Rethinking the Role of Demonstrations:
What Makes In-Context Learning Work?
By Min et al.
Presented by Parsa Hejabi - 10/07/24
Introduction
- In-Context Learning (ICL):
- Language models perform tasks by conditioning on examples provided in the prompt.
- No parameter updates; the model uses the context to make the predictions.
- Objective of the Paper:
- Investigate the role of demonstrations in ICL.
- Understand what aspects of demonstrations are crucial for model performance.
Introduction

- How important are correct input-label mappings in demonstrations?
- Which aspects of demonstrations contribute most to performance gains?
- How does meta-training with an ICL objective affect these findings?
Main Research Questions
Experiments
-
12 Models:
-
GPT-2 Large (774M parameters)
-
GPT-J (6B parameters)
-
Fairseq LMs (6.7B & 13B parameters)
-
GPT-3 (175B parameters)
-
MetaICL (Meta-trained GPT-2 Large)
-
-
Inference Methods:
-
Direct Method: Predict output directly from input and context.
-
Channel Method: Predict input given output and context.
-
Experimental Setup
-
Evaluation Data:
-
26 Datasets covering:
-
Sentiment analysis, paraphrase detection, Hate speech detection, etc.
-
-
All tasks are classification or multi-choice tasks
-
-
Experimental Details:
-
Demonstrations: K = 16 examples per prompt.
-
Repetitions: 5 random seeds, experiments run 5 times.
-
For Fairseq 13B and GPT-3: subset of 6 datasets and 3 seeds
-
-
Metrics:
-
Macro-F1 for classification tasks
-
Accuracy for multi-choice tasks
-
-
-
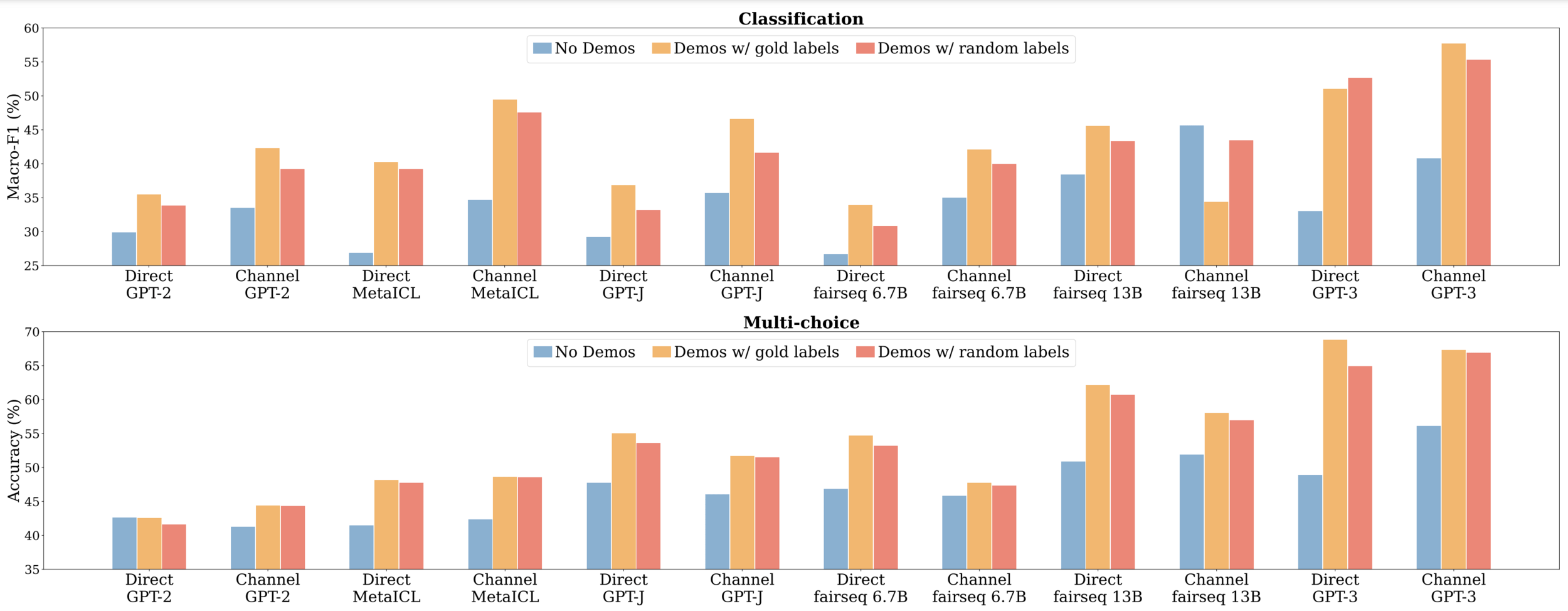
Method: Replace gold labels with random labels in demonstrations.
