


Piotr Żelasko
Research scientist at CLSP, John's Hopkins University. PhD @ AGH-UST in Cracow. My interests are automatic speech recognition, natural language processing, C++ and Python, machine learning and deep learning, and jazz music.
Author: mgr inż. Piotr Żelasko
Supervisor: dr hab. inż. Bartosz Ziółko
Reviewers: prof. dr hab. Zygmunt Vetulani
dr hab. inż. Artur Janicki
AGH University of Science and Technology, Kraków, 30.05.2019
With time aligned transcripts:
Others:
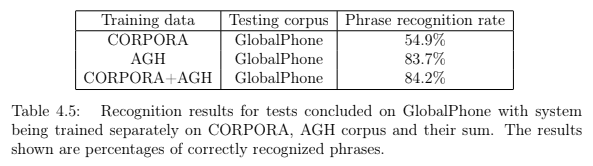
P. Żelasko, B. Ziółko, T. Jadczyk, D. Skurzok, AGH corpus of Polish speech, Language Resources and Evaluation (2016 IF = 0.922), vol. 50, issue 3, p. 585-601, Springer, 2016
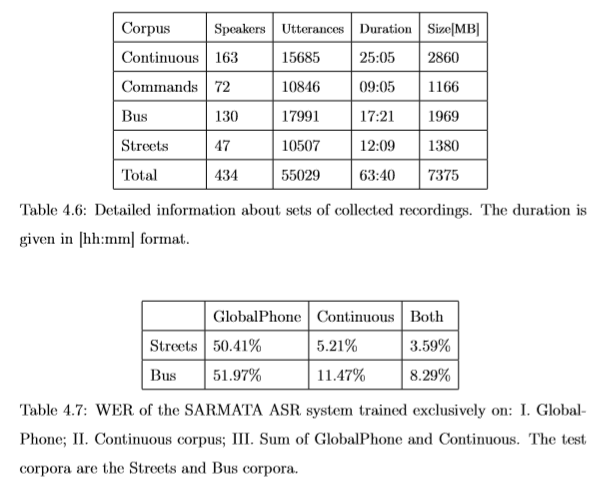
B. Ziółko, P. Żelasko, I. Gawlik, T. Pędzimąż, T. Jadczyk, An Application for Building a Polish Telephone Speech Corpus, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
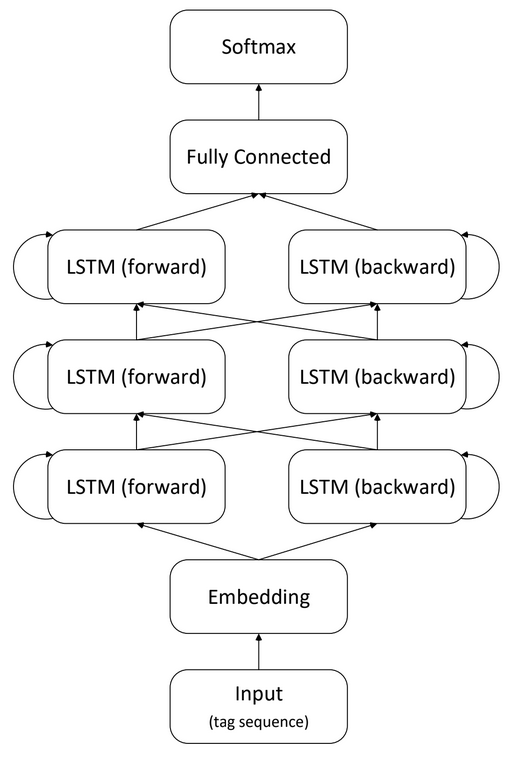
Train a BLSTM on morphosyntactic tag sequences to predict the masked tag.
