PUT SOME Numba in YOUR SQLite
SLUMBA
About me
- Open source
Pythonanything - https://github.com/cpcloud
- Love interesting hacks
WARNING:
Hacks AHEAD
PLEASE:
ASK QUESTIONs
TAKEAWAY:
NUMBA iS POWEFUL
TAKEAWAY:
not Hard to extend

Extending SQlite
-
UDF: User-Defined Function
-
UDAF: User-Defined Aggregate Function
USING PYTHON
UDFS
In [6]: import sqlite3
In [7]: con = sqlite3.connect(':memory:')
In [8]: def incr(x):
...: return x + 1
...:
In [9]: con.create_function('incr', 1, incr)
In [10]: list(con.execute('select incr(1)'))
Out[10]: [(2,)]UDAFS
In [12]: class Average:
...: def __init__(self):
...: self.total = 0.0
...: self.count = 0
...:
...: def step(self, value):
...: if value is not None:
...: self.total += value
...: self.count += 1
...:
...: def finalize(self):
...: if self.count:
...: return self.total / self.count
...: return None
...:
In [13]: con = sqlite3.connect(":memory:")
In [14]: con.create_aggregate("my_avg", 1, Average)
In [15]: query = "SELECT my_avg(column1) FROM (VALUES (1), (2), (3))"
In [15]: con.execute(query).fetchall()
Out[15]: [(2.0,)]
| v |
|---|
| 1 |
| 2 |
| NULL |
| 4 |
| 5 |
total = 0.0
count = 0UDAF EXECUTION
Scratch space, step and finalize
SELECT AVG(v)
FROM ttotal = 1.0
count = 1total = 3.0
count = 2total = 3.0
count = 2total = 7.0
count = 3total = 12.0
count = 4total / countstep(1)
finalize
step(2)
step(N)
step(4)
step(5)
3.0USING The C LANGUage
Don't copy any of this code

Public service ANNouncment
SQLITE C API - STEP
(Called once for each row)
void step(sqlite3_context* ctx, int argc, sqlite3_value** argv) {
static const size_t nbytes = sizeof(Average);
void* raw_ctx = sqlite3_aggregate_context(ctx, nbytes);
Average* agg_ctx = (Average*) raw_ctx;
if (agg_ctx != NULL) {
sqlite3_value* argument = argv[0];
int argument_type = sqlite3_value_type(argument);
if (argument_type != SQLITE_NULL) {
double value = sqlite3_value_double(argument);
agg_ctx->total += value;
agg_ctx->count += 1;
}
}
}typedef struct {
double value;
int64_t count;
} Average;SQLITE C API - FINALIZE
(Called exactly once, after all rows have been traversed)
void finalize(sqlite3_context* ctx) {
static const size_t nbytes = sizeof(Average);
void* raw_ctx = sqlite3_aggregate_context(ctx, 0);
Average* agg_ctx = (Average*) raw_ctx;
if (agg_ctx != NULL) {
if (agg_ctx->count > 0) {
double average = agg_ctx->total / agg_ctx->count;
sqlite3_result_double(ctx, average);
} else {
sqlite3_result_null(ctx);
}
}
}GOAL:
PYTHON API + C SPEED
(Keep the stdlib API)
C refresher
- Function pointers are pointers
- Pointers are integers
- => Function pointers are integers
- Not all integers are function pointers
But some are
😈
EVIL C refresher
never call UNTRUSTED functioN pointers
SERiOUSLY, DON'T
NUMBA
NUmba
Core:
- JIT compiler for Python
Add'l Features:
-
jitclass
- Extensible
-
cfunc
- powerful static analysis
- Community
NUmba
Core:
- JIT compiler for Python
Add'l Features:
-
jitclass
- Extensible
-
cfunc
- powerful static analysis
- Community
from numba import jit
@jit
def fast_sum(array):
total = 0.0
for el in array:
total += el
return totaljitclass
In [12]: class Average:
...: value: float
...: count: int
...:
...: def __init__(self):
...: self.value = 0.0
...: self.count = 0
...:
...: def step(self, value):
...: if value is not None:
...: self.value += value
...: self.count += 1
...:
...: def finalize(self):
...: if self.count:
...: return self.value / self.count
...: return NoneIn [12]: @jitclass
...: class Average:
...: value: float
...: count: int
...:
...: def __init__(self):
...: self.value = 0.0
...: self.count = 0
...:
...: def step(self, value):
...: if value is not None:
...: self.value += value
...: self.count += 1
...:
...: def finalize(self):
...: if self.count:
...: return self.value / self.count
...: return NoneJITCLASS
// tons of runtime overhead, comparatively
typedef PyObject* Average;typedef struct {
double value;
int64_t count;
} Average;From this
To this*
more specific GOAL:
call A JITted METHOD From A C FUNCTION defined in PYTHON

