Reproducibility and correctness in computational redistricting
Parker Rule
February 17, 2021
The replication crisis
What is it? The well-known metascience phenomenon that many studies—including important, splashy ones—cannot be replicated (or reproduced).
Publication bias and p-hacking are frequently cited as factors in the replication crisis.* However, complex software may also introduce replication issues.
*For an excellent introduction to the reproducibility crisis in biomedicine, see Nelson.
(Replication issues can also arise from fraud, deception, and gross incompetence. Math and theoretical computer science are prone to failed proofs. We'll largely leave these issues aside for today.)
Reproducibility ≠ correctness
Reproducibility ≠ correctness
"The replication crisis" means many things. Let's define our terms precisely in a way that's useful in our context.
A (redistricting) analysis is reproducible when a reasonably informed outsider can re-run the analysis code and produce the same results.
A (redistricting) analysis is correct when the analysis code matches its written specification well.
These aren't useful yet. (What written specification?)
Case studies


sources: Nature, JOCO, Retraction Watch
reproducibility
correctness
What are the norms?
source: Stodden et al. 2018
All data necessary to understand, assess, and extend the conclusions of the manuscript must be available to any reader of Science. All computer codes involved in the creation or analysis of data must also be available to any reader of Science. After publication, all reasonable requests for data and materials must be fulfilled. Any restrictions on the availability of data, codes, or materials, including fees and original data obtained from other sources (Materials Transfer Agreements), must be disclosed to the editors upon submission...
Consider the policy Science instituted in 2011.
Case study

What happens when we mandate reproducibility and data sharing? (Stodden et al.)
source: Stodden et al. 2018
What are the norms?
tl;dr: Scientists are an overworked, competitive, and grumpy lot.*

source: Stodden et al. 2018
What are the norms?
Tacit knowledge strikes again! 😢
source: Stodden et al. 2018

currently a major problem in machine learning
Can we do better?
source: Science

Passive > active! (Aim for a bus factor of ∞ 🚍)
What are our field's norms?
source: Duchin & Spencer 2021

