
Operational
whoami
Assess your Knowledge
Learning Objectives
- Install a Hadoop Cluster with Apache Ambari
- Describe the various services that comprise HDFS
- Run Hadoop's resource manager - YARN
- Perform basic JVM administration
- Interact with Hive
- Use Swift as an additional data storage for Hadoop

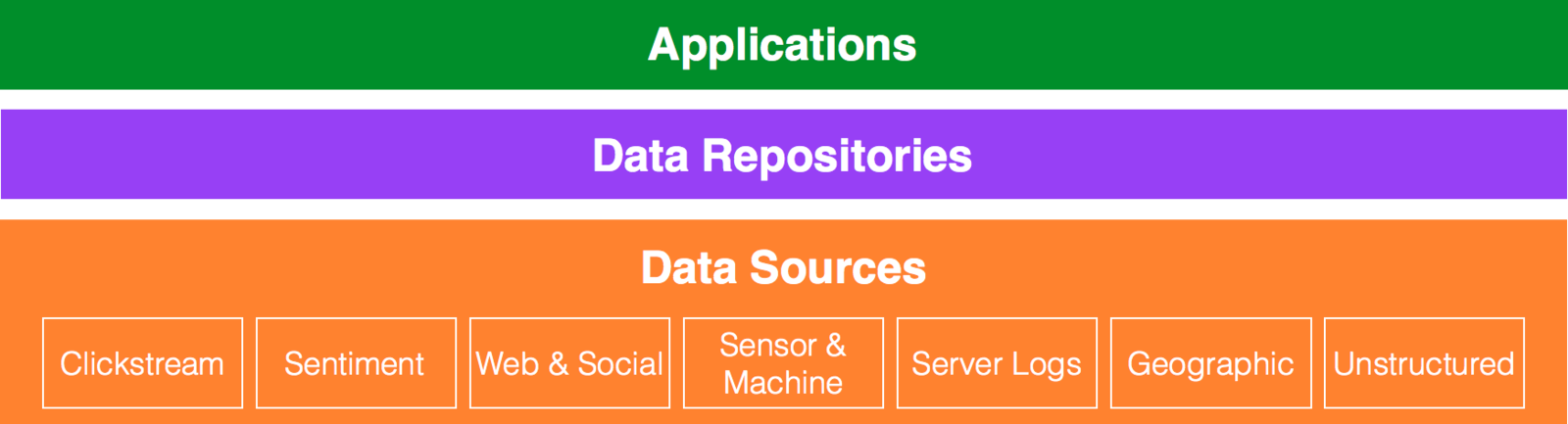
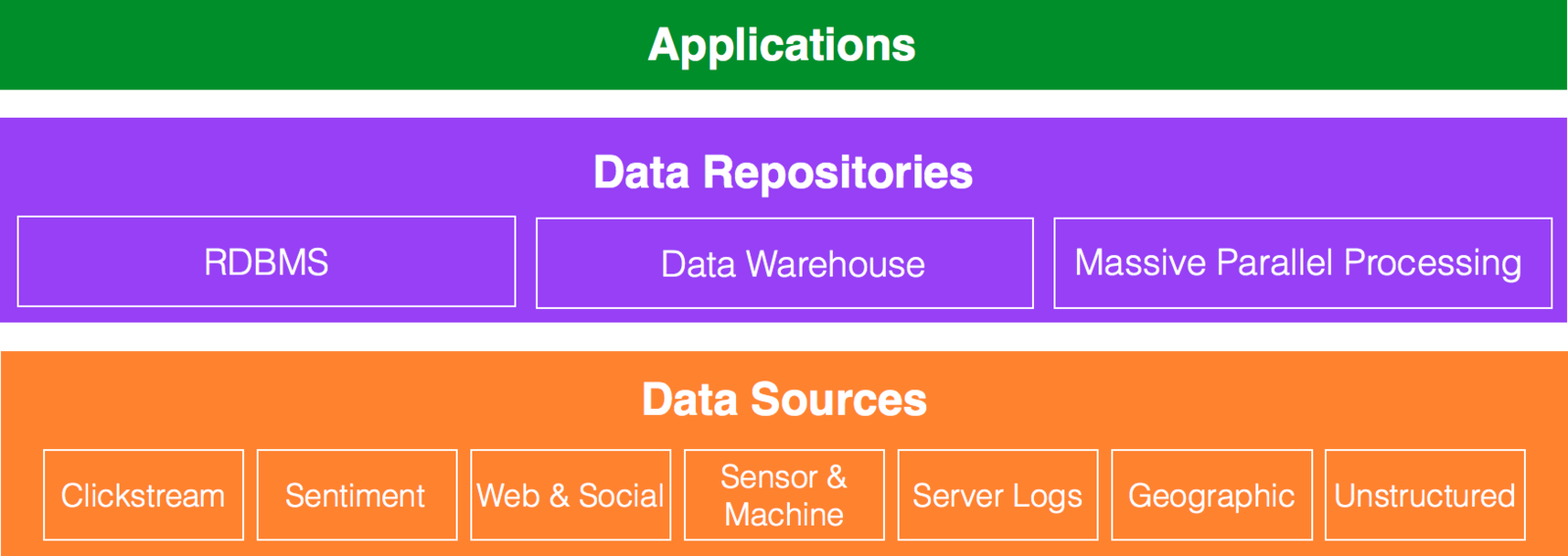
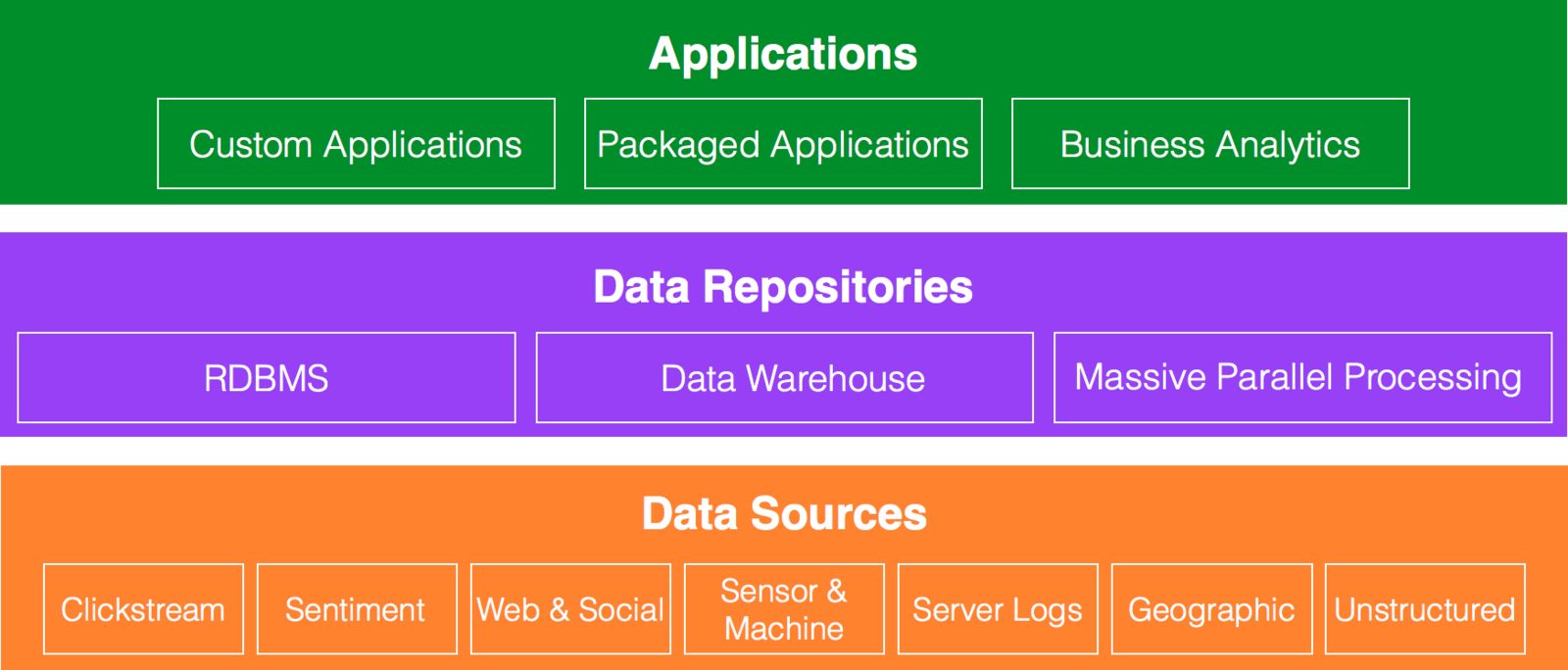
