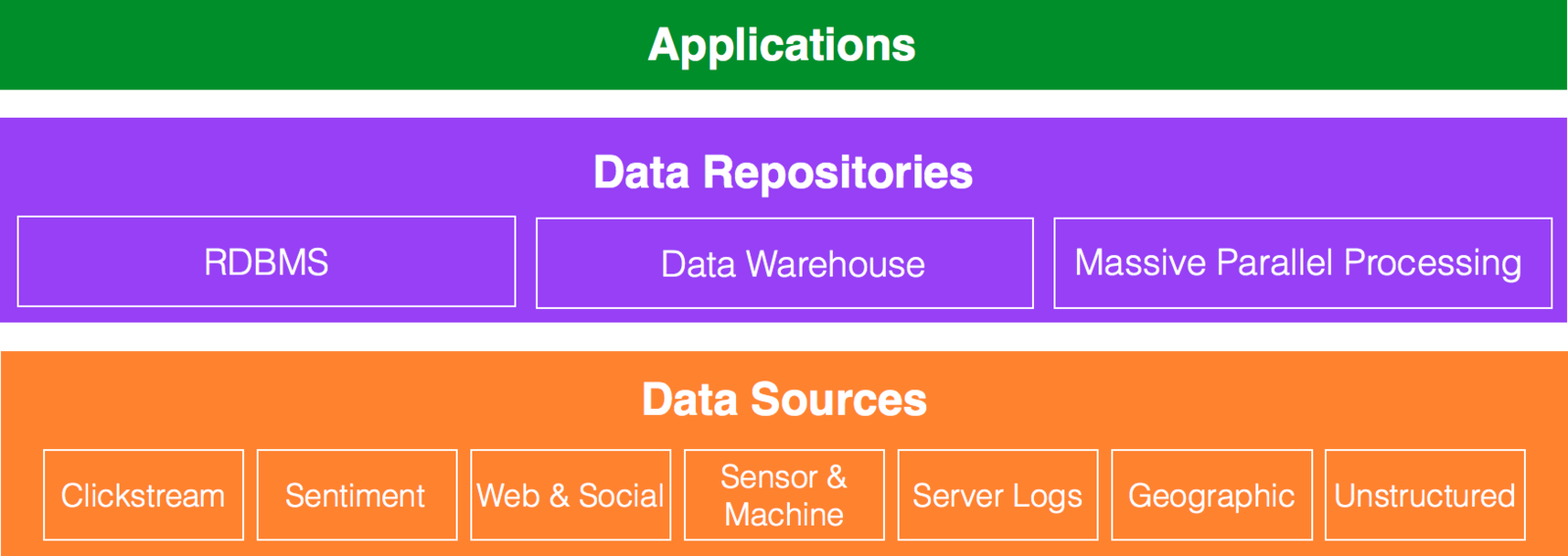
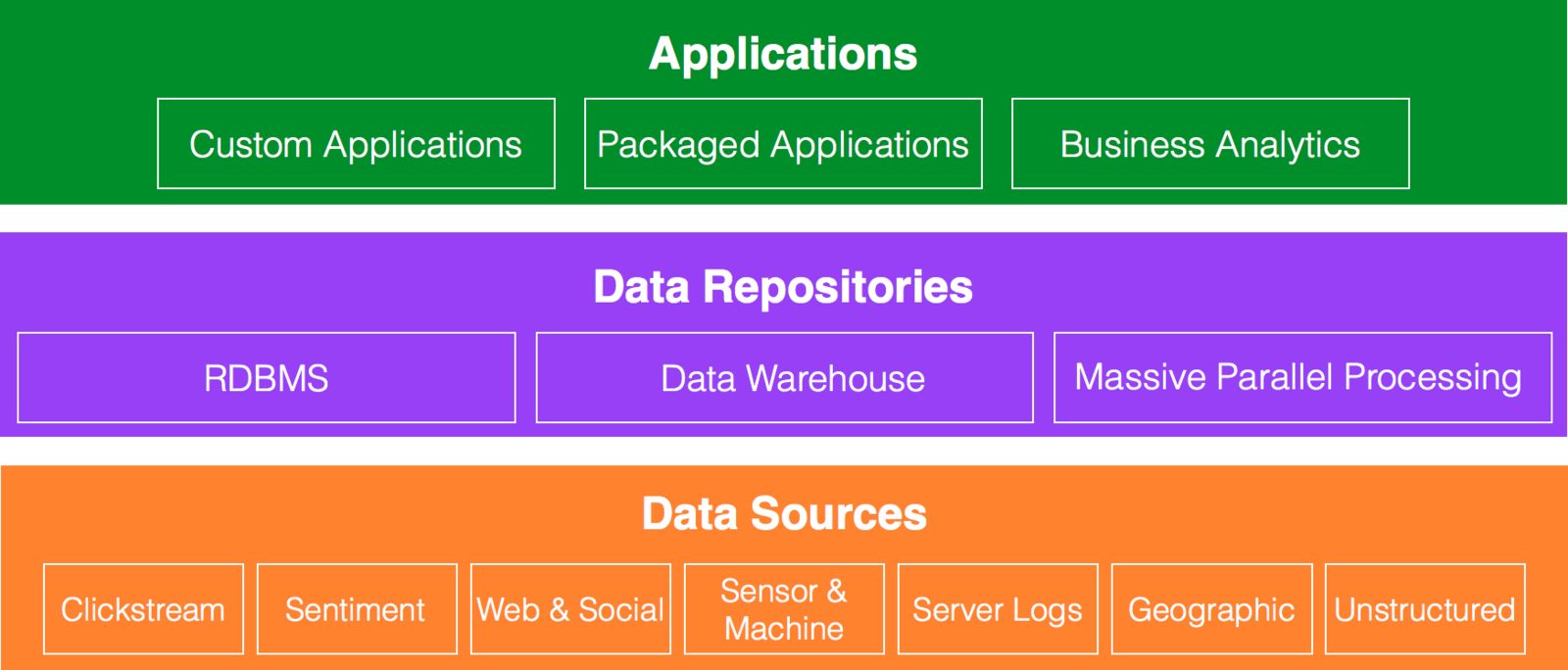
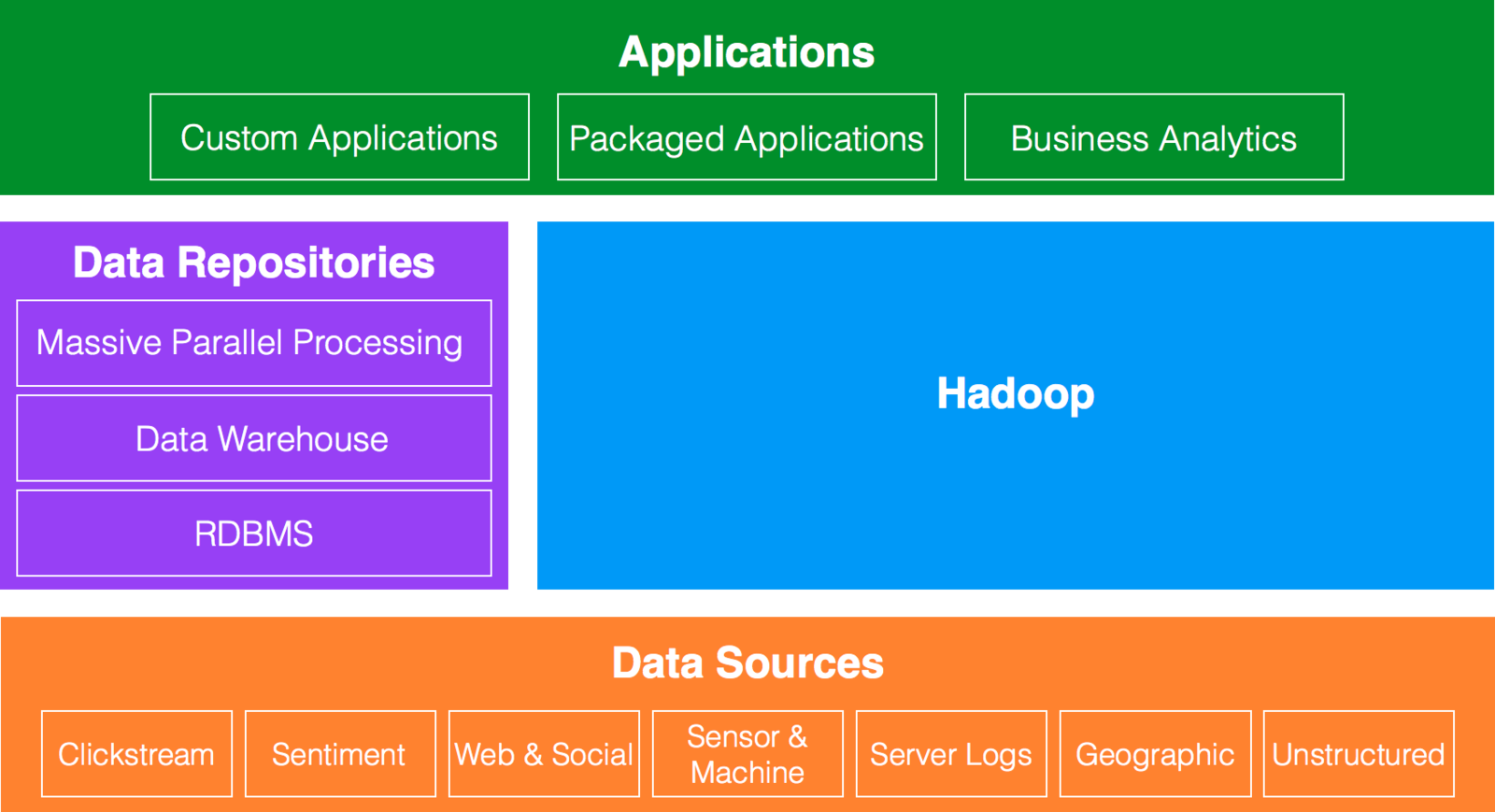
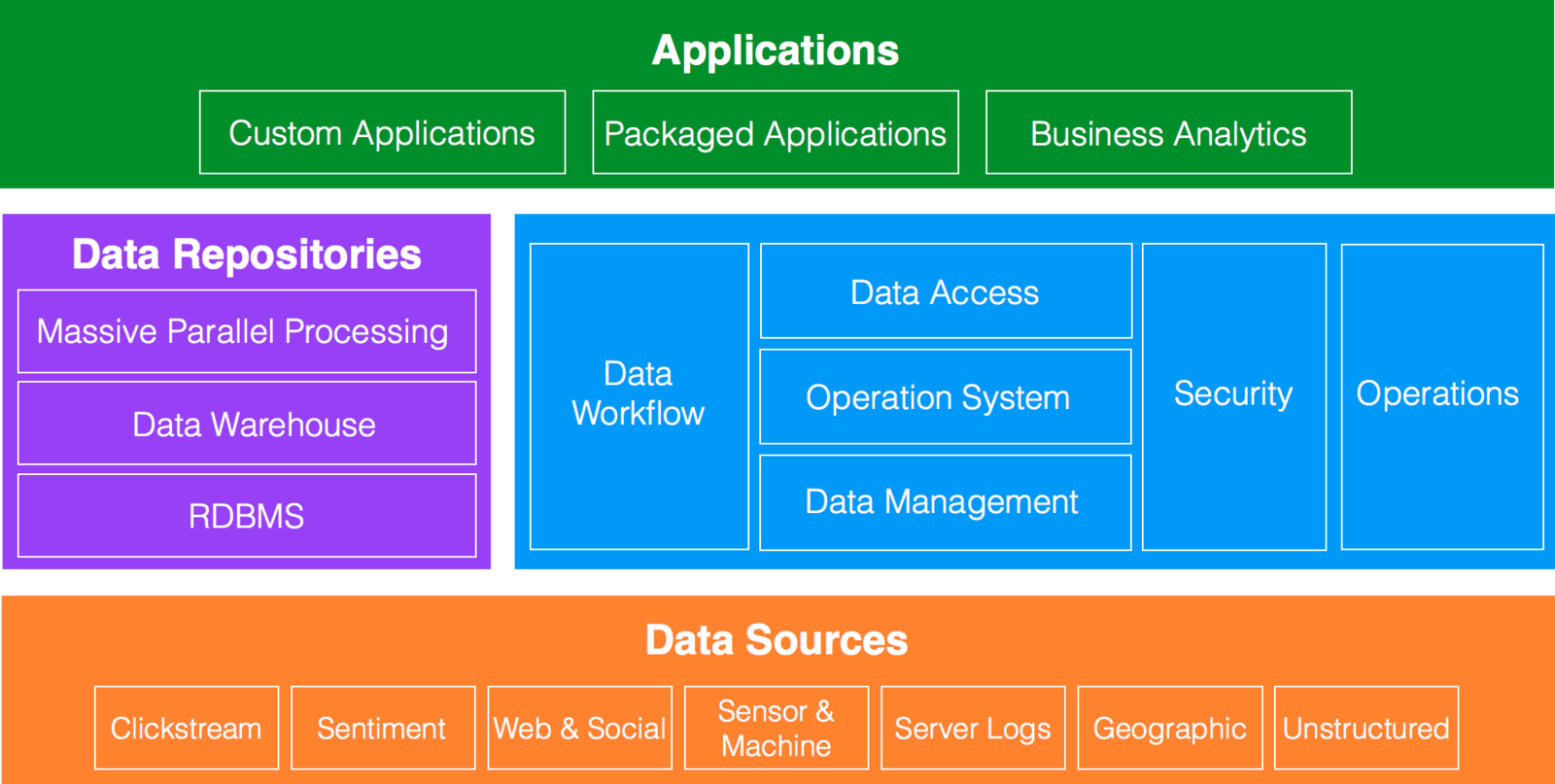
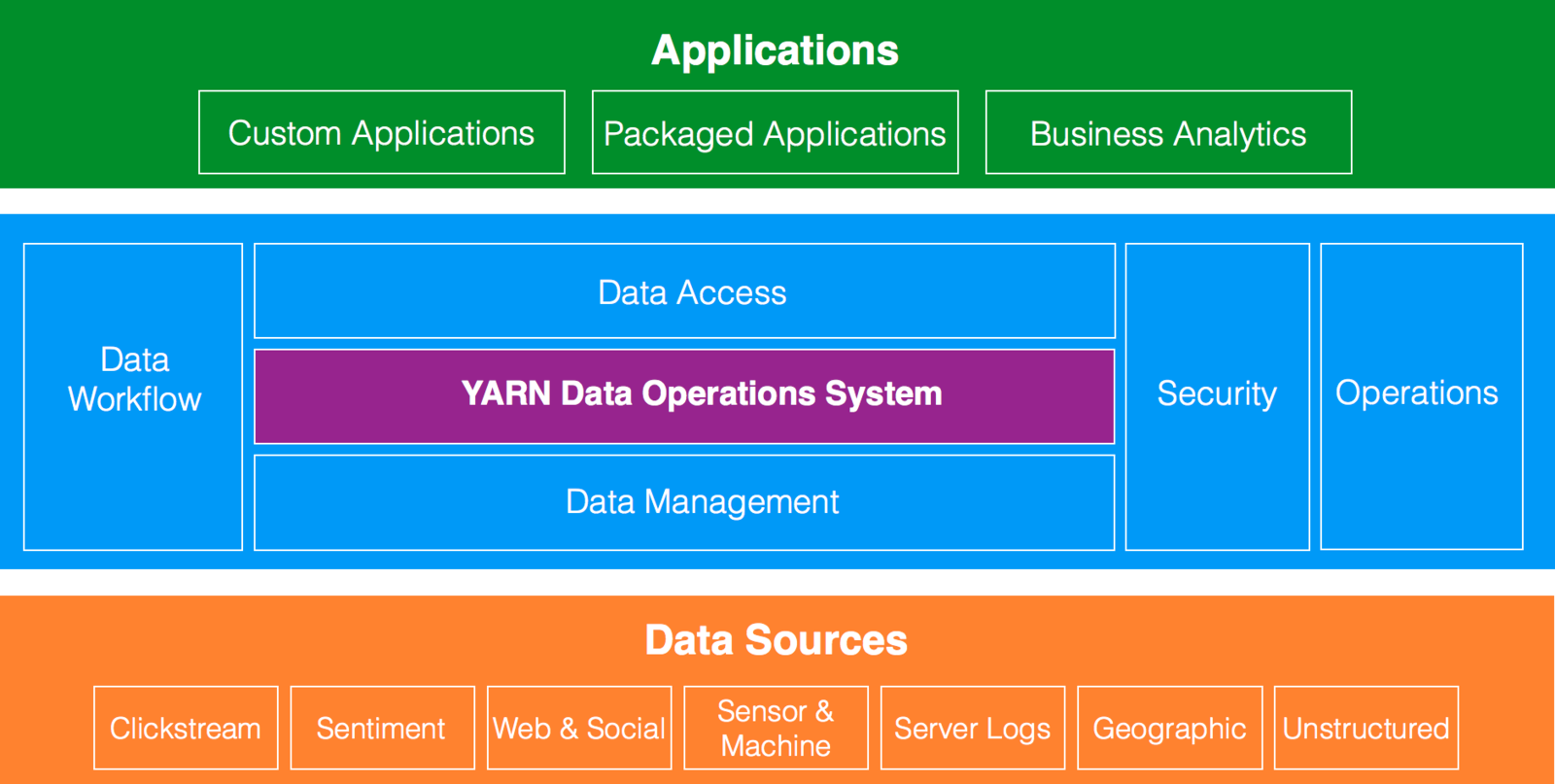
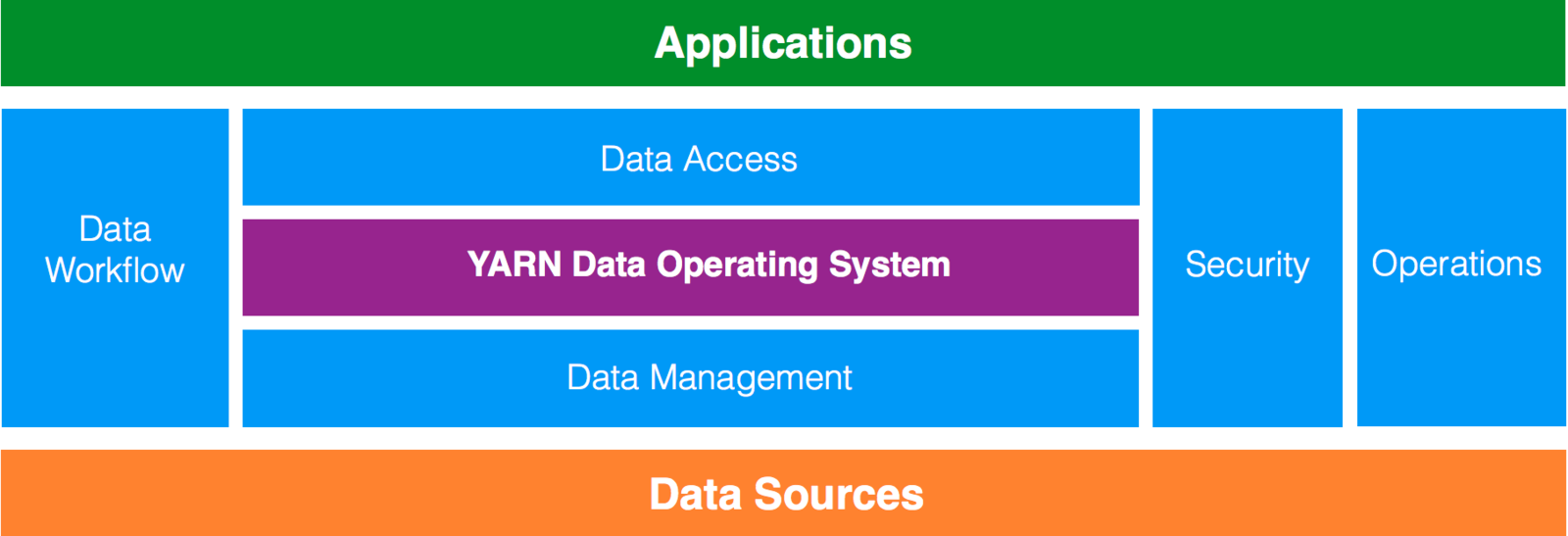
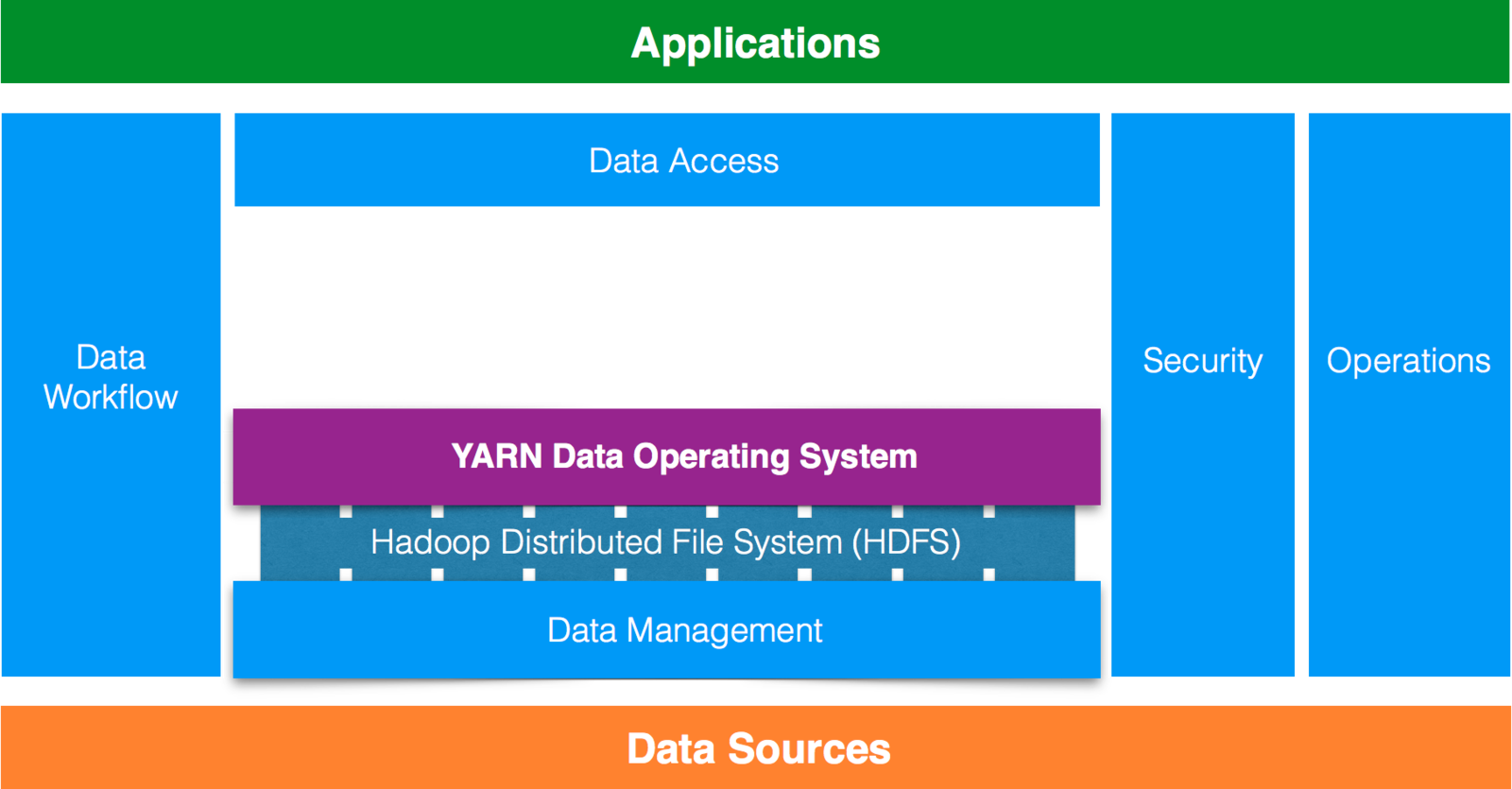
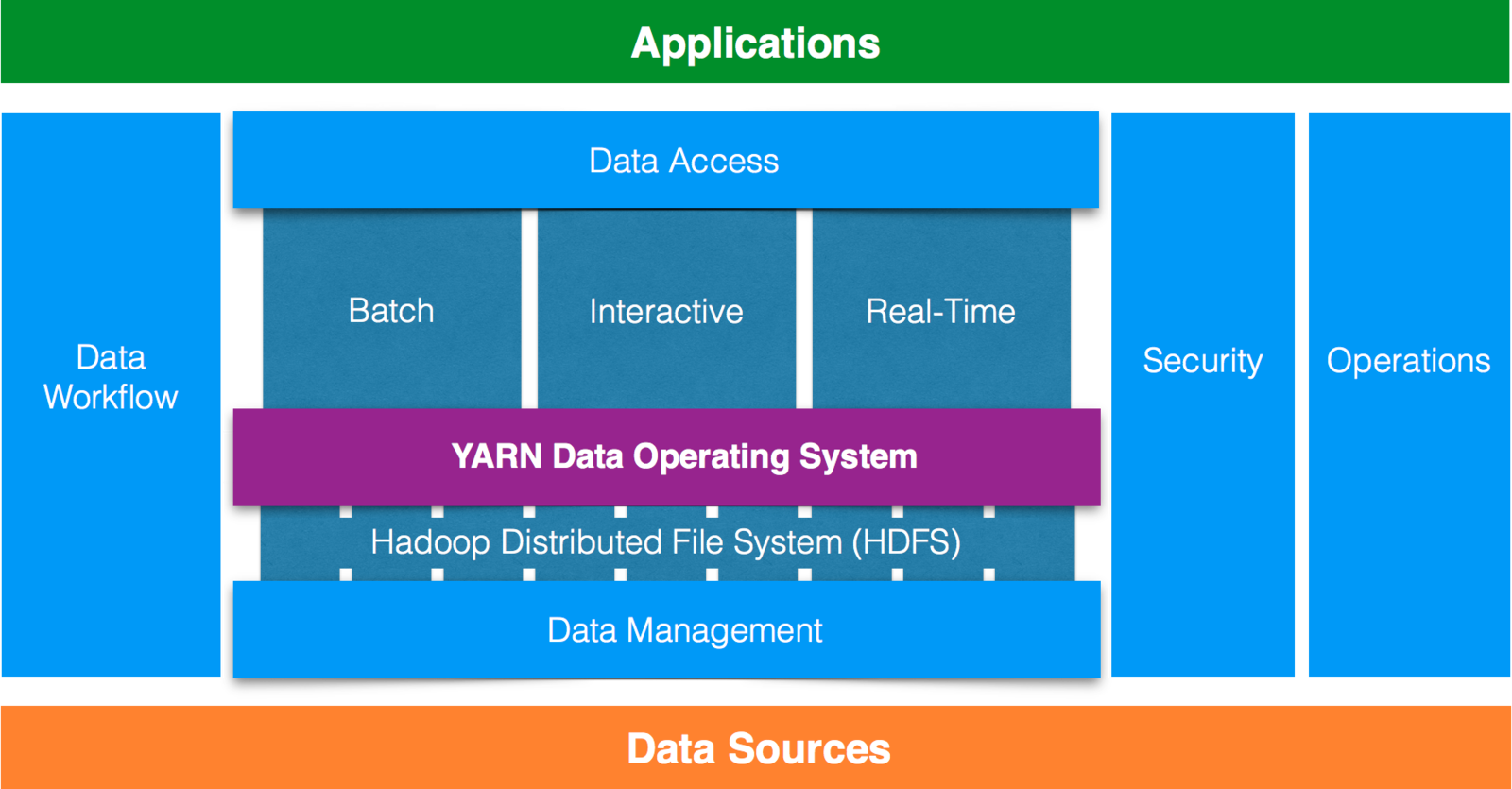
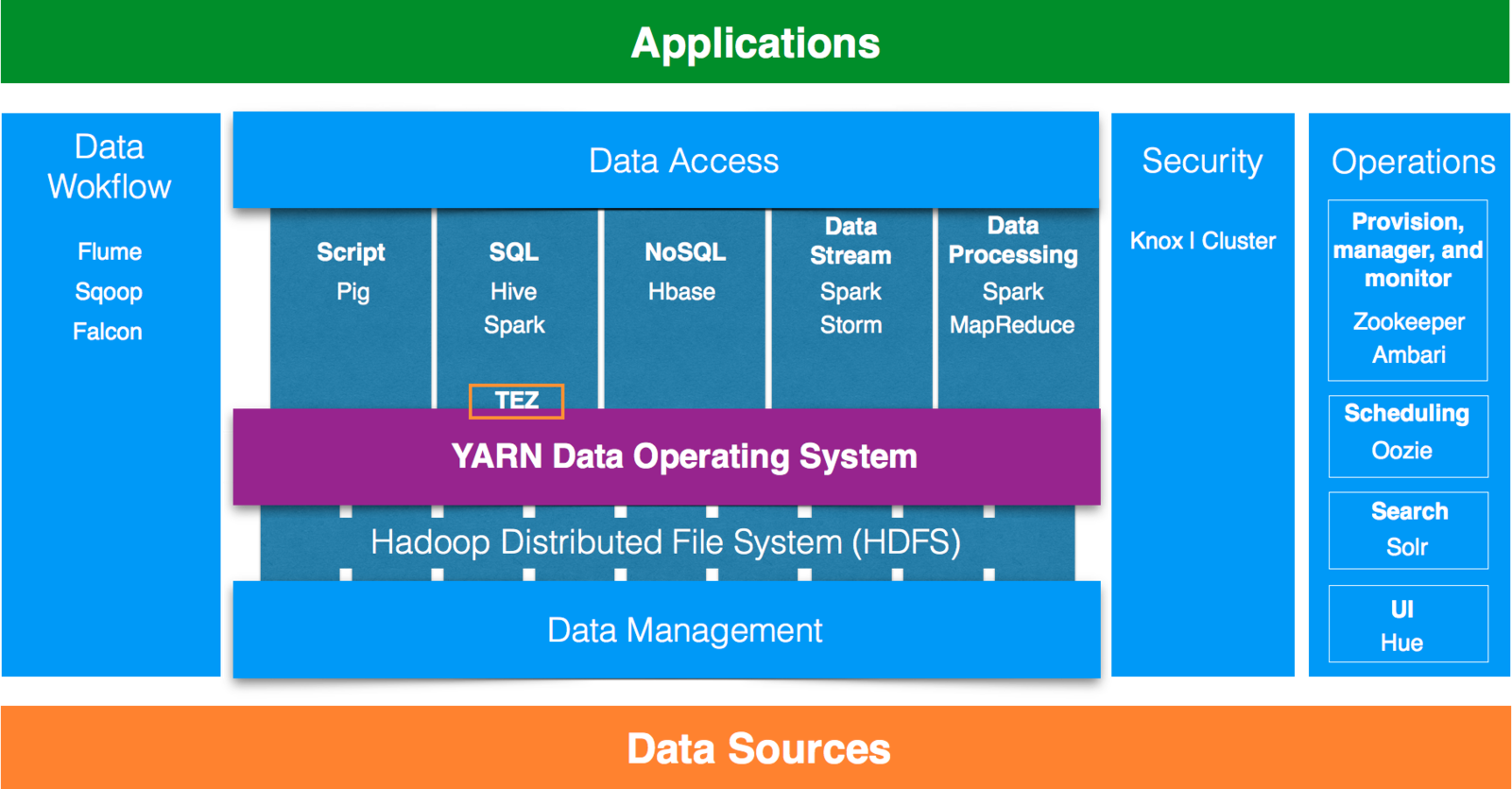
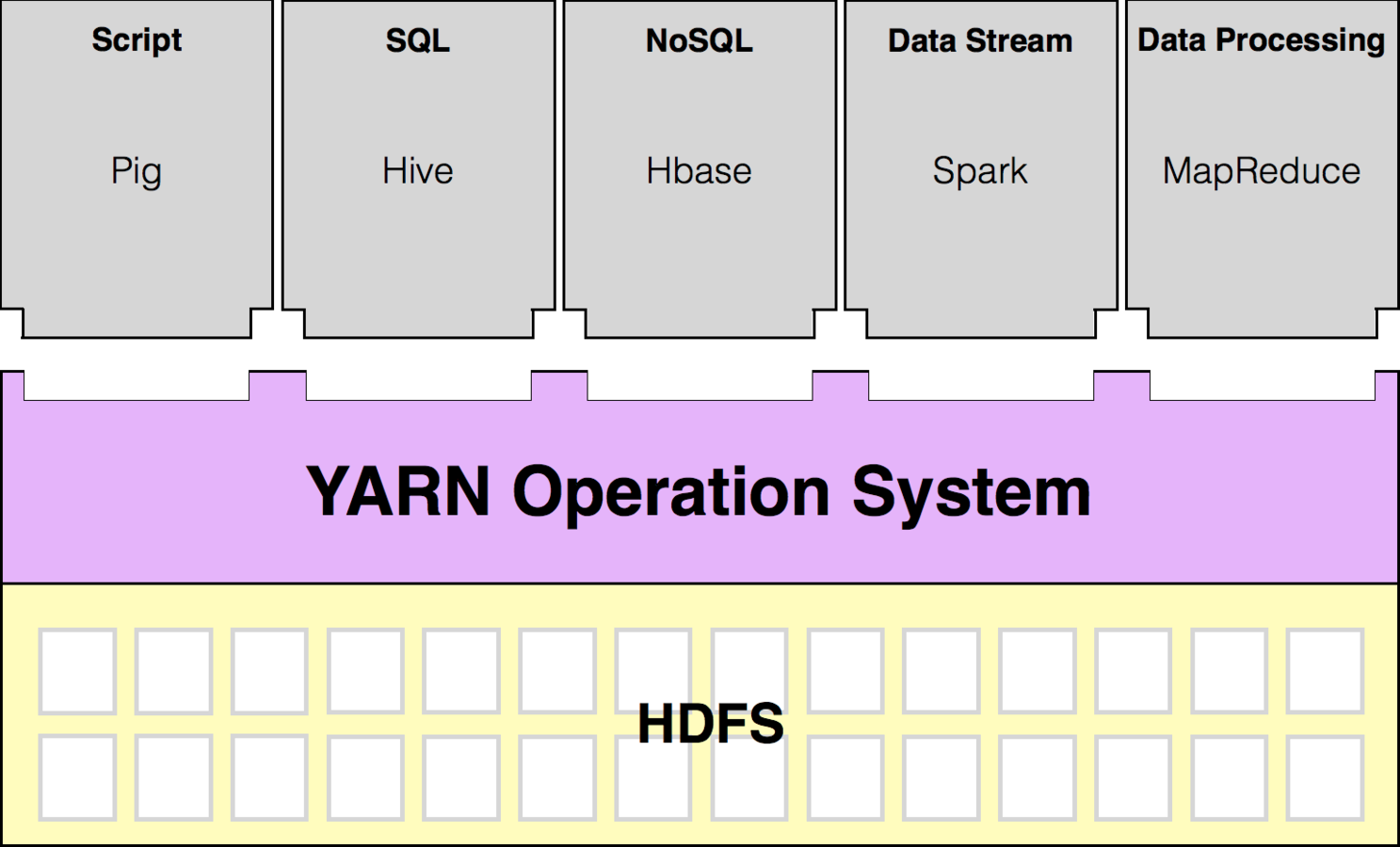
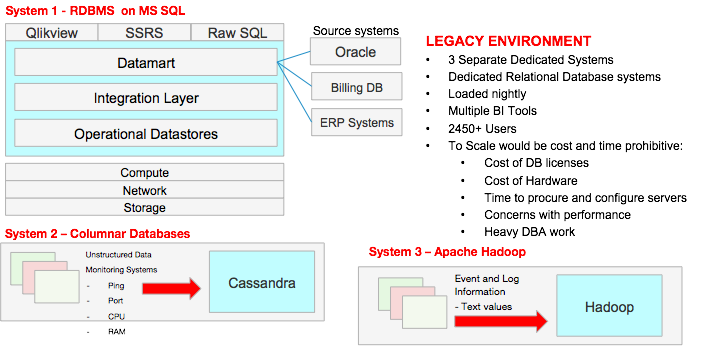