| Dataset | Baseline | BLSTM |
|---|---|---|
| Train | 42.8% | 84.5% |
| Valid | 42.6% | 85.7% |
| Test | 40.3% | 74.2% |
Baseline: the most frequent tag for a given abbreviation
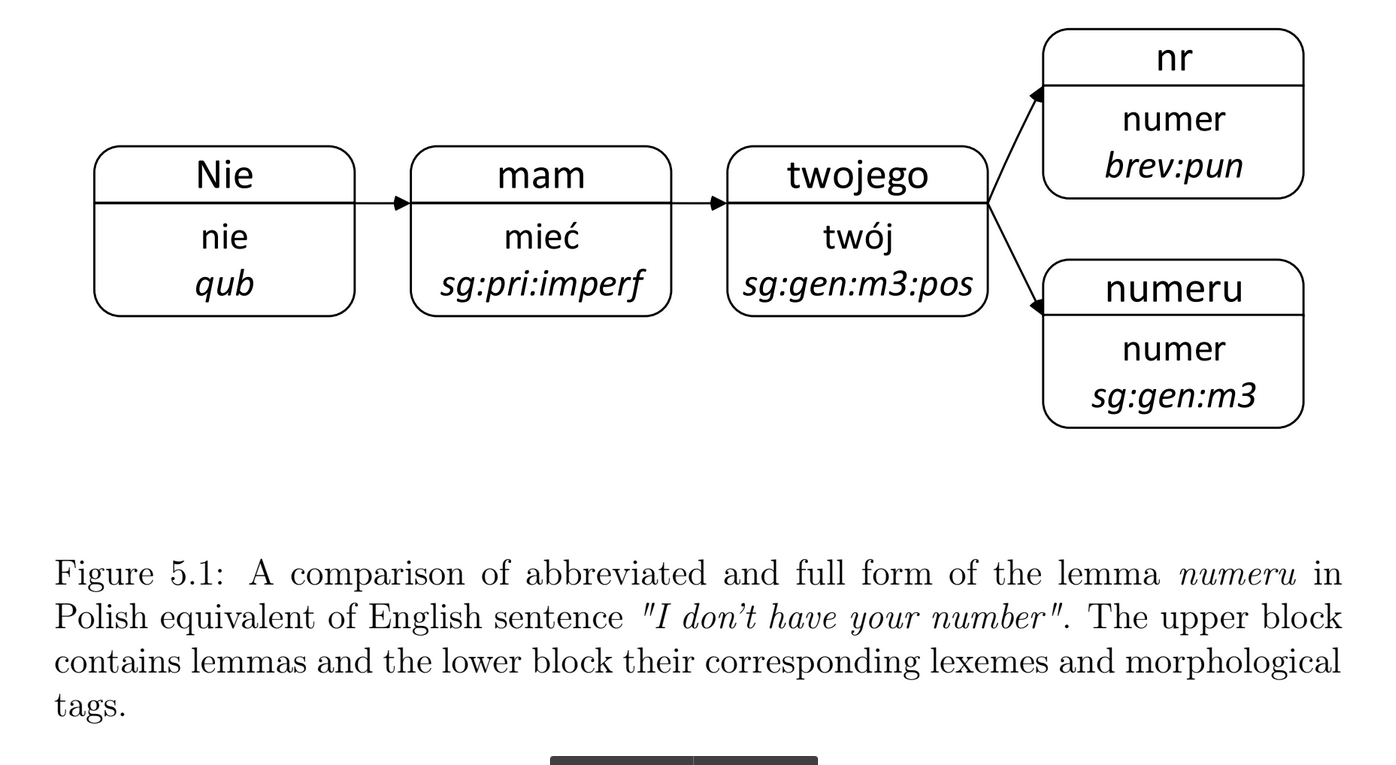
P. Żelasko, Expanding Abbreviations in a Strongly Inflected Language: Are Morphosyntactic Tags Sufficient?, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
the network seems to have learned a rule:
5 cm -> 5 centimeters
5 % -> 5 “percents”
P. Żelasko, Expanding Abbreviations in a Strongly Inflected Language: Are Morphosyntactic Tags Sufficient?, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
the network seems to have learned a rule:
5 cm -> 5 centimeters
5 % -> 5 “percents”
Another 4 % are feminine/masculine confusions in grammatical gender (bias towards masculine forms).
