儲存與檢索
Storage and Retrieval
理解 Storage Engine 的內部知識
選擇適合的 Application
- DB 如何儲存和檢索、資料存在 DB 會發生什麼事、再次查詢資料時,DB 會怎麼做?(根據 Storage Engine 有所不同)
- 高層次的分類:OLTP vs OLAP
- 兩個 OLTP 主流的 Storage Engine: Log & Update-In-Place
- 概述在 OLTP 上更複雜的 indexing structures
- 把資料都存在 memory(記憶體) 而最佳化的 DB
- Data Warehouse
- Column-Oriented Storage
DB 如何儲存和檢索
根據 Storage Engine 有所不同
格式主要是 key-value pair
寫入有分
1. Append
2. Overwrite
極簡的 Query 效能是 O(n)
為了提升效能使用 Index data structure
使用額外的 metadata 幫助 Query
但這額外的結構就會影響寫入的效能
需要針對不同的 Query Patterns 來選擇最適合的 Indexing Structure
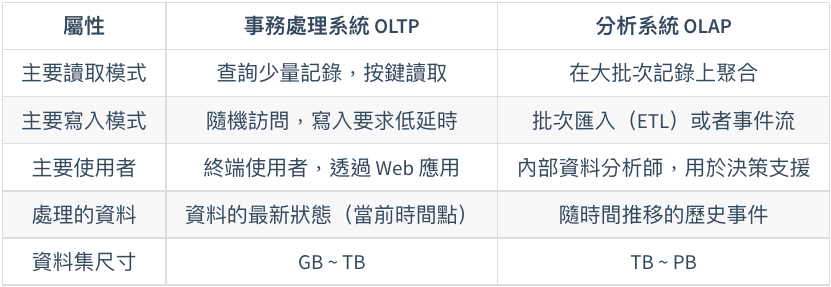
OLTP vs OLAP
OLTP 主流的 Storage Engine
