An Introduction to
Data Linking
Rachel House
slides.com/rachhouse/intro-to-data-linking
what is data linking?

Data linking is the task of identifying, matching, and merging records from multiple datasets that correspond to the same entities.
P. Christen, Data Matching, Data-Centric Systems and Applications.
Data deduplication is a subset of data linking
in which you identify and consolidate records
from the same dataset that refer to the same entity.
data linking
record linkage
data matching
entity resolution
object identification
field matching
data linking
record linkage
data matching
entity resolution
object identification
field matching

What is Bread Zeppelin's list of unique customers?
Company A:
Company B:
Dirigible Depot
Beautiful Bakery
Bread Zeppelin
J. Smith
B. Jones
Mr. Incredible
Jane W.
Bobby Tables
L. Luthor
C. Kent
B. Parr
W. White
Fred
H. Eisenberg
Bobby Jo
Jane
Superman
We need to integrate data from disparate sources to:
We are generating an inconceivable amount of data.

- improve data quality,
- enrich existing data sources,
- and facilitate data mining.
Why does the need for data linking exist?
Data linking is not a new problem.
1946: The term record linkage is coined.
1950s - 1960s: Howard Newcombe proposes to use computers to automate data matching.
1969: Ivan Fellegi and Alan Sunter publish their probabalistic record linkage paper.
1990s: William Winkler develops techniques for probabalistic record linkage at the US Census Bureau.
1974: Benjamin Okner publishes a paper on existing data matching projects.
Late 1990s: Computer scientists and statisticians start cross-referencing data linking work.
National Census
Health Sector
Data linking is heavily used in important domains.
National Security
Crime and Fraud
Detection and Prevention
Business Mailing Lists
People are the most linked entity.
We don't always have a GUID.

Why is data linking challenging?
The computational complexity grows quadratically.
Data is often dirty and incomplete.
There is a lack of training data.
Privacy and confidentiality are key concerns.
why should you care about data linking?

It's a really interesting problem!
No, seriously!

Professionally:
1
You've already had to integrate data from different sources...

...or it is inevitable that you will.
You still haven't figured out how coupon mailers follow you from address to address.