source: Duchin & Spencer 2021

source: Duchin & Spencer 2021
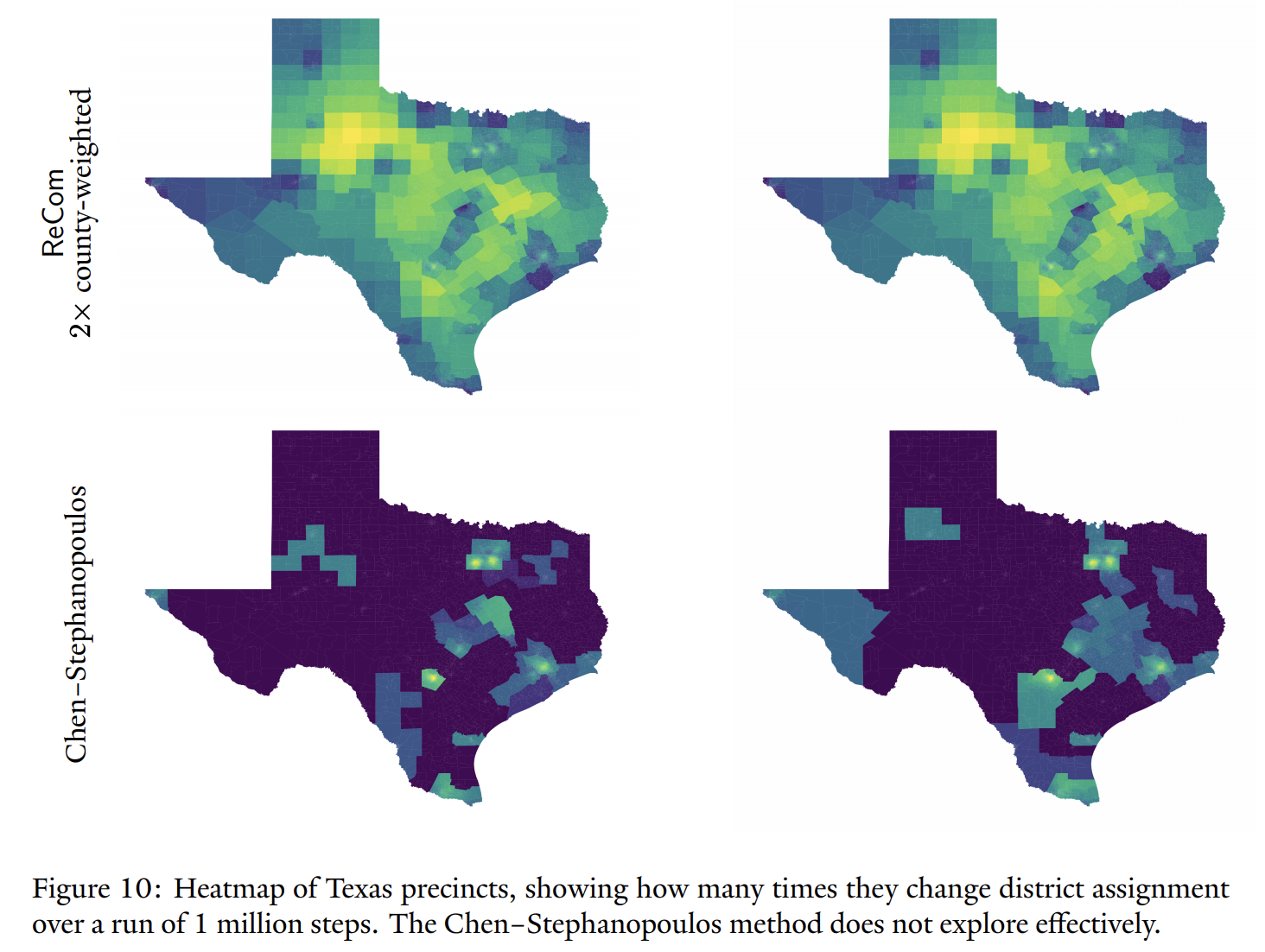
The computational landscape
source: mggg.org
Duke
MGGG
Let's not take this for granted.
What's in a boxplot?
High-level decisions & normative considerations
What visualizations should we make?
What statistics should we track?
What data should we use?
What algorithms should we use?
Low-level decisions & implementation details
How do we make visualizations? (Matplotlib, TikZ, QGIS, ...)
How do we track and store statistics? (GerryChain, CSVs, ...)
How do we preprocess, clean, and store data?
(Pandas, NumPy, QGIS, GitHub; automatic vs. manual)
How do we implement algorithms? (Python, Julia, NetworkX, ...)
What's in a boxplot?
Raw data (U.S. Census, state GIS)
⋃ Data preprocessing
⋃ Description of chain algorithm (ReCom + parameters + constraints)
⋃ Implementation of chain algorithm
⋃ Description of chain statistics/updaters
⋃ Implementation of chain statistics/updaters
⋃ Postprocessing/plotting code
⋃ Code dependencies
refer to canonical source, checksum
version control & dependency management (V&D)
(manuscript)
V&D
(manuscript)
V&D
V&D
dependency management
What's in a boxplot?
Raw data (U.S. Census, state GIS)
⋃ Data preprocessing
⋃ Description of chain algorithm (ReCom + parameters + constraints)
⋃ Implementation of chain algorithm
⋃ Description of chain statistics/updaters
⋃ Implementation of chain statistics/updaters
⋃ Postprocessing/plotting code
⋃ Code dependencies
auditing, code review, tests, documentation
specify well
code review, tests, benchmarks
specify well
code review, tests
code review; keep minimal
Sideline: why does this matter?
Solution: version control and dependency management
These practices are well-established in the software engineering world. We're already doing a lot of this.
pip freeze, conda list, poetry
Aim for rigor. Exact versions (may) matter.
Even better (see computational biology, etc.): use Docker and Singularity to store information about the exact system. Store an exact image of the system, even (when feasible).
Solution: structured description → human-readable documentation
{
"metadata": {
"stateLegalName": "Commonwealth of Massachusetts",
"stateFIPSCode": 25,
"stateAbbreviation": "MA",
"git": "https://github.com/mggg-states/MA-shapefiles.git",
"repoName": "MA-shapefiles",
"archive": "MA_precincts_02_10.zip",
"fileName": "MA_precincts_02_10.shp",
"yearEffectiveStart": 2002,
"yearEffectiveEnd": 2010
},
"descriptors": {
"stateFIPS": "STATEFP10",
"countyFIPS": "COUNTYFP10",
"countyLegalName": "",
"totalPopulation": "TOTPOP"
},
"sources": ["CENSUS", "SOS"],
"elections": {
"parties": [{
"partyDescriptorFEC": "DEM",
"partyLegalName": "Democratic Party",
"years": {
"2010": {
"USSenateAbsentee": "SEN10D",
"USSenateNoAbsentee": "SEN10D"
},
"2008": {
"USSenateAbsentee": "SEN08D",
"USSenateNoAbsentee": "SEN08D",
"USPresidentAbsentee": "PRES08D",
"USPresidentNoAbsentee": "PRES08D"
},(documentation as data)
Solution: operationalize more precisely
Fun fact: ReCom (as described in DeFord et al. 2019) is a family of sampling algorithms, parameterizable by the spanning tree distribution and the like.
As we saw in the case of our recent Yale Law Journal work, mapping legal requirements to code is a critical (and under-discussed) step.
Solution: beyond unit tests
When possible, implement distribution tests. (We can we write down the reversible ReCom target distribution in closed form, for instance.)
Match field-wide benchmarks (Imai)
Create new benchmarks!
Solution: mob code review of tricky bits
Case study: Python Reversible ReCom implementation
ReCom is quite simple, actually!
Solution: standardize and centralize
Make the 80/20 visualizations easy.
Store output data in a central place and in a uniform format.
(Don't rewrite the same visualization code when possible.)
Coming soon: chain-db (ask me for a demo notebook!)
Store input data in a central place and in a uniform format.
Ideas?
Reproducibility and correctness in computational redistricting
By Parker Rule




