Principles of Computer Systems
Autumn 2019
Stanford University
Computer Science Department
Lecturer: Chris Gregg
Philip Levis

Lecture 14: Virtualization and Caching
- Abstraction
- Modularity and Layering
- Naming and Name Resolution
- Caching
- Virtualization
- Concurrency
- Client-server request-and-response
Two of Seven
- Caching
- Virtualization
Two of Seven
- Caching
- Virtualization
Two of Seven
- Through a layer of indirection, make one look like many or many look like one
- Virtualizing the CPU (e.g., processes): one like many
- Virtual machines: one like many
- Virtual memory: one like many
- RAID (Redundant Array of Inexpensive Disks): many like one
- Logical volumes: one like many
- Virtual private networks: one like many
- Decouples program from physical resources
Virtualization
- Through a layer of indirection, make one look like many or many look like one
- Virtualizing the CPU (e.g., processes): one like many
- Virtual machines: one like many
- Virtual memory: one like many
- RAID (Redundant Array of Inexpensive Disks): many like one
- Logical volumes: one like many
- Virtual private networks: one like many
- Decouples program from physical resources
Virtualization
- Disks have limited space: biggest disk today is ~15TB
- What if you need more than 15TB?
- Could make bigger and bigger disks -- but cost is non-linear
- Use virtualization: put multiple physical disks together to look like one bigger virtual disk
RAID (Redundant Array of Inexpensive Disks)
- Disks have limited space: biggest disk today is ~15TB
- What if you need more than 15TB?
- Could make bigger and bigger disks -- but cost is non-linear
- Use virtualization: put multiple physical disks together to look like one bigger virtual disk
RAID (Redundant Array of Inexpensive Disks)

- Size: we can make arbitrarily large disks
- Speed: if we lay out data well, we can read from N disks in parallel, not just one
- Cost: N inexpensive disks is cheaper than one huge disk
RAID: a lot of advantages
- Stripe data across disks
- n disks of size S, have nS bytes!
RAID 0
- If one disk fails, the entire RAID array fails
- Suppose each disk has a probability p of failing per month
- Probability each disk does not fail is (1-p)
- Probability all n disks do not fail is (1-p)
- Suppose p = 0.001; if n=20, there's a 2% chance the RAID array will fail each month
RAID 0 Problems
n
- Key idea: arrange the data on the disks so the array can survive failures
- Simplest approach is mirroring, RAID 1
- Halves capacity, but still less expensive than a big disk
- Probability 2 replicas fail is 1-(1-p )
- If p = 0.001, if n=20, there's a .00001% chance the RAID array will fail each month
Redundant Array of Inexpensive Disks: RAID 1
2
n/2
- There are better ways to have recovery data than simple replication
- Exclusive OR (XOR)
- Suppose we have two drives, A and B
- One extra drive C: C = A B
- If B fails, then you can recover B: B = A C
The Power of XOR
| A | B | C |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
=
A
B
C
- RAID 5 stripes the data across disks, sets aside 1 disk worth of storage as parity
- Parity is the XOR of all of that sector on all of the other drives
- Writes write two drives: data and parity; parity is spread: lose 1/n of storage
- Requires two drives to fail: n=6, p=0.001, failure ≈ 0.000015
- If one drive fails, it can be recovered from the parity bits (just XOR other disks)
RAID 5: Resiliency With Less Cost
- Suppose we have 6 disks total, one parity disk
- We lose disk 4
- Question 1: Can we still service reads? If so, how does one read from disk 4?
- Question 2: Can we still service writes? If so, how does one write to disk 4?
- Question 3: How do we recover disk 4?
RAID 5: Resiliency With Less Cost
- What if chances more than can fail becomes dangerous (thousands of drives)?