Personally:
2
Your privacy is important, and you need to be aware of how your data is used and can be used.
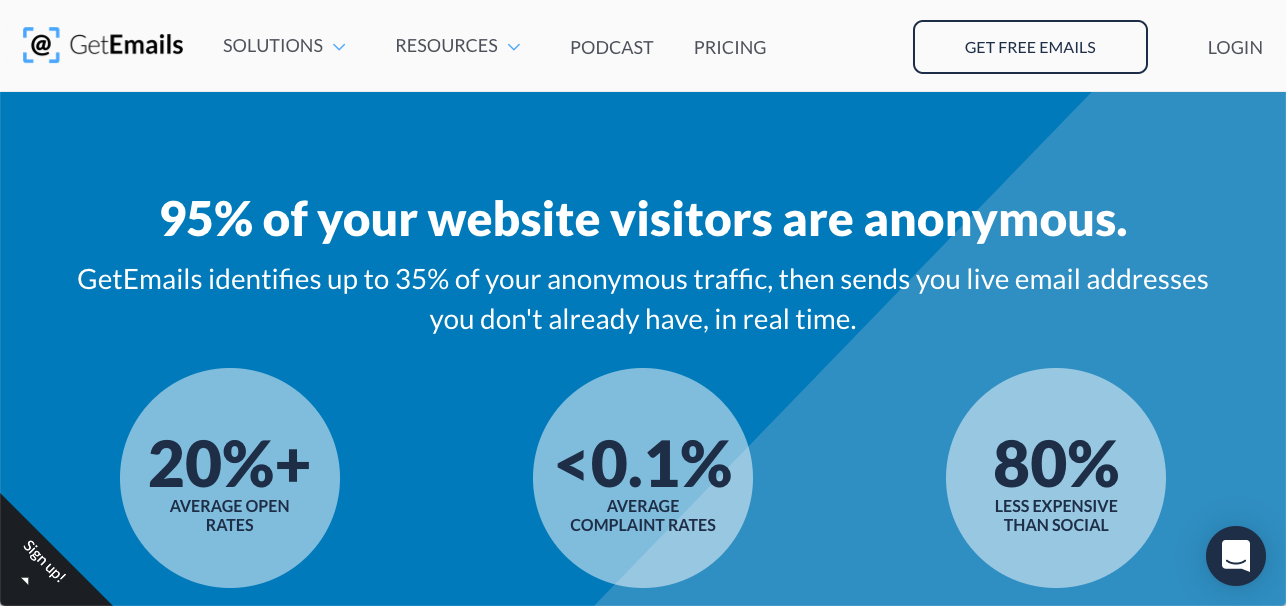
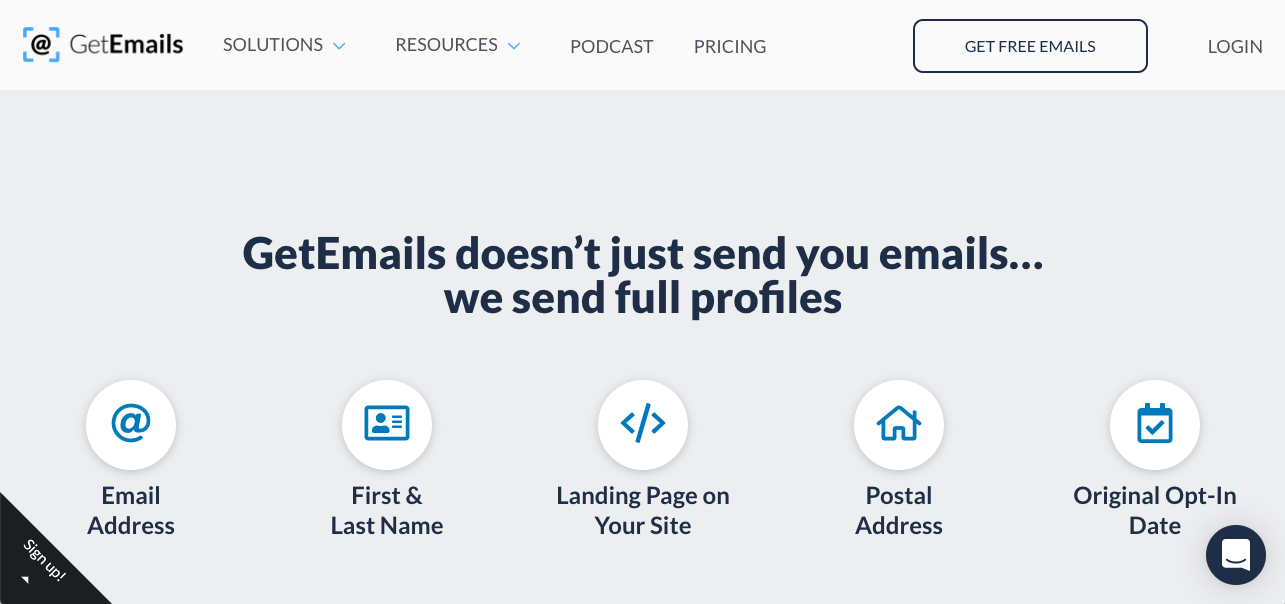
Your email, full name, and home address, supplied to a company whose website you anonymously browsed.
the linking process

Alice
Avery
Bob
Claire
Dale
First Name
Last Name
DOB
Byrd
Conners
Dooley
...
9 June 04
10/01/1985
bbyrd@aol.com
12/26/1952
2010-03-14
avers@gmail.com
doolzroolz@me.com
...
...
...
...
Records
Attributes
Name
B. Byrd
Anna Avers
Hugh Man
Age
Birthday
May 5th
10 Jan
36
bbyrd@aol.com
17
aa7r@school.edu
bot123@site.biz
...
...
...
...
Cleaning
Indexing (Blocking)
Comparing
Classification
Evaluation
Dataset A
Dataset B
Adapted from: P. Christen, Data Matching, Data-Centric Systems and Applications.
Cleaning
Link
Non-Link
Potential Link
Human Review
Cleaning
Comparing
Blocking
Classification
Evaluation
Cleaning
?
Alice
Avery
Bob
Claire
Dale
First Name
Last Name
DOB
Byrd
Conners
Dooley
Name
B. Byrd
Anna Avers
Hugh Man
Age
Birthday
...
9 June 04
10/01/1985
May 5th
10 Jan
36
bbyrd@aol.com
bbyrd@aol.com
12/26/1952
2010-03-14
avery@gmail.com
17
aa7r@school.edu
bot123@site.biz
doolzroolz@me.com
...
...
...
...
...
...
...
...
Records
Attributes
cleaning

Cleaning
Indexing (Blocking)
Comparing
Classification
Evaluation
Dataset A
Dataset B
Cleaning
Link
Non-Link
Potential Link
Human Review
Real-world data is dirty, noisy, inconsistent, and incomplete.
Data varies widely in format, structure, and content.
Addressing these deficiencies is central to the cleaning step.