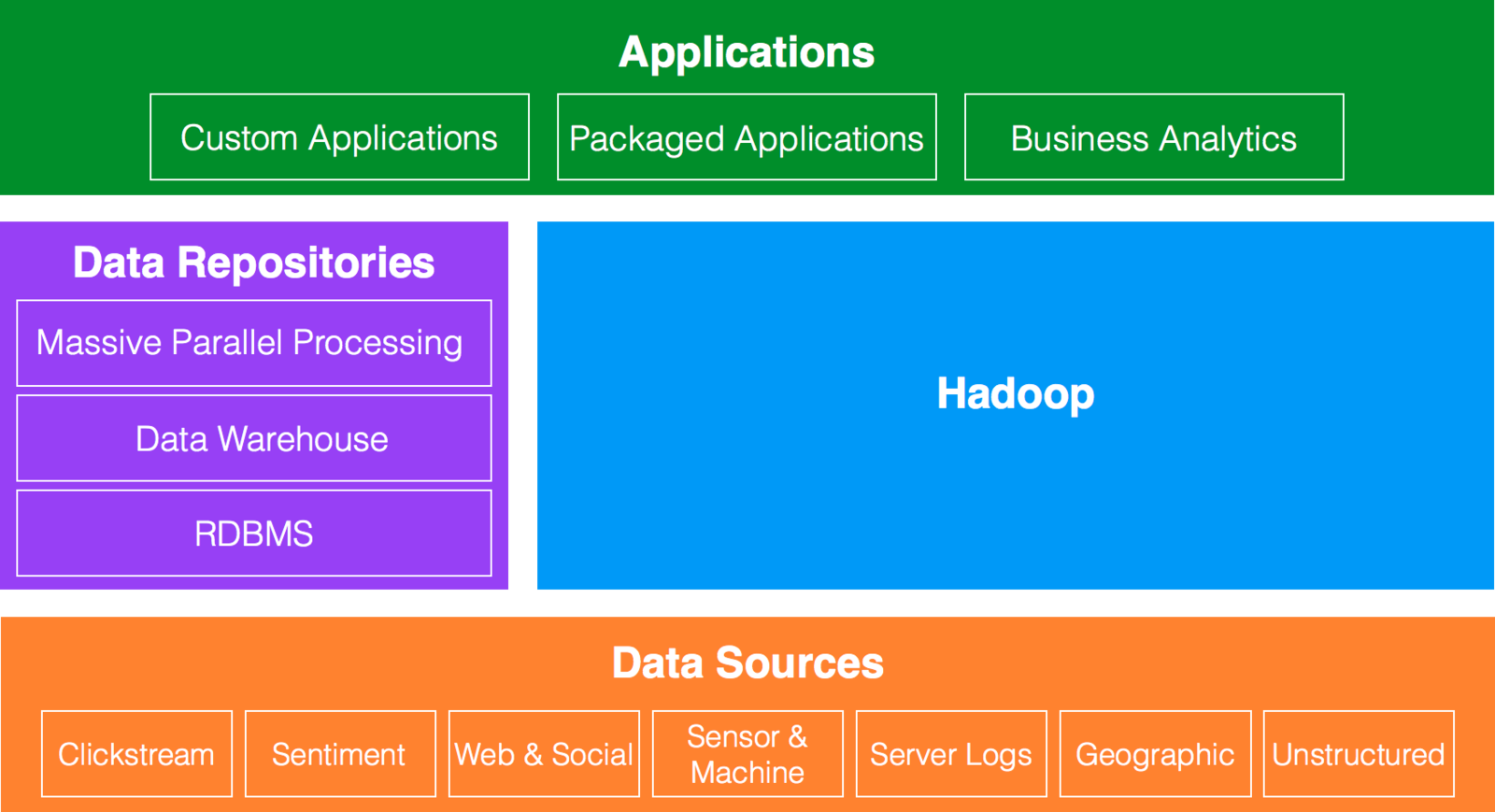
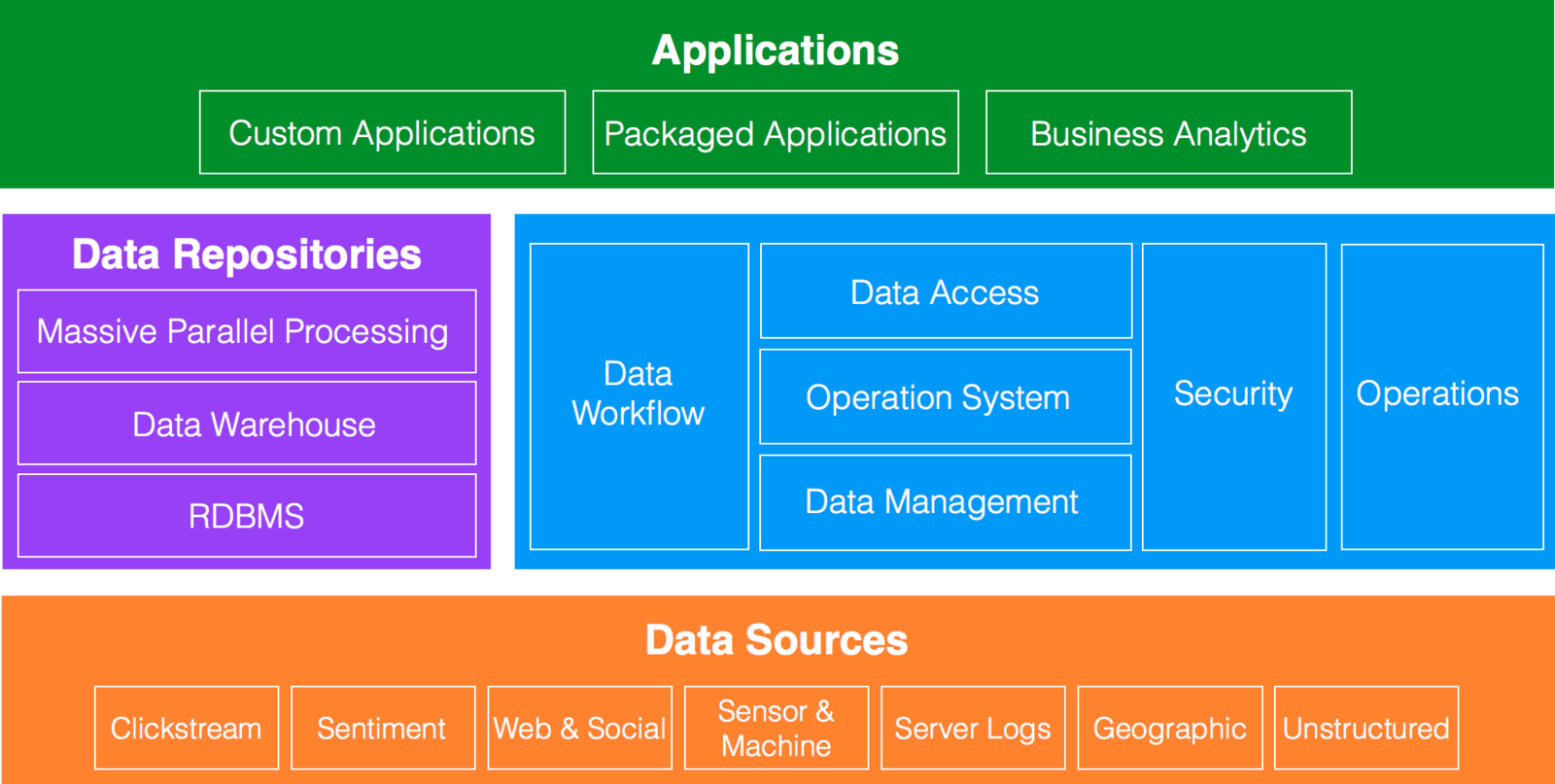
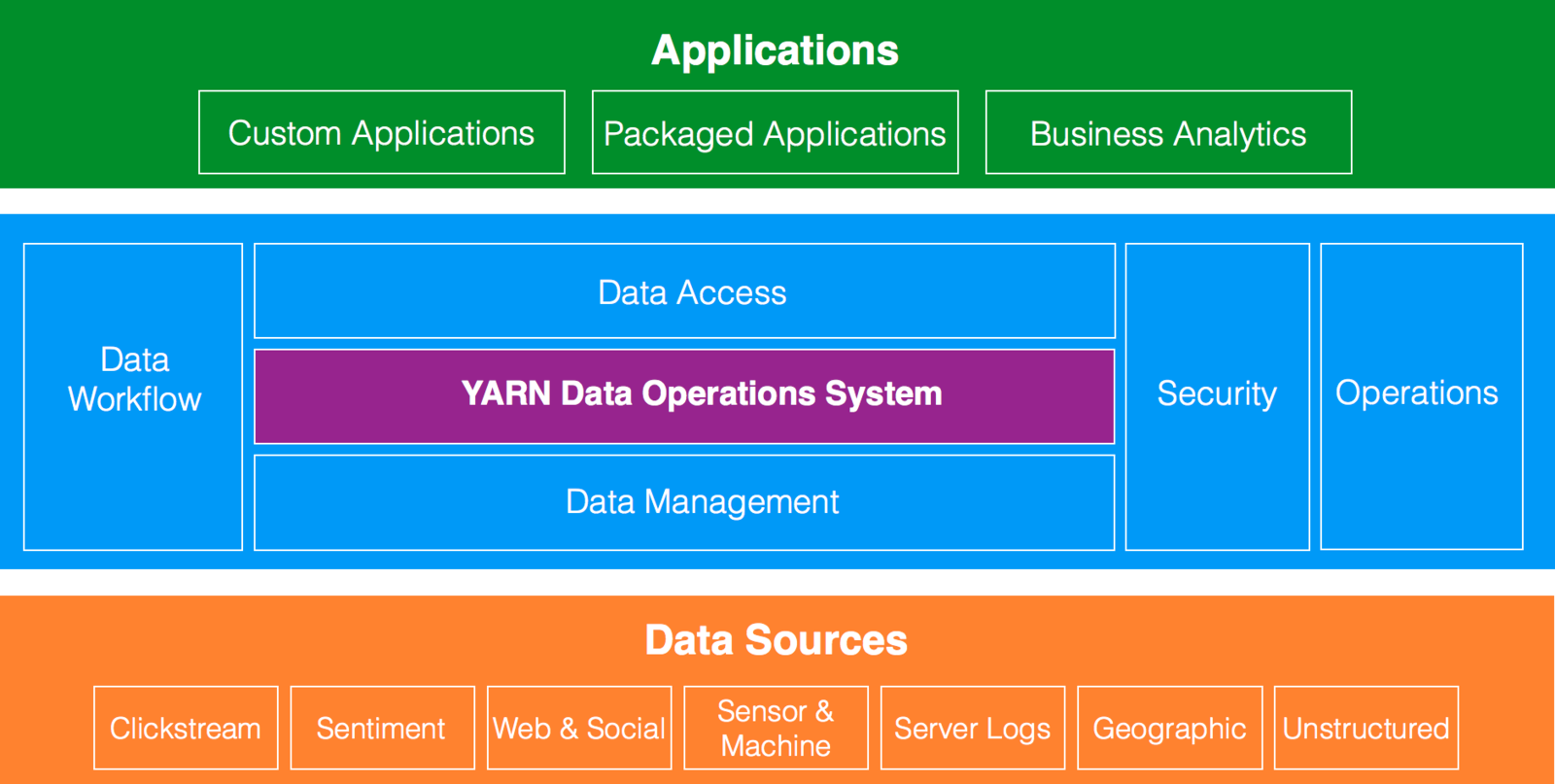
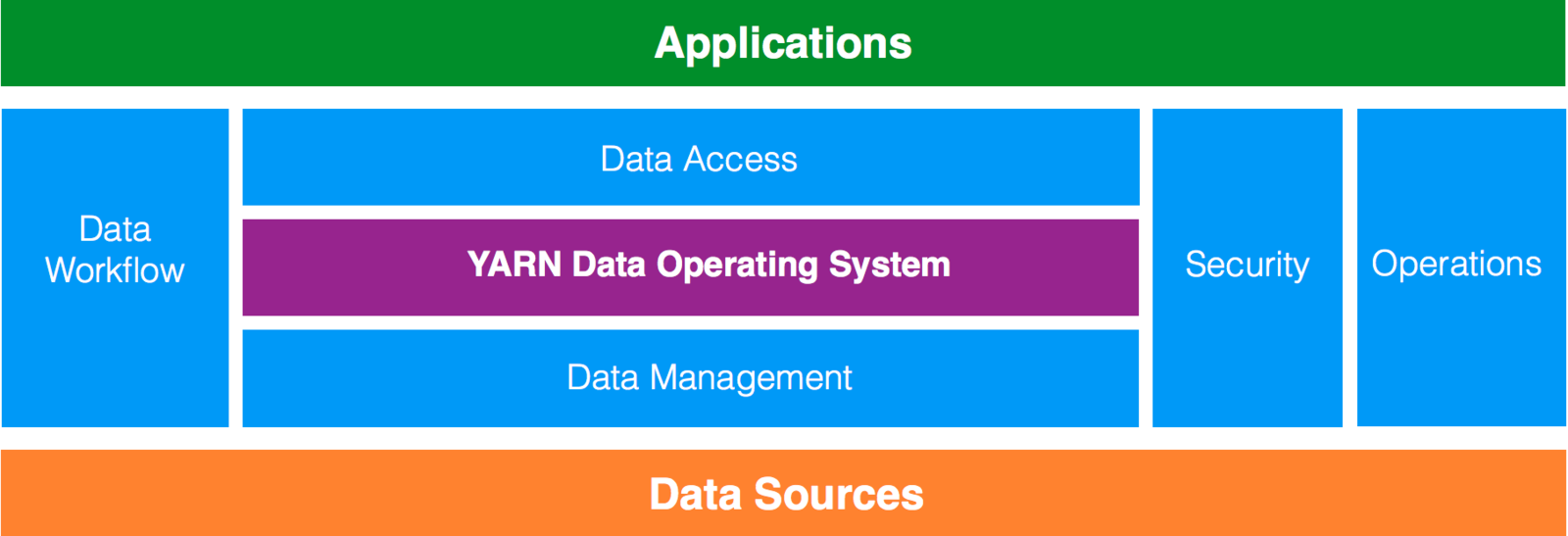
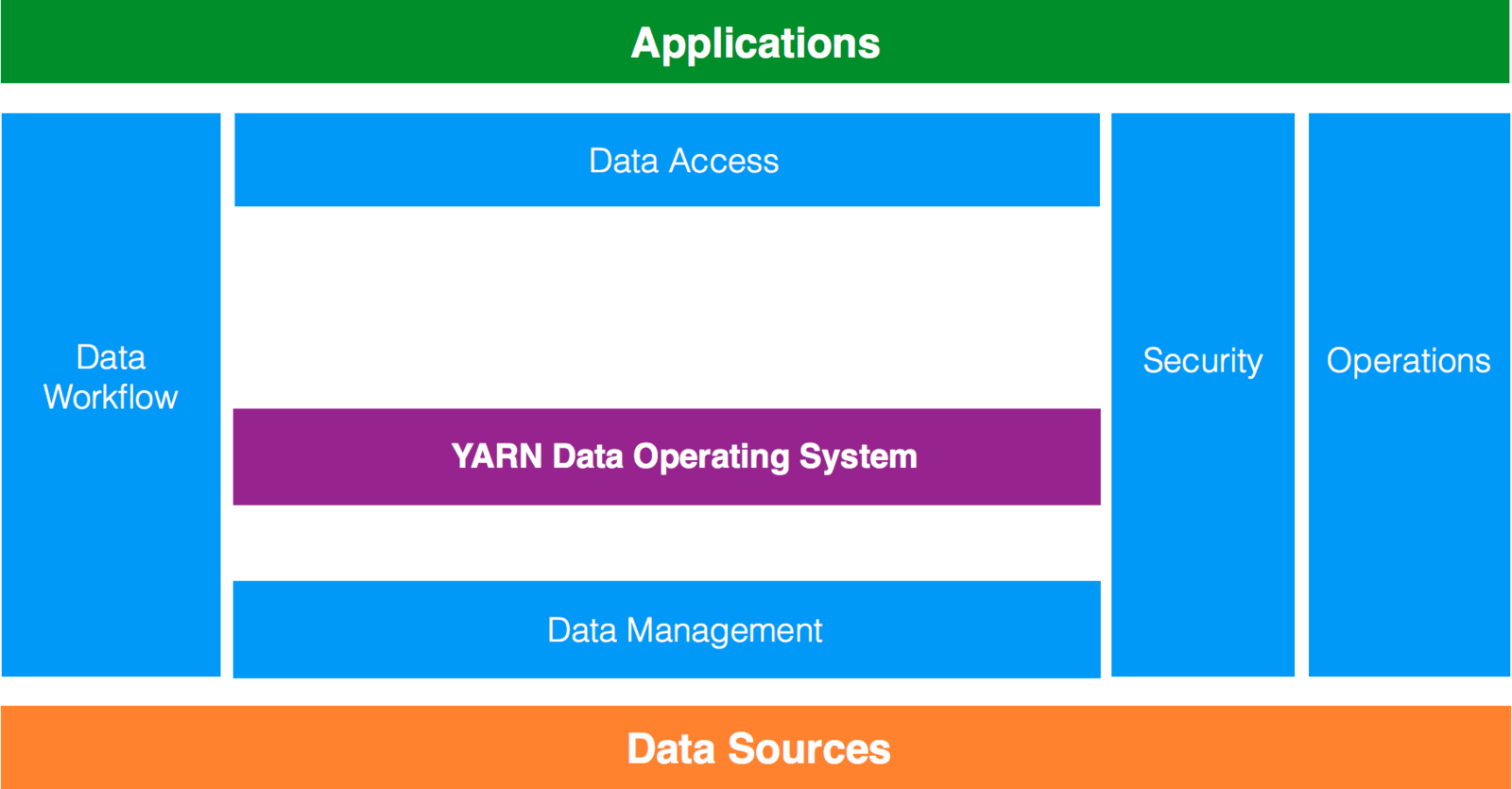
Data Architecture