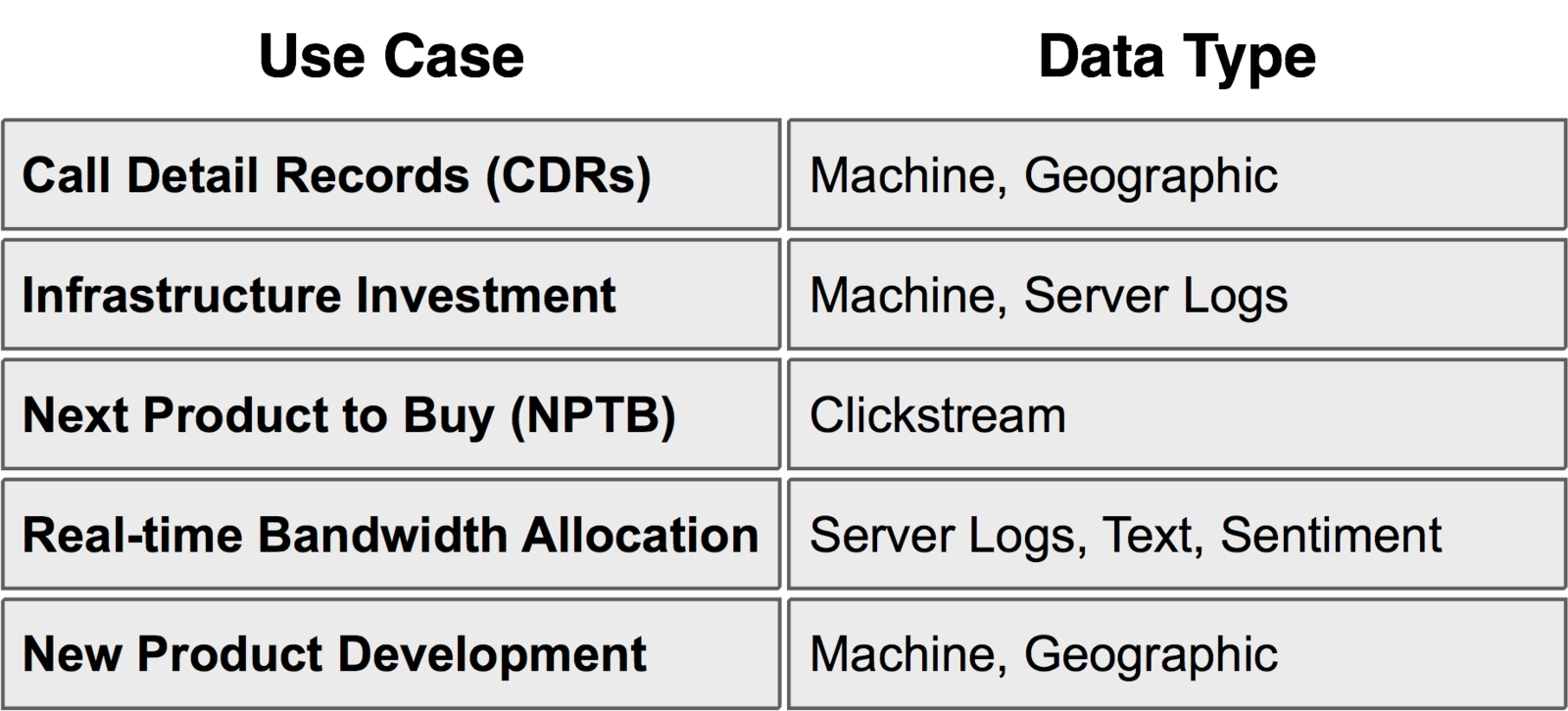
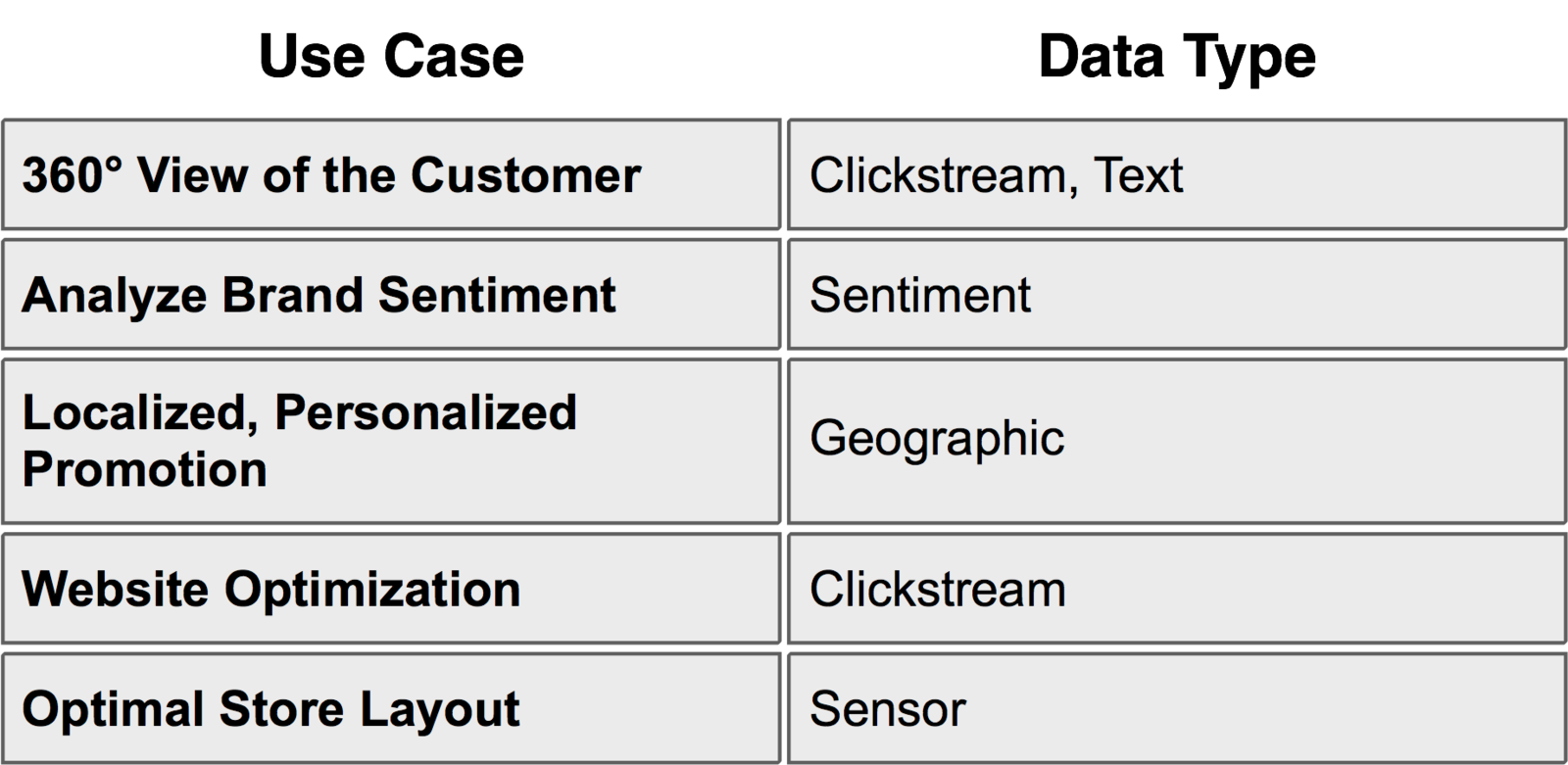
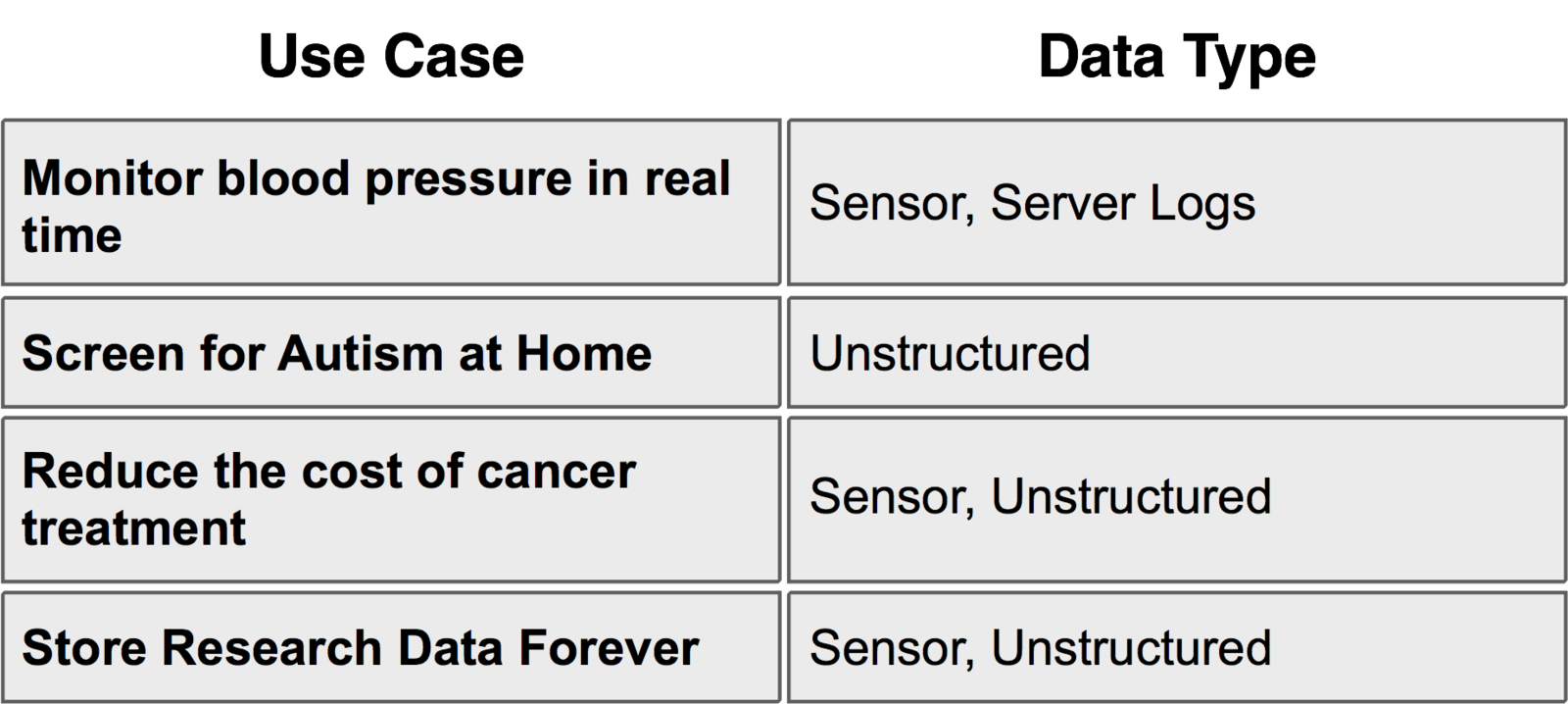
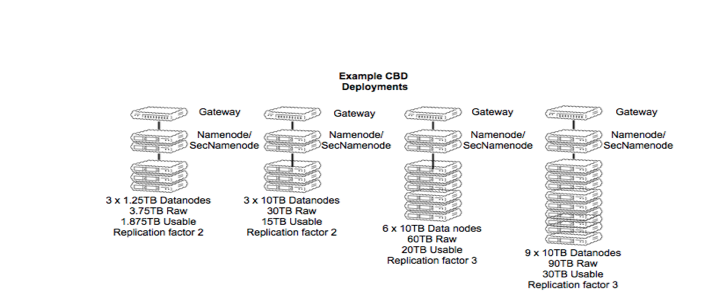
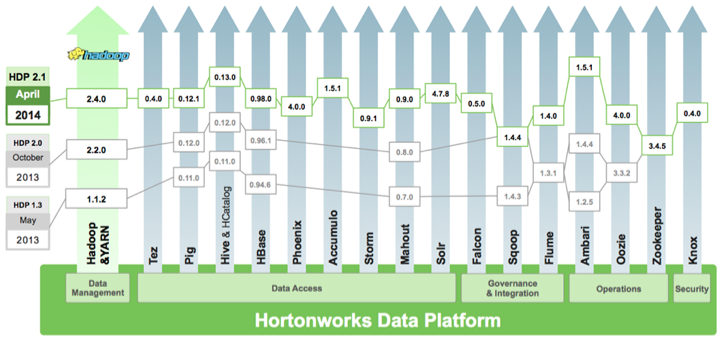
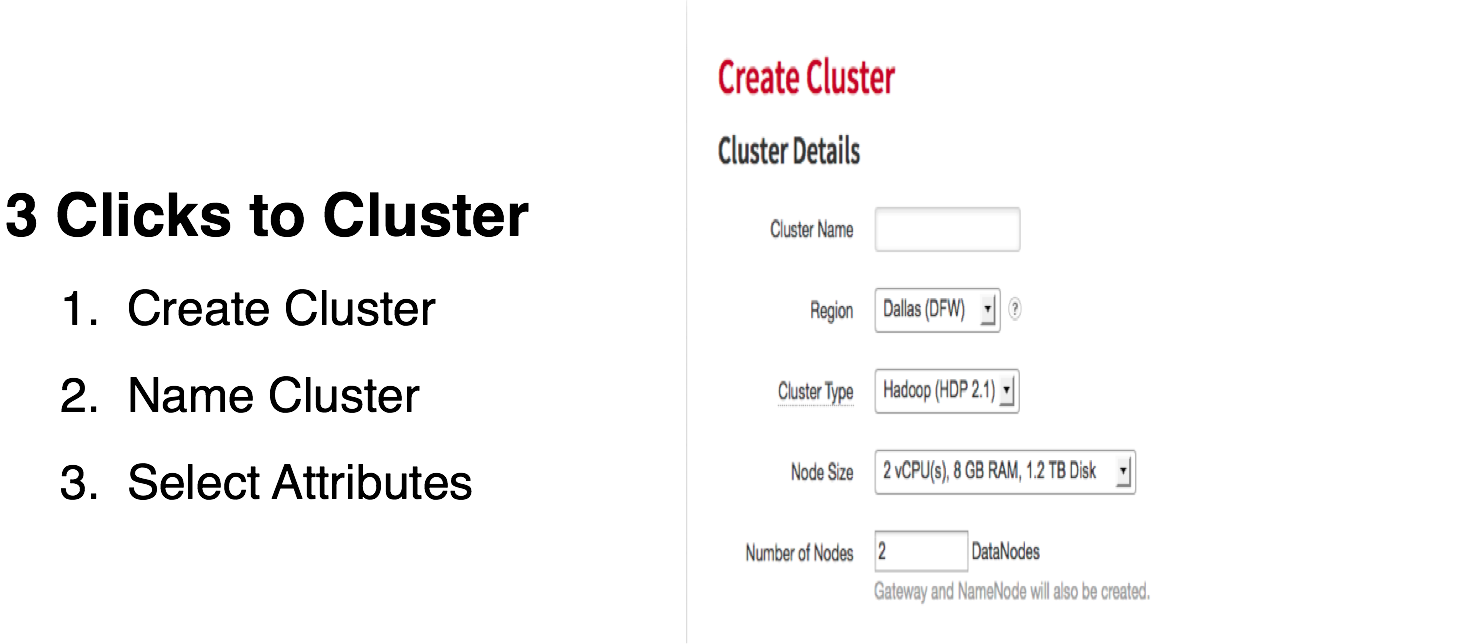
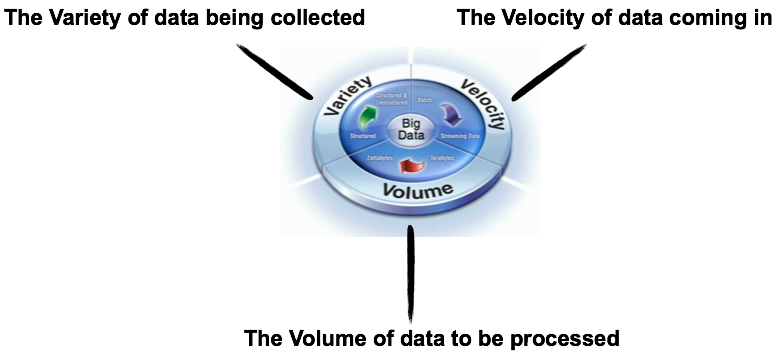
Definition of Big Data
Volume: Data coming in from new sources as well as increased regulation in multiple areas means storing more data for longer periods of time.
