
Fundamentals
- Name (Who are you?)
- Rank (What, exactly, would you say you do here?)
- Tenure (How long you been around these parts?)
- A Rackspace Moment
(Tell me a great RS memory!)
![]()

Introductions
Learning Objectives
- Explain what big data is
- Cite big data use cases
- Give an overview of Hadoop
- Recognize and explain the Hadoop ecosystem
- Describe Rackspace’s Cloud Big Data Platform
Big Data
Definition of Big Data


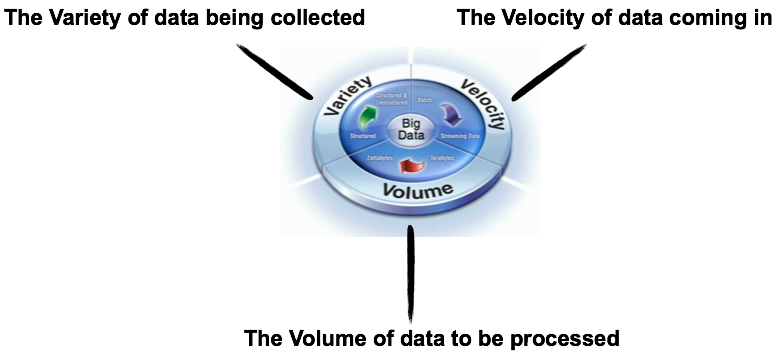
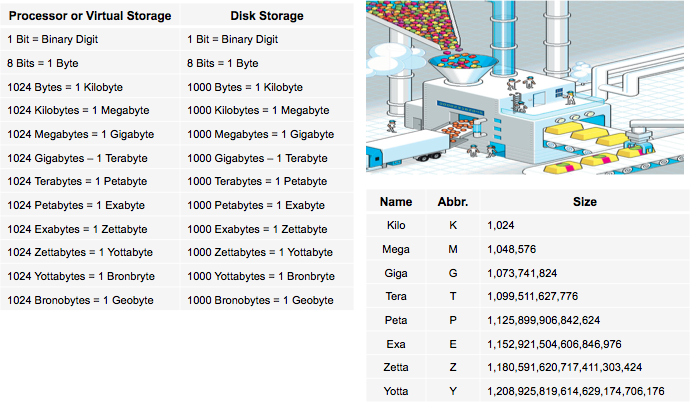

Estimated 1.5 terabytes of compressed data is produced daily.
Twitter messages are 140 bytes each generating 8TB data per day.


A Boeing 737 will generate 240 terabytes of flight data during a single flight across the US
Facebook has around 50 PB warehouse and it’s constantly growing.

Why invest time and money into Big Data?

IDC is predicting the big data market is expected to grow about 32% a year to $23.8 billion in 2016
The market for analytics software is predicted to reach $51 billion by 2016
Mind Commerce estimates global spending on big data will grow 48% between 2014 and 2019
Big data revenue will reach $135 billion by the end of 2019
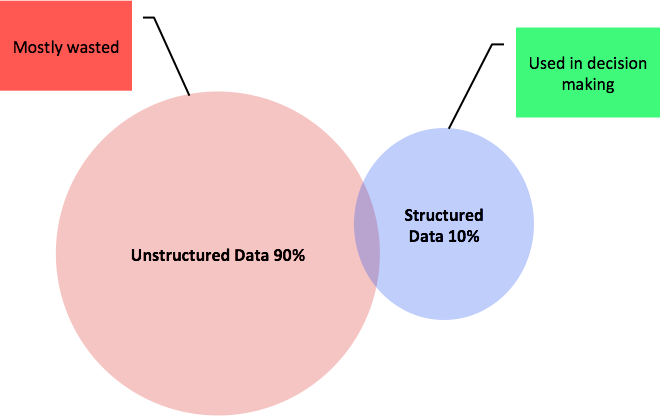
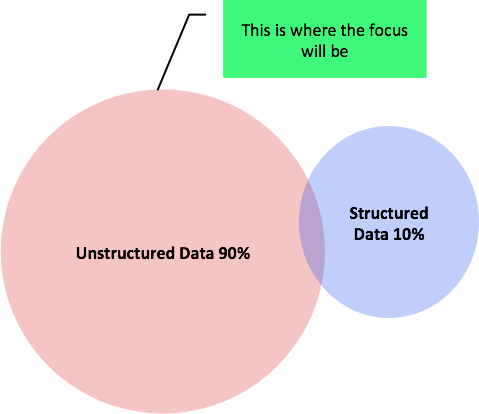
Most Common Types of Data


Big Data Technologies

Big Data Short Video
Top ten Big Data Insights at Rackspace
10 Minute Video
What is Big Data to Rackspace?
7 Minutes
Hadoop
What is Hadoop?
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
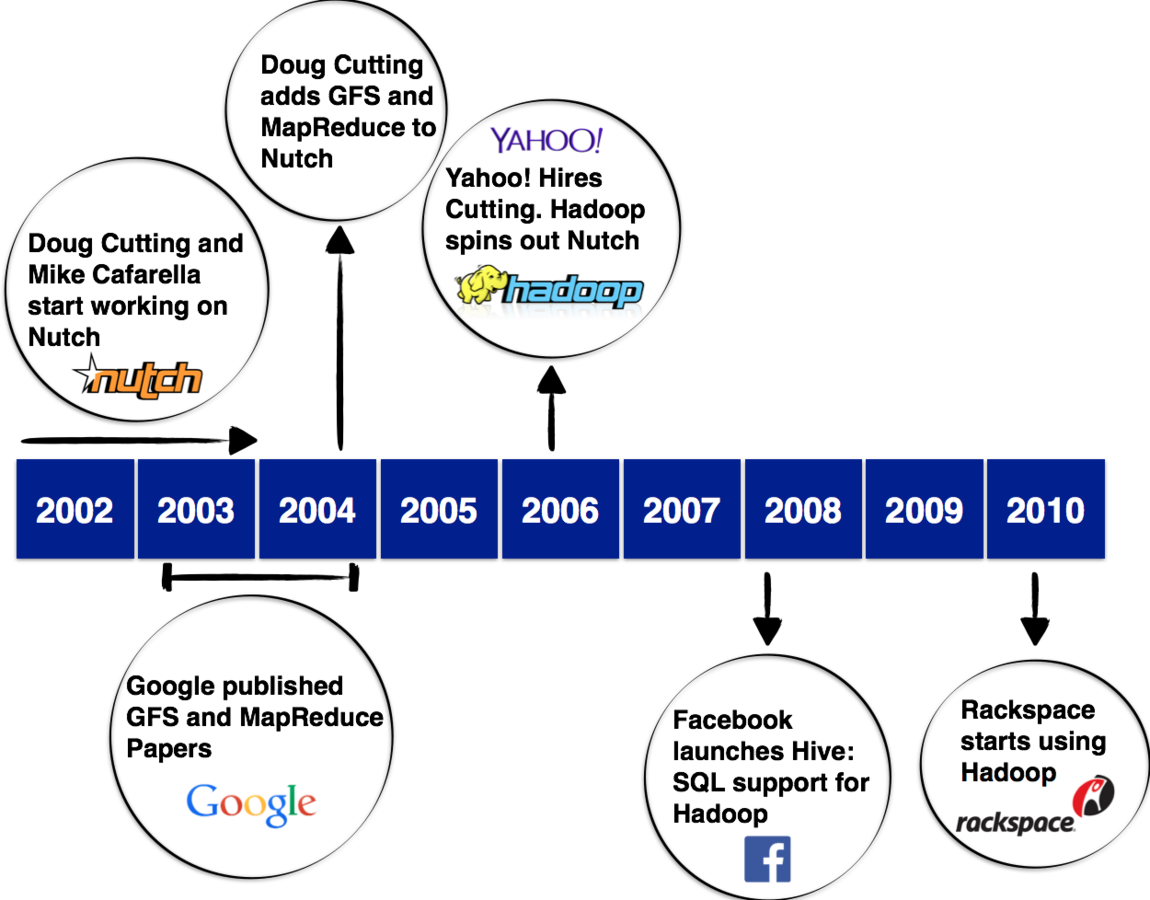
Evolution of Hadoop
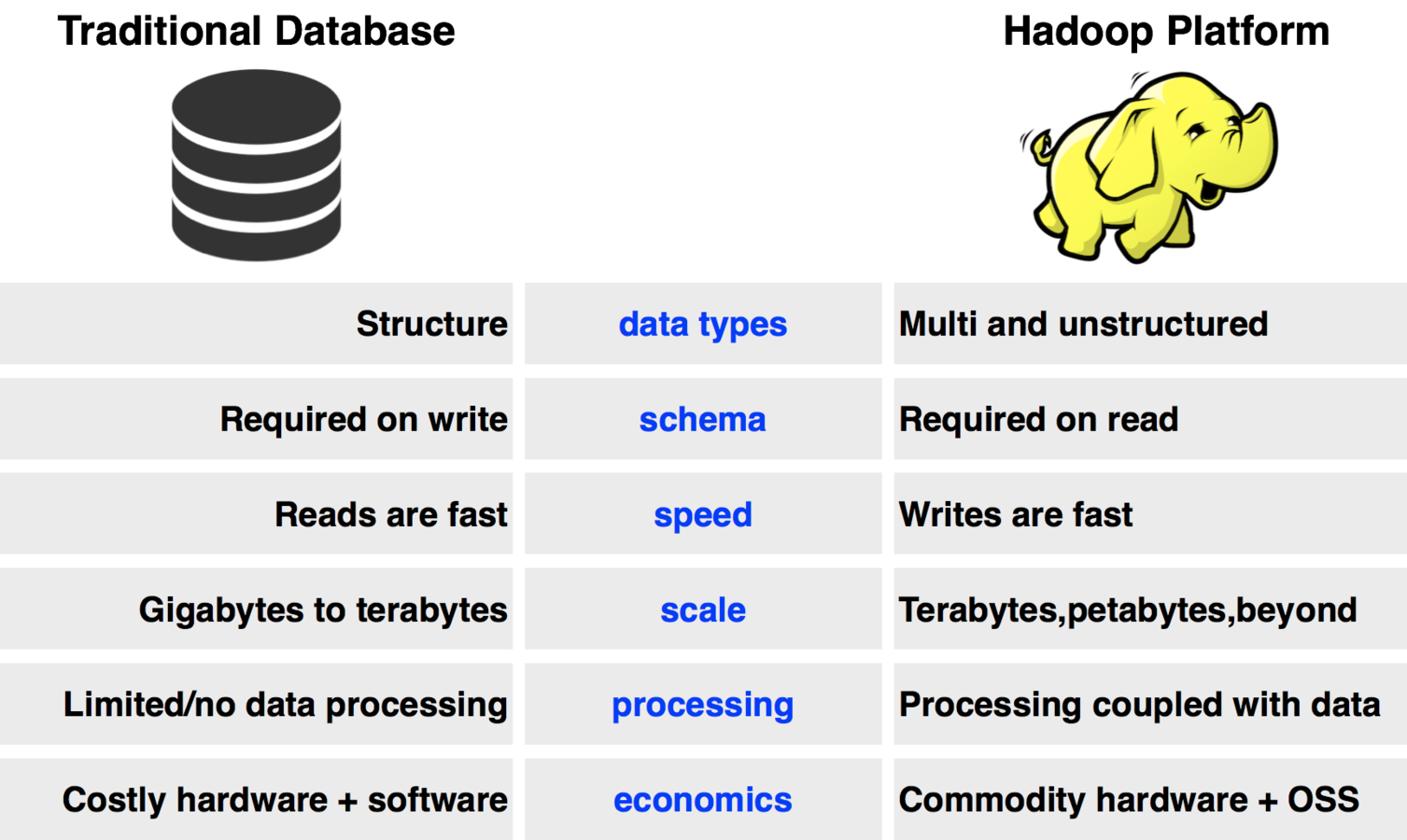
Traditional Systems vs. Hadoop
Facts about Hadoop






Apache Hadoop Framework

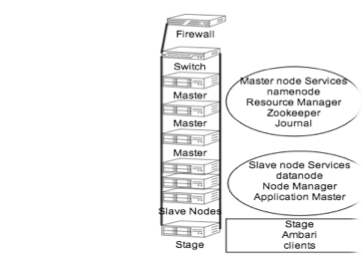
Hadoop Configuration
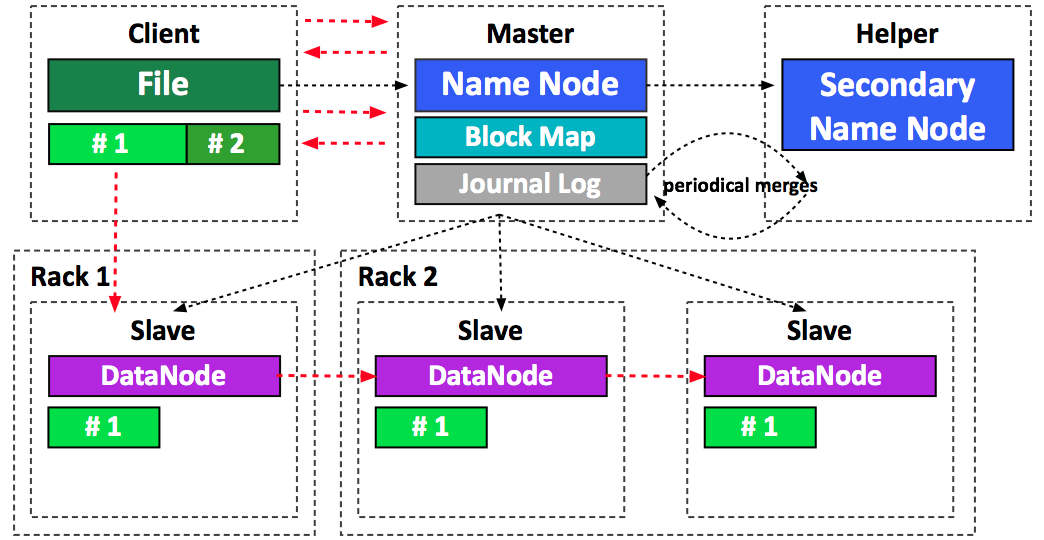
Name Nodes - is the centerpiece of a HDFS file system. It keeps a directory tree of all files in the file system, and tracks data location within the cluster. It does not store the data, it only keeps track of where it lives.
Gateway Node - Gateway Nodes are the interface between the cluster and outside network. They are also used to run client applications, and cluster administration services, as well as serving a staging area for data ingestion.
Data Nodes - These are the nodes where the data lives, and where the processing occurs. They are also referred to as “slave nodes”.
Hadoop Configuration
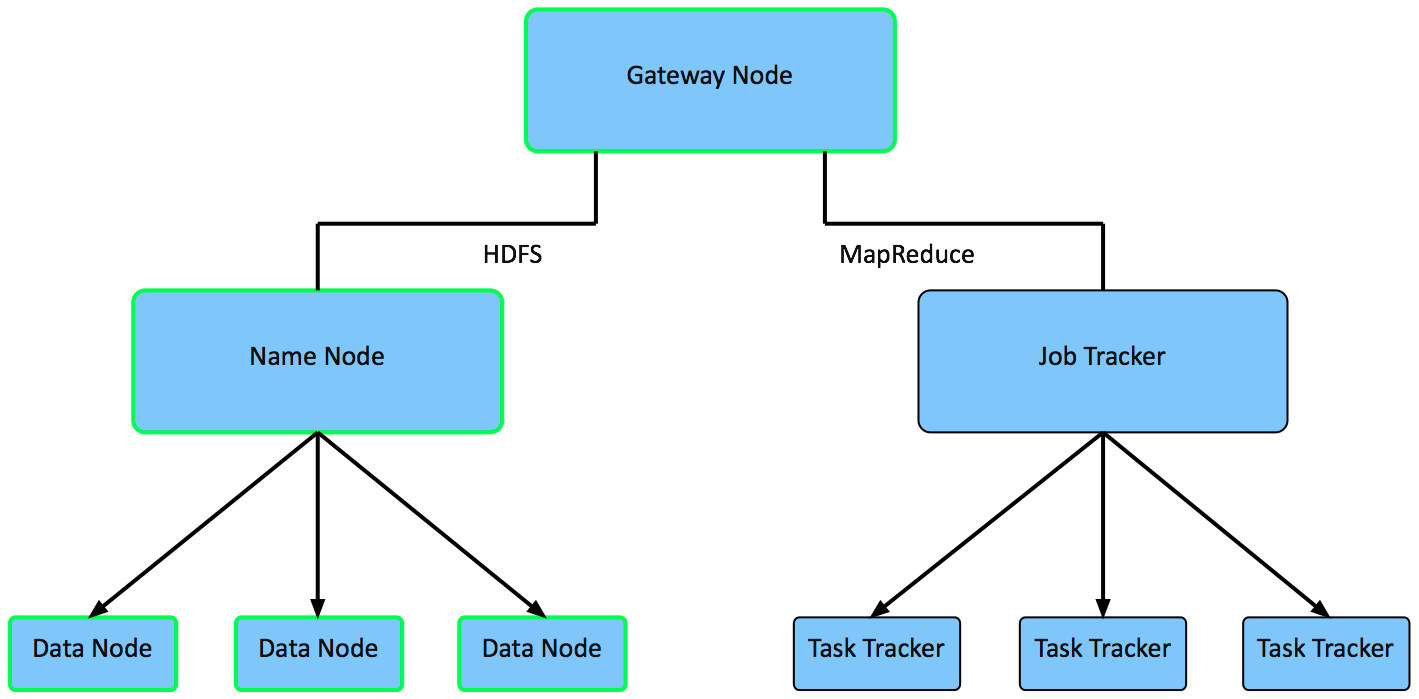
Hadoop Cluster
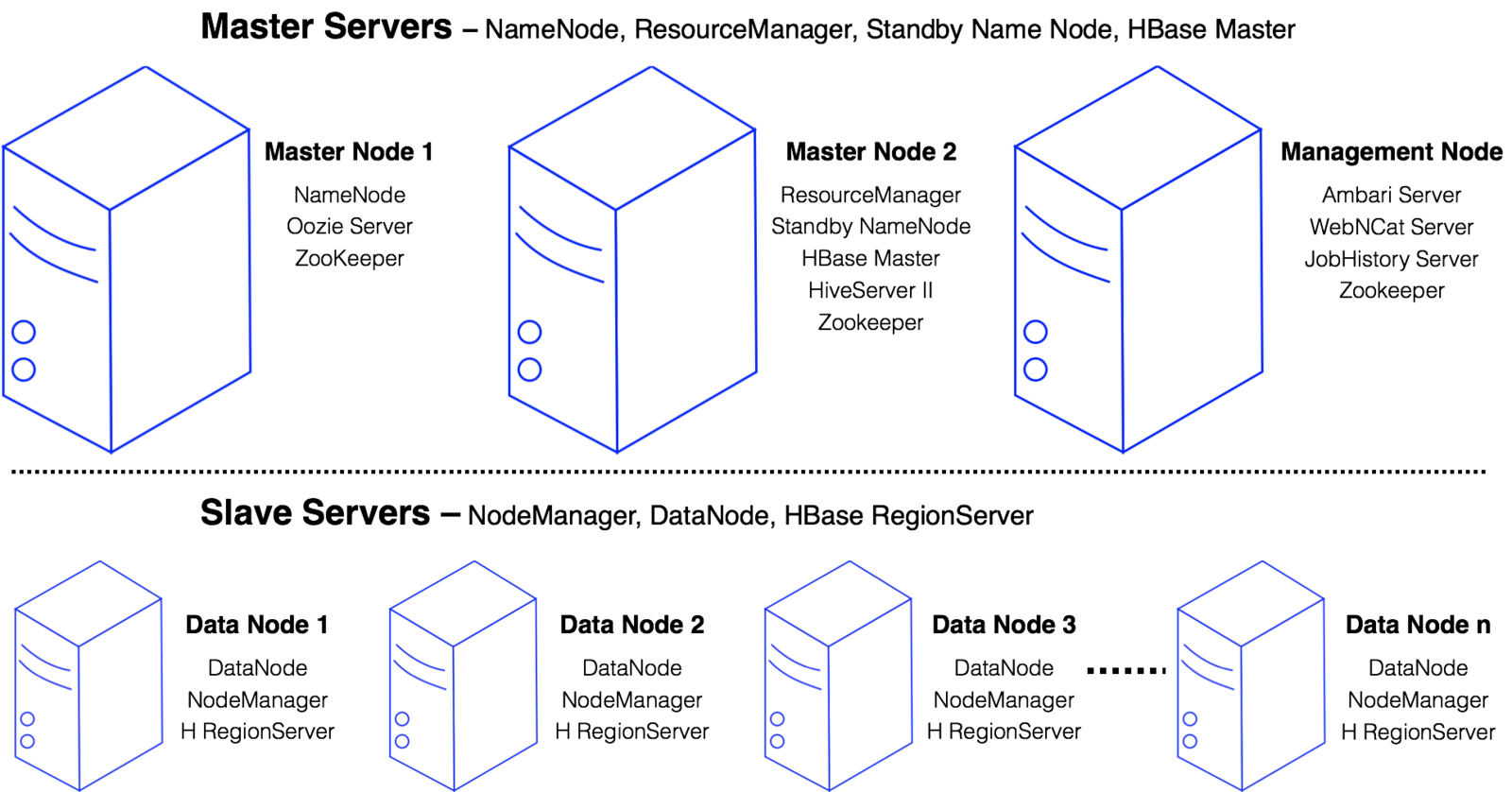
Hadoop Cluster
Master Servers manager the infrastructure
Slave Servers contain the distributed data and perform processing
Hadoop Cluster
Hadoop at Rackspace