Data Architecture
 "
"Data Architecture
Data Architecture
Hadoop
Hadoop
Hadoop
Hadoop
Hadoop
Hadoop
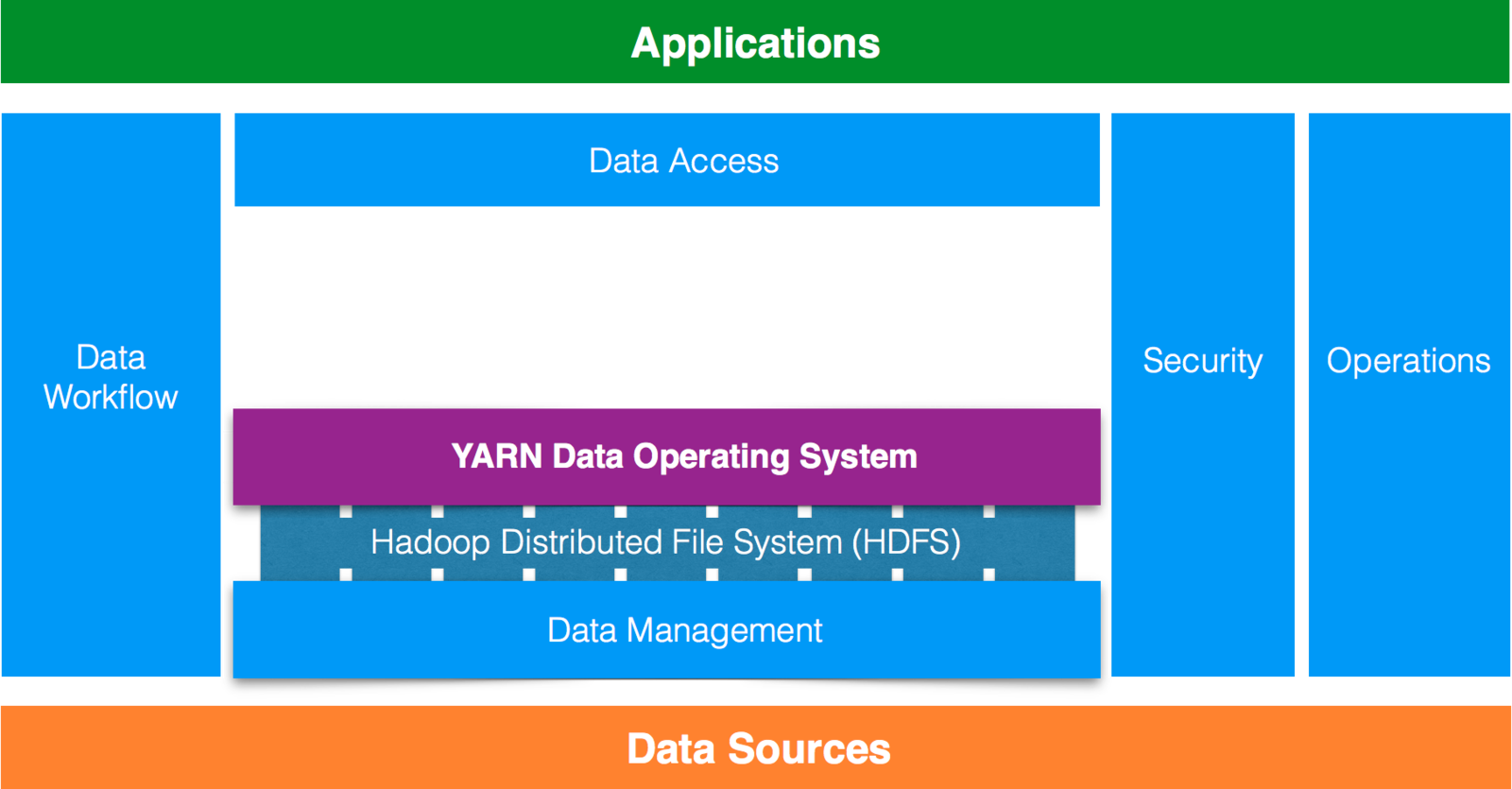
Hadoop
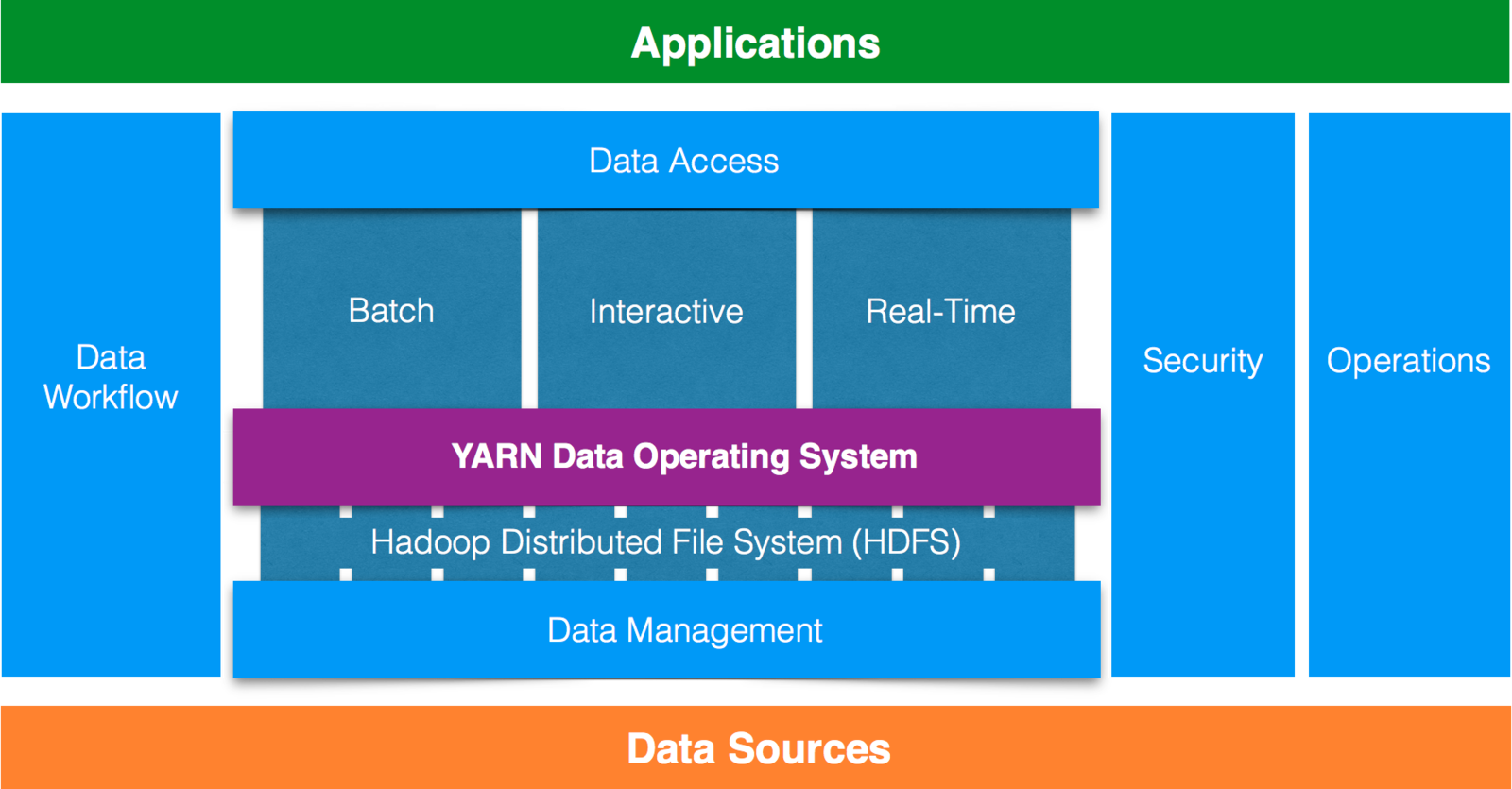
Hadoop Ecosystem
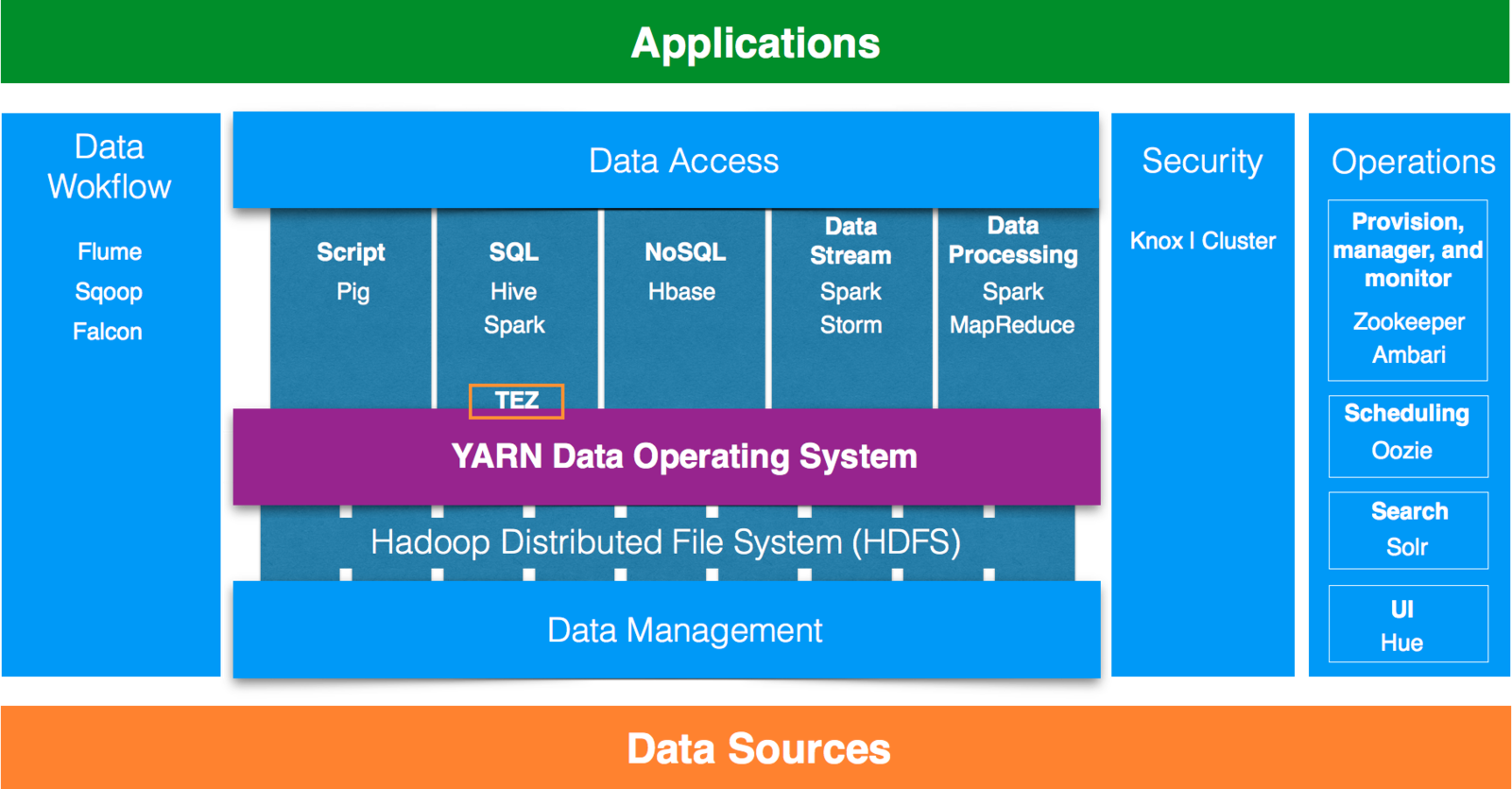

