Variety: Unstructured and semi-structured data is becoming as strategic as traditional structured data and is growing at faster rates.
Velocity: Social media, RFID, machine data, etc. are needing to be ingested at speeds not even imagined a few years ago.
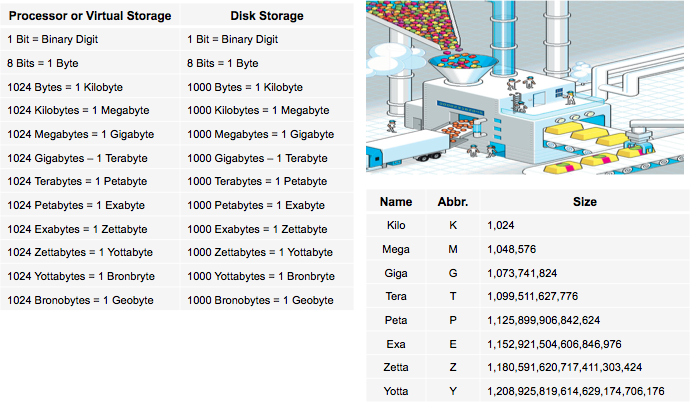
Estimated 1.5 terabytes of compressed data is produced daily.
With over 6 million paying subscribers, 1.5 billion playlists and more than 20 million songs, an estimated 1.5 terabytes of compressed data is
produced daily.
Terabytes of data is analyzed daily in order to get statistics about Spotify and our users, learn about artist trends, target advertisements and do better music recommendations.
The goal is to use data to make a better music service.
Interesting Fact: The company used its collection of data last year to see whether the decisions of the Recording Academy (the people who vote on the winners at the Grammy Awards)
reflected the habits the public on the streaming service. Out of 8 categories, Spotify attempted to predict the winners by looking at its users’ data (listening habits, subscribers to a playlist, popularity of an artist, etc.) The accuracy? 67%. That figure may seem low, but you should consider how many nominees had to be considered.
Twitter messages are 140 bytes each generating 8TB data per day.
A Boeing 737 will generate 240 terabytes of flight data during a single flight across the US
Facebook has around 50 PB warehouse and it’s constantly growing.
Why invest time and money into Big Data?
Source for following slides: http://www.researchmoz.us/big-data-market-business-case-market-analysis- and-forecasts-2014-2019-report.html
IDC is predicting the big data market is expected to grow about 32% a year to $23.8 billion in 2016
The market for analytics software is predicted to reach $51 billion by 2016
Mind Commerce estimates global spending on big data will grow 48% between 2014 and 2019
Big data revenue will reach $135 billion by the end of 2019
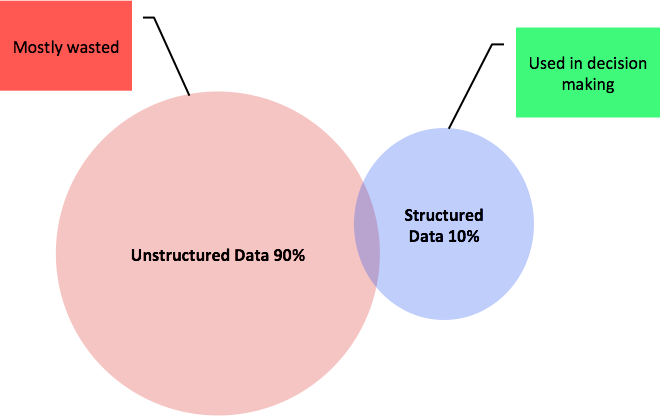
Structured data is any data that is captured in keys, records, attributes, and indexes in a standard DBMS.
Unstructured data is any data that is not managed by a standard database management system (DBMS). Such data comes in many formats, including text,
document, image, video, and more.
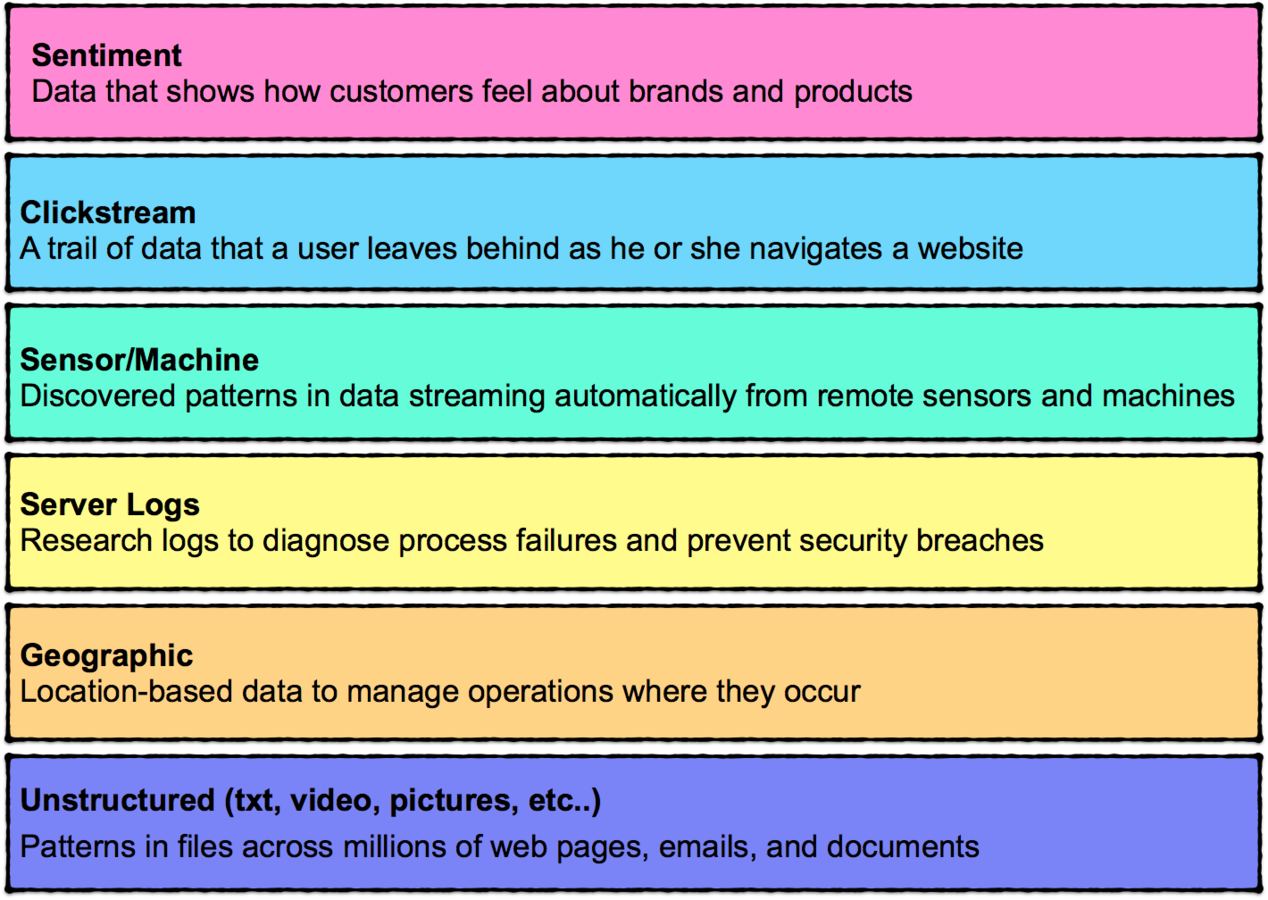
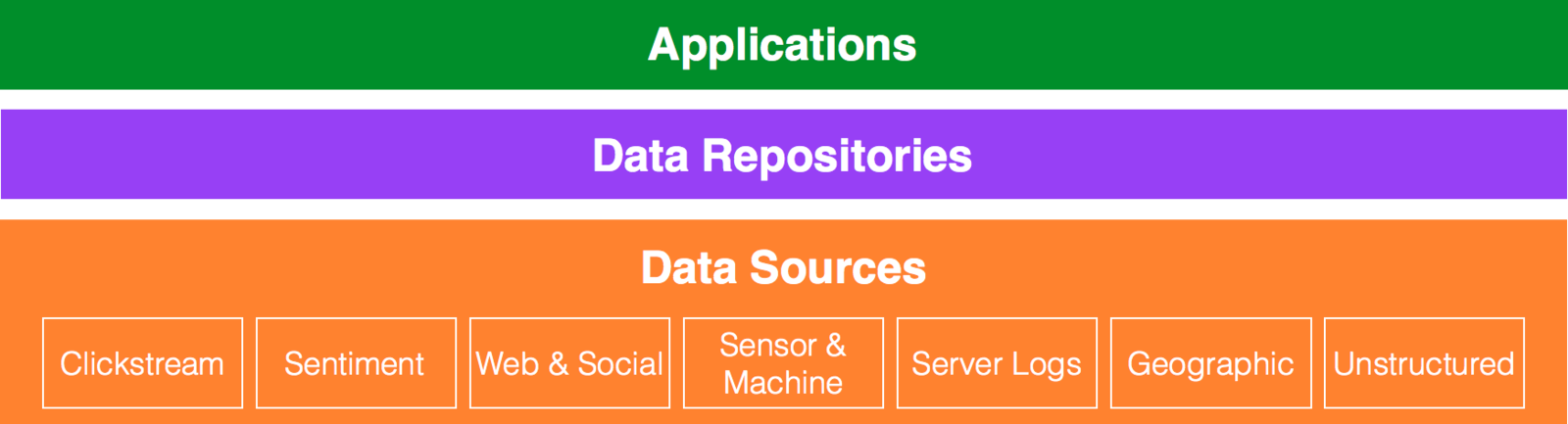
Most Common Types of Data
Sentiment: The most commonly sighted source, analyzing language usage, text and computational iinguistics in an attempt to better analyze subjective information. Many companies are trying to leverage this data to provide sentiment trackers, identify influencers etc.
Clickstream: The trail a user leaves behind as he navigates your website. Analyze the trail to optimize website design.
Sensor/Machine: These are everywhere: cars, health equipment, smartphones, etc. Nike put one in shoes. Someone also put one in baby diapers! They call it ‘proactive maintenance’.
Geographic: Location based data – a common use being location based targeting. This data has much more wider application in supply chain optimization across the manufacturing industry allowing organizations to optimize routes, predict inventory levels, etc.
Server logs: This one is not new to the IT world. You often lose precious trails and information when you simply roll over log files. Today, you should not have to lose this data; you just save the data in Hadoop!
Text: Text is everywhere. We all love to express ourselves - every blog, article, news site, ecommerce site you go these days, you will find people putting out their thoughts. And this is on top of the already existing text sources like surveys and the Web content itself. How do you store, search and analyze all this text data to glean for key insights? Hadoop!
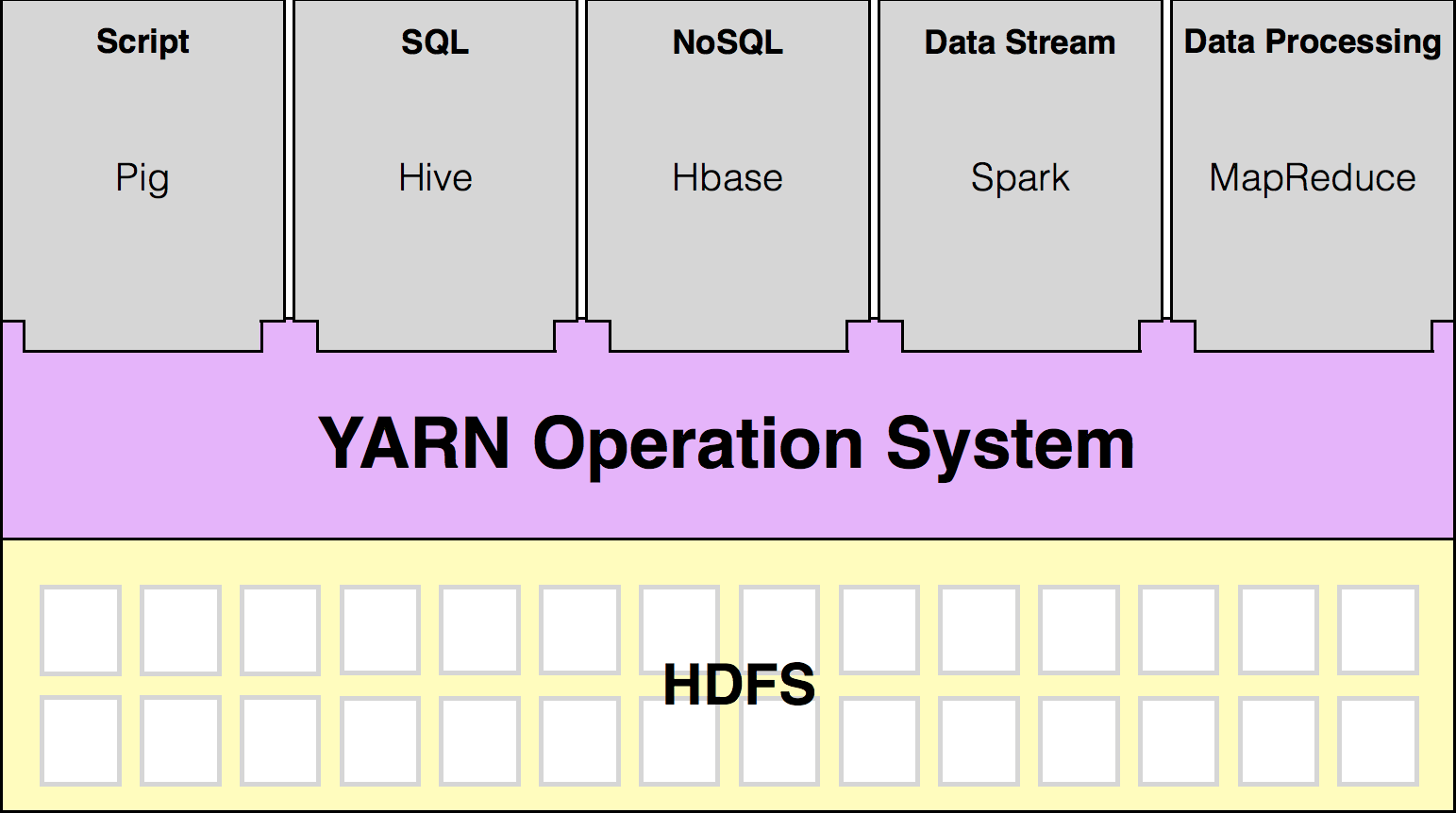
Big Data Technologies
Big Data Short Video
Top ten Big Data Insights at Rackspace
10 Minute Video
What is Big Data to Rackspace?