Cloud Big Data Architecture
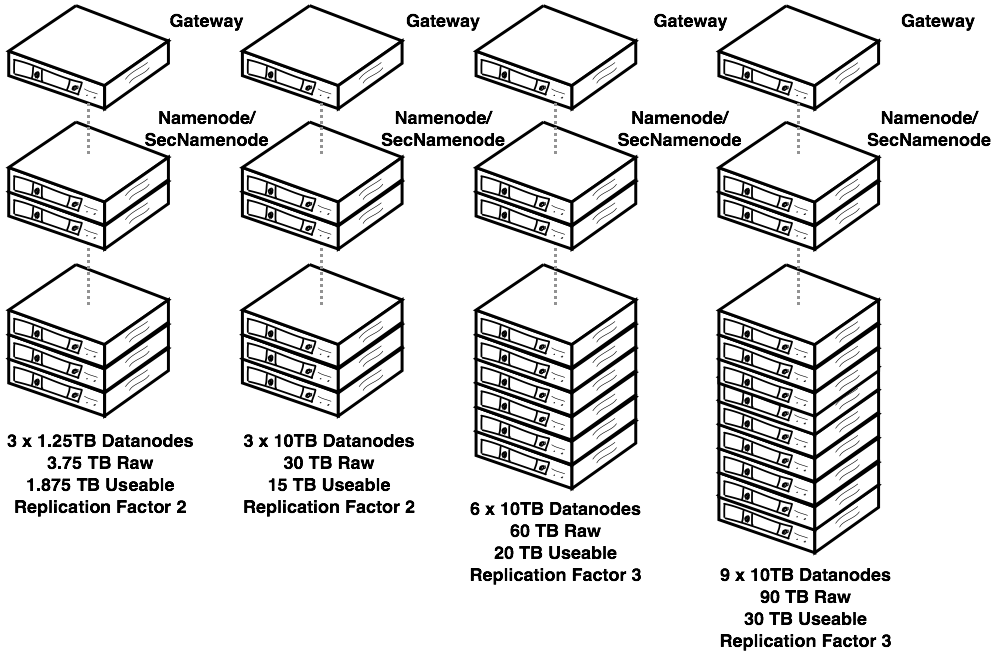
Managed/Dedicated Big Data Architecture

Test your Knowledge
Is Hadoop a data store?
No. While you can technically store data in a Hadoop Cluster, it is really more of a data processing system, than a true data store.
Then what is a data store?
A data store is a data repository including a set of integrated objects. These objects are modeled using classes defined in database schemas. Examples of typical data stores, MySQL, PostgreSQL, Redis, MongoDB
What is Data Processing?
Think of Data Processing as the collection and manipulation of items of data to produce meaningful information. In the case of Hadoop, this means taking unstructured, unusable data, and processing it in a way that makes it useful or meaningful
Hadoop Ecosystem
V1
