- Reed-Solomon coding: turn k data blocks into n, can recover from any (n-k) failures
- E.g., turn 223 data blocks into 255, can recover from any 32 failures
- Used in CDs, DVDs, QR codes, Mars Rovers, and most cloud storage systems
- RAID 6: use Reed-Solomon to have two parity drives
Reed-Solomon Coding
RAID invented in 1988 (4 years after first Macintosh)

Described up to RAID 5 (also, RAID 2, RAID 3, RAID 4)
- Through a layer of indirection, make one look like many or many look like one
- Virtualizing the CPU (e.g., processes): one like many
- Virtual machines: one like many
- Virtual memory: one like many
- RAID (Redundant Array of Inexpensive Disks): many like one
- Logical volumes: one like many
- Virtual private networks: one like many
- Decouples program from physical resources
Virtualization
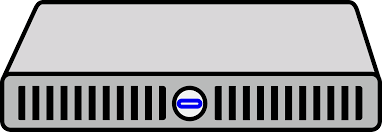
- Software that makes code (running in a process) think that it's running on raw hardware
- A virtual machine monitor runs in the host operating system
- It loads and run disk images for guest operating systems
- Operations in the guest operating system that are normally not allowed trap into the virtual machine monitor
- Guest operating system tries to change page tables
- Guest operating system tries to disable interrupts
- Virtual machine monitor emulates the hardware
Virtual Machine
Host OS
VMM
guest
OS
guest
OS
guest
OS
vi
bash
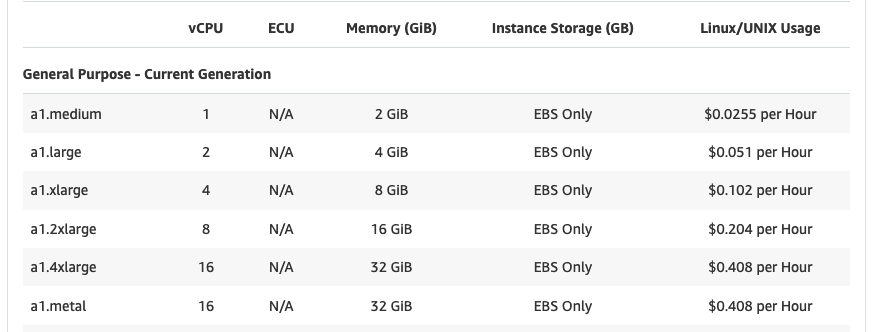
- Amazon computing service: a virtual computer is called an instance
- Many different kinds of instance: general purpose, memory-optimized, compute-optimized, GPUs, etc.
- There's generally a full instance size, and you can have 1/2 of it
- Four a1.large is the same as one a1.2xlarge
- Two a1.2x large is the same as one a1.4xlarge
Amazon Elastic Compute Cloud (EC2)
n
Amazon EC2 Example
Host OS
VMM
a1.2xlarge
a1.large
management
a1.large
a1.large
a1.large
- Move whole images anywhere: completely decouple all software from hardware
- Can replicate computer images: run more copies
- If your service is overloaded, scale out by spinning up more instances
- Can arbitrarily start/stop/resume instances very quickly
- Must faster than shutting down machines
- Complete software encapsulation
- Common technique used in software tutorials: download this VM image and run it
- Web hosting: one server can run 100 virtual machines, each one thinks it has a complete, independent computer to configure and use
- Complete software isolation
- In theory, two VMs are completely isolated, can maybe only sense something due to timing (e.g., if they are sharing a CPU), more on this later
- Enabled us to have cloud computing
- Original business case was the desktop! E.g., need to run Windows and Linux in parallel, don't want 2 machines.
Virtual Machine Advantages
Modern Virtual Machines Invented in 1997

- Caching
- Virtualization
Two of Seven
Latency Numbers Every Programmer Should Know
(Peter Norvig and Jeff Dean)
| 0.5ns | |||
| 5ns | |||
| 7ns | |||
| 25ns | |||
| 100ns | |||
| 3,000ns | 3us | ||
| 10,000ns | 10us | ||
| 150,000ns | 150us | ||
| 250,000ns | 250us | ||
| 500,000ns | 500us | ||
| 1,000,000ns | 1,000us | 1ms | |
| 10,000,000ns | 10,000us | 10ms | |
| 20,000,000ns | 20,000us | 20ms | |
| 150,000,000ns | 150,000us | 150ms |
| L1 cache reference |
| Branch mispredict |
| L2 cache reference |
| Mutex lock/unlock |
| Main memory reference |
| Compress 1K with Zippy |
| Send 1K over 1Gbps network |
| Read 4K randomly from SSD |
| Read 1MB sequentially from RAM |
| Round trip within a datacenter |
| Read 1MB sequentially from SSD |
| Hard disk seek |
| Read 1MB sequentially from disk |
| Send packet CA->Netherlands->CA |
- Performance optimization
- Keeping a copy of some data
- Usually, closer to where the data is needed
- Or, something that might be reused (don't recompute)
- Used everywhere in computer systems
- Registers
- Processor caches
- File system buffer cache
- DNS caching
- memcached
- Database page cache
- Spark analytics framework
- Web browser page/image cache
- Phone email/SMS cache
Caching
-
There is a basic tradeoff in performance and size
-
If you make it bigger, it's slower
-
Takes longer to get to (due to size)
-
Addressing it is more complex (more bits to switch on)
-
-
Faster storage is more expensive
-
16GB RAM: $59.99
-
1TB HDD: $59.99
-
4TB HDD: $116.99
-
4TB SSD: $499.99
-
-
Think about the places your web page might be stored...