7 Minutes
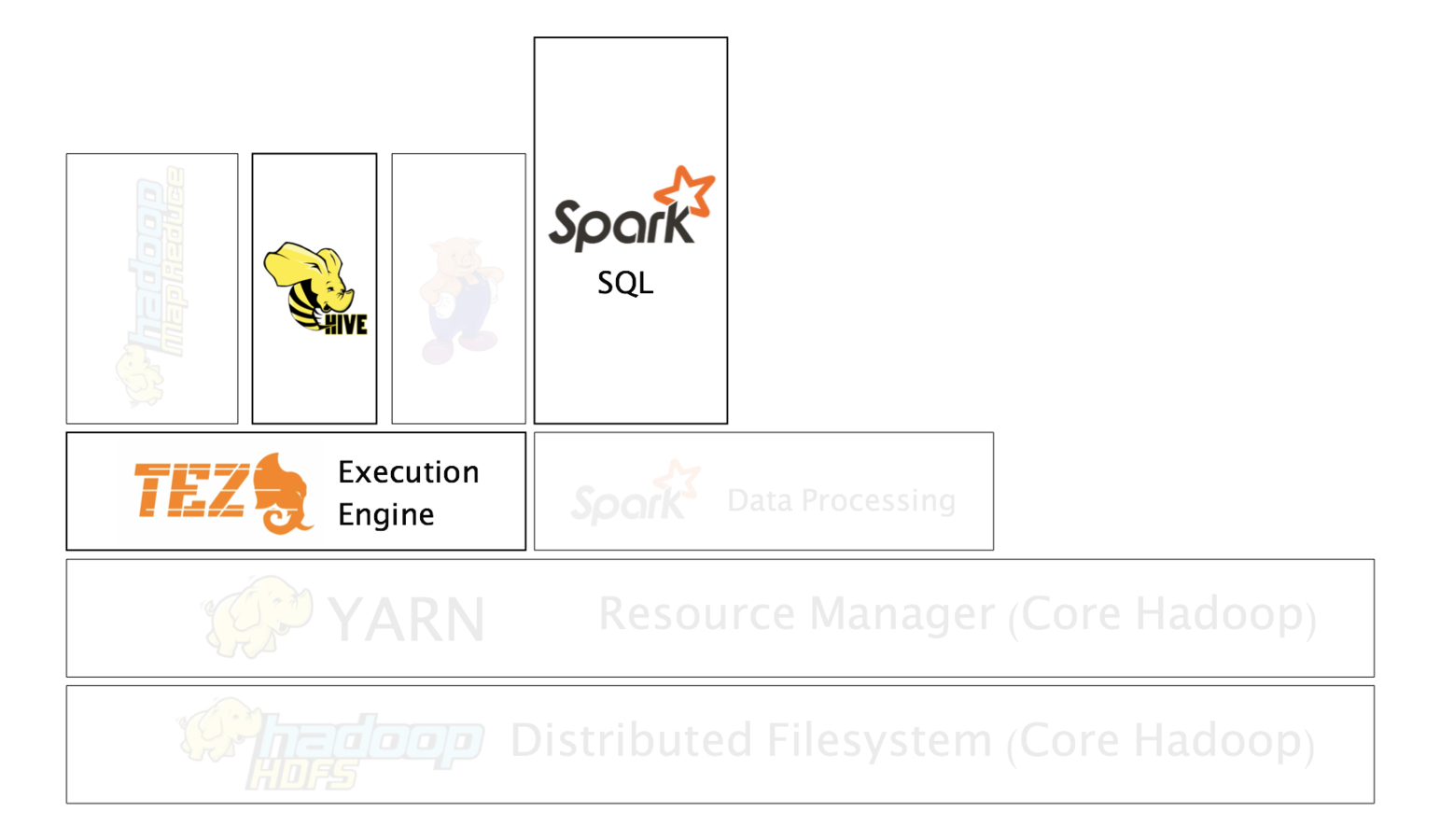
Hadoop
Lots of things can be "Big Data". Today we will focus on Hadoop.
What is Hadoop?
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
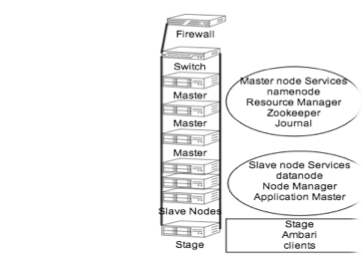
Hadoop is all about processing and storage. Hadoop is a software framework environment that provides a parallel processing environment on a distributed
file system using commodity hardware. A Hadoop cluster is made up of master processes and slave processes spread out across different x86 servers.
This framework allows someone to build a Hadoop cluster that offers high performance super computer capability.
WHITEBOARD four master nodes and 10 data nodes and explain how Hadoop does parallel processing across data nodes on a highly available distributed file system.
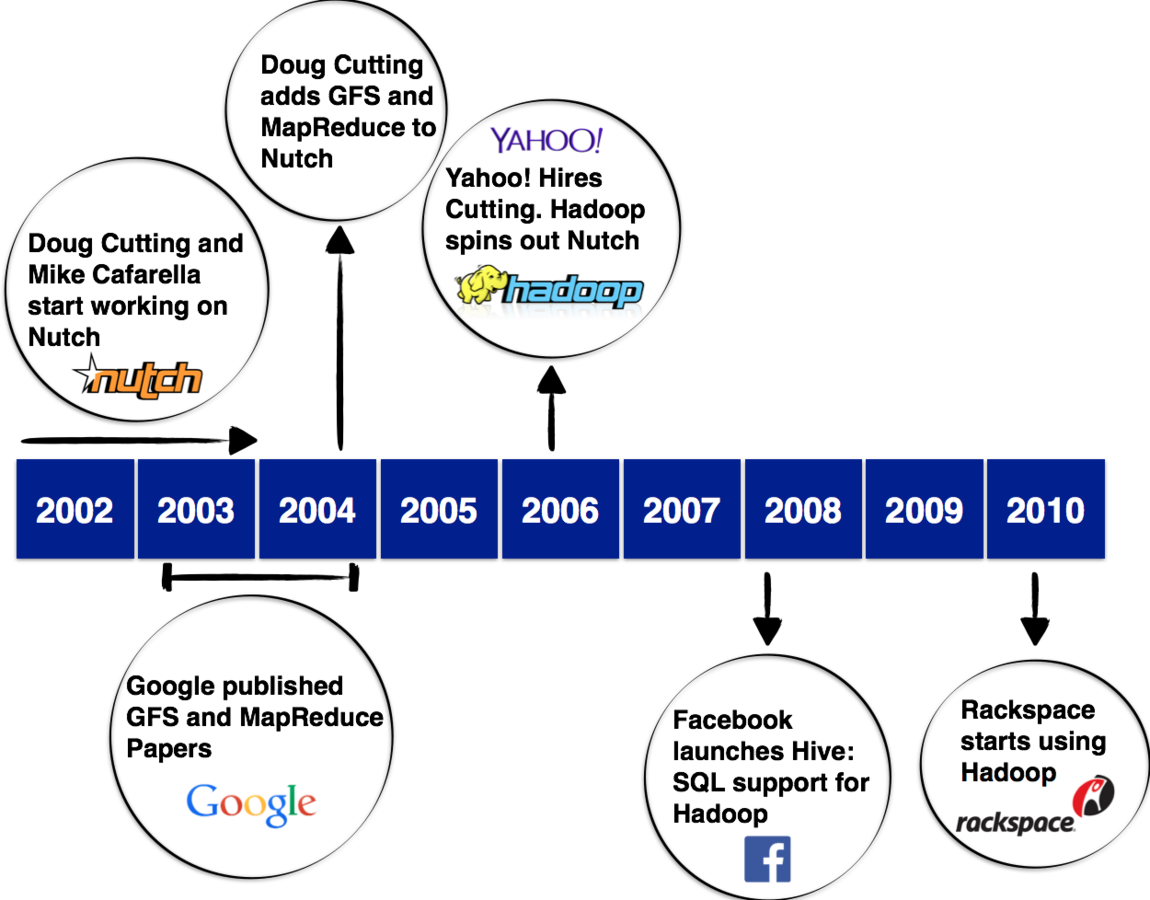
Evolution of Hadoop
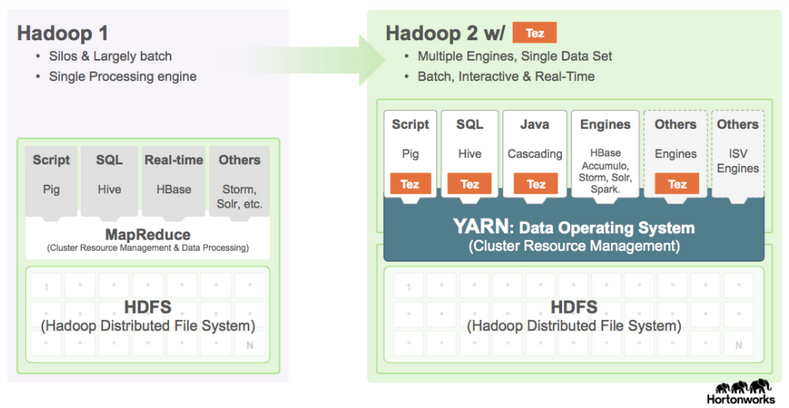
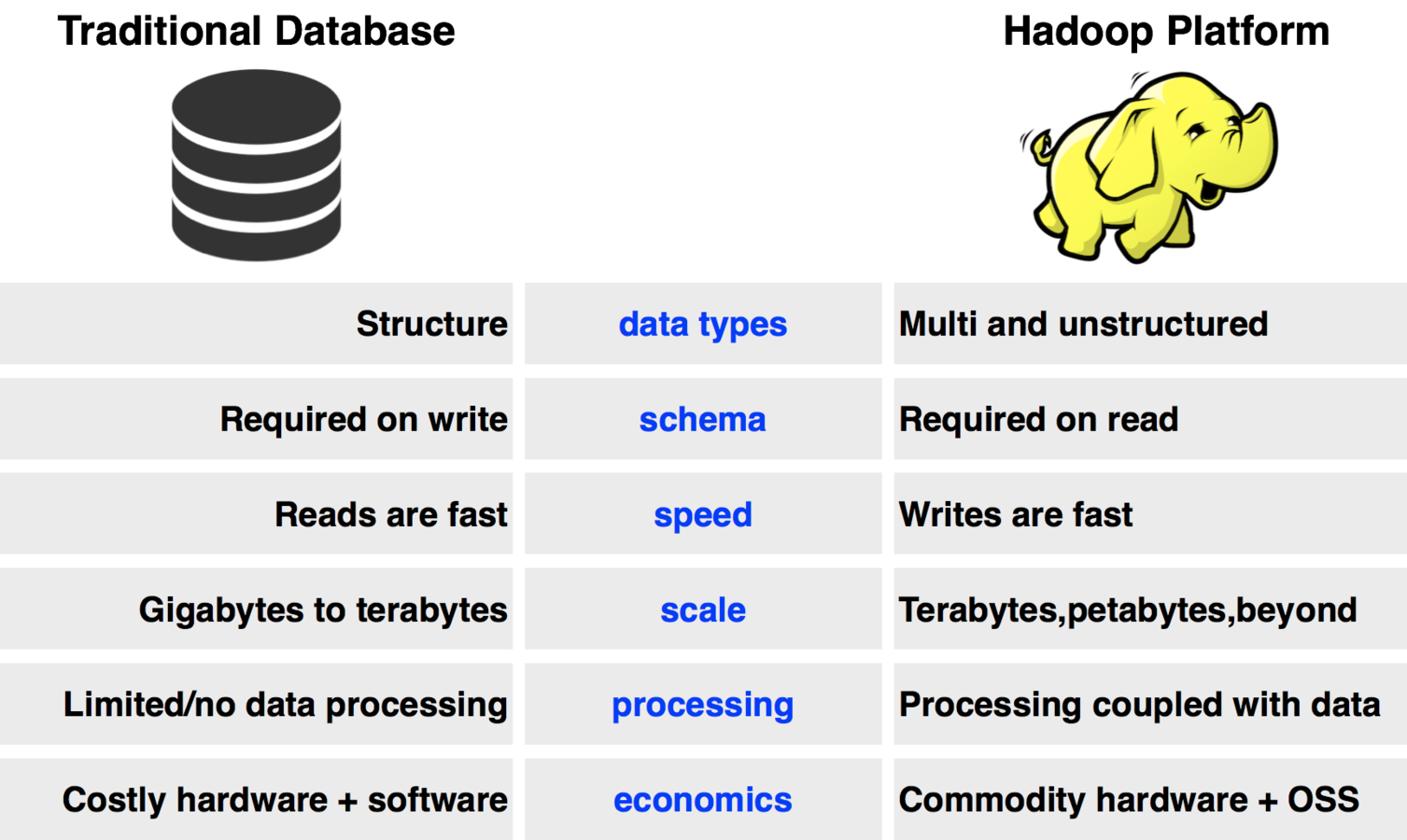
Traditional Systems vs. Hadoop
Traditional Systems vs. Hadoop
Hadoop is not designed to replace existing relational databases or data warehouses. Relational databases are designed to manage transactions. They contain a lot of
feature/functionality designed around managing transactions. They are based upon schema-on-write. Organizations have spent years building Enterprise Data Warehouses (EDW)
and reporting systems for their traditional data. The traditional EDWs are not going anywhere either. EDWs are also based on schema-on-write.
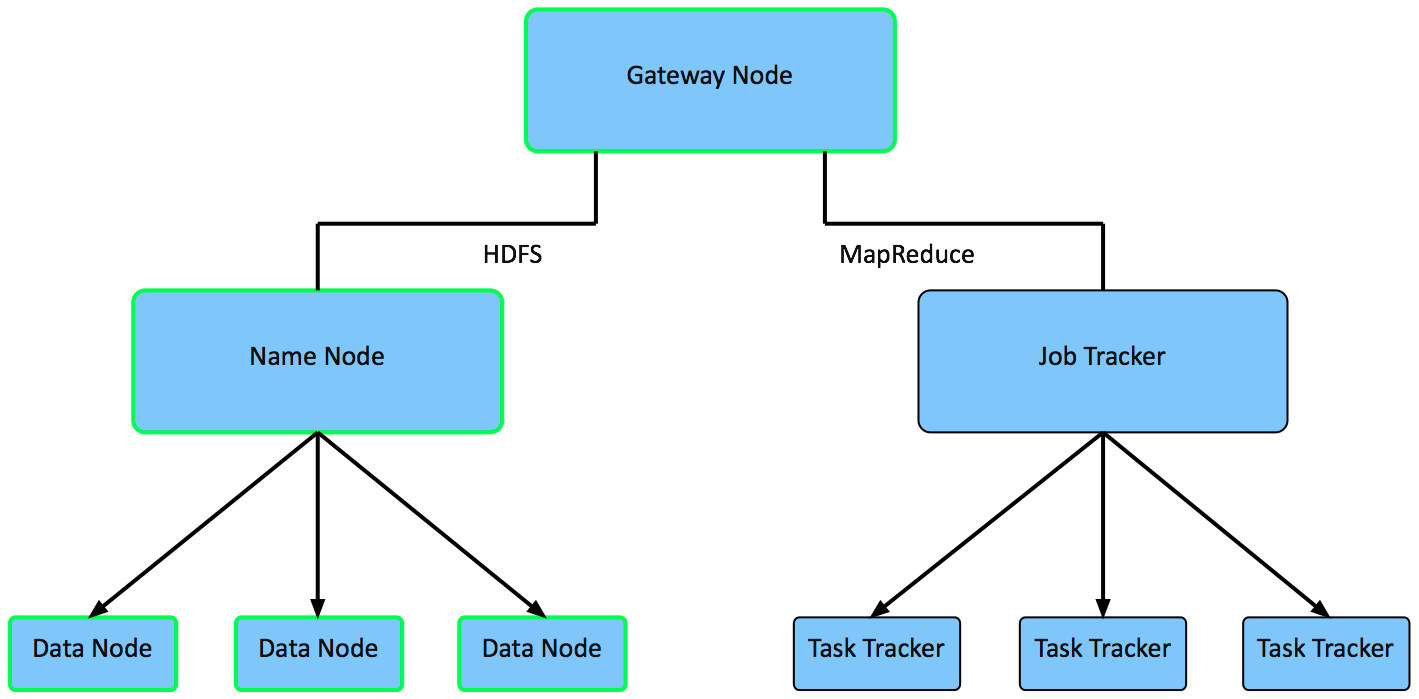
Apache Hadoop Framework
Hadoop Configuration
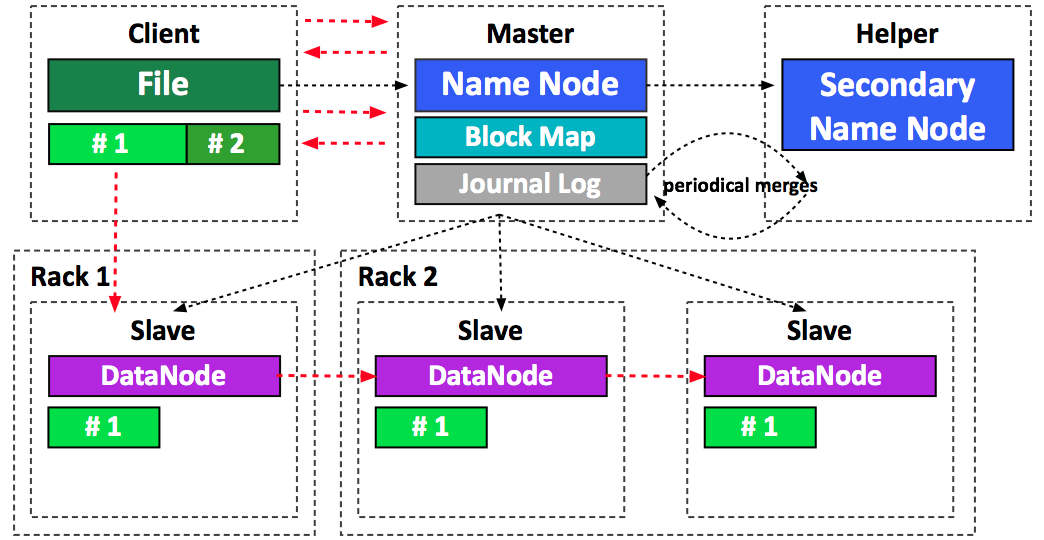
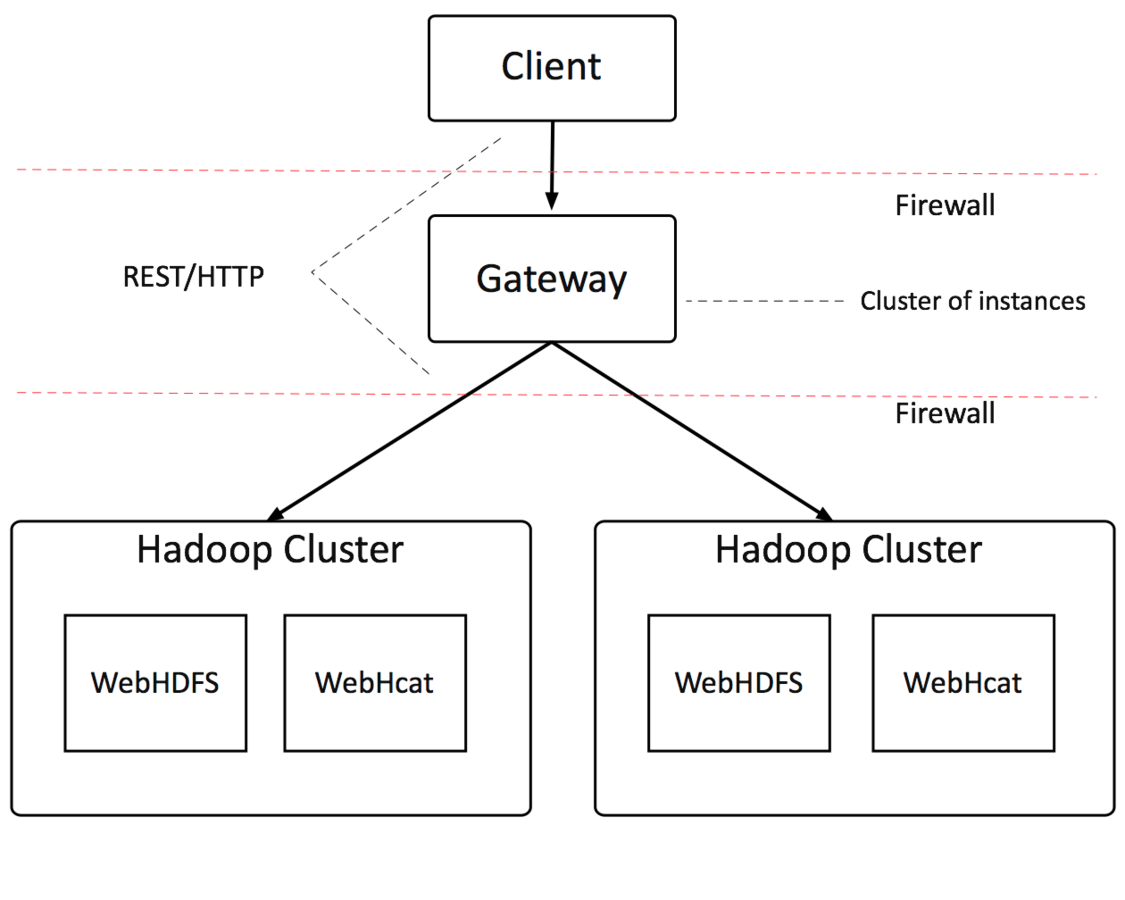
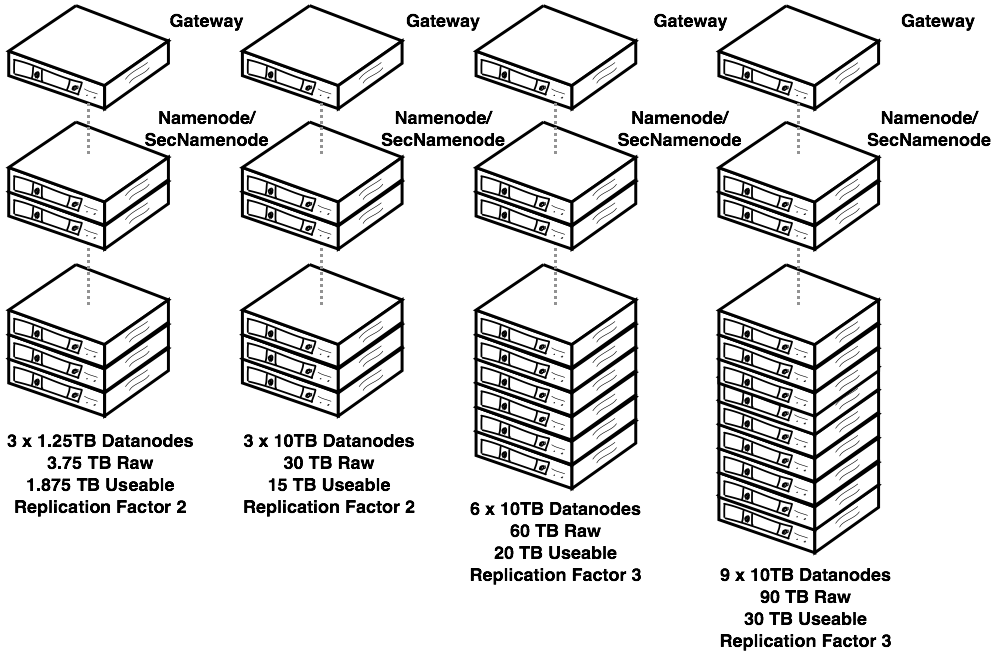
Name Nodes - is the centerpiece of a HDFS file system. It keeps a directory tree of all files in the file system, and tracks data location within the cluster. It does not store the data, it only keeps track of where it lives.
Gateway Node - Gateway Nodes are the interface between the cluster and outside network. They are also used to run client applications, and cluster administration services, as well as serving a staging area for data ingestion.
Data Nodes - These are the nodes where the data lives, and where the processing occurs. They are also referred to as “slave nodes”.
One of the benefits of Hadoop is that it is highly scalable, and it was designed to run on commodity hardware, as opposed to high-end, purpose built
hardware.