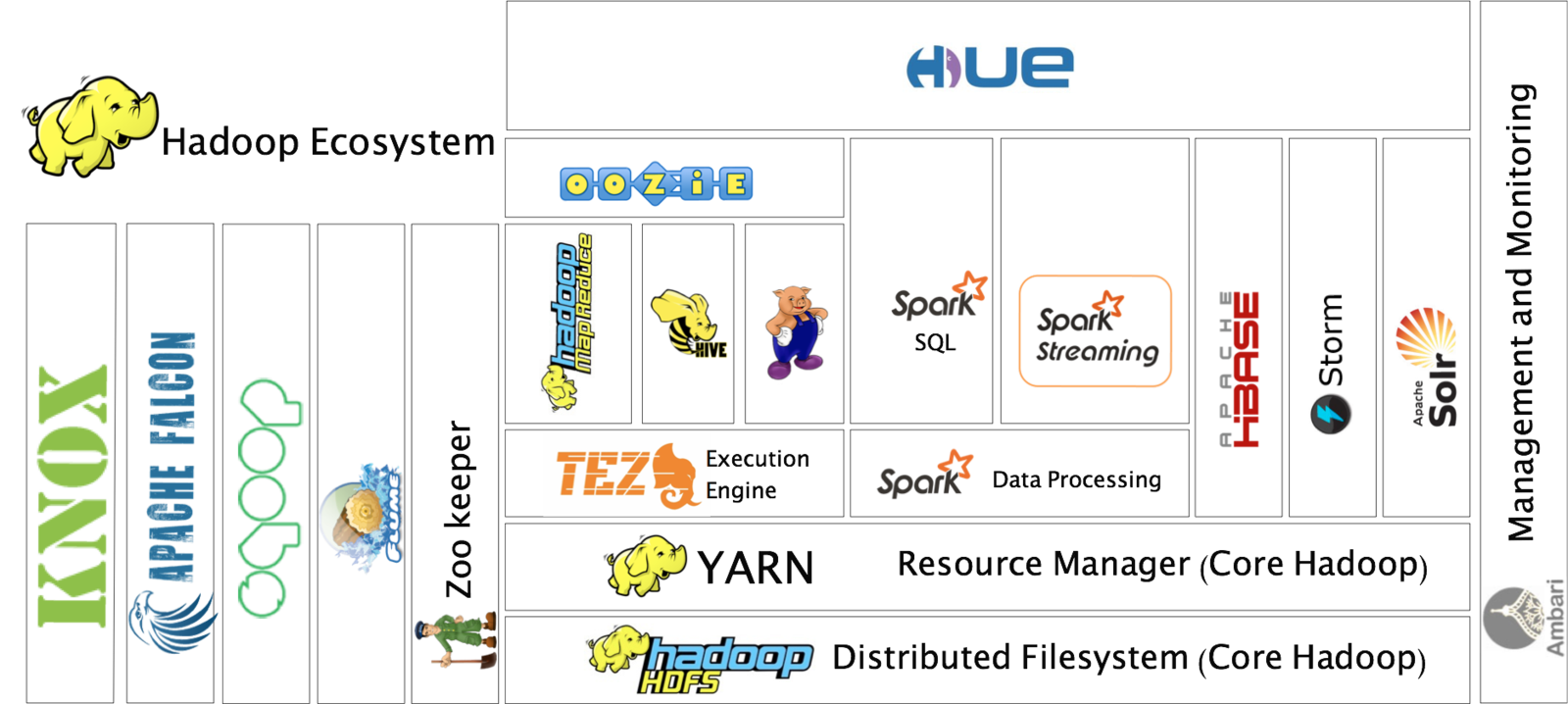

Hadoop Ecosystem
V2
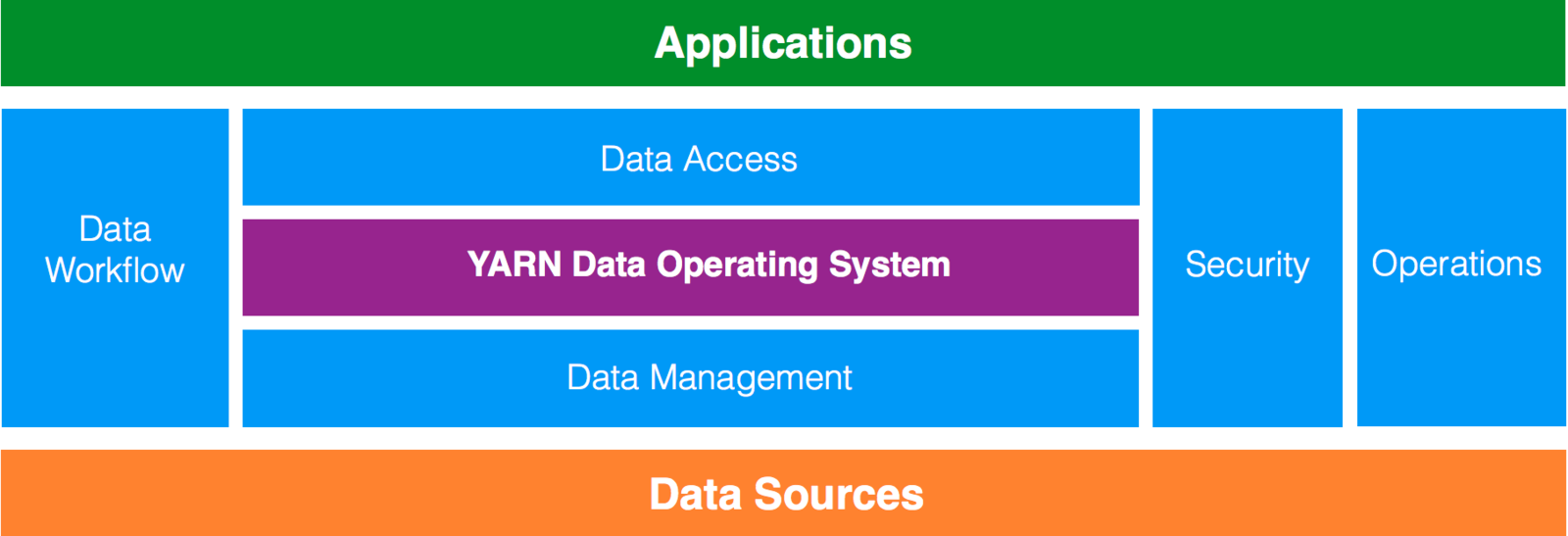
Data Architecture

Data Architecture
"
Data Architecture
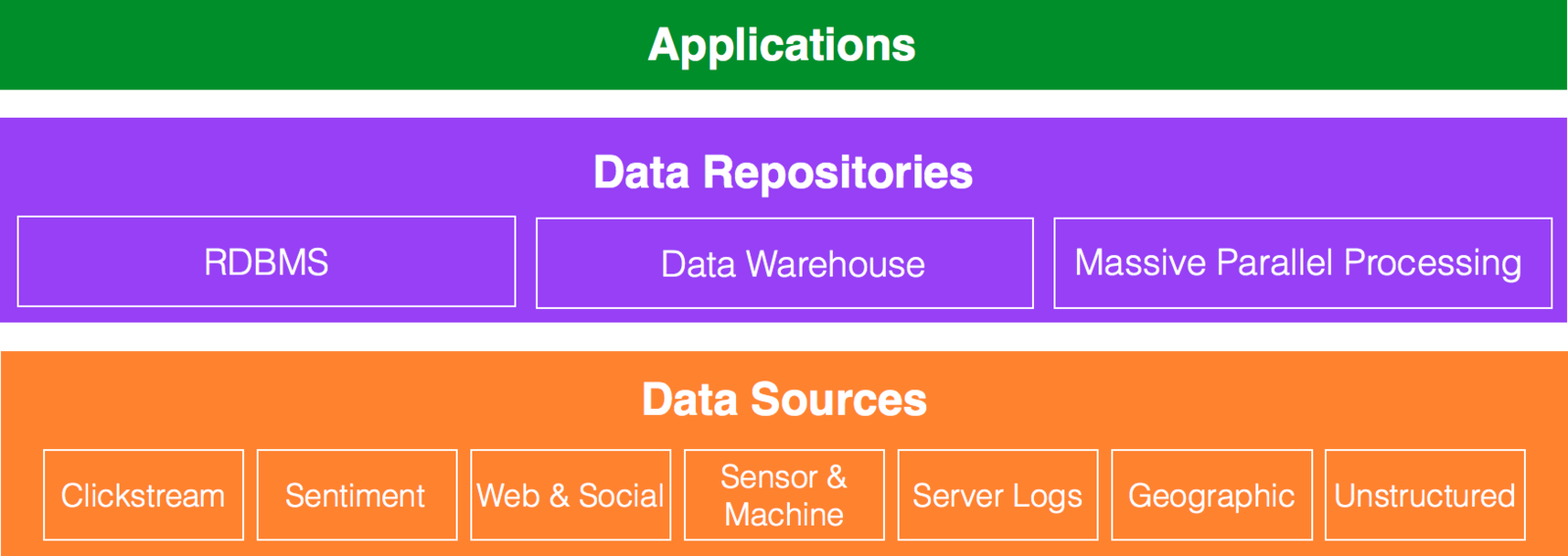
Data Architecture
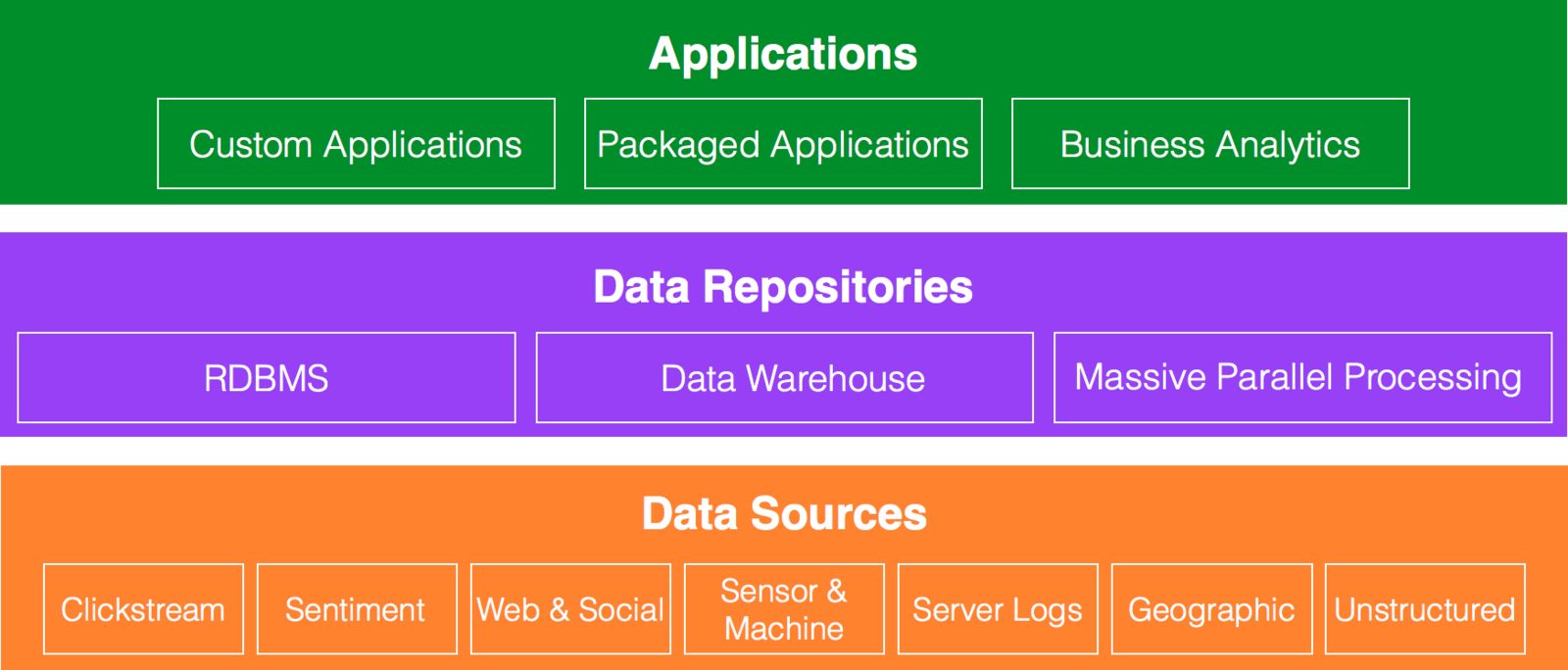
Hadoop
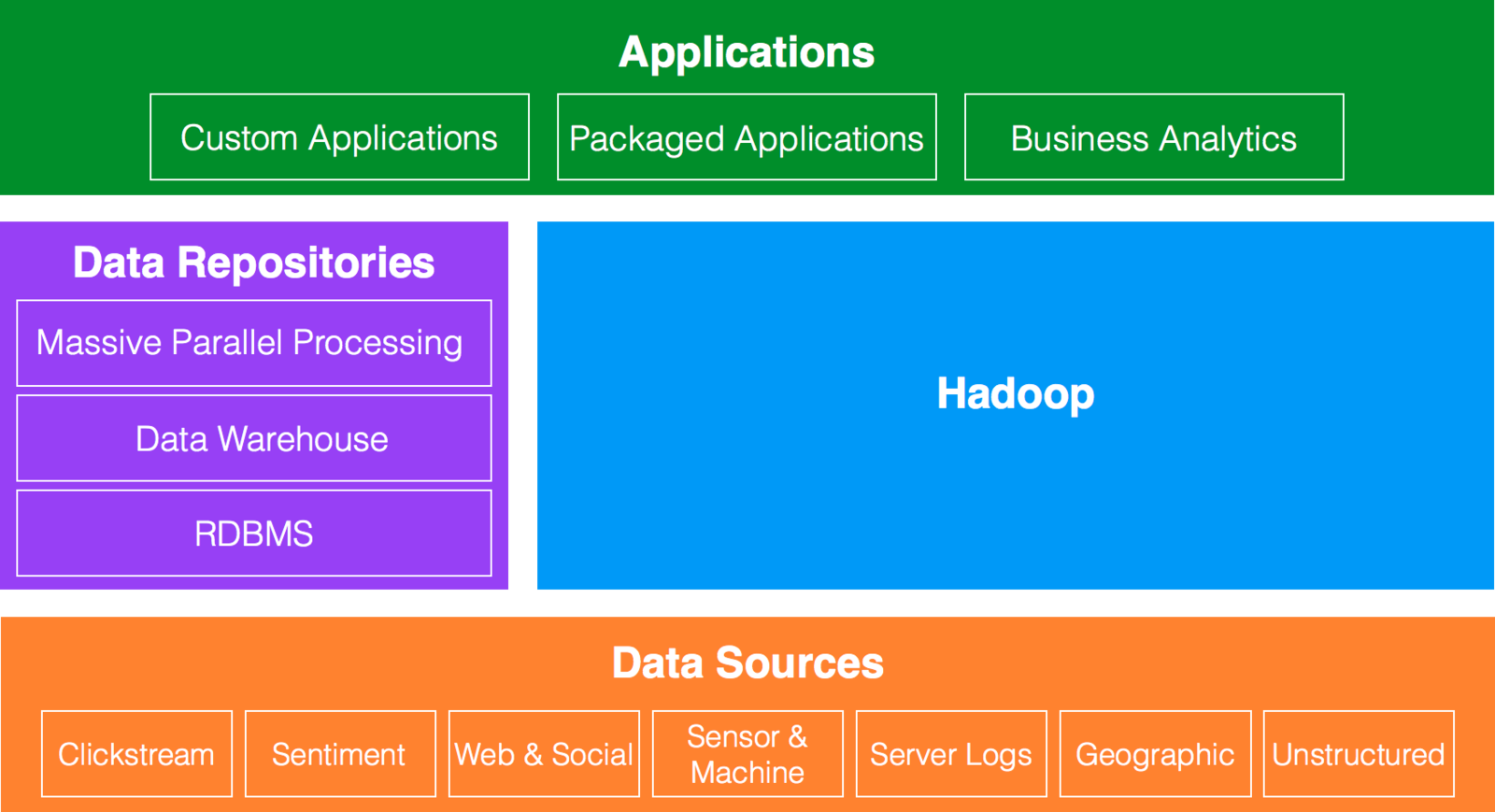
Hadoop
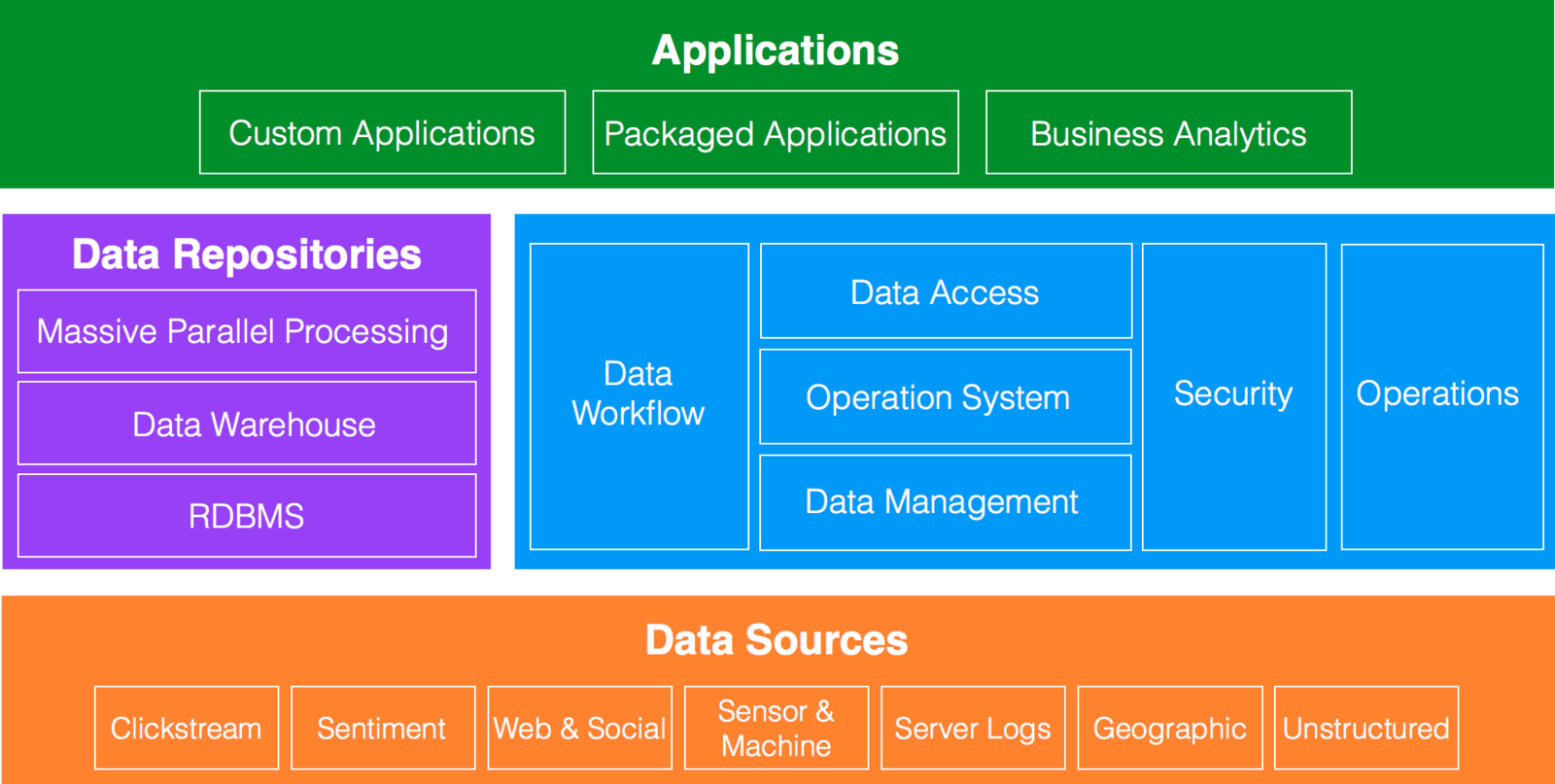
Hadoop
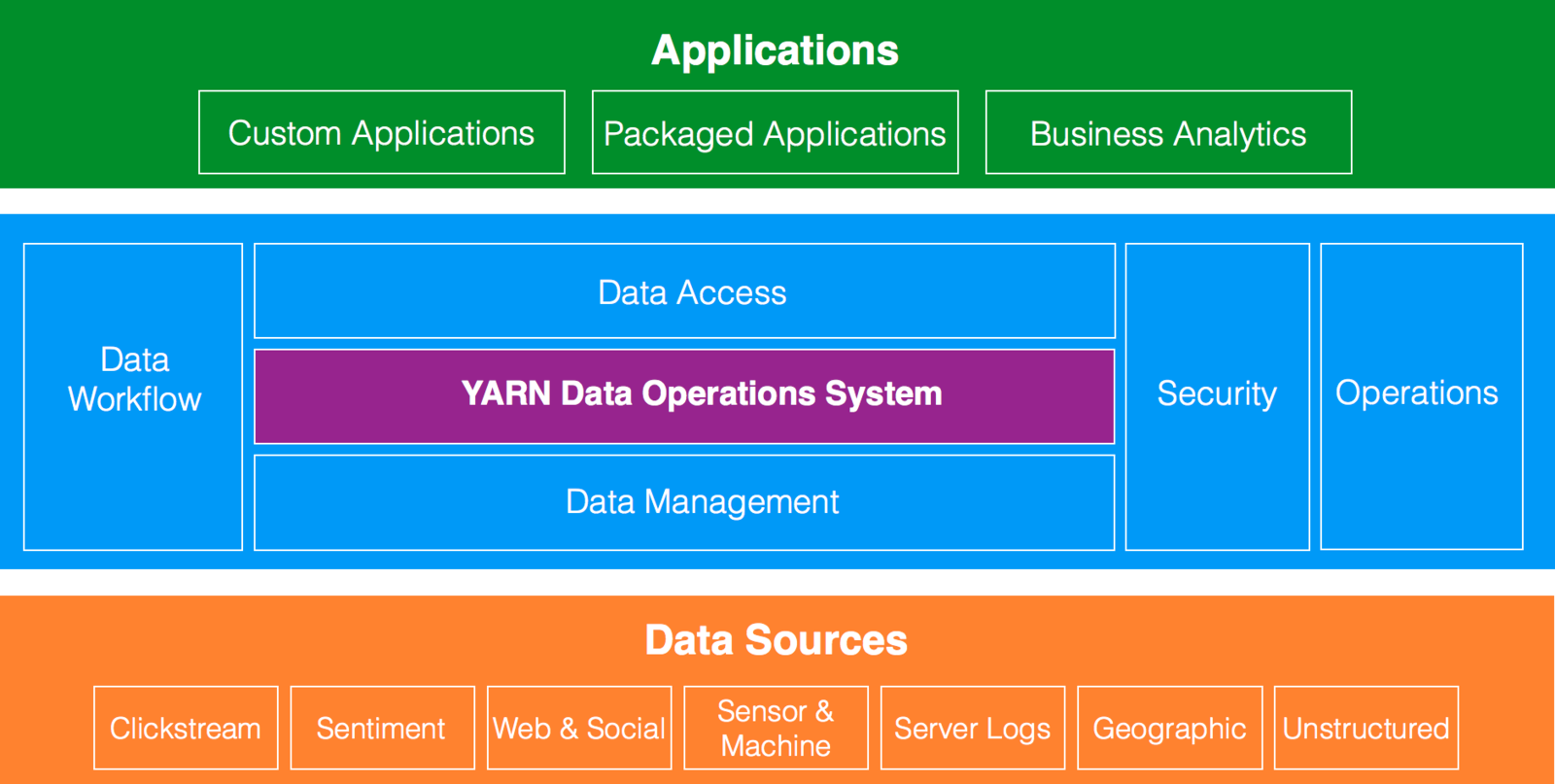
Hadoop
Hadoop
Hadoop
Hadoop
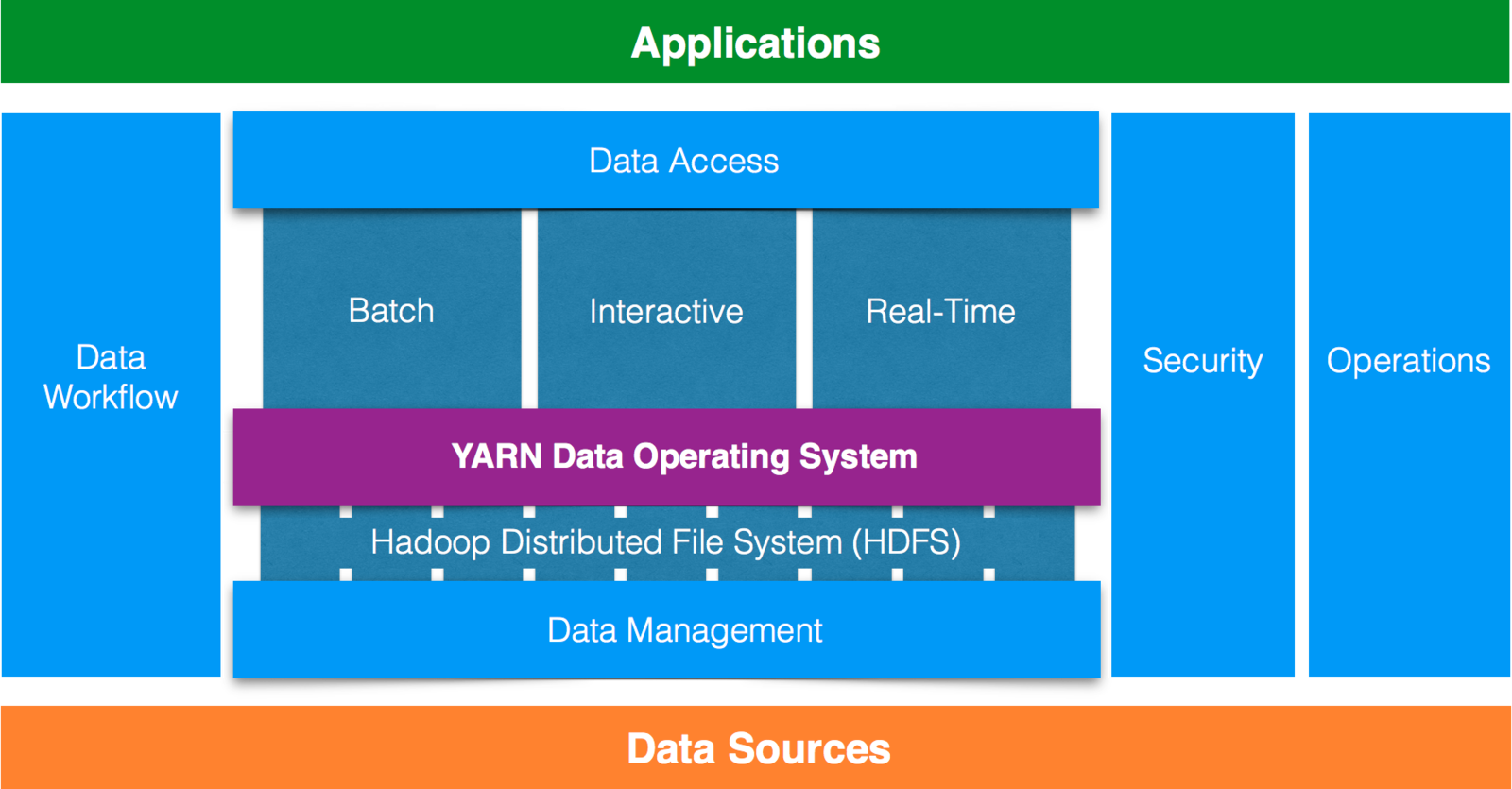
Hadoop Ecosystem
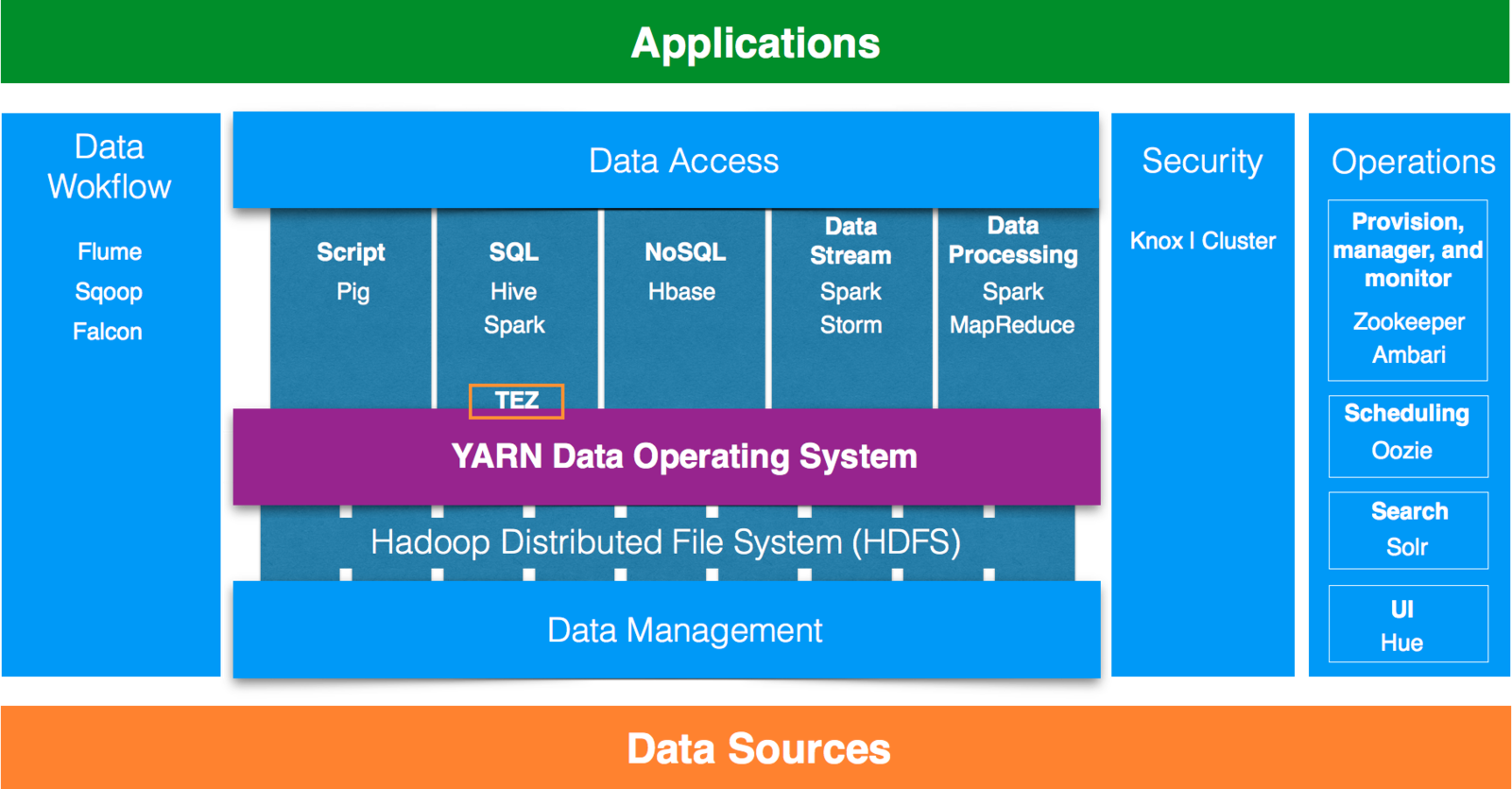




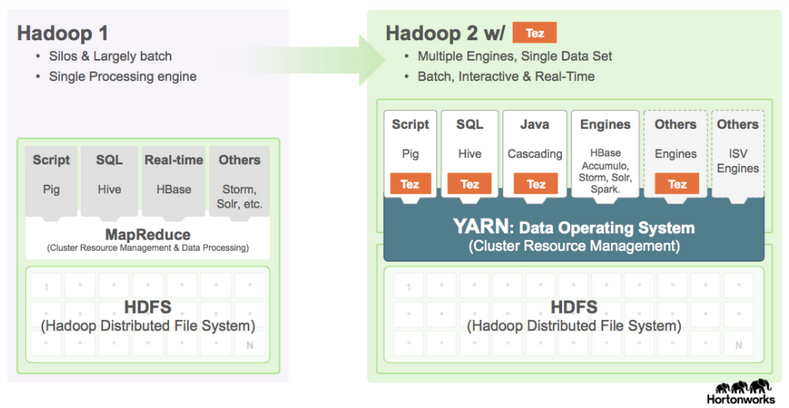
- Framework for data processing.
- Allows multiple data processing engines to use Hadoop as the common standard for batch, interactive and real-time engines that can simultaneously access the same data set.