P. Żelasko, Expanding Abbreviations in a Strongly Inflected Language: Are Morphosyntactic Tags Sufficient?, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
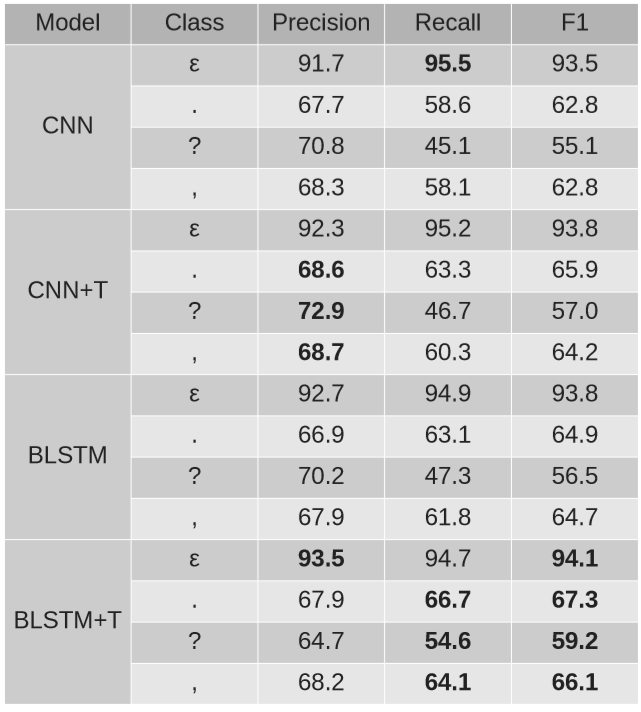
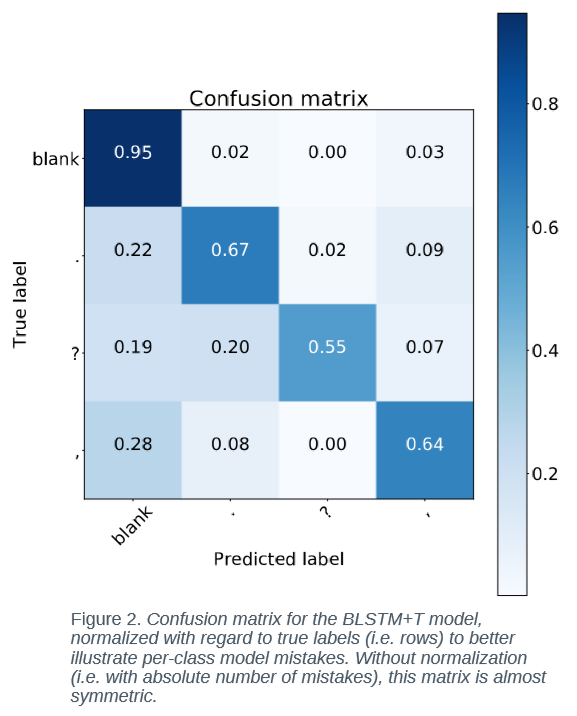
P. Żelasko, P. Szymański, J. Mizgajski, A. Szymczak, Y. Carmiel, N. Dehak, Punctuation Prediction Model for Conversational Speech, Proceedings of Interspeech 2018, Hyderabad
Fisher (Cierci et al., 2004)
+T - uses temporal features
ε - blank (no symbol)
The presented research has been applied in (at least) two speech processing systems:
P. Żelasko, B. Ziółko, T. Jadczyk, D. Skurzok, AGH corpus of Polish speech, Language Resources and Evaluation (2016 IF = 0.922), vol. 50, issue 3, p. 585-601, Springer, 2016
B. Ziółko, P. Żelasko, I. Gawlik, T. Pędzimąż, T. Jadczyk, An Application for Building a Polish Telephone Speech Corpus, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
P. Żelasko, Expanding Abbreviations in a Strongly Inflected Language: Are Morphosyntactic Tags Sufficient?, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
P. Żelasko, P. Szymański, J. Mizgajski, A. Szymczak, Y. Carmiel, N. Dehak, Punctuation Prediction Model for Conversational Speech, Proceedings of Interspeech 2018, Hyderabad
The inputs:
The outputs:
The parameters:
By Piotr Żelasko
Slides for my PhD thesis defense presentation.