Hadoop Configuration
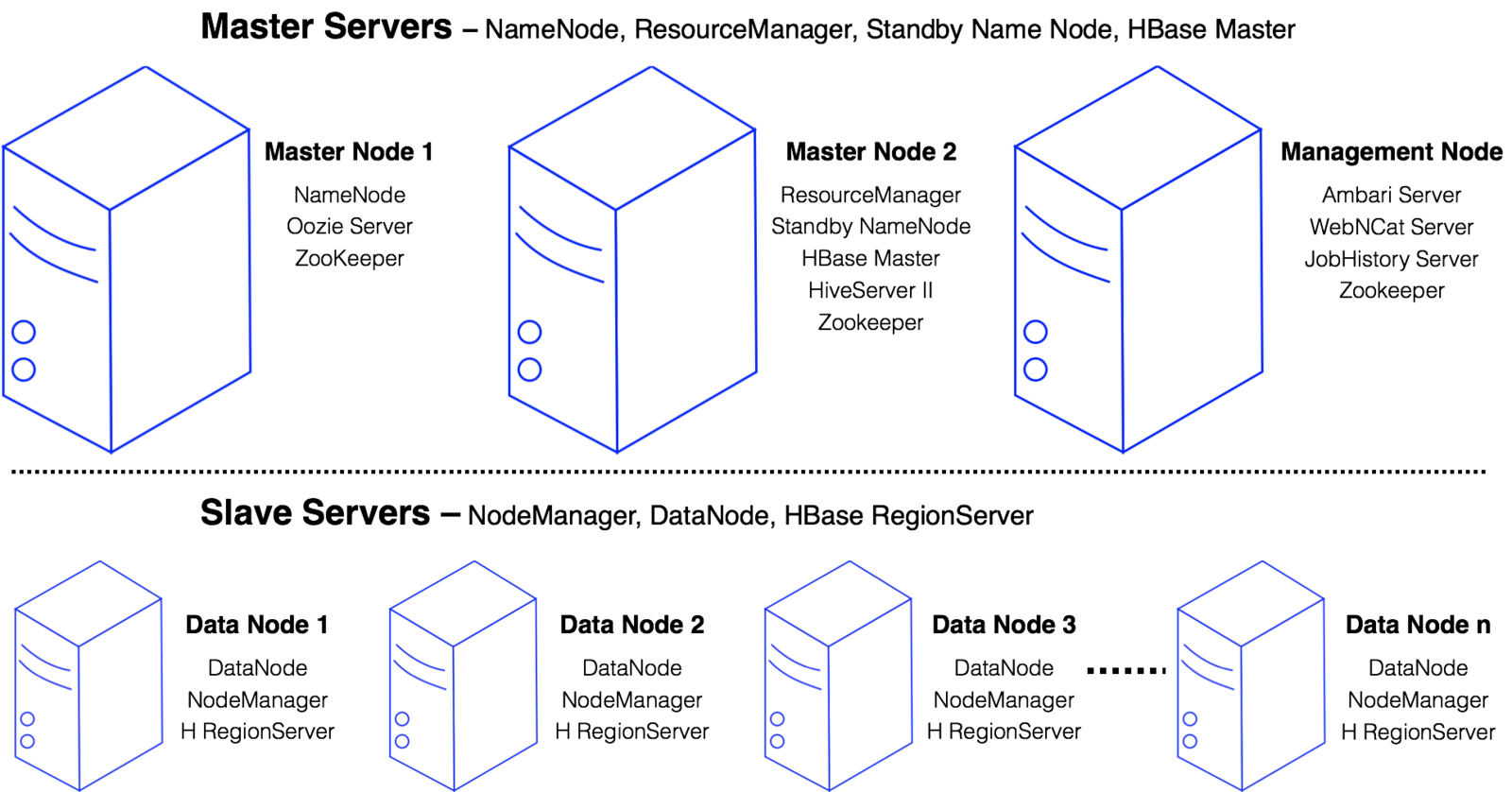
Hadoop Cluster
Master Servers manager the infrastructure
Slave Servers contain the distributed data and perform processing
A Hadoop cluster is made up of master and slave servers.
Hadoop Cluster
Overview of a Hadoop Cluster
Hadoop cluster consists of the following components:
- NameNode: a master server that manages the namespace of HDFS.
- DataNodes: slave servers that store blocks of data.
- ResourceManager: the master server of the YARN processing framework.
- NodeManagers: slave servers of the YARN processing framework.
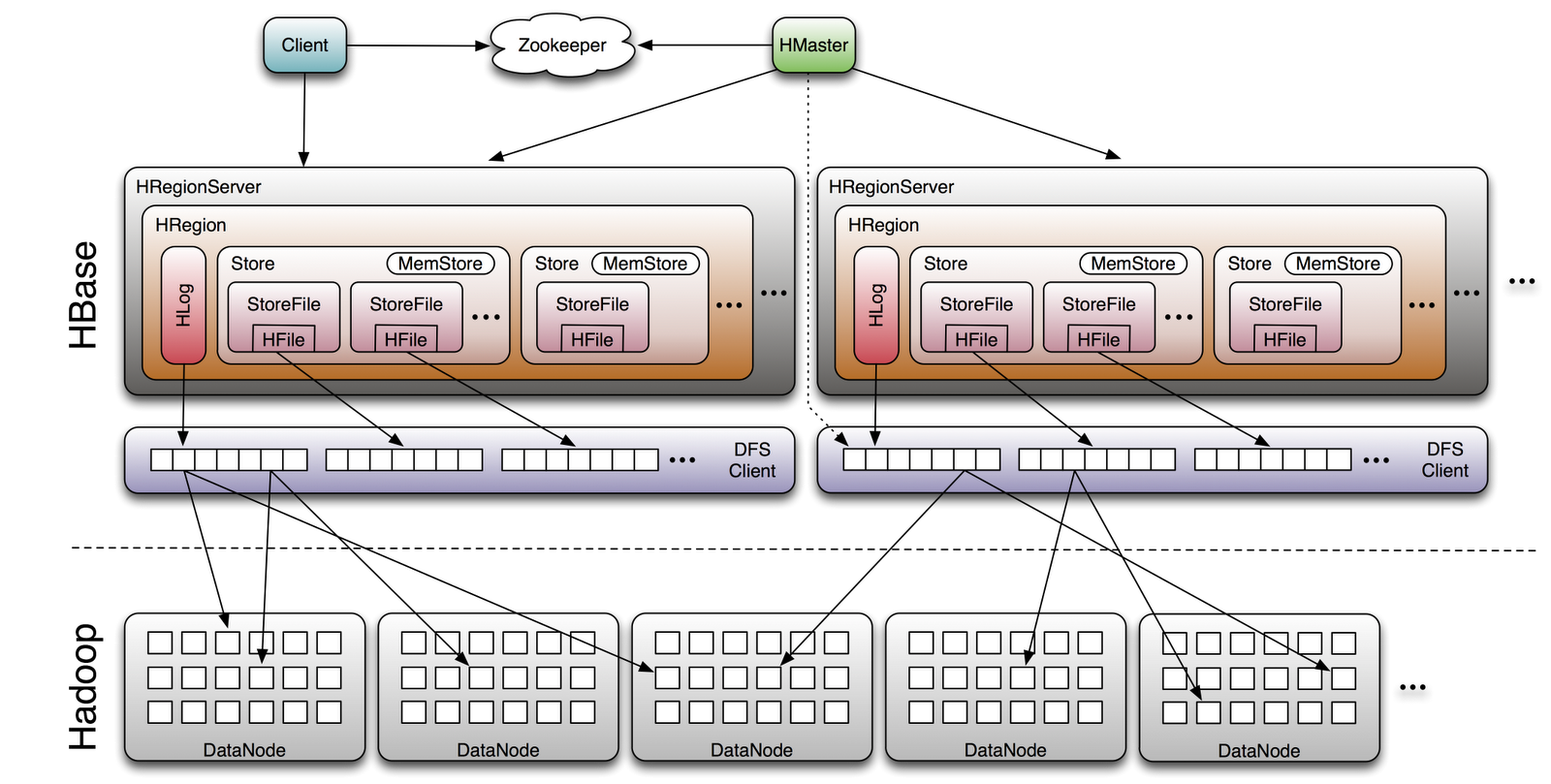
- HBase components: HBase also has a master server and slave servers called RegionServers.
Some of the components working in the background of a cluster include ZooKeeper, Ambari, Ganglia, Nagios, JobHistory, HiveServer2, and WebHCat.
Cloud Big Data Architecture
Managed/Dedicated Big Data Architecture
Test your Knowledge
this is a transition slide
Is Hadoop a data store?
No. While you can technically store data in a Hadoop Cluster, it is really more of a data processing system, than a true data store.
Ask the group this question. If so someone says yes, ask the larger group if that's the correctn answer. When someone says no, ask the group why it isn't. The goal here is to build an open discussion.
Then what is a data store?
A data store is a data repository including a set of integrated objects. These objects are modeled using classes defined in database schemas. Examples of typical data stores, MySQL, PostgreSQL, Redis, MongoDB
Ask the group this question. The goal here is to build an open discussion.
What is data processing?
Think of Data Processing as the collection and manipulation of items of data to produce meaningful information. In the case of Hadoop, this means taking unstructured, unusable data, and processing it in a way that makes it useful or meaningful
Ask the group this question. The goal here is to build an open discussion.
this is a transition slide
YARN Architecture
generate a naming convention for the nodes
YARN Use Case
At one point Yahoo! had 40k+ nodes spanning multiple datacenters – 365PB+ of data
YARN provided a compute framework that allowed higher utilization of nodes
100% utilization (while being efficient) is always a good thing
Yahoo! was able to bring down an entire datacenter of about 10k Nodes
Source: Hortonworks
HDFS
Java-based distributed file system.
Stores large volumes of unstructured data and spans across large clusters of commodity servers.
Works closely with MapReduce.
Hadoop is flexible. It lets you use other filesystems like GlusterFS, and it has a number of plugins
for a number of other data storage layers. MapR wrote its own distributed filesystem that uses an NFS interface and relies on
local filesystems rather than using Namenodes, and they claim some impressive performance numbers with their system.
You can also plug it in to object stores like OpenStack Swift, as well as distributed databases like MongoDB and Cassandra.
HDFS will be your primary concern, but you should be aware that these other options exist.
HDFS Architecture
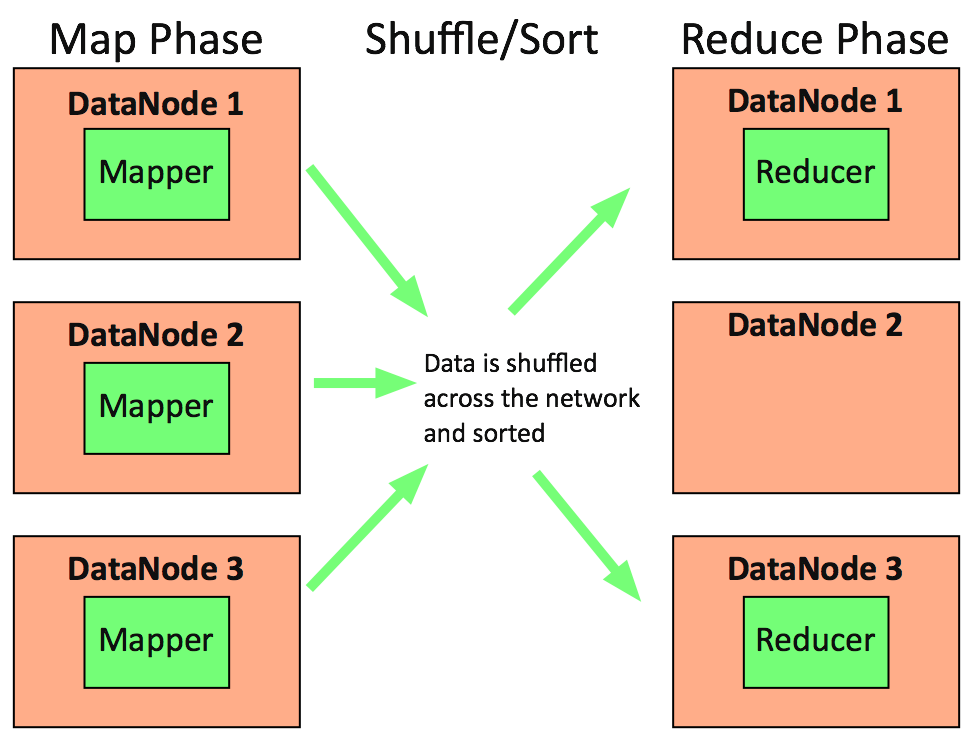
The primary data processing framework for big data on Hadoop is MapReduce, which is based on the paper published by Google in 2004.
The basic idea is that you process data in parallel by passing the processing code along to the location where the data lives (since the data is larger than the code in
these cases). You map your function across all the data in parallel, and then reduce those results into a singular resultset. This is the predominant way to process data
in Hadoop, and for a long time was the only way to process data.
MapReduce
Framework for writing applications that process large amounts of structured and unstructured data.
Designed to run batch jobs that address every file in the system.
Splits a large data set into independent chunks and organizes them into key, value pairs for parallel processing.
The primary data processing framework for big data on Hadoop is MapReduce, which is based on the paper
published by Google in 2004. The basic idea is that you process data in parallel by passing the processing code along to
the location where the data lives (since the data is larger than the code in these cases).
You map your function across all the data in parallel, and then reduce those results into a singular resultset.
This is the predominant way to process data in Hadoop, and for a long time was the only way to process data.
MapReduce Architecture
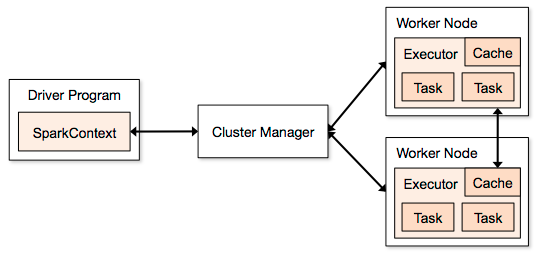
Spark Data Processing
Alternative to the traditional batch map/reduce model that can be used for real-time stream data processing and fast interactive queries that finish within seconds.
Spark is ideal for in-memory data processing. It allows data scientists to implement fast, iterative algorithms for advanced analytics such as clustering
and classification of datasets.
Spark is a is an alternative to Tez in many respects, as it also provides a way to process data using a DAG (directed acyclic graph), but it’s also an alternative to Pig as
it can be run natively within Java, Scala, or Python programs to execute functions across the data in your cluster with ease.
Spark can offer performance up to 100 times faster than Hadoop MapReduce for certain applications.
MapReduc e writes results to disk.Spark holds intermediate results in memory.
MapReduce supports map and reduce functions. Spark supports more than just map and reduce functions.
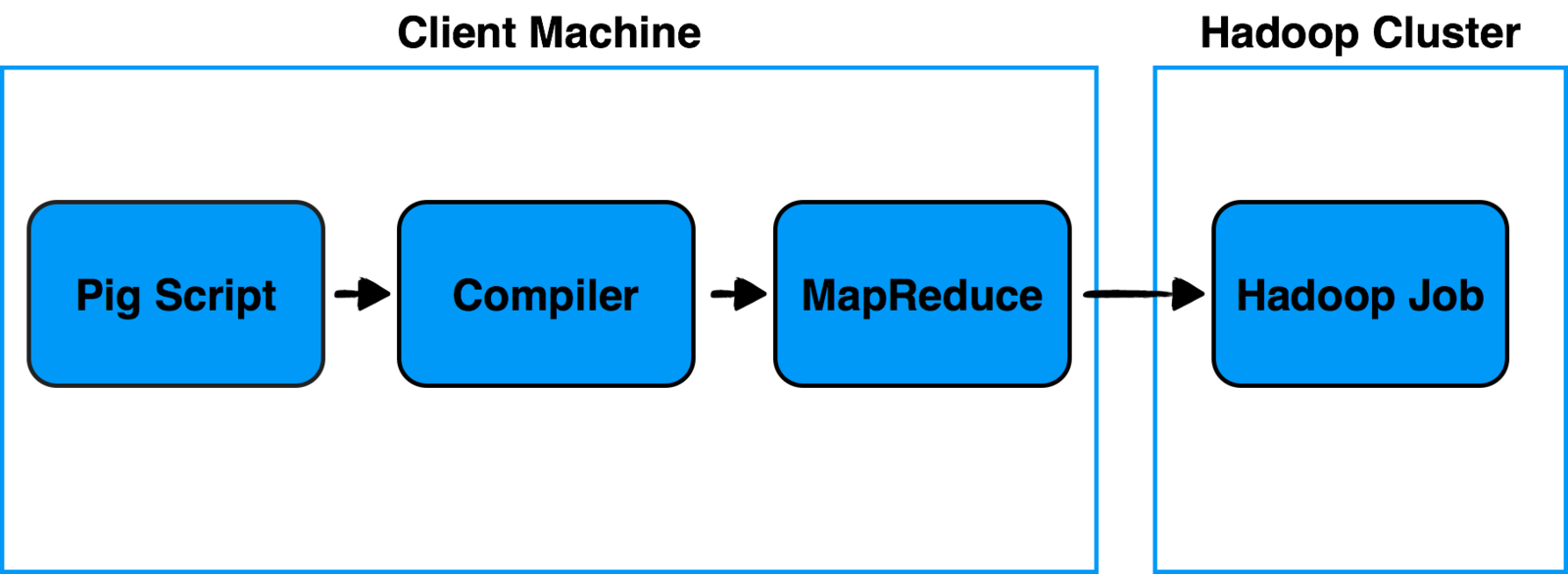
Pig
Allows you to write complex MapReduce transformations using a simple scripting
language called "Pig Latin". It's made of two components:
Pig Latin (the language) defines a set of transformations on a data set such as aggregate, join and sort.
Compiler to translate Pig Latin to MapReduce so it can be executed within Hadoop.
Pig is a Hadoop-based language developed by Yahoo.
It is relatively easy to learn and is adept at very deep, very long data pipelines (a limitation of SQL.)<
Pig
Hive
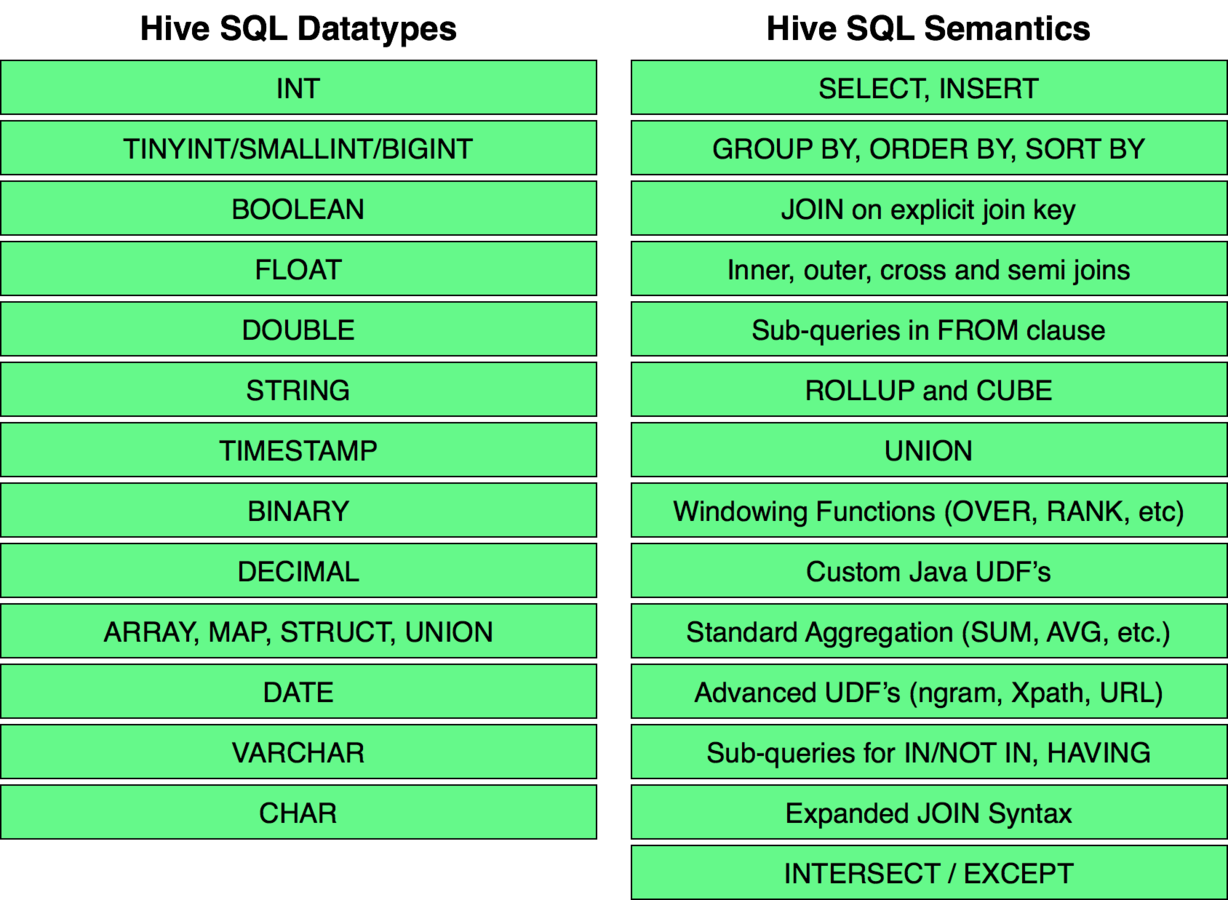
Used to explore, structure and analyze large datasets stored in Hadoop's HDFS.
Provides an SQL-like language called HiveQL with schema on read and converts queries to map/reduce jobs.
Hive is the oldest and most popular projects that provide an interface to Hadoop.
Allows users to write queries in a SQL-like language caled HiveQL, which are then converted to MapReduce. This allows SQL programmers
with no MapReduce experience to use the warehouse and makes it easier to integrate with business intelligence and visualization tools
Great website for Hive: https://cwiki.apache.org/confluence/display/Hive/Home
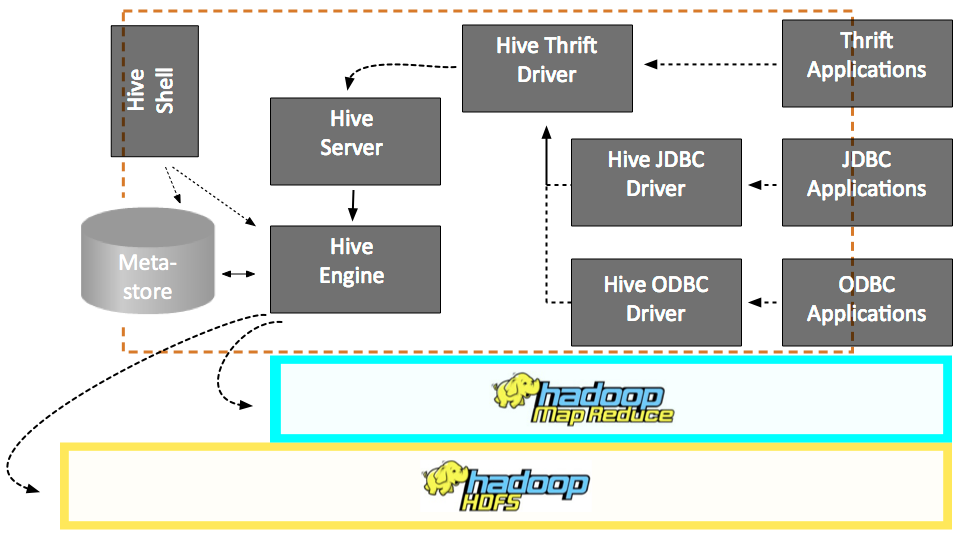
Hive Architecture
This diagram shows the major components of Hive and its interactions with Hadoop. As shown in this diagram, the main components of Hive are:
1. UI - The user interface for users to submit queries and other operations to the system. Currently the system has a command line interface and a web based GUI is being developed.