C = small discrete set of possible labels => labels are randomly sampled at uniform from C - Findings: Performance drops only marginally compared to using correct labels.
Importance of Correct Input-Label Mappings
?
?
?
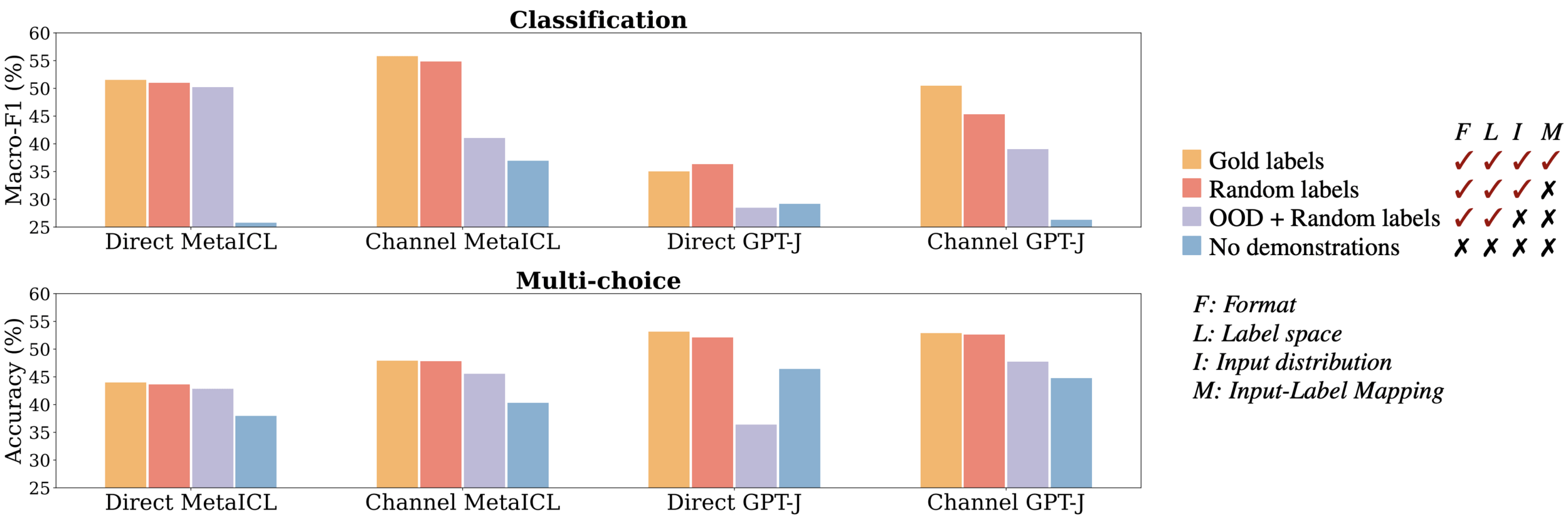
- Objective: Assess the effect of using out-of-distribution (OOD) inputs in demonstrations.