... that matches the SQLite C API
@CFUNC
Kind of evil
😈
In [33]: from numba import cfunc, float64
In [34]: @cfunc(float64(float64))
...: def my_incr(x):
...: return x + 1
...:In [33]: from numba import cfunc, float64
In [34]: @cfunc(float64(float64))
...: def my_incr(x):
...: return x + 1
...:
In [35]: my_incr.address
Out[35]: 139623106748448wat
SLUMBA
- Numba: LLVM codegen/cfunc
- User: step/finalize methods
- Slumba: ???
slumba
NUMBSQL
Important Renaming information

Tying it all together
1. USER DEFINES A JITClass
from typing import Optional
from numba import jitclass
@jitclass
class Avg:
total: float
count: int
def __init__(self) -> None:
self.total = 0.0
self.count = 0
def step(self, value: Optional[float]) -> None:
if value is not None:
self.total += value
self.count += 1
def finalize(self) -> Optional[float]:
if not self.count:
return None
return self.total / self.count1. USER DEFINES A JITClass
from typing import Optional
from numba import jitclass
from numbsql import sqlite_udaf
@sqlite_udaf
@jitclass
class Avg:
total: float
count: int
def __init__(self) -> None:
self.total = 0.0
self.count = 0
def step(self, value: Optional[float]) -> None:
if value is not None:
self.total += value
self.count += 1
def finalize(self) -> Optional[float]:
if not self.count:
return None
return self.total / self.count2. numbsqL DEFINES WRAPPERS
@cfunc(void(voidptr, intc, CPointer(voidptr)))
def step(ctx, argc, argv):
raw_pointer = sqlite3_aggregate_context(ctx, sizeof(cls))
agg_ctx = unsafe_cast(raw_pointer, cls)
if not_null(agg_ctx):
agg_ctx.step(*make_arg_tuple(step_func, argv))@cfunc(void(voidptr))
def finalize(ctx):
raw_pointer = sqlite3_aggregate_context(ctx, 0)
agg_ctx = unsafe_cast(raw_pointer, cls)
if not_null(agg_ctx):
result = agg_ctx.finalize()
if result is None:
sqlite3_result_null(ctx)
else:
result_setter = get_result_setter(result)
result_setter(ctx, result)@cfunc(void(voidptr, intc, CPointer(voidptr)))
def step(ctx, argc, argv):
raw_pointer = sqlite3_aggregate_context(ctx, sizeof(cls))
agg_ctx = unsafe_cast(raw_pointer, cls)
if not_null(agg_ctx):
agg_ctx.step(*make_arg_tuple(step_func, argv))STEp
- Allocate space for the class
- Cast pointer to our type
- If allocation didn't return a null pointer
- construct an argument tuple given a function signature and arguments
- Call the step method

@cfunc(void(voidptr, intc, CPointer(voidptr)))
def step(ctx, argc, argv):
raw_pointer = sqlite3_aggregate_context(ctx, sizeof(cls))
agg_ctx = unsafe_cast(raw_pointer, cls)
if not_null(agg_ctx):
agg_ctx.step(*make_arg_tuple(step_func, argv))STEp
@cfunc(void(voidptr, intc, CPointer(voidptr)))
def step(ctx, argc, argv):
raw_pointer = sqlite3_aggregate_context(ctx, sizeof(cls))
agg_ctx = unsafe_cast(raw_pointer, cls)
if not_null(agg_ctx):
agg_ctx.step(*make_arg_tuple(step_func, argv))
To clarify what's happening here:
- make_arg_tuple is producing a tuple
- numba recognizes that the tuple has the same number of arguments as the step call
- unrolls the tuple into a sequence of loads
- passes that to the method