2. Driver - The component which receives the queries. This component implements the notion of session handles and provides execute and fetch APIs modeled on JDBC/ODBC interfaces.
3. Compiler - The component that parses the query, does semantic analysis on the different qurey blocks and query expressions and eventually generates an execution plan with the help of the table and partition metadata looked up from the metastore.
4. Metastore - The component that stores all the structure information of the various table and partitions in the warehouse including column and column type information, the serializers and deserializers necessary to read and write data and the corresponding hdfs files where the data is stored.
5. Execution Engine - The component which executes the execution plan created by the compiler. The plan is a DAG of stages. The execution engine manages the dependencies between these different stages of the plan and executes these stages on the appropriate system components.
Hive
Spark SQL
Part of the Spark computing framework.
Allows relational queries expressed in SQL, HiveQL, or Scala to be executed using Spark.
Used for real-time, in-memory, parallelized processing of Hadoop data.
Spark SQL
Spark SQL Use Cases
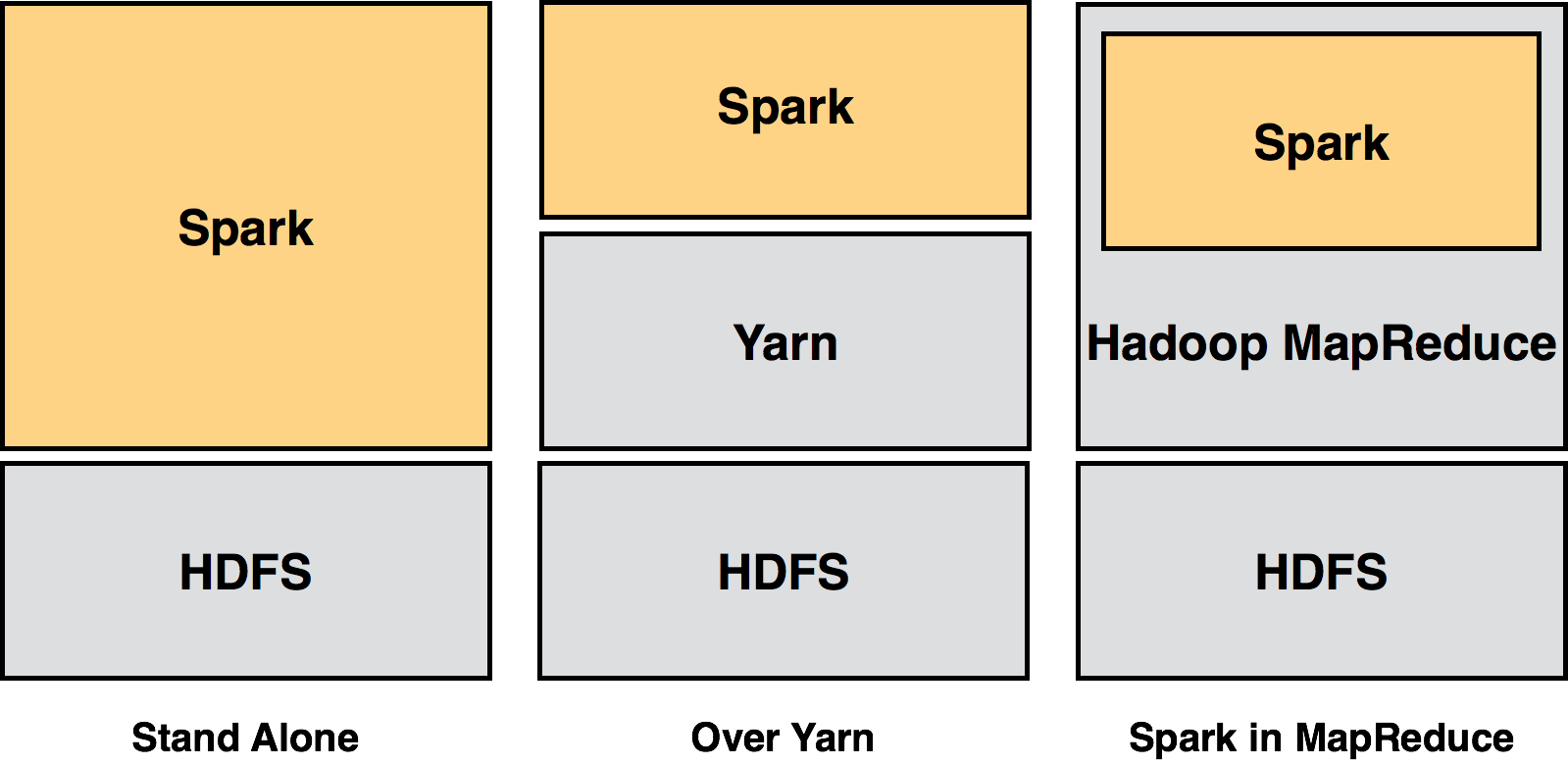
Stand Alone: Standalone deployment: With the standalone deployment one can statically allocate resources on all or a subset of machines in a Hadoop cluster and run Spark
side by side with Hadoop MR. The user can then run arbitrary Spark jobs on her HDFS data. Its simplicity makes this the deployment of choice for many Hadoop 1.x users.
Spark Over Yarn: Hadoop Yarn deployment: Hadoop users who have already deployed or are planning to deploy Hadoop Yarn can simply run Spark on YARN without any
pre-installation or administrative access required. This allows users to easily integrate Spark in their Hadoop stack and take advantage of the full power of Spark,
as well as of other components running on top of Spark.
Spark In MapReduce (SIMR): For the Hadoop users that are not running YARN yet, another option, in addition to the standalone deployment, is to use SIMR to launch Spark
jobs inside MapReduce. With SIMR, users can start experimenting with Spark and use its shell within a couple of minutes after downloading it! This tremendously lowers
the barrier of deployment, and lets virtually everyone play with Spark.
TEZ
Extensible framework for building YARN based, high performance batch and interactive data processing applications.
It allows applications to span the scalability dimension from GB’s to PB’s of data and 10’s to 1000’s of nodes.
Apache Tez component library allows developers to use Tez to create Hadoop applications that integrate with
YARN and perform well within mixed workload Hadoop clusters.
TEZ
Using Tez to create Hadoop applications that integrate with YARN
The Apache Tez component library allows developers to use Tez to create Hadoop applications that integrate with YARN and perform well within mixed workload Hadoop clusters.
website with more information: http://hortonworks.com/hadoop/tez/
TEZ
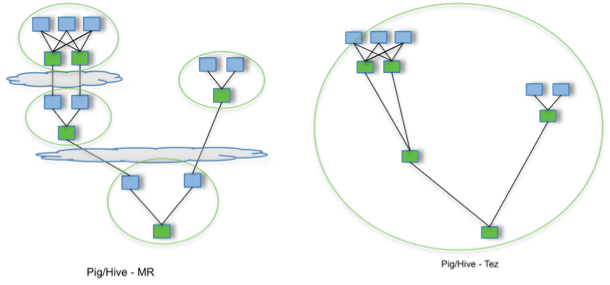
By allowing projects like Apache Hive and Apache Pig to run a complex DAG of tasks, Tez can be used to process data, that earlier took multiple MR jobs, now in a single Tez job as shown above.
Apache Tez component library allows developers to use Tez to create Hadoop applications that integrate with
YARN and perform well within mixed workload Hadoop clusters.
HBase
Column oriented database that allows reading and writing of data to HDFS on a real-time basis.
Designed to run on a cluster of dozens to possibly thousands or more servers.
Modeled after Google's Bigtable
EBay and Facebook use HBase heavily.
The active link on this slide is for a 1 minute and 42 second video that covers HBase. It's slides with music in the background.
When to use HBase?
When you need random, realtime read/write access to your Big Data.
When hosting very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware.
HBase 101 Architecture
Data streaming provides the ability to manipulate data as it enters or exits the system.
Think of it as the big data version of an RSS reader, except you can programmatically manipulate the feed as it’s generated.
Storm
Distributed real-time computation system for processing fast, large streams of data.
With Storm and MapReduce running together in Hadoop on YARN, a Hadoop cluster can efficiently process a full range of workloads from real-time to interactive to batch.
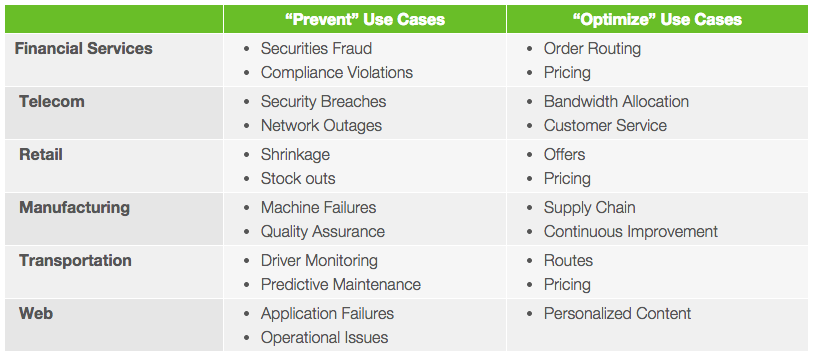
Storm Characteristics
Storm
Enterprises use Storm to prevent certain outcomes or to optimize their objectives. Here are some “prevent” and “optimize” use cases.
Storm
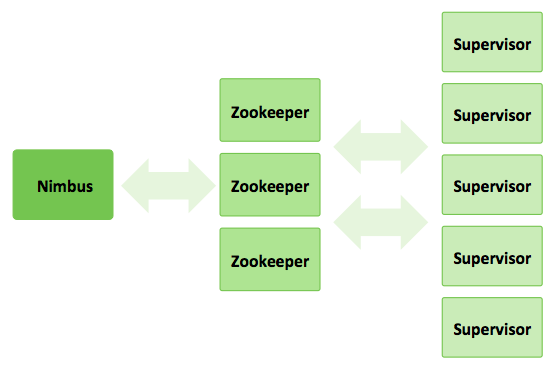
How Storm Works
A storm cluster has three sets of nodes:
Nimbus node (master node, similar to the Hadoop JobTracker):
Uploads computations for execution
Distributes code across the cluster
Launches workers across the cluster
Monitors computation and reallocates workers as needed
ZooKeeper nodes – coordinates the Storm cluster
Supervisor nodes – communicates with Nimbus through Zookeeper, starts and stops workers according to signals from Nimbus
Spark Streaming
Part of the Spark computing framework.
Easy and fast real-time stream processing.
Provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data.
Supports higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Spark Characteristics
Spark
Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ or plain old TCP sockets and be processed using complex algorithms
expressed with high-level functions like map, reduce, join and window.
Processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s in-built machine learning algorithms, and graph processing
algorithms on data streams.
Spark
Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by
the Spark engine to generate the final stream of results in batches.
this is a transition slide
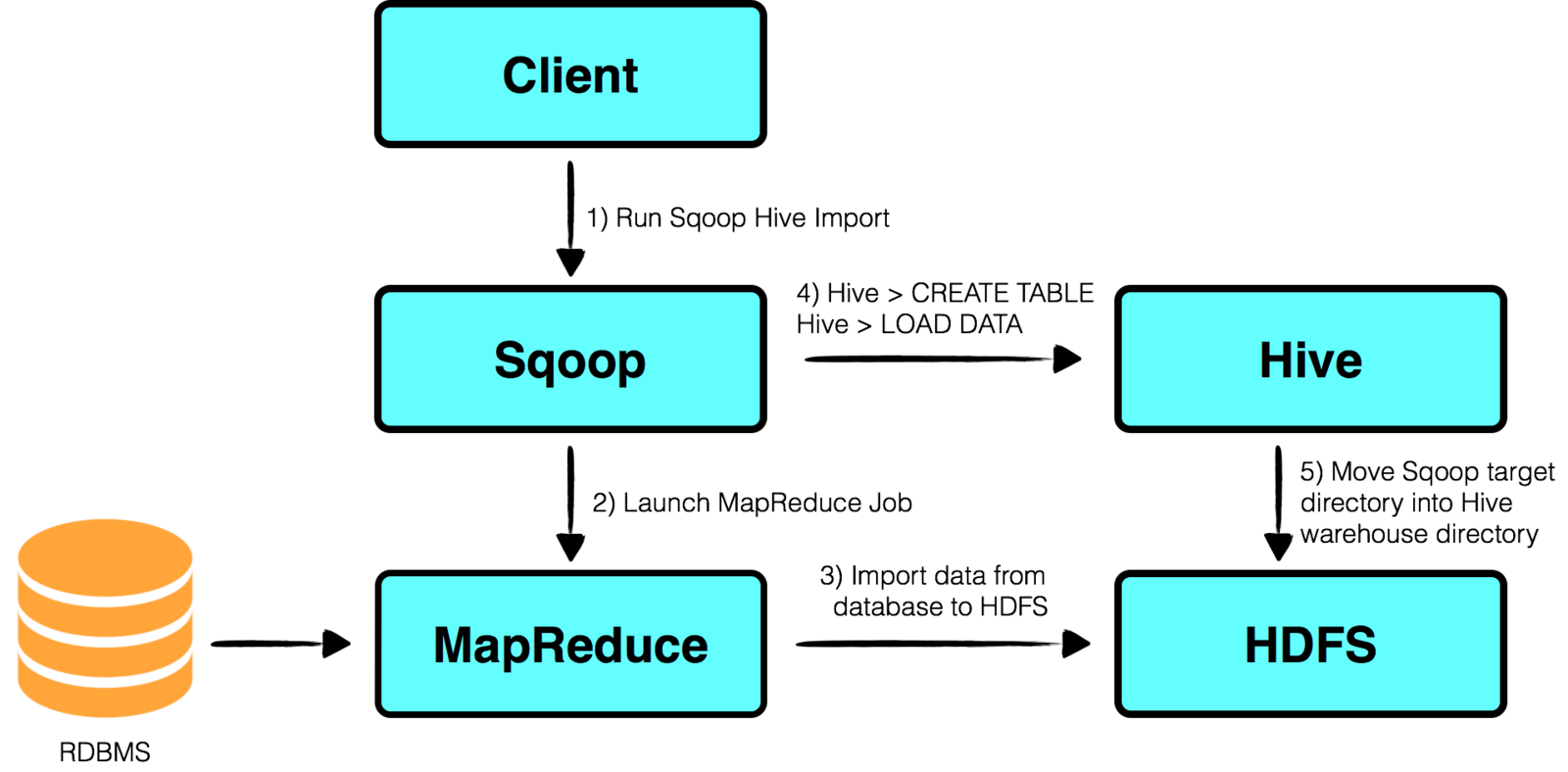
Sqoop
Command-line interface application used to transfer data to and from Hadoop to any RDMS.
Sqoop: Importing to Hive
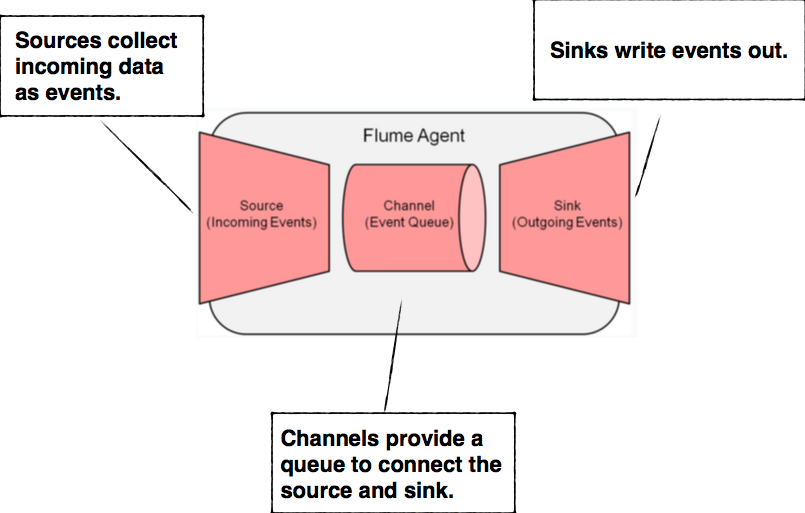
Flume
Application that collects, aggregates, and moves large amounts of streaming data into the Hadoop Distributed File System (HDFS).
Flume was the stream of tweets collected in Iron man 3.
Flume
Flume
Agents consist of three pluggable components: sources, sinks, and channels. An agent must have at least one of each in order to run.
Sources
Flume sources listen for and consume events. Events can range from newline-terminated strings in stdout to HTTP POSTs and RPC calls — it all depends on what
sources the agent is configured to use. Flume agents may have more than one source, but must have at least one. Sources require a name and a type; the type then dictates
additional configuration parameters.On consuming an event, Flume sources write the event to a channel. Importantly, sources write to their channels as transactions. By
dealing in events and transactions, Flume agents maintain end-to-end flow reliability. Events are not dropped inside a Flume agent unless the channel is explicitly allowed
to discard them due to a full queue.
Channels
Channels are the mechanism by which Flume agents transfer events from their sources to their sinks. Events written to the channel by a source are not removed from the
channel until a sink removes that event in a transaction. This allows Flume sinks to retry writes in the event of a failure in the external repository (such as HDFS or an
outgoing network connection). For example, if the network between a Flume agent and a Hadoop cluster goes down, the channel will keep all events queued until the sink can
correctly write to the cluster and close its transactions with the channel. Channels are typically of two types: in-memory queues and durable disk-backed queues. In-memory
channels provide high throughput but no recovery if an agent fails. File or database-backed channels, on the other hand, are durable. They support full recovery and event
replay in the case of agent failure.
Sinks
Sinks provide Flume agents pluggable output capability — if you need to write to a new type storage, just write a Java class that implements the necessary classes.
Like sources, sinks correspond to a type of output: writes to HDFS or HBase, remote procedure calls to other agents, or any number of other external repositories.
Sinks remove events from the channel in transactions and write them to output. Transactions close when the event is successfully written, ensuring that all events are
committed to their final destination.
Ambari
Operational framework for provisioning, managing and monitoring Apache Hadoop clusters.
Ambari is a 100% Apache open source operations framework for provisioning, managing, and monitoring Hadoop clusters.
It provides these features through a web frontend and an extensive REST API.
With Ambari, clusters can be built from ground up on clean operating system instances. It will do the job of propagating binaries, configuring services,
launching them, and monitoring them to all the hosts in a cluster.
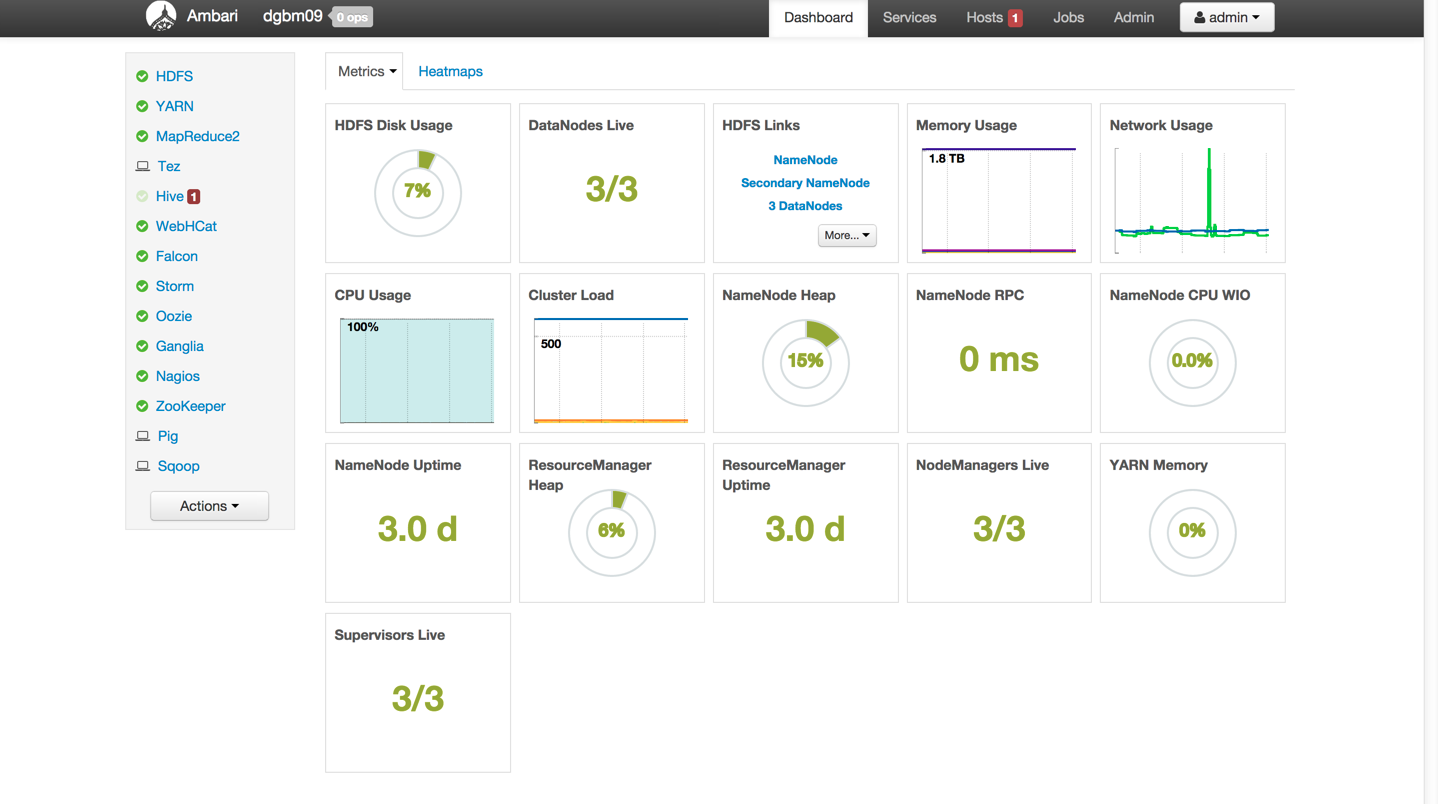
Ambari Dashboard
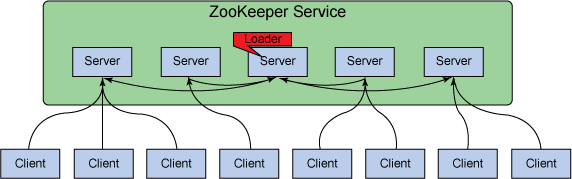
Zookeeper
Provides configuration service, synchronization service, and naming registry for software in the Hadoop ecosystem.
