

Piotr Żelasko
Research scientist at CLSP, John's Hopkins University. PhD @ AGH-UST in Cracow. My interests are automatic speech recognition, natural language processing, C++ and Python, machine learning and deep learning, and jazz music.
Paper authors: Dayana Ribas,
Emmanuel Vincent, Jose Ramon Calvo
What were i-vectors used for again?
Since we know only Bob and Dave, which one of them is it? Or is it some stranger?
This is Bob:
And this is Dave:
Who is this?
Unlike in previous example, i-vectors dimensionality usually ranges from 300 up to even 1000!
These guys helped.
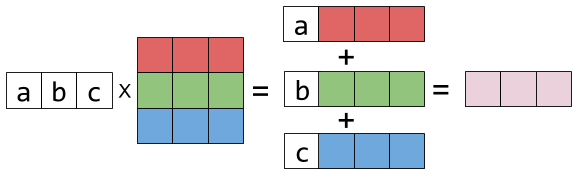
We took their means...
...and stacked them into a supervector!
However, it may be as large as
13.000 dimensions...
our i-vector
(300 dimensions)
our T matrix (maps the 13000~ dimensions to the 'most important' 300 ones)
our supervector
(13000 dimensions)
Usually, we also use LDA in order to project our i-vector into another vector space which maximises discriminability.
Something like that...
We've got different representations so far:
We haven't accounted much for channel variability so far.
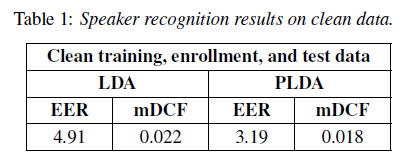
We can train speaker recognition system on a clean set of data...
... but will it generalise well on real-life data?
... especially clean data we usually get in lab conditions...
(no)
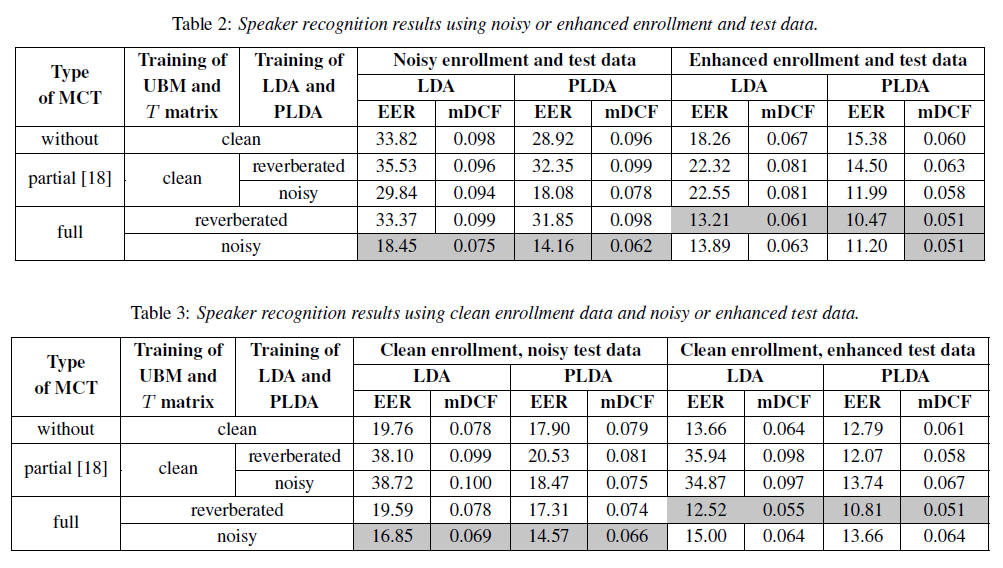
Multicondition training! (MCT)
Add some reverberation and noise to make the data dirty...
... add the dirty data to the training set...
... voila!
(basically, that's it)
In total,
Speaker recognition databases are still mostly single-channel; but today, with multi-microphone systems being everywhere, we can use multiple recording channels and use some pretty awesome denoising multichannel algorithms to improve our input!
The authors observed that it's common tendency to apply MCT only during LDA training; They claim to be the first to try to use it while training the UBM and the T matrix.
By Piotr Żelasko
Presentation about a paper by Dayana Ribas, Emmanuel Vincent and Jose Ramon Calvo (it's not mine, all copyright belongs to the authors) from Interspeech 2015