TYPE INFERENCE IS HARD ...
# double my_func(sqlite3_context* ctx,
# int64_t narg,
# sqlite3_value**);
@cfunc(float64(voidptr, int64, CPointer(voidptr)))
def step(ctx, argc, argv):
args = () # tuple of *shrug*
for i in range(argc):
# sqlite3_value* argument
arg = argv[i]
# note: *runtime* type
value_type = sqlite3_value_type(arg)
# check the runtime type
if value_type == SQLITE_FLOAT:
args += (sqlite3_value_double(arg),)
elif value_type == SQLITE_INTEGER:
args += (sqlite3_value_int64(arg),)
# this is our jitclass method, and we must
# know the number of arguments and their
# types at *compile* time
return agg_ctx.my_jitclass_method(*args)... BUT we require
argument types
WhaT are we solving??
TypE inference is hard not necessary
def codegen(context, builder, signature, args):
_, argv = args
converted_args = []
for i, argtype in enumerate(argtypes):
instr =
converted_args.append(instr)
res = context.make_tuple(
builder, tuple_type, converted_args)
return imputils.impl_ret_untracked(
context, builder, tuple_type, res)

make_arg_tuple
Face-melting calls into llvmlite
make_arg_tuple
converted_args = []
for i, argtype in enumerate(argtypes):
# get the appropriate ctypes extraction routine
ctypes_function = VALUE_EXTRACTORS[argtype]
# create a numba function type for the converter
converter = ctypes_utils.make_function_type(ctypes_function)
# get the function pointer instruction out
fn = context.get_constant_generic(
builder, converter, ctypes_function)
# get a pointer to the ith argument
element_pointer = cgutils.gep(builder, argv, i)
# deref that pointer
element = builder.load(element_pointer)
# call the value extraction routine
value = builder.call(fn, [element])
# add value to the argument list
converted_args.append(value)sqlite3_value_double🐍double my_udf(double value);void step(sqlite3_context* ctx, int argc, sqlite3_value** argv);element_pointer = argv + i;element = *element_pointer;double value = sqlite3_value_double(ctx, element);double (*fn)(sqlite3_context*, double);

my_udf(*converted_args)taken from the user-defined signature
3. NUMBA JITS all the things

numba
Python
numbsql

LLVM
4. USER REGISTERS THE AGG WITH THE DB
>>> con = sqlite3.connect(...)
>>> create_aggregate(con, 'myavg', 1, Avg)What does numbsql PROVIDE?
numbsql adds the following Numba intrinsics
-
sizeof
-
unsafe_cast
-
safe_decref
-
get_sqlite3_result_function
-
is_not_null_pointer
-
init
-
make_arg_tuple
QUESTIONS?