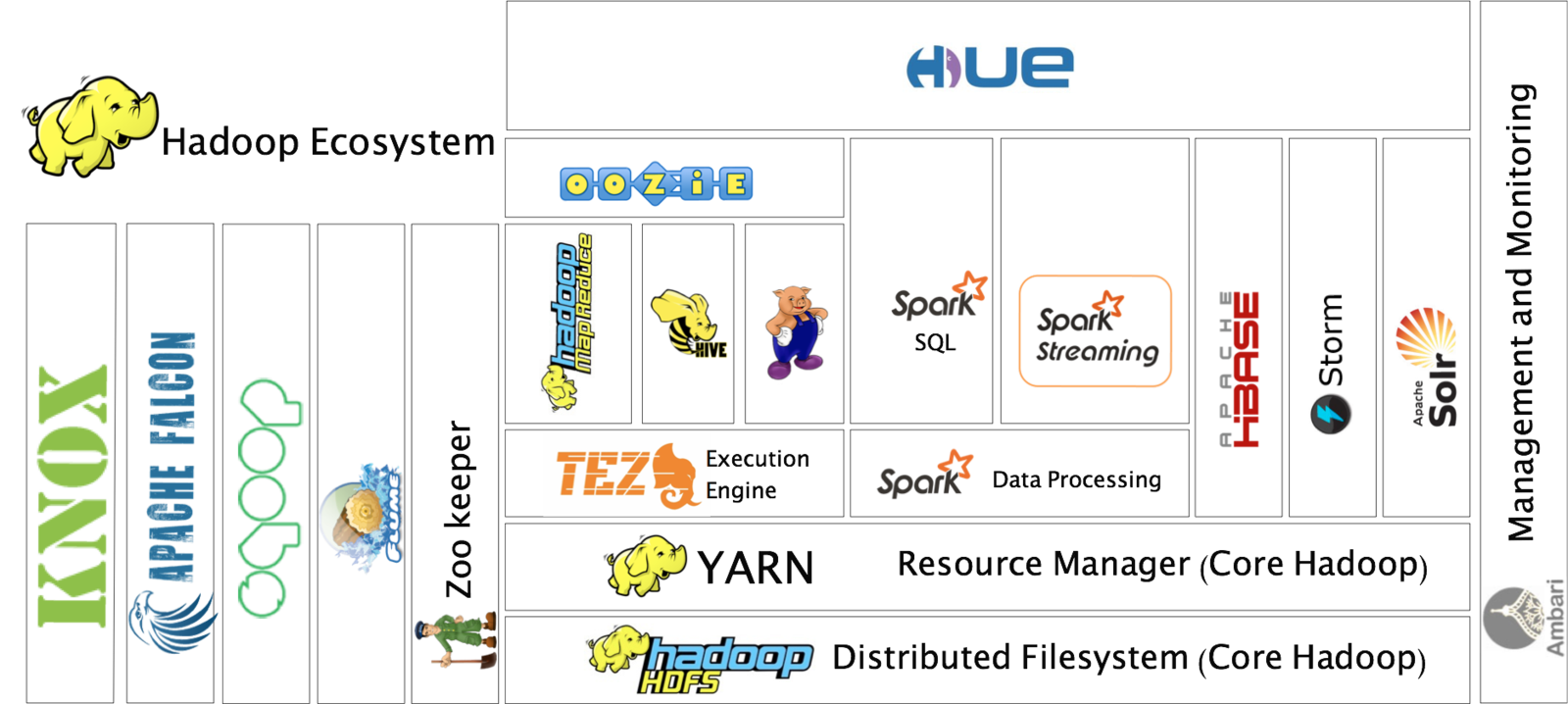

Getting started
w/ Cloud Big Data Platform
Hadoop Architecture Overview
What is the Cloud Big Data Platform


Cluster Types
Lab: Spin up a CBD Cluster
- Create a cluster in the Reach control panel
- SSH into the gateway node
- Load the status pages via an SSH SOCKS proxy
Step 1: Create a cluster in the Reach control panel
Log in to https://mycloud.rackspace.com

Step 2: Create a cluster in the Reach control panel
Use the command below to SSH into the gateway node using its public IP and the username/password you created
ssh -D 12345 username@gatewayip

Step 3: Load the status pages via an SSH SOCKS proxy
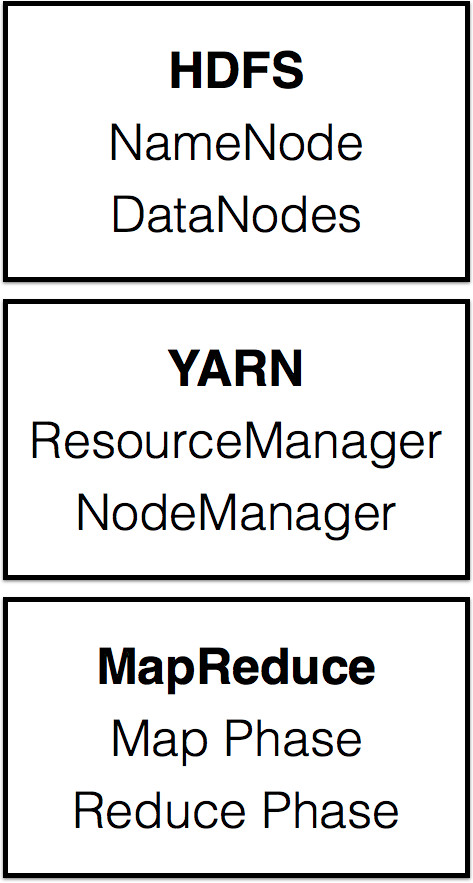
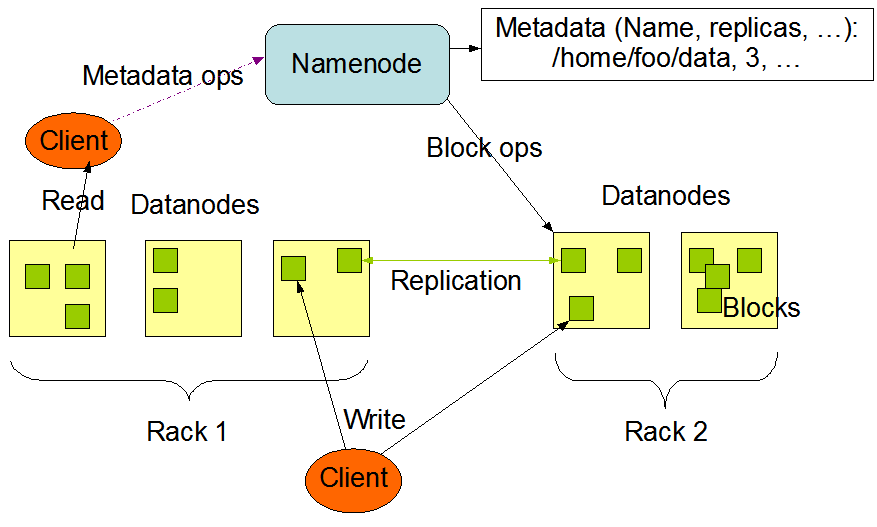
Distributed Filesystem - HDFS
NameNode and DataNodes
File System