- Method: Replace in-distribution inputs x1,x2,…,xkx_1, x_2, \dots, x_kx1,x2,…,xk with random sentences from an external corpus (e.g., CC-News).
-
Findings:
- Significant performance drop (3–16% absolute decrease) for most models.
- In some cases, worse than no demonstrations.
Impact of Input Distribution
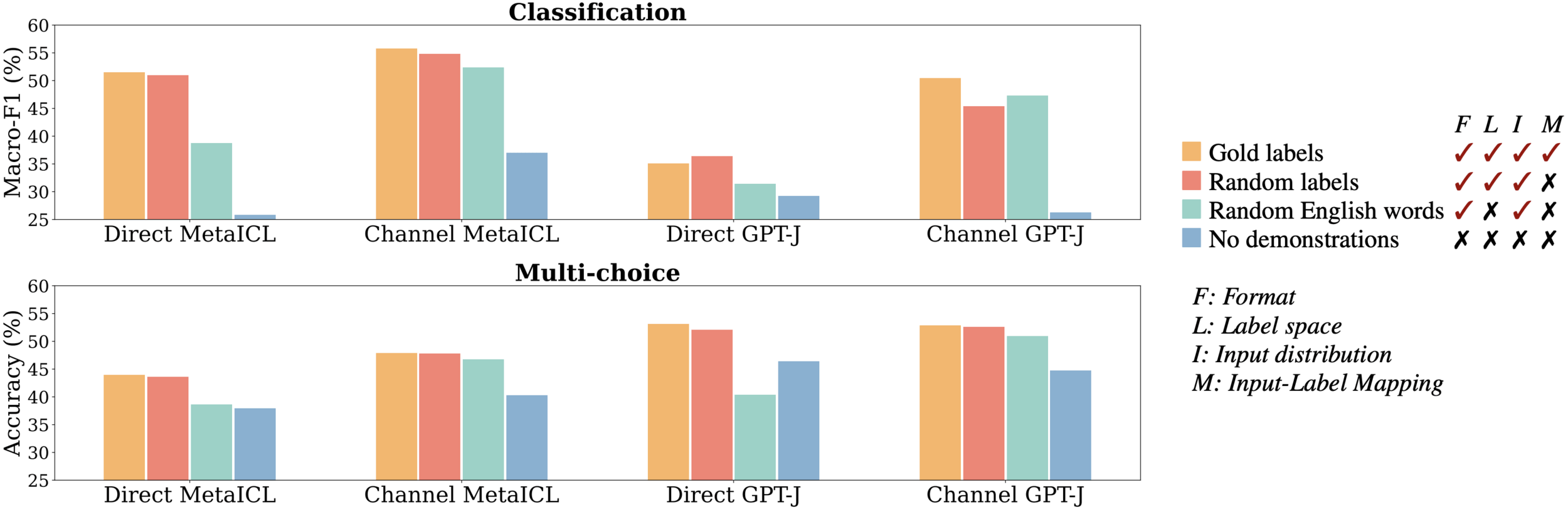
- Objective: Examine the role of the label space in model performance.
- Method: Replace task-specific labels with random English words.
-
Findings:
- Significant performance drop (5–16% absolute decrease).
- Indicates that knowledge of the correct label space is important.
-
Direct models have significant gaps, but channel models:
- Minimal impact (0–2% drop or slight increase).
- Channel models are less affected by changes in label space.
