Score (NTST14) |
|---|---|
| Baseline System | 33.30 |
| Cho et al. | 34.54 |
| State of the art | 37.0 |
| Rescoring the baseline 1000-best with a single forward LSTM | 35.61 |
| Rescoring the baseline 1000-best with a single reversed LSTM |
35.85 |
| Rescoring the baseline 1000-best with an ensemble of 5 reversed LSTMs | 36.5 |
| Oracle Rescoring of the Baseline 1000-best lists | ~45 |
Table 2: Methods that use neural networks together with an SMT system.
| Method | Test BLEU Score (NTST14) |
|---|---|
| Bahdanau et al. | 28.45 |
| Baseline System | 33.30 |
| Cho et al. | 34.54 |
| State of the art | 37.00 |
| Single forward LSTM, beam size 12 | 26.17 |
| Single reversed LSTM, beam size 12 | 30.59 |
| Ensemble of 5 reversed LSTMs, beam size 1 | 33.00 |
| Ensemble of 2 reversed LSTMs, beam size 12 | 33.27 |
| Ensemble of 5 reversed LSTMs, beam size 2 | 34.50 |
| Ensemble of 5 reversed LSTMs, beam size 12 | 34.81 |
| Rescoring the baseline 1000-best with a single forward LSTM | 35.61 |
| Rescoring the baseline 1000-best with a single reversed LSTM | 35.85 |
| Rescoring the baseline 1000-best with an ensemble of 5 reversed LSTMs | 36.5 |
| Oracle Rescoring of the Baseline 1000-best lists | ~45 |
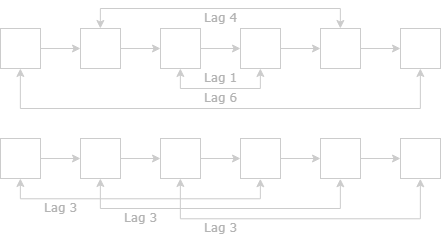
Figure 2: The 2-dimensional PCA projection of the LSTM hidden states that are obtained after processing the phrases in the figures.
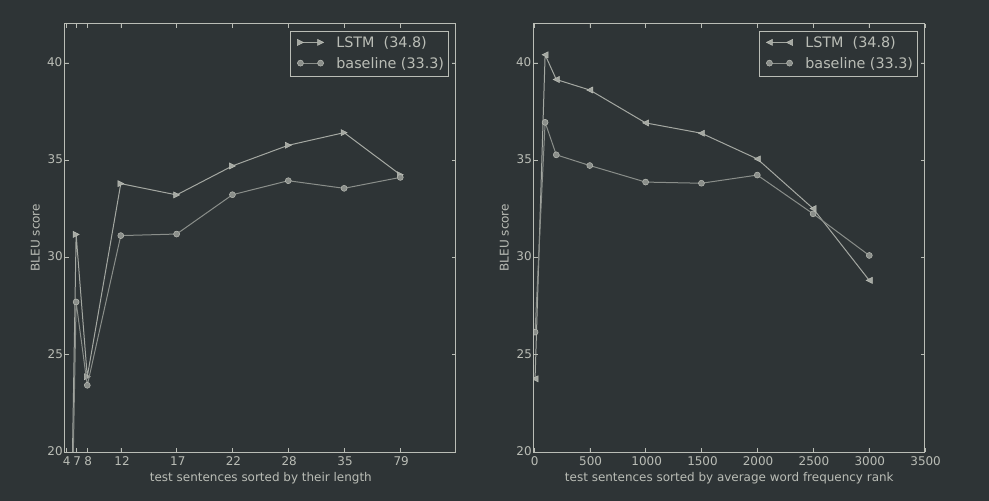
Figure 3: The left plot is showed with sorted by length of test sentences. The right plot is showed with sorted by average word frequency rank of test sentences.
By Penut Chen (PenutChen)
Sequence to Sequence Learning with Neural Networks