Why Is Caching Useful
CPU cache
register
memory
web cache
proxy cache
website
0.3ns
7ns
100ns
20ms
25ms
100ms
reduce network use
- Performance optimization
- Keeping a copy of some data
- Usually, closer to where the data is needed
- Or, something that might be reused (don't recompute)
- Used everywhere in computer systems
- Registers
- Processor caches
- File system buffer cache
- DNS caching
- memcached
- Database page cache
- Spark analytics framework
- Web browser page/image cache
- Phone email/SMS cache
Caching
- The operating system maintains a buffer cache of disk blocks that have been brought into memory
- When you read or write a file, you read or write to a buffer cache entry
- If that block was not in RAM, the OS brings it into RAM, then does the operation
- A write marks a buffer cache entry as dirty
- Dirty entries are asynchronously written back to disk
- Can be forced with fsync(2)
- Buffer cache absorbs both reads and writes, prevents them from hitting disk (100,000x performance difference)
File System Buffer Cache
Disk
Buffer Cache
- Recall that a process memory space is divided into segments
- Some segments are mmaped files (e.g., your program, libraries)
- The buffer cache is what sits behind this
- If memory is low, start deleting buffer cache entries
- If the entry is clean, just reclaim the memory
- If it's dirty, write it back to disk
- Others are anonymous -- zeroed out memory for heap, stack, etc.
- Backed by swap, a region of disk for storing program state when memory is scarce
- Why does sometimes a process take a while to respond after being idle?
File System Buffer Cache Integration with mmap(2)
Address Kbytes Mode Offset Device Mapping 000055bde4835000 8 r-x-- 0000000000000000 008:00008 gedit 000055bde4a36000 4 r---- 0000000000001000 008:00008 gedit 000055bde4a37000 4 rw--- 0000000000002000 008:00008 gedit 000055bde5d32000 13944 rw--- 0000000000000000 000:00000 [ anon ] 00007fc910000000 132 rw--- 0000000000000000 000:00000 [ anon ] 00007fc910021000 65404 ----- 0000000000000000 000:00000 [ anon ] 00007fc918000000 896 rw--- 0000000000000000 000:00000 [ anon ] 00007fc9180e0000 64640 ----- 0000000000000000 000:00000 [ anon ] 00007fc91c750000 204 r---- 0000000000000000 008:00008 UbuntuMono-R.ttf 00007fc91c783000 644 r-x-- 0000000000000000 008:00008 libaspell.so.15.2.0 00007fc91c824000 2048 ----- 00000000000a1000 008:00008 libaspell.so.15.2.0 00007fc91ca24000 20 r---- 00000000000a1000 008:00008 libaspell.so.15.2.0
- Performance optimization
- Keeping a copy of some data
- Usually, closer to where the data is needed
- Or, something that might be reused (don't recompute)
- Used everywhere in computer systems
- Registers
- Processor caches
- File system buffer cache
- DNS caching
- memcached
- Database page cache
- Spark analytics framework
- Web browser page/image cache
- Phone email/SMS cache
Caching
- Every computer on the Internet has an IP address
- This is a 32-bit number, written as 4 8-bit values
- stanford.edu: 171.67.215.200
- Often, many computers share a single address, but let's not worry about that for now
- Network communication is in terms of these addresses
- You can't send a web request to www.stanford.edu; you can send request its IP address
- The addresses have some structure
- Stanford controls the block of 65,536 addresses starting with 171.67
- Stanford has 5 such blocks (called a /16 because the first 16 bits are specified)
- The Domain Name System (DNS) maps names like www.stanford.edu to IP addresses
- It's a network service run on some servers
- Uses a special message format, called a query: you ask a DNS resolver to answer the query, it goes out and asks other servers around the Internet and returns the result to you
- Every answer has a time-to-live field: how long is this answer valid?
- Resolvers cache the answer for at most that long: if another query comes in, answer from the cache rather than going out over the network
- Some heavily-used, shared machines (e.g., myth) run their own resolver cache as well
- When you get an IP address by associated with a network, you're given an IP address to use to query DNS with
Domain Name System (DNS)
Domain Name System (DNS) Example With dig
Domain Name System (DNS) Naming
- Example of naming and name resolution
- Turn a structured, human readable name into an IP address
- Look it up in reverse order: www.stanford.edu
- Ask root servers: "whom can I ask about .edu?"
- Ask .edu servers: "whom can I ask about stanford.edu?"
- Ask stanford.edu server: "What's the IP address of www.stanford.edu?"
- What do you do when the cache is full?
- Cache eviction policy
- Buffer cache
- Optimal policy knows what will be accessed in the future, doesn't evict those
- Let's approximate: least recently used (LRU)
- Keeping track of exact LRU is expensive, let's approximate
- Keep two FIFO queues, active and inactive
- If a page in the inactive queue is accessed, put it into the active queue
- If you need to evict, evict from head (oldest) of inactive queue
- If active queue is too long, move some pages to inactive queue
Questions with Caching
active
inactive
- DNS
- Keep record until its TTL expires
- Abstraction
- Modularity and Layering
- Naming and Name Resolution
- Caching
- Virtualization
- Concurrency
- Client-server request-and-response
- These principles come up again and again in computer systems
- As we start to dig into networking, we're going to see
- abstraction
- layering
- naming and name resolution (DNS!)
- caching
- concurrency
- client-server
Systems Principles
CS110 Lecture 14: Virtualization and Caching
By philip_levis




