瀏覽器原理解析
- 元件 / 功能
- Render Engine
- Html Parser
- 輸入網址之後發生了什麼事?
瀏覽器的主要元件
1. 使用者介面
2. 瀏覽器引擎
3. 渲染引擎
4. 網路
5. 使用者介面後端
6. JS 直譯器
7. 資料儲存
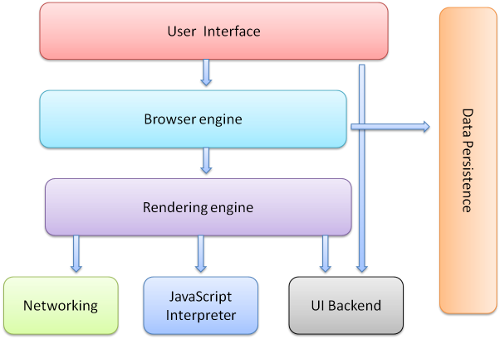
瀏覽器的主要功能
向伺服器發出請求,在瀏覽器視窗中展示您選擇的網路資源。
解釋並顯示 HTML 檔案的方式是由網路標準化組織 W3C(全球資訊網聯盟)所規範。
相容性問題:
1. 瀏覽器們沒有完全遵守規範
2. 開發自己獨有的擴充條件程式
3. 瀏覽器本身的使用者介面也沒有正式規範
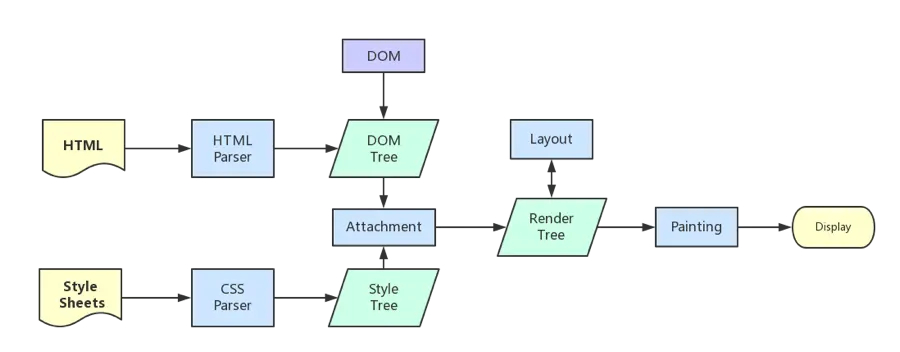
渲染引擎(Rendering Engine)
功能:在瀏覽器的螢幕上顯示請求的內容
Firefox 使用的是 Gecko,這是 Mozilla 公司「自制」的呈現引擎。
而 Safari 和 Chrome 瀏覽器使用的都是 WebKit。

流程
1. 解析HTML,建構DOM Tree 和 CSS Rule Tree
2. 用上述兩者建構 Render Tree
3. Render Tree 排版
4. Render Tree 繪製
Webkit
Gecko
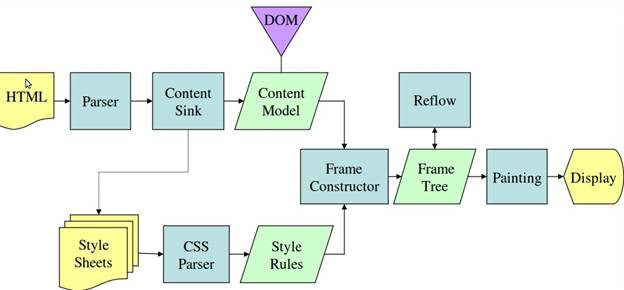
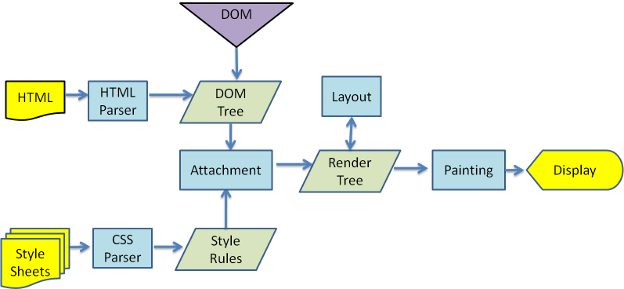
不同引擎的流程
HTML Parser
The job of the HTML parser is to parse the HTML markup into a parse tree. (DOM)
<html>
<body>
<p>
Hello World
</p>
<div>
<img src="example.png"/>
</div>
</body>
</html>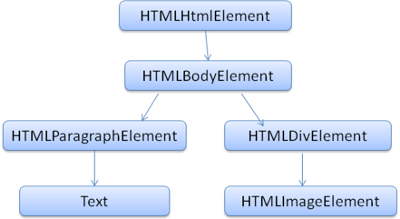