Impact of Label Space
y_i
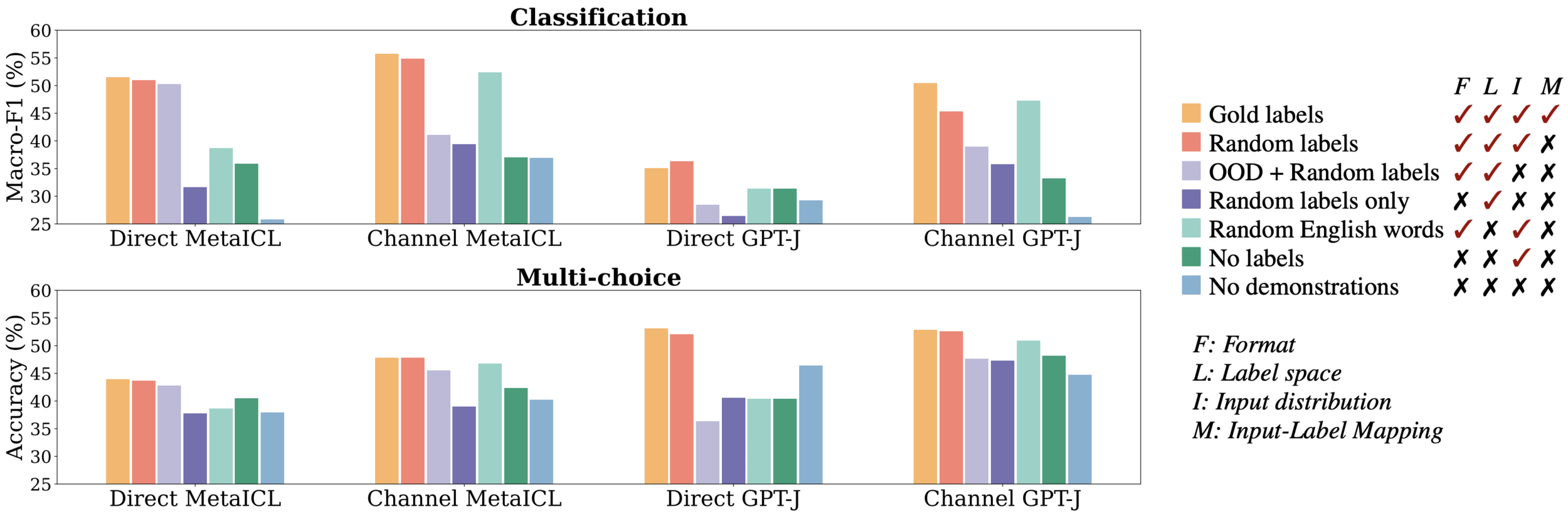
- Objective: Assess the importance of the input-label pairing format in demonstrations.
-
Method:
- No Labels: Use inputs only in demonstrations.
- Labels Only: Use labels only without inputs.
-
Findings:
- Removing the input-label pairing format leads to performance worse than or close to no demonstrations.
- Keeping the format allows models to retain a significant portion of performance gains.
- Key Insight: Format is crucial for triggering models to mimic and complete tasks.
Impact of Input-Label Pairing (Format)
- MetaICL Model:
- GPT-2 Large meta-trained with an in-context learning objective.
- Observations:
- Patterns are more pronounced with MetaICL.
- Ground truth input-label mappings matter even less.
- Format becomes even more important.
- Hypothesis:
- Meta-training encourages models to exploit simpler aspects (like format) and ignore complex ones (like input-label mappings).
- The input-label mapping is likely harder to exploit
- The format is likely easier to exploit
- The space of the text that the model is trained to generate is likely easier to exploit than the space of the text that the model conditions on
- Meta-training encourages models to exploit simpler aspects (like format) and ignore complex ones (like input-label mappings).
Impact of Meta-Training
Conclusion
- Main Findings:
- Correct input-label mappings have little impact on performance.
- Performance gains come from independent specification of inputs and labels.
- Format of demonstrations is key to performance.
- Meta-training magnifies reliance on superficial aspects.
- Implications:
- Models may not learn new tasks but exploit patterns and priors from pertaining.
- In-context learning might not work for tasks not captured during pretraining.
Conclusion
Thank You!
🙋♂️🙋♀️
Copy of Robustness to Noisy Labels in Parameter Efficient Fine-tuning
By Parsa Hejabi




