Slot-Gated Modeling for Joint Slot Filling and Intent Prediction
Slot-Intent识别任务
我要去北京的飞机票
Domain(optional):Travel
Intent:Order Ticket
Slot:destCity=北京
Slot-Intent识别任务
| 模型 | 差异 | |
|---|---|---|
| NER | CRF,Bi-LSTM(SOTA) | 没有Intent,无法联合训练; |
| Slot/Intent | Seq2Seq,Bi-LSTM(SOTA) | 有Intent可以联合训练,很多时候是人工构造数据,专攻特定领域; |
| 中文分词(Word Seg) | Bi-LSTM(SOTA) | 不用CRF和Seq2Seq;数据集差异性大; |
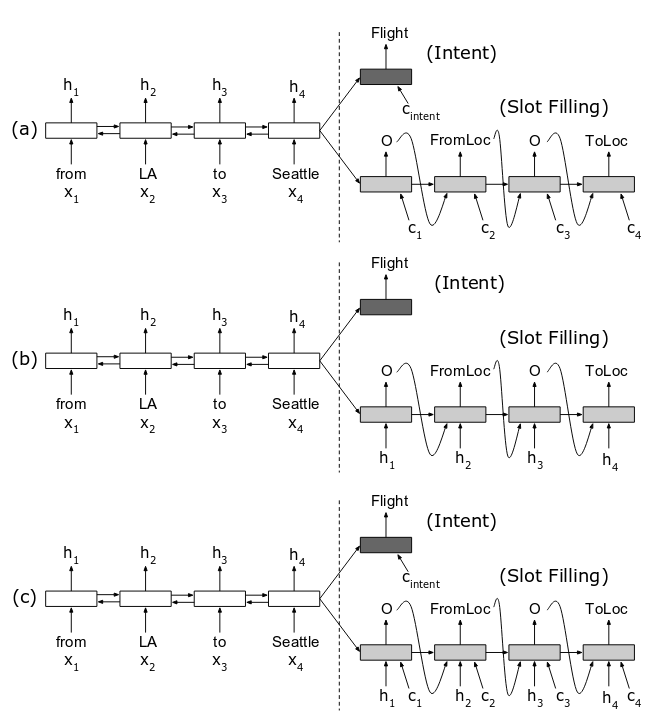
以前的工作
Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling (Bing Liu, Ian Lane, 2016)
这篇paper的工作
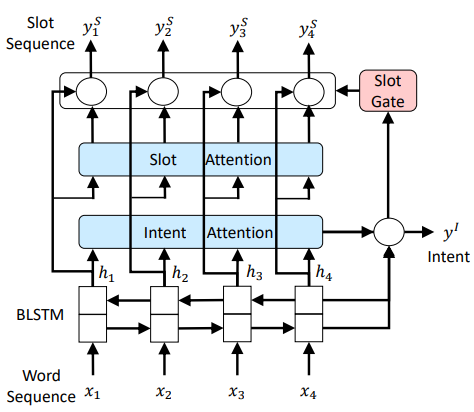
特点:
1、取消了Output部分的前向依赖
2、增加了有Intent信息参与的Slot Gate
计算Attention
输入 h_1, h_2, h_3, ..., h_i, ...
c^I = c^S_T
a^S_{i,j} = \frac{exp(e_{i,j})}{\sum^T_{k=1} exp(e_{i,k})}
e_{i,k} = \sigma(W^S_{he}h_k)
c^S_i = \sum^T_{j=1}a^S_{i,j}h_j
Slot Atten
Intent Atten
输出 y^S_1, y^S_2, y^S_3, ..., y^S_T, y^I
y^S_i = softmax(W^S_{hy} (h_i + c^S_i))
y^I = softmax(W^I_{hy} (h_T + c^I))
Intent Ouput
Slot Output
Intent Atten
Slot Atten
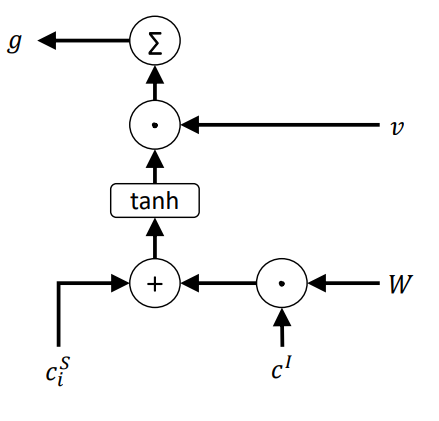
Slot Gate
y^S_i = softmax(W^S_{hy} (h_i + c^S_i \cdot g))
g = \sum v \cdot tanh(c^S_i + W \cdot c^I)
Slot Gate
y^S_i = softmax(W^S_{hy} (h_i + h_i \cdot g))
g = \sum v \cdot tanh(h_i + W \cdot c^I)
Intent Attention Only
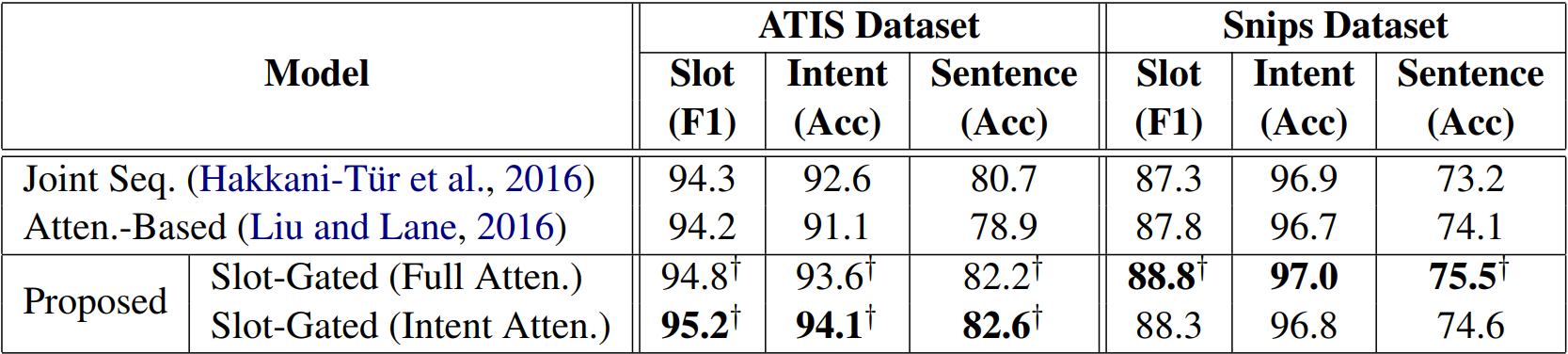
Result
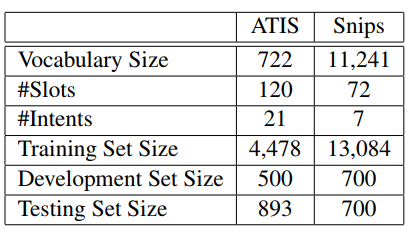
ATIS比Snips用Full Atten的效果差,作者认为可能是ATIS数据集比较小,完成任务的所需信息并不需要那么多
Slot-Gated Modeling for Joint Slot Filling and Intent Prediction
By qhduan