Log-Structure
Update-In-Place
- 只允許追加檔案和刪除過時的檔案
- 不能更新已寫入的檔案
-
較新的技術,改變資料寫入的方式
- 隨機寫入 → 依序寫入
- 更高的寫入吞吐量(Hard Drives & SSDs 的效能特點)
-
Examples
- Bitcask、SSTables、LSM-Tree、LevelDB、Cassandra、HBase、Lucene
- 把硬碟當作一組固定大小的頁面,可以被覆寫
- Example: B-Trees
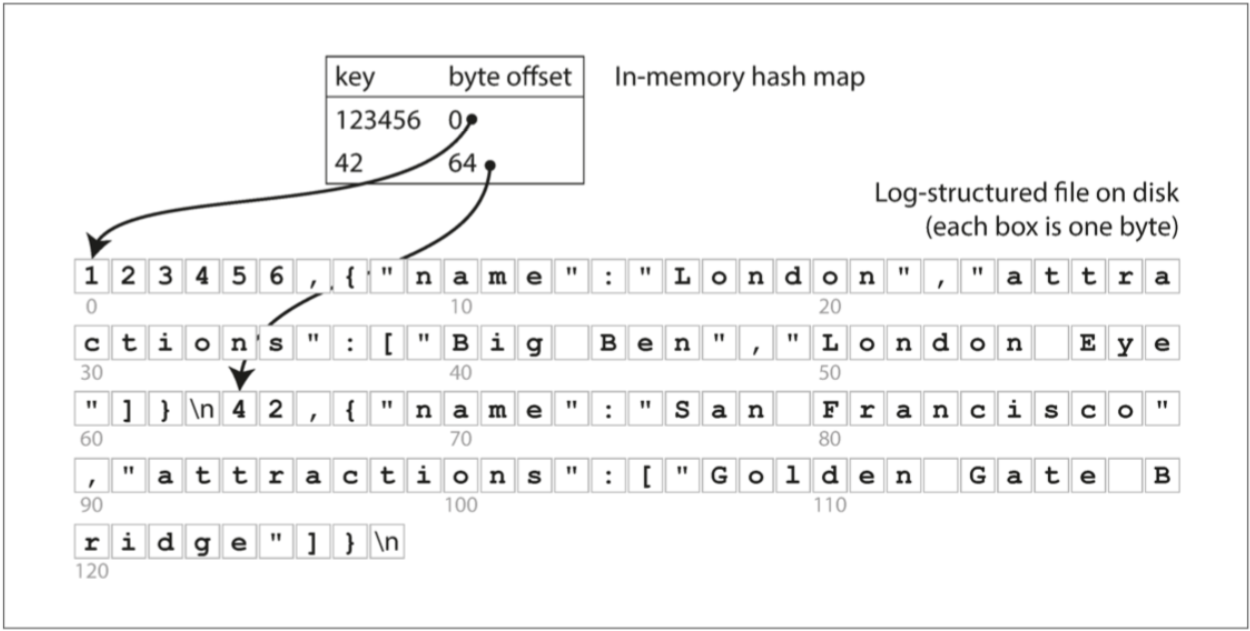
極簡的 Log:Append-Only File
SSTable

資料按照 Key 的順序排列
因為依序,所以可取該 Key 在最新 Segment 中的 Value 就好
SSTable
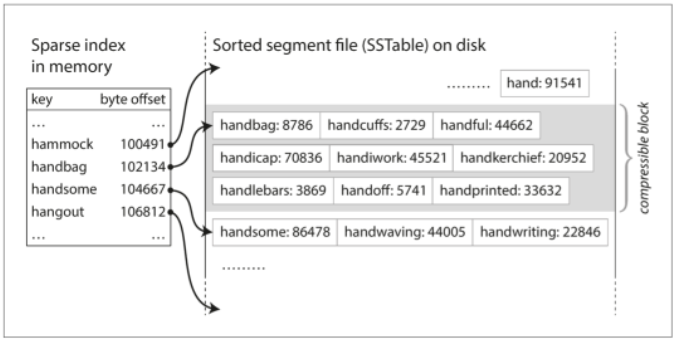
不需為了查找 Key 而在 Memory 中存所有 Key 的 index
將紀錄分塊(block),並在寫入 Disk 前壓縮
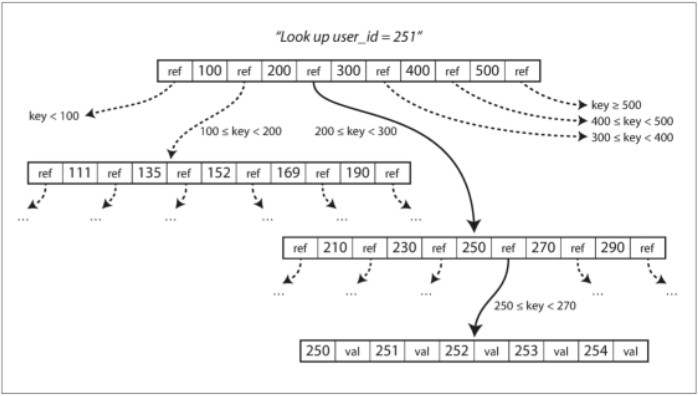
B-Tree
將資料庫分解成固定大小的塊(block)或頁面(page)
B-Tree
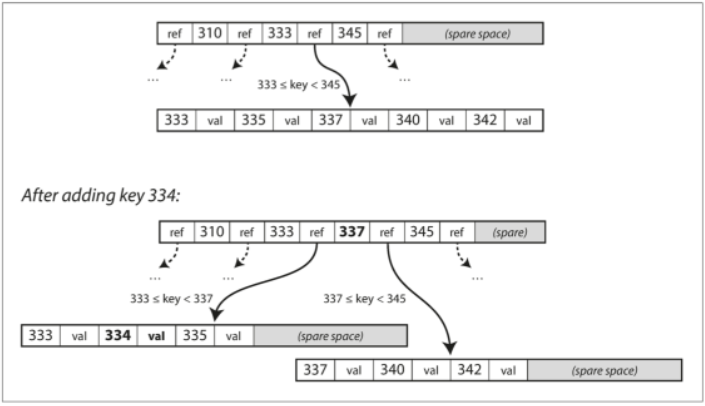