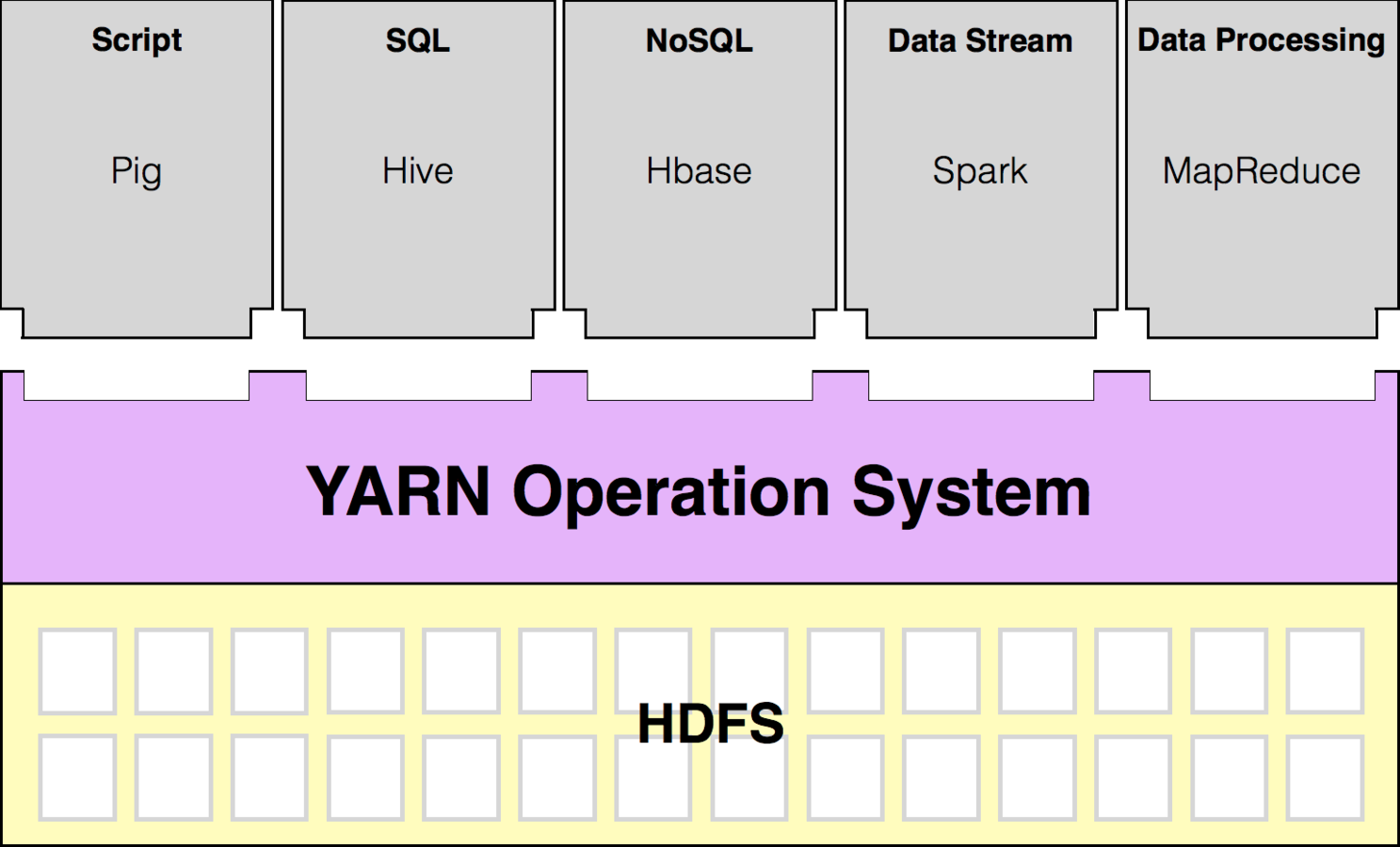
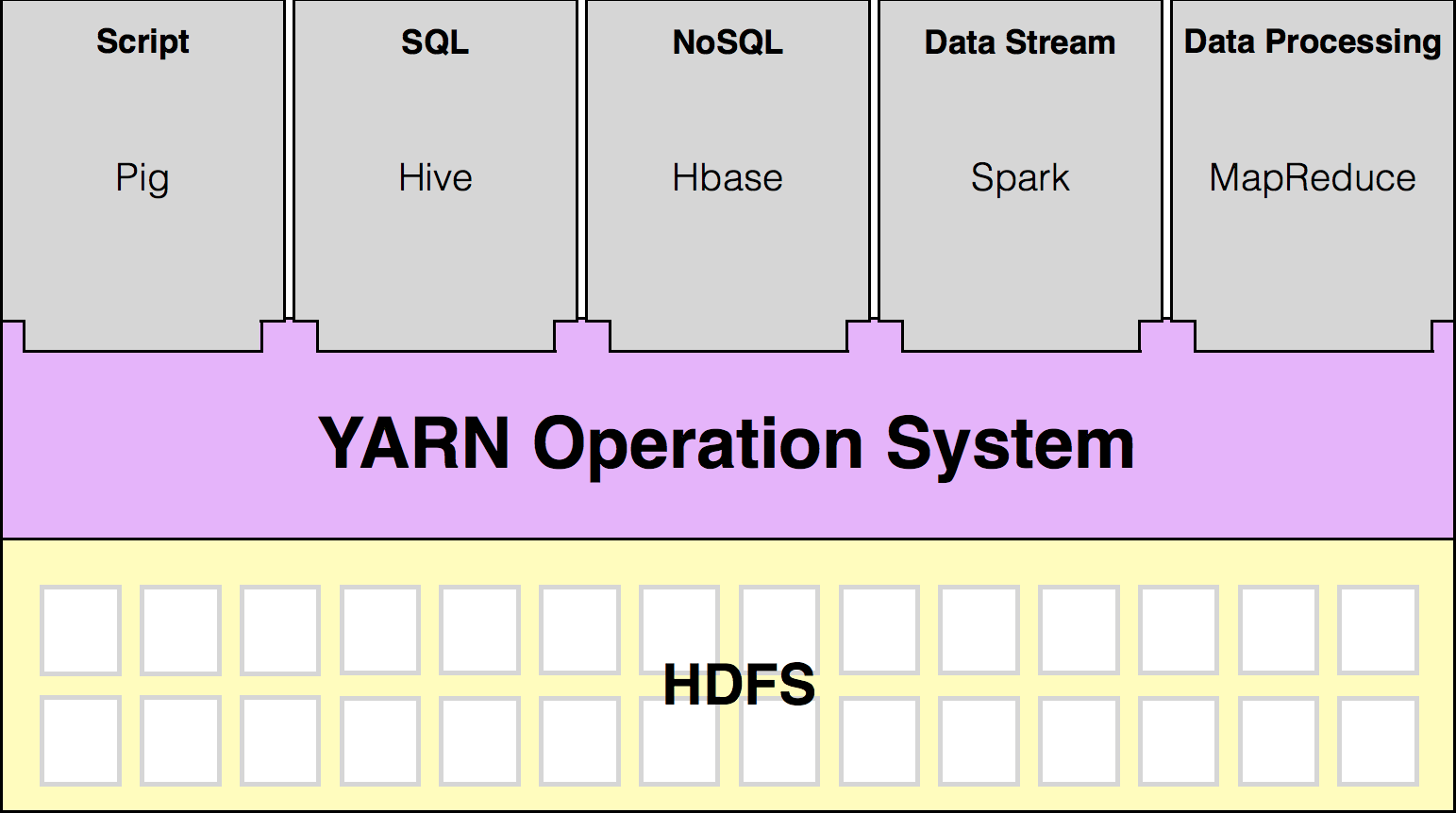

YARN Architecture
YARN Use Case
- At one point Yahoo! had 40k+ nodes spanning multiple datacenters – 365PB+ of data
- YARN provided a compute framework that allowed higher utilization of nodes
- 100% utilization (while being efficient) is always a good thing
- Yahoo! was able to bring down an entire datacenter of about 10k Nodes
Source: Hortonworks


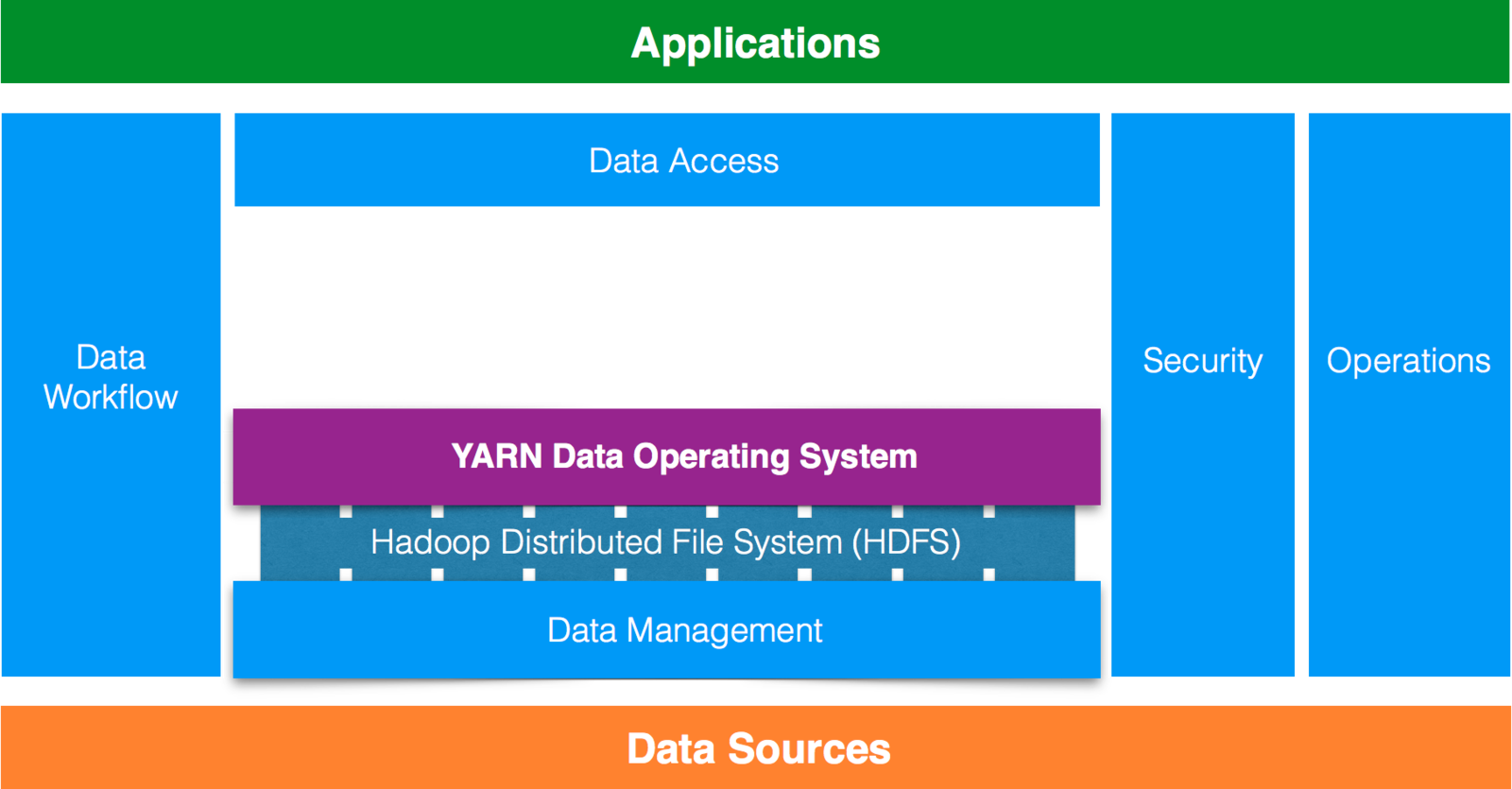
- Java-based distributed file system.
- Stores large volumes of unstructured data and spans across large clusters of commodity servers.
- Works closely with MapReduce.
HDFS Architecture




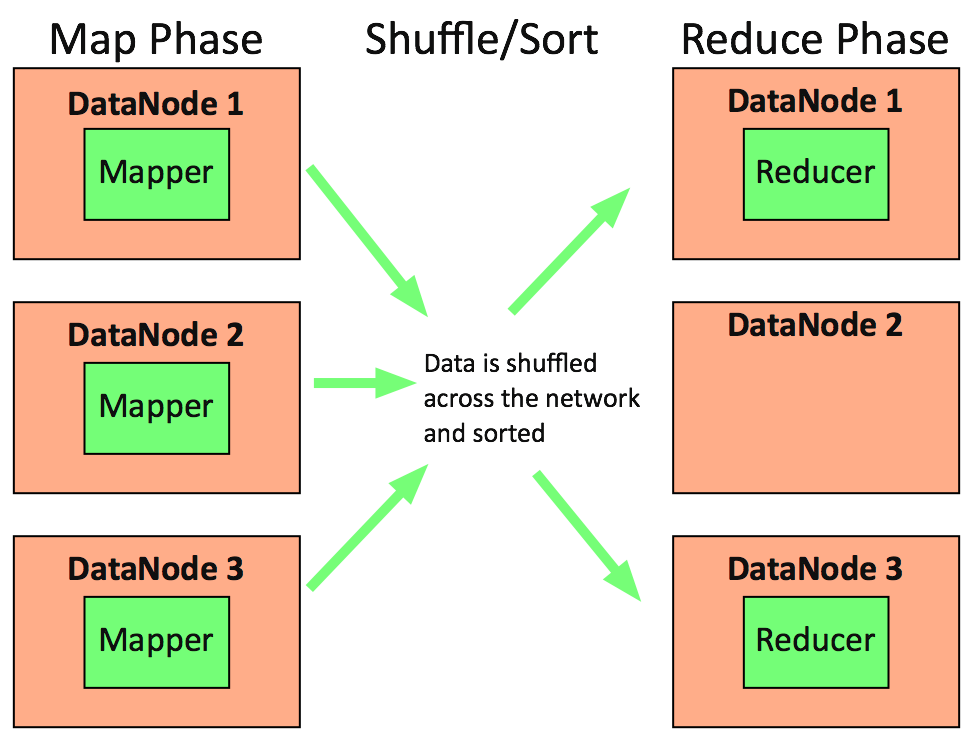
- Framework for writing applications that process large amounts of structured and unstructured data.
- Designed to run batch jobs that address every file in the system.
- Splits a large data set into independent chunks and organizes them into key, value pairs for parallel processing.

MapReduce Architecture
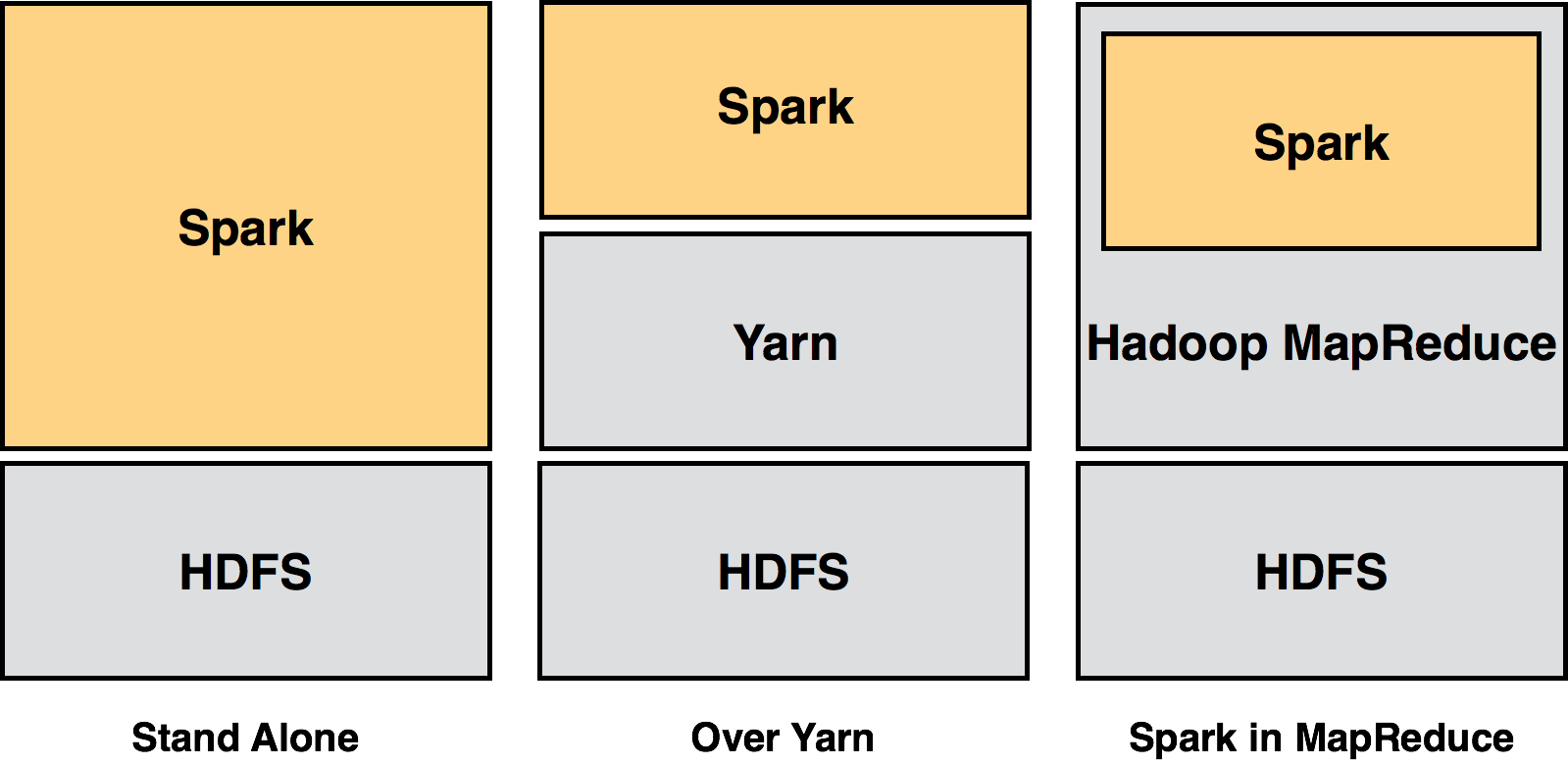
Alternative to the traditional batch map/reduce model that can be used for real-time stream data processing and fast interactive queries that finish within seconds.

MapReduce writes results to disk.
Spark holds intermediate results in memory.
MapReduce supports map and reduce functions.
Spark supports more than just map and reduce functions.



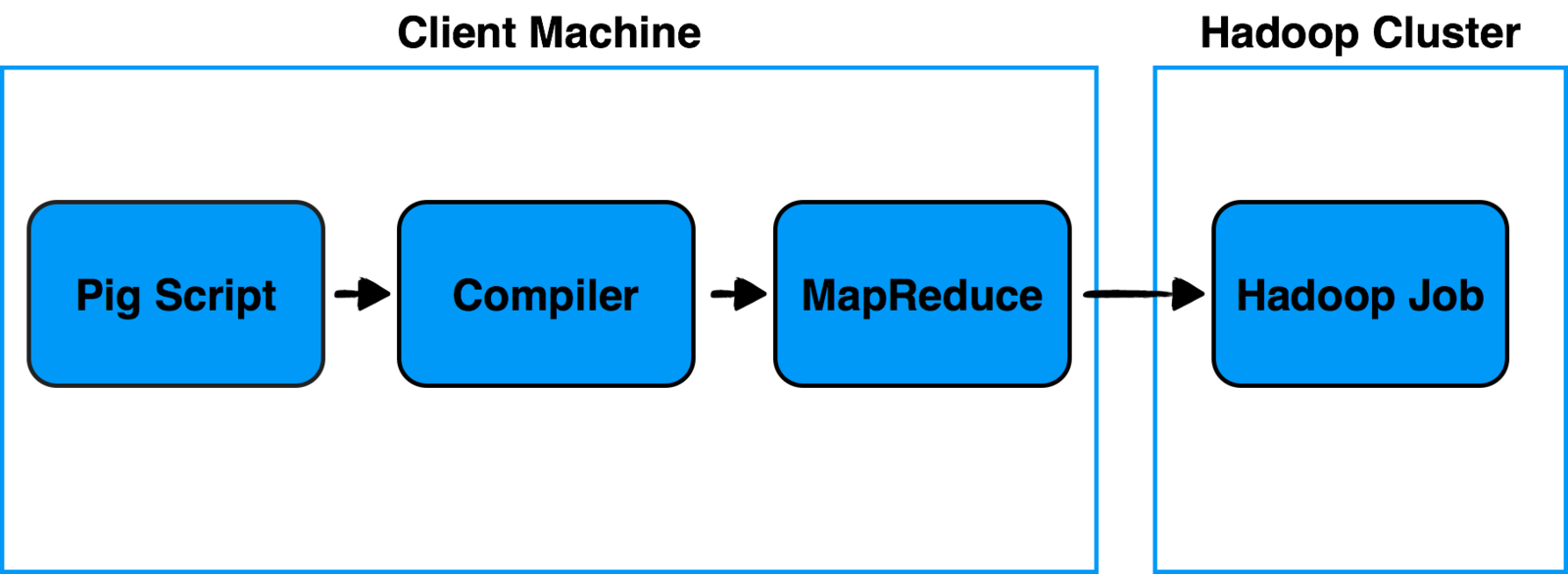
Allows you to write complex MapReduce transformations using a simple scripting language called "Pig Latin". It's made of two components:
- Pig Latin (the language) defines a set of transformations on a data set such as aggregate, join and sort.
- Compiler to translate Pig Latin to MapReduce so it can be executed within Hadoop.
Pig

- Used to explore, structure and analyze large datasets stored in Hadoop's HDFS.
- Provides an SQL-like language called HiveQL with schema on read and converts queries to map/reduce jobs.