Configuration

Data ingest and replication
How data is saved to HDFS

Lab: HDFS ingest and replication
- Copy a file into HDFS with 1 MB (1048576 b) blocksize
- Copy a file into HDFS with a 5x replication factor
- Look up all the information that’s available on the webpages for the services
NOTE: Complete this work on the Gateway Node
Lab Solution
hadoop fs -D dfs.blocksize=30 -put somefile somelocation
hdfs fsck filelocation -files -blocks -locations
hdfs dfs -mkdir test
hdfs dfs -ls
Namenode functionality
- Keeps track of the HDFS namespace metadata
- Controls opening, closing, and renaming files/directories by clients
Datanode functionality
- Handles read/write requests for blocks
- Reports blocks back to the Namenode
- Replicates blocks to other datanodes
File Permission
Supports POSIX-style permissions
- user:group ownership
- rwx permissions on user, group, and other
$ hdfs dfs -ls myfile
-rw-r--r-- 1 swanftw swanftw 1 2014-07-24 20:14 myfile
$ hdfs dfs -chmod 755 myfile
$ hdfs dfs -ls myfile
-rwxr-xr-x 1 swanftw swanftw 1 2014-07-24 20:14 myfile
File System Shell


File system shell (HDFS client)



File system shell (HDFS client) cont...


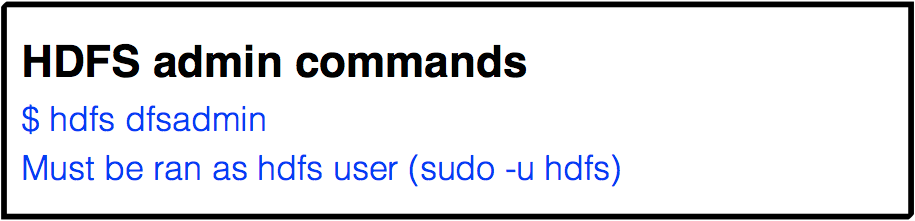
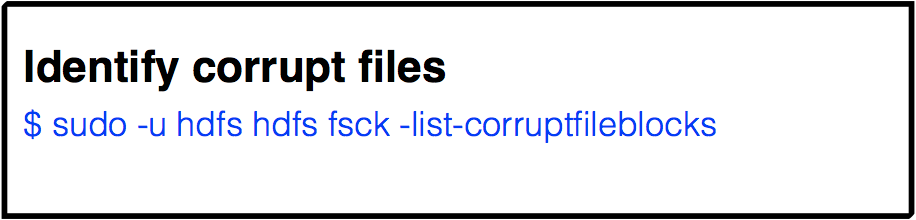
File system shell (HDFS admin)


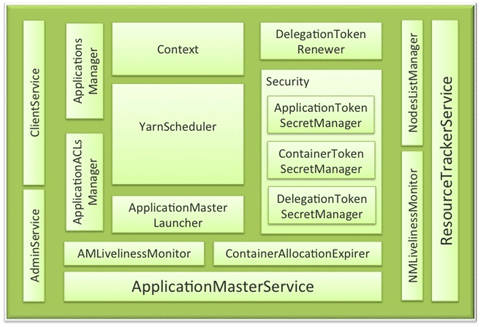
YARN


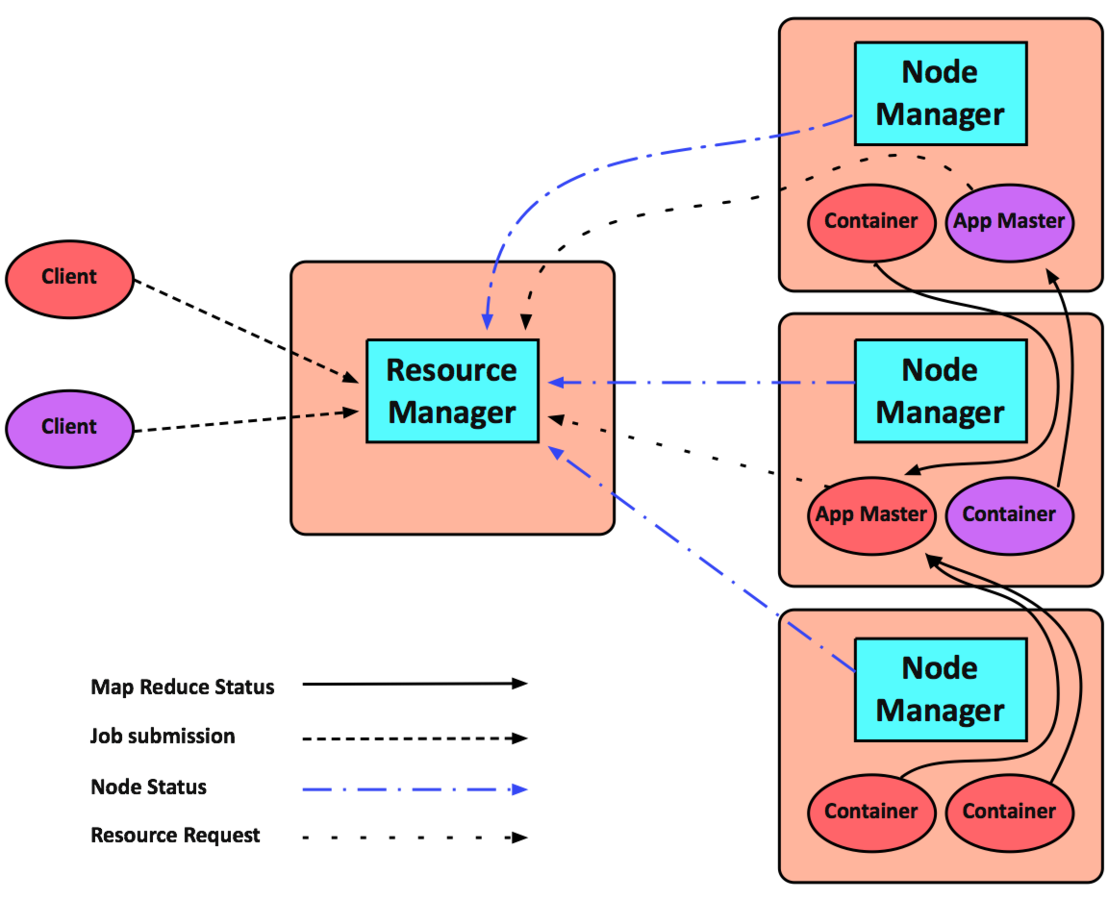
YARN
The JobTracker and TaskTracker have been replaced with the YARN ResourceManager and NodeManager.
Application Master negotiates resources with the Resource Manager and works with the NodeManagers to start the containers
YARN
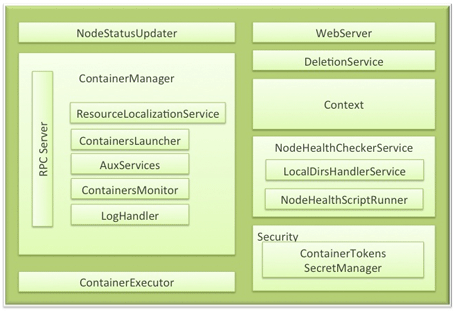
Node Manager
- Typically runs on each datanode
- Responsible for monitoring and allocating resources to containers
- Reports resources back to Resource Manager
Resource Manager
- Typically runs alongside the Namenode service
- Coordinates all resources among the given nodes
- Works together with the Node Managers and Application Masters
- Splits a large data set into independent chunks and organizes them into key, value pairs for parallel processing
- Uses parallel processing to improve the speed and reliability of the cluster
- YARN based job that takes advantage of the ability to parallel process
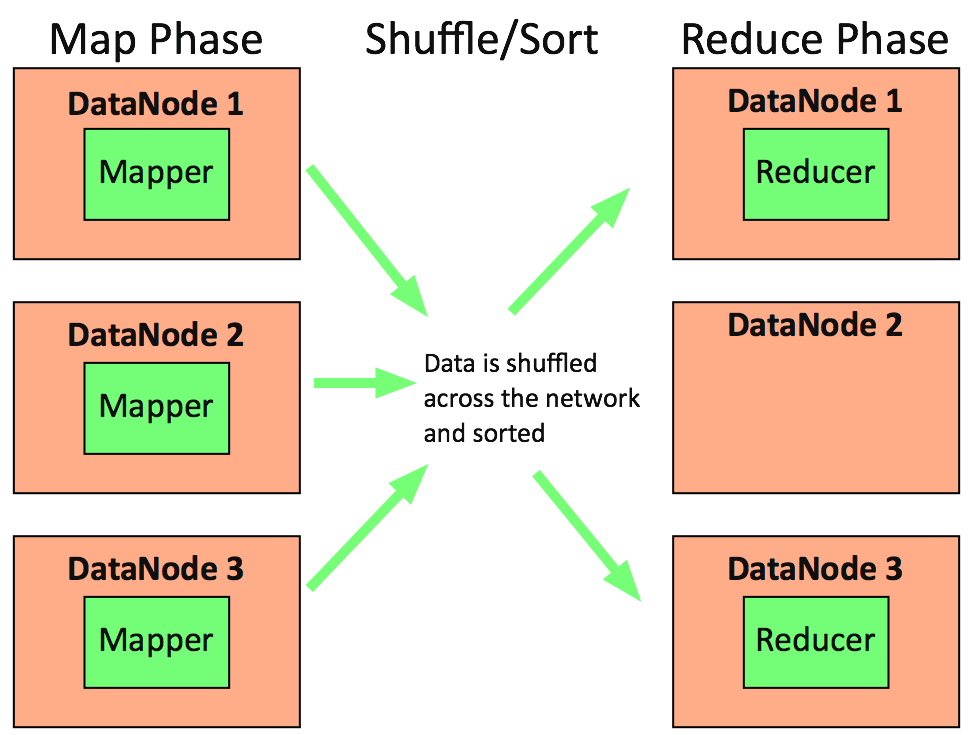
- Three step process of Map, Shuffle/Sort and then Reduce
Map
The ETL or Projection piece of MapReduce
- Extract > Transform > Load
- Map phase
Divides the input into ranges and creates a map task for each range in the input. Tasks are distributed to the worker nodes. The output of each map task is partitioned into a group of key-value pairs for each reduce.
Shuffle/Sort
This refers to the action of shuffling & snorting data across the network nodes
Reduce
Reduce Phase
- Collects the various results and combines them to answer the larger problem the master node was trying to solve. Each reduce pulls the relevant partition from the machines where the maps executed, then writes its output back into HDFS.
MapReduce
YARN Applications