The data quality struggle is real.
Accuracy
Consistency
Completeness
Timeliness
Believability
Smooth noisy values
Fundamental data cleaning tasks:
1
2
3
Identify and correct inconsistent values
Handle missing values
The how of cleaning is infinite.
Let's focus on the what.
compliments of xkcd.com
Raw input data is converted into well-defined and consistent formats.
If data cleaning was successful...
Equivalent information is encoded in the same way for the separate datasets.
blocking

Cleaning
Indexing (Blocking)
Comparing
Classification
Evaluation
Dataset A
Dataset B
Cleaning
Link
Non-Link
Potential Link
Human Review
But first, a thought experiment...
A1
A2
A3
B1
B2
B3
This does not scale well.
records in each dataset
10
100
1,000
10,000
100,000
1,000,000
10,000,000
100,000,000
: comparisons
100
10,000
1,000,000
100,000,000
10,000,000,000
1,000,000,000,000
100,000,000,000,000
10,000,000,000,000,000
(at 100,000 comparisons per second)
0.001s
0.1s
10s
16.6 min
27.7 hours
116 days
31 years
3,170 years
comparison time
We need to intelligently decide which records to compare, so that we can reduce the comparison space.
This is where indexing comes in.

Indexing filters out record pairs that are unlikely to correspond to links.
Ideally, indexing minimizes:

record pairs to compare
missed
true links
Conventional indexing technique
Blocking
Break record pairs into comparable blocks, based on a blocking key
Record pair comparison is symmetric, each unique pair is only compared once
Individual blockers should be simple,
but can be combined logically with and/or
A successful blocking key results in similar records being grouped in to the same blocks.
attribute
data quality
attribute value frequencies

Phonetic Encodings
Convert a string (usually a name) into a code based on how it is pronounced.
Soundex
NYSIIS
Double Metaphone

christine
christina
kristina
c623
c623
k623
chra
chra
cras
krst
krst
krst
Sorted Neighborhood
Newer alternative to standard blocking
Datasets are sorted by a key
A sliding window of fixed size is moved over the datasets
Candidate record pairs are generated from records in the window at each step
Blocking vs. Sorted Neighborhood

P. Christen, Data Matching, Data-Centric Systems and Applications.
all records
blocking
candidate
record pairs

It's time to get hands-on!
comparing

Cleaning
Indexing (Blocking)
Comparing
Classification
Evaluation
Dataset A
Dataset B
Cleaning
Link
Non-Link
Potential Link
Human Review
Problem: We can't match all record pair attribute values using exact methods.
Solution: Use comparison functions which indicate how similar two attribute values are.
< \textrm{sim}(a_{i}, a_{j}) <
exact match
completely different


0
1
strings
dates
numbers
locations
What sort of attribute types will we compare?
names
Are the two values identical?
Exact Comparisons
sim_exact("hello", "hello")=
≠
sim_exact("hello", "world")sim_exact(123, 123)Are the two truncated values exactly the same?
sim_exact_first5("97035-1234", "97035-5678")=
=
Comparisons count the
single-character operations required to transform one string to another.

Edit Distance
insert
delete
substitute
swap
Levenshtein Edit Distance
- Allowable edits: insert, delete, substitute
- Each edit has a unit cost of 1
cat
cats
1
(insertion)
blocks
2
(deletion, substitution)
socks
locks
Variations in Levenshtein Edit Distance:
Damerau-Levenshtein
Adds swapping (adjacent characters) as an edit operation.
Edit operation cost modifications
Assigns different costs for edit operations.
Hamming
Only allows substitution, strings must be of same length.
Split strings into substrings of length q characters.
Q-Gram Based Comparison
elephant
ele
lep
eph
pha
han
ant
q = 3
Similarity is based on the number of q-grams the compared strings have in common.
plant
pla
lan
ant
Jaro-Winkler String Comparison Family
Jaro
Counts number of common characters and transpositions in two strings within a window of characters.
Jaro-Winkler
Increases the Jaro similarity value for up to four agreeing initial characters.
Numbers
Maximum absolute difference, relative difference
Non-string attribute comparisons
Dates and Times
Absolute date-time difference (days, hours, minutes, etc.)
Locations
Geographical distance measures, e.g. Haversine distance
"Left" Record
"Right" Record
a1
a2
a3
a4
b1
b2
b3
b4
sim(a1, b1)
sim(a2, b2)
sim(a3, b3)
sim(a4, b4)
Comparison Vector
The output of the comparison step is a comparison vector for every candidate record pair.
id
first name
last name
street num
street
city
state
a1
elizabeth
b1
liz
smith
smith
55
42
main st
main st ne
aberdeen
abilene
tx
tx
0.7
1.0
0.0
0.9
0.3
1.0
0.3

