Performance of an Attention-based Model on Atomic Systems
Praharsh Suryadevara
How do atoms configure themselves?

??
\(C_1\)
\(C_2\)
\(E(C_1) < E(C_2)\)
\(\vec{F}(C_1) = 0\)

This is consequential and hard

Complicated function
Evaluating \(E(C_1)\) is \(\mathcal{O}(d^{n_e})\) exactly and \(\mathcal{O}(n_e^3)\) approximately

Drug design

New photovoltaic materials
Task
Complicated function
Given positions of atoms \(C\) predict \(\vec{F}(C)\) and \(E(C)\)
\(C\)
Equivariance: Rotational symmetry
\(\vec{F}(R(C)) = R (\vec{F}(C))\)

In \(3d\) 500x the cost
https://e3nn.org/
Equivariance: Rotational symmetry
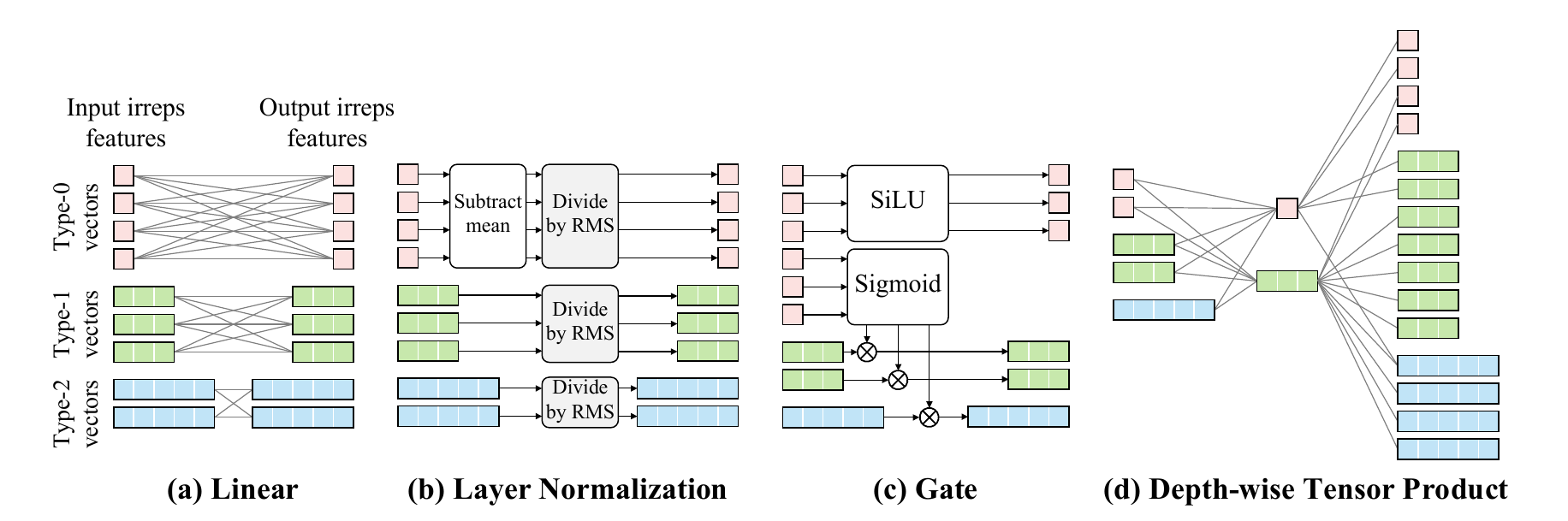
Decompose atom-atom interactions into Type-\(L\) vectors
Every Layer preserves rotational information
Example: energy
Example: Force
Equiformer: Equivariant Graph Attention Transformer for 3D Atomistic Graphs, Yi-Lun Liao et al
Equiformer = Transformer + Equivariance

Equiformer: Equivariant Graph Attention Transformer for 3D Atomistic Graphs, Yi-Lun Liao et al
Attention Is All You Need
Extra norm in the beginning
Equivariant graph attention

Nonlinear Message passing

Attention Is All You Need
Done over multiple heads
Equiformer: Equivariant Graph Attention Transformer for 3D Atomistic Graphs, Yi-Lun Liao et al
Erratum: Equivariant graph attention
Nonlinear Message passing
Attention Is All You Need
Done over multiple heads
Equiformer: Equivariant Graph Attention Transformer for 3D Atomistic Graphs, Yi-Lun Liao et al
MLP Attention
Results: Aspirin MD17

1500 epochs
- Attention models with equivariance gives SOTA on atomic force and energy predictions
- Ablation studies show equivariance and non-linear message passing improve performance!

Lower is better!
Force MAE matches exactly, energy matches upto \(\approx 0.1 \) meV
Not done on MD17
MAE on Test Set
Best!
Erratum: Results: Aspirin MD17
1500 epochs
- Attention models with equivariance gives SOTA on atomic force and energy predictions
- Ablation studies show MLP attention and non-linear message passing improve performance!

Lower is better!
Force MAE matches exactly, energy matches upto \(\approx 0.1 \) meV
Not done on MD17
MAE on Test Set
Best!
Backup
Results: Aspirin
| Model | Energy MAE | Force MAE | Energy MAE (original) | Force MAE (original) | Parameters |
|---|---|---|---|---|---|
| Non-linear message passing + MLP | 5.4 | 7.2 | 5.3 | 7.2 | 3.5 million |
| Linear message passing + MLP | 5.4 | 8.2 | - | - | 2.9 million |
| Dot product attention | 5.8 | 9.2 | - | - | 3.3 million |
1500 epochs: ~1.5 days per run
Ablation studies show MLP and non-linear message passing make a difference!
Results: Other
MD17
- Training for ~950 epochs done for full model on Ethanol, Malonaldehyde, Naphthalene, Salicyclic_acid
- Hit GPU hour limits
MD22
- Training attempted on DNA base pairs and Ac-Ala3-NHMe
- Hit Memory limits

Naphthalene

DNA base pair (AT-AT)
Acknowledgements

NYU HPC
Nitish Joshi
Assesment of an Attention-based model on Atomic systems
By Praharsh Suryadevara