rmadmin Commands

Lab: MapReduce
- Submit a MapReduce job
- Inspect the output and observe the status pages while your job is running and after it completes
- Copy a book in txt format into HDFS and use it as input to the wordcount function in hadoop-mapreduce-examples.jar
Lab Solution
$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount /user//in /user//out
Lab: Commands
- Submit a MapReduce job of your choice
- Use the commands learned in this section to view the status of the job
Basic JVM Administration

HEAP
Memory Allocated to a JVM and is where referenced objects are stored.
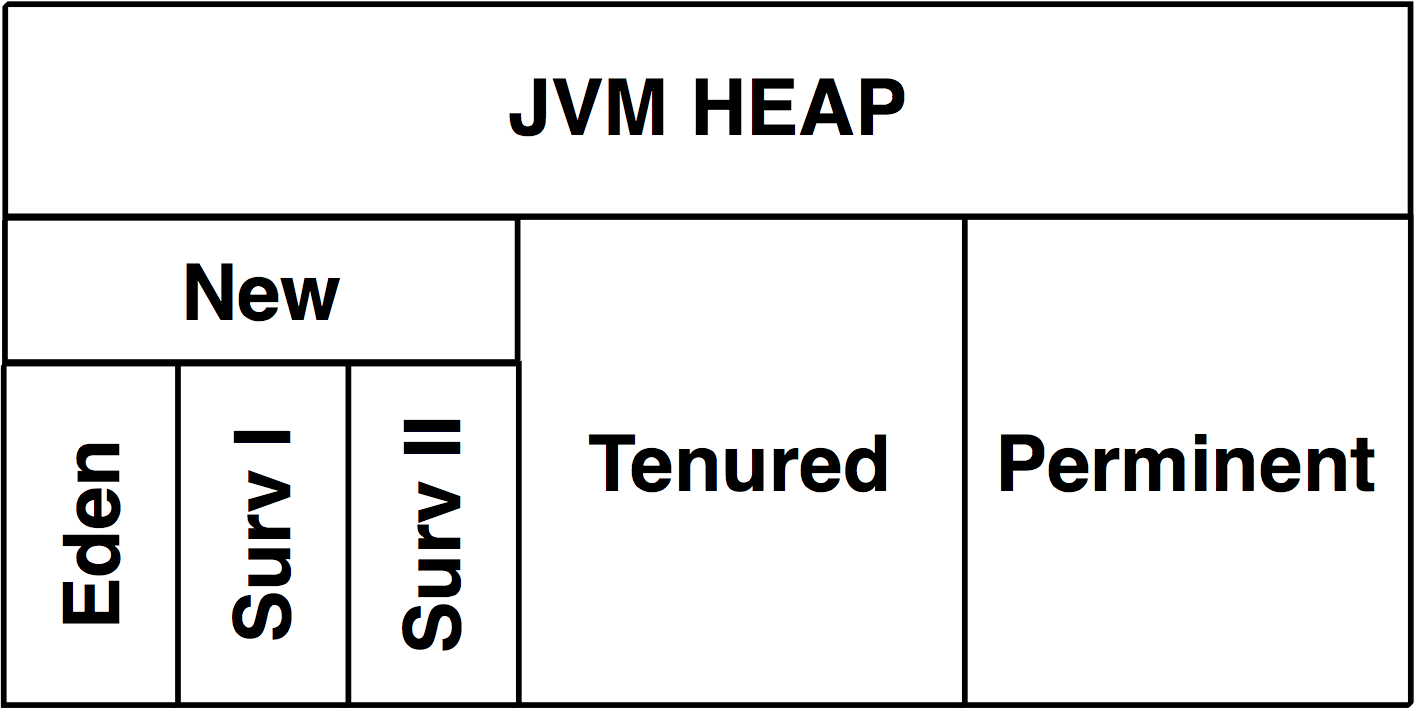
HEAP
During Garbage Collection unreferenced objects are cleared out of memory and survivors of the process are moved to the first survivor space.
As an object survives longer it is promoted into older generation space.
Java Commands


JMX
Hadoop by default extends information about the running processes for monitoring via nagios or other custom monitoring.
Slide Title
fields in jstat -gcutil

Lab: Java Monitoring
- From the Primary Namenode, run “ sudo jps -l “ and identify the namenode service /font>
- Using jstat iterate over the statistics until you observe the garbage collection process move objects
- What statistics changed?
Lab Solution
jps -l
25760 org.apache.zookeeper.server.quorum.QuorumPeerMain
1615 org.apache.hadoop.hdfs.server.namenode.NameNode
2279 org.apache.hadoop.yarn.server.nodemanager.NodeManager
jstat -gcutil 1615 2000 ←- 1615=PID 2000=Times to report
-observe changes in allocations
sudo yum -y install java-1.7.0-openjdk-devel.x86_64
Hive and Pig


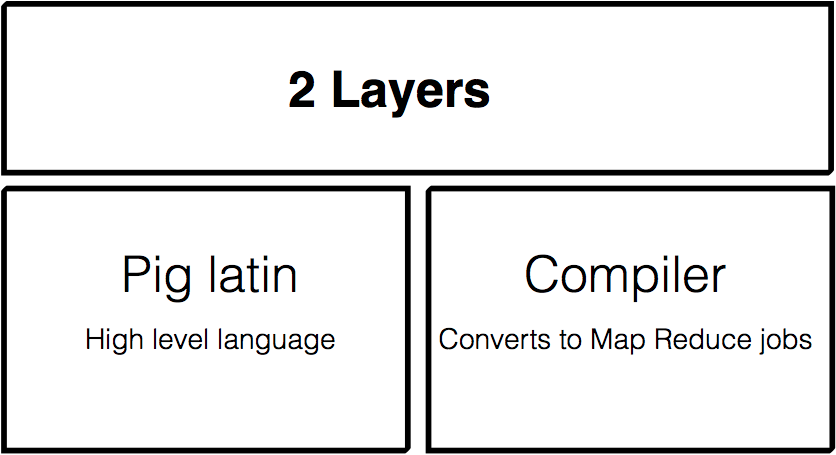
What is Pig?
Apache Pig is a high level language for expressing data analysis programs built on top of the Hadoop platform for analyzing large data sets.
Why Pig?
- Ease of programming
- Optimization opportunities
- Extensibility
Using Pig
- Grunt Shell - For interactive pig commands
- Script file
- Modes: Local Mode and Hadoop Mode
Sample Pig Script
A = load ‘passwd’ using PigStorage(‘:’);
B = foreach A generate $0 as id;
store B into ‘id.out’;
Hive
- Opensourced by Facebook
- Data warehouse for querying large sets of data on HDFS
- Supports table structuring of data in HDFS
- SQL like query language - HiveQL
Hive continued...
- Complies HiveQL queries into MapReduce jobs/font>
- Data stored in HDFS
- Doesn’t support transactions
- Supports UDF’s (User Defined Functions)
Hive Components
- Shell - Interactive queries
- Driver - session handle, fetch and execute
- Compiler - Parse, plan and optimize
- Execution Engine - default TEZ | DAG of stages (Converted to MapReduce)
- Metastore - Schema, data location, SerDe
Hive Metastore
- Database - Namespace containing a set of tables
- Table - Contains list of columns, their types and SerDe info
- Partition - Mapping to HDFS directories
- Statistics - Info about the database
- Supports MySQL, Derby and others