Hive Architecture
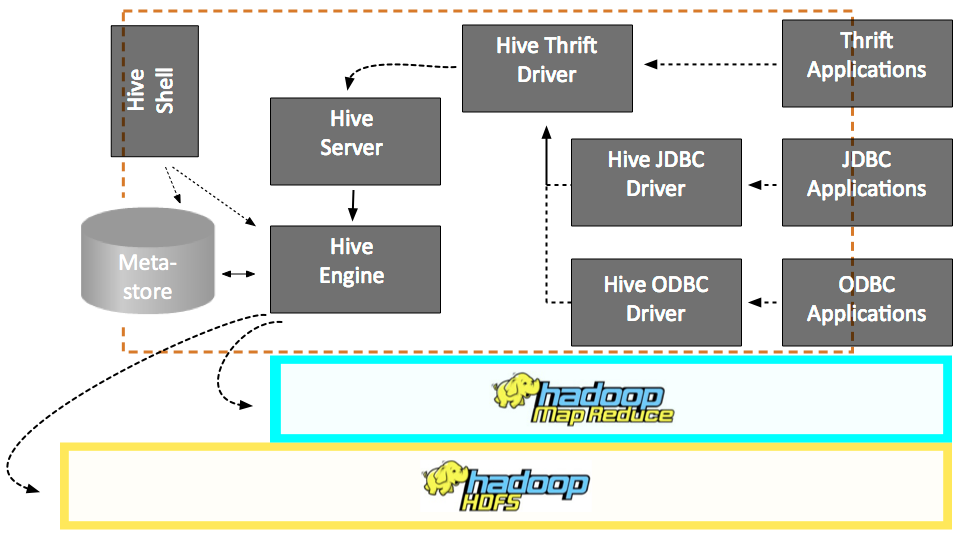
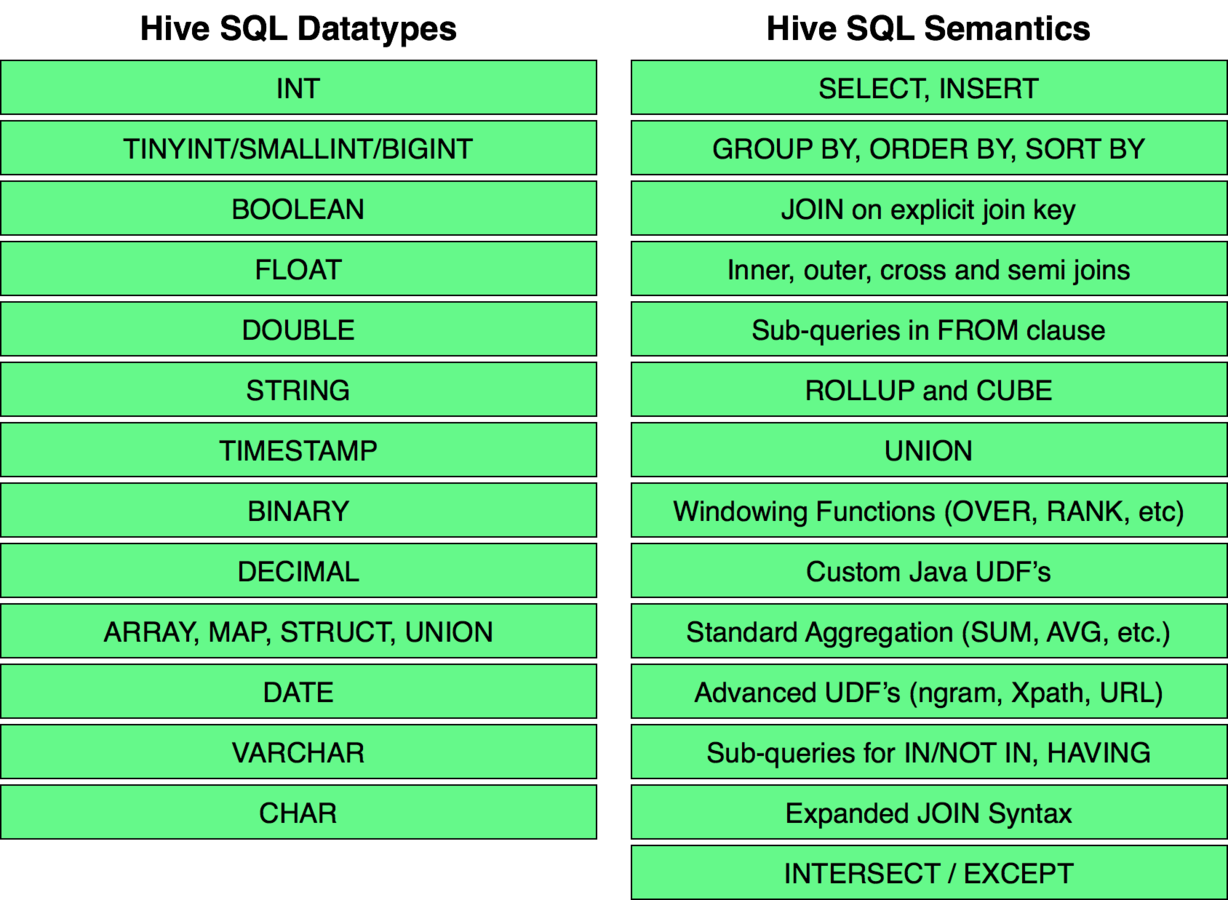
Hive
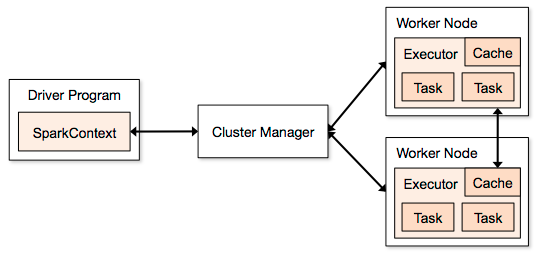
- Part of the Spark computing framework.
- Allows relational queries expressed in SQL, HiveQL, or Scala to be executed using Spark.
- Used for real-time, in-memory, parallelized processing of Hadoop data.
Spark SQL
Spark SQL Use Cases
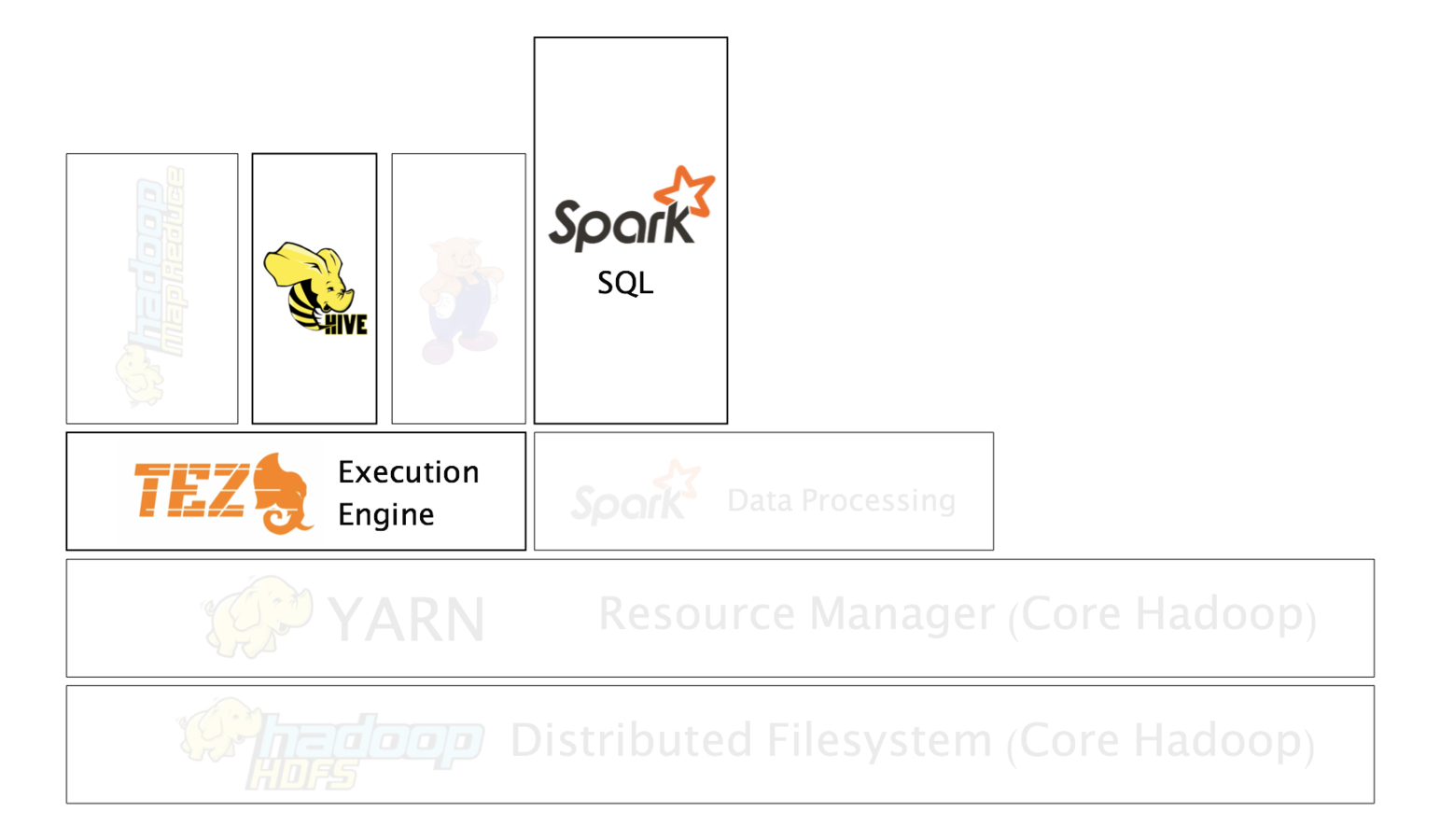
- Extensible framework for building YARN based, high performance batch and interactive data processing applications.
- It allows applications to span the scalability dimension from GB’s to PB’s of data and 10’s to 1000’s of nodes.

TEZ
Using Tez to create Hadoop applications that integrate with YARN
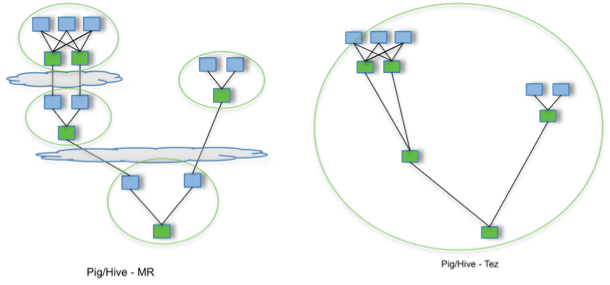
TEZ
By allowing projects like Apache Hive and Apache Pig to run a complex DAG of tasks, Tez can be used to process data, that earlier took multiple MR jobs, now in a single Tez job as shown above.

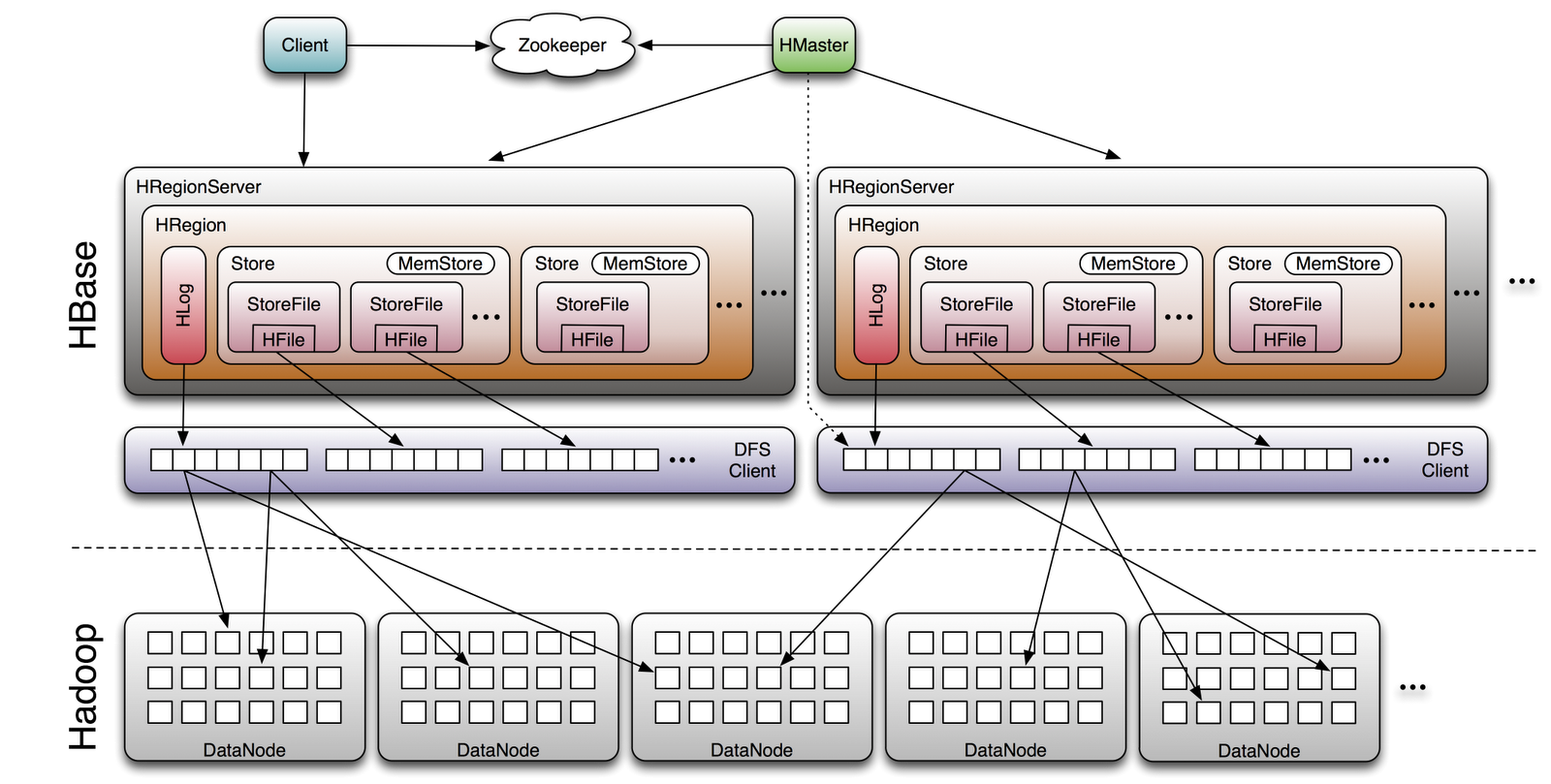
Column oriented database that allows reading and writing of data to HDFS on a real-time basis.
- Designed to run on a cluster of dozens to possibly thousands or more servers.
- Modeled after Google's Bigtable
- EBay and Facebook use HBase heavily.

When to use HBase?
- When you need random, realtime read/write access to your Big Data.
- When hosting very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware.
HBase 101 Architecture

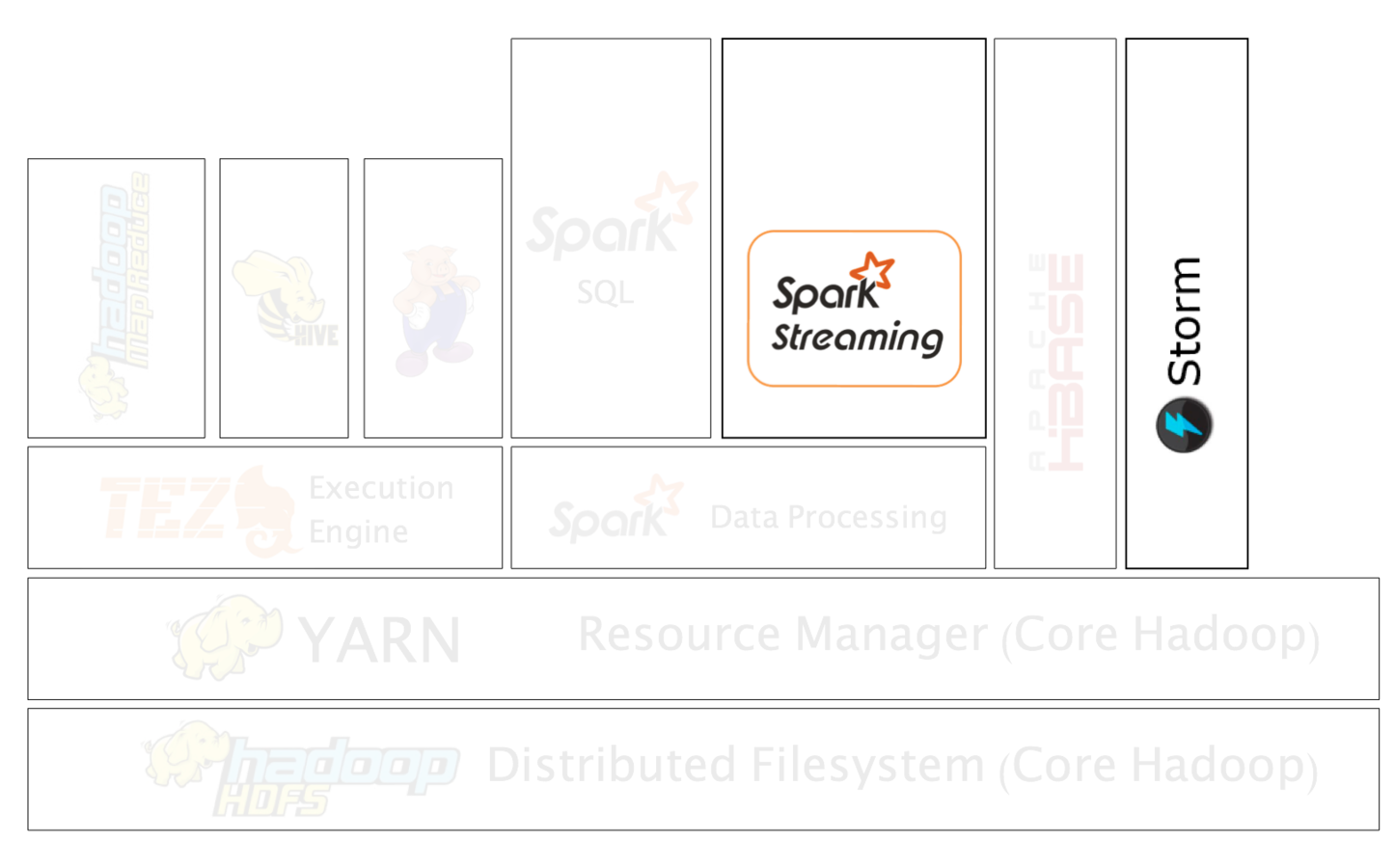

- Distributed real-time computation system for processing fast, large streams of data.
- With Storm and MapReduce running together in Hadoop on YARN, a Hadoop cluster can efficiently process a full range of workloads from real-time to interactive to batch.
Storm Characteristics

Storm
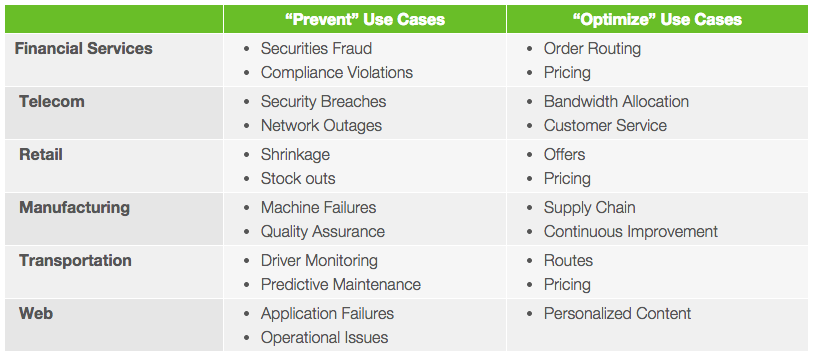
Enterprises use Storm to prevent certain outcomes or to optimize their objectives. Here are some “prevent” and “optimize” use cases.
Storm
- Part of the Spark computing framework.
- Easy and fast real-time stream processing.
- Provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data.