Distributed applications use ZooKeeper to store and mediate updates to important configuration information.
Zookeeper Benefits
Zookeeper
Clicl on the title's hyperliunk to learn how zookeeper works in the diagram
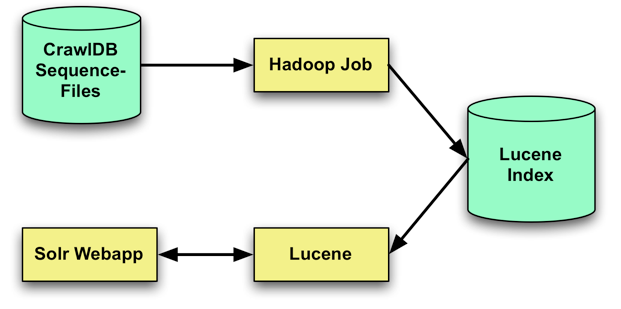
Solr
Searches data stored in HDFS in Hadoop.
Powers the search and navigation features of many of the world’s largest Internet sites, enabling powerful full-text search and near real-time indexing.
Solr Features
Near real-time indexing Advanced full-text search Comprehensive HTML administration interfaces Flexible and adaptable, with XML configuration Server statistics exposed over JMX for monitoring Standards-based open interfaces like XML, JSON and HTTP
Linearly scalable, auto index replication, auto failover and recovery
Hue
An open-source Web interface that supports Apache Hadoop and its ecosystem.
Hue is one of the many out of the box methods that HDFS provides for clients to interact with the file system.
DEMO
Hue
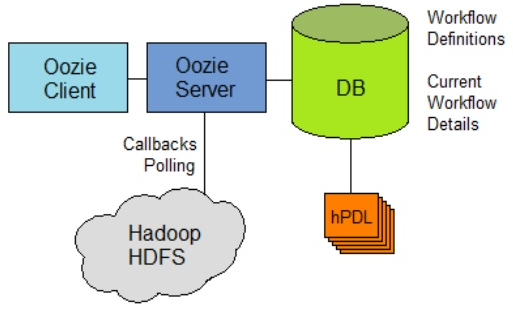
Oozie
Workflow scheduler system to manage Apache Hadoop jobs.
There are two basic types of Oozie jobs:
Serves the same purpose as Tez, but predates Tez and runs on top of other Hadoop constructs rather than below them.
Oozie Architecture
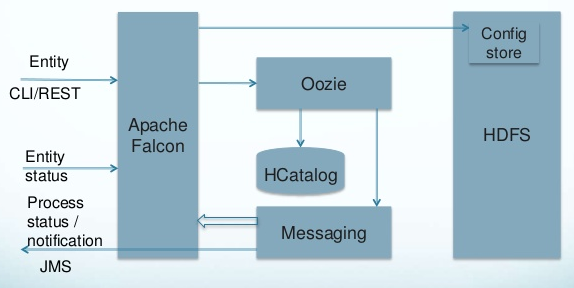
Falcon
Framework that simplifies data management by allowing users to easily configure and manage data migration, disaster recovery and data retention workflows.
Data management framework for simplifying data lifecycle management and processing pipelines on Apache Hadoop®. It enables users to orchestrate data motion,
pipeline processing, disaster recovery, and data retention workflows.
Falcon provides the key services data processing applications need. Falcon manages workflow and replication.
Falcon’s goal is to simplify data management on Hadoop. It achieves this by providing important data lifecycle management services that any Hadoop application can rely on.
Instead of hard-coding complex data lifecycle capabilities, apps can now rely on a proven, well-tested and extremely scalable data management system built specifically for
the unique capabilities that Hadoop offers.
Falcon also supports multi-cluster failover.
Falcon Architecture
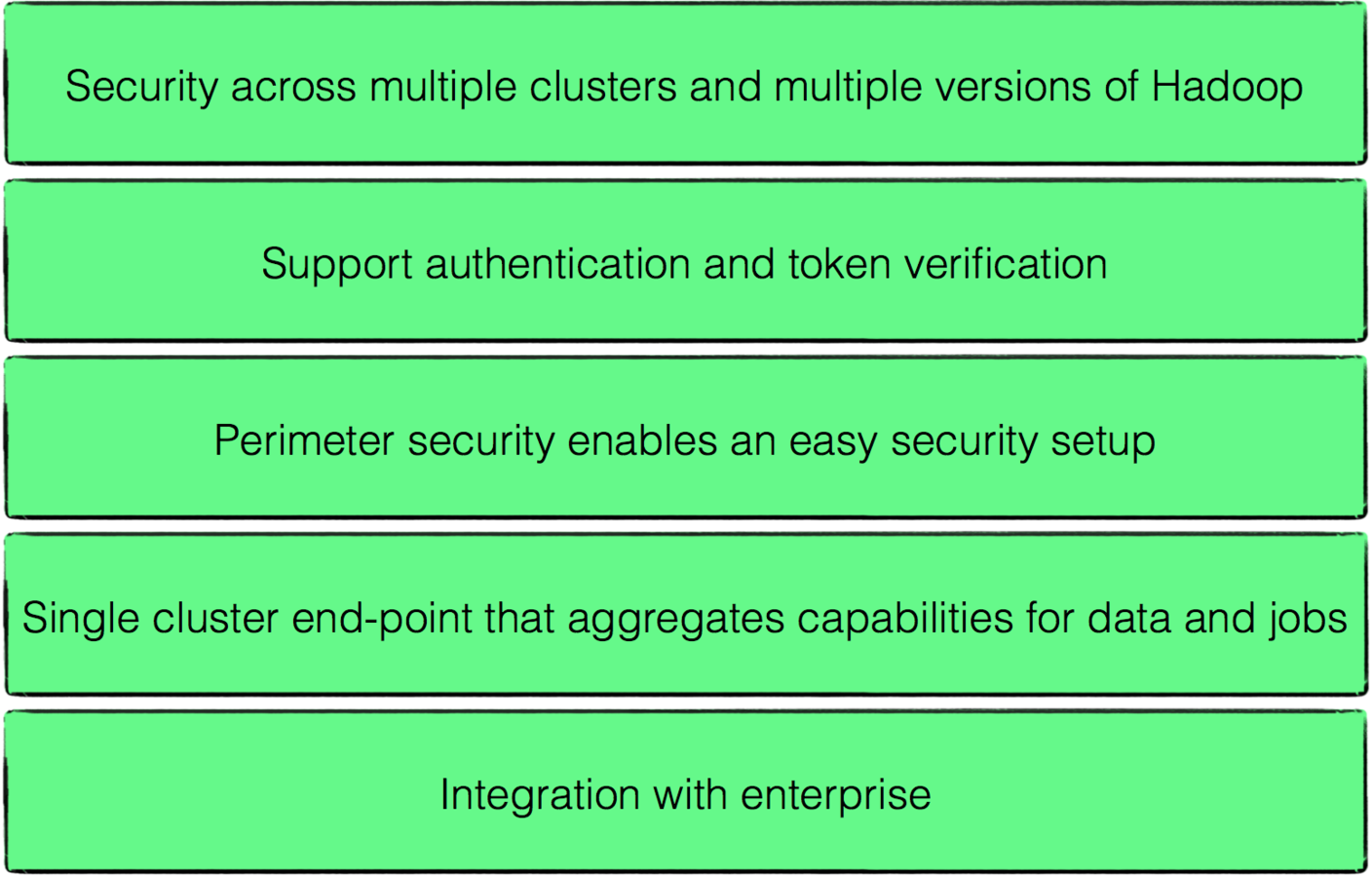
KNOX
Provides a single access point for Hadoop services in a cluster.
Knox runs as a server (or cluster of servers) that serve one or more Hadoop clusters.
Knox is intended to provide permiter security. It aims to provide a single point of entry into a Hadoop cluster for a user to access different services
such as HDFS, YARN, Hive, Oozie. Knox can be installed in HDP 2 as an add-on. A user authenticates once with the Knox service via Kerberos, while Knox itself handles serving
requests for that user inside the cluster.
Knox Advantages
Knox Architecture
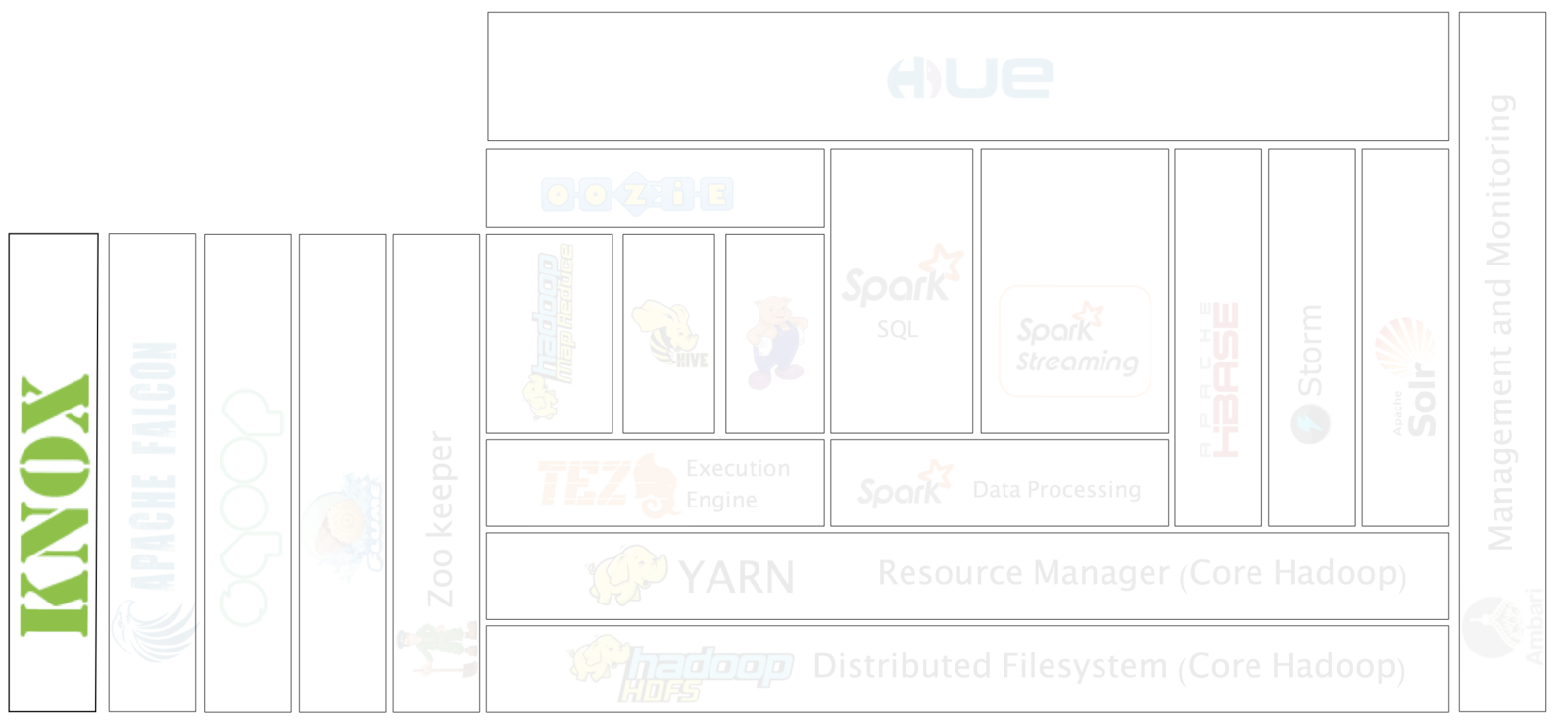
Let's take another look at the ecosystem
Find a use case for your group's assigned component
1. Form 2-3 person groups
2. Assgn each group to one of the columns...Data Processing | SQL Engines | NoSQL Engines | Data Ingest/Management | Stream Processing
3. Have the groups research a Hadoop use case for one or both of the Hadoop components in their assigned column
4. Have groups report their findings
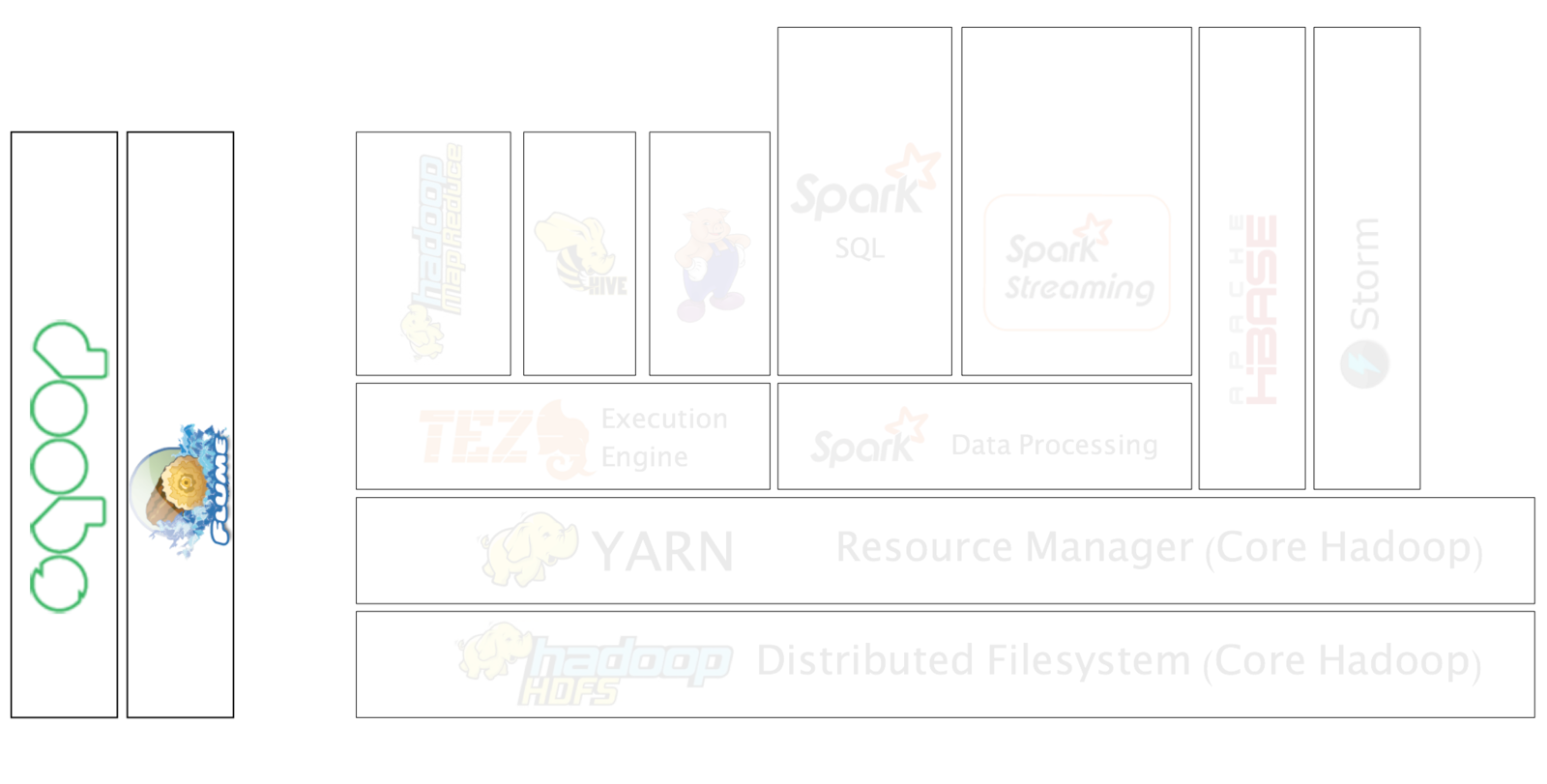
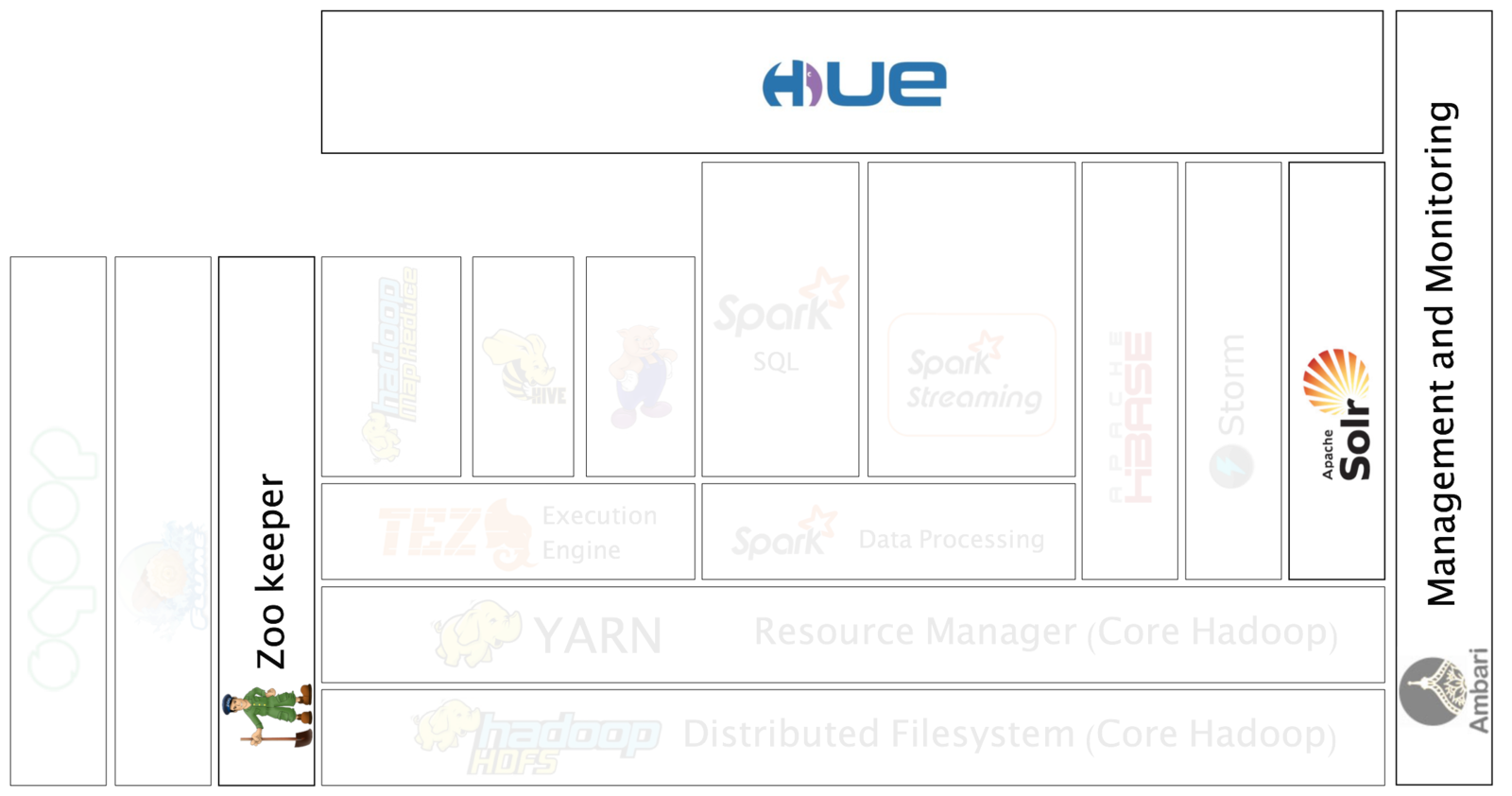
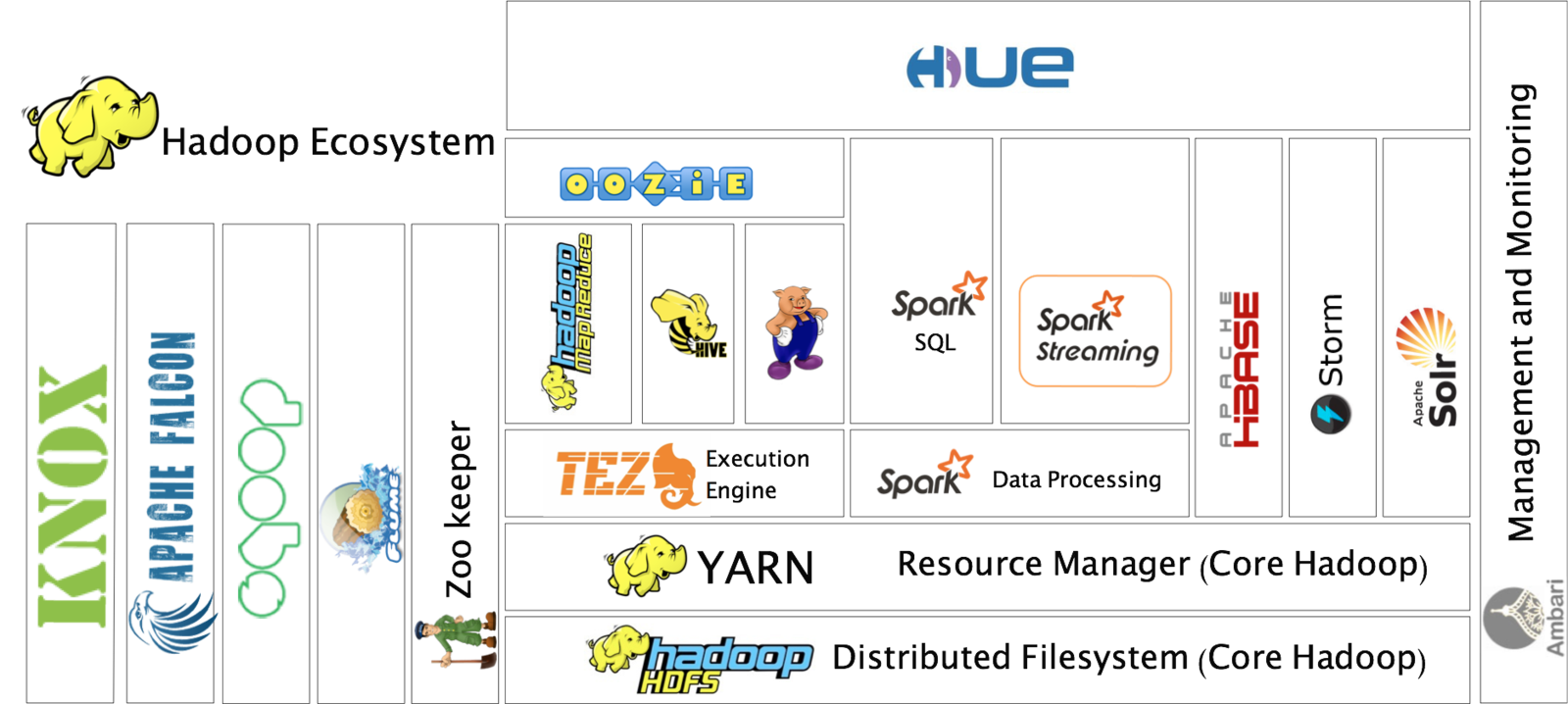
Hadoop Ecosystem
Hadoop Use Cases
Lots of things can be "Big Data". Today we will focus on Hadoop.
five major types of Hadoop data that organizations are using to increase business value, including everything from decreasing costs, optimizing security processes, and building value.