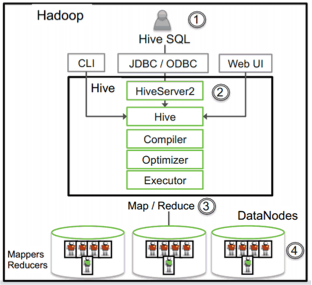
Query Processing
Hive/MR vs Hive/Tez
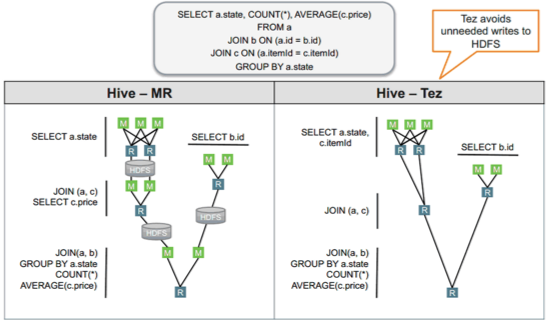
Interacting with Hive
- Hive cli to connect to hiveserver
- Beeline cli to connect to hiveserver2
$hive
hive> create table test(id string);
hive> describe test;
hive> drop table test;

Hive Tables
HCatalog
- Metadata and table management for Hadoop
- Shared schema for Hive, Pig and MapReduce
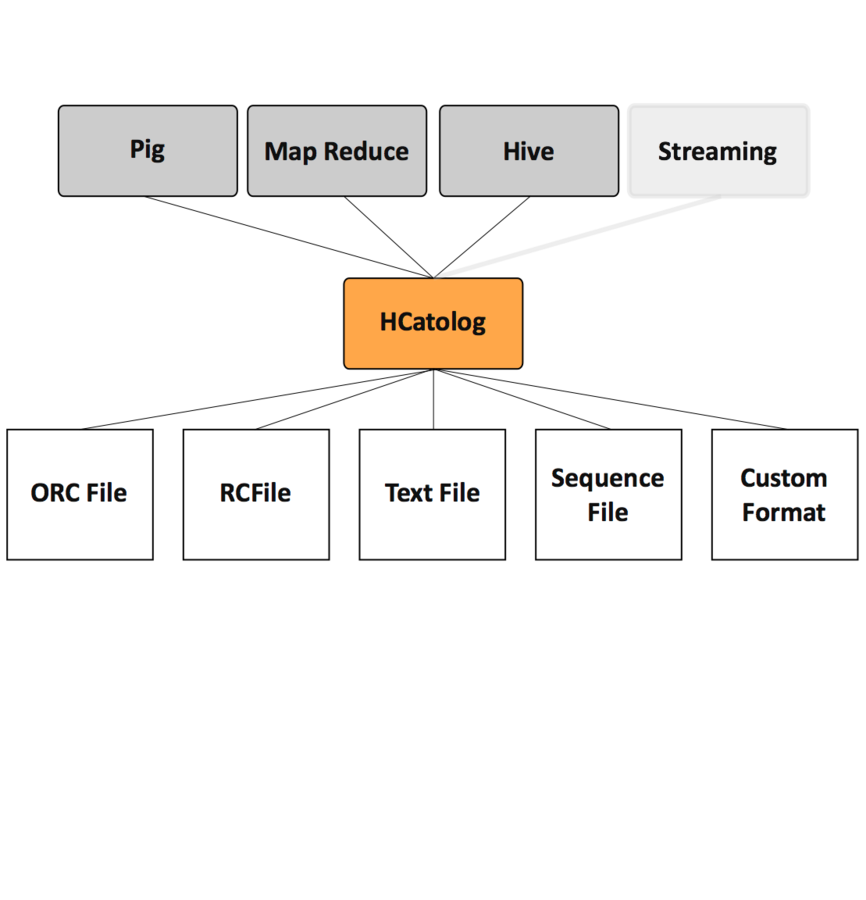
HCatalog
Apache Tez
- Execution framework to improve performance of Hive
- In the future Pig will also be able to use the Tez engine as its back end
Pig Walkthrough
Log onto the gateway node
wget https://s3.amazonaws.com/hw-sandbox/tutorial1/infochimps_dataset_4778_download_16677-csv.zip
unzip
cd infochimps_dataset_4778_download_16677/
hdfs dfs -put NYSE
pig
STOCK_A = LOAD 'NYSE/NYSE_daily_prices_A.csv' using PigStorage(',') AS (exchange:chararray, symbol:chararray,
date:chararray, open:float, high:float, low:float, close:float, volume:int, adj_close:float); DESCRIBE STOCK_A
B = LIMIT STOCK_A 100;
DESCRIBE B;
C = FOREACH B GENERATE symbol, date, close;
DESCRIBE C;
STORE C INTO 'output/C';
quit
hdfs dfs -cat output/C/part-r-00000
Lab: Working with Hive
- Download data from http://seanlahman.com/files/database/lahman591-csv.zip
- This lab will use Master.csv and Batting.csv from unzipped files
- Load those files into HDFS, load it thru hive, cleanse and run queries
- Get the max runs per year
- Next get the player ID who has the highest score
Lab: Working with Hive
- Now load Master.csv similar to how we loaded Batting.csv. The column names should be available in the readme.txt file from the unzipped folder.
- Combine data from both fields to list the player name instead of the player id.
Hive Walkthrough
SSH into the Gateway node
wget http://seanlahman.com/files/database/lahman591-csv.zip
sudo yum install unzip
unzip lahman591-csv.zip
hdfs dfs -mkdir /user//baseball
hdfs dfs -copyFromLocal Master.csv Batting.csv /user//baseball
hive (This gets you into the hive shell)
hive> CREATE TABLE batting(player_id STRING, year INT, stint INT, team STRING, league STRING, games INT, games_batter
INT, at_bats INT, runs INT, hits INT, doubles INT, triples INT, homeruns INT, runs_batted_in INT, stolen_bases INT,
caught_stealing INT, base_on_balls INT, strikeouts INT, walks INT, hit_by_pitch INT, sh INT, sf INT, gidp INT, g_old INT) ROW
FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
hive> LOAD DATA INPATH '/user/baseball/Batting.csv' OVERWRITE INTO TABLE batting;
hive> SELECT year, max(runs) FROM batting GROUP BY year;
hive> SELECT b.year, b.player_id, b.runs from batting b JOIN (SELECT year, max(runs) runs FROM batting GROUP BY year) y ON (b.year = y.year and b.runs = y.runs);
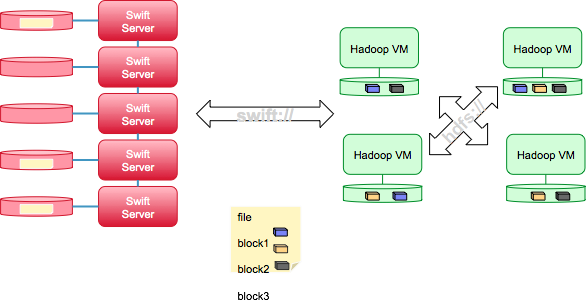
Ingest Data via Swifts

SwiftFS for Hadoop
- New Hadoop filesystem URL, swift://
- Read from and write to Swift object stores
- Supports local and remote stores
- Included as part of Hadoop
- Can use anywhere you can use hdfs:// URLs
- swift://[container].rack-[region]/[path]
SwiftFS for Hadoop cont...
SwiftFS for Hadoop (cont.)

Advantages
- Store data 24/7 without a running cluster
- “Unlimited” storage capacity
- Easily share data between clusters
- Cross-datacenter storage
- Compatible with Hive, Pig, and other tools
- Other considerations | ~30% performance hit
Disadvantages
- Content will be retrieved/sent to Swift for storage, as operations will still occur within HDFS
- Network throughput for this work can be a bottleneck
- Slower read/write, but still fucking cool
Wiki Resource
http://www.rackspace.com/knowledge_center/article/swift-filesystem-for-hadoop
Lab: Working with SwiftFS | Part 1
- Working on your gateway node, unzip files from http://seanlahman.com/files/database/lahman591-csv.zip
- Using the same DC as your cluster, create a container in Cloud Files called baseball
- Load Master.csv and Batting.csv into the container
- Load data in the .csv file in Cloud files into a hive table similar to the previous chapter but using swiftFS URI instead
Lab: Working with SwiftFS | Part 2
- Run the same queries
- Create an external table in CloudFiles using Hive and load some results there.
Assess your Knowledge
A massive thanks to the content dev team...
Casey Gotcher
Chris Old
David Grier
Joe Silva
Mark Lessel
Nirmal Ranganathan
Sean Anderson
Chris Caillouet
Hadoop Operational
By Rackspace University