Spark Characteristics

Spark

Spark



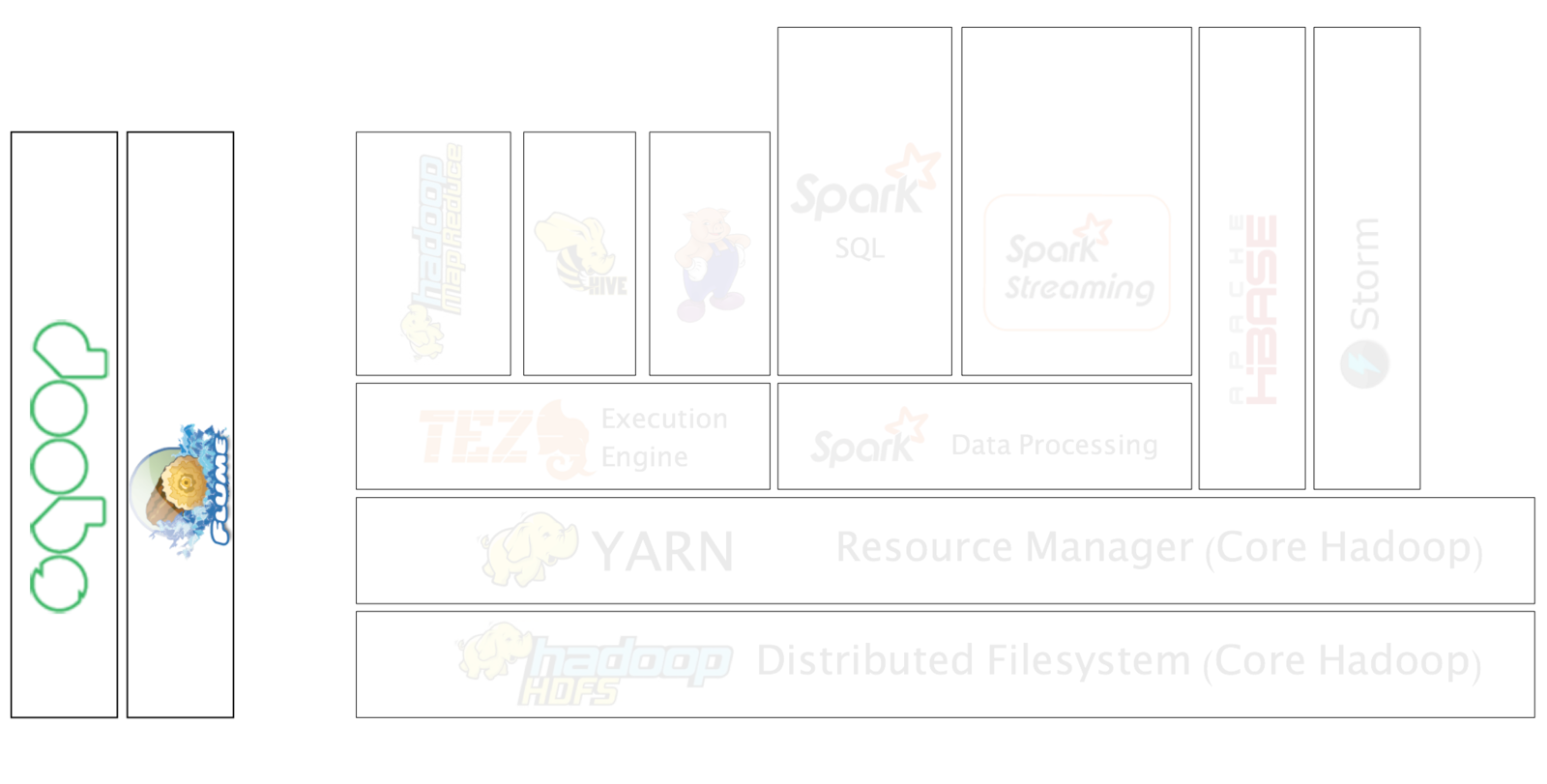
Command-line interface application used to transfer data to and from Hadoop to any RDMS.
Sqoop: Importing to Hive
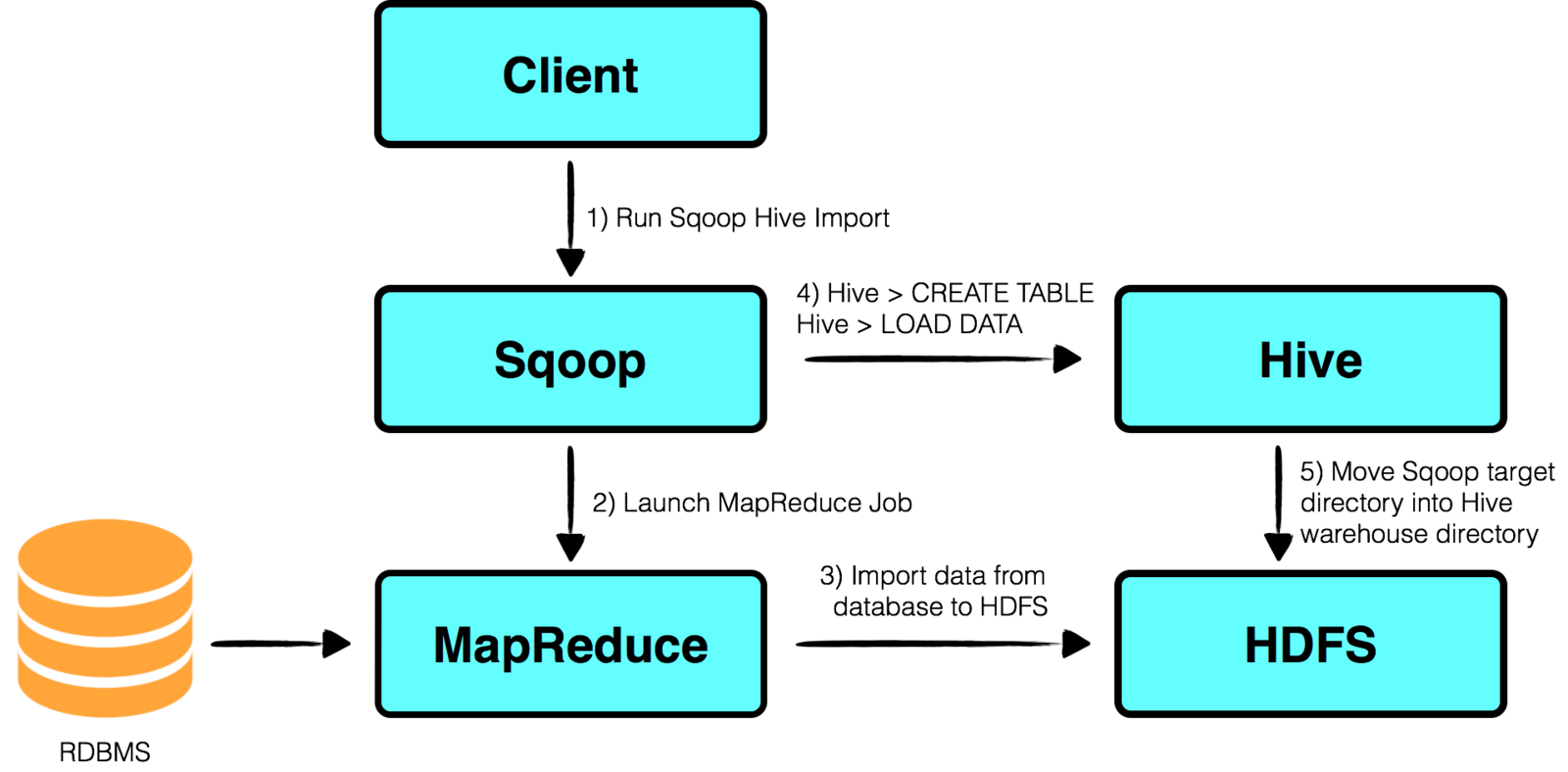
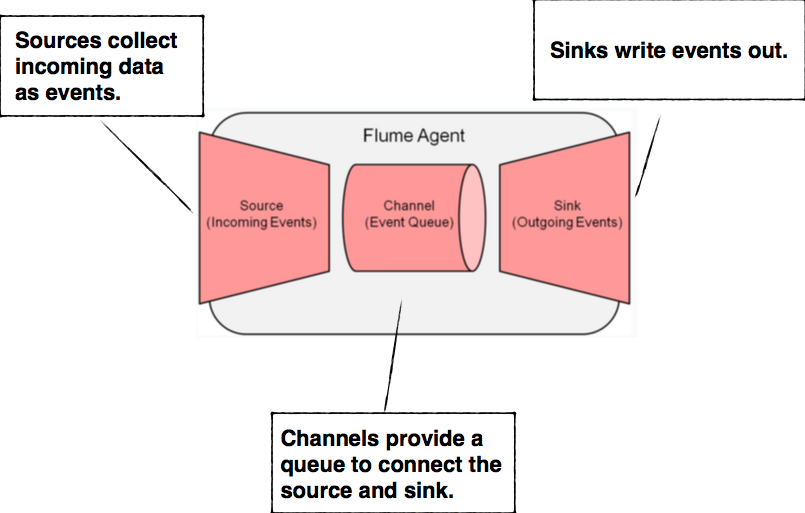
Application that collects, aggregates, and moves large amounts of streaming data into the Hadoop Distributed File System (HDFS).
Flume

Flume
Agents consist of three pluggable components: sources, sinks, and channels. An agent must have at least one of each in order to run.


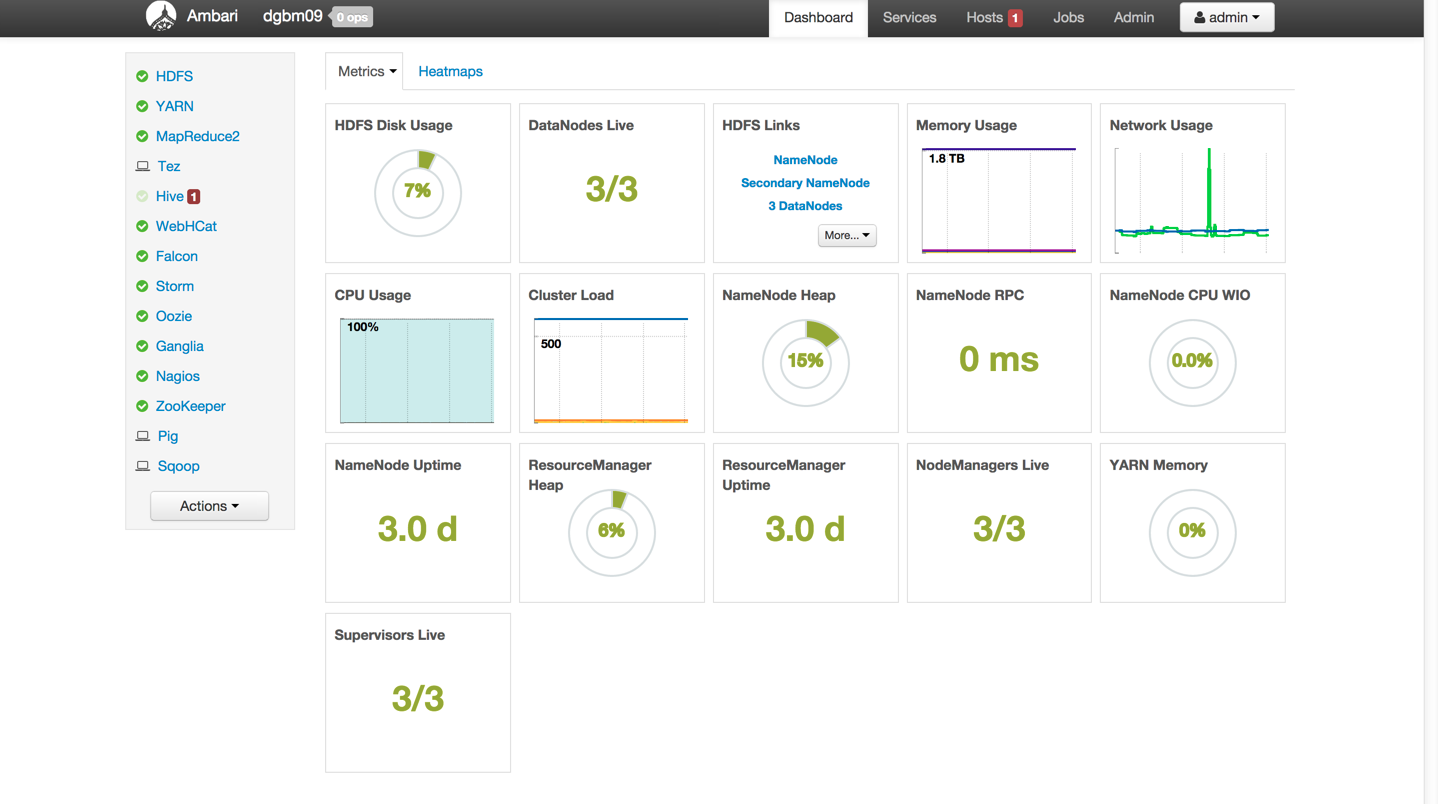
Operational framework for provisioning, managing and monitoring Apache Hadoop clusters.

Ambari Dashboard
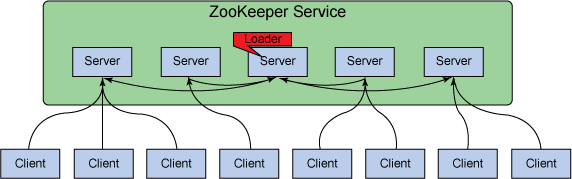
Provides configuration service, synchronization service, and naming registry for software in the Hadoop ecosystem.
Zookeeper Benefits


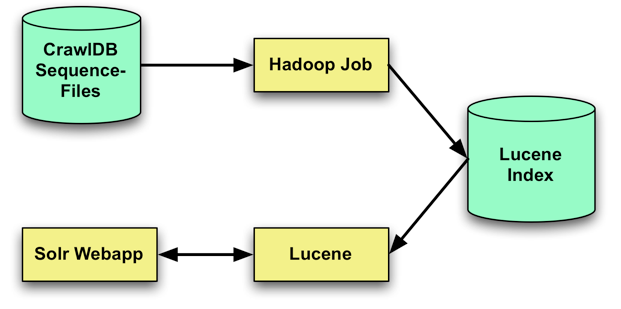
- Searches data stored in HDFS in Hadoop.
- Powers the search and navigation features of many of the world’s largest Internet sites, enabling powerful full-text search and near real-time indexing.
Solr Features
- Near real-time indexing
- Advanced full-text search
- Comprehensive HTML administration interfaces
- Flexible and adaptable, with XML configuration
- Server statistics exposed over JMX for monitoring
- Standards-based open interfaces like XML, JSON and HTTP
- Linearly scalable, auto index replication, auto failover and recovery
An open-source Web interface that supports Apache Hadoop and its ecosystem.
Hue



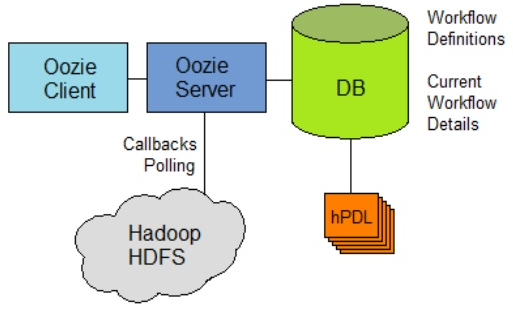
- Workflow scheduler system to manage Apache Hadoop jobs.
- There are two basic types of Oozie jobs:

Oozie Architecture

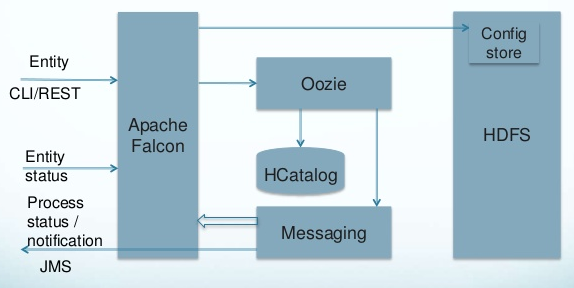
Framework that simplifies data management by allowing users to easily configure and manage data migration, disaster recovery and data retention workflows.
Falcon Architecture

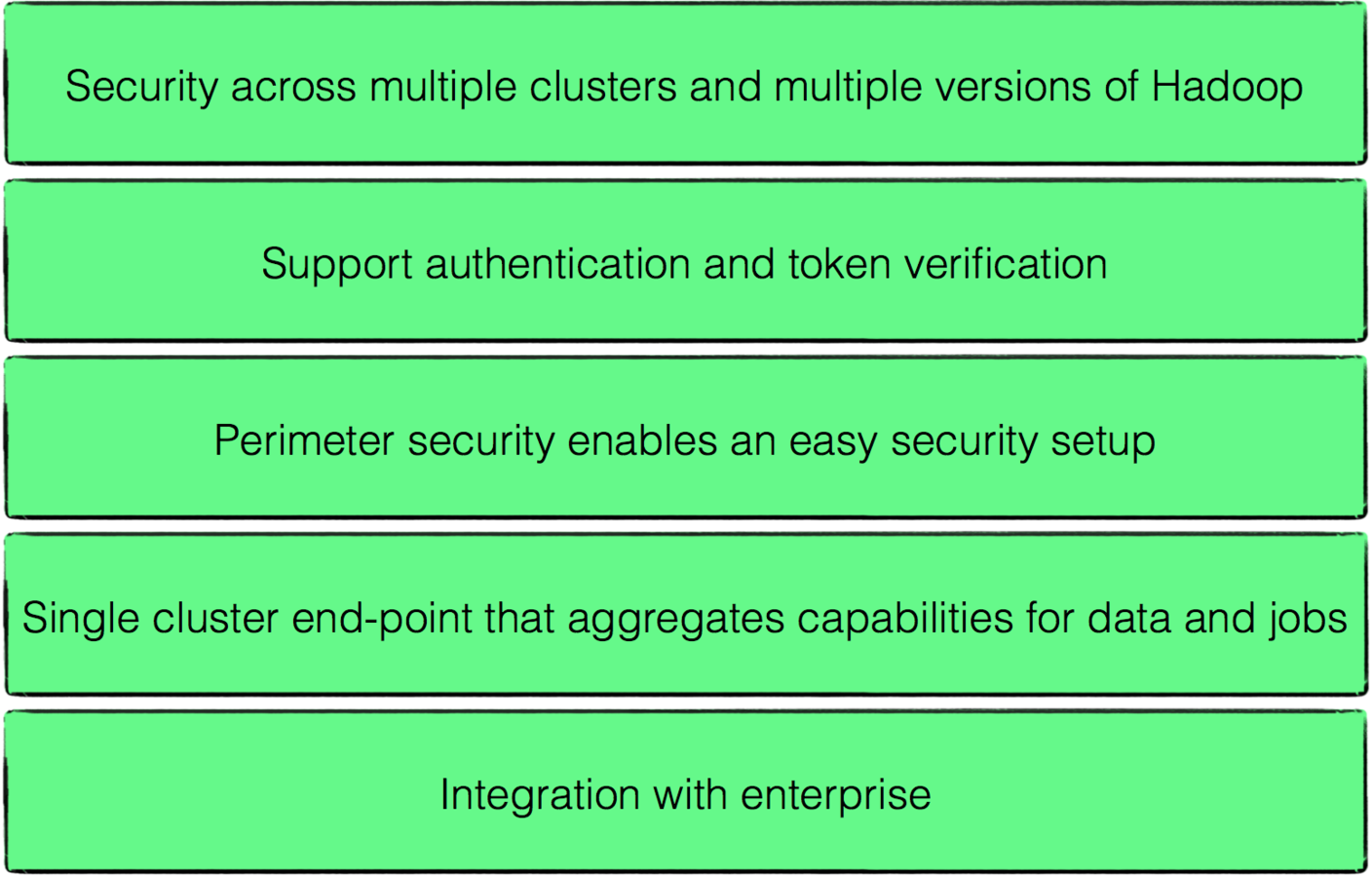
- Provides a single access point for Hadoop services in a cluster.
- Knox runs as a server (or cluster of servers) that serve one or more Hadoop clusters.