Sentiment: The most commonly sighted source, analyzing language usage, text and computational iinguistics in an attempt to better analyze subjective information. Many companies are trying to leverage this data to provide sentiment trackers, identify influencers etc.
Clickstream: The trail a user leaves behind as he navigates your website. Analyze the trail to optimize website design.
Sensor/Machine: These are everywhere: cars, health equipment, smartphones, etc. Nike put one in shoes. Someone also put one in baby diapers! They call it ‘proactive maintenance’.
Geographic: Location based data – a common use being location based targeting. This data has much more wider application in supply chain optimization across the manufacturing industry allowing organizations to optimize routes, predict inventory levels, etc.
Server logs: This one is not new to the IT world. You often lose precious trails and information when you simply roll over log files. Today, you should not have to lose this data; you just save the data in Hadoop!
Text: Text is everywhere. We all love to express ourselves - every blog, article, news site, ecommerce site you go these days, you will find people putting out their thoughts. And this is on top of the already existing text sources like surveys and the Web content itself. How do you store, search and analyze all this text data to glean for key insights? Hadoop!
Sentiment Data
Data collected from social media platforms ranging from Twitter, to Facebook, to blogs, to a never-ending array websites with comment sections and other ways to socially interact on the Internet.
While clickstreams will give a sort of Boolean understanding of customers and their actions, this is the era of social media where organizations can get a more subjective
appreciation of what their customers are thinking about them (and their competitors), and take actions to respond to these sentiments.
From Twitter, to Facebook, to blogs, to a never-ending array websites with comment sections and other ways to socially interact on the Internet, there is the potential
to be a massive amount of sentiment information available about any given company. That unstructured data creates problems for traditional databases; however, unstructured
data is where Hadoop shines.
An organization can collect all of these data streams and track how their customers and prospects feel about its products, the company itself, issues important to the
company, competitors and more. Correlating information about prevailing sentiments and their locations, a company can custom target their marketing and ad campaigns to
either capitalize on or combat the sentiments.
Sentiment Data
This use case is for sentimental and geographic data
Hadoop was used to track the volume of tweets around the movie’s launch. Three clear spikes in global tweet volume were identified, including the Friday premier,
the Saturday matinee time, and the Saturday evening showing. Correlating location data with sentiment analysis, the studio was able to see that in Ireland, over half the
tweets expressed positive sentiments about the movie, where in Mexico, negative sentiments about the movie outweighed the positive ones.
These sentiments were then tracked during the launch for real time marketing activities (i.e. increasing spends and extending campaigns in a particular market ), as well
as planning future movie launches.
Sensor/Machine Data
Data collected from sensors that monitor and track very specific things, such as temperature, speed, location
Sensor data is among the fastest growing data types, with data collectors being put on everything under the sun. These sensors monitor and track very specific things,
such as temperature, speed, location – if it can be tracked, there’s a sensor to track it. People are carrying sensors on them regularly (smart phones), and more come
online every day.
Hadoop is a very attractive store for sensor data due to the ability to dump so much of the juice into the framework and then use analysis tools to extract correlations
that give insights on operations, and how things change when conditions change.
Sensor data promises to be huge, as the desire to monitor the moment-to-moment status of things increases as businesses look for ways to increase efficiency and cut costs
in their operations. With every second, another data point needs to be stored, creating a challenge for existing traditional database paradigms. The relative cheapness of
Hadoop makes it a very attractive candidate for sensor data storage.
Sensor Data
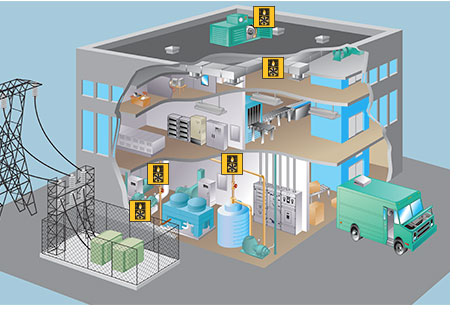
HVAC
Used Hadoop to monitor the heating ventilation and air conditioning also known as HVAC in 20 large buildings around the world.
Sensors and each HVAC system wirelessly transmitted temperature data that was combined with other data to maintain comfortable indoor environments and minimize heating
and cooling expense. They loaded, refined and visualized the sensor data. They loaded sensor data on the target and actual temperatures in the buildings. It flowed
into the Hadoop distributed filesystem known as HDFS via apache flume. They also used apache sqoop to import structured data on the HVAC units into HDFS. Think of this as a
data leg that contains years of data of their heating and cooling systems.
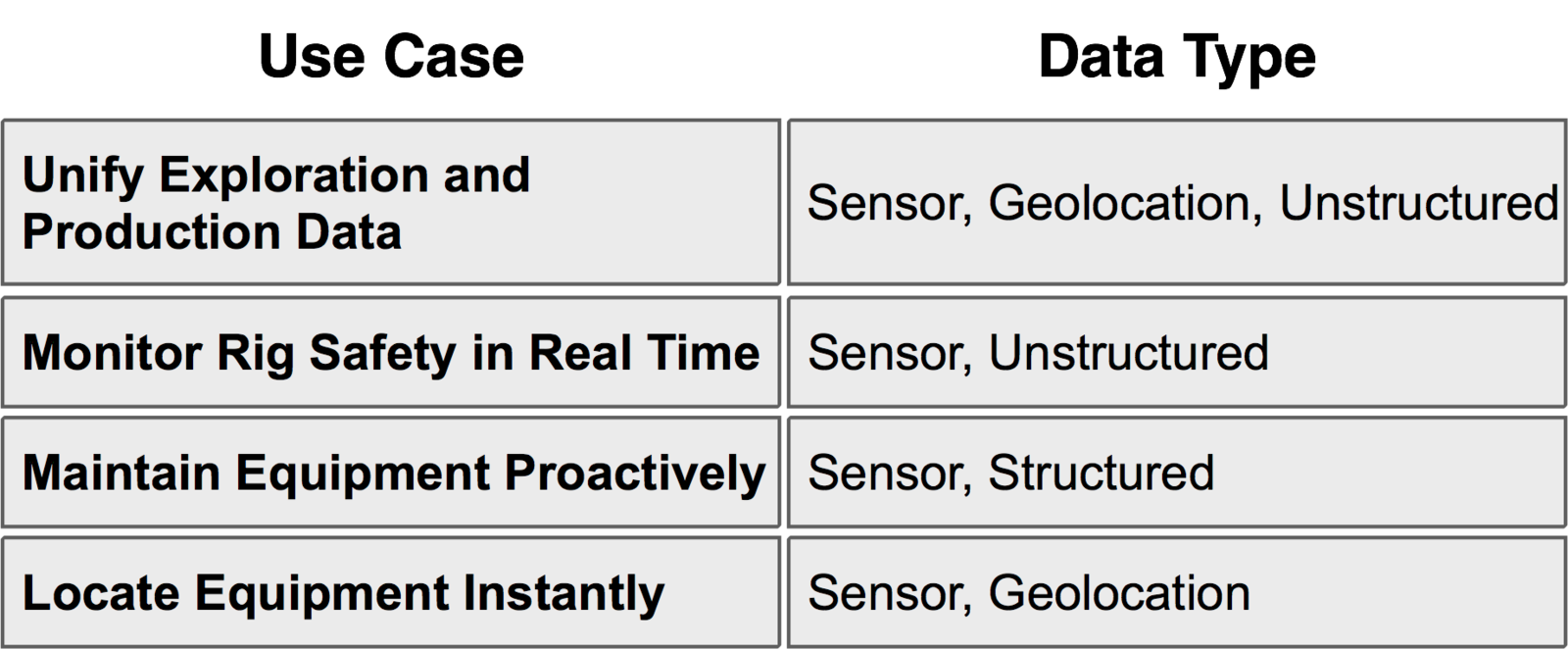
Geographic Data
Geolocation data gives organizations the ability to track every moving aspect of their business, be they objects or individuals.
Geolocation data gives organizations the ability to track every moving aspect of their business, be they objects or individuals.
In the age of smart phones, companies now have the ability to track their customers in ways that have previously been unimaginable.
Geographic Data
Geolocation
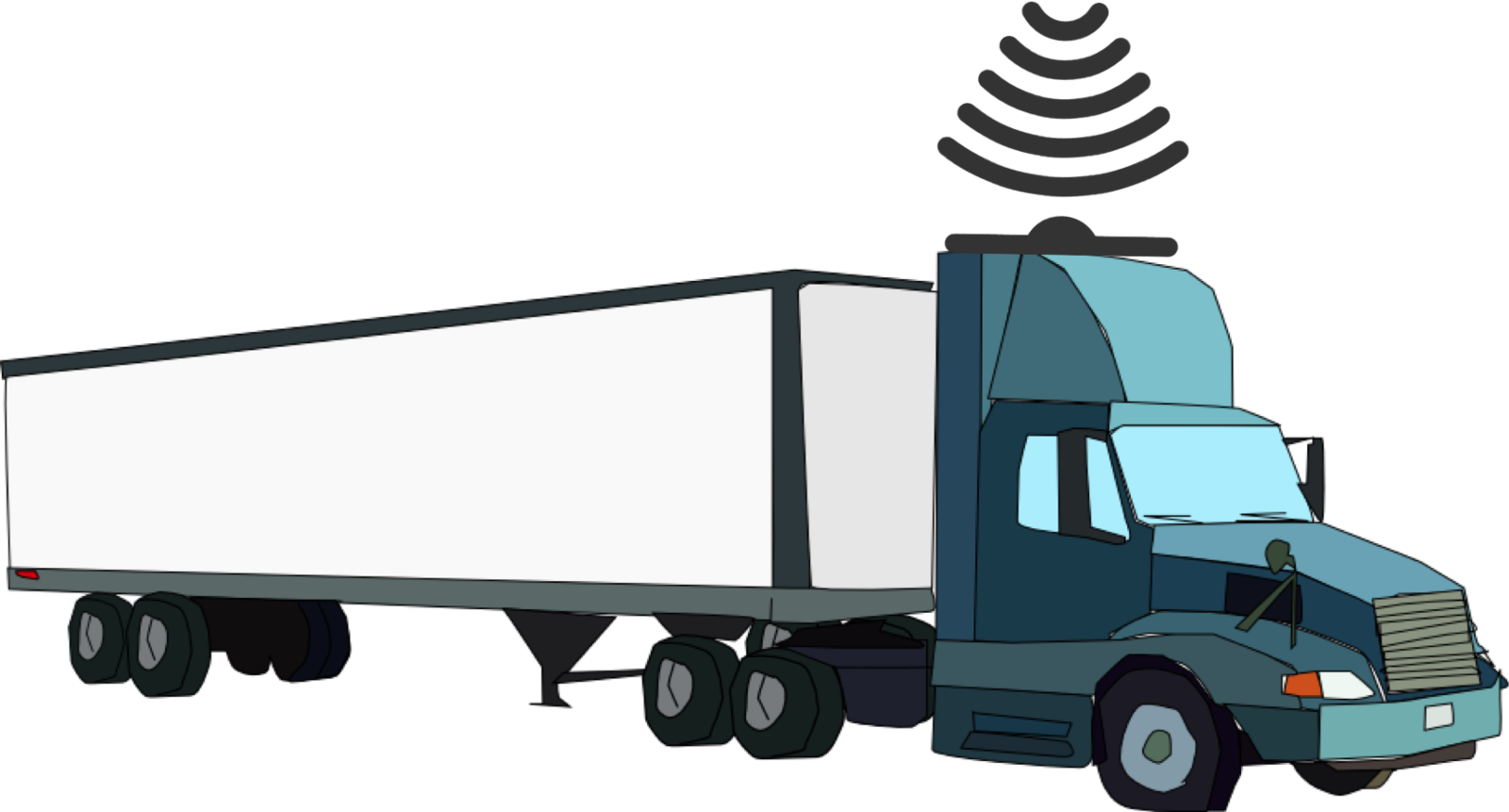
A trucking company used Hadoop to analyze geolocation data, reduce fuel cost, and improve driver safety. Geolocation identifies the location of an object or individual
at any point in time. This data might take the form of a cortinate or actual street address. Geolocation data is used to locate people or assets. For people enterprises can
learn where and when customer contegrate.
For assets, transportation and logistics companies can better maintain their vehicles and control risks.
This company placed sensors on 100 long haul trucks. The sensors communicate the position and speed of each vehicle. They also sense unsafe events such as speeding or
swerving. The company loads, refines and visualizes this geolocation data. Geolocation data from the trucks along with other types of data is loaded into HDFS.
Apache Flume streams geolocation data into HDFS and use apache sqoop to import structured truck data from a database.
Clickstream Data
Stream of clicks that a user takes as they path through a website.
Path Optimization
Basket Analysis
Next Product to Buy Analysis
Allocation of Website Resources
Granular Customer Segmentation
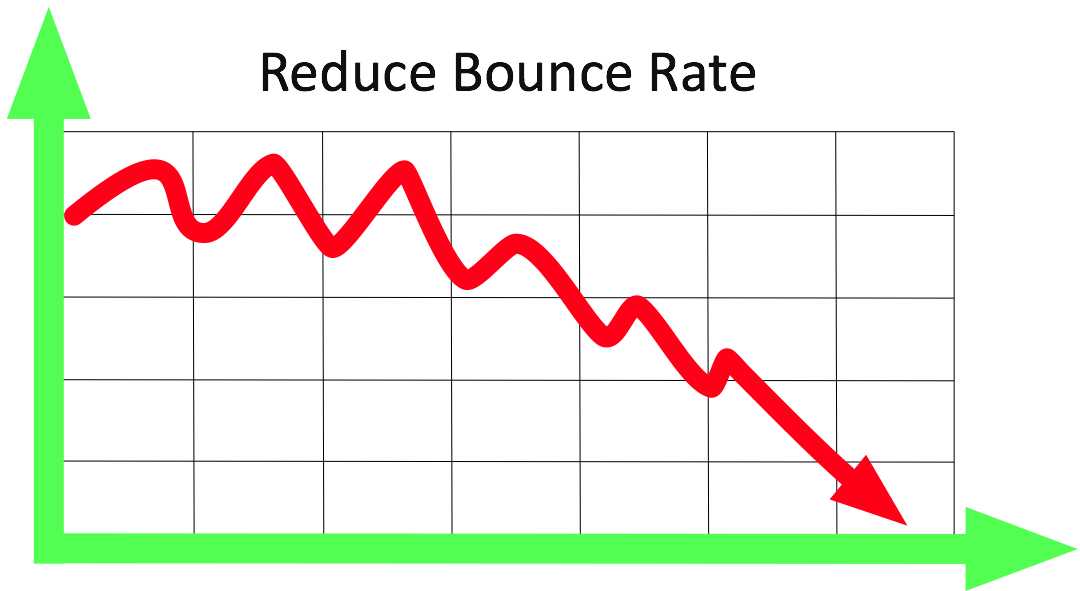
Path Optimization – Path optimization aims at reducing bounce rates and improving conversions.
Basket Analysis – This aims at understanding aggregate customer purchasing behavior by examining such things as customer interests, and paths to purchase – when customers
bought Product X, what common paths did they take to get there.
Next Product to Buy Analysis – Related to basket analysis, this type of analysis looks at correlation in purchases, and what can be offered next to help provide more
immediate value to the customer, and increase the likelihood of another sale.
Allocation of Website Resources – Having clickstream data on hand, a company will know what their hottest and coldest paths on the site are and can assign development
resources accordingly, optimizing resource allocation.
Granular Customer Segmentation – With clickstream and correlated user data, a company can discover and gain insight on how particular segments and micro-segments of
customers are using the site, and how to best cater to them.
Clickstream analysis is all about measuring users and their behavior. With the data collected, the hot and cold spots on a website can be located and actions taken to
ensure that users are seeing the most valuable offers.
Clickstream Data
Clickstream: Path Optimization.
A company wanted to change their website to reduce bounce rates and improve conversion. They used Hadoop to transform the sites data into three steps: Load, refine,
visualize the click stream.
First they loaded the raw web logs with customer and product data into HDFS. Then they moved clickstream files into HDFS. Hadoop allowed them to mount the HDFS file
system directly to their computer so the data could be loaded with a simple drag and drop. The clickstream file contained 5 days of clickstream data, about four million
(4,000,000) rows.
After sorting the bounce pages they could see that there were four top candidates for improvement they used hadoop to drive this insight from a huge clickstream web
log combined with customer and product records all in the data leg. This was done in just a matter of minutes.
Server Log Data
Server log data is for security analysis on a network.
Some estimates say that global internet traffic will reach 1 zettabyte (the equivalent of 1 billion terabytes) by 2015. All of this data, as well as all assorted
flavors of network traffic, winds up in server logs and is considered “exhaust data.”
One of the chief uses for server log data is for security analysis on a network. Admins are able to load their server logs into Hadoop using applications like Apache
Flume, building a repository that they can use for analysis in order to identify and repair vulnerabilities.
Server log data can be used for an array of purposes to give organizations insights on everything from network usage, security threats, and compliance. Hadoop will be a
central player in staging and analyzing this type of data for some time to come.
Server Log Data
A System Administrator's system looks good when he went to lunch. When he returned he noticed a ten fold spike in the number of support tickets.
And then his phone begins to ring off the hook. Members of his enterprise were unable to login to the VPN.
He captured and stored the server logs into the HDPS. This allowed him to see the logs from the VPN server flowing through Flume to HDFS. He noticed a distributed denial
of service or DDOS attack.
He could tell when the network traffic increased and could see that most of the traffic came from unauthorized machines. This helped him determine that this was a DDOS
attack. He was also able to see that the traffic was coming from several different companies where his company doesn't have a presence.
He used this data to update the firewall, deny requests from unauthorized IP addresses, and in a matter of minutes VPN access returns to his coworkers all over the globe.
Unstructured Video
Data from non-text-based things; that includes both images and also video.
If you were to store a bunch of images in a database, what you would really see in a database is they're just blobs. You can take a database,
you can store it, but you’ve basically turned a database into just storage. You can’t really express a SQL function that does anything with those images meaningfully.
In Hadoop, yes, you can store it, but you can actually process it and analyze it. This is one of the nice bits of flexibility that you get with the MapReduce framework:
When you do MapReduce in Hadoop, what you do for your Reduce function can be quite varied. That Reduce step could be things like study an image.
Unstructured Video
Sky Box Imaging Use Case
Sky Box Imaging is a satellite company. They launch a bunch of commodities satellites and take all kinds of overhead images of things going on in the world and then run
that through imaging processing, which is scaled out using MapReduce. They're basically grabbing lots of pictures of the world and they're using Hadoop to refine that
and put it into valuable information. Then they're selling that information as a service to large corporate customers.
For example, is in the oil and gas industry, if they want to actually count out how many refining pads there are in a given site in the world is because you're trying to
understand the aggregate capacity of your industry. That’s something that’s actually possible to do. If you want to count how many cars are in a retailer’s parking lot,
right, that’s an image-processing thing you can also do. So these are the types of things they're doing.
A more complex but interesting use case...
Astronomy department at the University of Washington processing astronomical images in Hadoop.
Astronomy in the Cloud: Using MapReduce for Image Coaddition!!!
Astronomical surveys of the sky will generate tens of terabytes of images and detect hundreds of millions of sources every night.
link to whitepaper: http://arxiv.org/pdf/1010.1015v1.pdf
Link to slides: http://www.slideshare.net/ydn/8-image-stackinghadoopsummit2010
Unstructured Text
Data collected from free-flowing text sources such as documents, emails, and tweets.
There is unstructured data, then there is unstructured text/content. There is a difference.
Unstructured text/content refers to documents, emails, and other objects that are made up of free-flowing text. The contents of a Tweet, for example, are a type of
unstructured text (while Tweet metadata – when it was posted and by who – is unstructured data).
Unstructured text lacks just about any form or structure we commonly associate with traditional corporate data. The text can be in any language, follow (or not follow)
accepted grammatical rules, and/or mix words and numbers. But the big difference between unstructured data and unstructured text is not what it is but what you do with it.
Unstructured text can be mined for the same type of patterns, but it also holds a treasure trove of insight that neither structured nor unstructured data offer:
human sentiment. Unlike most unstructured data, humans, not machines, generate unstructured text. Text written in Tweets, project proposals, and personal emails can reveal
what people are thinking and feeling.
Three steps for processing data from free flowing text:
1. Extraction: each document is split up into its individual words, and each word is counted by the map function
2. Summarization: the framework groups all identical words with the same key and feeds them to the same call to reduce
3. Analysis: for a given word, the function sums all of its input values to find the total appearances of that word
Unstructured Text
The process of legal reasoning and argument is largely based on information extracted from a
variety of documents. Lawyers are paid large hourly sums to analyze documents to build their
cases. Hadoop can help make this manual review process more efficient. Firms can store the
documentation in Hadoop, and then analyze that text en masse using processes like natural
language processing or text mining. This allows legal researchers to search documents for
important phrases and then use Hadoop ecosystem solutions to analyze relationships between
those and other phrases. This preliminary analysis optimizes the lawyer’s time reviewing the text,
so she can read the parts that really matter.
Source: http://hortonworks.com/wp-content/uploads/2014/05/Hortonworks.BusinessValueofHadoop.v1.0.pdf
Analytics Compute Grid
Analytics Compute Grid is a data analysis project
Rackspace uses Hadoop along with other big data technologies to understand customer patterns and identify trends.
This allows us to be better at delivering fanatical support to our customers using multiple data sources and systems.
Rackspace Analytics Compute Grid
The old model had a bunch of peace milled parts trying to integrate
Big Data: After Re-Architecting for Private Cloud
We used Openstack and new technologies like Hadoop and Cassandra to aggregate and make sense of all the data sources. This gives us a single view of customer info.
Popular Companies Leveraging Hadoop
Data Refinement... Distilling large qualities of structured and unstructured data for use in a traditional DW, e.g.: "sessionizatiuon" of weblogs
Data Exploration across unstructured content on millions of customer satisfaction surveys to determine sentiment.
Application Enrichment provides recommendations and personalized experience to website for each unique visitor.
Financial Services
Telecom
Retail
Manufacturing
Healthcare
Oil and Gas
Pharmaceutical
















































 "
"