benchmarks
WHole-TABLE AGG
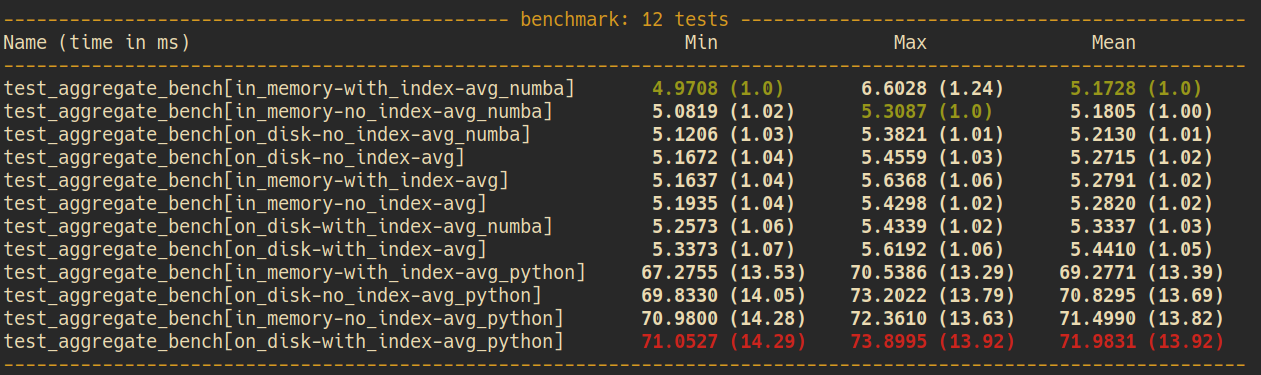
SQLite Builtin
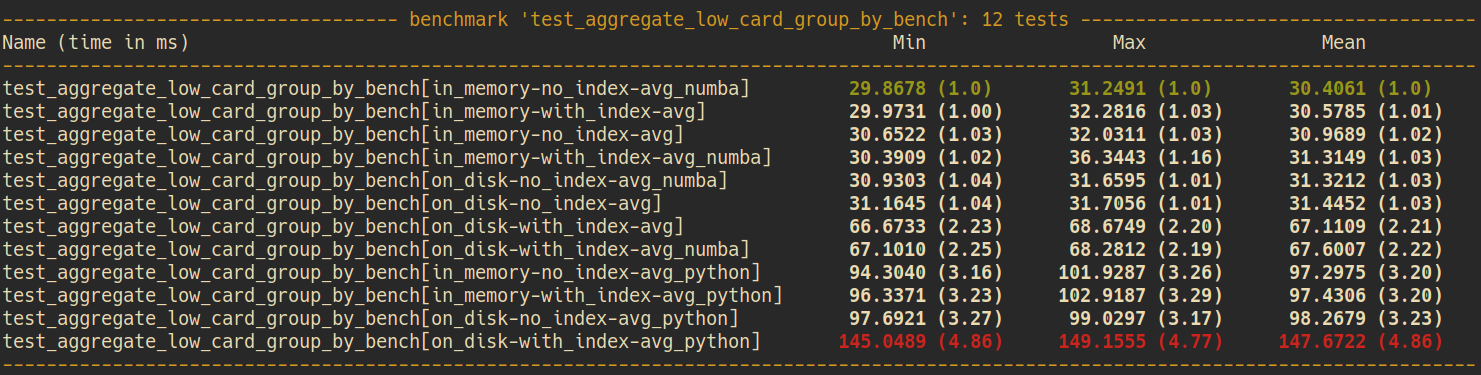
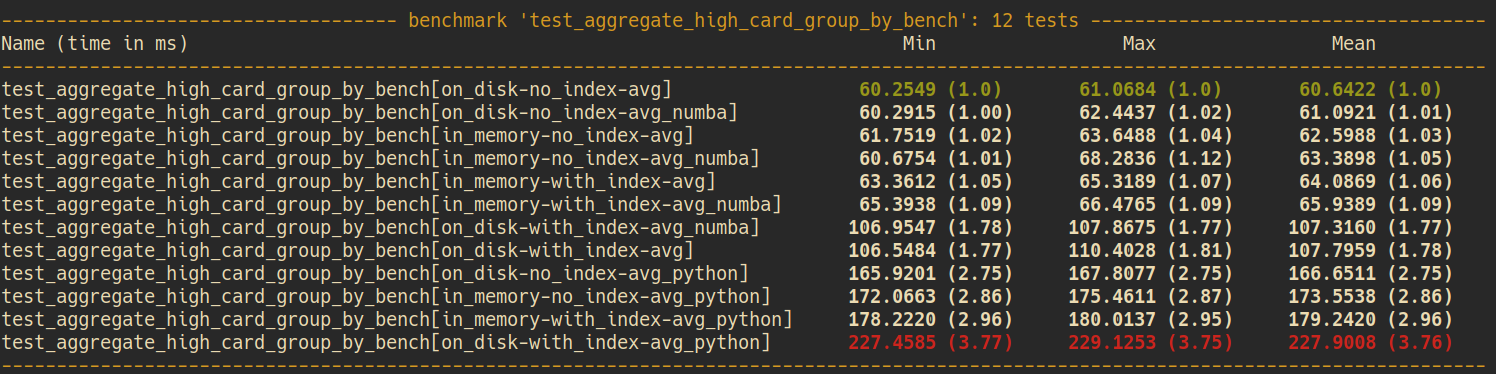
Legend
Numba
Python
LOW CARD. GROUP BY
HIGH CARD. GROUP BY
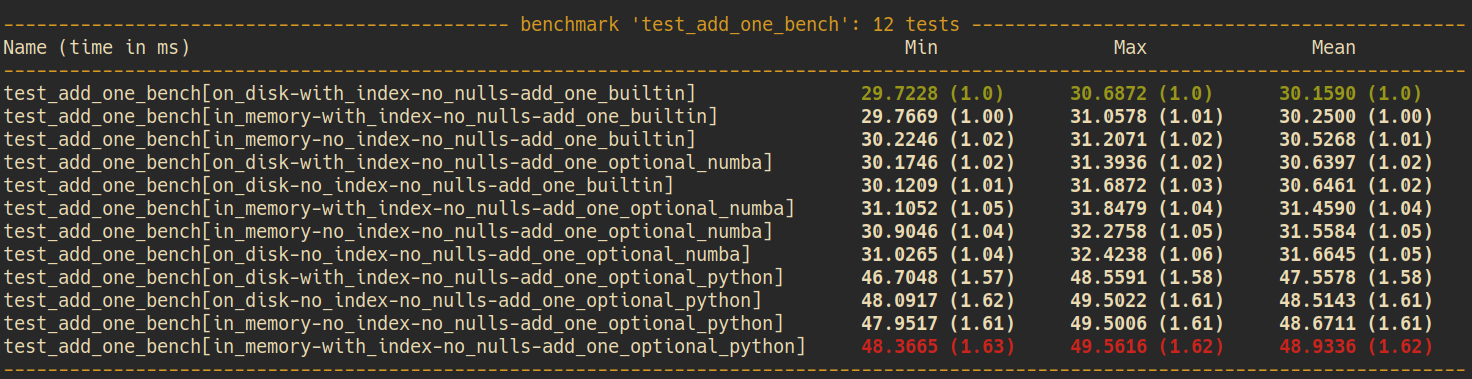
Scalar ADD ONE
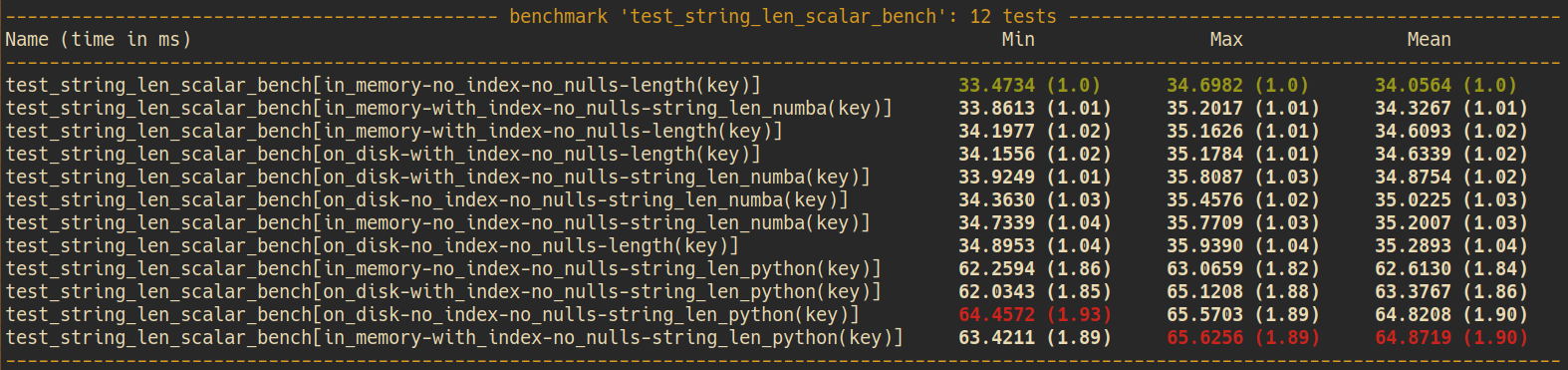
Scalar string length
what numbsql CAN't do
STATEFUL HEAP STUFF
- String support is limited to scalar functions
- No support for BLOB (yet)
- No support for complex data types
GENERAL ISSUES WITH NUMBA
- Memory management inflexible
- jitclass performance in some scenarios
- custom intrinsics can be unapproachable
Thank you!
slumba
By Phillip Cloud
slumba
Melt your mind by learning how to run jit-compiled numba functions inside of SQLite. Not for the faint of heart.