Knox Advantages
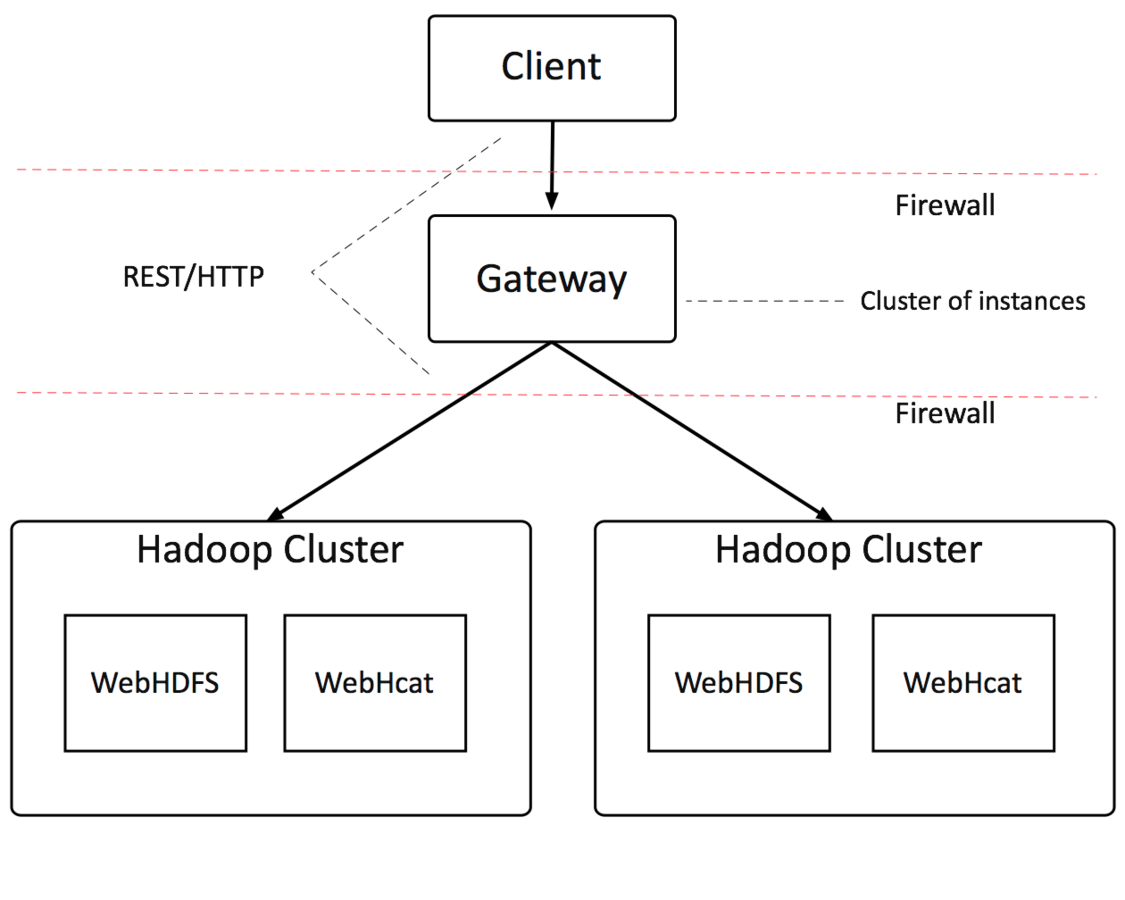
Knox Architecture
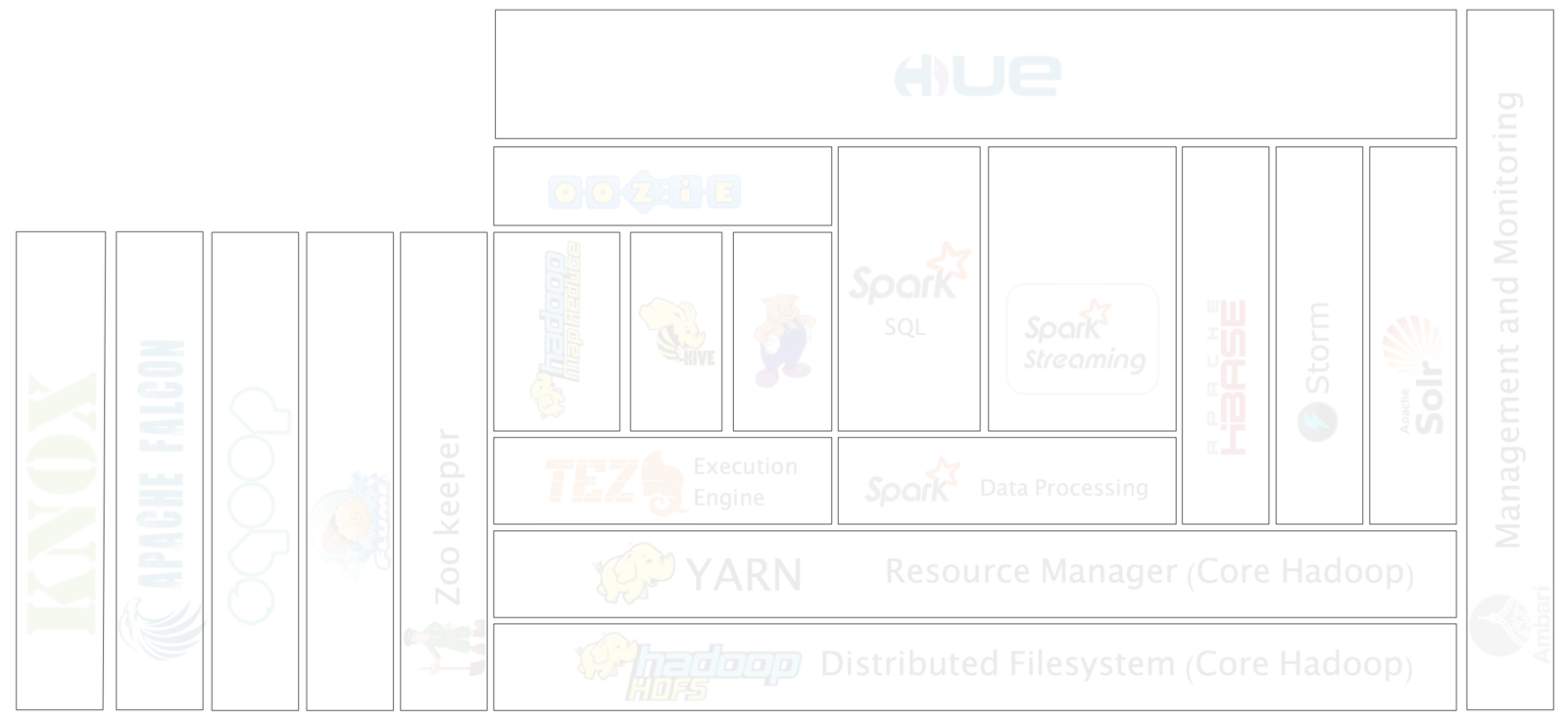
Let's take another look at the ecosystem
Find a use case for your group's assigned component

Hadoop Ecosystem
Hadoop Use Cases
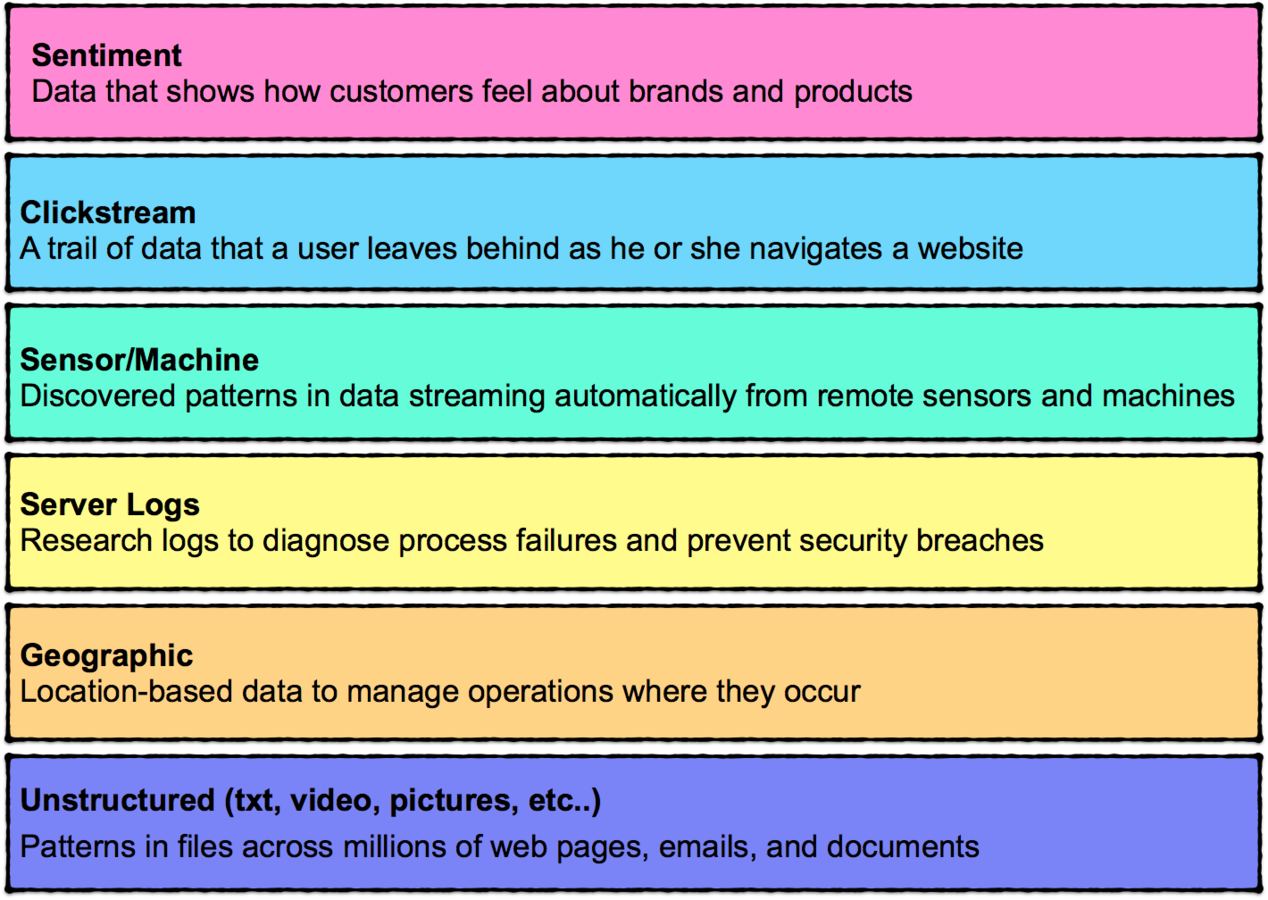
Sentiment Data
Data collected from social media platforms ranging from Twitter, to Facebook, to blogs, to a never-ending array websites with comment sections and other ways to socially interact on the Internet.
Sentiment Data

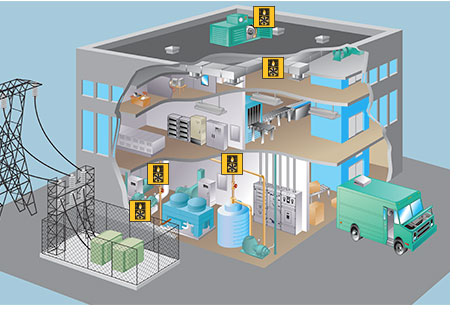
Sensor/Machine Data
Data collected from sensors that monitor and track very specific things, such as temperature, speed, location
Sensor Data
HVAC
Geographic Data
Geolocation data gives organizations the ability to track every moving aspect of their business, be they objects or individuals.
Geographic Data
Clickstream Data
Stream of clicks that a user takes as they path through a website.
- Path Optimization
- Basket Analysis
- Next Product to Buy Analysis
- Allocation of Website Resources
- Granular Customer Segmentation
Clickstream Data
Server Log Data
Server log data is for security analysis on a network.

Server Log Data
Unstructured Video
Data from non-text-based things; that includes both images and also video.
Unstructured Video
Unstructured Text
Data collected from free-flowing text sources such as documents, emails, and tweets.
Unstructured Text

Rackspace Use Case
Analytics Compute Grid
- Analytics Compute Grid is a data analysis project
- Rackspace uses Hadoop along with other big data technologies to understand customer patterns and identify trends.
- This allows us to be better at delivering fanatical support to our customers using multiple data sources and systems.
Rackspace Analytics Compute Grid
Big Data: After Re-Architecting for Private Cloud

Popular Companies Leveraging Hadoop
Data Refinement...Distilling large qualities of structured and unstructured data for use in a traditional DW, e.g.: "sessionizatiuon" of weblogs
Data Exploration across unstructured content on millions of customer satisfaction surveys to determine sentiment.
Application Enrichment provides recommendations and personalized experience to website for each unique visitor.
Use Case by Industry
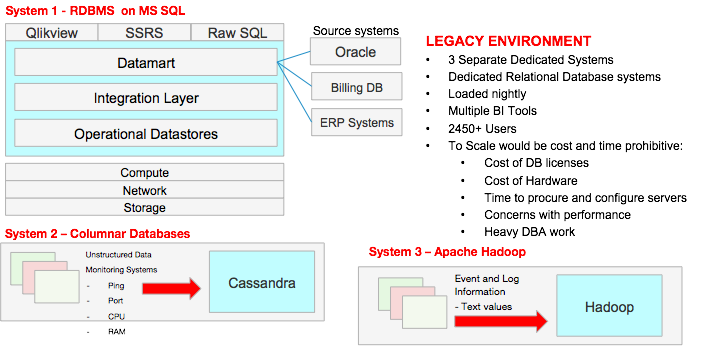
Financial Services

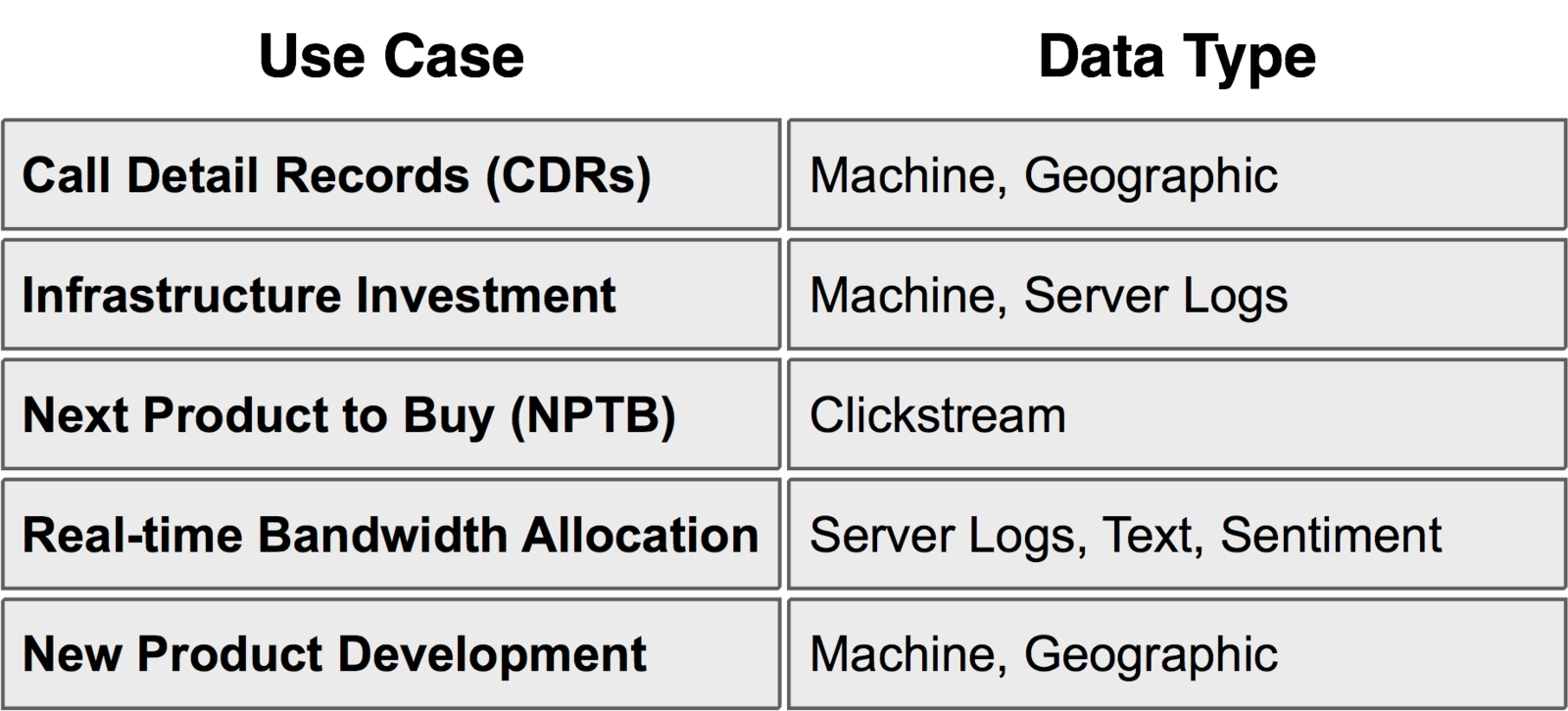
Telecom
Retail
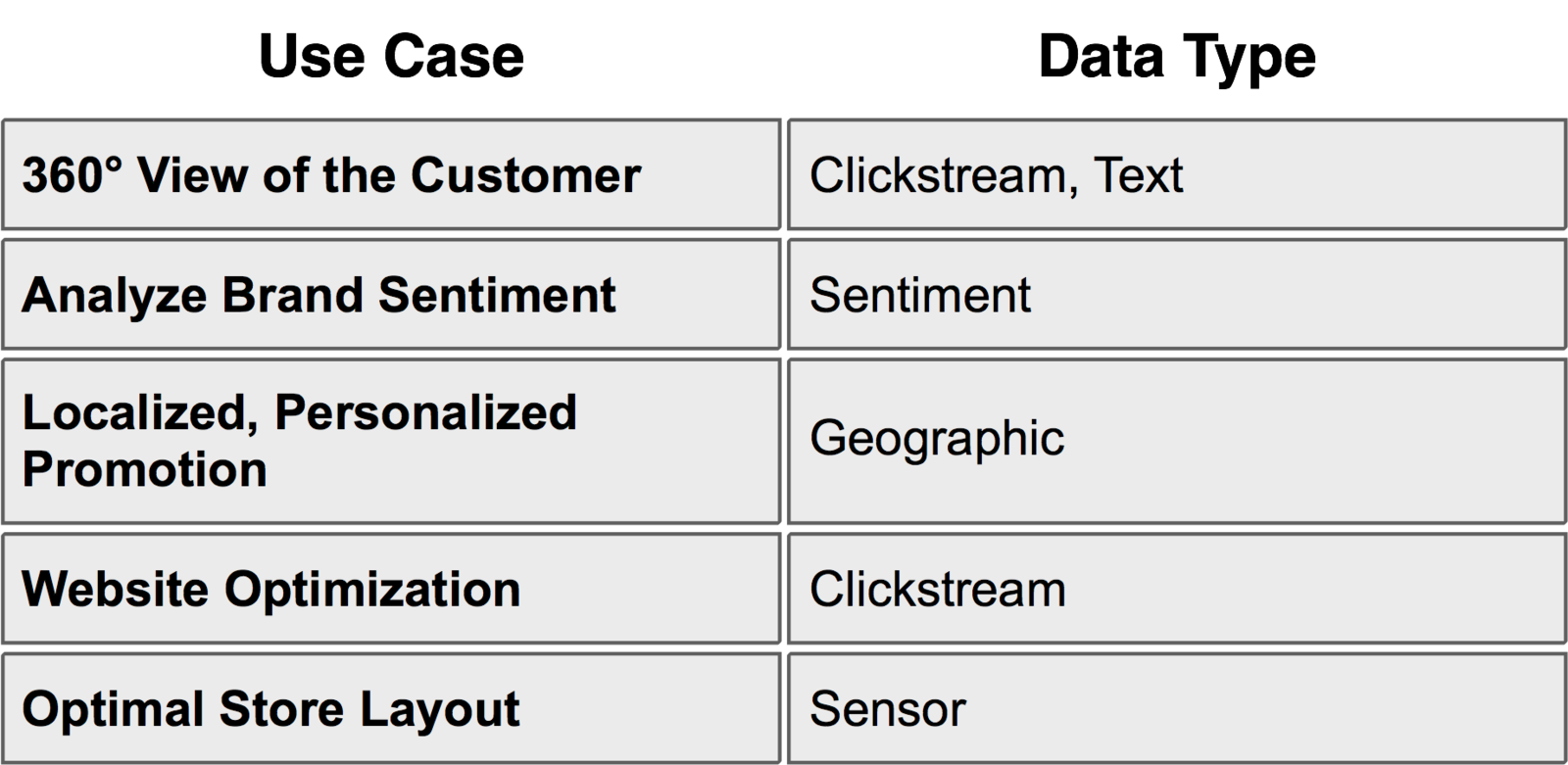
Manufacturing