The parsing algorithm
HTML 的解析需要用與上下文無關的語法來定義,因此,所有的常規解析器都不適用於 HTML
(但是,它們可以用於解析 CSS 和 JavaScript)
解決方式: 標記化 和 樹構建
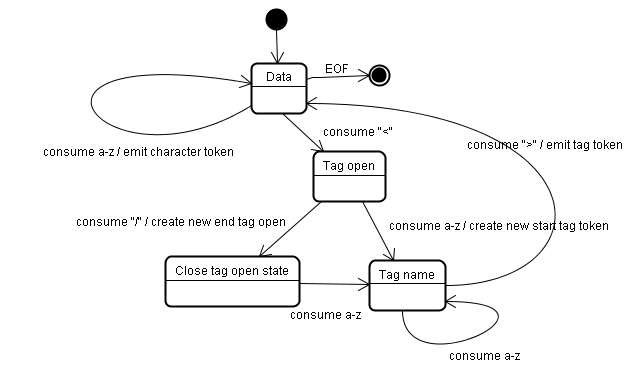
標記化(Tokenization)
詞法分析過程,將輸入內容解析成多個標記(Tokens)
<html>
<body>
Hello world
</body>
</html>該演算法使用狀態機來表示。每一個狀態接收來自輸入資訊流的一個或多個字元,並根據這些字元更新下一個狀態。
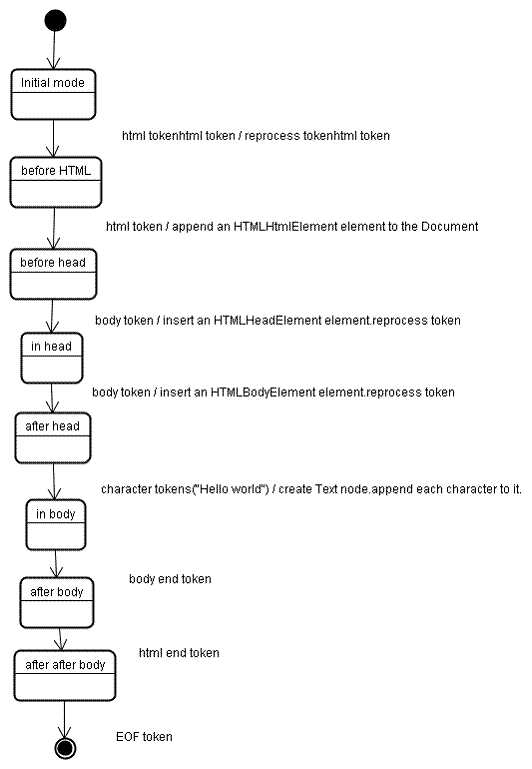
樹建構演算法( Tree construction algorithm )
在建立 parser 的同時,也會建立 Document 物件。
在樹構建階段,以 Document 為根節點的 DOM 樹也會不斷進行修改,向其中新增各種元素。
其演算法也可以用狀態機來描述。這些狀態稱為“插入模式”。
<html>
<body>
Hello world
</body>
</html>總結一下:我們在瀏覽器輸入網址之後,做了哪些事?
1. 請求資源
2. 解析 Html 建構 DOM tree
3. 解析 Css 建構 Rule tree
4. 合成建構 Render tree
5. Layout of Render tree
6. Painting the render tree
謝謝大家~~~
參考資料:
1.https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/
2. https://codertw.com/ios/19788/
3. http://fex.baidu.com/blog/2014/05/what-happen/
4.https://ithelp.ithome.com.tw/articles/10197966
瀏覽器原理解析
By parkerhiphop