Write a new key
在 OLTP 上更複雜的 indexing structures
- 次級索引 secondary indexes
- 聚集索引(在索引中儲存所有的行資料)
- 非聚集索引(僅在索引中儲存對資料的引用)
- 覆蓋索引(covering index) 或 包含列的索引(index with included columns)
- 多列索引 Multi-column indexes
- Full-text search and fuzzy indexes
把資料都存在 memory(記憶體) 而最佳化的 DB
省去了將記憶體資料結構編碼為硬碟資料結構的開銷
- Redis 為各種資料結構(如優先順序佇列和集合)提供了類似資料庫的介面
- 將所有資料儲存在記憶體中,所以它的實現相對簡單
OLAP & Data Warehouse
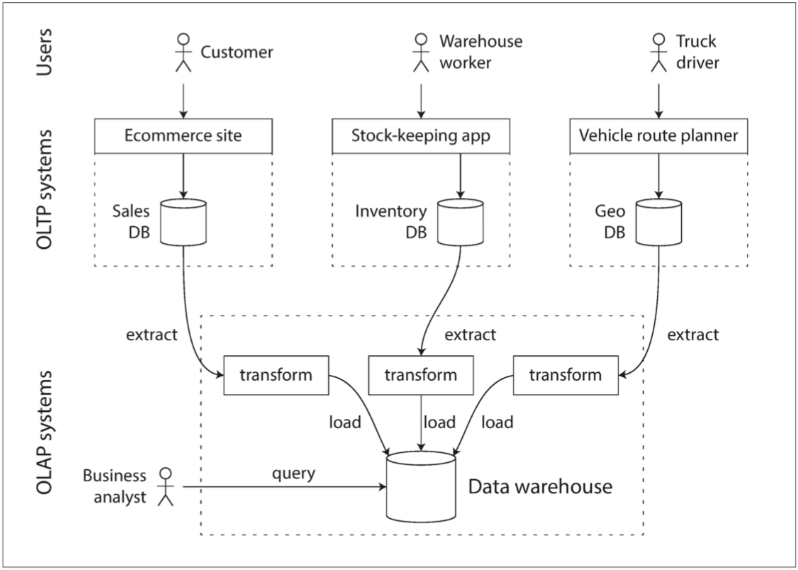
ETL
Column-Oriented Storage
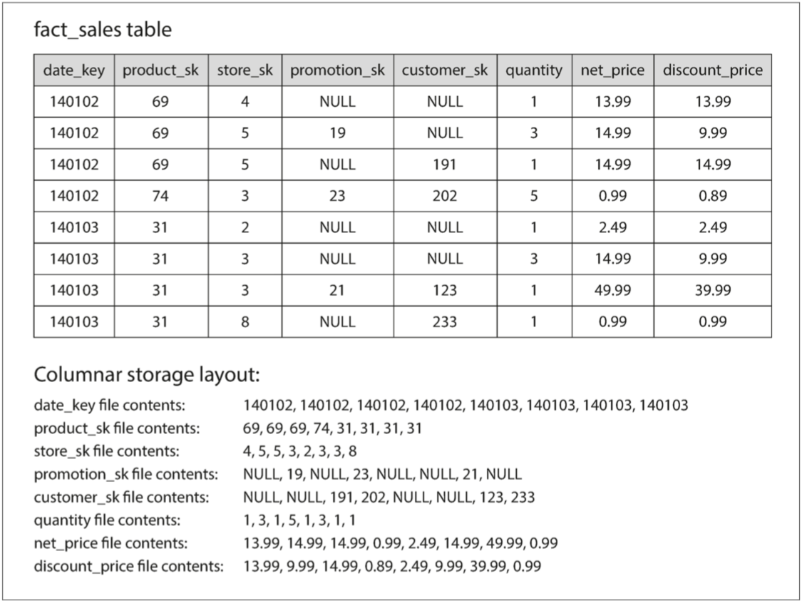
不要將所有來自 Column 的值儲存在一起,而是將來自 Row 的所有值儲存在一起。
點陣圖編碼

資料立方
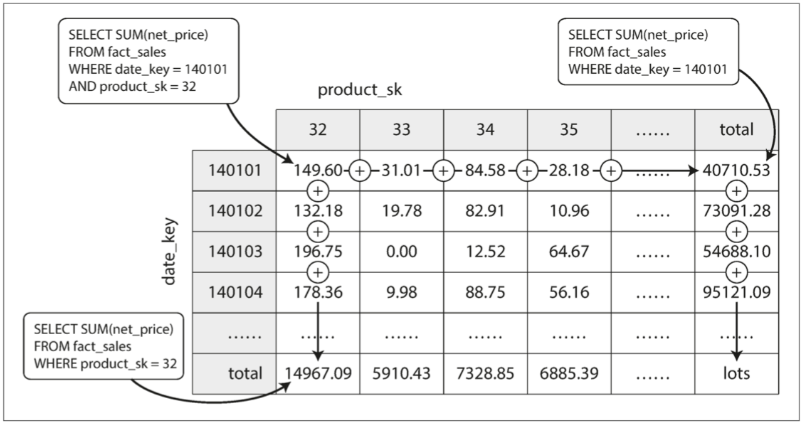
deck
By parkerhiphop