Healthcare
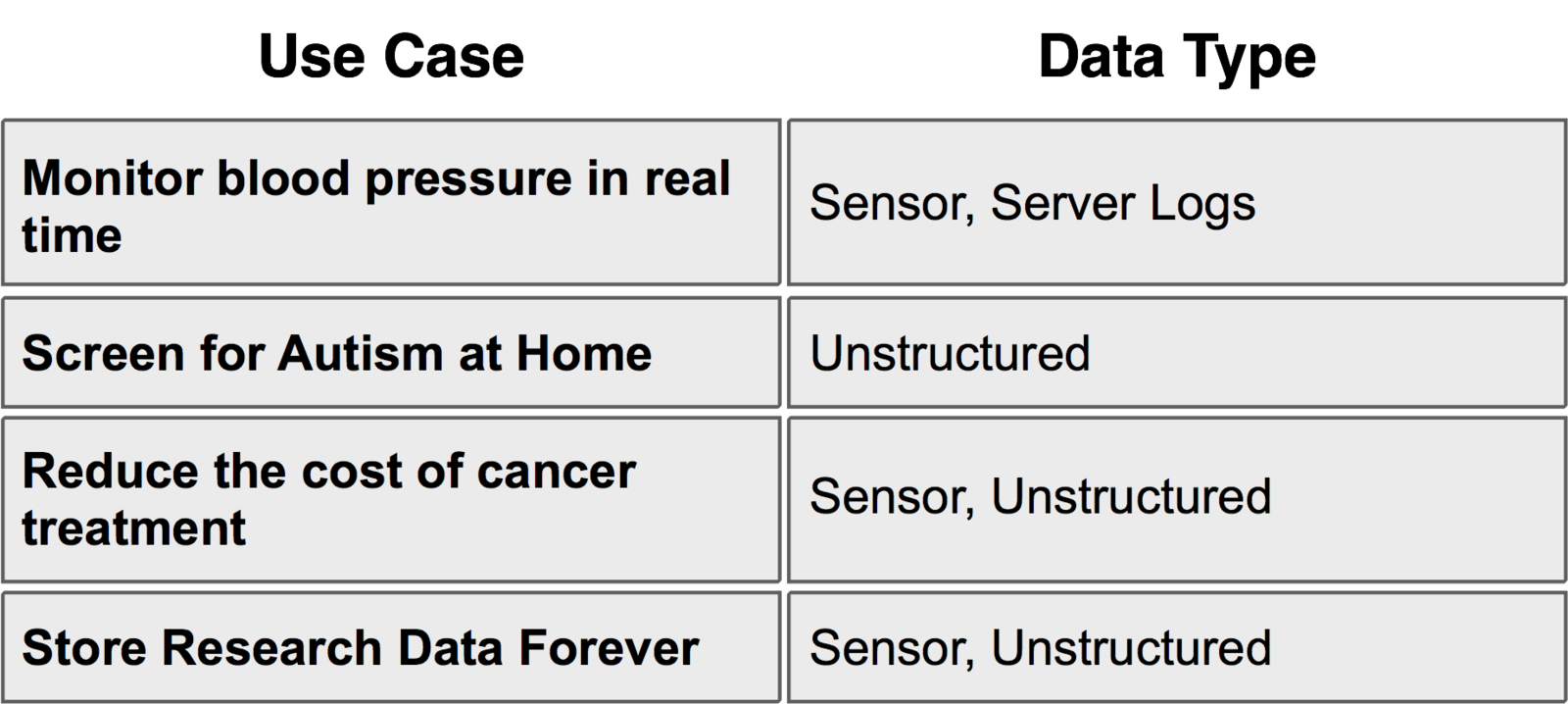
Oil and Gas
Pharmaceutical

Rackspace Big Data Platform
Managed and Cloud Big Data
Big Data Platform


Managed Big Data Platform

Cloud Big Data Platform
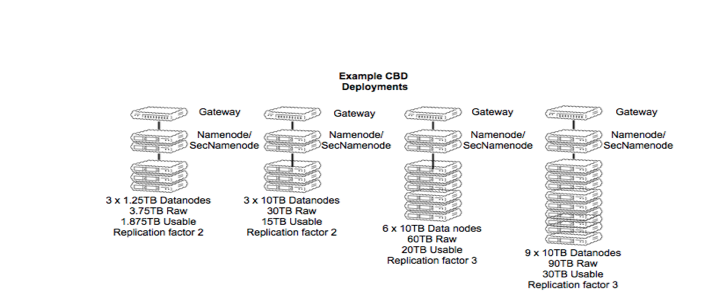
Cloud Big Data
Supporting Hosting Environments


Hybrid Cloud

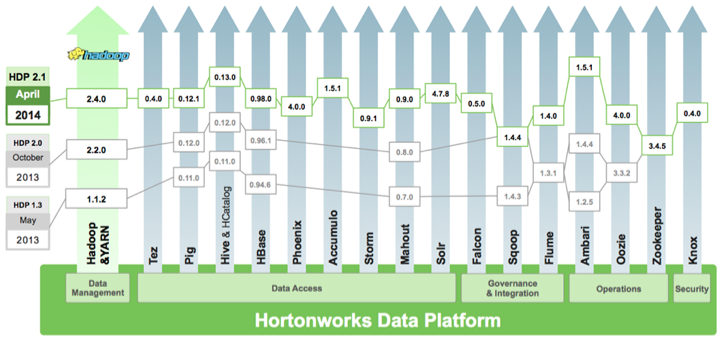
Hortonworks Data Platform

Rackspace Cloud Control
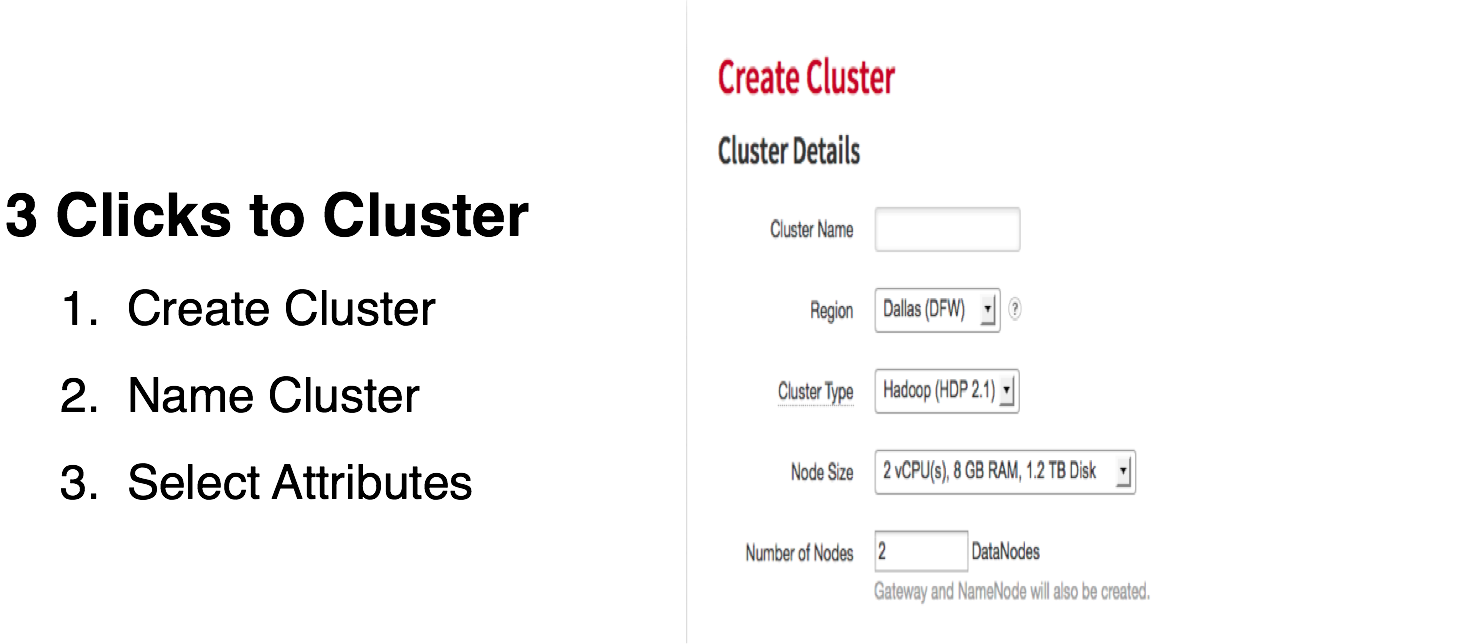
Building a CBD Cluster
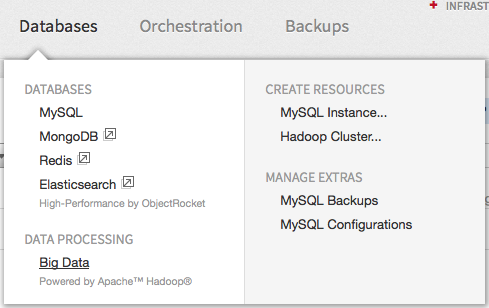
In the mycloud portal, select Big Data from the Databases menu:
Click on Create Cluster:
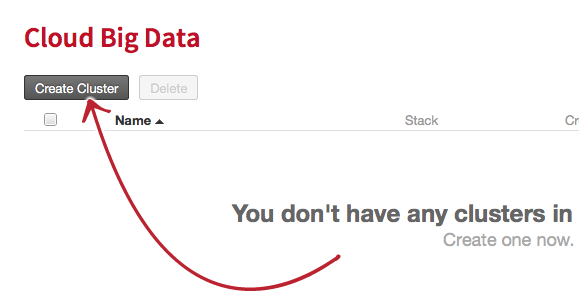
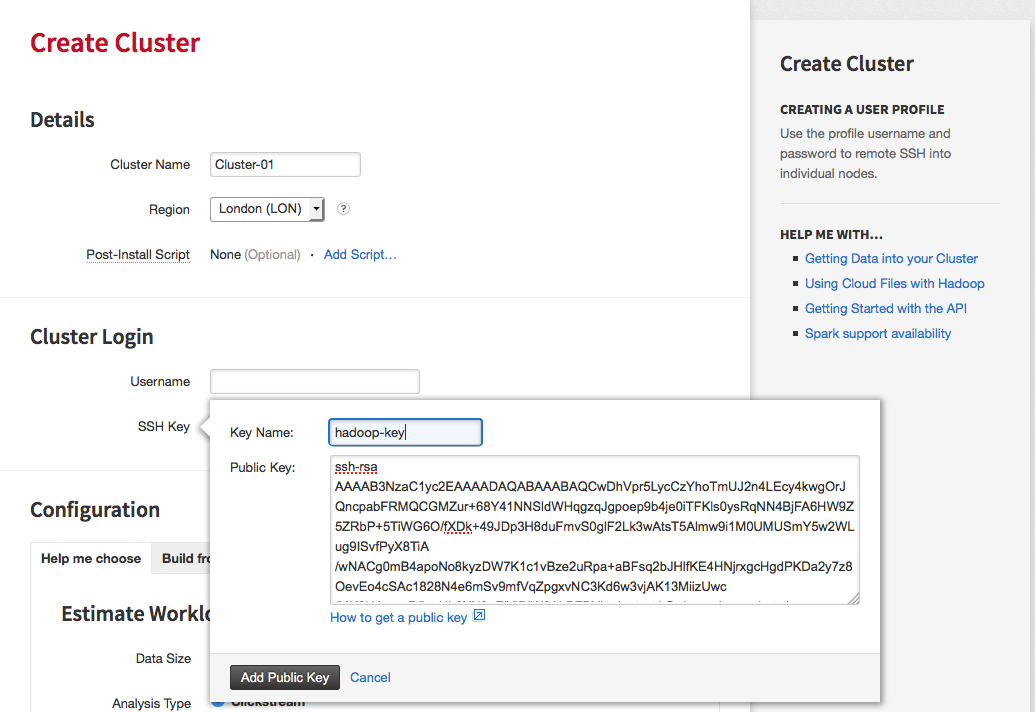
Set the cluster name, select a region and set the SSH username and SSH key:
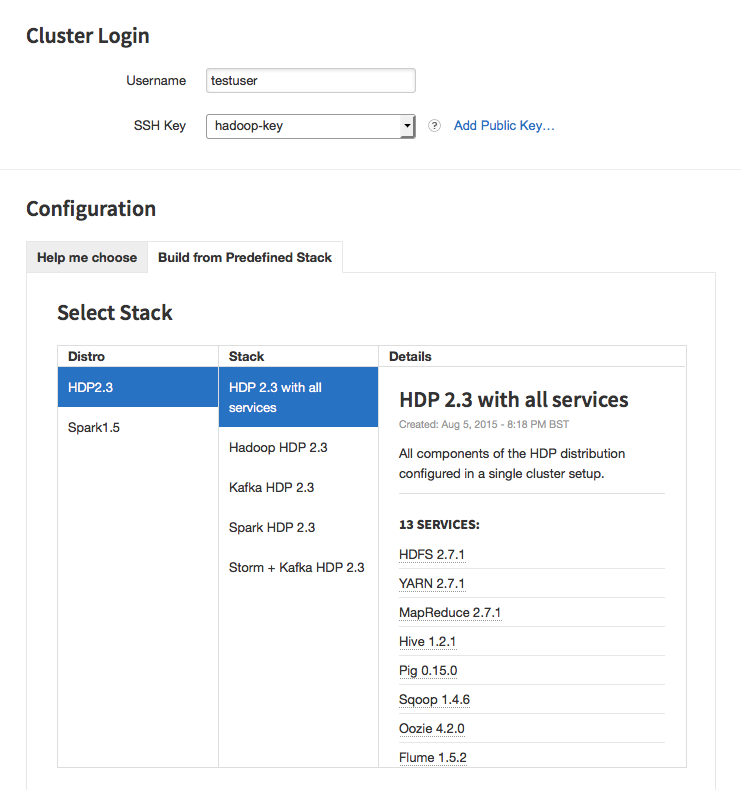
Select the Stack by clicking on Build from Predefined Stack link.
For the purpose of this exercise, use HDP 2.3 with all services:
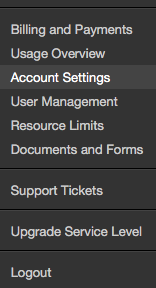
Add the Rackspace Cloud API key in order to access Cloud Files from Hadoop:

The username and the key can be found on the mycloud portal under the Account Settings menu:
CBD Stacks
Hadoop HDP 2.3
- Includes:
- HDFS, YARN, MapReduce, Hive, Pig, Sqoop, Oozie, Flume, Zookeeper, Hue
- Use cases:
- Core batch processing systems (MapReduce workloads), interactive querying with Hive, Pig scripting (good for ETL and data validation), workflow scheduling, log aggregation/collection and a GUI for Hadoop
Hadoop HDP 2.3 with all services
- Includes:
- HDFS, YARN, MapReduce, Hive, Pig, Sqoop, Oozie, Flume, Storm, Kafka, Zookeeper, Falcon, Hue
- Use cases:
- Same as Hadoop HDP 2.3 plus a distributed message queuing system (Kafka), data lifecycle management (Falcon) and real-time stream processing (Storm)
Kafka HDP 2.3
- Includes:
- HDFS, Kafka, Zookeeper
- Use cases:
- An individual Kafka stack serving as a distributed message queuing system
Spark HDP 2.3
- Includes:
- HDFS, YARN, MapReduce, Hive, Pig, Oozie, Zookeeper, Spark, Hue
- Use cases:
- Spark on Yarn supporting both fast batch and real-time processing. It also includes the core batch processing systems (MapReduce), interactive querying with Hive, Pig scripting (good for ETL and data validation), workflow scheduling and a GUI for Hadoop
Storm + Kafka HDP 2.3
- Includes:
- HDFS, YARN, MapReduce, Hive, Storm, Kafka, Zookeeper, Hue
- Use cases:
- Focused on real-time stream processing with Storm/Kafka but also includes the core batch processing systems (MapReduce), interactive querying with Hive and a GUI for Hadoop
Spark-Tachyon 1.5
- Includes:
- HDFS, Spark, Tachyon, Zookeeper, Zeppelin
- Use cases:
- Spark standalone supporting both fast batch and real-time processing with an in-memory filesystem, plus interactive data analytics and data visualization
Cloud Big Data with RackConnect v3
RackConnect v3
- Uses Cloud Networks which can be consumed between dedicated-cloud accounts, as well connected between cloud accounts
- layer 3 routing
- No in-instance automation needed
- like it was on RCv2
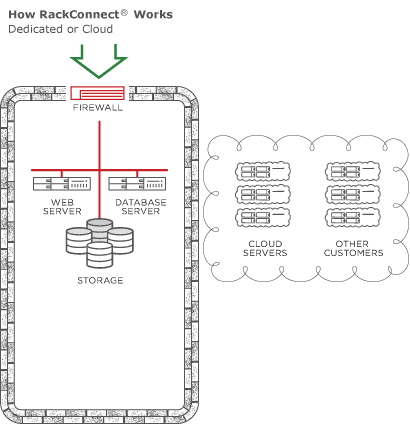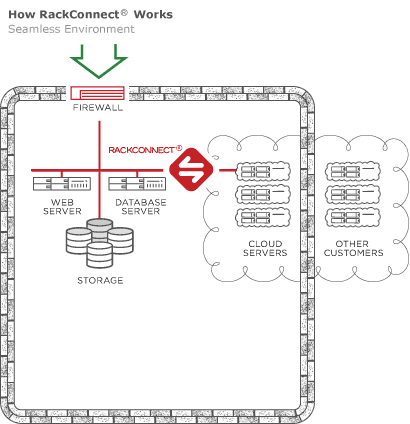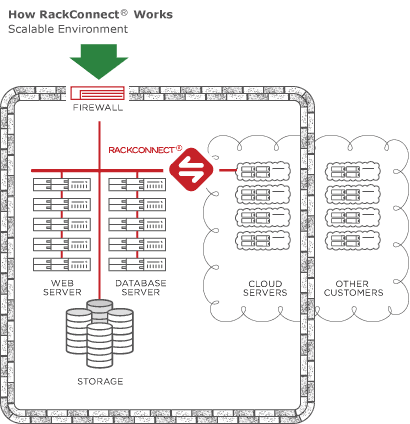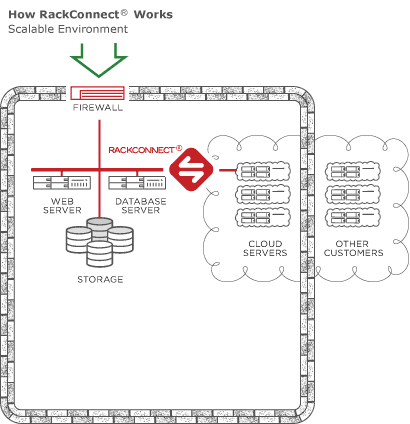
CBD on RackConnect v3
- As of October, 2015 Cloud Big Data builds are compatible with RCv3
Deploying CBD on RackConnect v3
- Customer request for a RCv3 CBD cluster lands with the CDE team. CDE team communicates with RC DevOps team to set it up
- Tasks:
- nexthop information is gathered (RC Devops team)
- Cloud Network is created via lava-admin client. (CDE Team)
- When Rackconnect automation to complete, NSX GW attachment is moved to the Cloud Network created by CDE team (RC DevOps)
- Cloud Network is enabled for the tenant by using lava-admin client (CDE Team)
- Cluster is created using lava-admin client (CDE Team)
- Cluster is validated and handed over to the customer to consume (CDE Team)

- Kafka is a scalable, durable, and fault-tolerant publish-subscribe messaging system
- It's system design can be thought of as that of a distributed commit log, where incoming data is written sequentially to disk.
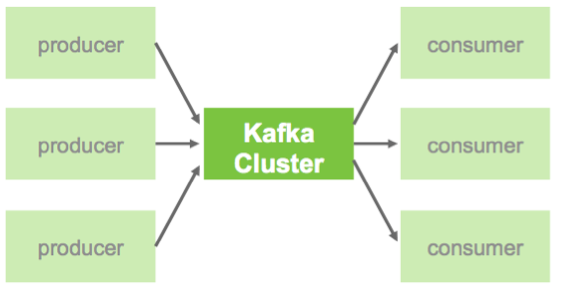

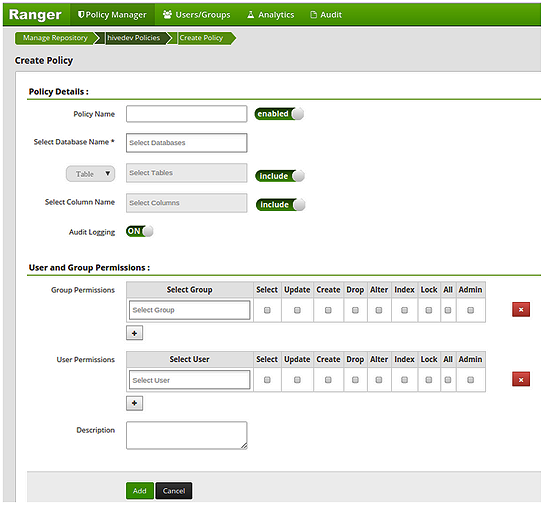
- Framework that monitors and manage data security across the hadoop platform
- In the Ranger console, you can create policies for access to files, folders, databases, tables and columns on a user/group basis

Hadoop Fundamentals 2016
By Rackspace University