Let's continue our hands-on activity.
classification

Cleaning
Indexing (Blocking)
Comparing
Classification
Evaluation
Dataset A
Dataset B
Cleaning
Link
Non-Link
Potential Link
Human Review
Classification is based on the similarity values in the comparison vectors of the record pairs.
comparison vectors == feature vectors
id
first name
last name
street num
street
city
state
a1
elizabeth
b1
liz
smith
smith
55
42
main st
main st ne
aberdeen
abilene
tx
tx
0.7
1.0
0.0
0.9
0.3
1.0
0.3
classification
links
non-links
| 0.7 | 1.0 | ... | 0.3 | 0.1 |
|---|
similarity score
(low scores)
(high scores)
potential links
The simplest classification approach!
- Sum similarity values for each comparison vector.
- Apply a threshold to the sum to determine link status.
SimSum Classification
| id | name | last name | street num | street | city | state |
|---|---|---|---|---|---|---|
| a1 | elizabeth | smith | 55 | main st | aberdeen | tx |
| b1 | liz | smith | 42 | main st ne | abilene | tx |
| 0.7 | 1.0 | 0.0 | 0.9 | 0.2 | 1.0 | 3.8 |
|---|
link
not a link
>= 3.0
< 3.0
SimSum classification & simple thresholding has drawbacks:
All attributes contribute equally toward the final summed similarity.
Information contained in individual similarity values is lost in summation.

Remember, comparison vectors == feature vectors.
Supervised Classification
Feed comparison vectors to your classification model(s) of choice to train via supervised learning.

Supervised learning requires labeled training data, which is usually non-existent or expensive to procure in the linking domain.
Threshold on trained model inference scores.
The active learning approach:
Active Learning
build classifier with small seed of examples
while model is not good enough:
classify new comparison vectors
route model results to skilled humans (SMEs)
add manually vetted results to training data set
retrain modelWith human input, active learning allows you to jumpstart a training dataset and classification model.
Clustering
Unsupervised Classification
- Each cluster consists of records referring to one (the same) entity
- No training data required
- Ideally, high intra-cluster similarity and low inter-cluster similarity
- Suited for deduplication use cases
evaluation

Cleaning
Indexing (Blocking)
Comparing
Classification
Evaluation
Dataset A
Dataset B
Cleaning
Link
Non-Link
Potential Link
Human Review
Mission Objective: Identify true links.
But, how can we evaluate if we've accomplished our goal?
you have a ground truth evaluation set
(with known true links and true non-links)...
IF

then you can easily calculate conventional ML classification metrics based on classification scores.
Optimistic solutions to acquire ground-truth datasets:
Use results from other data linking projects in the same domain.
1
Use a publicly available dataset.
2
Use synthesized data with the same characteristics as the datasets to be linked.
3
Realistic approaches to build ground-truth datasets:
Sample records from the datasets to be matched, and manually classify the pairs.
1
Iteratively build a golden evaluation set as SMEs validate model output across increasingly performant versions of your linking model.
2
0
1
Model Score
Count of Pairs

Link
Not a Link
Validation
1. It's all about the cutoff.
Model Score
Cutoff
0.65
Classify as Link
1
Classify as Non-Link
At a given model cutoff, we can calculate:
true links
true non-links
classified links
true positives
false negatives
false positives
true negatives
classified
non-links
Knowing TP, TN, FP, and FN, we can calculate:
Accuracy: Not suitable as a linking evaluation measure due to imbalanced classes.
Precision: Of the candidate pairs classified as links, the percentage that are actually true links.
F1 Score: Harmonic mean of precision and recall, combines the two metrics into a single figure.
Recall: Of the total quantity of true links, the percentage that were classified as links.
0
1
Model Score
Count of Pairs
Link
Not a Link
Validation
2. Cutoff score choices determine performance.
Model Score
Cutoff
0.65
1
0.8
0.5
↓ Precision
↑ Recall
↑ Precision
↓ Recall
0
1
Model Score
Precision/Recall Value
Recall
Precision
Metric
3. Your particular performance requirements will drive the cutoff score.
1
1
0


And now, back to the (co)laboratory.
parting thoughts

Linking is a challenging, prevalent, and revelant problem in today's data-saturated world.
The key steps of data linking are:
Block
Compare
Classify
Clean
Block
You, as a person, are the most commonly linked entity.
May you be victorious in all your (data) linking quests!

Thank You
resources

accompanying tutorials
Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection, Peter Christen.
books
open source projects & python libraries

An Introduction to Data Linking
By Rachel House
An Introduction to Data Linking
In this talk, we'll cover the basics of data linking: the need for data linking, how it works, its challenges, and practical knowledge for applying data linking to your own use cases. In the workshop version of this talk, we'll also explore data linking hands-on with Python.




